
Abstract
Dynamic Time Warping (DTW algorithm) provides an effective method to obtain the similarity between unequal-sized signals. However, it cannot directly deal with high-dimensional samples such as matrices. Expanding a matrix to one dimensional vector as the input data of DTW will decrease the measure accuracy because of the losing of position information in the matrix. Aiming at this problem, a two-dimensional dynamic time warping algorithm (2D-DTW) is proposed in this paper to directly measure the similarity between matrices. In 2D-DTW algorithm, a three dimensional distance-cuboid is constructed, and its mapped distance matrix is defined by cutting and compressing the distance-cuboid. By introducing the dynamic programming theory to search the shortest warping path in the mapped matrix, the corresponding shortest distance can be obtained as the expected similarity measure. The experimental results suggest that the performance of 2D-DTW distance is superior to the traditional Euclidean distance and can improve the similarity accuracy between matrices by introducing the warping alignment mechanisms. 2D-DTW algorithm extends the application ranges of traditional DTW and is especially suitable for high-dimensional data.
Introduction
As a significant similarity measure, distance is widely used in many clustering and classification algorithms in the field of machine learning and pattern recognition [6, 8]. Some well-known distances, such as Euclidean distance, Manhattan distance, chebyshev distance, minkowski distance, hamming distance, cosine similarity and so on [1], explain the similarity from different perspectives. However, a strict precondition is required for these distances that the samples (general are vectors) must be of the same length. Some vectors obtained by certain feature extraction method are very easy to satisfy thus constraint. But for many original signals directly from sampling, it is not applicable to calculate the similarity because of their unequal length, for example, some original speech timeseries and gene sequence. Fortunately, Dynamic Time Warping (DTW) [2] is available to solve this problem and become one of the important distance measures for vectors with unequal length.
DTW algorithm take advantage of the local stretch or compression to the time axes, and search the optimally alignment of points to map one timeseries onto another with difference length. E.g. for the speech signal, it is unavoidable for one speaker that there are differences in tone and environment. In other words, almost all the speech timeseries are different even sampling from the same person with same language content. So it is impossible for traditional methods to one-to-one align the similar points of signals exactly right. With the merit of time warping technique to nonlinear align the sequence, it is credible for DTW to obtain the exact similarity between such unequal length timeseries and then achieve high recognition accuracy. And still for the advantage of nonlinear alignment mechanism, our improved 2D-DTW algorithm is superior to traditional distances even for equal length samples (which will be discussed and analyzed in experimental section).
With the rapid development of intelligent technology, DTW algorithm has been comprehensively applied in many fields in last few years, including the complex sequences recognition by DTW in machine vision and bioinformatics. For the gait recognition in machine vision, Ahmed et al. proposed a DTW-based kernel and rank-level fusion in 2015 [3]. Zhao et al. achieved the region correction for train coupler buffer images in 2017 [14]. For image similarity, Wang et al. proposed a measurement of graph similarity based on vertical dimension sequence DTW in 2018 [11]. That is to say, in addition to speech recognition, DTW algorithm has a wide-ranging application and excellent identification effect in image processing.
Like many bursting algorithms, DTW continuously develop in theory along with the advanced intelligent technology, and some improved hybrid algorithms based on DTW have been explored. For example, in 2011, Jeong et al. proposed the weighted DTW by penalizing points with higher phase difference between a reference point and a testing point [13]. Zhao et al. proposed a shape DTW algorithm in 2018, which try to match the local similar points and avoid the point with different neighborhood structure [7]. In 2018, Li et al. proposed a filtering search method to balance the matching precision and computational efficiency [15]. In 2020, Li et al. developed an adaptively constrained DTW to adjust the corresponding relationship between two trajectories [5].
As an active similarity measure, DTW provides excellent performance for many distance-based machine learning algorithms such as support vector machine and fuzzy clustering. However, because traditional DTW can only process one dimensional sample, feature extraction is generally required for some matrices to get one dimensional vector in advance to complete the optimization procedure. The loss of information in the process of feature extraction will decrease the measurement accuracy. Therefore, it is desirable to overcome this limitation to directly calculate the similarity between matrices. Here, we proposed a two-dimensional dynamic time warping algorithm by designing a distance-cuboid between matrices and searching the shortest path with dynamic programing theory (For the convenience of description, we use the short term 2D-DTW for this new algorithm hereinafter). What’s more, the input data of 2D-DTW is extended from one dimensional sequence to two dimensional matrices which broaden the application ranges and especially suitable for high-dimensional data.
