
Abstract
Intelligent data analysis rapidly transforms healthcare care by improving patient care and predicting health outcomes through machine learning (ML) techniques. These advanced analytical methods allow intelligent healthcare systems to process large amounts of health data, improving diagnosis, treatment, and patient monitoring. The success of these systems is highly dependent on the quality and balance of the data they analyze. Class imbalance, a situation where certain classes dominate the dataset, can significantly affect the accuracy and effectiveness of ML models. In healthcare, it is not only crucial, but urgent, to accurately represent all conditions, including rare diseases, to ensure proper diagnosis and treatment. For this analysis, data was gathered from six reputable academic databases: ScienceDirect, IEEE Xplore, Scopus, Web of Science, Google Scholar, and PubMed. This review offers a comprehensive overview of current approaches to handling class imbalance, including data preprocessing methods like oversampling, undersampling, hybrid techniques, and ensemble learning strategies such as bagging, boosting, and AdaBoost. It also addresses the limitations of these methods and the ongoing challenges in effectively managing class imbalance in healthcare data. Furthermore, the review explores innovative and promising strategies that have shown success in overcoming class imbalance, with a particular emphasis on fairness, diversity, and ethical considerations, offering a hopeful outlook for the future of healthcare data analysis. The discussion highlights how class imbalance can impact the accuracy and reliability of intelligent healthcare systems, underscoring its significance in improving patient care, healthcare delivery, and the broader medical community.
Keywords
Introduction
Class imbalance presents challenges across various disciplines, bearing particularly significant implications in the healthcare sector due to its direct impacts on patient outcomes and overall health. Addressing class imbalances in medical datasets necessitates a comprehensive understanding of the ethical, clinical, and public health considerations that differentiate healthcare from other fields such as finance and security. The emergence of intelligent healthcare systems, underpinned by advanced technologies, data analytics, and connectivity, has transformed traditional medical practices. These systems leverage smart devices, infrastructure, Artificial Intelligence (AI), the Internet of Things (IoT), big data analytics, and Machine Learning (ML) to enhance patient care, improve operational efficiency, and drive superior health outcomes. Nonetheless, managing class imbalance within this framework is imperative to ensure that these intelligent healthcare solutions remain reliable and equitable.1,2 These networks generate vast amounts of data necessitating data classification. In recent years, there has been a notable increase in the exploration of data classification. Imbalanced data collection is commonplace in ML and results in the development of inaccurate classification algorithms. Various methodologies have been employed to classify unbalanced data sets. The majority of traditional classifier learning methods operate under the presumption of a generally balanced class distribution and equal error costs, which constitutes a significant limitation when classifying data characterized by an uneven class distribution. 3 Given the potential for bias, it is imperative to exercise stringent caution concerning the quantity, quality, and processing of the data.
The dependability of this reviewer model is compromised along with the ethical, fairness, and diversity questions. As a type of inaccuracy in ML, “data bias” occurs when sections of a data collection are given excessive weight compared to others.4,5 It is critical to understand how class imbalances in medical data sets can impact machine learning models, leading to skewed predictions and reduced accuracy due to disproportionate representation of classes, such as gender imbalances and socioeconomic disparities. In addition to complicating the development of accurate healthcare analytics, this issue exacerbates existing inequalities, raising ethical concerns and costs. The development of machine learning applications in healthcare must use sophisticated methodologies to ensure that they accurately reflect and serve diverse patient populations, advancing fair and effective healthcare delivery.6–8 The existing literature classified the methods into three areas data-level, algorithmic, and cost-sensitive. It is critical to determine whether the mislabeling of minority classes affects the cost of classifying fraudulent transactions and whether the classifier declares fraudulent transactions as usual.9,10 Classifiers often overlook the class represented by a few examples, although this class is essential, and demonstrate correctness by treating it as the majority class. Data that might be helpful for training are lost if samples from the minority class are eliminated.
The predominant strategy employed to attain an even distribution of instances across all categories is under-oversampling. In contrast to algorithmic methodologies, preprocessing procedures restrict the number of classifiers utilized as cost-sensitive approaches. Conversely, problem-dependent methods involve the meticulous selection and application of classifiers that are specifically designed to confront the distinctive challenges associated with imbalanced data. Data are externally resampled to equilibrate the instance count within each class. For a dataset to be classified as highly divergent, it must contain a substantially greater number of instances from one class relative to another. The class ratio indicates that the number of samples from the majority class surpasses those from the minority class, which can vary from (100 - 1) to (1000 - 1). Current research endeavors aim to minimize the impact of unbalanced data on classification algorithms by developing new algorithms or enhancing existing ones. Conventional practice entails the use of ensemble learning or a cost-sensitive learning approach. 11 This enhances the accuracy of the baseline classification algorithm, while the former increases the penalty for misclassifying minority class members compared to majority class members. The cost-sensitive learning technique utilizes
Undersampling, Oversampling, and Hybrid Sampling. Undersampling is a methodology utilized within the domain of machine learning and data analysis to mitigate the problem of class imbalance within a dataset. Class imbalance transpires when one class (or category/label) in a classification task has a markedly lower number of instances compared to another class. This imbalance can lead to skewed model performance, where the model may excel in predicting the majority class but perform inadequately for the minority class. 12 Through oversampling, the distribution of data is improved by augmenting the quantity of samples in the undersampled category. In conclusion, hybrid sampling techniques amalgamate oversampling and undersampling to yield results of statistical significance.13,14 This systematic literature review (SLR) is crucial to deepen an understanding of the complexities associated with class imbalance, biases in favor of dominant data, and overall data integrity in healthcare analytics. Although a substantial body of literature exists on imbalanced datasets, most studies fail to address the challenges and intricacies pertinent to medical data. This SLR endeavors to bridge these lacunae by investigating the impact of class imbalances on healthcare classifier performance, contrasting various preprocessing techniques, and identifying optimal strategies to balance medical data and classifiers.
Moreover, this SLR addresses data preprocessing methods, classification algorithms, model evaluation, and challenges with future prospects. Initially, we present a comprehensive research methodology for conducting this SLR, followed by a taxonomy of the established areas of unbalanced learning application, and subsequently, we examine the applications within each category. Ultimately, the reviewed publications are synthesized to furnish new avenues for the investigation of unbalanced learning challenges and rare event identification. Machine Learning algorithms are explored to tackle classification challenges in unbalanced medical datasets, encompassing preprocessing techniques, joint learning strategies, algorithmic approaches, and cost sensitivity. Various preprocessing methods are compared to address classification imbalances, thereby achieving optimal balance and classification of healthcare data. Additionally, the SLR classifies and scrutinizes current unbalanced learning applications and proposes new methodologies for the identification of uncommon events and unbalanced learning. As part of the objectives, a research methodology for the SLR will be developed, encompassing the analysis of data-level, algorithmic, and cost-sensitive techniques, along with an overview of imbalanced learning applications.
The remainder of the paper is structured as follows: Section 2 outlines the research methodology for this literature review. Section 3 examines the taxonomy of the literature concerning imbalanced data. Section 4 delves into data-level algorithms, exploring both internal and external data-level algorithms. Section 5 discusses the evaluation metrics for imbalanced datasets, while Section 6 addresses the extant challenges and opportunities.
Research methodology
The SLR is one type of review in which the sequence of steps is used to reduce research bias. This SLR is based on existing literature on ML algorithms to overcome classification problems in unbalanced medical data sets. Figure 1 shows the research methodology framework to carry out this SLR and report the results. This SLR adopted the three-step review process that includes planning, conducting, and documenting.
