
Abstract
The spatial co-location pattern refers to a subset of non-empty spatial features whose instances are frequently located together in a spatial neighborhood. Traditional spatial co-location pattern mining is mainly based on the frequency of the pattern, and there is no difference in the importance or value of each spatial feature within the pattern. Although the spatial high utility co-location pattern mining solves this problem, it does not consider the effect of pattern length on the utility. Generally, the utility of the pattern also increases as the length of the pattern increases. Therefore, the evaluation criterion of the high utility co-location mining is unfair to the short patterns. In order to solve this problem, this paper first considers the utility and length of the co-location pattern comprehensively, and proposes a more reasonable High-Average Utility Co-location Pattern (HAUCP). Then, we propose a basic algorithm based on the extended average utility ratio of co-location patterns to mining all HAUCPs, which solves the problem that the average utility ratio of patterns does not satisfy the downward closure property. Next, an improved algorithm based on the local extended average utility ratio is developed which effectively reduces the search space of the basic algorithm and improves the mining efficiency. Finally, the practicability and robustness of the proposed method are verified based on real and synthetic data sets. Experimental results show that the proposed algorithm can effectively and efficiently find the HAUCPs from spatial data sets.
Keywords
Introduction
With the continuous popularization and development of various new and high technologies such as Internet and wireless communication technologies, a large amount of data containing spatial location information is constantly collected, and people’s requirements for spatial data mining technology is gradually increasing. As a hot research direction of spatial data mining, spatial co-location pattern mining has received more attention and expectation. A spatial co-location pattern is a collection of spatial features whose instances are frequently co-located in a spatial neighborhood. For example, West Nile virus often occurs in mosquito-infested areas where poultry is raised; hospitals, drug stores, and flower shops often appear side-by-side. In recent years, Huang [1, 2], Yoo [3, 4], Wang [5, 6], Tran [7, 8], and Yang [9, 10, 11] have proposed multiple algorithms for mining the co-location patterns, in these algorithms, the participation index is used to measure the prevalence of a co-location pattern, and the importance or value of each feature is not distinguished and studied. These traditional co-location pattern mining methods are easy to ignore those patterns that occur infrequently, but they are very useful. The spatial high utility co-location pattern mining method largely compensates for the missing information caused by the prevalent spatial co-location pattern mining. However, the spatial high utility co-location pattern mining only considers the utility of co-located features, and ignores the impact of the length of patterns, normally, the more the number of features in a pattern, the greater the utility value of the pattern, so the long pattern is more likely to become high utility patterns. It is unfair to use the same minimum utility ratio threshold to measure patterns of different lengths, which may easily lead to mining ineffective long patterns. For example, for the cultivation of commercial crops, although the profit of each crop is very low, the combination of multiple crops leads to high utility results. The combination of crops has higher profits, which is a meaningless pattern for economic crop growers. Therefore, the High-Average Utility Co-location Pattern (HAUCP) criterion is a more reasonable judgment criterion.
The main contributions of this paper are listed as follows: (1) A concept of HAUCPs is proposed, and the average utility ratio is used as the metric of interest. (2) The downward closed property of the extended average utility ratio is analyzed, and a basic algorithm for mining the HAUCPs based on the extended average utility ratio is designed. (3) We analyze the performance of the basic algorithm, and propose an improved algorithm based on local extended average utility ratio to further improve the efficiency of the basic algorithm. (4) We conduct extensive experiments on real data sets and synthetic data sets to prove the practicability, efficiency and robustness of the proposed algorithms.
The rest of the paper is structured as follows: Section 2 introduces the related work. Section 3 gives the related definition of HAUCPs. We present the HAUCP mining algorithms in Section 4. In Section 5 we perform the relevant experimental evaluation. Section 6 summarizes the paper.
Related work
Spatial co-location pattern mining is an important research direction of spatial data mining. It was first proposed in [1], which used the minimum participation ratio (called Participation Index – PI) as the interesting measure of a spatial co-location pattern. Since the PI satisfies the downward closure property, using this measure can effectively prune the candidate pattern. In recent years, many researches on the spatial co-location pattern mining have focused on two aspects of pruning candidate patterns and computational optimization of table instances.
After Yao et al. [12] introducing the high utility to frequent itemset mining in transaction databases, the high utility pattern mining has received extensive attention. At present, there are many high utility pattern mining methods for transaction databases. Liu et al. [13] introduced a weighted transaction concept with downward closure property, and proposed an effective pruning algorithm. Ahmed at el. [14] proposed the IHUP algorithm, which effectively avoids multiple scans of the database. The UP-Growth algorithm was proposed in [15], it uses a tree structure, and the effect is better than IHUP. Yin at el. [16] combined the utility with sequential patterns and proposed the US-pan algorithm to mine high utility sequential patterns. Yang at el. [17] introduced the concept of utility to the spatial co-location pattern mining, defined the concepts of pattern utility and pattern utility ratio (PUR), and an extended pruning algorithm EPA was proposed, but it did not fully consider the differences between features and between different instances of the same feature. For this problem Wang et al. [18] further considered the utility of different instances of the same feature, a new utility participation index (UPI) was proposed as an interesting measure of the high utility co-location pattern. However, none of the literatures [17, 18] takes into account the effect of pattern length on pattern utility.
