
Abstract
Many retrieval applications can benefit from multiple modalities, for which how to represent multimodal data is the critical component. Most deep multimodal learning methods typically involve two steps to construct the joint representations: 1) learning of multiple intermediate features, with each intermediate feature corresponding to a modality, using separate and independent deep models; 2) merging the intermediate features into a joint representation using a fusion strategy. However, in the first step, these intermediate features do not have previous knowledge of each other and cannot fully exploit the information contained in the other modalities. In this paper, we present a modal-aware operation as a generic building block to capture the non-linear dependencies among the heterogeneous intermediate features, which can learn the underlying correlation structures in other multimodal data as soon as possible. The modal-aware operation consists of a kernel network and an attention network. The kernel network is utilized to learn the non-linear relationships with other modalities. The attention network finds the informative regions of these modal-aware features that are favorable for retrieval. We verify the proposed modal-aware feature learning in the multimodal hashing task. The experiments conducted on three public benchmark datasets demonstrate significant improvements in the performance of our method relative to state-of-the-art methods.
Keywords
Introduction
Multimodal hashing [1, 2], which embeds multimodal data into a single binary code and aims to improve performance by using complementary information provided by the different types of data sources, has drawn much attention. Since good representations are important for multimodal hashing, we only focus on designing a better feature learning approach in this paper.
To learn the representations, multimodal fusion [3, 4] is proposed, which aims to generate a joint representation from two or more modalities in favor of the given task. These fusion methods mainly fall into two categories [3]: model-agnostic approaches [5] and model-based approaches [6]. The model-agnostic methods do not use a specific machine learning method. According to the data processing stage, model-agnostic methods can be mainly split into early and late fusion. Early fusion immediately combines multiple raw/preprocessed data into a joint representation. In contrast, late fusion performs integration after all of the modalities have made decisions. The model-based approaches fuse the heterogeneous data using different machine learning models [7], e.g., the graphical models [8] and the deep networks [9].
Illustration of two different feature extractions for multimodal data: (A) each modality uses individual neural layers to learn intermediate features; (B) our proposed modal-aware feature learning that can learn the non-linear dependencies among the heterogeneous data. 
Recently, deep multimodal fusion has attracted much attention because it is able to extract powerful feature representations from raw data. As shown in Fig. 1 (A), the common practices for deep multimodal fusion are as follows [10, 11, 12]: 1) Each modality start with several individual neural layers to learn intermediate feature. 2) These multiple intermediate features are merged into a joint representation via a fusion strategy. Such a fusion approach is called as intermidiate fusion [13] because the powerful intermediate features obtained by deep neural networks (DNNs) are merged to construct the joint representation. Deep multimodal learning has been shown to achieve remarkable performance for many machine learning tasks. For instance, the deep cross-modal hashing [14] and the deep semantic multimodal hashing [15].
While most existing methods focus on designing better fusion strategies, e.g., gated multimodal units (GMUs) [16] and multimodal compact bilinear pooling (MCB) [17] for data fusion, and only limited attention has been paid to the intermediate features. The multiple intermediate features are separately learned and do no fully utilize the underlying correlation structures in other modalities. For example, we have two pictures, a picture of a white egg and another picture of a white ping-pong ball. Since these two images are very similar, we need to look carefully to distinguish them. Thus, the intermediate features only learned from the image modality are not efficient. If we can utilize the information from the textual modality, e.g., the textual tags “egg” and “ping-pong”, we can obtain more powerful and efficient intermediate features. Thus, a natural question arises: Can we incorporate information from other modalities to learn the intermediate features?
To this end, we propose a deep architecture to learn the modal-aware features for multimodal hashing. Unlike in other deep multimodal approaches, in which each intermediate feature is learned via several individual neural layers, our method learns the dependent and joint intermediate features among the heterogeneous data sources. As shown in Fig. 1 (B), the modal-aware feature learning module is proposed to produce new intermediate features, in which these new intermediate features are learned jointly and dependently. Hence, each intermediate feature consists of information from other modalities, and we can incorporate the information from other modalities to learn more powerful intermediate features.
