
Abstract
With the rapid development of technologies such as cloud computing, big data, and the Internet of Things, the scale of data continues to grow. The recommendation system has become one of the important intelligent software to help users make decisions. The recommendation model based on user rating data is widely studied and applied, but the data sparsity problem and the cold start problem seriously affect the recommendation quality. In this paper, Multi-view Hybrid Recommendation Model (MHRM) based on deep learning is proposed. First, we use WLDA (an improved Latent Dirichlet Allocation method) to extract the vector representation of user review text, and then apply LSTM to contextual semantic level user review sentiment analysis. At the same time, the emotion fusion method based on user score embedding is proposed. The problems such as deviations between the user score and actual interest preference, and unbalanced distribution of the score level are solved. This paper has been tested on Amazon product data and compared with various classic recommendation algorithms, using Mean Absolute Error (MAE), hit rate and standardized discount cumulative return for performance evaluation. The experimental results show that the prediction of the MHRM proposed in this paper on the 7 recommendation data and the TopN recommendation index have been significantly improved.
Introduction
The recommendation system has become one of the important intelligent software to help users make decisions. Currently popular recommendation methods are divided into collaborative filtering recommendation and content-based recommendation.
The recommendation algorithm based on collaborative filtering (CF) is to use the user’s historical scoring of the item and the interaction or preference between the user and the item to generate a recommendation list [31]. However, when the user interacts with the project very sparsely, the CF method is often affected by limited performance, which is very common in big data collection scenarios such as online shopping. In addition, the CF method cannot recommend some new projects because these projects have never received any feedback from users in the past and caused cold start problems. Subsequent research work found that due to the authenticity of item ratings, recommendation results based on user rating parameters cannot accurately reflect users’ interest preferences [12, 14].
The content-based recommendation can effectively solve the cold start problem in the recommendation system [2, 40], is not subject to user sparseness, and can find hidden information in the item, and has a good user experience. However, due to the limited amount of natural language description information of a single acquired item, semantic analysis is difficult, and a better recommendation effect cannot be achieved.
In short, the previous research has not fully utilized the potential of knowledge, and they are subject to the following restrictions:
the imbalance of user score distribution and the difficulty of integrating multiple recommendation views. The lack of natural language description of the item content makes the semantic analysis more complicated. User ratings and user reviews are biased and do not truly reflect user authenticity issues. The problem of the heavy and cumbersome user review text extraction features.
To address the above mentioned problems, a new recommendation framework is proposed in this paper, which combines user scoring matrix, user review text, item content information description and other multi-dimensional recommendation factors, and proposes a Multi-view Hybrid Recommendation Model (MHRM), different from the traditional collaborative filtering and content-based recommendation system, this paper designs a multi-view collaborative training recommendation algorithm based on user score, user review sentiment analysis and item content information feature extraction, which realizes user score and user review behaviors are integrated, and a recommendation system that combines user’s comprehensive scores with item content descriptions. The main contribution of this paper is to propose a new recommendation framework and use deep learning natural language processing technology to integrate auxiliary information such as user review text and item content description:
A multi-view hybrid recommendation model is proposed. A recommendation model based on a multi-view fusion of user scores, user review and item content description is designed. The sparseness of user scoring matrix is filled and corrected, the recommendation based on user score prediction is realized, and the problem of data sparsity and cold start is solved. A method based on user review sentiment analysis and user scores based fusion is proposed. An embedded network structure is intended to implement implement deep semantic mining of user reviews. The problem of deviation from user ratings and user reviews in the recommendation system and the uneven distribution of scores is solved. Using deep learning techniques, analyzed and studied the skill of natural language processing techniques for user review texts and project content descriptions. In this paper, the improved LDA and distributed paragraph vector representation technology respectively realizes the natural language processing of user review text and item content description and design the method of measuring the candidate object similarity computer.
The rest of this article is shown below. The related work is represented in Section 2. Section 3 details the sentiment analysis and comprehensive scoring model based on user review texts and the similarity calculation model based on item content. Section 4 discusses the results of the experiment, and Section 5 provides a brief review of the conclusions of this paper.
The traditional recommendation system is mainly divided into collaborative filtering recommender system, content-based recommender system and hybrid recommender system.