High-average utility pattern mining is also called high-average utility itemset (HAUI) mining. It was first proposed in [19]. As long as an itemset meets that its utility value divided by the number of items is not less than the user defined minimum average utility threshold, the itemset can be called a high-average utility itemset. To improve the performance of mining HAUIs, at present, there are many HAUI mining methods for transaction databases [20, 21, 22, 23, 24, 25, 26, 27, 28]. Lin et al. [20] proposed a HAUP tree structure and a HAUP growth algorithm for mining high-average utility itemsets. The projection-based PAI algorithm [21] was proposed which leverages an innovative pruning technique. The HAUI-tree approach was proposed [22] to mine HAUIs using an indexing table structure, the total number of candidates involved in mining HAUIs can be significantly reduced. An innovative, more efficient HAUI-Miner [23] was proposed with two pruning strategies to mine HAUIs based on a compressed average-utility (AU) list structure. Lin et al. [24] then developed three pruning strategies to speed up the mining process of the HAUIs. Then they presented an updating algorithm called FUP-HAUIMD [25] to maintain the discovered HAUIs with transaction deletion. The FUP-HAUIMD algorithm can easily update the discovered HAUIs without scanning the database all the time. Lin et al. [26] addressed the limitation of high utility sequential pattern mining from uncertain databases and presented a probabilistic high-average utility sequential pattern mining framework for discovering the set of probabilistic high-average utility sequential patterns from uncertain databases. In the meantime, they also proposed an efficient framework called PRE-HAUIMI for transaction insertion in dynamic databases, which relies on the average-utility-list (AUL) structures [27] and addressed the limitation of the previous potential high-utility sequential pattern mining and presented a potentially high average-utility sequential pattern mining framework for discovering the set of potentially high average-utility sequential patterns (PHAUSPs) from the uncertain dataset by considering the size of a sequence, which can provide a fair measure of the patterns than the previous works. Lin et al. [28] introduced a level-wise algorithm named High Average-Utility Itemset Mining with Multiple Minimum Average-Utility thresholds, which relies on a novel transaction-maximum utility downward closure (TMUDC) property and a concept of least minimum average-utility (LMAU) to mine high average-utility itemsets (HAUIs). Due to the autocorrelation of the spatial data in the spatial data sets, and the complexity of the spatial data types and spatial relationships, extracting high-average utility co-location patterns (HAUCPs) from a spatial data set appears more difficult than extracting the corresponding patterns from a transaction database. In this paper, we first introduce the concept of high-average utility to the spatial co-location pattern mining and study related issues.
Related concepts and definitions
This section first introduces the basic concepts of traditional co-location pattern mining and a classic star neighbor materialization model for spatial data. Then, the concepts related to HAUCP mining are defined.
Traditional co-location pattern mining
In a spatial data set, different spatial feature represents different kind of things in space. The spatial feature set represents a collection of different kind of things in space, denoted as
An example of spatial features and instances.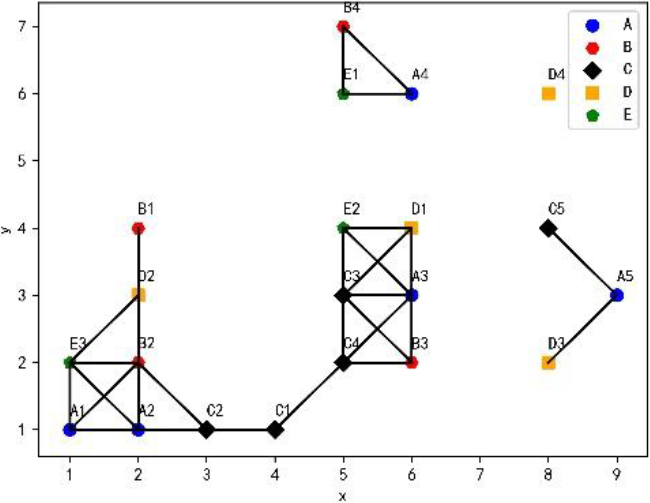
A
The star neighbor materialization model for spatial data is proposed by Yoo et al. [4]. The star neighbor materialization model is the basis of the classic join-less mining algorithm. The following will introduce the definition of star neighborhoods and star instances.
The star neighbors of all instances in a spatial data set form the star neighborhood materialization of the spatial data set. According to Definition 2, a star instance {
Star neighborhoods of the spatial data set in Fig. 1
Star neighborhoods of the spatial data set in Fig. 1
Table instances of some spatial co-location patterns of the spatial data set in Fig. 1.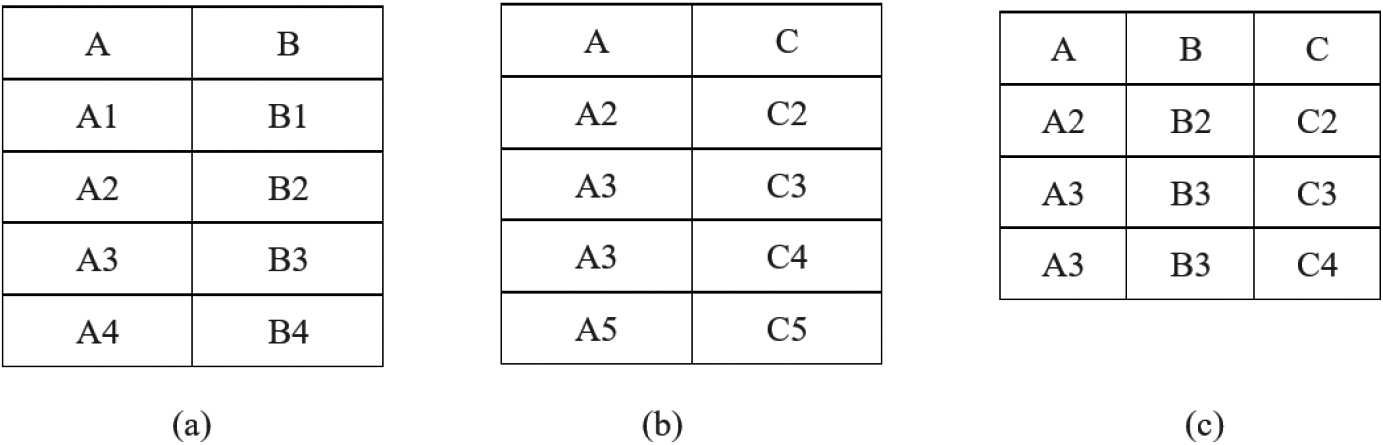
Taking Fig. 1 as an example, Fig. 2 shows the table instance of co-location
The external utilities corresponding to the features of the spatial data set in Fig. 1 are shown in Table 2.