In the context of multimodal retrieval, two factors are considered in the proposed modal-aware operation. The first consideration is how to learn the non-linear dependencies from other modalities. Inspired by the kernel methods [7], we present a kernel network to learn the underlying correlation structures in other modalities. Given two intermediate features from two modalities, we first calculate the kernel similarities, i.e., dot-product similarities, between the two features. Then, the similarities are used as weights to reweigh the original features. The second consideration is how to learn powerful intermediate features in favor of the binary hash codes. We propose an attention network that focuses on selecting the discriminative parts of the multimodal data. The uninformative parts will be removed and will not be used to encode the binary codes. Thus, our method can learn more efficient binary codes to some extent because the binary codes are generated from the informative parts of multimodal data that are favorable for retrieval. To fully explore all modalities, all intermediate features of the modalities are incorporated to learn the attention maps.
Finally, the main contributions of this paper are listed as follows.
We present a modal-aware operation to learn the intermediate features. This operation can learn the information contained in other modalities before fusion, which helps capture data correlations. We propose a kernel network to capture the non-linear dependencies and an attention network to find the informative regions. These two networks learn better intermediate features for generating binary hash codes. The extensive experiments are conducted on three benchmark multimodal databases. Our method achieves better performance compared with several state-of-the-art baselines. The experimental results show the usefulness of the proposed modal-aware operation.
Multimodal fusion
Multimodal fusion is an important step for multimodal learning. A simple approach for multimodal fusion is to concatenate or sum the features to obtain a joint representation [18]. For instance, Hu et al. [19] concatenated text embeddings and visual features for image segmentation. Reconstruction methods were also proposed to fuse the multimodal data, e.g., the autoencoders [20] and deep Boltzmann machines [21]. They used only one modality as the input to reconstruct both modalities. Subsequently, inspired by the success of bilinear pooling and gated recurrent networks, multimodal compact bilinear pooling [17] is proposed to efficiently combine multimodal features, and John et al. [16] used a gated multimodal unit to determine how much each modality affects unit activation. To capture cross-modal signal correlations, Liu et al. [22] multiplicatively combined a set of mixed source modalities. Although many approaches have been proposed for multimodal fusion, these deep learning methods do not fully explore the dependencies among the modalities prior to the fusion operations. In this paper, we argue that capturing the dependencies among the heterogeneous modalities will benefit multimodal fusion.
Multimodal retrieval
Another similar work is that on cross-modal hashing [23, 24, 25], which aims to retrieve the relevant data from the different modality. Many algorithms have been proposed, e.g., the cross-view hashing (CVH) [26] and the semantic correlation maximization (SCM) [27]. They used hand-crafted features for representing the modal data. Recently, deep-network-based methods [28, 23] have drawn much attention. The representative work includes deep cross-modal hashing (DCMH) [14], cross-modal hamming hashing [29], pairwise relationship guided deep hashing (PRDH) [30] and so on. Attention-aware deep adversarial hashing [31], self-supervised adversarial hashing (SSAH) [32], multi-label variational hashing [33] and semi-supervised cross-modal hashing (SCH-GAN) [34] apply the adversarial learning to generate better binary codes. Although many approaches have been designed for cross-modal hashing, the multimodal hashing and cross-modal hashing are different. The proposed multimodal hashing aims to learn the joint representations but not coordinated representations, in which the joint approach combines multiple modal data into a representation space while the coordinated approach learns the multiple data separately and enforce similarity-preserving among different modalities [3].
Other similar works include those on multi-view hashing methods that leverage multiple views to learn better binary codes. Some representative works include multiple feature hashing (MFH) [35], multi-view latent hashing (MVLH) [36], composite hashing with multiple information sources (CHMIS) [37], dynamic multi-view Hashing (DMVH) [38] and so on. In this paper, we only consider the multimodal data but not the multiple views, e.g., SIFT and HOG from the same image modality.
