
Abstract
The Associative Pattern Classifier (APC) was designed as an associative memory, focusing particularly on pattern classification. This implies that the training memory is constructed in a single operation and pattern classification also occurs in a single process. It is important to note that the APC translates the input patterns through a translation vector, which represents the average of all input patterns. Until now, there is no theoretical framework to explain the inner workings of the APC. Its relevance is inferred from the fact that several studies have been conducted using it as a foundation. This paper seeks to provide a theoretical comprehension of the APC’s operation to facilitate future enhancements. We found the APC creates a system in static equilibrium through concurrent vectors at the origin (translation vector), resulting in a balanced separation of patterns. However, the APC cannot achieve complete pattern separation because of the presence of a neutral region. The neutral region is defined by all the points that define the separation hyperplanes. The points over the hyperplanes cannot be classified by the APC. Additionally, we discovered that the APC is unable to accurately classify the translation vector, which could be included as part of the input patterns. Our previous research showed that the APC is unsuccessful in achieving the linear separation of the AND function. In this research, we also broaden the examination of the AND function to illustrate that achieving linear separation is not feasible because the separation line represents a neutral region. The APC demonstrated exceptional performance when tested with artificial datasets where patterns were distributed over balanced regions, thus operating as an efficient multiclass and non-linear classifier. Nevertheless, the performance of the APC is lower when tested with real-world databases, making the APC inaccurate due to its restricted inner workings.
Introduction
An Artificial Neural Network (ANN) with a layer is referred to as Associative Memory (AM) [1, 2]. In an AM, each input pattern is associated with an output pattern. This means that an AM can associate pairs of similar or different patterns, making it capable of both autoassociative and heteroassociative tasks. Classification is a form of pattern heteroassociation [1, 2]. Let’s consider a set of learning patterns divided into a predefined number of classes. In response to an input pattern, the AM provides a class vector expressed with discrete values. There are two distinct operational phases in an AM: the construction and the retrieval phases. During the construction phase, a matrix or memory is generated. In the retrieval phase, an input pattern is presented to the memory to obtain its corresponding associated output pattern or class. Within an AM, there are two modes of pattern retrieval: static and dynamic. In static retrieval, the output pattern is determined through a simple synchronous update step. In dynamic retrieval, the output pattern is determined through an iterative feedback process [3].
The first reported model of AM in the literature is the Lernmatrix [4, 5]. This model can function as a binary pattern classifier, associating each pattern with its corresponding class. A second proposed model of AM is the Linear Associator (LA) [6–8]. The Learnmatrix can only accept binary patterns as inputs for classification. When the necessary and sufficient conditions, mentioned in [9–11], are not met, the Lernmatrix is not capable of recovering the fundamental set of associations. On the other hand, the LA imposes a strong constraint by requiring the orthogonality of input patterns [12]. For LA, perfect retrieval of the fundamental ser of associations is not achievable unless the number of stored patterns is small compared to the dimension n of the input patterns. Some researchers suggest that this small number of patterns should be between 0.1n and 0.2n [13–15]. In general, the purpose of AMs is pattern association rather than classification.
The Associative Pattern Classifier (APC) [16] is an AM with a specific purpose of pattern classification. The APC algorithm is proposed to address the drawbacks of the Lernmatrix and LA. This algorithm is primarily based on the training rule of the LA and the recovery rule of the Lernmatrix. In the APC, both the construction and recovery stages are performed statically. This means that the training memory is created in a single step, and pattern classification is also done in a single step. This algorithm enables real-number operations, overcoming the limitation of the Lernmatrix, which operates exclusively on binary numbers. It also removes the orthogonality constraint of the training set in the LA, as well as the restriction that the number of patterns in the training set must be small relative to the input pattern dimension. Furthermore, it maintains stable classification performance when trained with at least 10% of the total patterns from a given database [17].
Until today, since the inception of the APC in 2003, there has been a lack of a formal or theoretical framework for how it works. However, it has been deduced that it is accurate, as evidenced by the fact that some studies have been developed based on it. For example, in [18], the APC was employed to diagnose breast cancer, achieving an accuracy of 97.31% on the Breast Cancer Wisconsin database. In [19], an improvement that reduces the limitations of the original algorithm for multiclass processes was successfully implemented. In [20], was integrated the APC with an innovative coding technique and a voting procedure that enhanced the APC’s performance. Meanwhile, in [21] it was reported that the APC achieved the highest true positive rate in comparison to three traditional ANNs when tested on a collection of 58 real-world databases with imbalanced data. Aldape-Pérez [22] introduced a reinforcement phase following the training phase of the APC, specifically for medical diagnosis. Throughout all the tests, the proposed method consistently outperformed other algorithms in terms of average performance. In [23], a modification using fuzzy logic is presented for the diagnosis of diabetes mellitus. In that proposal, a degree of membership to each class is assigned to each training pattern, done before proceeding with training. The proposed algorithm only outperforms the others in average sensitivity. The author concludes that its proposal does not yield better results than the APC. In [24], the APC is applied to the diagnosis of diabetes mellitus, competing with today’s best classifiers and achieving results close to them. In [16], the author obtains better classification results on the Wine recognition database than three traditional machine learning algorithms.
Our research group has presented advancements related to the APC in two previous publications. In [18], we established the accuracy of the APC in handling the Breast Cancer Wisconsin database. Furthermore, in [19], we demonstrated that the APC functions as a bi-class algorithm, with no assurance of effectively solving multiclass problems. To overcome this limitation, we proposed a hierarchical tree-based approach. In the same publication, we highlighted that the APC struggles to solve even the simplest linear separation problem, the AND function. To address this issue, we introduced a method for calculating the boundary decision of the translation vector.
In contrast to our [18, 19] and the other earlier works [16, 20–24], which relied on empirical evidence, the focus of this paper is to provide a theoretical understanding of the APC’s functioning for future enhancements. We discovered that the APC employs concurrent vectors at the translation vector to establish a static equilibrium system, a principle we substantiated through a theorem. While this equilibrium system proves accurate for balancing class representation in various regions, it poses a drawback since real-world pattern classes are often imbalanced, as observed in tests on real-world databases. Despite this disadvantage, the APC showcases exceptional performance in tests involving artificial datasets with balanced pattern distribution, serving as an effective multiclass and non-linear classifier. However, it falls short when aiming for complete pattern separation due to the presence of a neutral region. The neutral region comprises all points that delineate the separation hyperplanes. Points located over the hyperplanes cannot be classified by the APC. This limitation is evident in the inability to solve the AND function. This paper also extends the analysis of solving the AND function initially discussed in [19]. Furthermore, we found that the APC struggles to precisely classify the translation vector.
The rest of this work is divided into the following sections. Section 2 presents the APC algorithm. Section 3 discusses general insights into how this classifier functions. In Section 4 a specific bi-class scenario is presented, offering further deductions. Section 5 introduces the specific case related to the AND function. Section 6 provides a rigorous and formal demonstration of the APC functioning as a static system and gives a formal demonstration that the APC cannot classify the translation vector. Section 7 details the design of experiments conducted to validate these observations statistically. Section 8 presents the conclusions.
The associative pattern classifier
An AM is a single-layer ANN that maps a set of input patterns
The APC proposed in [16] begins in the following manner: A fundamental set of associations is defined as: The classc∈ { 1, 2, . . . , q } to which each input pattern A translation vector Subsequently, the translation of all patterns The matrix First, the input pattern The following product is calculated: The class vector Finally, there is the class index, for which
In the process of
Just like the recovery phase in the Lernmatrix, the recovery phase of the APC involves presenting an input pattern
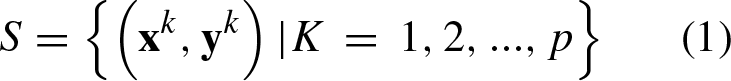
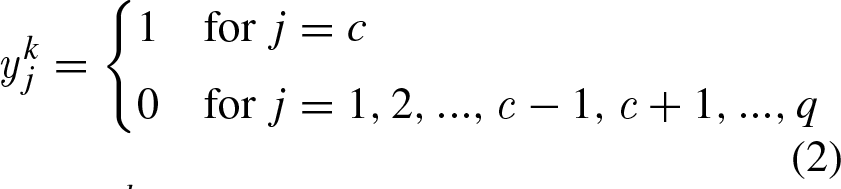
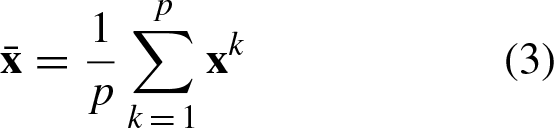

