
Abstract
Class imbalance of medical records is a critical challenge for disease classification in intelligent diagnosis. Existing machine learning algorithms usually assign equal weights to all classes, which may reduce classification accuracy of imbalanced records. In this paper, a new Imbalance Lessened Boosting (IMLBoost) algorithm is proposed to better classify imbalanced medical records, highlighting the contribution of samples in minor classes as well as hard and boundary samples. A tailored Cost-Fitting Loss (CFL) function is proposed to assign befitting costs to these critical samples. The first and second derivations of the CFL are then derived and embedded into the classical XGBoost framework. In addition, some feature analysis skills are utilized to further improve performance of the IMLBoost, which also can speed up the model training. Experimental results on five UCI imbalanced medical datasets have demonstrated the effectiveness of the proposed algorithm. Compared with other existing classification methods, IMLBoost has improved the classification performance in terms of F1-score, G-mean and AUC.
Introduction
The automatic classification of diseases based on heterogeneous medical records is an important research topic in intelligent diagnosis. Existing studys often apply Machine Learning (ML) methods to construct disease classification models with collected medical records as training data [1, 2, 3], and the common used ML models for classification include k-nearest neighbor, decision tree, support vector machine, naive bayes classifier, neural network, ensemble learning, and so on [4, 5, 6, 7, 8, 9]. Among these models, ensemble learning models have been demonstrated to have better performance on classifying medical records than other models with single classifier [10, 11]. As one of the most representative ensemble learning methods, boosting algorithm has achieved remarkable success on many classification and prediction problems. It has many implementations, such as Adaboost [12], XGBoost [13], LightGBM [14], CatBoost [15], and so on. Considering performance, affordable time and memory complexity of these models, XGBoost has become the first choice in related studies and competitions.
However, there is a common challenge in classification of real-life medical records: class imbalance. It is a phenomenon where samples in some classes (minor classes) are significantly less than samples in other classes (major classes). For example, in prevalent pneumonia, the number of negative and positive samples is very different, and for positive samples, various pneumonia subtypes are also imbalanced. The imbalance of disease samples often leads to bad classification results of ML models. Most of them assume that data samples in all classes are balanced [4, 5, 6, 7]. Hence, when dealing with imbalanced records, ML models often pay attention to the accuracy of major classes, and perform poorly on minor classes. However, the minor classes are usually of more interest and the errors coming from them are more important in medical diagnosis. For instance, if cancer patients (belonging to minor class) are diagnosed as healthy, they will miss the best time for treatment, which may be fatal. For this reason, traditional machine learning models cannot perform well on classification of unbalanced medical data. Even the XGBoost is applied, the performance is brittle when it comes to the class-imbalanced datasets [16, 17, 18, 19], due to the equal weight assignment to each class. Therefore, it is meaningful to develop an effective method to deal with the problem of class imbalance in learning based intelligent diagnosis.
Many efforts have been done to solve the imbalance learning problem. Current strategies for classification of imbalanced data can be divided into two types: data-level methods and algorithm-level methods. The data-level approaches usually use various sampling (over-sampling or under-sampling) techniques to eliminate class imbalance [20, 21, 22, 23, 24, 25]. But sampling methods have obvious disadvantages. On the one hand, over-sampling may introduce duplicated samples, which slows down the training process and makes the model susceptible to over-fitting. On the other hand, under-sampling may discard valuable samples that are important for training models. Due to these disadvantages of sampling, most of present works focus on algorithm-level approaches [26]. The main purpose of algorithm-level approaches is that models can assign different costs to different classes. And for this purpose, many researches [27, 28, 29, 30] have been devoted to designing class-imbalanced loss functions. They advocated that the cost of misclassified samples in minor classes is higher than that of major classes, thus the loss caused by samples in minor classes should be treated emphatically.
