
Abstract
Exploiting label correlation is crucially important in multi-label learning, where each instance is associated with multiple labels simultaneously. Multi-label learning is more complex than single-label learning for that the labels tend to be correlated. Traditional multi-label learning algorithms learn independent classifiers for each label and employ ranking or threshold on the classification results. Most existing methods take label correlation as prior knowledge, which have worked well, but they failed to make full use of label dependency. As a result, the real relationship among labels may not be correctly characterized and the final prediction is not explicitly correlated. To address these problems, we propose a novel high-order multi-label learning algorithm of Label collAboration based Multi-laBel learning (LAMB). With regard to each label, LAMB utilizes collaboration between its own prediction and the prediction of other labels. Extensive experiments on various datasets demonstrate that our proposed LAMB algorithm achieves superior performance over existing state-of-the-art algorithms. In addition, one real-world dataset of channelrhodopsins chimeras is assessed, which would be of great value as pre-screen for membrane proteins function.
Introduction
In real-world, objects might have multiple semantic meanings. In order to explicitly express semantics of objects, one direct solution is to assign a set of proper labels to each object. Multi-label learning is one of the major learning frameworks to deal with real-world objects with various semantics, where each instance is represented by a feature vector and assigned with multiple labels [29]. Multi-label learning has various application scenarios, such as tagging songs with a subset of emotions [22], image annotation [24], text classification [13, 18], information retrieval [7] video annotation [14] and bioinformatics [27].
A common approach to multi-label learning is to transform into multiple single-label learning problems [23]. When treating labels independently, these methods fail to model the dependency between multiple labels. Exploiting label correlation [1] in multi-label learning has been an important and practical research topic. Previous researches have shown that multi-label classification problems exhibit strong label co-occurrence dependencies [25]. For instance, blue sky and cloud usually appear together, while blue sky and smog almost never co-occur. Moreover, most of these methods either can not model higher-order label correlation, or sacrifice computational complexity to model a more complicated label relationship [19].
An example of image annotation. The image can be annotated with labels: wind chime, baby’s cot, sofa and stuffed elephant.