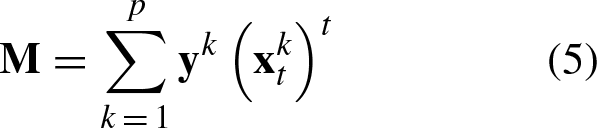



After defining the APC, we will proceed to illustrate the operational mechanism of the APC with various examples. In Subsection 3.1, we demonstrate how the APC establishes a system in static equilibrium. Moving on to Subsection 3.2, we explain how the APC generates separation regions using a set of hyperplanes in the translation plane. Subsection 3.3 shows how separation regions are formed in the original plane. In Subsection 3.4, we present the mathematical definition of how the Euclidean space is partitioned into different decision regions. Finally, in Subsection 3.5, we explore various behaviours of the APC’s performance during the recovery phase.
Concurrent vector system
Let’s assume that the following arbitrary patterns

Taking into account the construction phase of the APC: A translation vector Distribution of input patterns and translation vector of the APC in the Euclidian plane. The input patterns The matrix
The learning phase has concluded up to this point. Now, we will extract the weight vectors 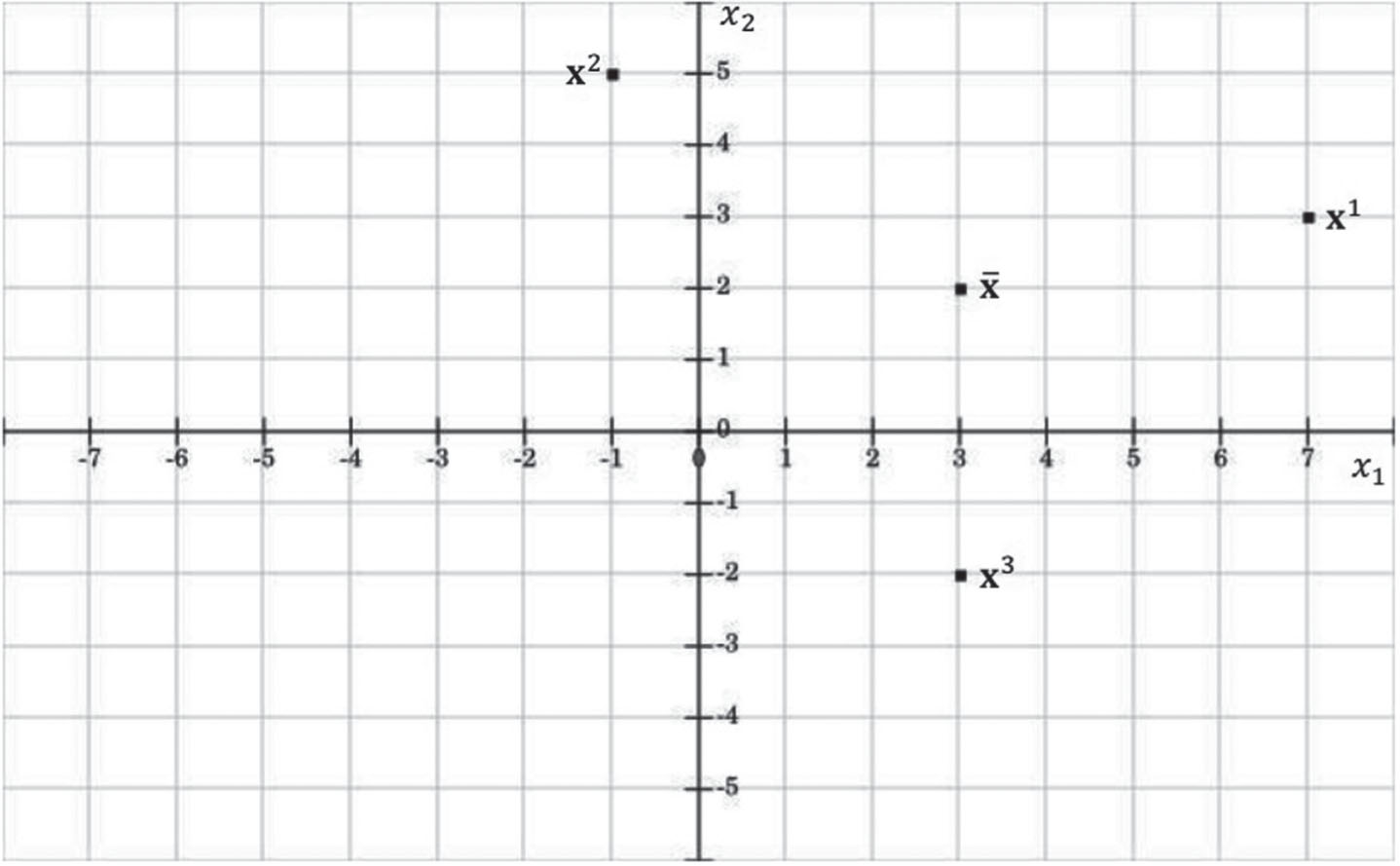