There are also two other important issues that should be considered in data classification: one is the classification difficulty of samples, and the other one is effect of boundary samples. Generally, not all samples in the dataset are useful for classification, and a good class-imbalanced loss function usually gives higher weights to loss caused by important samples rather than treating each sample equally. For example, studies [27, 28, 29] considered quantity differences of classes when dealing with imbalanced data and they assigned high weights to minor classes. However, the classification difficulty difference of samples was always ignored until the well-known focal loss [31] was proposed. Samples are difficult to be classified (e.g. with high classification errors) are called hard samples, otherwise called as easy samples. Focal loss function assigns a relatively high cost to samples in minor classes and hard samples. Recently, some studies have attempted to apply focal loss to classification models, but the effect is not satisfactory [26, 32, 33, 34, 35]. There is also a general defect in these studies, where the importance of boundary samples are not considered. In fact, boundary samples have important contributions to the classification performance due to their strong distinguishing ability of classes. If boundary samples in one class are misclassified to other classes, this may lead to blurred classification boundary. Hence, boundary samples should be assigned larger weights than samples within classes. Besides, some models [17, 21, 23, 36] are designed only for binary classification problems. As to multi-class data classification, it can be regarded as multiple binary classification tasks. Using this dismantling strategy, some methods [22, 24, 25, 27] have been applied to multiclass data.
Based on the above discussion, a novel IMbalance Lessened Boosting(IMLBoost) algorithm is proposed in this work to better classify imbalanced medical records for disease diagnosis. It integrates a tailored Cost-Fitting Loss (CFL) function with an innovative boosting framework. The major contributions of this paper can be summarized as follows:
The boosting framework adopts additive training to improve performance of individual classification trees, in which the first and second derivation of the CFL function is derived to enable the optimization of the training procedure. The tailored CFL function can assign befitting costs to different samples, taking the influence of minor samples, hard samples and boundary samples into account. It is composed of two items: extended focal loss and smoothed hinge loss. Specifically, extended-focal loss is designed for handling minor classes and hard samples, which can highlight the contribution of minor classes while automatically enhance the contribution of hard samples by focusing factors. Smoothed-hinge loss is proposed to adjust the effect of boundary samples, which is insensitive to interior samples under a boundary threshold. Some data preprocessing skills, feature engineering and parameter optimization are used to further improve boosting performance.
The remainder of this paper is organized as below. Section 2 gives a brief summary of related works. Section 3 shows the theory of the proposed model. In Section 4, experiments and results are shown to verify the effectiveness of the model. Finally, conclusions are given in Section 5.
In the past few years, machine learning methods have been widely used for automatic classification of diseases [4, 5, 6, 7], but the imbalance of medical data brings huge challenges to the practical implement of these methods. Since boosting algorithm is simple and effective, many scholars choose it to deal with the classification of imbalanced datasets. And there has been significant interest in embedding some novel ideas into boosting algorithms. Typical works can be mainly divided into two types: data-level approaches and algorithm-level approaches.
Data level approaches. The data-level approaches eliminate data imbalance by resampling. The resampling techniques either remove samples from major classes or add samples to minor classes. ‘Sampling Algorithm level approaches. The algorithm-level approaches mainly modify existing boosting algorithms to handle imbalanced data. Most of these algorithms adjust loss functions to assign high costs to samples from minor classes. The objective of these loss functions should not just maximize classification accuracy, but also pay more attention to minor classes, because high accuracy can be achieved as long as samples in major classes are correctly classified. Inspired by this, Fan et al. [27] proposed AdaCost, where weight increasement for misclassified samples in minor classes is larger than that for major classes. Subsequently, three other versions (AdaC1, AdaC2 and AdaC3) [28] were produced, and all of them attempted to adjust the weights and AdaBoost confidence parameters to improve accuracy of minor classes. Mahesh et al. [29] proposed RareBoost, which updates weights of different classes in different ways, more specifically, the prediction weights of positive and negative samples are updated according to TP/FP(True Positive/False Positive) and TN/FN(True Negative/False Negative) respectively. Wang et al. [30] proposed NIBoost, which also updates weights according to the predicted labels and error rate.