The collaborative filtering recommendation system was proposed by Su et al. [33] in the 1990s. Collaborative filtering uses the binary relationship between users and items to generate recommendation information by learning the interests and preferences of some user groups. The collaborative filtering recommendation system can be subdivided into user-based collaborative filtering methods, item-based collaborative filtering methods, and implicit feedback-based collaborative filtering methods. Among them, The user-based collaborative filtering method accomplishes the recommendation by calculating the similarity between users and finding the user with the most similar target users. The item-based collaborative filtering recommendation method is to complete the recommendation by the similarity between the items and the user’s rating of the item [21]. The real-time personalized recommendation based on the implicit user feedback data stream is to personalize the sensitivity of the user, transform the binary relationship between the user and the item into a scoring prediction problem, and collaboratively filter or sort the items by the user. Finally, a list of recommendations is generated [5, 11, 15, 36]. In the latent factor matrix decomposition model of the study, the SVD and SVD
The content-based recommendation method is to dig deep into the user’s product review information or product natural language description information, which is an end-to-end association method. The user review information can be used as a basis for collaborative filtering recommendation, and the content information is incorporated into the factor model for mixed recommendation [32, 41]. Based on the recommended method of reviews, deep integration of user review recommendation factors is realized by incorporating user-generated valuable review information into the user modeling and recommendation process. Among them, the factors related to comment recommendation include the content of the comment, the subject information of the comment, and emotional orientation, etc. [4, 35, 37]. Content-based recommendations can use deep neural networks to learn the underlying factors at all levels, helping users make better and faster decisions through deep learning of content [3, 4, 7, 35, 37, 42]. The content-based recommendation method mainly depends on user preferences and items, it does not require a large number of score records, and does not suffer from sparse score data, but is often difficult to extract information vectors.
Due to the shortcomings of the single recommendation method, mixed recommendation methods are proposed to produce a better recommendation effect. For the problem of data sparsity, researchers analyze the historical information of users and products, construct potential factor models and neighborhood models, establish connections between users and products, and use user explicit and implicit feedback to increase the accuracy of user recommendations. It is widely used in many systems due to its good performance [1, 6, 28, 34]. At present, multi-source heterogeneous data, fusion scoring matrix and review text based on deep fusion technology and multi-featured collaborative recommendation model have become the hotspots of new research [17, 25, 27].
Based on the above research, a Multi-view Hybrid Recommendation Model (MHRM) is proposed in this paper. MHRM solves the problem that user rating data, user review texts, and natural language descriptions of articles are not easily integrated. Different from traditional collaborative filtering and content-based recommendation system, this paper designs a multi-view collaborative training recommendation algorithm based on user score, user review sentiment analysis, and item content information feature extraction, which realizes the integration of user score and user review behavior. A recommendation system that combines a user’s comprehensive score and item content description.
Multi-view hybrid recommendation model
This section introduces a multi-view hybrid recommendation model based on deep learning. On the one hand, we use the improved LDA model to deeply mine the user review text, and use the opinion pre-filtering method [26] to achieve a comprehensive score of the user review and the original score. On the other hand, we perform deep data mining on the content description information of the item and use the paragraph vector to realize the distributed representation of the content description information of the item. Finally, the paper deeply integrates user ratings, user reviews, and article content descriptions, and adds confidence selection and cluster analysis data selection strategies in collaborative training to eliminate the data distribution bias added to the training data pool in iterative training. Based on the score matrix and content similarity calculation of the collaborative training model data, the initial recommendation results are filtered and sorted to obtain the final recommendation result. A multi-view hybrid recommendation model system framework based on deep learning is shown in Fig. 1.