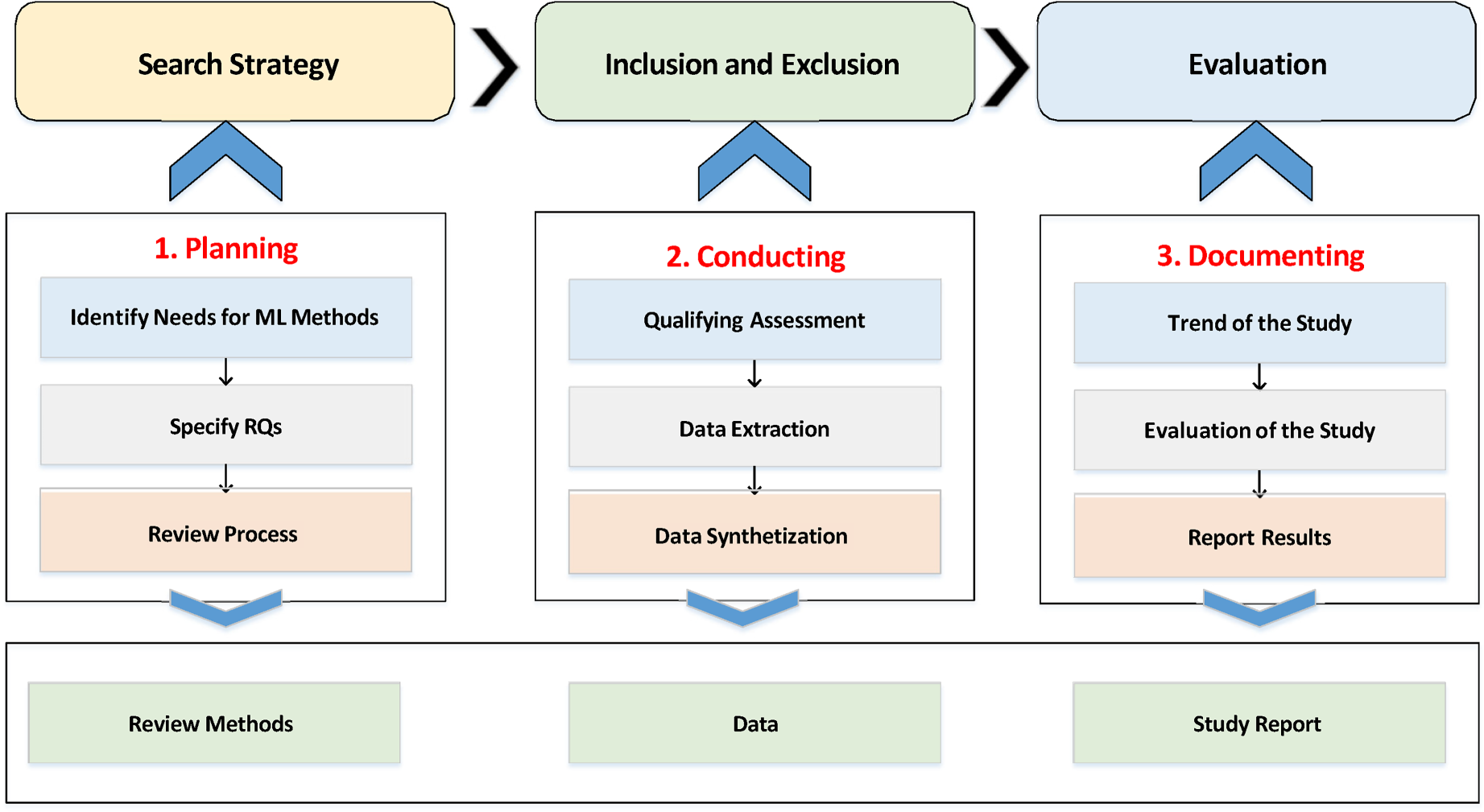
Research methodology framework.
The steps of the research methodology, including planning, conducting and documenting the SLR. In the planning phase, the SLR begins by identifying the existing literature on ML algorithms to overcome classification problems in imbalanced medical data sets. First, research questions are created to extract exact studies from the literature, such as:
What are the different ML algorithms for healthcare data analysis? What are the possible solutions to overcome the problem of an imbalanced data set? What are the current solutions to solve the problems of the unbalanced data set?
The data for this analysis were meticulously gathered from six esteemed academic databases, namely ScienceDirect, IEEE Xplore, Scopus, Web of Science, Google Scholar, and PubMed. Following the identification of a need for a systematic literature review (SLR), the research questions were employed to explicitly refine and direct the review process. An analysis of these databases facilitated the retrieval of approximately 1200 peer-reviewed articles, originating from an initial collection of approximately 500 literature sources. To uphold the quality of the review, stringent inclusion and exclusion criteria were enforced. Only studies published in scientific peer-reviewed journals were considered, whereas studies from alternative fields were excluded.
Throughout the review phase, each article was assessed against quality evaluation criteria, as delineated in Section 3. In conclusion, 152 works were earmarked for an in-depth examination in accordance with these criteria. These selected articles were systematically analyzed and documented to substantiate the findings and conclusions presented in our evaluation.
The data quality requirements for imbalanced data are vital in many domains, including artificial intelligence and machine learning. Classification tasks become more difficult in imbalanced data sets when minority classes are underrepresented. Researchers have investigated many methods to improve the performance of classification models when faced with unbalanced data in an effort to resolve this issue. General classification performance can be improved with a balanced dataset as compared to an imbalanced one, according to studies. 15 However, the traits of imbalanced datasets and the number of classifiers required to successfully manage them while preserving individual quality and complementarity must be carefully considered. 16 Several ensemble learning-based methods have been suggested for dealing with imbalanced datasets; they include EasyEnsemble, SMOTEBagging, Balanced Random Forest, and SMOTEBoost. 17 Ensemble models and intelligent algorithms for base classification are necessary to improve the precision of classification data in many domains, including diagnosis and treatments for prostate cancer. 18 Investigating deep neural networks to deal with extremely imbalanced data in bioinformatics has brought attention to the importance of complex procedures in the resolution of data quality issues. 19
Inconsistencies in real-world data pose significant challenges for statistical analysis. Imbalances are common in medical datasets, making data analysis solutions to identify healthy individuals more expensive to develop. Class imbalance is a growing concern in data mining, particularly when constructing analysis tools from nonuniform medical datasets. This problem increases the cost of misdiagnosing healthy individuals as ill. To improve clinical trial data analysis and quality, a quality assurance system has been implemented in medical records. Introduce a user-centered data quality theory grounded in well-defined concepts and three domain- specific language categories. An ensemble classification method is proposed that offers implicit regularization to mitigate overfitting issues, particularly when handling binary imbalanced data. This approach involves creating two additional virtual spaces alongside the original data set for use with the Support Vector Machine (SVM) classifier. 20 Additionally, fuzzy concepts are incorporated to expedite search times, and a four-step approach is presented: component analysis, feature selection, SVM-based minor classification, and sampling. To address the challenge of data asymmetry, random sampling is a commonly used technique. However, it has limitations, highlighting the need for a reliable genetic algorithm-based approach to determine sample ratios. To evaluate effectiveness, 14 data sets were used and a novel weighting method was introduced to improve the performance of less capable classifiers, using an improved AdaBoost algorithm.21,22 This model handles imbalanced data by considering the Hellinger distance between samples. Additionally, it addresses feature drift issues, aiding in the identification of relevant features for spam detection, thereby improving spam detection capabilities.23,24
A range of oversampling methods have been employed to equate the number of instances in the minority class with those in the majority class. Nonetheless, the introduction of synthetic examples through oversampling may contribute noise to the dataset. An alternative study 25 indicates that synthetic instances can modify the decision boundaries of classifiers. This investigation underscores the advantages of integrating data-level and ensemble methodologies to alleviate the risks tied to data resampling, which might lead to the irreversible loss of critical instances. Classifier performance was assessed using eight distinct datasets, subsequent to the application of specific preprocessing techniques.26,27 Fuzzy methodologies were implemented involving two families of classifiers; one operating at the bag level, and the other at the individual instance level to tackle the issue of imbalance. 28 Furthermore, a price-sensitive categorization method was proposed, which mitigates classification errors by inducing a high bias. 29
Visualization techniques for imbalanced data
To address the challenges associated with imbalanced data, a variety of visualization techniques have been proposed. Researchers have conducted a thorough review that investigates progress in the field of imbalanced data learning, encompassing present issues, characteristics, emerging technologies, and the metrics employed to assess learning effectiveness. Furthermore, it acts as a catalyst for prospective research by emphasizing potential opportunities, challenges, and directions within imbalanced data learning. 15 The review delves into various aspects of imbalanced data learning, including data streams, classification, clustering, and regression applied in practical contexts. The study systematically categorizes open challenges inherent in imbalanced learning, which include binary imbalanced data, multi-label learning, imbalances in big data, as well as unsupervised and semi-supervised learning. 16
In, 30 an innovative data visualization mechanism for the healthcare sector is introduced, engineered to automate the collection of data from medical documents. This solution utilizes a variety of data processing and visualization instruments to compile informative data advantageous for decision-making processes. Additionally, it encompasses the creation of a comprehensive medical information dashboard, with empirical results attesting to its effectiveness in visualizing healthcare knowledge. In, 31 a meticulous taxonomy of existing applications in the realm of imbalanced learning, notably within data mining and machine learning, is presented. This research assimilates prior reviews, brings forth novel insights, and offers insightful recommendations for future research trajectories. Addressing the pivotal challenge of evaluating imbalanced datasets, 32 elucidates an optimal model that integrates a combination of methodologies, including G- means, F-measure, Likelihood Ratio, Youden Index, alongside a variety of metrics such as AUC, Partial AUC, Weighted AUC, Cumulative AUC, and AUL. This holistic approach augments accuracy in churn prediction assessment models, a predominant challenge in data mining. Furthermore, in, 33 the authors underscore the underemphasis placed on the assessment of imbalanced data relative to balanced data. They propose the application of Deep Neural Networks (DNN) for the classification of imbalanced data, employing Means False Error (MFE) and Means Squared False Error (MQFE) as methods for training DNN models.