Besides solutions to the data quantity imbalance problem, other works also studied sample classification difficulty problem, which is also common in medical data analysis. These studies [31, 38, 39] assign higher costs to hard samples compared to easy samples, but this may cause classifiers to focus on harmful samples (e.g. noisy data or mislabeled data) [34]. It is feasible to combine several loss functions for different emphasis samples to reduce the influence of harmful samples. In [17], Wang et al. applied weighted cross-entropy and focal loss on XGBoost for the imbalanced classification, and it turns out to be better than just using focal loss. Except for allocation of costs, studies at algorithm level can also deal with the imbalance by ensemble learning itself, because it can take advantage of all weak learners while avoiding limitations of single classifiers. For example, Farshid et al. [21] proposed MEBoost, which mixes the decision tree and extra trees with boosting, and results show that it is a promising technique to handle imbalance problem, but it is implemented only for two-class data.
In addition to these aforementioned methods, many other techniques of imbalance learning have been developed, such as transferring learning, metric learning, meta learning/domain adaptation, decoupling representation&classifier and so on. The transferring learning [40, 41] can transfer the knowledge learned from major classes to minor classes so as to improve accuracy of minor classes. The metric learning can calculate the similarity of samples to reduce the distance between similar classes and increase the distance between different classes, then the classification boundary is more clear [42, 43], which can improve the accuracy of all classes. The meta learning/domain adaptation can process samples of major classes and minor classes in different ways, and learn how to reweight adaptively [44, 45]. The decoupling representation&classifier divides the process of learning into two steps, normal sampling in feature learning stage and balanced sampling in classifier learning stage, which can lead to better model learning results [46, 47]. However, these techniques are often attached with deep neural networks, but medical datasets are usually too small to train neural network models. From the feasibility of implementation, this work focuses on the algorithm-level improvement of boosting models.
Generally, the number of medical records for different disease types is rather imbalanced, and traditional machine learning methods usually have low accuracy for minor classes. To solve the problem, we propose the IMLBoost model, which involves a boosting classification framework with a novel class-imbalanced loss function. The boosting framework can perform better than other single classifiers on imbalance data classification. The loss function can improve the classification accuracy of minor classes, while hard samples and boundary samples are also considered to improve the performance.
The boosting framework for classification
For the classification of imbalanced medical data, traditional machine learning algorithms usually can not get satisfied performance, where samples in minor classes are easy to be misclassified. Ensemble learning methods use a set of independently trained classifiers to deal with this problem, which improve adaptability and robustness of base classifiers, and perform better than individual classifiers. Therefore, an effective ensemble learning algorithm XGBoost is chosen as the base classification framework. It is a gradient boosting ensemble model based on CART regression tree [13]. It is trained in an additive manner, adding a tree to fit residual of previous prediction in each iteration. The objective function of XGBoost at the
where
Thanks for the Taylor’s theorem, second-order approximation can be applied to optimize the objective function. As following, the first and second order gradient statistics of the loss function are defined as:
Then the objective is approximated as:
In this equation, the constant term can be removed to obtain the simplified objective Eq. (4) at the
Based on above analysis, the classification performance of XGBoost is indeed better than individual decision trees, but it uses overall accuracy as the optimization goal, assigning same weights to different classes, so its effectiveness on the classification of minor classes is limited.
Although ensemble learning is superior to single models in the classification of imbalanced data, it still assigns same importance to different classes. If a reasonable class-imbalanced loss function is defined and the function is second-order differentiable, then it can be introduced into the framework mentioned above. In other words, the performance of the XGBoost model for imbalanced records can be improved by embedding a class-imbalanced loss function.
Hence it is necessary to design a loss function to assign different weights to samples in different classes. Normally, there is a huge difference between the sample numbers of major and minor classes, which makes loss caused by major classes account for large proportion, and the adjustment of weights for major classes is dominant. Secondly, a dataset usually includes easy samples and hard samples. Similarly, easy samples usually dominate the gradient updating direction of loss functions, which results in invalid learning. In addition, samples on the boundary are more important than those within classes.