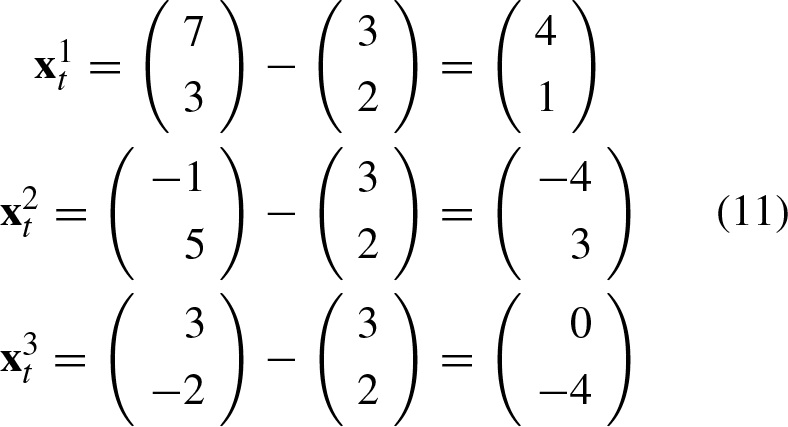
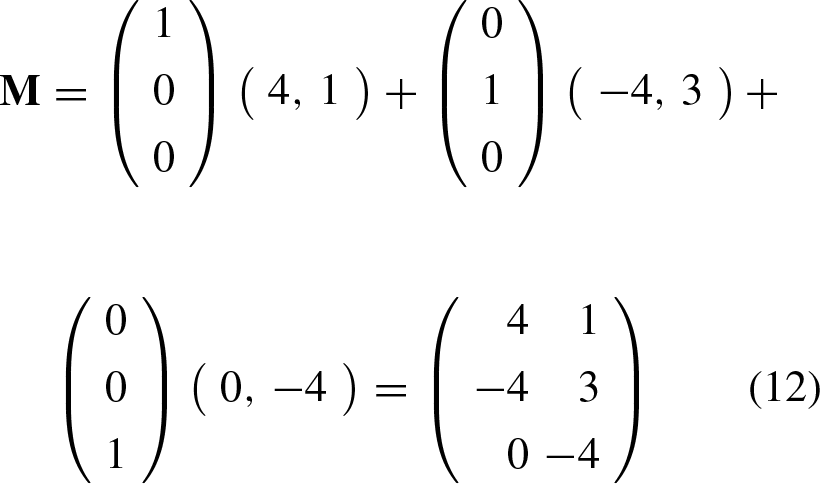
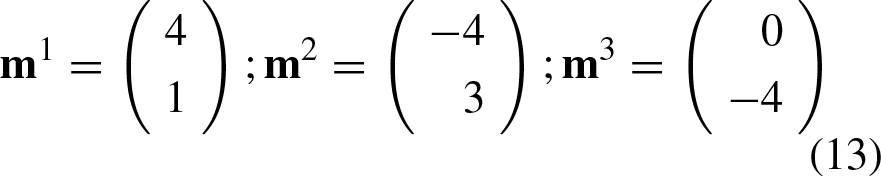
The matrix
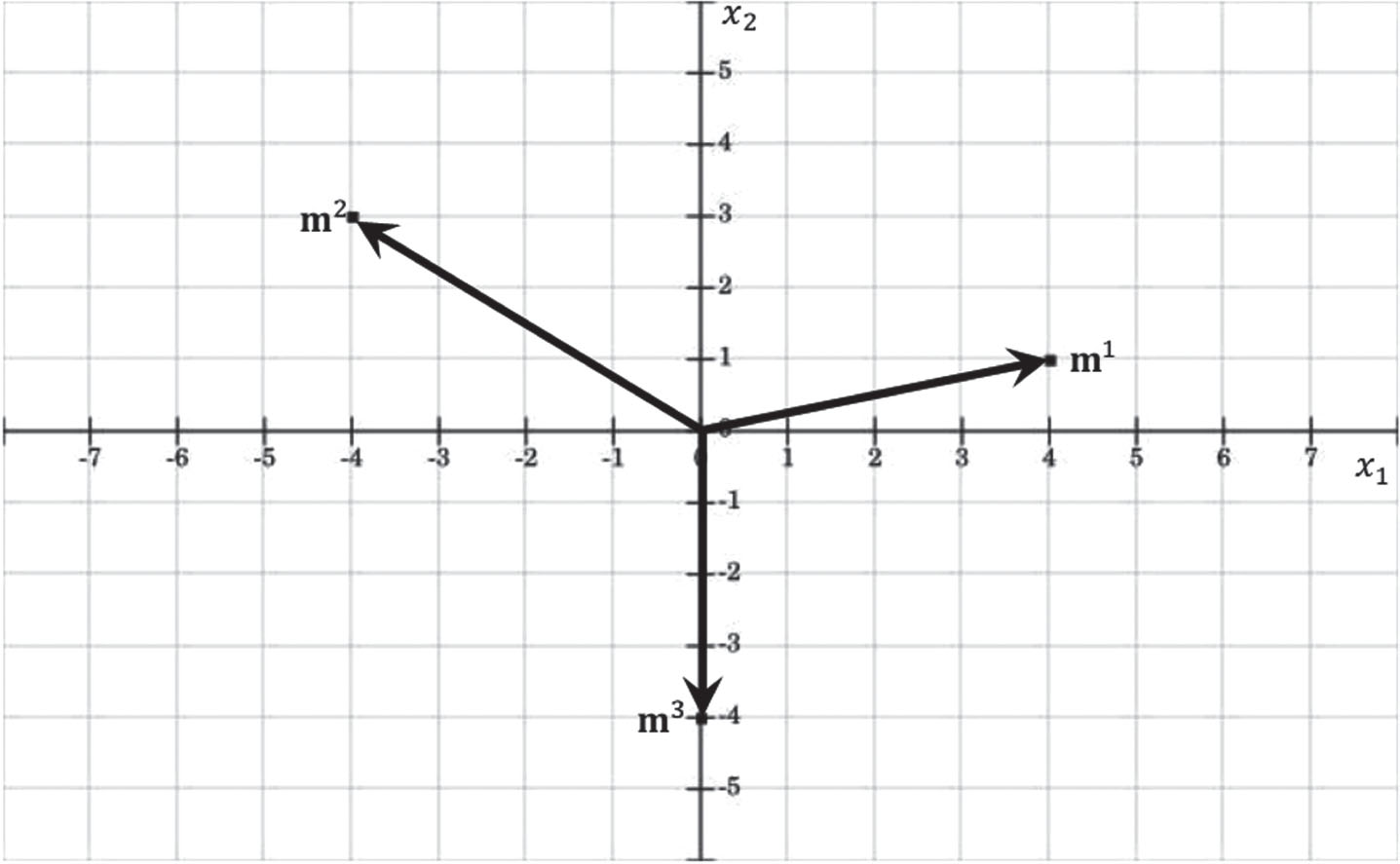
Concurrent and balanced vector distribution of the APC in the translation plane.
Without loss of generality, the vectors

For points
For points
In Fig. 3, the geometric representation for Equations 14–16 can be observed.
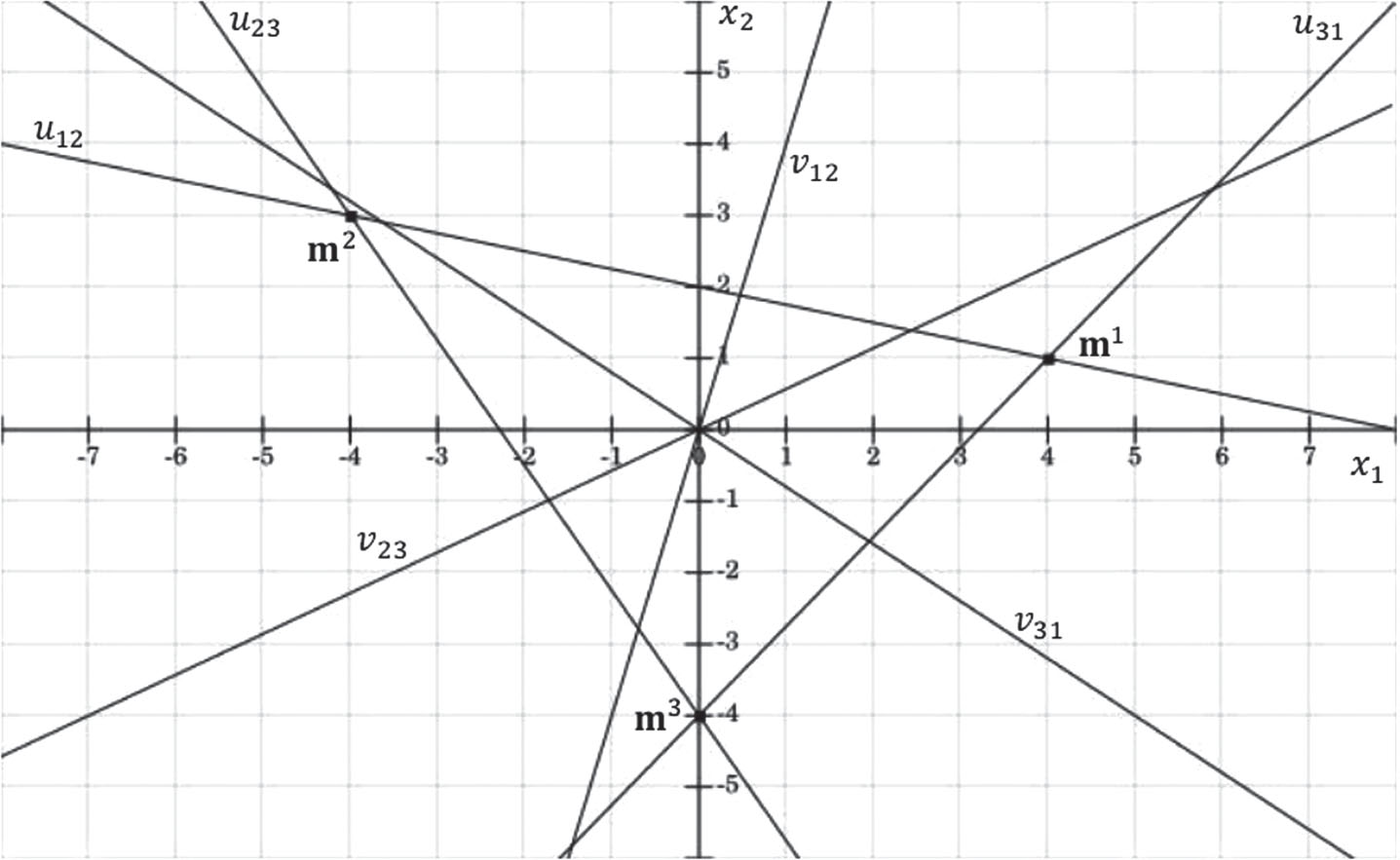
The hyperplanes v ij that divide the translation plane are perpendicular to the hyperplanes u ij of the APC.
Now, the hyperplanes that divide the translation plane are perpendicular to the hyperplanes u
ij
, and they will be referred to as v
ij
for i ≠ j. Continuing with the example, the hyperplanes u
ij
from Equations 14–16, yield the following perpendicular hyperplanes passing through the origin:
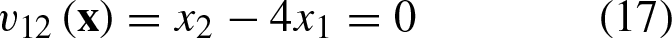
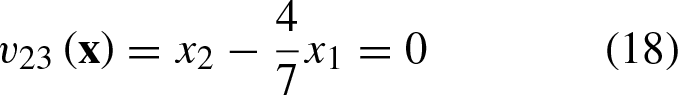
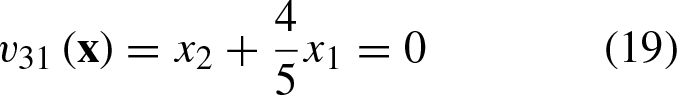
In Fig. 3, the geometric representation of Equations 17–19 can be observed.
To here, our work has been focused on the translation plane, and now the hyperplanes v
ij
will be shifted back to the original plane. These hyperplanes now serve as linear decision functions that separate the regions. These functions will be denoted as h
ij
for i ≠ j, which are obtained by translating the hyperplanes v
ij
concerning the translation vector
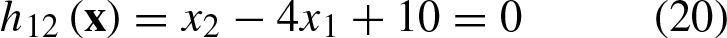
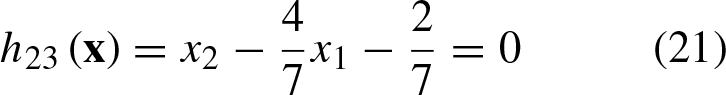
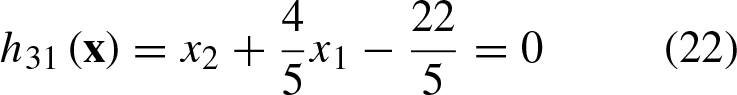
In Fig. 4, you can observe the geometric representation of Equations 20–22.

