
Abstract
Associative classification is a pattern recognition approach that integrates classification and association rule discovery to build accurate classification models. These models are formed by a collection of contrast patterns that fulfill some restrictions. In this paper, we introduce an experimental comparison of the impact of using different restrictions in the classification accuracy. To the best of our knowledge, this is the first time that such analysis is performed, deriving some interesting findings about how restrictions impact on the classification results. Contrasting these results with previously published papers, we found that their conclusions could be unintentionally biased by the restrictions they used. We found, for example, that the jumping restriction could severely damage the pattern quality in the presence of dataset noise. We also found that the minimal support restriction has a different effect in the accuracy of two associative classifiers, therefore deciding which one is the best depends on the support value. This paper opens some interesting lines of research, mainly in the creation of new restrictions and new pattern types by joining different restrictions.
Introduction
One capability usually associated to learning is the ability to analyze a large number of specific observations to extract and retain the important common features that characterize classes of these observations. In 1982, Mitchel [42] formalizes this as the problem of generalization: determining the most important generalizations that allows to differentiate a collection of positive objects from a collection of negative objects.
To select important generalizations, a predicate formed by a collection of restrictions is generally used. A restriction is a simple Boolean expression that can be evaluated on each observation, and ranges from the simple evaluation of a numerical measures to complex relations between observations. According to the type of restrictions used, these generalizations take particular names like subgroups[54], emerging patterns[15], contrast sets[10], supervised descriptive rule[46], contrast patterns[14], and discriminative patterns[39]. In this paper, we will refer to all with the term contrast patterns.
Associative classification (AC) is a pattern recognition approach that integrates classification and association rule discovery to build classification models (classifiers). These models are always formed by a collection of contrast patterns mined from the training sample. Associative classifiers are used in very different tasks like sentiment analysis [45], photovoltaic technology concentration [29], music analysis [12], prediction of chronic kidney disease [48], and heart disease prediction[50].
The high diversity in types of contrast patterns pose some challenges to select the appropriate one for a given problem. Firstly, the relation between the model accuracy and the type of contrast pattern used in problems is unknown. Published experimental comparisons derive only conclusions about the comparative behavior of different types using dataset collections. Secondly, every type of contrast pattern is formed by a particular subset of restrictions. Nevertheless, comparative studies evaluate types of contrast patterns, obscuring the contribution of each individual restriction. Finally, some types of patterns are introduced as novel although they are composed by already known restrictions or have minor changes with respect to previously defined ones.
Several authors have reported comparisons among classifiers on different datasets arriving to conclusions of which is the best classifier. As shown in this paper, without considering the imposed restrictions and values, these comparisons are meaningless. One algorithm can be significantly better than another algorithm under some restrictions and at the same time be significantly worst under different restrictions with the same datasets. For example, we show that classifier iCAEP[56], which is frequently considered superior to CAEP [16], is inferior for lower values of minimal support restriction.
A similar problem arises for researches comparing types of contrast patterns. For example, contrast patterns including the jumping restriction, that forbid the patterns to appear in other classes, are considered the most discriminative [20]. Nevertheless, we found that dataset noise degrade the quality of jumping patterns. Other example, the minimal support restriction is usually considered as very important to guarantee the quality of contrast patterns. Nevertheless, we found that, on some classifiers, increasing the minimal support deteriorates the classifier accuracy.
In 2018, García-Borroto[24] performed a theoretical study about types of contrast patterns from the perspective of their restrictions. For a better understanding, he grouped restrictions based on intuitions, which are insights about how a good contrast pattern should be. In order to provide experimental support to the conclusions in [24], González-Méndez et al. [30] performed some experiments. Nevertheless, their experiments have some important limitations.
In this paper, we extend the experimental evaluation performed in [30], with the following changes:
To avoid the bias that could create to use a particular miner, we mine all the frequent patterns after discretization using the FP-Growth algorithm. Since FP-Growth cannot deal with numerical attributes, we use the Entropy discretizer [21]. We evaluate a larger collection of restrictions, covering all the intuitions introduced in [24]. We use three different associative classifiers, with different algorithms for contrast pattern selection and vote aggregation. To avoid the problem of the impact of imbalance datasets in associative classifiers[41], we only use balanced datasets. We perform statistical analysis when appropriate.