Take Fig. 1 as an example, we might notice some more obvious objects in the image like baby’s cot, sofa, wind chime and elephant at the first glance. Such a combination of objects in the image hints us of a living room, which will further help us better recognize the elephant on the carpet to be stuffed animals instead of real ones. The recognition route from the baby’s cot to the living room, and then to stuffed animals, are supposed to deal with label correlation of the prediction. Previous researches, i.e., Classifier Chains (CC) algorithm [21] is a high-order approach considering the relationship among labels, but it is affected by the order of predicted labels. Therefore, how to make full use of the high-order label-dependencies among labels to improve the classification accuracy and reduce the computational complexity becomes extremely challenging. Previous methods mainly focus on exploiting uni-directional relationship. For example,
To resolve the above challenges, we present a novel high-order multi-label learning algorithm of Label collAboration based Multi-laBel learning (LAMB). It can not only well exploit label correlations, but also maintain acceptable computational complexity. Meanwhile, we propose a novel Classifier Reuse and Label-based Reweight (CRLR) algorithm to explore interaction of one label with all other labels in LAMB. Each label contains unique characteristics and it can be seen as domain expert which conveys essential domain knowledge to other labels. For one thing, in each boosting round, in addition to generating a base classifier for each label set from its own hypothesis space, CRLR tries to reuse the classifier generated for the other label set. The reuse process takes into account all trained classifiers from itself and all other labels. For another, CRLR adopts label-based reweight mechanism: if classifier on one label set reused by the other label set makes mistakes, the corresponding weight will be assigned higher. As a result, each label in multi-label learning is able to provide rich domain knowledge with each other and extract complementary information. As is shown in Fig. 2, LAMB algorithm trains
Example of LAMB’s voting procedure of the
The architecture of LAMB algorithm. The red circles in the rectangle denote the classifiers produced by CRLR algorithm. When invoking CRLR once, it outputs one classifier set composed of 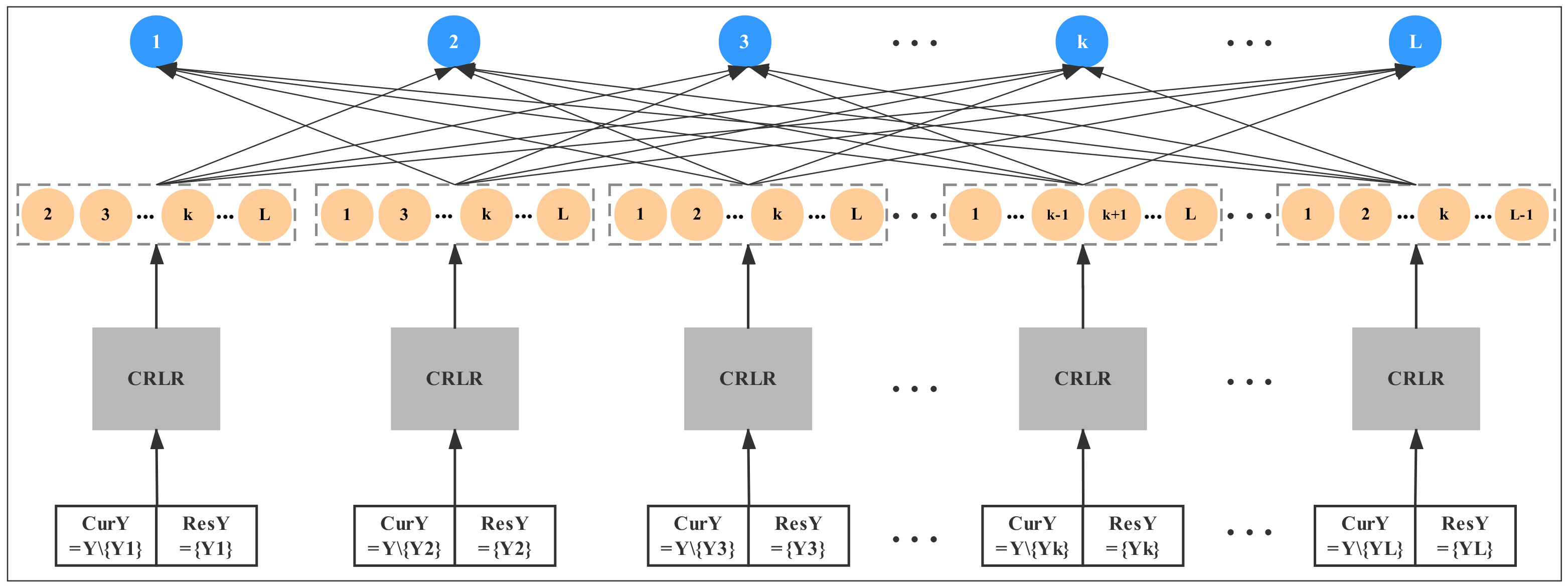
The main contributions of this paper include:
A novel algorithm of Label collAboration based Multi-laBel learning (LAMB) is proposed to learn global label correlation, with the help of our proposed Classifier Reuse and Label-based Reweight (CRLR) algorithm. Without pre-determining the label order for prediction, LAMB makes prediction for each label by combining the prediction of its own label and the prediction of other labels. LAMB algorithm is more compact and more powerful of high-order label co-occurrence dependency than other state-of-the-art multi-label learning algorithms. One real-world channelrhodopsins chimeras dataset is manually collected and adapted for LAMB algorithm. Furthermore, LAMB algorithm advances the prediction performance of eukaryotic expression and plasma membrane localization, which is significant for membrane proteins function pre-screen.
The rest of the paper is organized as follows. We start with a brief review of related work. Then we formulate the problem and propose LAMB algorithm. Next, experimental results are reported, followed by the conclusion.
In this section, we briefly review the development of multi-label learning algorithms in terms of the order of label correlation [6].