There has been limited attention paid to multimodal hashing. In [39], it integrates deep hashing into the secure multimodal biometric systems. Wang et al. [1] proposed deep multimodal hashing with orthogonal regularization to exploit the intra-modality and inter-modality correlations. Cao et al. [40] proposed an extended probabilistic latent semantic analysis (pLSA) to integrate the visual and textual information. There are multiple applications of large-scale retrieval in other domains, e.g., medical image analytics [41], lifelogging [42], etc. Different from these methods, we aim to learn better intermediate features (modal-aware) for multimodal hashing in this paper.
Overview of deep multimodal hashing. It consists of three sequential parts: (A) feature learning module; (B) fusion module; and (C) hashing module. Please note that the intermediate features are learned separately. In this paper, we focus on learning better intermediate features.
In this section, we first briefly introduce the existing deep multimodal hashing framework.
Let
Different from unimodal data, each instance consists of multiple unimodal signals. Combining these signals into a joint representation becomes a critical step. Currently, the deep multimodal learning (DML) approaches have been shown to achieve remarkable performance because they can learn the powerful features from all of the modalities. Merging these powerful features into a joint representation will lead to better and flexible multimodal fusion.
An illustration of a deep architecture for multimodal hashing is shown in Fig. 2. The architecture has three sequential parts: 1) the feature learning module, which learns the efficient intermediate features from the image and text raw data; 2) the multimodal fusion module, which merges the two intermediate features into a joint representation; and 3) the hashing module, which encodes the joint representations to the binary codes, followed by a similarity-preserving loss.
In the feature learning module, the convolutional layers are used to learn the powerful feature maps for the image modality. These images go through several convolutional layers to obtain the intermediate feature maps. For the text modality, the feed-forward neural network with stacked fully-connected layers is applied to encode the textual data into semantic text features.
In the fusion module, with two intermediate features, a fusion strategy is utilized to obtain a joint representation. Many methods for fusion have been proposed, e.g., concatenation, gate multimodal units (GMUs) [16] and multimodal compact bilinear pooling (MCB) [17].
In the hashing module, the joint representation is mapped into a feature vector with the desired length, e.g., an
However, in the above deep multimodal hashing, these intermediate features are learned separately and had no prior knowledge of other modalities before the fusion. To this end, we propose a modal-aware operation that aims to learn better intermediate feature representations. It contains a kernel network to learn the correlations among different modalities and an attention network that discovers the discriminative regions. The two aspects are described in detail in the next section.