System framework diagram of multi-view hybrid recommendation model based on deep learning.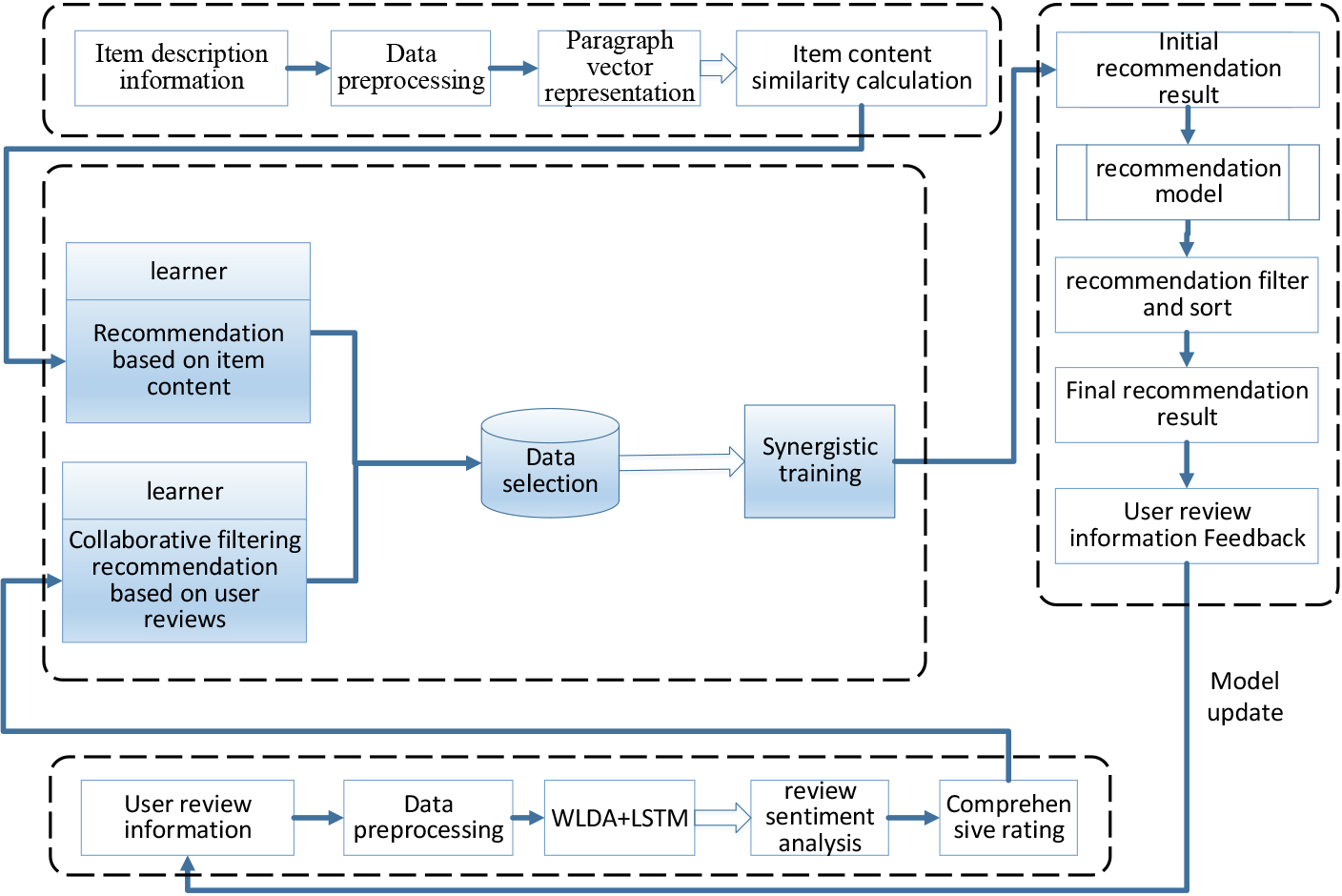
Vector representation of user review text
Through statistical analysis of the user review text, it is found that the user’s review text in the recommendation system is usually presented in the form of keywords and short text. The supervised emotional mining methods use the corpus to train and generate text sentiment classifiers with varying degrees, which generally have higher classification accuracy, but the expensive cost of acquiring training samples greatly limits the application of such methods. Therefore, unsupervised sentiment classification methods represented by JST [20], SLDA [19] and DPLDA [24] have been favored in recent years.
In order to solve the problem of traditional data sparse representation, we use a topic generation model based on an improved Latent Dirichlet Allocation (LDA). Namely WLDA. In addition, we have also improved the accuracy of keyword semantic representation by mining the associated attributes between words.
First, let’s introduce the LDA model. LDA is an unsupervised modeling model for natural language modeling. It can be used to identify hidden topic information in a large-scale document set or corpus, and can search for hidden topic distribution information in a document, as shown in Fig. 2.