As for first-order algorithms, the most straightforward way to deal with multi-label learning is to decompose them into multiple binary classification sub-problems. Binary Relevance (BR) [23] algorithm is the most simple and efficient solution of multi-label learning. Despite its simplicity, multiple labels are independent from each other.
As for second-order algorithms, they take pairwise relationship between labels into consideration, such as the ranking between relevant labels and irrelevant labels, or the interaction of paired labels [30]. Furthermore, LLSF [16] learns label specific features for each label, making the assumption that each label is only associated with a subset of features from the original feature set. And any two strongly correlated class labels can share more features with each other than two uncorrelated or weakly correlated ones.
As for high-order algorithms, one of the most prominent algorithms is Classifier Chains (CC) [21] which considers correlation between labels. It is obvious that the performance of CC is seriously affected by the training order of labels. To account for the effect of ordering, Ensemble of Classifier Chains (ECC) [21] is an ensemble framework of CC, which can be built with
Methodology
This section briefly presents the problem formulation, and then introduces the overall strategy of our proposed LAMB algorithm in detail.
Preliminary
Firstly, we summarize some formal symbols used in this paper. In the following, bold character denotes vector.
Let
In multi-label learning, the task is to learn a mapping function:
Diagrammatic illustration of multi-label learning. Circles on the right part denote labels. In the training phase, labels are tagged with 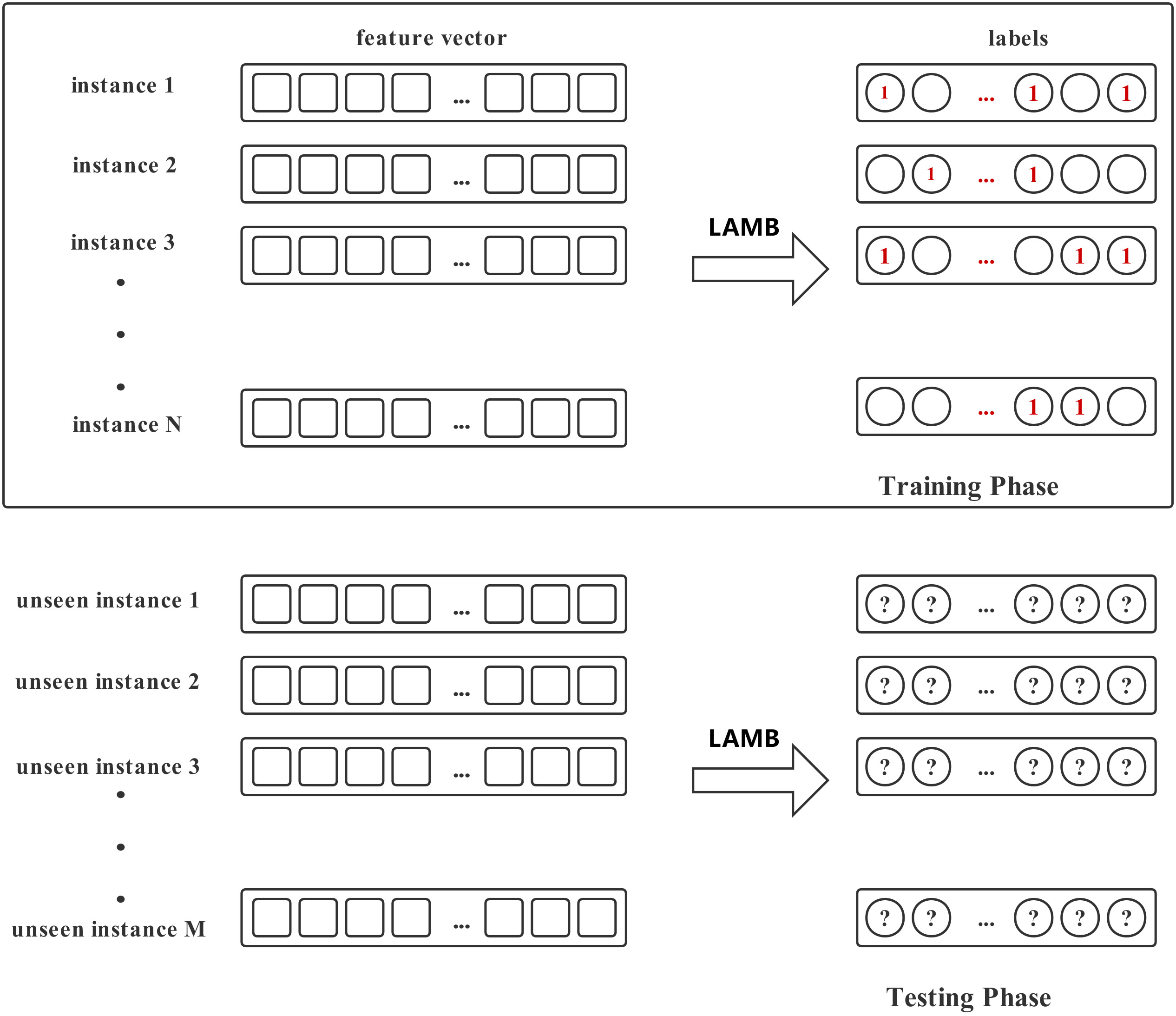
Furthermore, we define some notations used for testing phase. Suppose there is a testing dataset
Based on the above problem formulation, we present Label collAboration based Multi-laBel learning (LAMB) algorithm. In order to exploit the relationship between the
[h] : LAMB Algorithm[1]
Next, we introduce our proposed CRLR algorithm for LAMB algorithm in detail. The procedure of CRLR is shown in Alg. 3.2 and the additional notations is listed as follows.
CRLR algorithm decomposes the original problem into two dependent classification problems in the boosting framework. A common advantage of ensembles is their well-known effect of generally increasing overall predictive performance. In the classical AdaBoost algorithm, an instance on which classifier has made mistake will be emphasized by increasing its weight. CRLR algorithm maintains two sample distribution