Illustration of the kernel network. The image feature maps 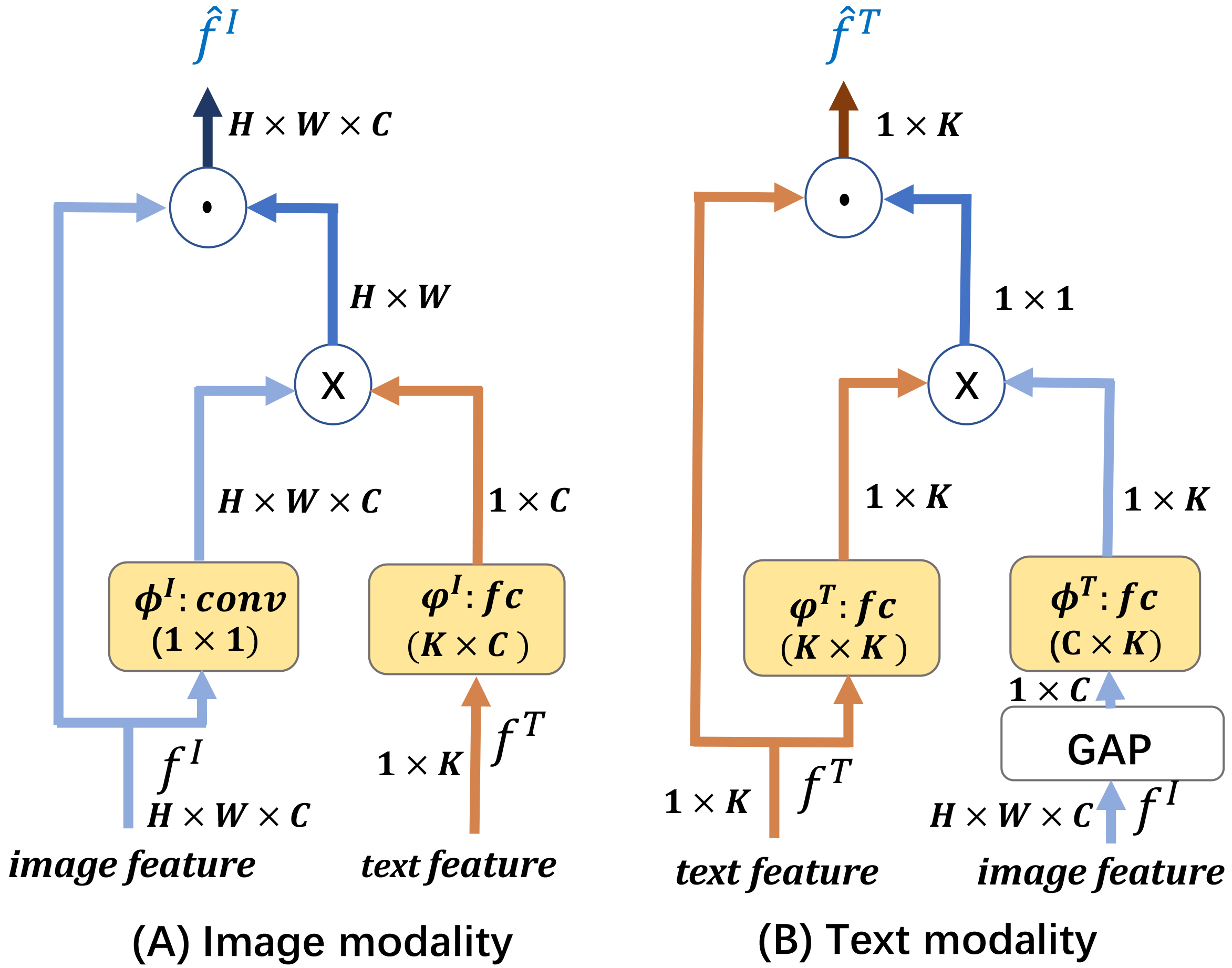
In this section, we present a modal-aware operation that has two parts, i.e., the kernel network and attention network, to learn the modal-aware features.
Kernel network
The kernel network takes two intermediate features as inputs: the feature maps from the image modality and the feature vector from the textual modality. More specifically, suppose that
Inspired by the non-local features [43] and kernel methods, the outputs of the kernel network are defined as
where
To easily learn the kernel network in end-to-end manner, the kernel function
where the
Figure 3 shows the detailed structure of the proposed kernel network. For the image modality, the feature maps
Since
where
A similar approach is used for the text modality. First, the global average pooling (GAP) layer reduces
where
Illustration of the attention network. “GAP” represents the global average pooling layer, and “fc” denotes the fully connected layer. “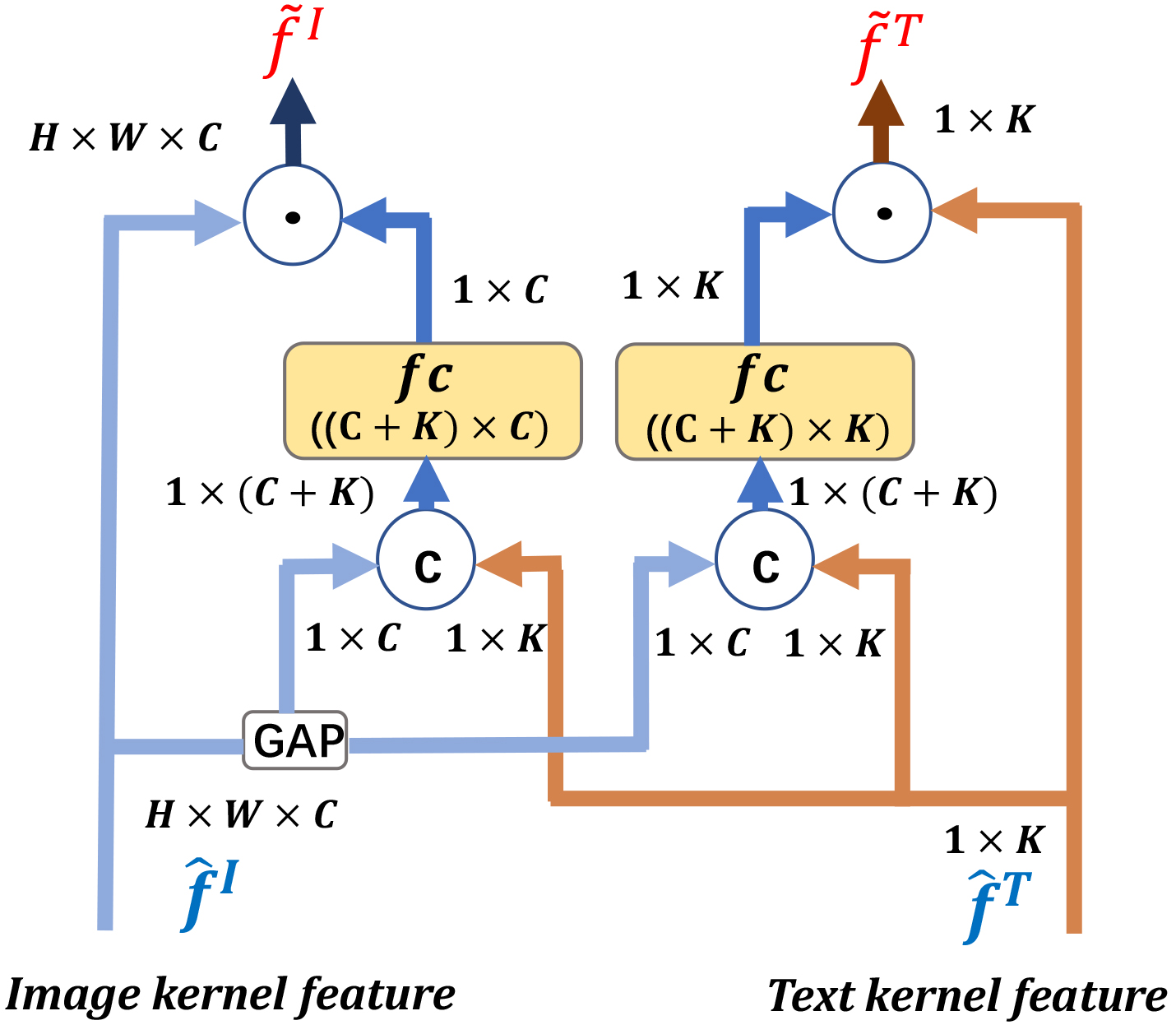
Inspired by how humans process information, we propose an attention network that adaptively focuses on salient parts to learn more powerful multiple intermediate features. To compute the attention efficiently, we aggregate information from all intermediate features. That is, we exploit both features rather than using each independently to locate the informative regions. The detailed operations are described below.