LDA model structure.
Where
Where
Because the LDA topic generation model ignores the relationship between words in the document during the training process, and the word2vec model can effectively infer new terminology words, and can obtain more word vectors with similar meanings. If the training word vector is expanded in the word2vec model during the Gibbs sampling phase of the topic model, then more meaning can be used in the inference step of the LDA topic model. In view of this, we use the word2vec model to train on long text corpus of short text stitching to obtain the word embedding space v, and training word vectors carrying contextual information. The improved LDA is shown in Fig. 3.
WLDA model structure.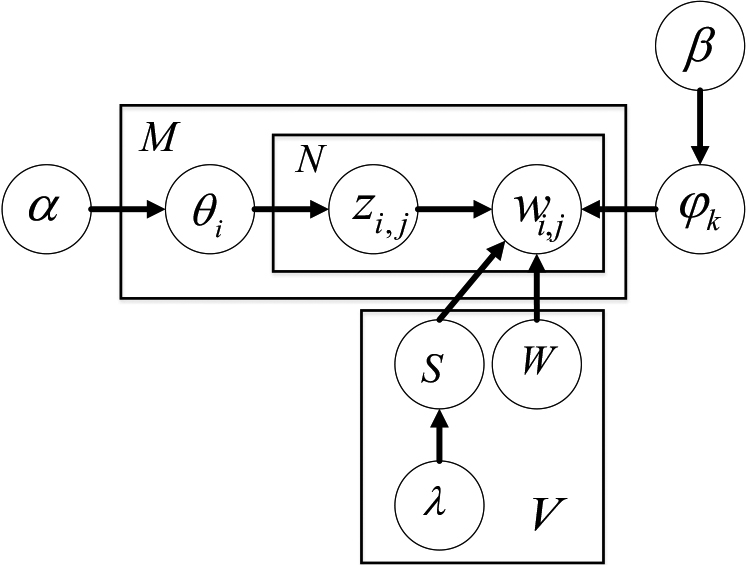
In the WLDA model, the preprocessed text is first input into the replacement word2vec model layer to obtain the trained word embedding space v. In the Gibbs sampling phase, the word
In the WLDA model, the joint probability distribution equation for all parameters is:
Among them, the first part
Where
Where
The analysis of each user’s review data by the WLDA topic generation model yields a representation of the topic vector and the high-frequency word vector.
After obtaining the K-dimensional real number vector representation of the keyword, we usually use the weighted average method to process the vector of the keyword. The vector of the keyword is equivalent to the vector representation of the user’s review text, so as to realize the sentiment analysis of the review information. The weighted average processing method ignores the ordering between words and does not have the ability of context “semantic analysis”, which in turn affects the prediction effect of the entire model. Therefore, this paper constructs a sentiment calculation model based on the WLDA topic vector and long-term and short-term memory network to realize the sentiment analysis of article reviews.
The most common method of text message processing is the Recurrent Neural Network (RNN). The RNN will produce a gradient disappearance when processing long sequences. To solve this problem, the researchers proposed a gated RNN, the most widely used of which is the LSTM. Studies have shown that neural networks using the LSTM structure perform better when processing text data than standard RNN networks.
The LSTM utilizes a “gate” structure to remove and add information to the cell state. The LSTM-based model can effectively avoid the gradient expansion or gradient disappearance of the RNN network structure by dynamically changing the accumulation of different moments while ensuring the parameters are unchanged. In the LSTM network structure, the calculation equation for each LSTM unit is as follows.
In Eqs (6)–(11),
An sentiment analysis method based on WLDA
In this paper, the sentiment analysis method based on WLDA and LSTM user reviews are shown in Fig. 4. First, WLDA is used to encode the input in matrix form into a lower-dimensional one-dimensional vector, while retaining most useful information; Then, LSTM is used to train the sentiment classification model of the user review text to predict the rating of the user review rating. In order to preserve the influence of user interaction information and the emotional interaction of the scores, this paper uses a based on opinion pre-filtering method and a method based on user score embedding to integrate user scores and sentiment prediction scores.