Taxonomy of literature on imbalanced data
Over the years, numerous strategies have been implemented and evaluated to address the issue of imbalanced data. This section examines various data preprocessing techniques. Nonetheless, integrating these and other methodologies may tackle class division problems in multiple ways. The conclusions derived from the reported studies might provide grounds for optimism. It could modify the ensemble learning method without altering the classifier, owing to the algorithms that support these techniques. Alterations have been made to the ensemble learning algorithm; achieving the learning stage necessitates initial data preparation. Moreover, alternative possibilities exist. Figure 2 depicts the taxonomy of literature studies concerning imbalanced data approaches.
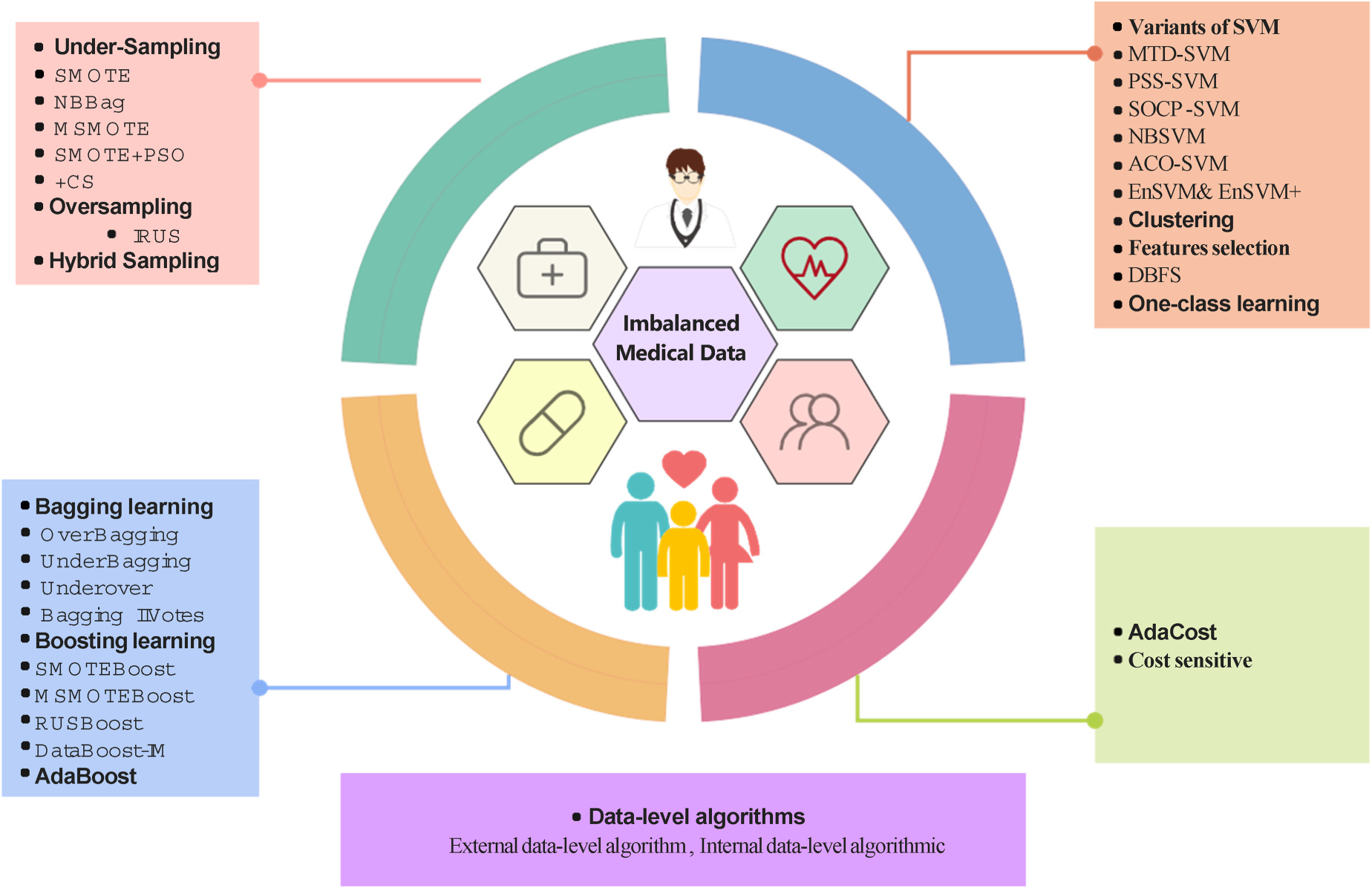
Taxonomy of literature studies for imbalanced data solution methods.
Machine learning classifiers face significant challenges in addressing outliers and imbalanced datasets. As cited in, 34 a selective data preparation strategy was proposed, utilizing an artificially constructed subset that modules can integrate to address outlier instances. To enhance the diversity within the training data, this strategy employed the Synthetic Minority Oversampling Technique (SMOTE), applied subsequent to the oversampling of anomalies, irrespective of class. The objective is to lessen the influence of outliers on the training dataset. Findings indicate that selective oversampling provides an improved classification method for SMOTE, as illustrated in Figure 2. Three principal techniques exist for managing imbalanced data: undersampling, oversampling, and hybrid methodologies, each intended to equilibrate the class distribution within the dataset.
Generative models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have gained significant traction in the management of imbalanced datasets. In the context of tasks such as fault diagnosis and anomaly detection, GANs have shown considerable effectiveness in generating synthetic data that closely resembles actual data.35,36 Conversely, VAEs are recognized as powerful instruments for unsupervised learning, facilitating the representation of intricate high-dimensional data within a low- dimensional latent space. Recent scholarly investigations have explored the integration of GANs and VAEs to enhance generative model performance. Scholars have endeavored to optimize both generative and reconstructive capabilities by leveraging the strengths inherent in both models. 37
Under-sampling
The principal aim of undersampling methodologies is to enhance the precision of the minority class by diminishing the size of the majority sample populations. Randomly selecting and subsequently removing a sample from the majority class exemplifies a straightforward undersampling technique. Classifier performance may be adversely affected when random samples are eliminated from the majority class, as this could result in the loss of crucial information among the remaining instances. Researchers have devised algorithms designed to meticulously select models from the extensive majority classes that do not contain pertinent data. 34 The stacking of community undersampling ensembles is a methodological approach employed to mitigate class imbalance via undersampling. This technique utilises a stacked ensemble as an undersampling strategy, with considerations for class imbalance, class overlap, and class noise. Rather than implementing undersampling solely as a preprocessing step, this method assimilates the undersampling process into the stacked ensemble itself, thereby establishing what is termed a stacked undersampling ensemble.
This approach applies a stacked ensemble as an undersampling strategy, taking into account class imbalance, class overlap, and class noise. Instead of treating undersampling as merely a preprocessing step, this approach incorporates the stacked ensemble directly, thereby forming a stacked undersampling ensemble. In addressing the degradation issue, a stacked ensemble is employed as an undersampling strategy that considers class imbalance, class overlap, and class noise. By integrating the undersampling process within the ensemble itself, a stacked undersampling ensemble is developed. A novel procedure for undersampling is employed, utilising a three-stage framework that includes demising, fuzzy K-Means clustering, and representative sample selection. 35 This approach incorporates a denoising phase preceding the clustering- based undersampling strategy to enhance the system's resilience to noisy data.