In order to solve aforementioned problems, a novel cost-fitting loss (CFL) function is designed to pay more attention to samples in minor classes, hard samples and boundary samples in the training stage. The CFL is defined as:
This function is composed of two terms. The first one (noted as ‘
The loss term
where
then the Eq. (6) can be rewritten:
Therefore, the
Then sigmoid function is selected as activation for two-class datasets, that is
Taking the sigmoid into consideration, the first and second order derivatives of
Finally, with the first order derivative in Eq. (12) and the second order derivative in Eq. (13),
Considering that
where
However, it’s obviously impossible to get second-order derivative of such a piece-wise function. Hence, a smoothed loss function
Its first and second order derivatives are then computed. They are denoted as:
By combining the first and second order derivatives of
In summary, a novel IMLBoost algorithm is proposed in this work to deal with the data imbalance problem in intelligent diagnosis, which embedding the designed CFL function into the boosting framework. The proposed CFL function includes two terms:
The diagram of the proposed model is shown in Fig. 1. The IMLBoost algorithm includes two mainly stages: train and predict. The objective (‘obj’) of the training stage involves the embedding of the CFL function. The second stage offers the prediction of samples.
The framework of the IMLBoost.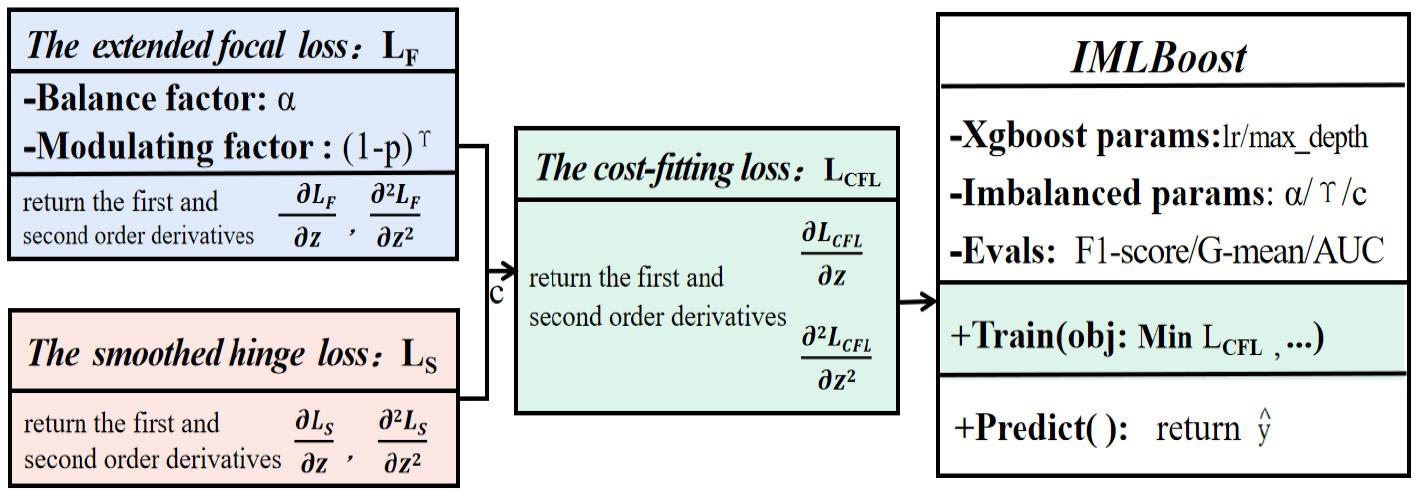
In this section, five imbalanced medical datasets are used to evaluate the performance based on three evaluation metrics. Some techniques including feature selection for high-dimensional datasets and parameter tuning are used to improve the performance of models. The proposed IMLBoost model is compared with other machine learning methods and class-imbalanced methods to verify its superiority.
Datasets and metrics
Datasets
In order to verify that the IMLBoost model has high applicability to the problem of imbalance, five datasets from UCI database [50, 51, 52] are chosen: Diabetes, Column, Heart failure, Arrhythmia, and Hypothyroidism. They all have imbalanced target labels and their associated task is classification. In addition, some of them contain missing values. Table 1 shows the characteristics of these datasets, where ‘samples’ is the number of samples, ‘classes’ is the number of targets, ‘features’ is the number of attributes and ‘imbalance ratio’ is a ratio between the maximum and minimum number of samples among all classes. The larger imbalance ratio is, the more imbalanced dataset is.