The opinion pre-filtering method uses WLDA and LSTM to model the user review text and then performs sentiment analysis to predict the emotional tendency score
Where
This paper combines the user’s scoring information with the LSTM output vector (Eq. (13)), and then uses the above result as the input of the last layer (all-connected layer), and directly outputs the final comprehensive sentiment score through the softmax activation function (Eq. (14)).
In the recommendation system, the introduction of the items is mostly described by a relatively regular natural language. This paper uses the paragraph vector [18] to distributed representation the short text information of the items description. The paragraph vector is a neural network-based implicit short text analysis model. The distributed representation of the item content paragraph vector is shown in Fig. 5.
A framework for learning paragraph vector.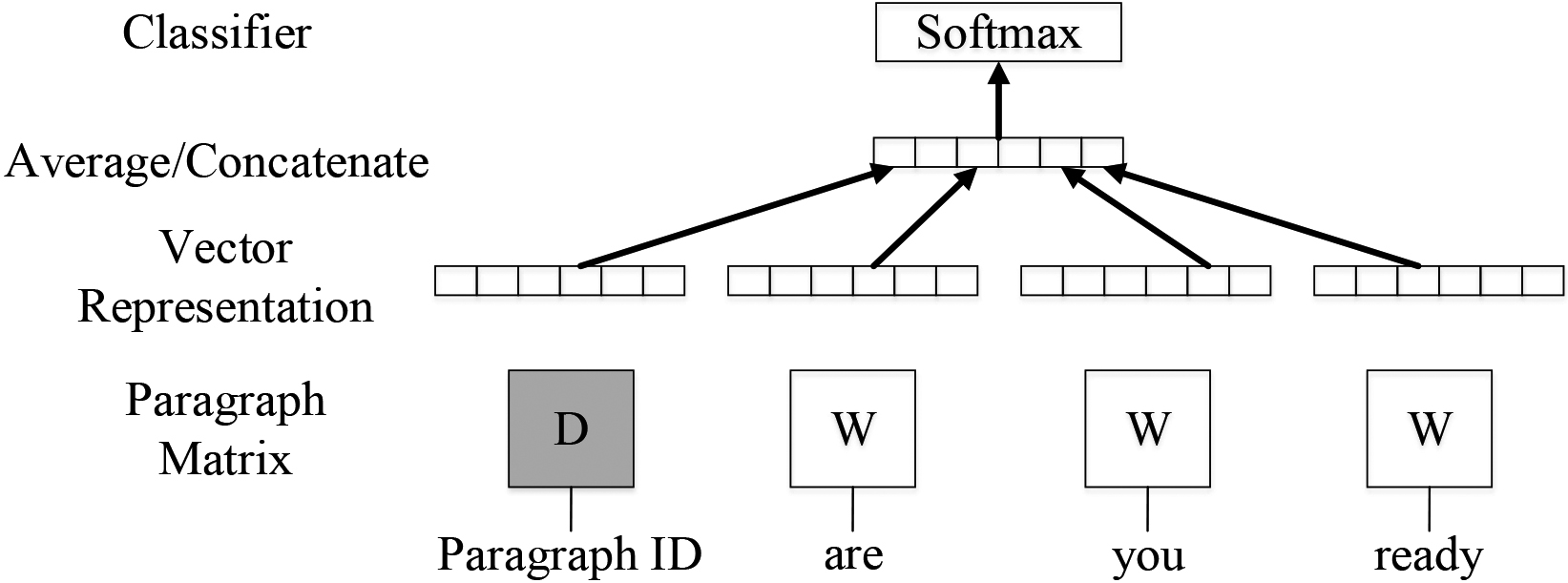
After obtaining the unique d-dimensional distributed vector representation of the item description content, this paper uses the similarity calculation method to obtain the similarity and distance between the two item contents. In this paper, the cosine equation is used to measure the similarity between two items, and the Tanimoto coefficient distance is used to calculate the distance of the natural language description of the two items. It is assumed that the paragraph vector of the natural language description of the two items is represented as;
When constructing a multi-view hybrid recommendation system based on deep learning, this paper constructs a user-based recommendation model by using the user comprehensive evaluation view; constructs a recommendation model based on the item content using the natural language description view of the item content; Finally, through the collaborative training model, the two views based on the user review comprehensive evaluation view and the item content-based recommendation view are fusion.