To select a representative of the majority class, a random sample is used. 36 Clustering-based undersampling is used in predictive modeling of healthcare-associated infections to under-sample just certain parts of the whole space of variables, hence reducing the likelihood of overfitting and the severity of under-negative sampling's consequences. A clustering method is used in an n-dimensional space, where n is the number of attributes other than the class attribute, to generate these areas. 37
The predictive diagnosis of diseases with imbalanced data sets is suggested. To remedy this sampling discrepancy, it used an undersampling technique based on the overlap between the two groups, which resulted in more representative data for the underrepresented minority in the overlapping areas. This is achieved by identifying and excluding negative class samples from the overlap area, increasing class reparability in the data space. 38 It implemented a pair of undersampling techniques where the first cluster centers and the second relied on nearest neighbors to strike a class-balancing chord. Five different classification methods are used to evaluate the performance of the new method on the various datasets. The experimental findings showed in, 39 that these methods are more accurate when a comparison of sample techniques is used to imbalanced medical data. This research examined the impact of imbalance strategies on the diagnosis of patients with lung cancer using three classifiers (logistic regression, random forest, and linear svc), and compared 10 undersampling techniques, seven oversampling methodologies, and two integrated sampling techniques. The findings favor oversampling techniques over undersampling and hybrid approaches. 40
Oversampling
Oversampling strategies, in contrast to undersampling ones, focus on increasing the number of samples from the minority group. To improve the classification performance of minority samples, the SMOTE uses linear interpolation on comparable neighbor samples randomly chosen to generate additional minority samples.41,42 However, there are drawbacks to using oversampling techniques, such as the introduction of overlap, boundaries, noise, and other artifacts into the samples. A set of SMOTE algorithm improvements is presented to address the issues. Most recently, the misclassification-oriented synthesized minority oversampling approach (m-smote) and edited closest neighbor based on Random Forest (RF) have been used in conjunction with synthesis from minority class instances. To collect more data from underrepresented groups, M-smote is often used. The m-smote oversampling rate is calculated from the RF misclassification rate.
To preserve the distributional characteristics of the original data. In,43,44 two oversampling methods are proposed including adaptive-smote and selectively selecting groups of inner and danger data from the minority class to synthesize a new minority class based on the selected data. Danger data refers to vulnerable data in ML systems such as model theft, system hijacking, data poisoning, and evasion attacks. The second approach, known as Gaussian oversampling, combines dimensionality reduction with the Gaussian, 45 distribution to produce a flatter distribution with a narrower tail. Synthetic minority oversampling is used to create minority class instances and rebalance medical datasets. This method is improved by applying the orchard approach. In, 46 an interclass and intra-cluster distribution-aware distributed fuzzy-based adaptable synthetic oversampling technique is proposed. Fuzzy clustering of c-means, together with a weighted distribution and a mixed synthetic approach, comprise the components. According to the definition of natural neighbors of the synthetic minority oversampling approach presented in. 47
Hybrid sampling
Hybrid sampling is all about finding the right balance in datasets by boosting the number of minority samples and reducing the majority ones. This method helps to tackle the common problems with oversampling—like overfitting—and undersampling, which can result in losing important data. By blending these two approaches, hybrid sampling provides a more reliable way to handle imbalanced data.44,48 Take health record analysis, for instance, where there is often a massive imbalance with a few minority samples. To deal with this, an algorithm called Husdos-boost is used. It combines boosting with an intelligent, distribution-based oversampling technique. This method also uses undersampling to remove duplicate majority samples and creates new minority samples based on the actual distribution of that class., 49 A common technique in this scenario is M-SMOTE, where more samples are drawn from the underrepresented group.
In this process, many samples in the Edited Nearest Neighbor (ENN) step are undersampled. Then, hybrid sampling kicks in, and the classification prediction continues until the classification index signals it is time to stop. 50 Finally, classification prediction is performed using hybrid sampling with the stopping threshold for iterations established according to changes in the classification index. In, 51 In another study, a new hybrid method combining synthetic minority oversampling with ENN was used to clean and filter the data. This approach effectively addresses imbalanced data by leveraging the strengths of both over- and undersampling. The K- Means method was applied to find representative samples from both the majority and minority classes, with a local search making the process more efficient. How data is spread across different classes is crucial for accurate classification.
However, in imbalanced datasets, the minority class often gets the short end of the stick, making it challenging for classifiers to perform well, especially when there is class overlap or limited samples. Class imbalance is a persistent issue in data mining, particularly in real-world categorization tasks. There are several strategies to tackle class differences, generally falling into three main categories. Figure 3 is highlighted because it shows the application of the SMOTE technique in improving the accuracy of diabetes prediction. This figure is fascinating because it illustrates how hybrid sampling techniques are applied in practice, effectively balancing data and improving prediction outcomes—making it a key example of success in the critical area of diabetes prediction.52–54 Figure 3 shows the SMOTE technique used for diabetes prediction accuracy.
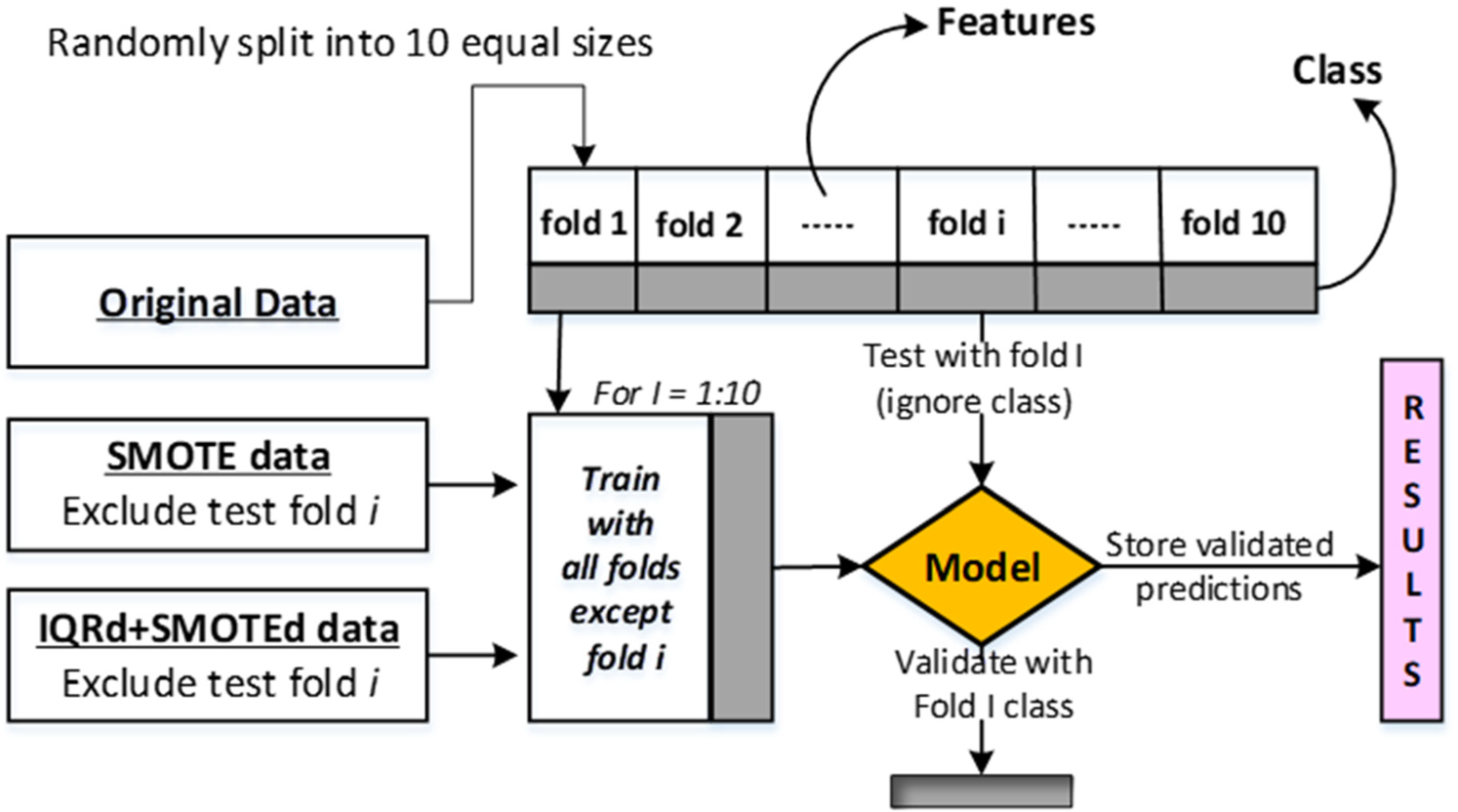
Improves diabetes prediction accuracy by smoothing out noisy training data using the interquartile range and the SMOTE Technique. 55
One way to deal with unbalanced data is to develop new algorithms or improve existing ones. This section discusses the different types of existing algorithms.