According to our best knowledge, no similar study has been published, neither from the theoretical nor the experimental component. This study, along with its two previous papers, shift the focus from type of patterns to restrictions. Focusing on restrictions could help to understand better the behavior of existing types of contrast patterns and could guide the creation of new types of patterns that could improve the accuracy of associative classifiers.
The structure of the paper is the following. First, Section 5.2 introduces associative classifiers, including some formal definitions and the similarities/differences between them and other classifiers based on patterns. Then, Section 3 presents a review of different approaches to compare associative classifiers. Section 4 formalizes the restrictions based on different intuitions, including a review of their usage in different types of patterns. Section 5 presents the experiments performed together with the discussion of the results. Finally, Section 6 presents the conclusions and future work.
Let
The universe of all possible, maybe infinite, items is denoted
A pattern
An important measure related to patterns is the support, defined as the ratio of instances matched by the pattern in a given set
A contrast pattern is a pattern that appears significantly more in a class
Like most trainable classifiers, associative classifiers operate in two stages: model building and model exploitation [2, 1]. During model building, a training sample formed by objects whose class is known is used to extract contrast patterns from each class
During model exploitation, a query object
Model is built based on the information present in a training sample:
Find contrast patterns in the training sample. According to the type of pattern miner, this process might be performed independently per each problem class or in a single step per all classes. Prune not interesting patterns based on particular criteria.
The model is used to predict the class of a query object
From the contrast patterns mined in model building, find those matching Sort and filter the found contrast patterns, according to its relation to Aggregate the information of selected contrast patterns, usually by some form of vote aggregation; each contrast pattern emit a vote according to some pattern measure. Assign the most probable class to
Examples of associative classifiers are CBA [4], CAEP [16], BCEP[18], CSM [35], a fuzzy classifier FEPM [27], iCAEP[56], and specialized for imbalance datasets like PBC4cip [41].
Associative classifiers are similar to other pattern-based classifiers, but they have the following differences:
Rule based classifiers[53] Rules are obtained by sequential covering algorithms, so most of the resulting rules are local and not representative of the whole dataset. Then, to classify a query object a single rule or a small rule subset is selected. Lazy associative classifiers [52] A limited model is built for classifying a query object Decision trees [47] A decision tree is a tree where every path from a leaf to the root node represents a contrast pattern. In this way, it represents a hierarchical decomposition of the objects in the training dataset using a set of properties selected by a greedy algorithm. In these classifiers, a single contrast patterns matches the query object.
To solve a real problem using an associative classifier, users need to make some decisions that have a significant impact in the quality of the result: the classifier to use, the type of contrast pattern, the discretization procedure if it is necessary,1
Some contrast pattern miners require that all the features are discrete.
At each step, mining procedure is influenced by all the patterns mined before.
In 2018, García-Borroto[24] performed a theoretical study about types of contrast patterns from the perspective of their restrictions. For a better understanding, he grouped restrictions based on intuitions, which are insights about how a good contrast pattern should be. Although some interesting conclusions were suggested, no experimental evidence was provided to support them.
In order to provide experimental support to the conclusions in [24], González-Méndez et.at [30] performed some experiments. Nevertheless, their experiments have some important limitations. Firstly, only a single measure was evaluated per intuition using two classifiers. Secondly, contrast patterns were mined using an algorithm designed to mine a particular type of pattern, so it could bias the result. The used miner do not discretize the dataset, which was good for avoiding information loss, but it did not mine the whole set of patterns. That can also introduce some implicit bias very hard to detect. Thirdly, the datasets selected for experiments included imbalanced datasets, but the evaluation was performed using accuracy, a measure that could have a low performance in imbalanced datasets. Finally, no statistical analysis was performed.
This study, together with its two previous papers, shift the focus from type of patterns to restrictions, which could help to understand better the behavior of existing combinations of restrictions and to guide in the creation of new combinations that could help to improve the accuracy of associative classifiers.
For building an associative classifier, we need to mine useful contrast patterns. The definition of a useful contrast pattern usually includes a set of restrictions like minimum support or confidence. These restrictions are used for three main purposes: speeding up the mining process, avoiding noisy patterns, and avoiding redundant patterns. In [24], the author group these restrictions according to three intuitions or insights about what a good contrast pattern is, which appears implicit in many related papers.
In this section, we present some restrictions grouped by intuitions, using the following notations. The probability of finding an object with a given contrast pattern
This intuition is commonly measured using the pattern support
We omit here the original references because they are irrelevant for this paper. Readers can found them in [23].