Datasets for experiment
Datasets for experiment
A detailed description of two datasets is present: the low-dimensional Heart failure dataset and the high-dimensional Arrhythmia dataset. The former dataset contains 299 patients records collected during the follow-up period. Each patient file has 12 clinical features, including 5 category attributes(sex, anaemia, smoking, high_blood_pressure and diabetes) and 7 continuous attributes(e.g.age, ejection_fraction and serum_sodium). Its target is death or survival. The latter one is divided into 16 classes. It has a total of 452 samples and each sample contains 279 attributes, 206 of which are continuous attributes and the rest are category attributes. They are expressed as ordinal numbers X1, X2,
The indicator is very important for measuring the performance of models on imbalanced data [53]. Three measures are used to assess the classification performance in this work: F1-score, Geometric-mean(G-mean) [54], and the Area Under ROC curve(AUC) [55], which have been widely used in imbalanced classification. According to the confusion matrix, TP (FP) is the number of positive (negative) samples classified correctly, and FN (TN) is the number of positive (negative) samples classified wrongly. These three metrics are computed as follows:
here precision
Experimental design
These medical datasets may have some problems such as missing values and outliers. Therefore, some preprocessing work is performed before training models, such as missing values filling, standardization of continuous attributes and so on. Then models are trained and tested with proper parameter settings. All experiments randomly select 80% of data for training and the remaining 20% for testing. To better illustrate the validity of our proposed model, two groups of comparative experiments are conducted. Firstly, the proposed method is compared with 3 machine learning classification models. Secondly, it is compared with other 4 anti-imbalance boosting methods.
Data preprocessing and feature analysis
Exploratory data analysis. (a) (c) (e) represent the class distribution, categorical attribute and continuous attribute analysis of the Heart failure dataset; (b) (d) (f) accord to the Arrhythmia dataset.