Variants of SVM
Due to the prevalence of class imbalance issues in DNA microarray data, the predictive ability of minority classes is significantly compromised, often leading to the neglect of the minority group in model predictions. SVM is highlighted in this section because of its exceptional ability to handle complex, high-dimensional, and imbalanced datasets, especially in areas like DNA microarray data. Its robustness and adaptability, through various modifications and hybrid models, make it a powerful tool for improving prediction accuracy, particularly in challenging scenarios. This focus on SVM is justified by its proven effectiveness and versatility in addressing the unique challenges posed by imbalanced data.56,57 To address this issue, a novel under sampling strategy based on the concept of Ant Colony Optimization (ACO) has been developed. A common categorization method is used for imbalanced data by using a SVM.58–60
The Megatrend Diffusion Strategy (MTD) may also be utilized to increase minority group representation. During the predictor phase, there are a variety of ML approaches to merge SVM and KNN into hybrid MTD- KNN, MTD-SVM, and prediction models. The researchers used cost,61,62 and discussed that MTD-SVM is superior to the alternatives of RF, Naive Bayes, and KNN. The researchers suggested a prediction algorithm that can classify people with high type 2 diabetes. There are two sections of the investigation. Data imputation methods, such as median value imputation, KNN imputation, and iterative imputation are explored in this study in terms of their performance when applied to the missing data problem. Consequently, many classification techniques (including linear, tree-based, and ensemble algorithms) are used to verify the effects of these
imputations on classification precision. It is used as an artificial neural network to model the highest quality imputed data, while SMOTE- Tomek is used to ensure that it fairly represents all classes. The accuracy is 98% by using this method on the test data, which is higher than any other tested method on the same data. Population and gender are the main themes in the data set. 62
Dealing with a dataset that is skewed toward one group or the other, the majority or the minority, the kernel scaling approach is used to improve SVM. The PSS-SVM classification, which mixes Parallel Select Sampling (PSS) with the SVM, demonstrated impressive results on benchmark datasets, which are much better than ordinary SVM due to the lack of convergence. It may reduce the imbalance in large data sets by selecting data from the dominant class.63,64 A mixed ensemble of SVMs is used under and oversampling tactics to improve prediction performance. Extensive testing has shown that this strategy is superior for standalone SVM and several alternative classifiers. The research compared the performance of the EnSVM basic model with the selective EnSVM + ensemble by using various resampling strategies. 64 Using SVM training as a preprocessor, these strategies improved the results of intelligent machine learning algorithms including Multilayer Perceptron (MLP), RF, and Logistic Regression (LR).
There are two phases to the implementation of the balancing approach. In the first stage, the SVM altered the imbalanced data to produce better balance data, and in the second stage, MLP, RF, and LR used these enhanced data as input.65–67 Table 1 presents the advantages and disadvantages of SVM and its different variations. Each method, such as Megatrend Diffusion SVM (MTD-SVM), Ant Colony Optimization SVM (ACO- SVM), and Ensemble SVM (EnSVM-R), offers unique benefits tailored to specific imbalanced data challenges, particularly in healthcare. For instance, MTD- SVM effectively improves minority class representation, but its effectiveness is limited to smaller datasets, whereas EnSVM-R enhances predictive accuracy but requires careful parameter tuning. This revised discussion clarifies why specific algorithms may be preferred depending on the dataset's characteristics and computational resources.
A summary of Various SVM algorithm approaches.
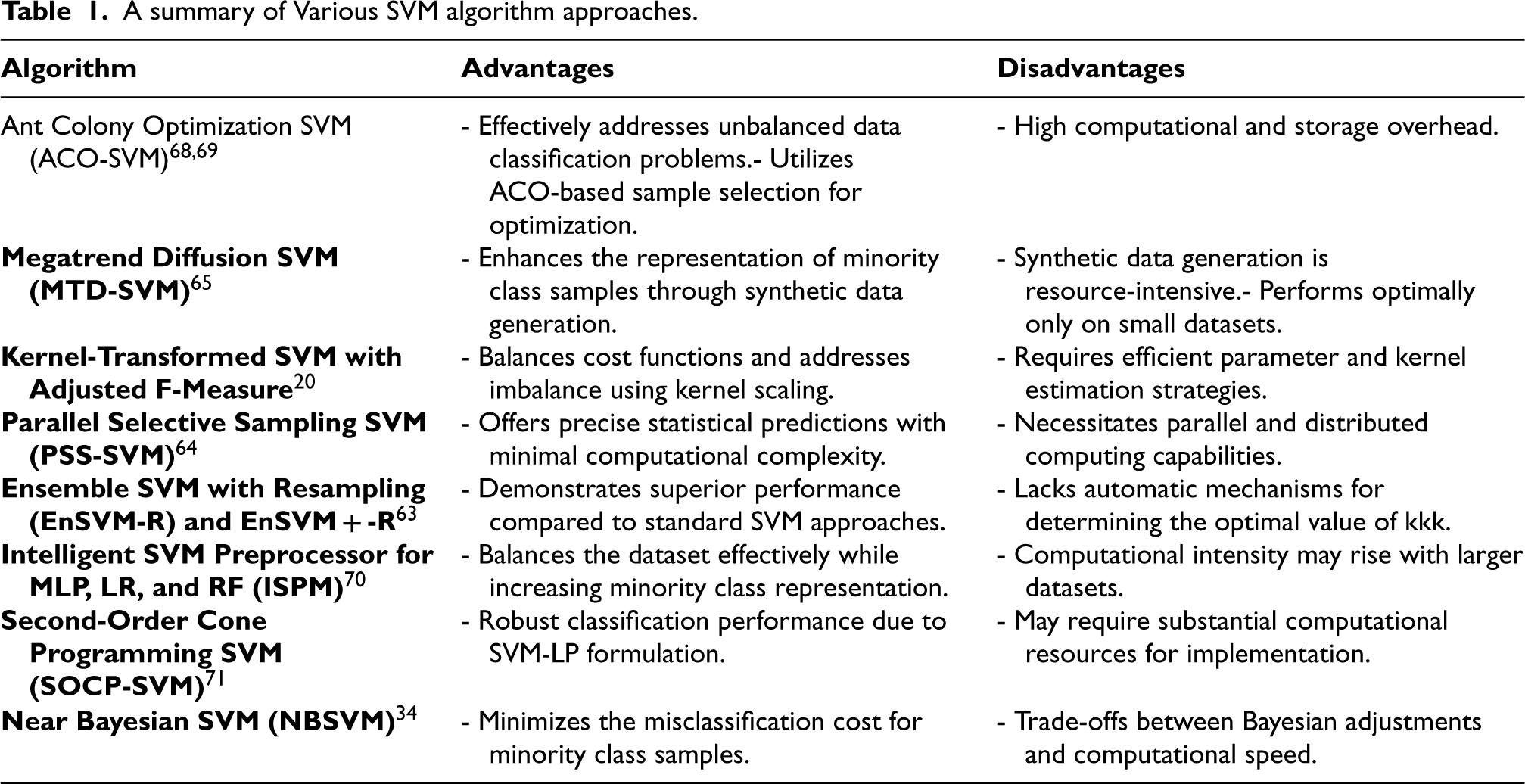
A summary of Various SVM algorithm approaches.
Clustering is used to classify data, while outlier detection is used to find outliers. The similarity-based hierarchical decomposition method runs on the back of clustering algorithms and the detection of outliers. 72 There are two parts dedicated to the process of creating hierarchies: the first discusses making a mistake while classifying clusters, while the second focuses on doing it correctly. 73 Data similarities of labeled subgroups at every level are utilized to generate hierarchy and feature sets, as well as other data based on these different levels. With this method, this revision can prevent issues such as class overlap and inequities between groups. 74 The research presented under sampling based on clustering in data with an unequal distribution of classes. 75 Fuzzy Rule-based Classes (FRBCSs) are also used to improve classification accuracy. Using 2-tuple genetic tuning, which also increases the efficiency of FRBCSs, this approach is useful for dealing with imbalanced data, as it can handle both low and high ratios of skewed datasets. Clustering-based oversampling is a revolutionary data-level resampling strategy for improving learning from class unbalanced datasets. The concept of methodology that underpins the proposed method is that one can infer the number of new sample points that need to be generated for a minority class sample by using the distance that exists between a minority class sample and the respective cluster centroid for that minority class sample.63,76
Feature selection methods
In contexts of high-dimensional data, the selection of features frequently serves as the preliminary step for numerous machine learning algorithms. In scenarios involving high-dimensional heterogeneous data, the implementation of feature selection delivers optimal outcomes. 77 A wide array of applications, such as bioinformatics, text mining, and image classification, are influenced by the challenges of high dimensionality and class imbalance. Through thorough experimentation across various domains employing a Random Forest classifier, a hybrid approach is advocated, integrating feature selection techniques with strategies to address class imbalance. This hybrid methodology adeptly manages datasets manifesting both characteristics, exhibiting superior efficacy relative to the use of either technique independently, 78 as illustrated in Figure 4. Regarding imbalanced datasets, existing methods applied for feature selection have been shown to be insufficient. A paradigm is proposed for feature selection which distinguishes between majority and minority characteristics. By assessing demographic data in two distinct manners (majority and minority), it becomes straightforward to adapt existing standards accordingly.