Maybe the first and most used measure to estimate contrast is confidence Contrasting the probability of finding the pattern in both classes estimated by division in Emerging Patterns ( Restricting the appearance of the pattern in the negative class ( Contrasting the probability of finding and not finding the pattern in the positive class, using for example ( Testing for dependency between the pattern and the positive class, using different quality measures like (
The simplest restriction based on this intuition is (
( ( ( ( ( ( ( (
Restrictions used on different types of contrast patterns. Rightmost columns are associated to intuitions I1[24]
Table 1 presents a collection of existing types of contrast patterns[24]. Each column is associated with a particular intuition, and each cell contains the restriction used in the particular case. Based on the table, the author in [24] arrives to the following conclusions:
As expected, all types of contrast patterns include a contrast restriction. Many different quality measures have been used, no matter the high correlations reported between them [23]. Most types of contrast patterns with a minimal pattern restriction include also a minimal support restriction. This is somewhat unexpected, because minimal patterns have usually the highest supports. Only half of the contrast pattern types use restriction based on support. The author hypothesizes that this is because finding a good threshold for minimal support is hard and cannot be accurately estimated a-priori using dataset characteristics. The same restriction appears in different types of patterns. For example, restriction 1A appears 15 times and 2D appears 7 times. Additionally, different pattern types contains almost identical subsets of restrictions, which makes harder to select the appropriate one for a given problem.
In this section, we introduce the experimental evaluation of some selected restrictions belonging to the three described intuitions. First, Section 5.1 presents the experimental setup, including datasets and evaluation protocol. Then, Section 5.2 introduces the associative classifiers that will be used in the experiments. Since all types of contrast patterns include a contrast restriction, Section 5.3 evaluates those restrictions in order to select the best one. Restrictions belonging to the remaining two intuitions are evaluated in Sections 5.4 and Section 5.5.
Experimental setup
Dataset description according to number of instances, number of features, number of classes, minimal support used to mine frequent items, and number of frequent patterns mined. Since cross-validation was used, the last column is an average between the 10 folds
Dataset description according to number of instances, number of features, number of classes, minimal support used to mine frequent items, and number of frequent patterns mined. Since cross-validation was used, the last column is an average between the 10 folds
We selected 21 datasets from the UCI Machine Learning Repository [8] described in Table 2. From all the available datasets in that repository, we selected those with the following characteristics:
Balance between the number of classes to avoid dealing with imbalanced datasets. Datasets must have less than a million frequent patterns with very low support, to evaluate the minimal support restrictions. Datasets must have a large collection of contrast patterns with relative high minimal support threshold, to evaluate different contrast restrictions and how their behavior is influenced by the minimal support threshold.
Statistical tests for comparing classifiers were performed according to [13]. First, we performed a Friedman test with null hypothesis that the classifiers results are identical. Then, if the p-value is below 0.05, we rejected the null hypothesis and performed an all-vs-all Holm post-hoc to find out which classifiers actually differ. Classifier pairs with adjusted p-value below 0.05 are considered different.
Since all databases are balanced, all comparisons are performed based on accuracy, with datasets sampled using 10 folds cross validation. Ranks are calculated as in the Friedman test, using 1 as the best procedure, so lower rank values are better.
In this section we describe the three associative classifiers used in the experiments. They were selected because they are frequently used in comparisons and the source code is available.
CAEP[16] classifies an object
where
The second classifier, iCAEP[56], employs the minimum encoding inference approach to classify an object, based on the assumption that a good model is the one leading to a concise total description. To materialize this idea, iCAEP builds a model per class iteratively adding contrast patterns until all object properties are covered. Contrast patterns are selected from those mined in the class after sorting them using a particular criterion. Finally, the class that minimizes Eq. (2) is returned.
where
BCEP[18] uses contrast patterns matching the query object
Candidate thresholds used for each selected quality measure
Candidate thresholds used for each selected quality measure
The most important restrictions for associative classifiers are those in the Contrast intuition[24]. These restrictions are composed by a quality measure and a threshold value. Since many quality measures produce results whose ranks are very correlated, the results using one or the other are very similar [23, 40]. In this paper, we used the groups of correlated measures created in [40], selecting one per group. They are growth rate (gr), odds ratio (or), weighted relative accuracy (wracc), chi-squared (chi2), and strength. Selecting proper values of thresholds is a complex task with a direct impact in the quality of the result. In this study, we selected three candidate thresholds based on the histogram of each quality measure (Table 3). Then, results are compared taking into account the highest, median, and lowest value obtained per quality measure, with independence of the ordering of the threshold values. Figure 1 presents the results of the ranks per classifiers considering the highest accuracy value (Fig. 1a), the median value (Fig. 1b), and the lowest value (Fig. 1c).