It is important to preprocess these datasets because the quality of data may greatly affect the classification ability of models. As we all know, noise and missing values often exist in the data in the real world, and models are sensitive to them. On the one hand, models behave badly with increasement of missing values. In general, linear models are sensitive to missing values. The proposed model is based on the tree, in which the missing values are not considered when the nodes are split [13], then it is not sensitive to missing values. On the other hand, the noise data interferes with the learning of models. The proposed boosting framework we used adds modification parameters in pruning to tolerate noise. Therefore, the proposed model also can mitigate the impact of noise to a certain extent.
The preprocessing work includes missing values filling, dummy variable processing, standardization of continuous attributes and so on. More specifically, the targets are label encoded. The missing values of categorical variables are filled with mode values and the missing values of continuous variables are filled with mean values. The min-max method is used to standardize continuous attributes. Then descriptive statistics and data visualization of the Heart failure and the Arrhythmia dataset are presented in Fig. 2.
Heat map of correlation analysis for the Arrhythmia dataset.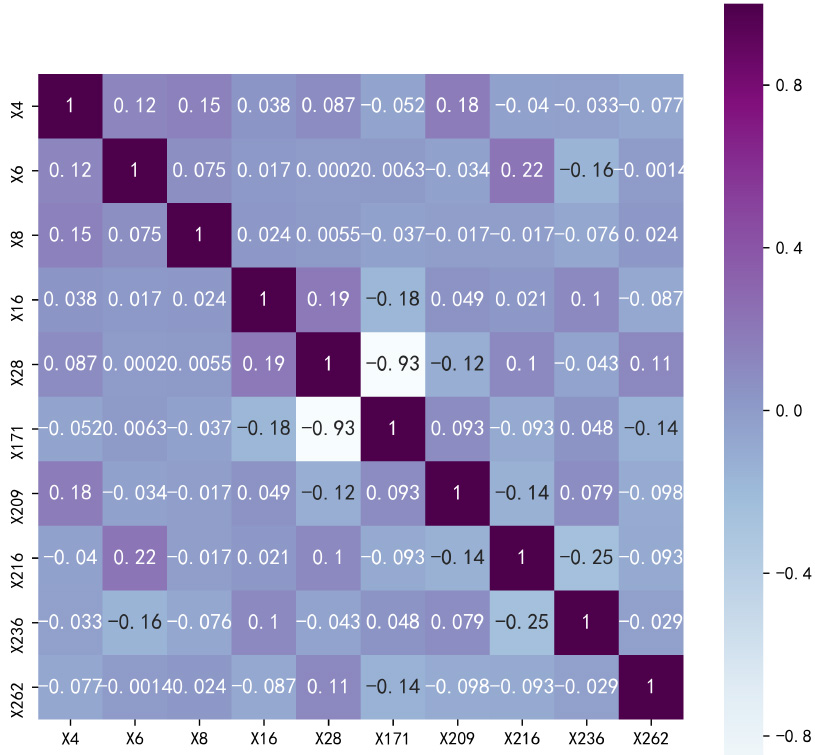
In the exploratory data analysis, the number of samples in all classes are shown in Fig. 2(a) and (b). It is clear from the pie charts that data labels are imbalanced. Next the histograms in Fig. 2(c) and (d) are used to show the relationship between category attributes and labels. Taking the attributes ‘existence of derivation of R’ and ‘sex’ in Fig. 2(d) as examples, it can be seen that if the ‘existence of derivation of R’
In addition to the univariate analysis above, correlation analysis is conducted to fully demonstrate the relationship between features. Generally, it is used to measure the linear relationship between two features and reveal the closeness between two features. If two variables change in the same direction, they are positively correlated. Conversely, if two variables change in opposite direction, they are negatively correlated. The correlation matrix of the Arrhythmia dataset is shown in Fig. 3. It can be observed there is a light color between X28 and X171, which shows that the correlation relationship between them is strong. That features have strong correlation relationship means that there are redundancy in dataset, so feature selection in next section is necessary.