In terms of data selection, clustering and data selection algorithms based on learning vectorization are used for filtering. After filtering, unlabeled data is added to the training data pool of another classifier, and then the next round of training is performed.
Hybrid recommendation for multi-view collaborative training
The multi-view collaborative training-based hybrid recommendation algorithm firstly constructs an initial scoring matrix for the item; then, the pre-filtering method is used to update the scoring matrix. The loop filling and optimization scoring matrix are calculated according to the vector similarity of the comprehensive scoring matrix and the item content description, and the recommendation and sorting are implemented.
: Multi-view collaborative filtering recommendation algorithm
In MHRM, the rating of item i by the user u is recorded as
In algorithm 1, we populate the default value of the user’s scoring matrix with a collaborative scoring; and at the same time update the training dataset of the new user. In the sentiment classification model, this paper uses the level 2 sentiment classification to set the user’s emotions as positive and negative scores, corresponding to the scores of 5 points and 1 point respectively; then use the opinion pre-filtering method to synthesize the user’s emotional score and the original score.
: Item content description-based recommendationInput: User’s predicted score
Finally, the data selection algorithm based on confidence and cluster analysis is used to filter data, and the user-based collaborative filtering model is used to predict and fill the scoring matrix, and the added data is added to the training data set of user
In the item-based content description model, the Tanimoto coefficient algorithm is used to calculate the distance of the item content description, and the update and fill user ratings and default values are calculated by the cosine similarity and Tanimoto coefficient of the item and will be used for the recommendation model based on the item content, Then proceed to the next iteration. The recommendation algorithm description based on the item content description is as shown in algorithm 2.
The hybrid recommendation system applies a variety of recommended techniques to the recommendation system for a better-recommended effect. This paper first uses the comprehensive scoring training prediction model to achieve the filling and updating of the scoring matrix. Then, according to the updated scoring matrix and the item content description information. it is used as an input of the user-based collaborative filtering recommendation model, and the next iteration training is performed. In each iterative training, the method makes full use of the user’s evaluation of the project, the review information and the description information of the project content, thereby realizing the fusion of multiple recommended views and achieving a better recommendation effect.
Experiment
Basic data
We conduct experiments on the public data set Amazon [22], which covers 346867770 reviews, 6,643,669 users and 2,440,063 items. The dataset includes: item information, user information, item reviews, and other information. The user information includes a user name, a location, a user level. and the like; the item information includes information such as an item ID, an item title, an item price, and an item introduction; the review information includes a user ID, an item ID, a user name, a text review, an item rating, and timestamp and other information. Table 1 depicts the statistics of the dataset.
Amazon product data statistics table
Amazon product data statistics table
In the experiment of this paper, we use the accuracy and the Mean Absolute Error (MAE) to evaluate the recommendation method.
The MAE is defined as:
Where
Accuracy of sentiment classification model
Accuracy of sentiment classification model
Scoring prediction result of recommendation model
This article tests the performance of the sentiment classification model on Amazon product data. This paper selects 10000 user reviews in 7 data sets such as Automotive and Baby from the Amazon review dataset and marks each review text as positive and negative emotion tags for model training and testing. Among them, 5000 data of
In this paper, the Sk-Learn machine learning library is used to construct the classification model, and the classic SVM algorithm in Sk-Learn is selected as the classification algorithm. Setting the SVM kernel function to the polynomial kernel (SVC (
From Table 2, compared with the SVM algorithm, the accuracy of the emotional classification model trained by LSTM is improved by 8%. In the WLDA
Recommended prediction experiment
Comparative experiment
we selected six more classical algorithms in the experiments to verify the performance of MHRM. The six algorithms are ItemKNN [30], MF [16], DMF [39], HFT [23], NFC [9], IGAR [13], respectively.
Model’s score prediction
In the experiment of the recommended algorithm, we use the model’s predictive score and the real score of MAE as the evaluation indicators to measure the experimental results of various recommended algorithms. On the same data set, the classification is compared using the ItemKNN [30], the MF [16], the DMF [39], and the MHRM proposed in this paper.
Table 3 shows the experimental results of the proposed algorithm and the three classic algorithms of ItemKNN algorithm, MF algorithm and DMF algorithm on Amazon product data. From the experimental results, the MHRM proposed in this paper is superior to the other three classical recommendation algorithms in the MAE evaluation index.