[h] : CRLR algorithm[1]
Overview of LAMB algorithm at 
Classifier reuse
As illustrated in Fig. 4, we train three classifiers at each boosting round.
Classifier 1: Given training dataset
Classifier 2: Classifier 1 is reused to make prediction for label set in
Classifier 3: Similarly, Classifier 1 is reused to make prediction for label set in
Afterwards, we get classifier
where
where
Label-based reweight
We maintain two dataset
Considering mistake made by its own classifier. An instance on which the classifier that has made mistake will be emphasized by assigning a higher weight. As for
where As for
Considering mistake made by classifier reuse. We denote As for
As for
Above all, the sample distribution weight
where mistakes might be amplified if the classification is not correct through iterations.
To efficiently classify, we need to define a stop criterion for our algorithm.
The classifier is considered to be too weak to get better performance in the boosting framework when Reaching the maximum boosting round
Finally, taking classifier
where
In this section, we firstly describe the experimental datasets and experimental setting. And then, we present extensive experimental results and comparisons that demonstrate the superiority of our proposed LAMB algorithm. All the experiments are running on a machine with 3.2 GHz Inter Core i7 processor and 64 GB main memory.
Dataset description
The experiments are conducted on three public multi-label datasets and one manually collected real-world dataset. Note that there is no noise or missing values in these datasets. Details of the datasets are summarized in Table 6, where
Scene
A natural scene may contain multiple objects such that the scene can be described by multiple labels (e.g., a field scene with a mountain in the background). Semantic Scene [3] classification, is a public multi-label dataset with 2407 instances, where each instance contains 294 features and 6 labels.
Emotions
A piece of music may belong to more than one class. Emotions [22] is a publicly available dataset with 72 music features for 593 songs categorized into one or more out of 6 classes of emotions.
Yeast
Yeast Saccharomyces cerevisiae is one of the best studied organisms and Yeast [28] dataset is one of the most commonly used multi-label bioinformatic dataset. Each gene is described by the concatenation of micro-array expression data and phylogenetic profile. In Yeast gene functional classification dataset, there are 2417 genes each represented by a 103-dimensional feature vector and each gene is associated with 14 possible gene functional labels.