The proposed modal-aware feature learning for multimodal hashing. Two modal-aware operations were added in the feature learning module.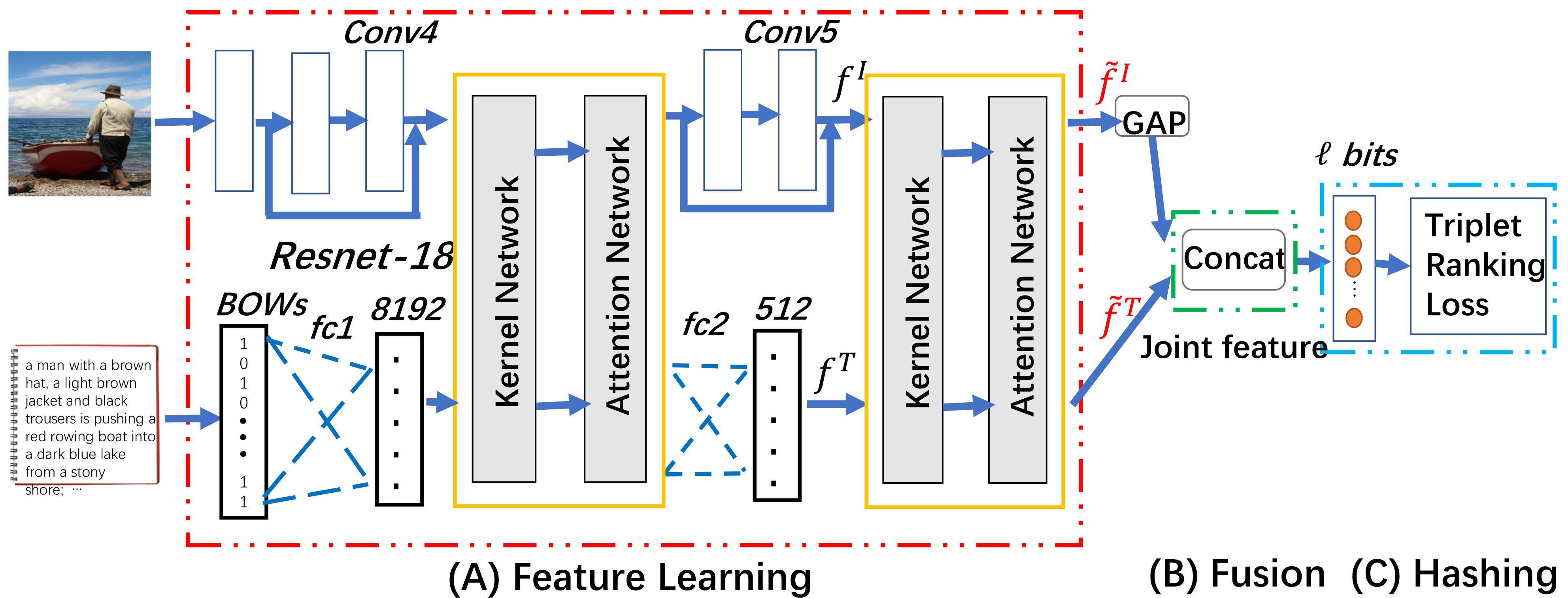
Figure 4 shows the specific structure of the attention network. First, the visual feature maps
where
where
The proposed modal-aware feature learning for multimodal hashing is shown in Fig. 5. We apply modal-aware operations in the earlier layers. Please note that it only has two fully connected layers for text modality. The proposed two operations are applied after each fully connected layer.
Network architectures
For the image modality, ResNet-18 [45] is used as the basic architecture to learn the powerful feature representations, which has shown great success in many machine learning tasks. In the ResNet-18, the last global average pooling layer and the last 1000-d fully-connected layer are removed. The feature maps in Conv4_2 and Conv5_2 are utilized as the intermediate features
After the modal-aware operation, we have two features:
Training object
The triplet ranking loss [46] is used to train the deep network. We note that other losses, e.g., contrastive loss [47], can also be used in our framework and the loss function is not our focus in this paper. Specifically, given a triplet of instances
where
In this section, we conduct extensive experiments and compare the proposed method with several state-of-the-art algorithms.
Datasets
NUS-WIDE [48]: This dataset consists of 269,648 images and the associated tags from Flickr. Each image is associated with several textual tags. The text for each point is represented as a 1,000-dimensional bag-of-words vector. MIR-Flickr 25k [49]: This dataset contains 25,000 images collected from Flickr. Each image has associated textual tags. The textual tags are represented as a 1,386-dimensional bag-of-words vector. IAPR TC-12 [50]: This dataset consists of 20,000 still natural images. Each image is associated with a text caption, which is represented as a 2,912-dimensional bag-of-words vector.