Regions and linear decision functions of the APC in the original plane.
In Fig. 4, it can be observed that the dashed portion of a linear function indicates that within that region, the function does not influence the classification process, as it only does so for the regions it separates. Therefore, the APC is capable of generating a non-linear decision function in a general way.
From the previous analysis, considering a set of q pattern classes
In this manner, the Euclidean space is divided into q decision regions as follows:

Please note that a neutral region exists, which means there is no absolute separation between the regions. The neutral region is defined by all the points that define the hyperplanes. In other words, the points over the hyperplanes cannot be classified by the APC. It’s also worth noting that the regions originate from the translation vector
Continuing with the example, several unknown patterns are presented to the matrix
Let’s assume a noisy pattern The noisy pattern The matrix The class vector Thus, the vector The pattern The translated pattern The class vector Thus, the vector The pattern The matrix The class vector Thus, the vector
Now, let’s take a noisy vector that solves hyperplane h31 (Equation 22):
Now, let’s examine a pattern that traverses the same separation hyperplane h31 (Equation 22), but this time on the side that doesn’t interfere with the division of regions (the dashed portion within the region class c2 in Fig. 4):
In this latter case, note that in the vector
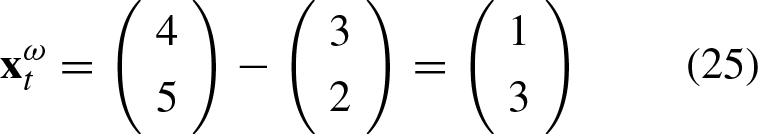
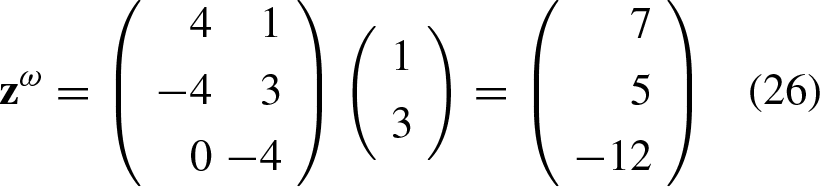
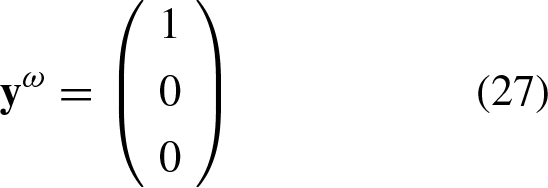
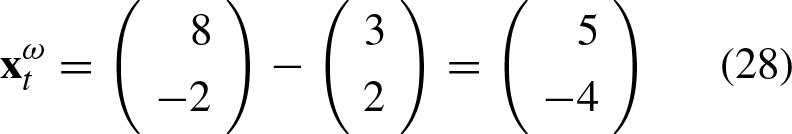
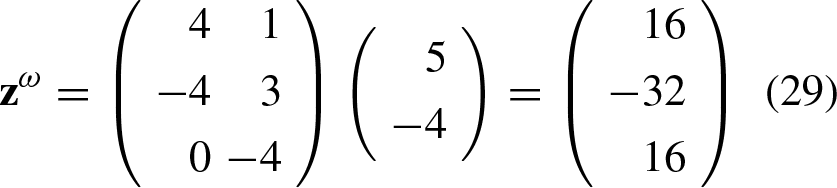