Related works
DTW algorithm is one of the branches of nonlinear programming theory, which is to study the relationship of unequal length signals by introducing the dynamic programming technique to get the shortest cumulative distance as the similarity measure.
Suppose two sequences
The element
Then we provide the detailed process of searching shortest path in matrix D0 by dynamic programming [12, 9]. According to the pairwise similarity of elements
Where
To guarantee that DTW algorithm can convergence in finite time and the completeness of the algorithm, some constraint conditions should be satisfied.
Comply with the theory of DTW and its constraint conditions, the pseudocode of DTW algorithm is given as.
There are two main parts in DTW algorithm, in where part 1 is the calculation of shortest accumulated distance according to Eq. (2), and part 2 is the backtracking of shortest path (so called “warping path”) from the last state of the minimum cumulative distance to the initial state.
By virtue of introducing the ideas of dynamic programming to compare single element, DTW algorithm provide an effective method to obtain the distance between unequal length sequences, as well as the method for equal length sequences to obtain more accurate distance. However, the limitation of traditional DTW is that it cannot directly deal with high-dimensional samples such as matrices.
As for the position information in matrix, one dimensional sequence has no ability of storage and process, which limits the applications of traditional DTW in some practical problems. That is the motivation of our work to develop the similarity between two dimensional matrixes to improve the traditional method. The proposed algorithm based on dynamic programming theory is named as 2D-DTW algorithm.
Different from other pattern recognition methods such as deep learning or neural networks, 2D-DTW algorithm can obtain the similarity between two matrices without any training samples. Not needing to collect a large number of reliable samples as training data, 2D-DTW can be directly applied to unsupervised learning without prior knowledge. In theory, the similarity result between two matrices in 2D-DTW algorithm is independent of the size of dataset, whether for a small sample or a large-scale sample. As a contrast for ANN, if the training data is insufficient or not with high quality, the performance will be seriously affected.
What more, 2D-DTW can process unequal-sized samples by warping alignment mechanism, which is essentially different from other methods that using one-to-one correspondence between equal-sized samples. However, many approaches such as ANN, have difficulty to deal with unequal-sized samples. Some special steps are required to convert the unequal-sized samples to equal-sized samples, which will cause the loss of information in the matrix and then impair the result.
Construct distance-cuboid
Suppose two matrices
In order to construct the distance-cuboid, matrices
Three-dimensional cuboid by matrix alignment.
If the cuboid is regarded as a three dimensional matrix, then the values of single point distance between matrices
Where
To obtain the shortest path in cuboid-D with dynamic programming, we use the cutting and compressive technique to map the three dimensional cuboid-D to one plane and get a two dimensional mapping matrix. The detailed method of accumulating mapping values of the cuboid is given below.
In Eq. (4), there is the same
The demonstration of cutting cuboid-D.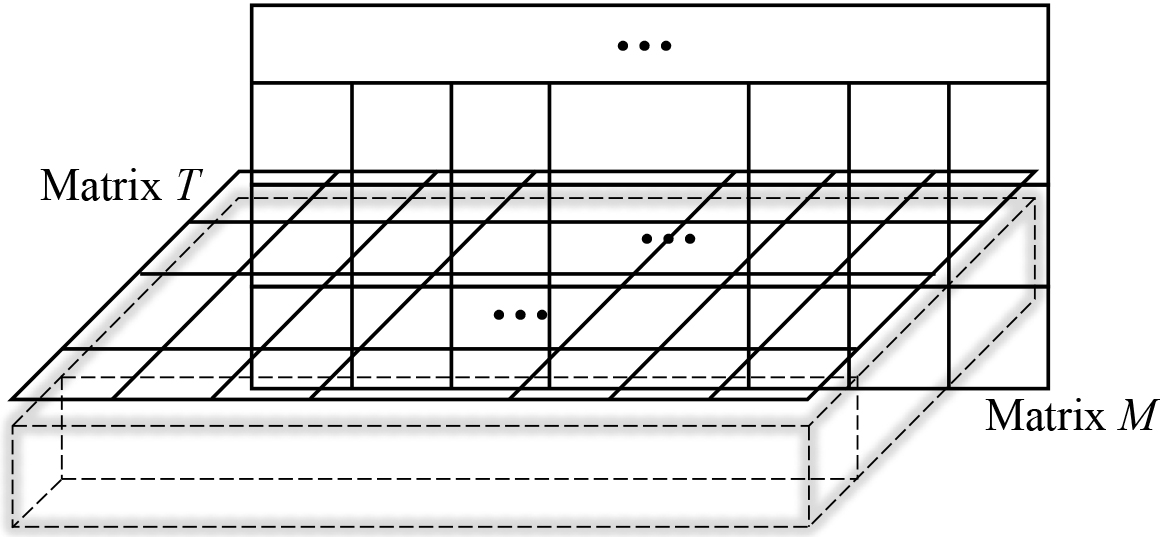
The cutting method in Fig. 2 can also be regarded as respectively cutting the matrices
The relationship between 
After cutting cuboid-D and getting all
Substitute Eq. (4) into Eq. (5), we can obtain Eq. (6)
Distance matrix D contains all the comparison between
Although distance
It should be noticed that the value of shortest distance vary with the size of input matrices. In order to eliminate the effect of matrix size and get an unbiased similarity measure, we define a standard distance as Dist in Eq. (7) by normalizing the shortest distance.