For all of the experiments, the experimental protocols of DCMH [14] are followed to construct the query sets, retrieval databases, and training sets. The NUS-WIDE dataset contains 81 ground-truth concepts. To prune the data without sufficient tag information, we select a subset of 195,834 image-text pairs from the 21 most-frequent concepts as suggested by [14]. The randomly sampled 2,100 image-text pairs (100 pairs per concept) are used as the query set, and the rest of the image-text pairs are constructed as the retrieval database. In the retrieval database, 10,000 image-text pairs are randomly selected to train the hash functions. In the MIR-Flickr 25k and IAPR TC-12 databases, the randomly sampled 2,000 image-text pairs are used as the query set. The rest of the pairs are used as the database for retrieval. We randomly select 10,000 pairs from the retrieval database to form the training set. The detailed characteristics of datasets are listed in Table 1.
Detailed statistic information of three datasets, where
Our codes are based on the open-source deep learning platform PyTorch.2
Comparison with state-of-the-art methods on NUS-WIDE dataset
Comparison with state-of-the-art methods on MIR-Flickr 25k dataset
Comparison with state-of-the-art methods on IAPR TC-12 dataset
The comparison results of precision-recall curves with 32 bits.
In the first set of experiments, we aim to compare with state-of-the-art baselines. We use two different methods as baselines.
The first set of baselines belongs to the unimodal approaches. In this set of baselines, only one modality is utilized to train the deep networks. For the image modality, several state-of-the-art image hashing algorithms are selected: deep pairwise-supervised hashing (DPSH) [51], deep supervised hashing (DSH) [52], HashNet [53], deep triplet hashing (DTH) [46] and central similarity quantization (CSQ) [54]. DPSH and DSH belong to deep pair-wise approaches, and DTH is a triplet-based approach. HashNet minimizes the quantization errors of the binary codes. CSQ is the recently state-of-the-art method for optimizing the central similarity between data points. For a fair comparison, the deep architectures for these four methods are all the same as ours. For the text modality, we utilize the same network for text data, which is referred to as TextHash. TextHash only uses text representations to learn the hash codes.
The second set of baselines is different fusion strategies used to combine multiple modalities. We note that only the fusion module in Figure 2 uses different fusion strategies and the other modules are the same.
Concat We concatenate the intermediate features of both the image and text modalities to train the hashing architectures.
GMU A gate multimodal unit (GMU) [16] is an internal unit in a neural network for data fusion. GMU uses multiplicative gates to determine how modalities influence the activation of the unit.
MCB Multimodal compact bilinear pooling (MCB) [17] uses bilinear pooling [55] to combine visual and text representations.
The comparison results of precision curve w.r.t. different numbers of top returned samples.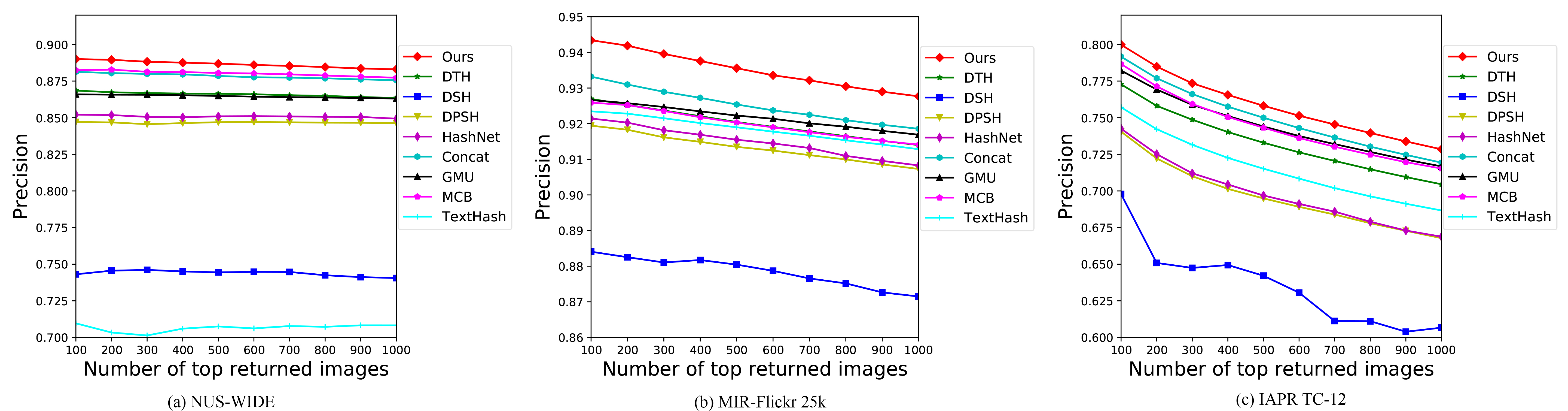
Tables 2–4 show the comparison results of the obtained MAP values for the three multimodal datasets. Figures 6 and 7 show the precision-recall curves and the precision curves on 32 bits, respectively. Our proposed method achieves the highest accuracy and beats all the baselines for most levels. The following observations can be made from the results.