External utilities of five features in Fig. 1
External utilities of five features in Fig. 1
For the data set in Fig. 1, the utility of feature A in co-location pattern {A, B} is:
For the data set in Fig. 1, the average utility of co-location pattern
For the data set
Based on the above definitions, HAUCP mining can be defined as: given a spatial data set
In the traditional prevalent co-location pattern mining, the prevalence measure
Basic algorithm
Total utilities of star neighborhoods of the spatial data set in Fig. 1
Total utilities of star neighborhoods of the spatial data set in Fig. 1
For example, in Table 3, the total utility of star neighborhood
For example in Table 3:
If the
For example, in Table 3
For example, in Table 3,
According to Lemmas 3 and 4, based on the extended average utility of co-location patterns, some patterns that are not likely to become a HAUCP are removed in advance. Algorithm 1 is our basic algorithm for mining all HAUCPs
The basic algorithm is explained as follows:
Steps 1–4 (initialization): Given an input spatial data set
The time complexity of Algorithm 1 is related to the number of candidate HAUCPs, and the number of candidate HAUCPs is related to the distance threshold, the number of features, the number of instances, and the average utility threshold. For the candidate HAUCPs that has not been pruned, it is necessary to scan the neighbor relationship
Because the extended average utility in the basic algorithm is too loose, the pruning effect is not obvious. In order to more effectively prune candidate patterns, this section we will reduce the extended average utility of the pattern to make it closer to the actual average utility value of the pattern.
Maximum utilities of star neighborhoods of the spatial data set in Fig. 1
Maximum utilities of star neighborhoods of the spatial data set in Fig. 1
For example in the star neighborhood
For example in Table 4:
If
For example, in Table 4, there are
For example, in Table 4, there are
Based on the Lemma 5 and Lemma 6, an improved algorithm is designed as follows.
Algorithm 2 is explained as follows:
Steps 1–4 (initialization): Same as Algorithm 1 Steps 5–9 generates size