Where, dist is the shortest distance that is directly obtained from matrix D. So far we achieve the expected similarity between two matrices, as well as the row alignment of the input matrices. We used 2D-DTW distance to express the standard distance Dist when mentioned below.
2D-DTW distance obtained from Eq. (7) is an unbiased similarity measure, it can be regarded as a dimensionless measure that will not vary with data granularity. Regardless of the size of the matrix, the more similar the two matrices are, the smaller the 2D-DTW distance is. Of course, fine-grained data generally produce more accurate distance based on more reference comparisons, at the same time, the algorithm needs much time to search the optimal matching between all elements. That is to say, data granularity will affect the calculation speed and the similarity accuracy, but the similarity comparison of dimensionless measures is independent of granularity data. The provided 2D-DTW algorithm above only presents the cutting and compressive method for matrices with same column. Obviously, it is available for matrices with same row that cuboid-D can be cut and mapped to the bottom side to get compressed distance matrix. It needn’t to descriptions the algorithm again for the same steps. In the afterward section of experiments, our study is based on the same column matrices.
The theoretical rationality of 2D-DTW algorithm is analyzed firstly by using unequal sized matrices, then for the convenience of comparison with traditional method such as Euclidean distance, the equal sized matrices are used for the rest experiments. To verify the performance of 2D-DTW algorithm in practical applications and its sensitivity to noise and missing data, we performed the comparison experiments based on CIFAR-10 database, handwritten digit and real fingerprints.
Theoretical rationality experiment
Suppose two random integer matrices
The distance between matrices
Row alignment between matrices 
It can be seen from Fig. 4 that the row 1 and row 2 in matrix
In many applications, the foreground image in the sampling matrix cannot be in the same size for some uncontrollable factors. We compared the 2D-DTW distance and the traditional Euclidean distance based on CIFAR-10 image database [4]. No. 1 image in data_batch_2 in airplane dataset serve as the template sample which is shown in Fig. 5a. The 10 test samples randomly selected from the airplane dataset is No. 500, No. 85, No. 789, No. 29, No. 914, No. 719, No. 481, No. 570, No. 234, No. 845, which are renumbered as 1–10 images in Fig. 5b (when mentioned below we use the new numbers 1–10).