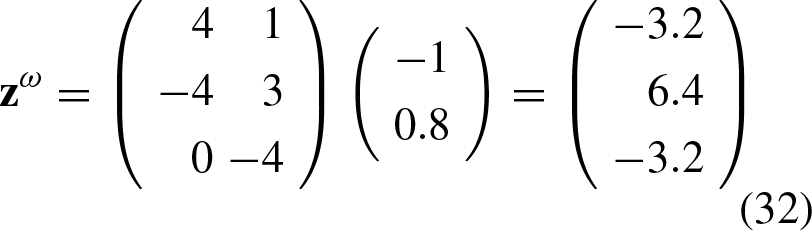

Now, we will consider a specific case for two classes from which further observations will be derived. Let’s assume that we have the following set of arbitrary associations:
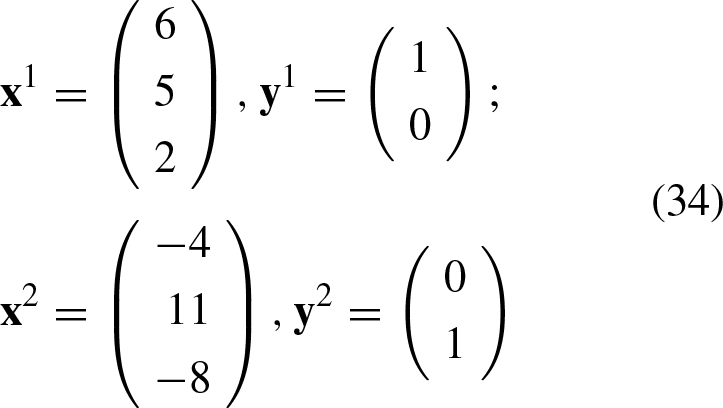
Taking into account the construction phase of the APC: A translation vector The input patterns The matrix The pattern The matrix The class vector Thus, the vector During construction, the translation of the two input patterns causes them to be the negatives of each other, that is, In the classification phase of the undistorted version of any input patterns, translation causes them to be initially transformed into their shifted original versions. The multiplication of the matrix In the classification phase of a distorted version of any input pattern, translation initially causes them to be shifted to one of the original translated versions. The moved vector can appear on either side of its corresponding translated original version. As long as the added noise to the input pattern does not cause its translated version to exceed the neutral position, the input pattern will always be correctly classified. Of course, if the translation of an input pattern results in
To test the classifier, a pattern
In this simple example, it is worth noting that in the case of two classes:
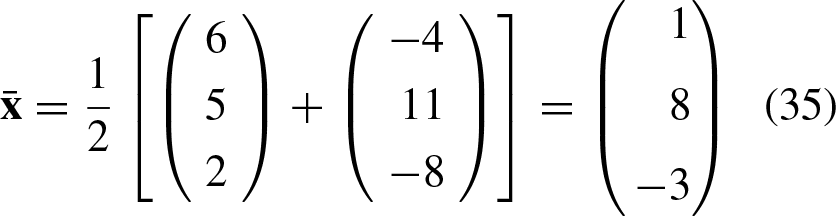
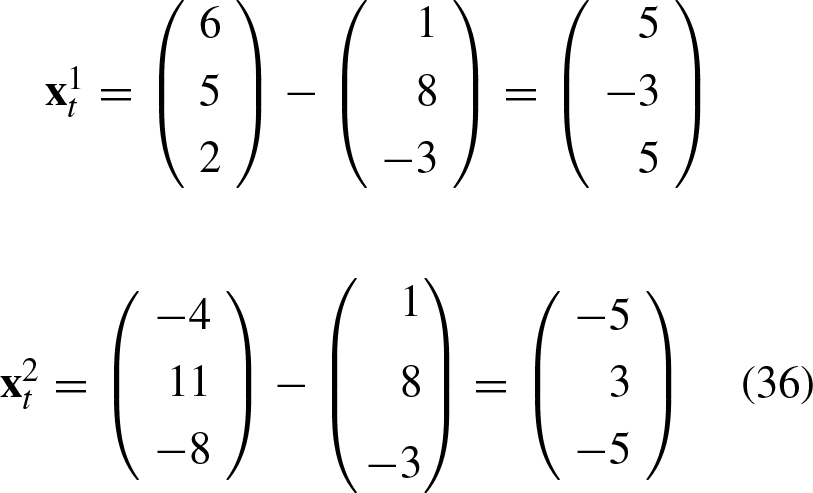
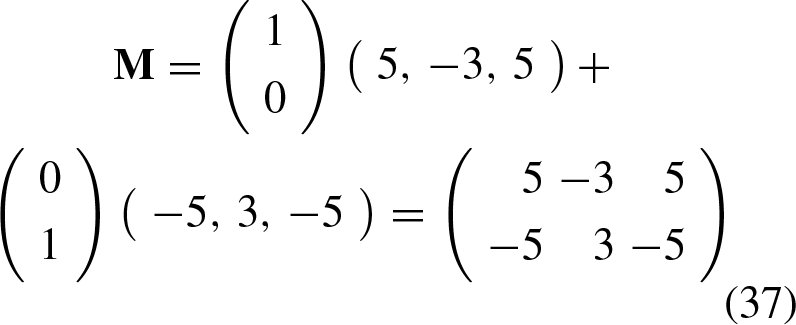
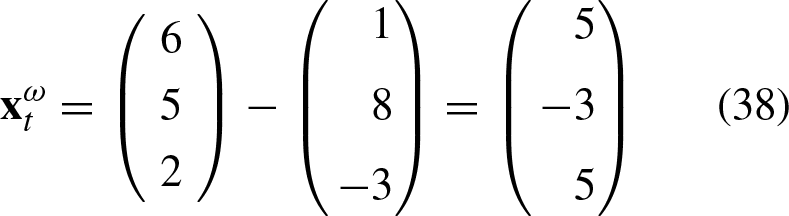
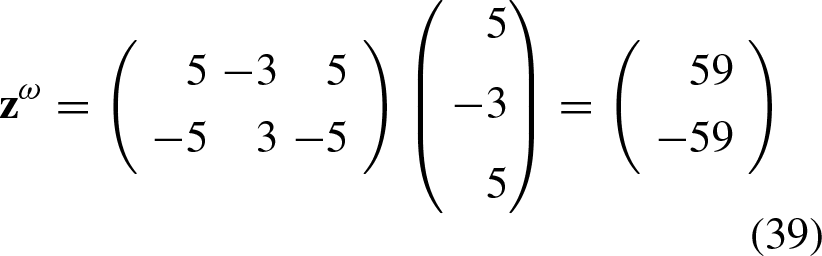
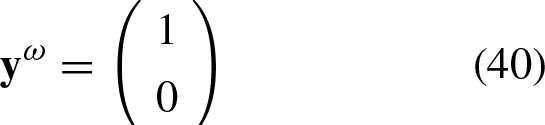

The AND function can be represented as shown in Table 1, where x1 and x2 represent the components of the training patterns, of which the first three can be labelled with the class “0” and the last pattern with the class “1”. This results in a set of four input patterns that belong to either class “0” or class “1” as the case may be.
AND function
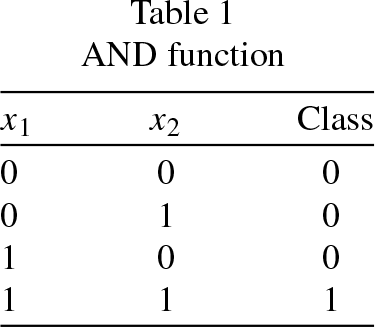
AND function
From Table 1, we can create the following set of associations: 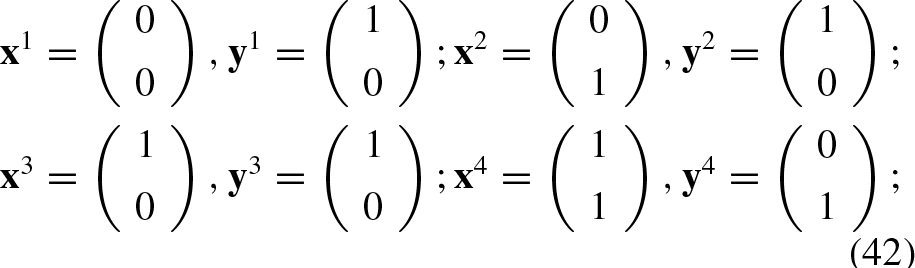
Considering the construction phase of the APC: A translation vector The input patterns The matrix The patterns The matrix The class vectors
To test the classifier, we take the four training patterns: 
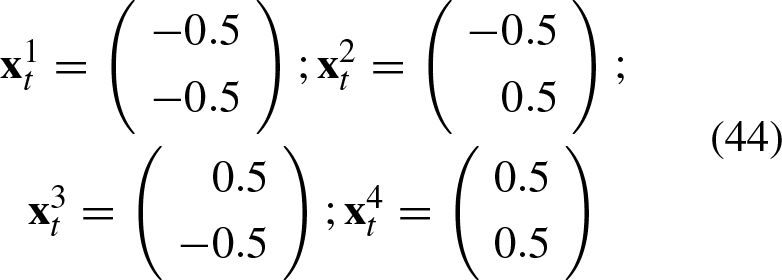