Since the two algorithms proposed in this paper differ only in the number of candidate patterns, according to Lemma 7, for any co-location pattern
Experimental environment
The HAUCP mining algorithm and the spatial high utility co-location pattern mining algorithm EPA [13] are both written in Java (
Experimental data
In the experiment, we mainly used two types of spatial data sets, the synthetic and the real data sets. The real data sets include “Gong Shan vegetation” data set 1, “Shanghai POI” data set 2, “Lasvegas” data set 3, “Beijing POI” data set 4, and “Toronto” data set 5. The data distributions of the 5 real data sets are shown in Fig. 3a–e, and their property information are listed in Table 5. Synthetic data sets are generated using a spatial data generator similar to [14]. In the following experiments,
A summary of the 5 real data sets
A summary of the 5 real data sets
The distribution of the 4 5 real data sets.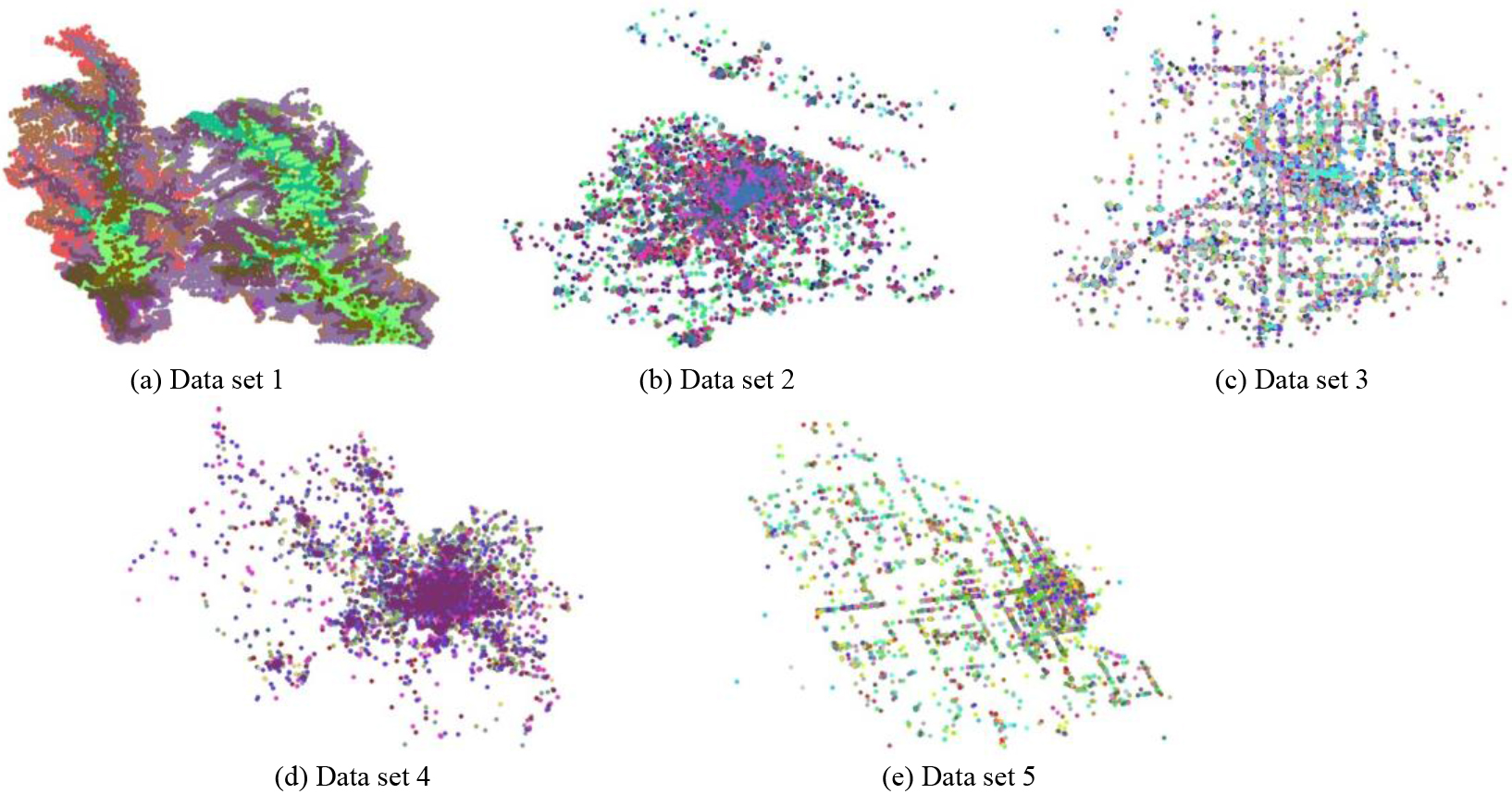
We aim at finding the high utility co-locations whose instances are frequently located together in geographic space and have high utilities. To measure the rationality of a mined pattern