Airplane images of template and test sample.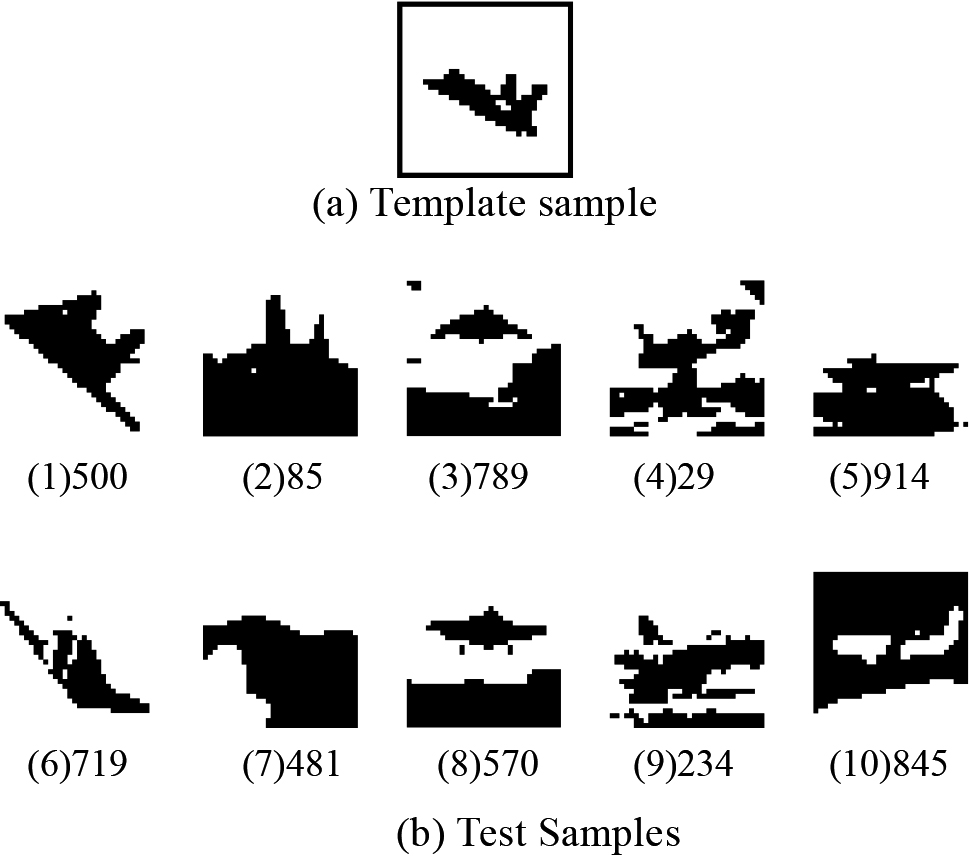
We preprocess the airplane images by binarization technology with Matlab tools [10] and get the binary images with the foreground only include the object of airplane. The image size of template and samples is 32
The comparison of 2D-DTW distance and Euclidean distance
The computing time of 2D-DTW distance and Euclidean distance (second)
It can be seen in Table 1 that No. 10 airplane is least similar to the template either by 2D-DTW distance or by Euclidean distance, primarily because of the opposite foreground and background. According to the distance values in Table 1, No. 1 and No. 6 airplane are most similar to the template based on 2D-DTW distance with the approximately equal smaller values 0.004180908 and 0.004364014. However, if considering the smallest Euclidean distance 0.00589, No. 6 airplane is most similar to the template. We also observed that the second similar Euclidean distance is No. 1 airplane, but there is a lot bigger value than that of No. 6 airplane.
Then we further analyze the disagreement results on No. 1 airplane. We can see that No. 1 airplane displays the visible aircraft outline and body shape, which is similar to the template aircraft with upper-left direction body shape, and there is somewhat similar in airplane’s wing. The main difference between them is that the aircraft in template is smaller than that in No. 1. Fortunately, this difference cannot affect the judgment of 2D-DTW algorithm benefit from its warping alignment mechanism for matching the similar point in the matrix. In contrast, the unequal sized foreground increased the Euclidean distance between No. 1 airplane and the template. The most similar No. 6 aircraft judged by Euclidean distance displays the visible approximate sized aircraft outline and the upper-left trend. According to the statistics, the foreground pixels proportion in template is 894/1024 and No. 6 image is 841/1024. The approximate percentages of black pixels in the two images lead to the above results judged by Euclidean distance.
In short, the 2D-DTW algorithm takes more into account about the matching of shape, trend and resize during the distance calculation. As for the one-to-one point comparison of Euclidean distance, the judgment depends on the object pixels percentage which conceal the important information such as shape, trend and resize.
Additionally, the computing time of the 10 test samples under the same environment is shown in Table 2.
We can know from Table 2 that 2D-DTW algorithm expends the total of 0.054615 seconds to computing all the 10 samples, and the average time is 0.0054615 seconds. The total time for Euclidean distance is 0.003383 seconds and the average time is 0.0003383 seconds. It is the alignment mechanism in 2D-DTW algorithm that increases the time consumption to achieve a more optimal matching.
The real fingerprint images come from semiconductor fingerprint sensor. The six fingerprint samples are respectively collected from three different overlap areas of right thumb image and three areas of left thumb image, and are stored as 176*176 grey images. The six fingerprint samples are numbered as in Fig. 6.