Rank of the contrast metrics considering the maximum, median, and minimum accuracies obtained by different cut values.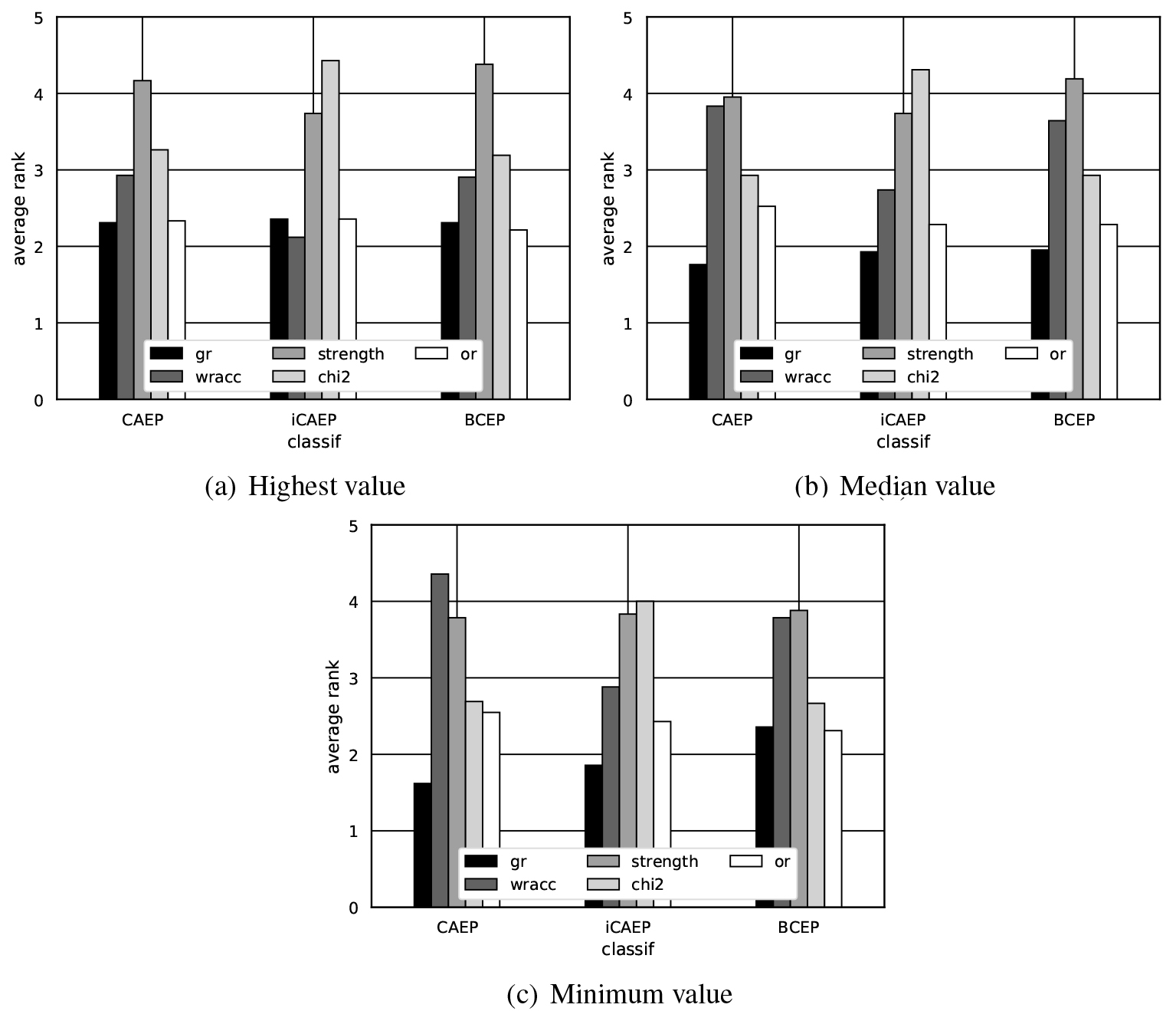
Figure 1a shows that the best ranks are achieved using gr and or in the three classifiers. Other measures like wracc have a good performance using some classifier, but not so good in the others. Figure 1b and c show that gr is usually equal or better than or. Due to all this, we conclude that gr is the quality measure with better performance.