Thus, the vector 
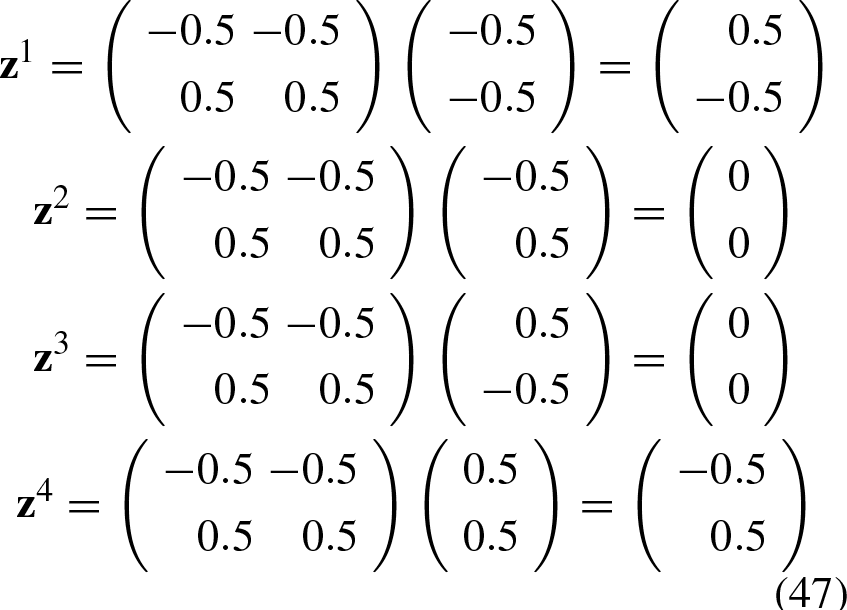

The line formed between the vectors
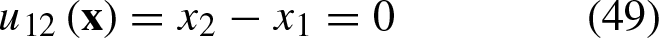
The perpendicular line from Equation 49 is: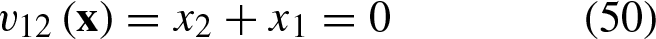
The hyperplane from Equation 50 is shifted with respect to the vector 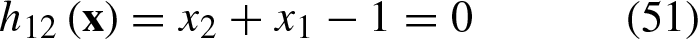
The decision line of Equation 51 is shown in Fig. 5. It is observed that the vectors
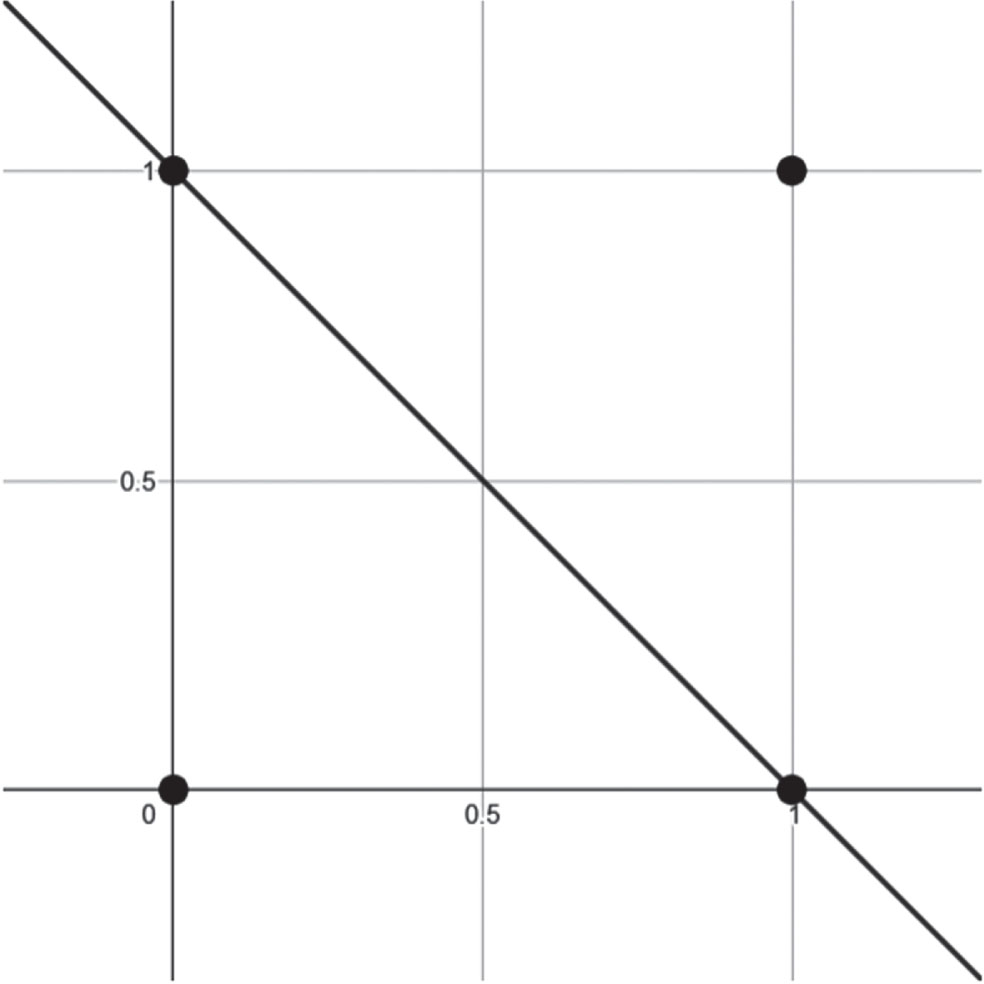
Decision line generated by the APC to solve the AND function.
This section demonstrates theoretically that the APC forms a system in static equilibrium and that the translation vector cannot be classified by the APC.
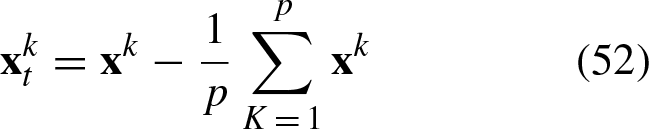