Through experimental comparison, it is found that the MHRM algorithm proposed in this paper has improved in the seven experimental data sets in Amazon product data. Analytical calculations show that on the Automotive, Beauty, Electronics, Home and Kitchen datasets, the MHRM algorithm improved by 7.82%, 11.24%, 9.19%, and 11.94%, respectively, compared to the best algorithm (ItemKNN); The item has a lot of user review information, and the introduction of implicit parameters in the model can effectively reduce the mean square error of the system score. Compared with the best algorithm DMF in the Kindle store, Office products, Sports and Outdoors data sets, the increase of 2.24%, 11.99%, and 8.93%, respectively. Studies have shown that incorporating user review information into the item-based content recommendation view can ameliorate the recommendation performance.
Through the above analysis, the MHRM proposed in this paper has a significant improvement in the MAE evaluation index than the traditional algorithm. It also shows that the prediction accuracy of the recommendation model has a great relationship with the real user’s score and the accuracy of the user’s reviews. The use of opinion pre-filtering methods and the fusion of virtual scores to obtain a user’s comprehensive score can effectively improve the accuracy of predicting user ratings. in addition, in the face of the user’s cold start problem, the text proposed MHRM algorithm combines the collaborative filtering recommendation of the item with the recommendation based on the item description content. The recommendation factor incorporates the sentiment analysis of user reviews and the semantic analysis of natural language based on the description of the content of the item. This auxiliary information helps to solve the cold start problem of the recommendation system to a certain extent.
The influence of the parameter balance factor in the recommended prediction
An important parameter is introduced in MHRM. Its main function is to balance the virtual score of the original user score and the sentiment analysis of the user review. In the equation
Different 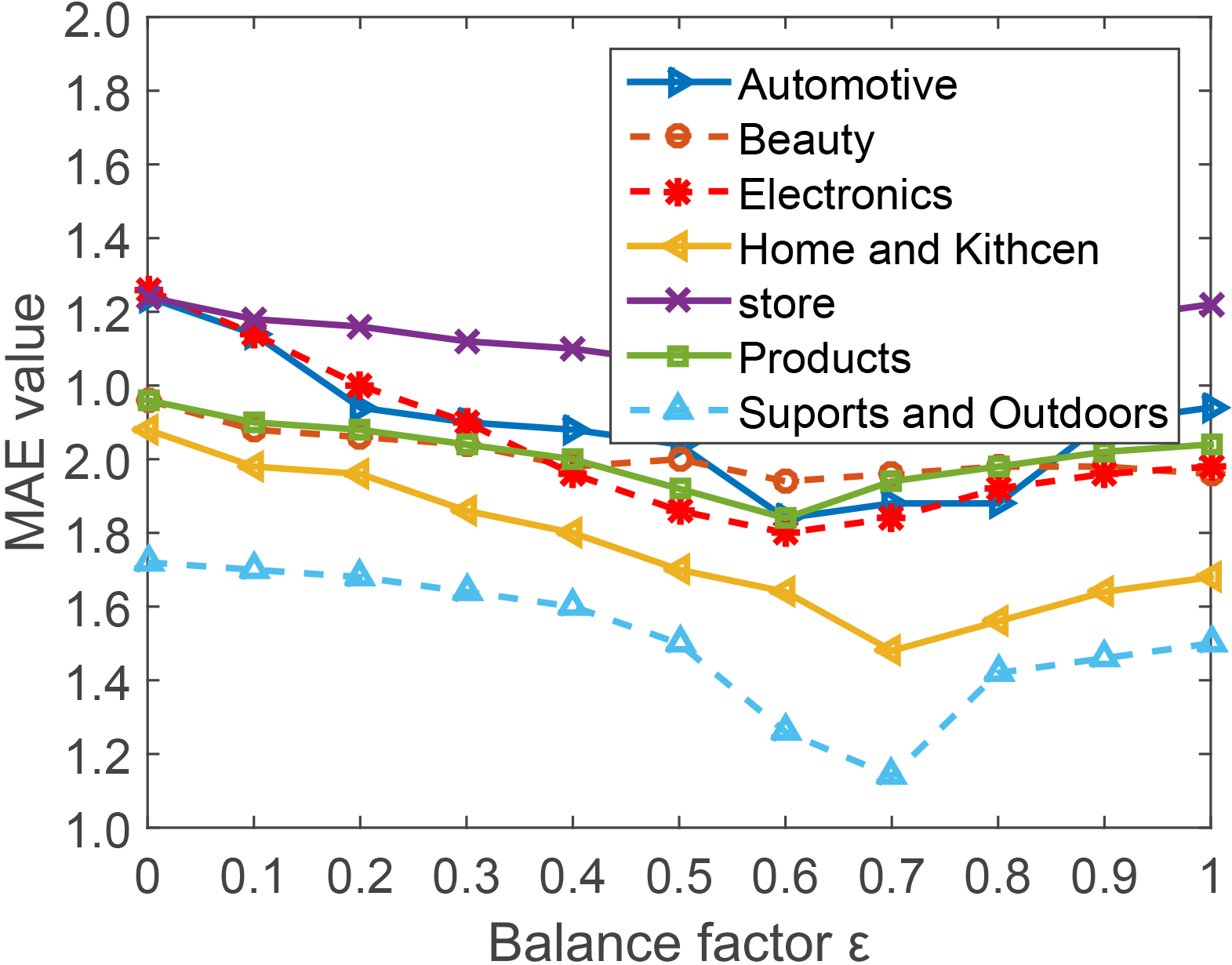
From Fig. 6, we can conclude that, in
Besides, Hit Radio (HR) [8] and Normalized Discounted Cumulative Gain (NDCG) [9] were used to evaluate the performance of the MHRM model.
Among them, Candidate test set represents the number of candidate test sets, and Top-N test set indicates the first N items recommended to the user in the test set.
where the molecular
In the TopN recommendation of the experiment, 100 users who did not participate in the scoring and the most similar items that the user liked were selected as candidate items. In the first three recommendation algorithms and the MHRM algorithm, the user’s