ChRs
A small subset 243 (0.2%) of ChR chimeras are chosen from a 118,098-variant ChR recombination library of three parent ChRs [2]. Detail in how to construct ChRs is described from the following two aspects.
As for input, we run ProFET over a sequence in
As for output, expression and localization are synthesized and measured for 243 sequences, which can be considered as two labels of membrane proteins. The biological experimental results (expression and localization) which is in the form of discrete values need to be transformed into class labels, i.e. 1 or
Statistics of datasets
Statistics of datasets
We compare high-order LAMB algorithm with four multi-label algorithms which are listed as follows:
4.3.1. HammingLoss evaluates the fraction of misclassified instance-label pairs, i.e. a relevant label is missed or an irrelevant is predicted.
where
4.3.2. SubsetAcc evaluates the fraction of correctly classified examples, i.e. the predicted label set is identical to the ground-truth label set. Intuitively, subset accuracy can be regarded as a multi-label counterpart of the traditional accuracy metric, and tends to be overly strict especially when the size of label space (i.e.
where
4.3.3.
where
4.3.4.
4.3.5.
For all these algorithms, we report the best results of the optimal parameters in terms of classification performance. Meanwhile, we perform 10-fold cross validation (CV) and take the average value of the results in the end.
Tables 3 and 4 report the detailed experimental results on three public datasets and one real-world channelrhodopsins chimeras dataset respectively, where the best performance among all the algorithms is shown in boldface. As for ChRs dataset, CC
Predictive performance (mean
std) comparison on three public multi-label datasets.
indicates that the larger/smaller the better of a criterion. The best performance on each dataset is bolded
Predictive performance (mean
Predictive performance comparison on ChRs dataset.
Predictive performance comparison on Scene dataset.
In order to investigate influence of boosting round and influence of label-based reweight parameter
Influence of boosting round
The number of boosting round
As is shown in Fig. 5, as number of boosting round increasing with
Influence of label-based reweight parameter
Reweight parameter
In Fig. 6, dotted lines represent the performance without label-based reweight mechanism and the other two solid lines are above the dotted line. It is obvious that LAMB with label-based reweight mechanism performs better than that without label-based reweight mechanism, which validate the effectiveness of label-based mechanism. Different datasets may have different optimal