Hybrid approaches for combine feature selection with imbalance Learning. 78
So far, another method proposed in, 79 is effective in several high-dimensional, imbalanced, small-sample datasets. In, 80 proposed a decomposition-based technique and a Hellinger distance-based approach for feature selection for imbalanced datasets. The conflict caused by the unequal distribution of classes is first addressed by calculating the distributional gaps. The second method partitioned huge classes into arbitrary subclasses by using a wide range of classification algorithms. Recently, it has investigated the efficacy of hybrid learning strategies that combine feature selection approaches to lower the data dimensionality with appropriate methods that deal with the negative impacts of class imbalance (in particular, data balancing and cost-sensitive techniques). Extensive studies have been conducted across data sets from many domains using a popular classifier called the RF, which is effective in high-dimensional spaces and applied to unbalanced problems. The findings demonstrated the advantages of this combined strategy over feature selection or imbalance learning alone. 81
Learning approaches based on traditional methods are plagued by class imbalance, which reduces performance and produces inaccurate results. It is when one group's representation is disproportionate to the other data set and is viewed from different category perspectives. They also presented a significant problem due to the high price of misclassification of minorities. The existence of overlapping instances of data inconsistencies could lead to a disastrous outcome for powerful learning. 82 By using this method, the algorithm selected only the samples that correspond to the desired class. Thus, it may be used to classify asymmetric information. For example, only samples from minority groups are retrieved, and all other groups are excluded.
There is a clear advantage to using one-class learning on large and imbalanced datasets. Furthermore, this method uses a rule-based approach to the divide-and-conquer principle of the rule- induction system to produce rules iteratively. 83 Evidence for Ripper's training has been found in the past. Rules are generated for each class, from the rarest to the most common, with more criteria being added to each rule over time. Ripper claims that this algorithm's strength lies in its ability to learn rules for marginalized groups. Overly skewed datasets, ones that have noisy features as well as high-dimensional space, might benefit greatly from one-class learning. In most cases, the benefits of one-class learning outweigh the additional costs associated with its implementation. 84 Figure 6 shows the framework for the prediction of type 2 diabetes as used in, 62 (see Figure 5).

Prediction of type 2 diabetes Framework. 62
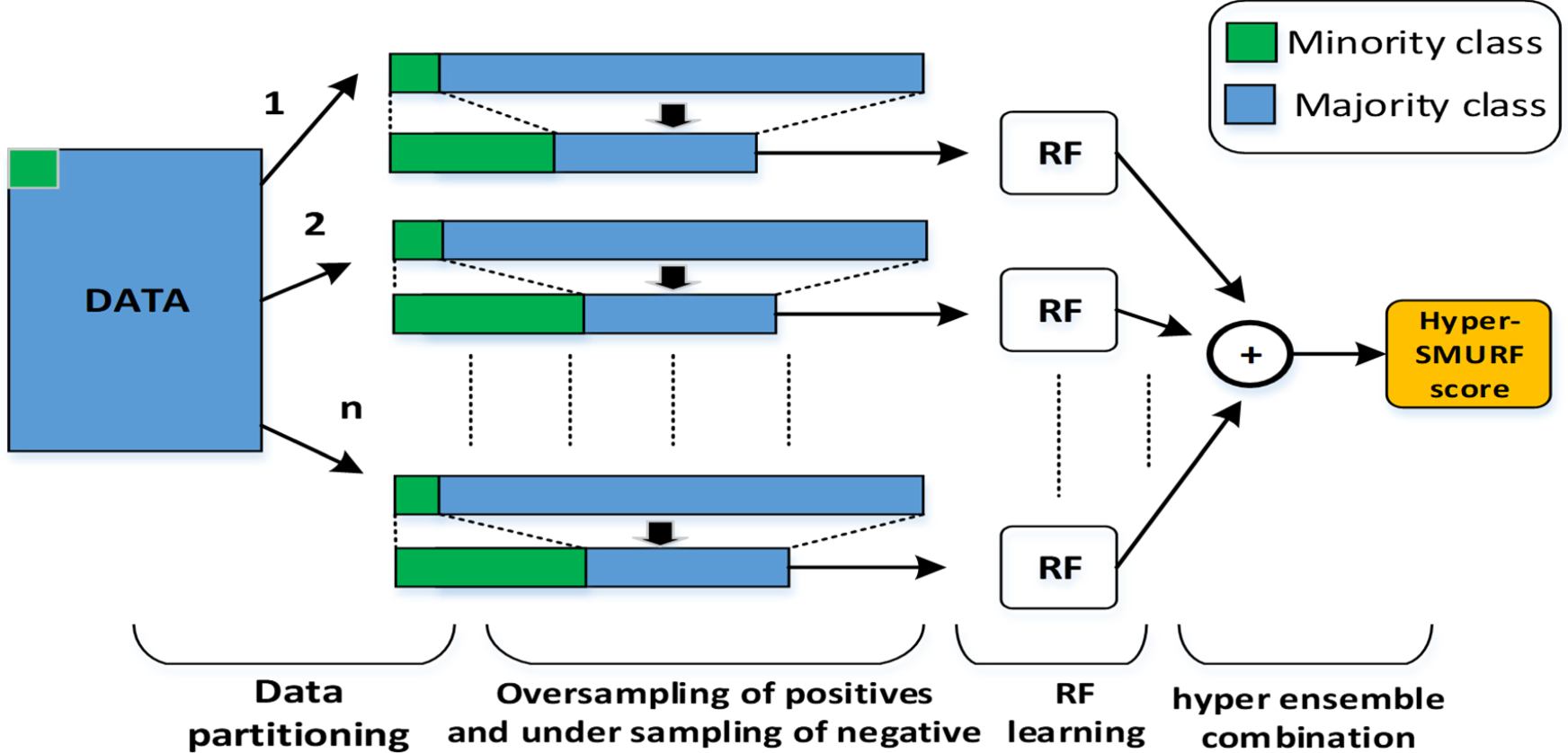
HyperSMURF approach (Polikar, 2006 85 ).
Another key is that the quality of the base learners is also crucial to the success of ensemble approaches. It is well known that ensembles generally improve the accuracy and robustness of the predictions of the learning machine. 86 Ensemble classifiers are made to make a single classifier more accurate by training multiple classifiers and combining their results into a single classifier that performs better than the individual classifiers. Therefore, ensemble-based techniques combine ensemble learning algorithms and hybrid approaches, such as data-driven algorithms or cost-sensitive solutions. Algorithmic techniques, such as ensemble learning are used to modify the underlying learner rather than update the fundamental classifier. To improve the performance of each classifier, the composition can be utilized in the same way to combine numerous classifiers into a single and more effective one.
In ML, the accuracy of a single classifier has been improved. Although both classifiers and individual learning classifiers are indeed incapable of resolving the imbalance class problem on their own, this problem can be addressed by using well-considered learning methods. 87 Assuming a weak learning algorithm allows the development of a wide variety of strategies and procedures that can be used to create an ensemble learning algorithm. Described a new strategy that outperforms state-of-the-art algorithms in two separate settings, namely, the prediction of noncoding variants associated with Mendelian and complex disorders, taking advantage of imbalance-aware learning strategies based on resampling techniques and a hyper-economy approach. 88 Figure 6 shows the hyper SMURF method diagram, and the blue rectangles represent the majority class, subdivided into n subclasses to increase the number of minority class training instances. The oversampling techniques generate unique cases from the minority class for each partition. At the same time, a sample of the larger demographic is drawn. Finally, hypersurf employs an ensemble-of-ensembles method to integrate the forecasts of n independently trained RF using symmetric data sets.