Comparison experiment of different recommendation algorithms in HR-N and NDCG-N (N represents TopN)
Table 4 shows the best experimental results recommended by TopN in different recommendation algorithms. The MHRM has achieved good performance on HR-N evaluation indicators. Compared with the current popular deep learning DMF, NCF, IGAR algorithm, because the algorithm proposed in this paper adds user-based information and introduces the description of the item content in collaborative training, it effectively overcomes the cold start problem of the recommendation system.
In Table 4, the MHCM, IGAR, and NFC algorithms have achieved good results on the NDCG-N evaluation index. IGAR and NFC algorithms use deep neural networks to construct interactions between users and items, and show strong performance in learning user and item potential factors. In this paper, when the user’s comprehensive rating of the item is calculated by the opinion pre-filtering method, the time dimension of the user review is added. The weighting factor is controlled according to the distance of the time dimension. The closer the time is, the larger the weight value is, and the longer the time is, the smaller the weight value is. In the TopN recommendation sorting, the timeliness of the recommended items is also fully considered. Experiments have shown that considering the addition of the time dimension has an important impact on the recommendation results of the item.
A multi-view hybrid recommendation model is proposed in this paper, which combines user reviews, user ratings, and item content descriptions to address the problems of sparseness, cold start, and insufficient recommendation factors for the recommendation model of a single view. Through the comparison experiment of the Amazon product data real data set, the surface-based sentiment analysis based on the user’s review and the user’s original score weighted comprehensive score effectively eliminate the problem of uneven score level. In terms of recommendation effect, we compare it with the ItemKNN algorithm, MF algorithm, and DMF algorithm. The results show that the proposed algorithm has a significant improvement in MAE. Our next work plan collects and organizes the recommended system dataset from the Internet e-commerce website, further evaluates, improves, and adjusts the recommended algorithms, continuously improving the accuracy and recall rate of recommendations, and improving recommendation performance.
Footnotes
Acknowledgments
The work was supported by the 2021 Autonomous Region Innovation Environment (Talents, Bases) Construction Special-Natural Science Program (Natural Science Foundation) Joint Fund Project (2021D01C004) and the 2019 Xinjiang Uygur Autonomous Region Higher Education Scientific Research Project (XJEDU2019Y057, XJEDU2019Y049).