Since the gr restriction has the best performance, we use the restriction
The jumping restriction (rst:Jumping) is frequently used in many different types of contrast patterns, thus it deserves a particular analysis. In [30], an experiment shows the impact of the level of noise in the dataset in the quality of patterns mined with such restriction. In this subsection, we will expand previous results.
In this experiment, we randomly insert noise to all datasets in levels from 0.02 to 0.12, with increments of 0.02. With higher noise levels, the accuracy drops so significantly that no analysis is possible. To add the noise, random objects are selected and its class is changed to a different random class.
Rank comparison of the accuracy using and not using the jumping restriction with different levels of noise.
Figure 2 shows the ranks of each of the tested classifiers using two different sets of patterns: the patterns with the jumping restriction (jep) and all the patterns (nojep). Results for CAEP (Fig. 2a) and iCAEP (Fig. 2b) are similar: when there is no noise inserted, patterns with the jumping restriction are better, and the more noise is inserted the more the jumping pattern quality deteriorates. In the case of BCEP (Fig. 2c), using all the patterns always leads to better results than using jumping patterns. Nevertheless, after
To look for an explanation to this behavior, Fig. 3 shows the number of patterns found by the miner, both jumping and total patterns. Since jumping patterns are a subset of the total pattern set, we show the ratio of the number patterns with respect to maximum number of patterns found when no noise is introduced. As can be seen, in most datasets, after some noise level, the number of jumping patterns decreases more rapidly than the number of total patterns, and this could be a factor in the accuracy drop.
Number of patterns, with respect to the patterns without noise, while increasing the level of noise from value 0 to 0.12. Black line is using the jep restriction, while gray is without using it.
In this section, we evaluated the minimal support restriction (
The minimal support restriction is used mainly for the following reasons:
Control the mining time and the space consumed by the mined patterns. This can be critical, because even small datasets can contain very large collections of contrast patterns. Control the classification time. This is important, because most associative classifiers need to use the whole pattern collection in order to classify query objects. Accuracy of the classifier. Since contrast patterns with low support can appear due to chance, removing them is expected to increase the quality of the resultant classifier.
Accuracy of classifiers CAEP (black, dotted), BCEP(gray, dashed) and iCAEP(light gray, continuous) per dataset with respect to minimal support value. Values in the 
In this section, we will focus on the third reason, which is the one related with classifier accuracy. The remaining two reasons might be applied in some cases even if they imply a drop in accuracy. Figure 4 shows the accuracy (between 0 and 1) of all the tested datasets, while increasing the value of the minimal support threshold.
Results are different for the tested classifiers. For CAEP (black line), increasing the minimal support threshold usually deteriorates the classifier accuracy. This might be explained because objects in the class border usually only match with low-supported contrast patterns. Then, if we remove low-supported patterns, those objects do not match any pattern or just match a few, therefore vote aggregation is no longer a good class estimation.
BCEP (gray line) has a similar behavior to CAEP, for a similar reason: removing low supported patterns can make the product approximation of the class posterior probability of border objects very unreliable or even impossible to calculate.
Finally, the behavior of iCAEP (light gray) is different in some datasets. This is because iCAEP iteratively builds a model for classification starting by contrast patterns with larger number of items. If low supported contrast patterns are allowed, they will be used with high probability in the final classification. Since low supported patterns are usually low quality patterns, the accuracy might be deteriorated.
Average ranking of the classifiers using different minimal support restrictions.
To compare among the accuracies of these classifiers, Fig. 5 shows a rank comparison of them using different minimal support thresholds. This figure shows that, for lower minimal support values, the CAEP classifier is better than the other two classifiers, by a large margin. On the other hand, increasing the minimal support threshold favors iCAEP, which is better for higher thresholds. The statistical analysis, performed independently for each threshold value, reveal that differences were only significant for extreme values of the minimal thresholds: 0, 0.1, and 0.25.