Where
The algorithm EPA proposed in the literature [13] is the only mining spatial high utility co-location pattern algorithm from data sets of spatial feature with utility, and the HAUCP mining algorithm proposed in this paper is also mining HAUCPs on data sets of spatial feature with utility. Therefore, the experiments in this part mainly compare the effectiveness and rationality of the mined patterns based on different metrics by
Effect of 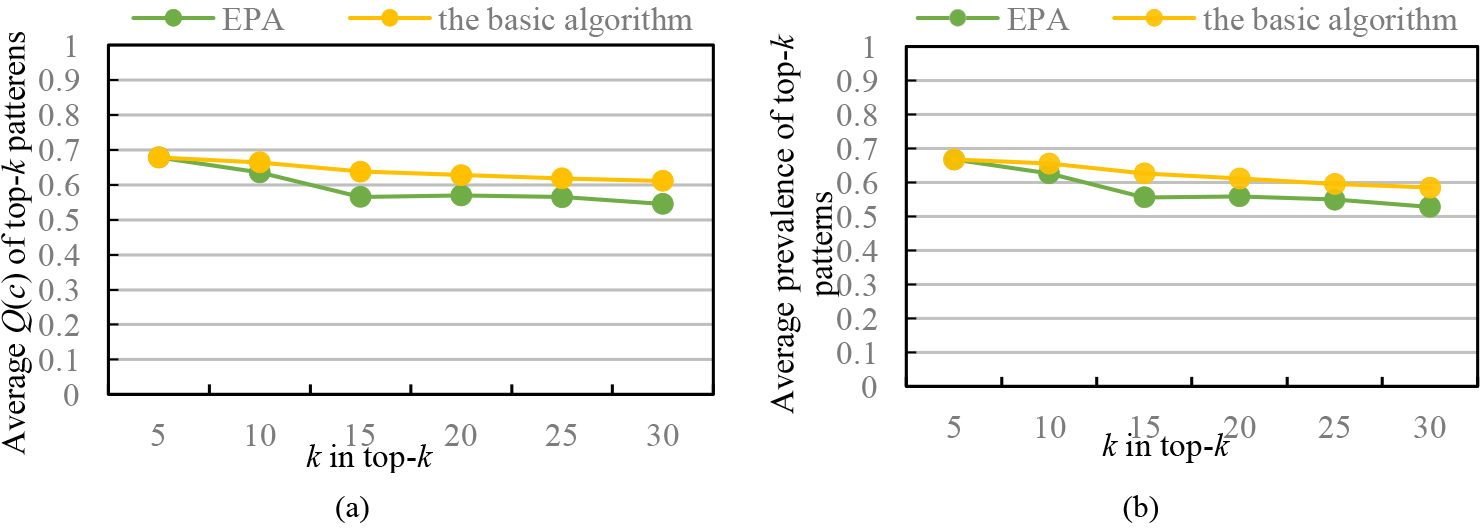
(A) Effect of
in top-
mined patterns
In Fig. 4, we set
(B) Effect of the pattern utility ratio threshold
In Fig. 5, we set
Effect of the pattern utility ratio threshold.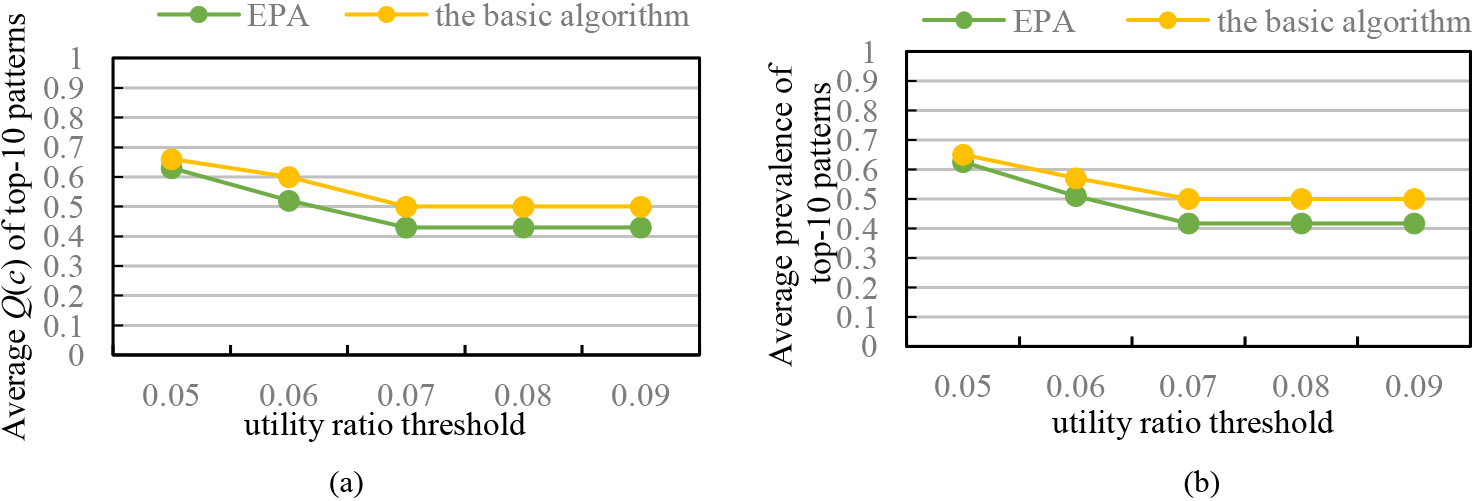
Effect of the distance threshold.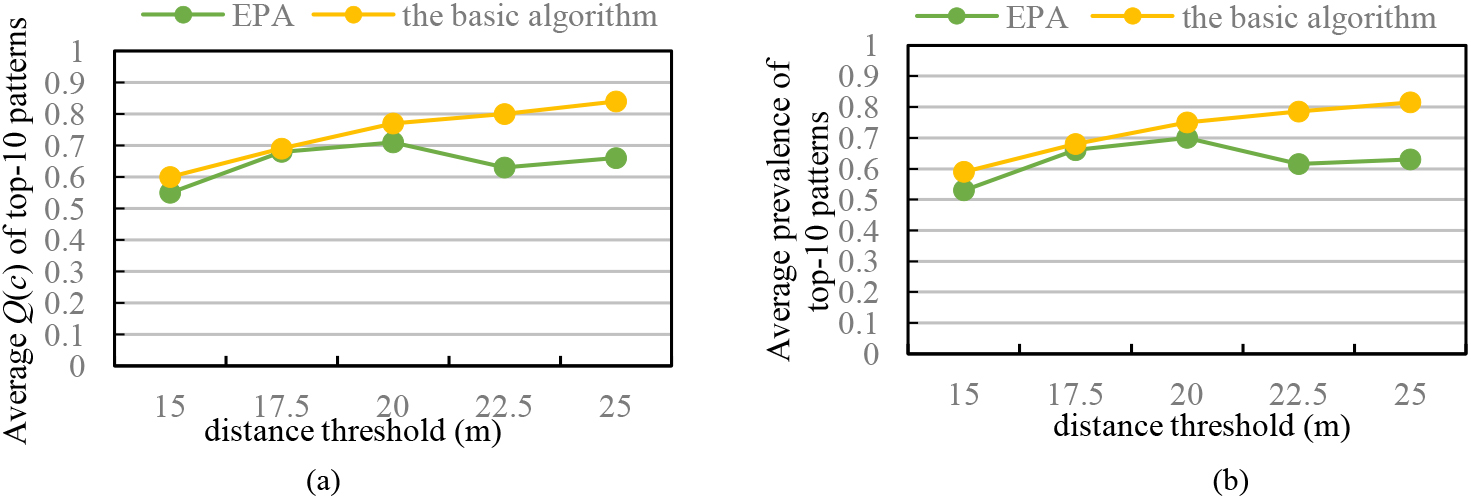
Effect of the pattern utility ratio threshold.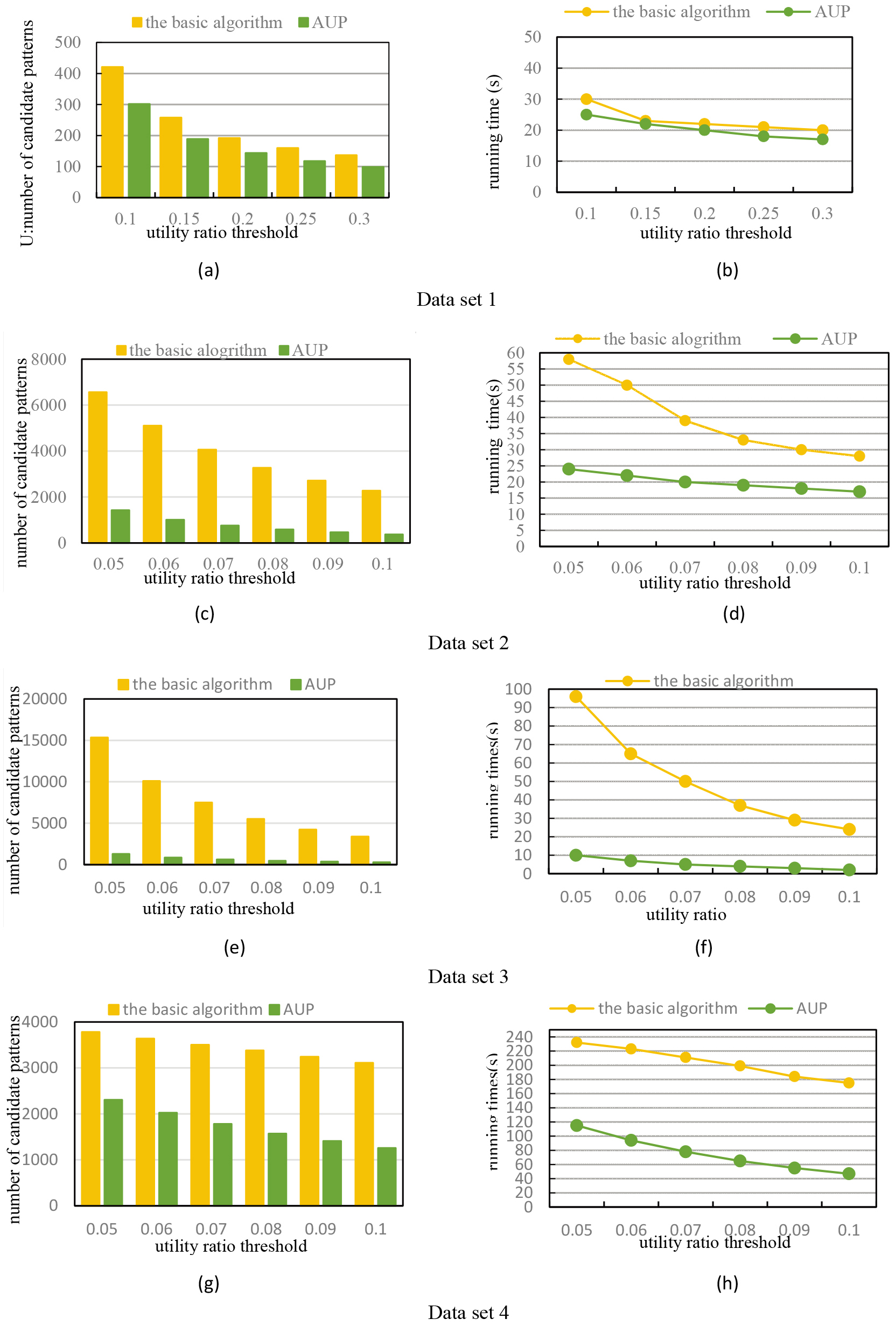
Continued.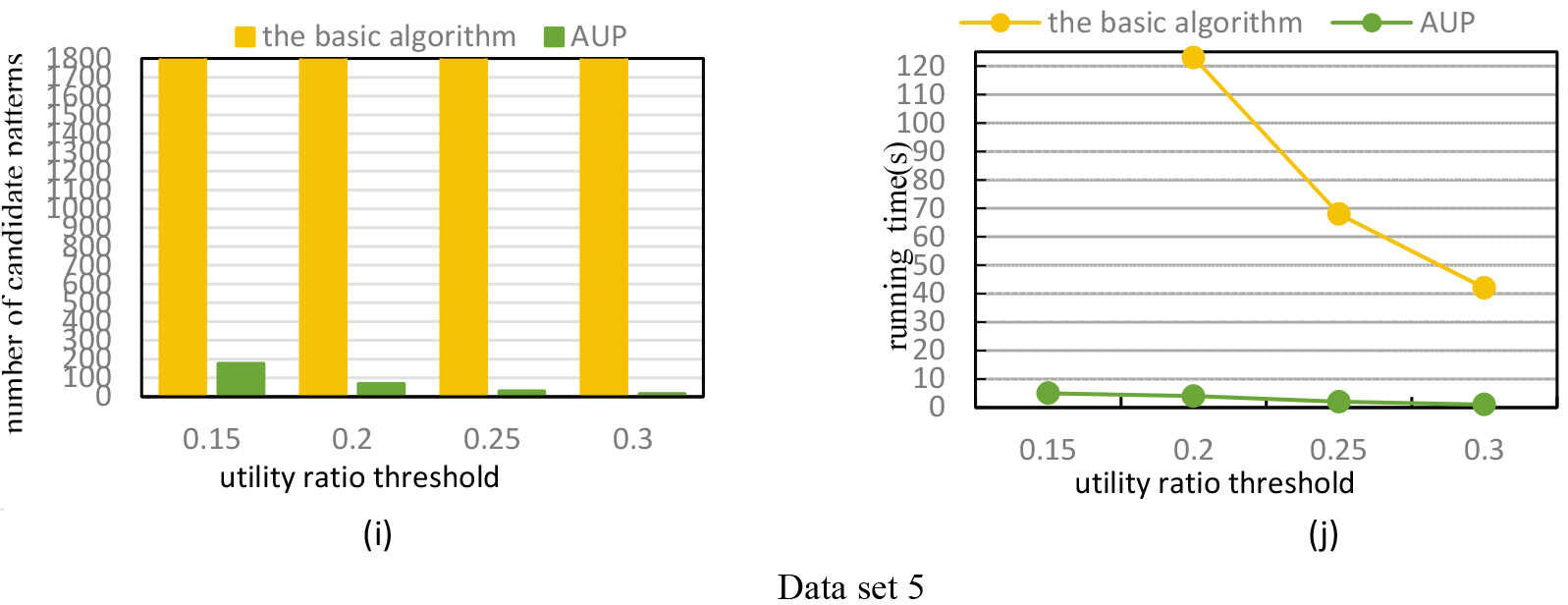
(C) Effect of distance threshold
In Fig. 6, we set
In this section, we compare the efficiency of the basic method and the improved algorithm (denoted AUP) on the 5 real data sets and synthetic data sets.