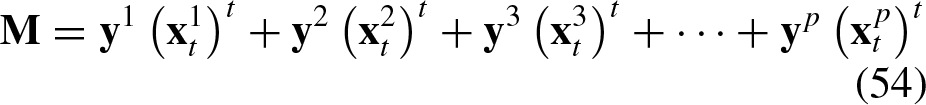
If we assume that each vector 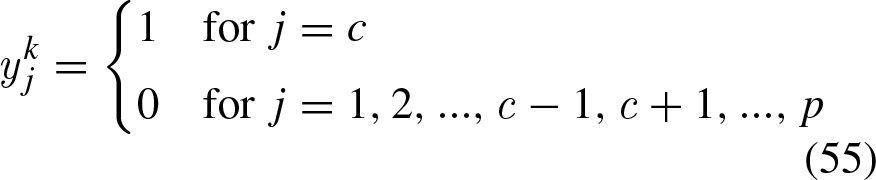
Thus, Equation 54 becomes:
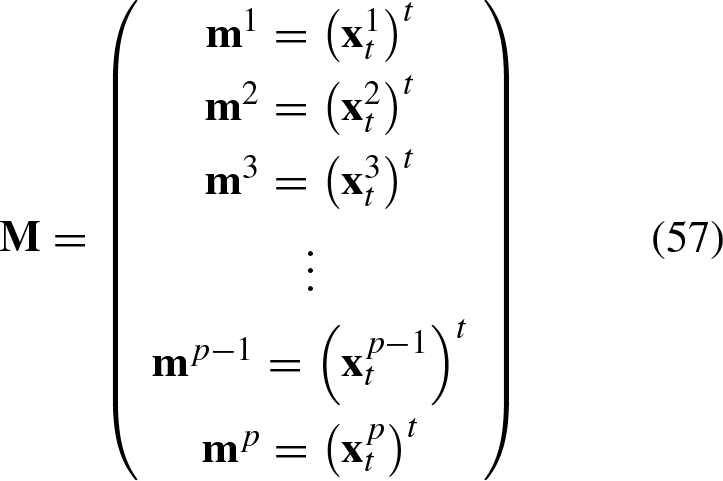
Hence, based on Equation 57, we can express the summation as follows: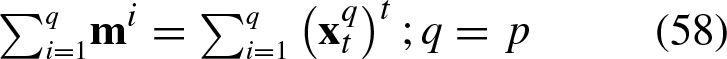
If we sum the translated patterns in Equation 53 as 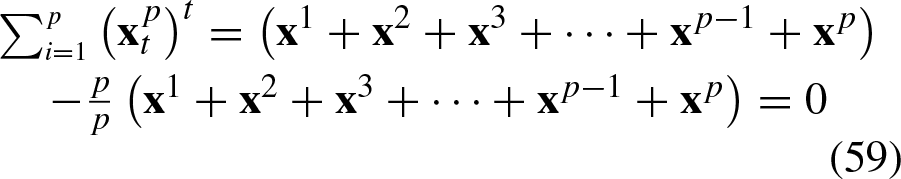
Consequently, the translation vector
In this section, we outline the experiments conducted to test the performance of the APC. A comparison was conducted between the APC and four state-of-the-art pattern classifiers. These classifiers are described in Subsection 7.1. Twenty real-world and two artificial databases were used. Real-world databases are described in Subsection 7.2 and the artificial database construction is described in Subsection 7.3. Subsection 7.4 gives the experiment design and Subsection 7.5 shows the results.
Pattern classifiers
Pattern classifiers were obtained from the machine learning algorithm collection Weka [27]. Here is a general description of the pattern classifiers used in the experimentation. Minimal Distance Classifier (MDC): This algorithm determines the class to which a given pattern belongs based on its proximity to a representative pattern of each class [28–30]. Naive Bayes (NB): This algorithm utilizes Bayes’ theories. It assumes that the presence (or absence) of a particular feature of a class is not related to the presence (or absence) of any other feature, taking into account the class variable [29, 31, 32]. K-Nearest Neighbors (KNN): It is a type of nearest neighbour classification, where a sample from each of the classes to which an unknown element can be assigned is taken [33]. It is called the nearest neighbour because the feature vector with the shortest distance compared to other feature vectors in the sample space determines the class to which the input vector will be assigned. C4.5: This algorithm generates a decision tree for classification, building on the predecessor algorithm ID3 [29].
A total of twenty databases with different distributions were utilized. All of them were extracted from the University of California Irvine (UCI) machine learning repository [34], except for the “Objects” database, which was created by H. Sossa from the Computer Research Center at the National Polytechnic Institute, Mexico, describing a set of five objects (a bolt, a washer, an eyebolt, a hook, and a dovetail) using the first two Hu invariant moments [35, 36]. Table 2 provides a summary of the number of instances, attributes, and classes for each of these databases.
Summary of the databases used for experimentation
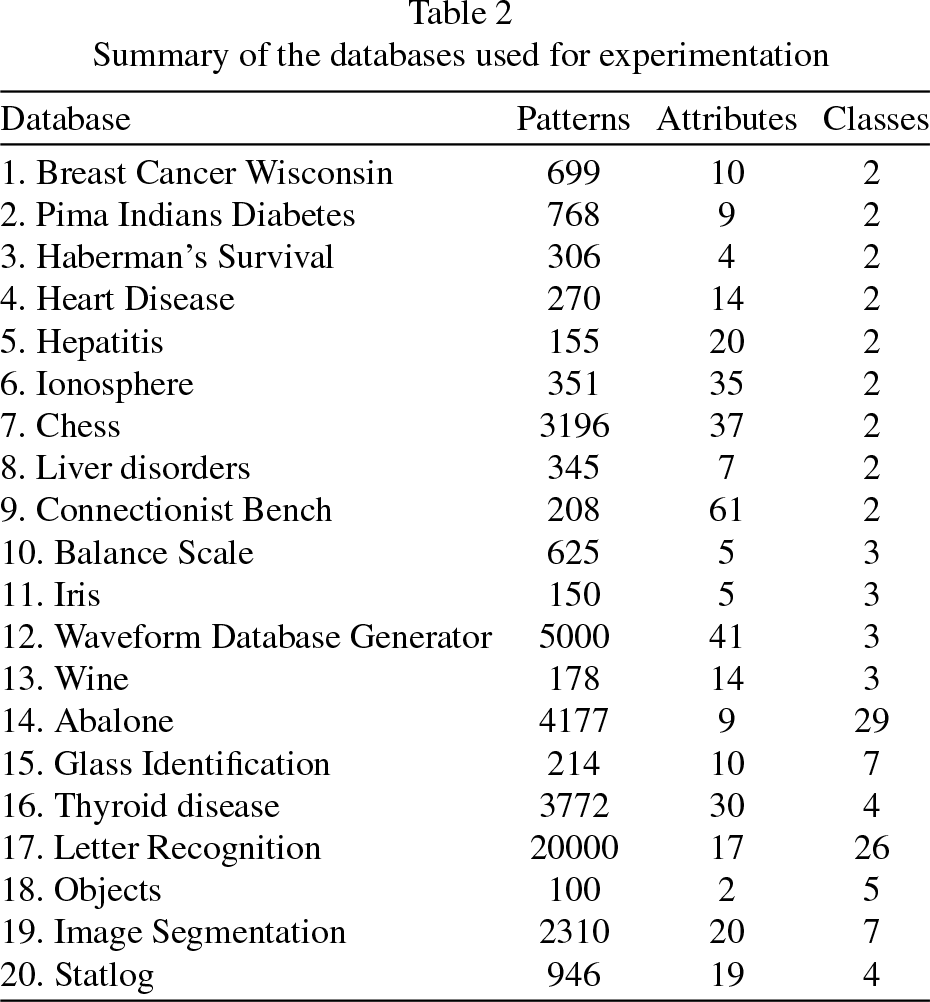
Summary of the databases used for experimentation
Two artificial databases were generated using MATLAB software. These databases were randomly created using a multivariate normal distribution with a mean vector and covariance matrix for each class. The first data set consists of 400 instances of two dimensions. These instances are non-overlapping and are distributed across four classes, with each class containing 100 instances. The class distribution is shown in Fig. 6, and the MATLAB code used is displayed in Listing 1. The second data set consists of 800 instances of dimension two. These instances are distributed across eight classes, each containing 100 instances. The class distribution, as shown in Fig. 7, reveals some overlapping between these classes. The MATLAB code used to generate this data set can be found in Listing 2.
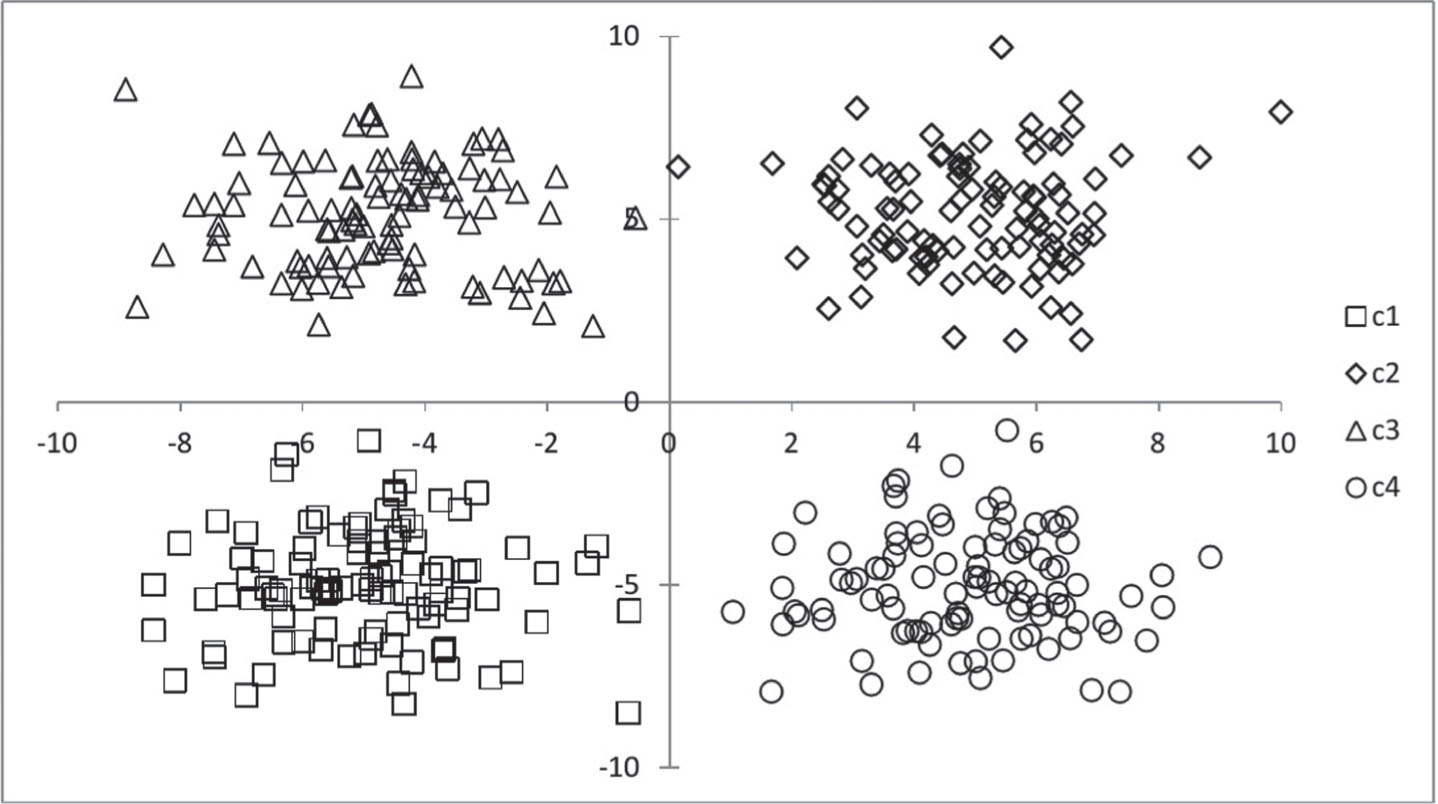
Balanced distribution of four classes of non-overlapping patterns.
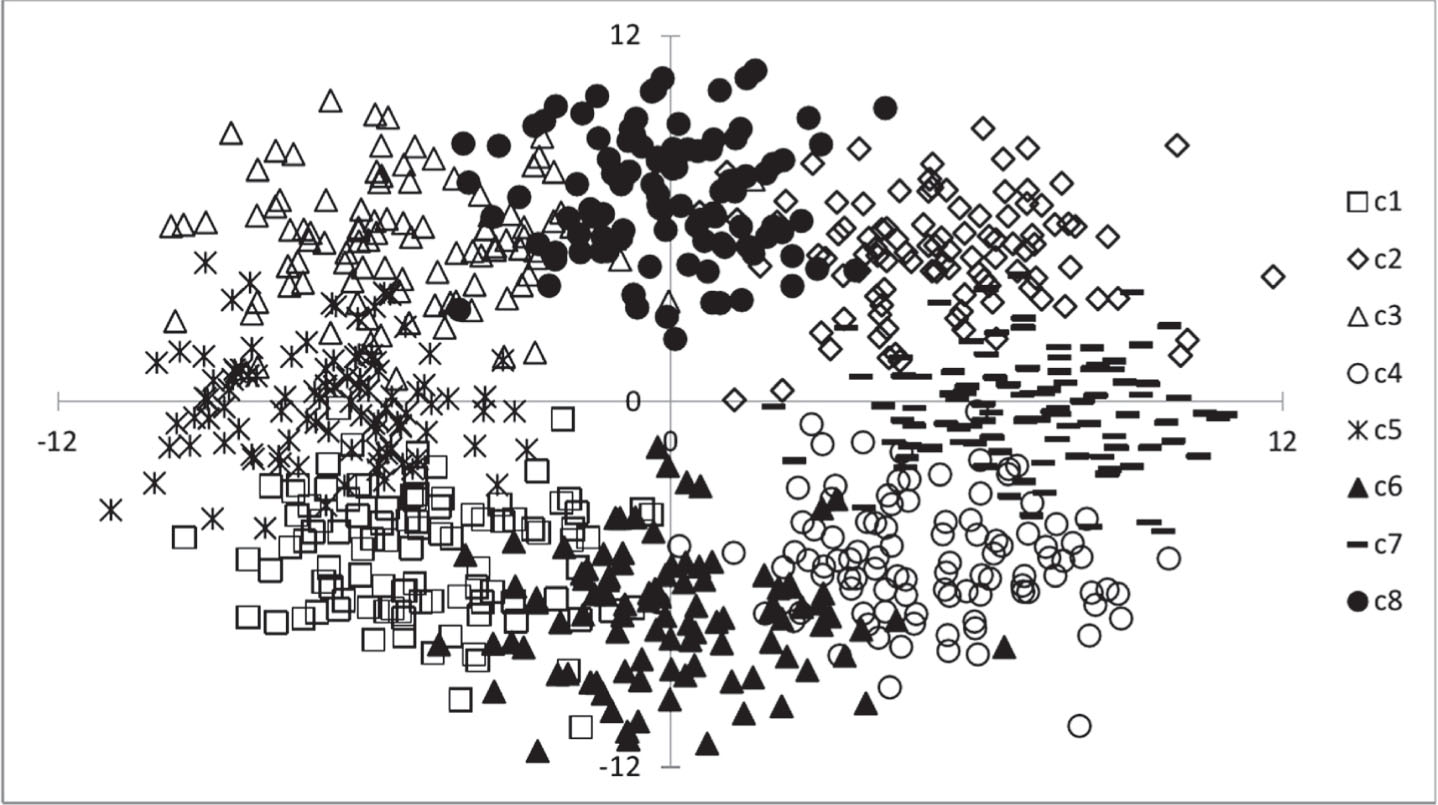
A balanced distribution of eight pattern classes with overlap.