Computational complexity of LAMB compared with common algorithms
Performance of changes made by the number of boosting round on Scene dataset when fix label-based reweight parameter 
Performance of changes made by label-based reweight parameter on Scene dataset. The dotted lines represent the performance when the number of boosting round is set to 1, without reweight.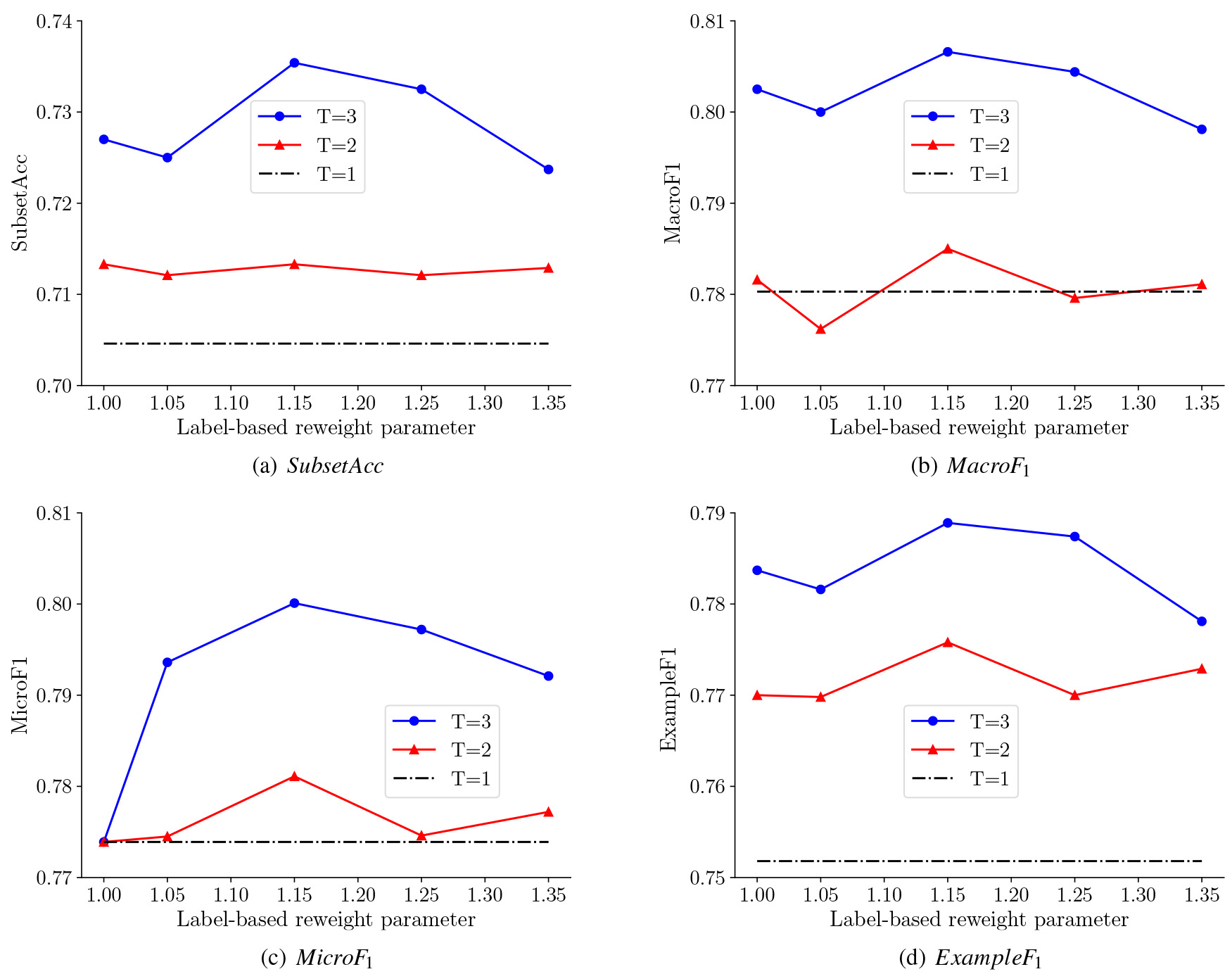
Complexity analysis
Table 6 shows the worst case computational complexity of LAMB and other transformation algorithms, in terms of the number of single-label models involved in the transformation, and the class labels and examples associated with these models. BR has linear complexity
where the second term dominates as long as
Complex objects, such as images, can be represented with multi-label information, where label relationship is very helpful for the final prediction. In this paper, we propose a novel high-order multi-label learning algorithm named Label collAboration based Multi-laBel learning (LAMB). For each label, LAMB algorithm combines its own label’s prediction and the prediction of other labels together as the final prediction, which makes each label collaborate with each other. Experimental studies on three public datasets validate the effectiveness of our proposed LAMB algorithm. Meanwhile, we assess one real-world channelrhodopsins chimeras dataset, which shows that LAMB can advance the prediction performance of eukaryotic expression and plasma membrane localization of channelrhodopsins. Furthermore, it provides new insights into understanding and designing membrane proteins. LAMB algorithm considers the global collaborative relationship between labels. However, different instances have different characteristics and such collaborative relationship may not be suitable for all the instances. In the future, we are supposed to explore different collaborative relationship between labels for different instances when there exists noise or missing labels in multi-label data.
Footnotes
Acknowledgments
This paper is supported by the National Key Research and Development Program of China (Grant No. 2018YFB1403400), the National Natural Science Foundation of China (Grant No. 61876080, Grant No. 62002137), the Key Research and Development Program of Jiangsu(Grant No. BE2019105), the Collaborative Innovation Center of Novel Software Technology and Industrialization at Nanjing University.