Bagging learning
Breiman's introduced the idea of bootstrap accumulation for constructing ensembles. Since there is an inequity between the proportions of minority samples in a dataset, statisticians employ a technique called “bagging” to correct the issue. Over-Bagging, Under-Bagging, Under-Over-Bagging, and Under-Over-Bagging are also offered as the four main bagging ensembles, all of which maintain the variety without sacrificing it. 89
Boosting
Boosting is an ML ensemble technique that aims to improve the performance of weak learners (typically simple models) by strategically combining their predictions. A research study confirmed the ability of the Probability Approximately Correct (PAC) learning framework to transform a poor learner into a good one. Similar to bagging, boosting involves picking the points that result in an incorrect forecast. 90 Presents a solution for an ensemble method, BPSO-Adaboost-KNN, to handle multiclass unbalanced data classification. The central concept of this algorithm includes feature selection and boosting into an ensemble. Furthermore, we employ a unique assessment metric for multiclass classification called AUCarea. 85
Adaboost
AdaBoost uses the whole dataset to train each classifier serially and each iteration, focusing on the samples to identify (minority instances) due to the algorithm's bias in learning (the weight) from imbalanced data. AdaBoost.M1 and AdaBoost.M2 are two well-known adaptations used in asymmetrical ruler ships. 91 An ensemble approach is also used for the classification of imbalanced data; this strategy divides an imbalanced data set into a large number of equal-sized subsets of the original data, each of which is subjected to a different number of classifiers using a unique classification algorithm. 92 Figure 6 shows the hyperSMURF approach.
Cost-sensitivity methods
Misclassification costs can be high when both data and algorithm levels are involved. This method aims to minimize the total cost of misclassification. A cost-sensitive approach would be more interesting if positive instances were recognized rather than negative ones.22,93 The cost of misclassifying a non-cancerous patient in the medical domain is limited to additional medical tests. On the contrary, the cost of misdiagnosis will be fatal, as potentially cancerous patients are considered healthy. An evaluation framework is used to bridge the gap between internal and external approaches when evaluating potential cost changes. The learning procedure is modified to accept costs and add costs to samples by combining algorithmic and data- level techniques. The classifiers tend to be biased toward the minority class to reduce overall cost misclassification for both courses if there is a higher mistake rate for the minority class. The cost and emotional impact of a false negative in cancer diagnostics (when a patient tests positive but receives a false negative result) are generally higher than that of a false positive (when a patient pushes negative but is classified as positive). 85
For example, if incorrectly classified a cancer patient is a positive class (i.e., minority class) and a non-cancer patient in a negative class (majority class), the patient could potentially lose life due to incorrect categorization or a delay in receiving proper medical treatment and diagnosis. To reduce misclassification and total test costs, in the same way, investigate various adjustments to cost matrices for cost-sensitive training and formulation costs. 94 To provide unequal treatment for classes that are not evenly treated by cost- sensitive learning, it keeps the central AdaBoost learning architecture while simultaneously including cost aspects into the weight update algorithm. Therefore, these methods may diverge solely in the specific ways in which they improve the weight update procedure. AdaC1, AdaC2, and AdaC3; CSB1, CSB2, and AdaCost are the most well-known cost- sensitive boosting algorithms.95,96 Table 2 shows the summary and analysis of clustering, feature selection, one-class learning, cost sensitivity, and ensemble learning approaches.
Clustering, feature selection, one-class learning, cost sensitivity, and ensemble learning techniques.

Clustering, feature selection, one-class learning, cost sensitivity, and ensemble learning techniques.
Many classification models have been presented to perform the classification task because of their importance in efficient data mining. On the other hand, regular classification models are highly sensitive to each dataset's specifics. Standard classification models are biased toward the most common patterns, leading to the misclassification of unusual cases when applied to datasets with a skewed class distribution. As a result of the gravity of class disparity issues, much effort has been put into finding effective ways to address them. In terms of how they deal with class differences, these ideas may be broken down into three camps: those that take an external (or data-level) approach, those that use an internal (algorithmic) approach, and those that are cost-sensitive. In addition, ensemble learning classifiers are also crucial in the categorization of imbalanced data. 90 Despite the extensive literature on data-level classifications, the computational burden of these methods is high.
The primary goal of algorithmic methods is to enhance the precision of a model by proposing new algorithms or adjustments to current methods. After comparing the effectiveness of various methods, in, 104 the naive Bayes and K-Nearest Neighbor (KNN) approaches tend to outperform the SVM and Random Forest (RF) approaches. Various problems can be solved using Genetic Programming (GP), an evolutionary approach. As a consequence, price adjustments can be considered a synonym for cost adjustments in GP. Adjusting costs in GP is as simple as following the suitable fitness functions. It is appropriate for the fitness function to reward solutions beneficial to minority and majority groups. Moreover, it demonstrated that both the accuracy (acc) and the average class accuracy (ave) of the fitness function are sufficient to address the problems associated with the imbalanced classification. Thus, the Ames, Incr, and Corr fitness functions are used.105,106
External data-level algorithm
A random undersampling approach, which excludes majority class specimens at random and creates a subset of the main dataset in a manner to balance the ratio, is one resampling technique used in the preparation of imbalanced data, which may be categorized into three forms. There is a risk of information loss if data that may be used in the induction process are omitted. Randomly duplicating the current samples, random Oversampling creates a supplementary set of main data that includes more samples from underrepresented groups. However, the increased possibility of repetition might lead to overfitting. Finally, the hybrid method combines the two sampling approaches to provide a more uniform distribution. 107 The minority class's Synthetic Minority Oversampling Technique (SMOTE) interpolation of already existing minority class specimens is used to generate new samples. To generate a duplicate specimen from two interpolated specimens, SMOTE randomly chooses one of the kNN of a poor specimen. Efforts to expand the reach of the minority class into the territory of the majority class are limited by a decision taken at the boundary level. The approach eliminates the overfitting problem but produces noisy and questionable specimens. 108
Some filtering-based approaches (SMOTE-TL and EL) are employed to suppress noise in asymmetric data sets. On the other hand, original sampling techniques are augmented with neighborhood-balanced bagging to deal with asymmetric data (NBBag). An enhanced version of SMOTE, known as the Modified Synthetic Minority Oversampling Technique (MSMOTE), is developed. This method divided the minority class into three categories: latent noise, safe, and border based on the distances between all samples. The MSMOTE created fresh instances, discarding occult noise spots using the kNN classification approach. 109 However, it addresses the hidden noise instances and does not emphasize key features. When dealing with disturbances and maintaining orderly class boundaries, researchers have turned to an extended version of SMOTE and an iterative partitioning filter (IPF). 110 For even more powerful data-level strategies, such as SMOTE extension, B1-SMOTE, and B2-SMOTE, SMOTE has been modified in many ways. 111 The Minority Weighted Minority Oversampling Technique (MWMOTE) is an efficient method for selecting and weighing samples from hard-to- learn minority classes. Furthermore, it can provide realistic simulated instances. Another approach is the Selective Pretreatment of Imbalanced Data (SPIDER), which combines complicated instances screened from the majority class with local oversampling of the minority class in a single step. 112
To fix the skewed data, researchers have turned to a novel Inverse Random Undersampling (IRUS) technique based on an inverse (ratio of unbalanced cardinality) strategy. This also has implications for multiple-label categorization systems. A Radial Basis Function Network (RBFN) is offered for dealing with imbalanced datasets. 113 It is created with both local and global terms in mind and employs a method of training local weights. A higher value of the Imbalance Ratio (IR) produced better results in local weight training techniques, and a lower value of the IR should be balanced with any technique. Incorporating well- known classifiers such as Logistic Regression (LR), the C5 decision tree model (C5), and the search for the nearest neighbor 1 in the tree, a classifier technique is suggested that combines PSO and SMOTE. This new collection of classifiers is shown to be efficient via the use of performance measurements, like accuracy indices and the G-mean. The experimental findings demonstrated the efficacy of the hybrid algorithm PSO + SMOTE + C5 to predict 5-year survival in breast cancer patients. The fusion of PSO, SMOTE, and an assisted Radial Basis Function (RBF) classifier is offered as another effective method for imbalanced binary class situations; evaluation with various metrics revealed that this approach works well for moderately imbalanced data sets but falls short for extremely imbalanced ones. 114
Internal data-level algotihms
One way to deal with imbalanced data is to develop new algorithms or improve the existing ones for the effects on underrepresented groups. Table 3 summarizes the benefits and drawbacks of all data-level approaches.