(A) Effect of the pattern utility ratio
In the real data set 1, we set
(B) Effect of distance threshold
For this experiment we set
Effect of distance threshold 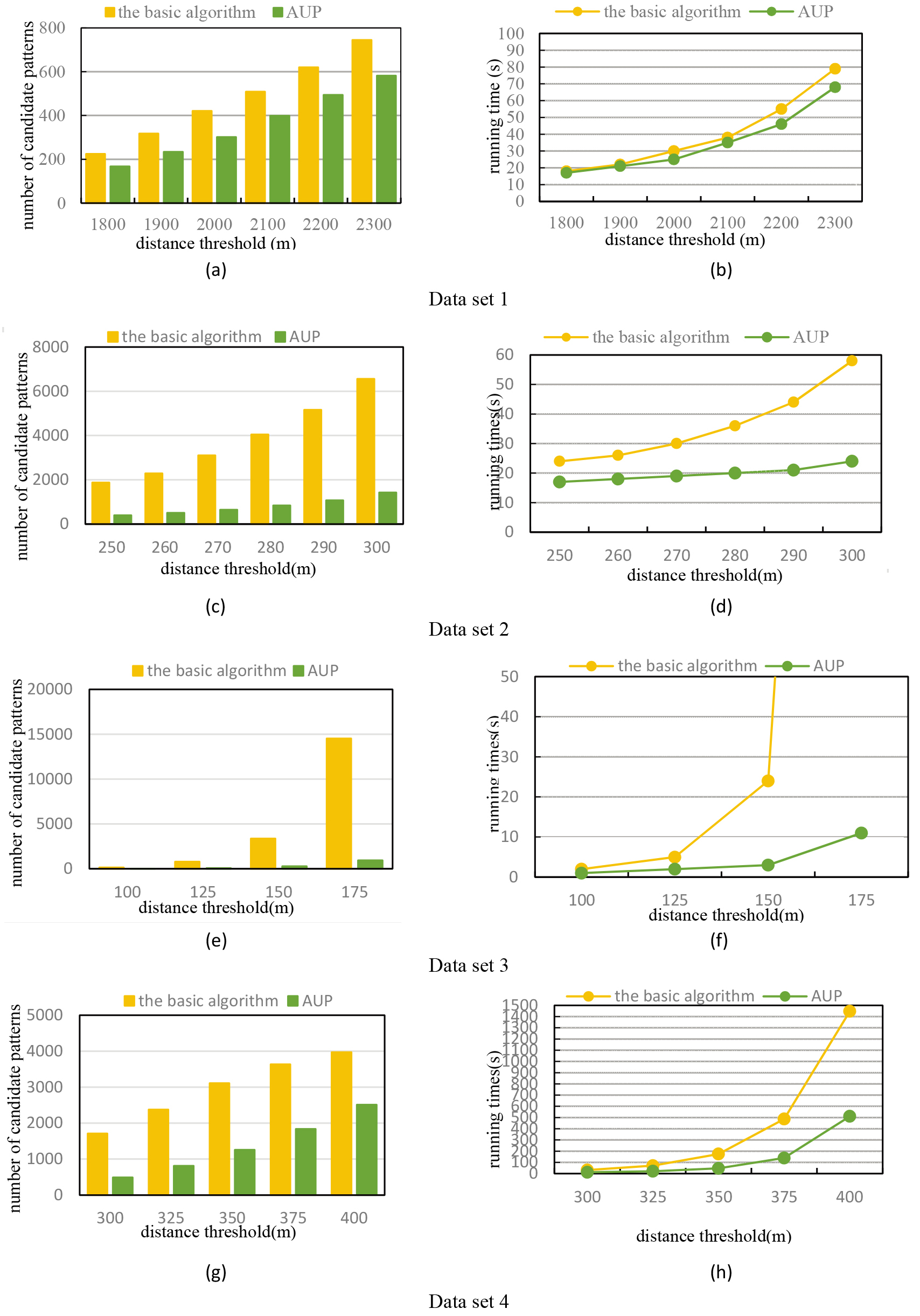
Continued.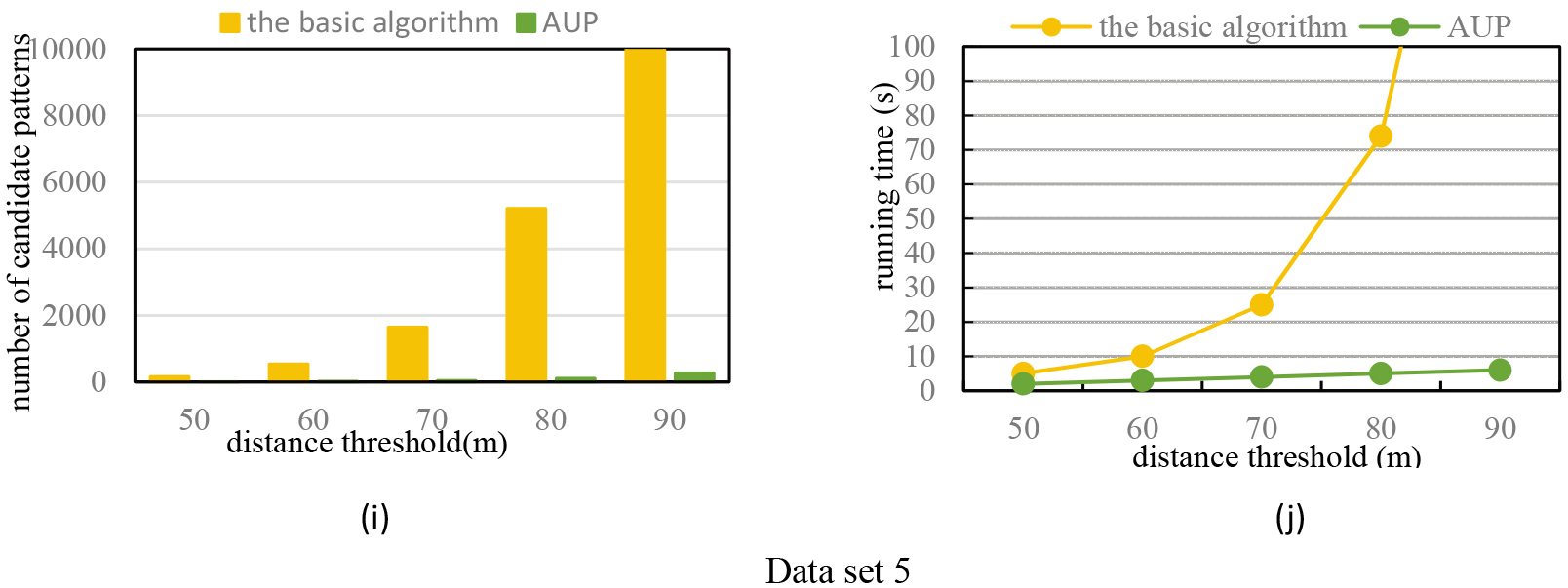
(C) Effect of the number of features
We do this experiment using synthetic datasets We set
Effect of the number of features.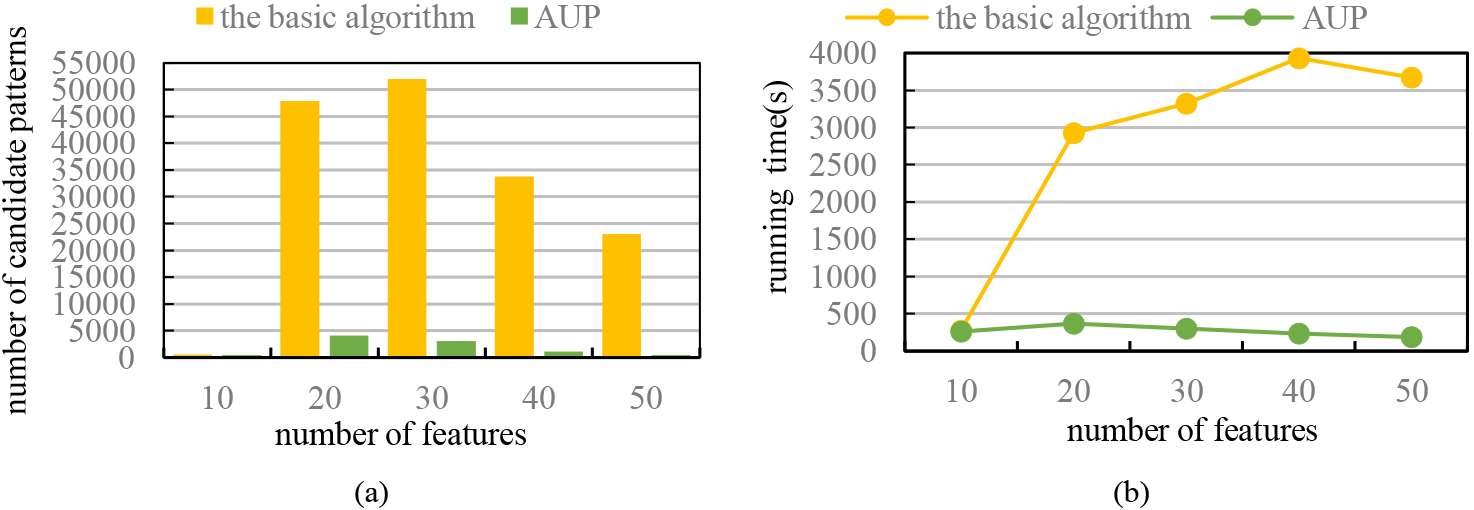
(D) Effect of the number of total instances
In the synthetic data set, we set
Effect of the number of total instances.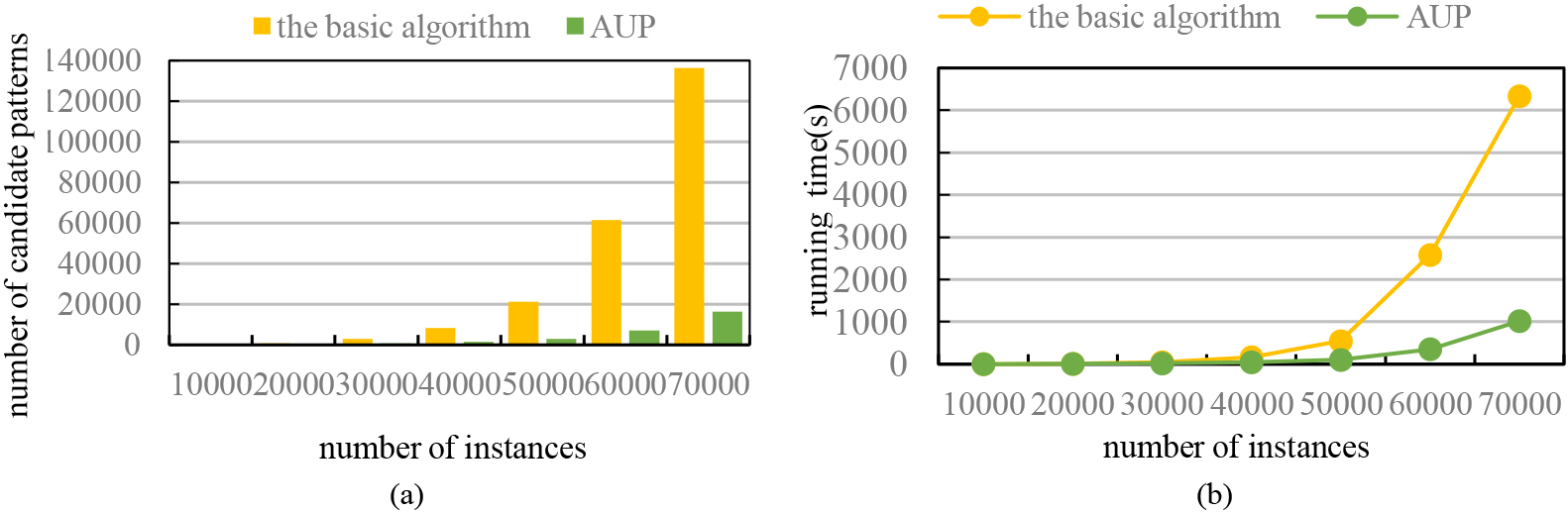
This paper redefines the metrics of patterns of interest and first introduces the average utility in the spatial co-location pattern mining framework. For the property that the average utility ratio does not satisfy the downward closure, we propose to over-estimate the average utility ratio of a pattern, and a basic algorithm for HAUCP mining is proposed. In order to improve the efficiency of the basic algorithm, this paper further improves the extended average utility in the basic algorithm and proposes an improved algorithm based on local extended average utility ratio. A large number of experimental results show that the improved algorithm can efficiently mine HAUCPs. However, the utility ratio threshold of this paper is given by the user, and it is highly dependent on the user. Setting an appropriate minimum utility ratio threshold is not easy. The most common method is to continuously try different thresholds and obtain the most suitable threshold from the results of multiple attempts. It can be seen that this method of setting the utility ratio threshold is not only tedious but uncontrollable. Therefore, in the future work, based on the research in this paper, we will consider the problem of mining the top-
Footnotes
Acknowledgments
This work is supported by the Yunnan Provincial Major Science and Technology Special Plan Projects (202202AD080003), National Natural Science Foundation of China (61966036, 41906148, 61662086), and the Project of Innovative Research Team of Yunnan Province (2018HC019).