Compared with the unimodal approaches, our method performs significantly better than the baselines. For instance, our method yields a higher accuracy compared to the TextHash that only uses the text modality. For image hashing methods, our method obtains a MAP of 0.7395 on the 16 bits and the value of 0.7115 of the HashNet on NUS-WIDE. On MIR-Flickr 25k, the MAP of DTH is 0.8332, while the proposed method is 0.8658 on 32 bits. Our method shows a relative increase of 4.6% Compared with other deep fusion strategies, the proposed method also performs best on all databases. Firstly, compared to the Concat approach, the only difference is that using or not using the modal-aware operations, these comparisons can answer us whether the modal-aware features can improve the accuracy or not. The results indicate that our modal-aware features can achieve better performance. For example, the MAP of our proposed method is 0.7395 on 16-bit length, compared to 0.7274 of Concat on NUS-WIDE dataset. Thus it is desirable to learn the powerful features for multi-modal retrieval. Compared to the GMU and MCB two baselines which achieve excellent performances, our proposed method also yields better performance. The main reason is that our method can incorporate the information from other modalities to learn the intermediate features, while the intermediate features of GMU and MCB are learned via individual neural layers.
Ablation study on each component on three datasets
The comparison results of precision curves for ablation study.
In this set of experiments, we do ablation study to elucidate the impact of each part of the proposed method on the final performance.
First, we explore the effect of the kernel network. In this baseline, the attention network is fixed and we do not use the kernel network. That is the features are directly forwarded to the attention network and the only difference is that using or not using the kernel network, which is referred to as w/o KN.
The second baseline explores the effect of the attention network. In this baseline, the kernel network was first performed to obtain two intermediate features. Then, we concatenate the two features to obtain the joint representation. We note that the only difference between the baseline and our method is the use or lack of use of the attention network. We use w/o AN to denote the baseline that is not using the attention network.
The comparison results are shown in Table 5 and Fig. 8. We observe that our method can achieve better performance than the two baselines. For instance, our method obtains a MAP of 0.7627 on 48 bits, compared to 0.7519 of the w/o AN and 0.7467 of the w/o KN. Compared to w/o KN on IAPR TC-12 dataset, our method gains 1.63% to 2.60% on MAP. Figure 8 shows the precision curves on three datasets. Again, our method yields better accuracy for all levels. The results indicate that it is desirable to learn the intermediate features with both the kernel network and the attention network. This also shows that our approach can achieve better feature learning for multimodal hashing.
In this paper, the textual data is represented as a bag-of-word vector. Other text representations, e.g., Sent2Vec or BERT [56], can be used in our framework. For example, on IAPR TC-12 database, each image is associated with a text caption. Thus Sent2Vec, which is computed via the pre-trained model,3
The comparison results of different texts representation
In this work, we proposed a modal-aware operation for learning good feature representations. The key to success comes from designing a generic building block to capture the underlying correlation structures in heterogeneous multi-modal data before multimodal fusion. First, we proposed a kernel network to learn the non-linear relationships. The kernel similarities between the two modalities were learned to reweight the original features. Then, we proposed an attention network, which aims to select the informative parts of the intermediate features. The experiments were conducted on three benchmark datasets, which demonstrated the appealing performance of the proposed modal-aware operations.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grants (U1811263 and 61772211). This work is also supported by Guangdong Basic and Applied Basic Research Foundation (2021A1515012172) and the Pearl River Nova Program of Guangzhou (201906010080).