Approaches at the data level with advantages and disadvantages.
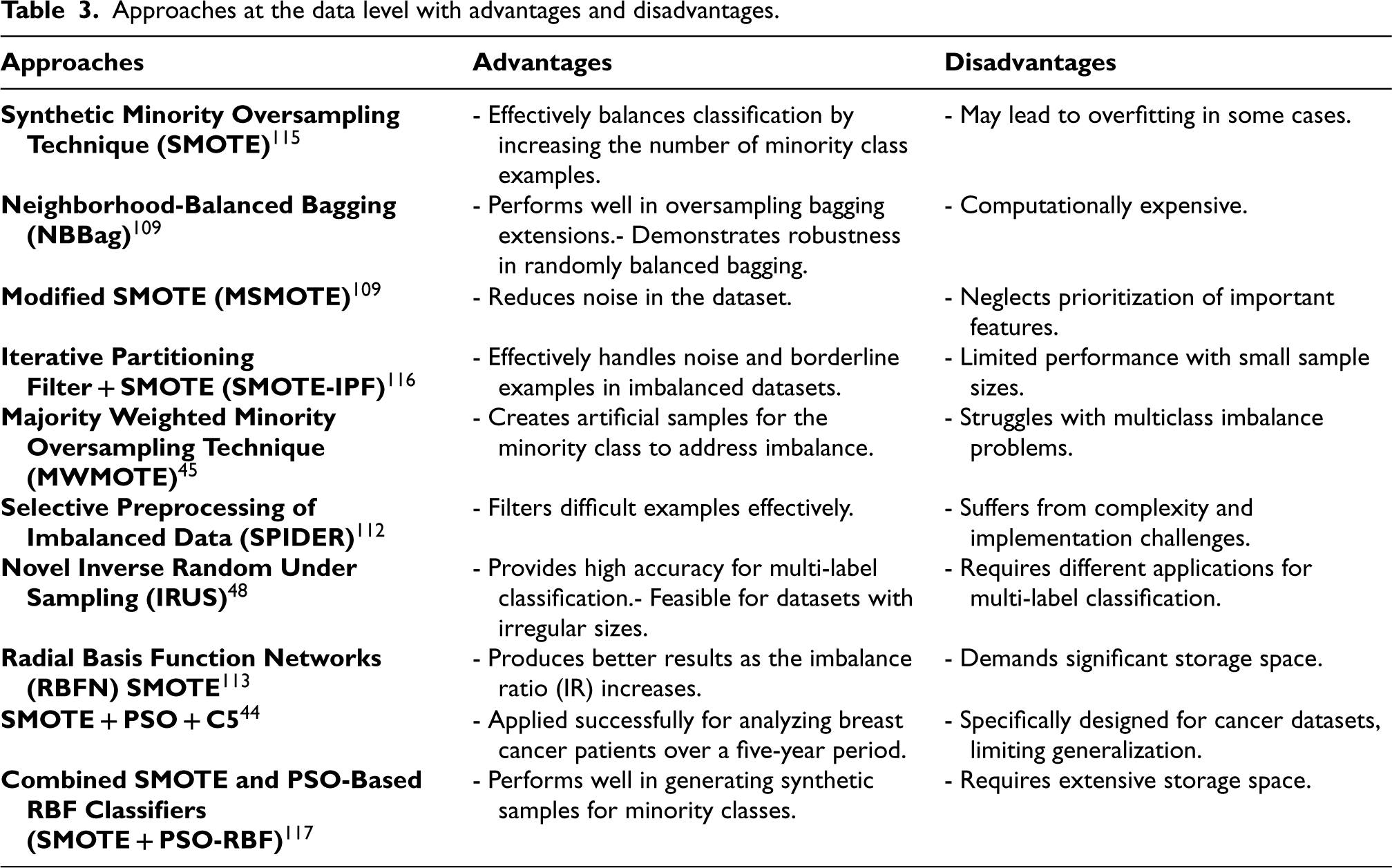
Approaches at the data level with advantages and disadvantages.
K-Means uses balanced data, which improves accuracy and reduces processing time compared to the initial imbalanced dataset. The process has two stages: first, we use K-Means to standardize the data, and then we use a support vector machine to sort the resulting balanced dataset. 118 Cross-validation is a fundamental method of evaluation of performance, but researchers are unfamiliar with imbalanced data. Traditional classifier algorithms assume a balanced class distribution. 119 Data Complexity Metrics (CMs) were introduced to detect dataset attributes that indicate classification difficulty and impact classifier accuracy. This research specifically developed two CMs tailored for imbalanced datasets to better explain the decline in classifier performance.
These measures utilize weighted KNN to account for the challenges posed by imbalanced class distributions. Class distribution skews in such datasets often lead models to favor majority classes, complicating classifier evaluation. While balanced accuracy is a commonly used statistic in these scenarios, it has limitations, particularly when class significance varies or when the distribution of class sizes is highly skewed. 120
Adaptive-SMOTE improves the SMOTE approach by adaptively picking clusters of inner and dangerous data from the minority class to create a new minority class, keeping the category boundary from expanding and enhancing the distributional characteristics of the initial data. 121 Resampling (SMOTE and US), PSO, and MetaCost are used with nine medical datasets and verified and compared the suggested strategy to the listed methods. A decision tree generates decision rules to simplify research results. 15 A study discussed a mix of metaheuristic Whale Optimization Algorithm (WOA) and local search Late Acceptance Hill-Climbing Algorithm (LAHCA) on the nearest neighbor imputation method for feature weighting. The Metaheuristic and Local Search-based Feature Weighted Nearest Neighbor Imputation (kNN + LAHCAWOA) method learned different k values for distinct test locations. The process is tested on benchmark EHR datasets with SVM, RF, and DNN classifiers (DNN). KNN + LAHCAWOA outperforms its competitors in classification performance because of its successful imputation mechanism. 122
Introduce R-Ensembler, a parameter-free greedy ensemble attribute selection approach, which uses the attribute-class, attribute-significance, and attribute-relevance measures from rough set theory to select a subset of attributes from a pool of distinct attribute subsets that are most relevant, significant, and non- redundant in predicting the presence or absence of different diseases in a medical dataset. 48 Another article 123 addressed data problems using ML workflow follows for coping with tiny data. The data source level is included with high-throughput computations and experiments, from the algorithm level, modeling algorithms for small data, and imbalanced learning. Table 4 provides a summary of the evaluation measures for several different ML techniques that aim to solve class imbalance.
Evaluation metrics of several ML algorithms for addressing class imbalance

Evaluation metrics of several ML algorithms for addressing class imbalance
The phenomenon of class imbalance in healthcare datasets poses considerable challenges that have the potential to substantially affect the efficacy of machine learning models. Our exhaustive review of the literature underscores several pivotal issues:
Conclusion
In conclusion, ensuring the accuracy and precision of machine learning models is imperative to avert issues such as majority intraclass bias and class imbalance within data types. This paper identifies and quantifies data biases and delineates steps that lead to practical strategies to mitigate their impact. The narrative review accentuates the significance of implementing robust data quality measures throughout the data lifecycle to mitigate misclassification bias and enhance model performance. Moreover, it elaborates on the challenges and perspectives associated with employing machine learning methodologies to address class imbalance in healthcare data. An overview of current methodologies is provided, encompassing data preprocessing approaches such as oversampling, undersampling, hybrid sampling, and ensemble learning strategies including bagging, boosting, and AdaBoost. Additionally, research on ensemble methods and hybrid resampling techniques, such as Iterative Partitioning Filter (IPF) and Edited Nearest Neighbors (ENN), has demonstrated promising solutions for managing imbalanced datasets, particularly in domains characterized by small sample sizes such as medical registrations through the application of undersampling and oversampling methods across all categories. This study further elucidates the effectiveness of various approaches in addressing data imbalance challenges and emphasizes the necessity for ongoing research and innovation in this realm. Future initiatives should prioritize the identification of key data types and the development of improved methodologies to enhance classification accuracy. Furthermore, integrating imaging techniques into the intelligent segmentation of health information presents a promising avenue for future research. The insights garnered from this research endeavor are instrumental in the development of more relevant and reliable AI systems.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by the Institute of Visual Informatics Universiti Kebangsaan Malaysia.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.