Each classifier was assessed using the accuracy metric. This performance metric was computed through a confusion matrix, which contained information about the correct classifications and predictions made by the algorithm. Accuracy is the ratio of the total number of correct predictions. A stratified 10-fold cross-validation was employed for the training and testing experiments. Each test was repeated ten times, from which an average classification performance was obtained.
Results
Table 3 provides a summary of the experimental results. The superior performances are indicated in bold. The average performance of APC is lower compared to other classifiers. In contrast, KNN (K = 1) achieves the highest average performance. Despite the APC showing minimal classification performance, it excels in performance for the Breast Cancer Wisconsin dataset and the two artificial databases. This is because the pattern distribution in the databases meets the conditions under which the APC operates. That is, the patterns are distributed in a balanced manner.
Summary of the classification accuracy of APC, MDC, NB, KNN (K = 1), and C4.5 algorithms, obtained through k-Folds and 10 repetitions

Summary of the classification accuracy of APC, MDC, NB, KNN (K = 1), and C4.5 algorithms, obtained through k-Folds and 10 repetitions
It can be stated that the APC is an AM that undergoes a learning process in a single iteration. This enables the APC to create a memory straightforwardly and quickly, based on a set of patterns associated with their respective class vectors. The construction of this memory takes place once the patterns are shifted about a translation vector, giving rise to a coordinate translation plane.
We demonstrate theoretically that, in the translation plane, the rows comprising the memory are concurrent vectors that form a system in static equilibrium, allowing the APC to distribute the various class regions in a balanced manner. While the APC achieves a proper separation of a set of evenly distributed regions on the plane, it cannot achieve an absolute separation, as there exists a neutral region that the APC cannot classify. The neutral region is defined by all the points that define the separation hyperplanes. However, the APC is a multiclass and a generalized non-linear classifier, enabling the APC to be efficient and swift in separating a set of evenly distributed classes. We also found that the APC is unable to classify the translation vector, it cannot be classified as it falls within the neutral region. Notably, the classifier exhibits noise tolerance; the algorithm creates decision regions where even more distorted versions of a given pattern can be classified, as long as they do not fall into the neutral region generated by the APC. It was found that the APC is incapable of separating the AND function due to the neutral region forming the separation line, which traverses two of the four points of the AND function. When the distribution of patterns aligns with the regions defined by the APC, it surpasses certain classifier algorithms like MDC, NB, KNN, and C4.5. The APC demonstrates reduced performance when evaluated with real-world databases, rendering it inaccurate due to its limited internal operations.
Footnotes
Acknowledgments
S. Valadez-Godínez expresses gratitude to the Universidad Politécnica de Pénjamo, CONAHCYT, and the Centro de Investigación en Computación of the Instituto Politécnico Nacional for their financial support in carrying out this research. H. Sossa want to thank to Instituto Politécnico Nacional (grants SIP 20220226, 20231622, and 20240956) for their financial support during the research. R. Santiago-Montero wishes to convey thanks to the Instituto Tecnológico de León and CONAHCYT for their assistance and support.