It is vital to select meaningful features to train models. Irrelevant and redundant features are not useful for classification, and may even bring bad influence on the performance. For example, patients’ names do not contribute to disease diagnosis at all, but they increase the complexity of learning process and affect learning performance. This is especially obvious for the high-dimensional datasets, which make the work of feature selection essential. Generally speaking, feature selection can be divided into three types: wrappers, filters, and embedded methods [56]. Wrappers methods select feature subsets according to their evaluation power, in which feature selection and models training affect each other; filters methods select subsets as a preprocessing step, independently of the models training; embedded methods perform feature selection in the process of training and are usually specific to given learners, in which some machine learning models are trained at first, then the importance of features are obtained and the subsets can be selected according to the importance.
The IMLBoost model adopts embedded method to select features and it is used for the high-dimensional Arrhythmia dataset. In the beginning, all the data are input into the IMLBoost for training, and the importance of some features is shown in Fig. 4. It can be found that f14 is the most dominant factor, and it represents heart rate (number of heartbeats per minute), which is highly consistent with the real life. Then we conduct experiments on this dataset of top-
The importance of features in IMLBoost.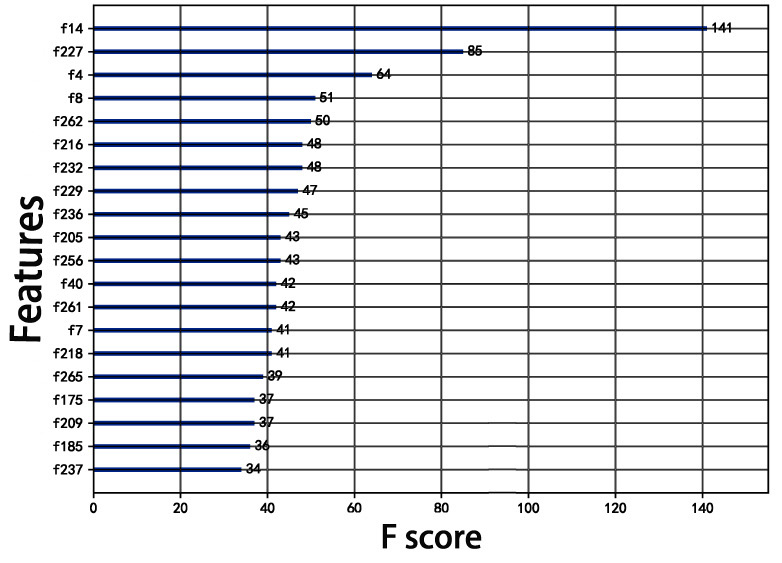
ROC curve with different numbers of features.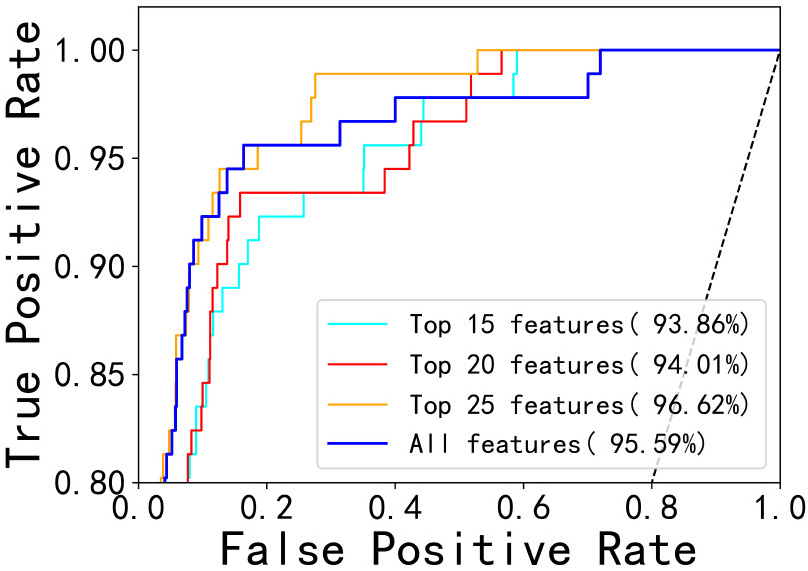
Results of IMLBoost on the Arrhythmia dataset with respect to (a) learning_rate (b) max_depth (c) 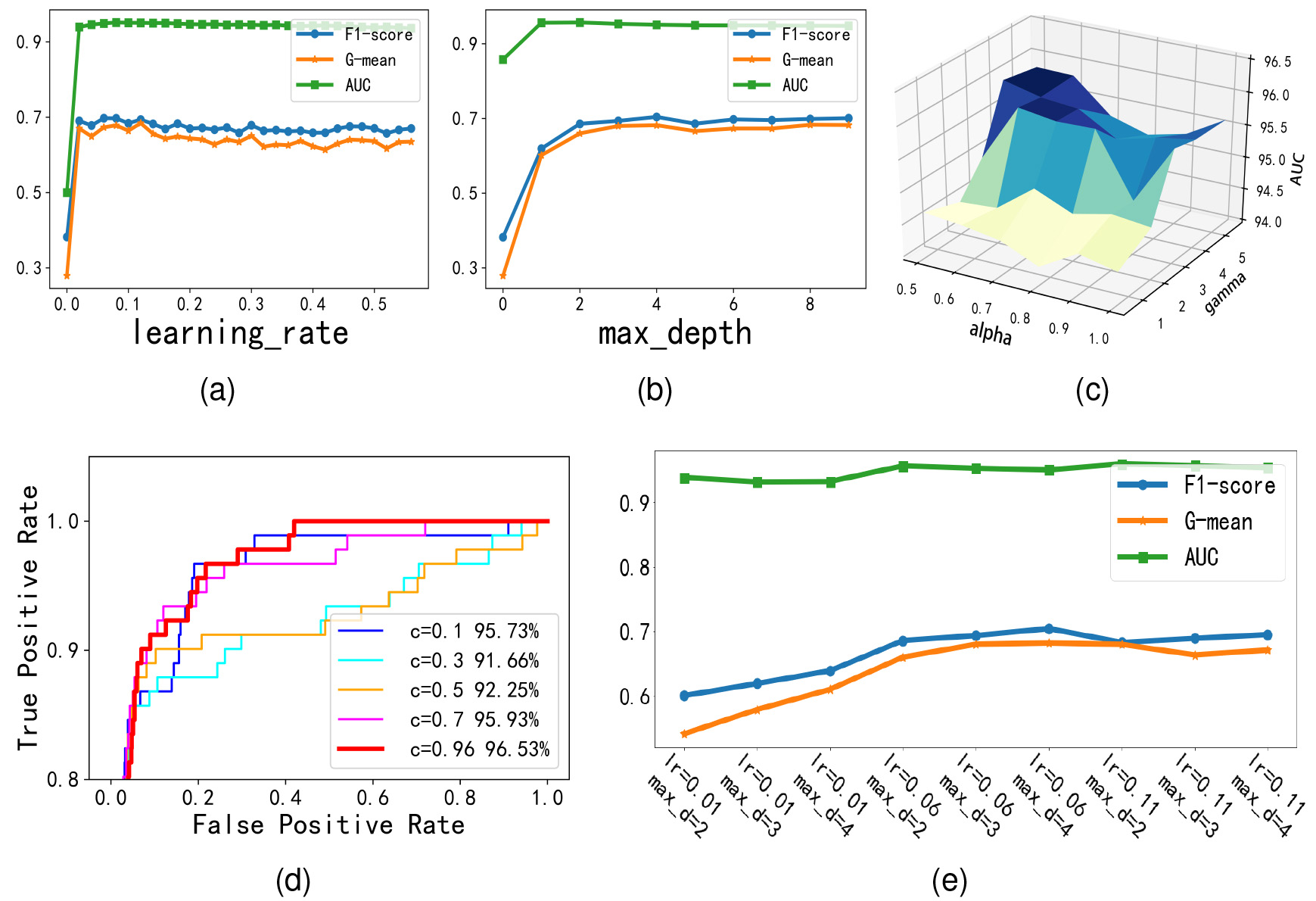
In this section, some parameters in the proposed model are fine-tuned. IMLBoost model is constructed based on the optimization of five parameters, including learning_rate, max_depth, alpha, gamma and weight c. Other parameters are set as default and fourfold cross validation strategy is used in experiments.
Experiment results on datasets(%)
Experiment results on datasets(%)
ROC curve of experiments. (a) (c) represent ML models and class-imbalanced methods on the Arrhythmia dataset; (b) (d) are results of the Heart failure dataset.
Based on the Arrhythmia dataset, some important parameters used in the experiments are described. The number of iterations is set to 50 and the min_child_weight is directly set to 2. The learning_rate and max_depth of IMLBoost are optimized as Fig. 6(a,b,e). They are divided in a certain range, where the range of learning_rate is [0, 0.6] with step 0.02 and the range of max_depth is [2, 10] with step 1. From the results in figure, the best performance can be obtained when learning_rate