This result could explain why the iCAEP is usually reported as a superior classifier than CAEP: all comparative studies use a minimal support threshold and do not evaluate the influence of that support in the tested classifiers. For example, in [56], iCAEP is reported to be better than CAEP using a minimal support threshold of 0.1. This threshold value is close to the point where we find iCAEP to start outperforming CAEP. The influence of the minimal support threshold in the behavior of a supervised classifier is frequently reported in other classification problems [3].
Restrictions in the minimal intuition are used for the following reasons:
To reduce pattern set redundancy, because in many datasets there are large amounts of very similar patterns, and using all of them could induce errors. Removing the redundancy allows also to have smaller models and faster classifiers. To make the classifier tolerant to noise, because the most general patterns are usually those with the largest supports, and their quality measures are less affected by wrong labeled objects. To substantially reduce mining time in generative methods, because once the algorithm finds a contrast patterns, more particular patterns do not need to be generated and tested.
In this section, we evaluated the simplest restriction in the minimal intuition: to reject all the contrast patterns that are not minimal. We do not evaluate other restrictions because each one is used only in a single paper. We compare the accuracy results using three different pattern sets: all the patterns (all), those fulfilling the minimal pattern restrictions (minimal), and those not fulfilling the minimal pattern restriction (non-minimal). We also explore the influence of the classifier and the minimal support threshold in the result as can be seen in Fig. 6.
Ranks of the collection of minimal patterns, non minimal patterns, and all patterns, using different minimal support levels.
We can extract some conclusions. On the one hand, removing minimal patterns deteriorates the classifier in almost all configurations, so minimal patterns are important. On the other hand, using minimal patterns deteriorates the quality for lower minimal supports. For higher minimal supports, the results depend on the classifier, but tend to favor minimal patterns. Differences between non-minimal and the other two sets are statistically significant for most values of min_sup (details appear in the sub-figure headers), but minimal patterns and all patterns were not found different in statistical tests. These results could explain to some extent a conclusion of the previous paper that show that most types of contrast patterns that include a minimal restriction include a minimal support restriction.
Summarizing, using a minimal pattern restriction could be beneficial if a minimal support restriction is included. In those cases, the decrease in the mining time with no drop in accuracy can be particularly beneficial.
In this paper, we extend two previous papers that evaluate theoretically and experimentally various of the most important restrictions used in associative classifiers. We conducted experiments to evaluate the impact of using those restrictions in the accuracy of three different associative classifiers. This section presents the conclusions we extracted and future work.
First, we evaluated restrictions on the Contrast intuition, which are formed by a quality measure and a threshold value. We grouped quality measures according to their similarities, selecting one per group. For each selected measure, we find three candidate threshold value using the histogram of their values. Experimental results show that the restriction based on growth rate achieves the best results for all tested classifiers, so we selected the restriction
Second, we evaluated a particular contrast restriction used in many papers, which is the jumping restriction. This restriction forces the contrast patterns to have zero support in all but one class, so it should be particularly affected by the level of noise in the database. Then, we introduce different increasing noise levels, contrasting the accuracy of jumping patterns with the whole pattern collection. We find that the accuracy of all classifiers significantly deteriorates. We also provide a candidate explanation to that accuracy dropping based on the drop in the number of patterns.
Third, we tested the impact of using the minimal support threshold, finding that for classifiers CAEP and BCEP it deteriorates the result quality in all tested datasets. Then, these restrictions should be added only for reducing both the classification time and memory consumption of the model. For iCAEP, a minimal support threshold might be necessary to improve the classification accuracy. Consistently with those results, the accuracy comparison among the three classifiers depends on the minimal support threshold used: for lower support thresholds CAEP is better while for larger thresholds iCAEP is better. This influence of the minimal support threshold in the quality of the results deserves more attention in the papers where similar comparisons are performed, because it could be biasing the conclusions.
Finally, we tested the most commonly used restriction on the minimal intuition. We find that minimal patterns are important, because removing them always deteriorates the classifiers accuracy. Additionally, we found that using minimal patterns is similar to using all the patterns for higher minimal support values. Since mining minimal patterns could be significantly faster than mining all the patterns, using this restriction could make sense in most cases.
This paper opens some interesting lines of research. First, more experiments are necessary to evaluate other existing restrictions, some of them maybe from new intuitions. Second, different non-known combinations of restrictions could be tested in order to find new and better types of contrast patterns. Finally, experimental evaluations of associative classifiers could be performed, in order to find the relations between their behavior and the restrictions used.