The Left thumb and Right thumb can be viewed as two categories, and then we performed the identification experiment by different distance. The pairwise similarities by 2D-DTW distances are shown in Table 3 and Euclidean distance in Table 4.
The pairwise similarity by 2D-DTW algorithm
The pairwise similarity by 2D-DTW algorithm
Real fingerprint images from semiconductor sensor.
The pairwise similarity by Euclidean distance
For each fingerprint images, the distances between it and all other images are calculated, and the zero values in Tables 3 and 4 indicate the comparison with oneself. The most similar results (except for oneself) for fingerprint indicated by each column heading are highlight with bold font. As for the highlighted cell, if the fingerprint indicated by row heading is the same category as the column heading, it is considered as a correct identification. The results in Tables 3 and 4 reveal that 2D-DTW algorithm successfully identify 5 samples (Left 1 is wrong), while Euclidean distance identify 4 samples (Left 1 and Left 2 are wrong).
Once again, 2D-DTW algorithm obtains expected performance benefit from warping alignment technique. The fingerprint images from one thumb possess the same ridge characteristic rather than the one-to-one similar points, only by local stretch or compression technique can achieve the warping optimally matching points. This is the explanation why the 2D-DTW algorithm is superior to Euclidean distance for this practical application.
We then verify the sensitivity of 2D-DTW algorithm to noise and missing data. Figure 7a is a handwritten image with the correct digit 0, Fig. 7b is a synthetic sample with 10% random noise, and Fig. 7c is also a synthetic sample with 10% data missing in foreground. Then we construct 10 template digit images with Times New Roman font. The different handwritten digit samples and 10 template digits are shown in Fig. 7.
Handwritten digits and 10 template digits. (a) Handwritten digit (b) Handwritten digit with 10% noise (c) Handwritten digit with 10% data missing in foreground (d) Template digits.
In Fig. 7, all handwritten images and template images are stored in matrices with size 28
The comparative recognition results obtained from three distances
Among the five most similar digits, the closer the number 0 is to the left, the better the performance of the corresponding algorithm. We can observe in Table 5 that the recognition results of sample (c) are the worst, which suggest that all three methods are sensitive to samples with missing data. And noise only affects DTW algorithm, but has a little effect on 2D-DTW and Euclidean distance.
By warping match the similar point, 2D-DTW algorithm achieve the best recognition results. In contrast, Euclidean distance using the one to one point comparison is inefficient for the roughly similar image. DTW is limited to one-dimensional method, and some location information will be lost after expanding the image matrix, which is the main reason for its poor recognition.
A new distance measure is defined in the proposed 2D-DTW algorithm to improve the traditional method. Where the input data of 2D-DTW is two dimensional matrices and the output is the similarity between matrices. By constructing a distance-cuboid and searching shortest path using dynamic programming in the mapped matrix, 2D-DTW algorithm can directly obtain the distance between matrices. It is worth mentioning that 2D-DTW can used for the especial unequal size matrices such as that have equal column but unequal row or vice versa. In additions, by normalizing the accumulated shortest distance, the 2D-DTW distance can eliminate the effect of input matrix size and get the unbiased similarity. By virtue of the introduction of warping alignment mechanism, 2D-DTW algorithm can measure the similarity of matrices more accurately than traditional Euclidean distance.
The experimental results based on CIFAR-10 images database and real fingerprints show that 2D-DTW algorithm can achieve expected performance within an acceptable computing time. Certainly, without considering the comparison, the unequal sized matrices (with the same number of row/column) can be used in the practical problem. With the idea of directly taking matrices as input data, 2D-DTW algorithm simplifies the feature extraction or preprocess step in machine learning or pattern recognition. In short, 2D-DTW algorithm based on dynamic programming provides a promising method for the similarity measure of equal size matrices and special unequal size matrices.
In the proposed method, the distance cuboid is constructed by using complete matrices. Actually, for the similarity between matrices in a certain domain, the searching of shortest path can be further simply if the matrices may be partitioned. Taking the similarity of two images as an example, if there are some domain knowledge, such as the matching of local region or special point, these prior knowledge can be used to pre segment the matrices, and then the calculation time between sub-matrices can be greatly reduced. Our future research work will focus on the computational efficiency.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (61402202, 61772013), China Postdoctoral Science Foundation (2015M581724).