In order to demonstrate the validation of the IMLBoost, comparative experiments are organized in two aspects. Firstly, the method is compared with other machine learning classification methods, such as decision tree, SVM and XGBoost. Secondly, the IMLBoost is compared with other existing anti-imbalance methods, such as SMOTEBoost, RUSBoost, AdaCost, MEBoost and Imbalance-XGBoost. Additionally, we also test the LFBoost(
The experiment results of these methods on the Heart failure and the Arrhythmia dataset are presented in Fig. 7, it is clear that the IMLBoost model has a higher AUC than other methods, which proves its effectiveness. Further, the classification results of these methods on all datasets are shown in Table 2, which shows F1-score, G-mean and AUC of each dataset and the averages on the five datasets. Considering that the MEBoost does not apply to multiclass datasets, it is not compared with other methods on the whole. From the table, it can be seen that the IMLBoost yields the best average rank in terms of all metrics. For the evaluation metric F1-score, our method is 0.5% higher than the second-best method; For G-mean, our method is 0.7% higher than the second-ranked method; For AUC, our method is 1.6% higher than the second place. In a word, all experimental results on these datasets confirm the effectiveness of the IMLBoost model.
Conclusions
In this paper, a new classification model IMLBoost for imbalanced medical records is proposed, which import the cost-fitting loss (CFL) function into a boosting framework. This CFL function leverages cost assignment to samples in minor classes as well as hard samples and boundary samples. The classification accuracy of those samples is largely improved. Owing to the first and second derivations of the CFL function, the boosting framework can be implemented in an optimized manner. Moreover, some machine learning skills (feature selection and parameter tuning) can further improve the performance of the IMLBoost. The experimental results on five imbalanced medical datasets indicated that the proposed model significantly performed better than other methods on F1-score, G-mean and AUC. The proposed IMLBoost can be extended for classification of more imbalanced datasets.
Footnotes
Acknowledgments
This work was supported by the Key Research Development program of Shandong Province [Grant 2019GGX101021] and the Taishan Scholars Program of Shandong Province [Grant NO.ts20190985].