
Abstract
With the development of wireless communication technology, when users use wireless networks to meet various needs, wireless networks also record a large number of users’ spatial-temporal trajectory data. In order to better pay attention to the healthy development of students and promote the information construction on campus, a spectral clustering algorithm based on the multi-scale threshold and density combined with shared nearest neighbors (MSTDSNN-SC) is proposed. Firstly, it improves the affinity distance function based on the shortest time dis-tance-shortest time distance sub-sequence (STD-STDSS) by adding location popularity and uses this model to construct the initial adjacency matrix. Then it introduces the covariance scale threshold and spatial scale threshold to perform 0–1 processing on the adjacency matrix to obtain more accurate sample similarity. Next, it constructs an eigenvector space by eigenvalue decom-position of the adjacency matrix. Finally, it uses DBSCAN clustering algorithm with shared nearest neighbors to avoid to manually determine the number of clusters. Taking Internet usage data on campus as an example, multiple clustering algorithms are used for anomaly detection and four evaluation metrics are applied to estimate the clustering results. MSTDSNN-SC algorithm reflects better clustering performance. Furthermore, the abnormal trajectories list is verified to be effective and credible.
Keywords
Introduction
While people make full use of various smart portable devices to enjoy a convenient life or work, they also generate a large number of data records. These records contain geographic location information, time, speed, moving direction and interactive behavior, which reflect the law of the activities of individuals or groups of moving objects [1]. More and more researchers are effectively sorting and extracting these data, and then digging into and analyzing the valuable information. Therefore, spatial-temporal trajectory data mining has become a new research hotspot and direction in recent years. Abnormal trajectory pattern mining, as a kind of spatial-temporal trajectory data mining, aims to discover outlier data objects that are not similar to many moving objects, or even have no common characteristics. Nowadays, anomaly detection based on spatial-temporal trajectory has been widely used in urban traffic management [2], health monitoring [3], climate monitoring [4], and animal migration analysis [5]. Different application contexts correspond to different anomaly definitions and detection methods. Current research scholars mainly focus on anomaly definition, trajectory similarity metric, clustering, and anomaly detection algorithms, while including the use of parallel [6] and distributed methods [7] to improve algorithm efficiency.
Existing trajectory anomaly detection methods still have certain limitations despite their ability to detect defined trajectory anomalies in usage scenarios. On the one hand, most anomalous trajectory detection methods need to set specific thresholds with the help of domain knowledge in order to identify anomalous trajectories. However, the threshold value often needs to be adjusted after several experiments, which can lead to noisy data with similar characteristics to the anomaly being misclassified as anomalous data or being missed. This can make the accuracy of detection greatly reduced. On the other hand, the existing anomaly detection often focuses on the detection results, but ignores the semantic information in the detection process, which is not conducive to mining the anomalous events and causes behind the results. In addition, similarity calculation, as one of the key techniques in anomaly trajectory detection, is still more based on distance metric under Euclidean space, and lacks further analysis from the perspectives of dimensional correlation and overall similarity.
With the popularization of information technology in various campuses, we focus on applying the data analysis method combining geographical background and spatial-temporal data to campus management. This is a more efficient way to analyze correlations between students and to identify possible student anomalies in time. Through the above methods, the traditional statistical analysis methods are gradually replaced. By using the online data records from September 2019 to December 2019 recorded by the campus wireless network, the spatial-temporal trajectory data are extracted by preprocessing the online data. Then we implement a spectral clustering algorithm based on the multi-scale threshold and density combined with shared nearest neighbor (MSTDSNN-SC) to apply it to the anomaly detection of preprocessed spatial-temporal trajectory data. Thereby, we enrich the usage scenarios of anomaly detection of spatial-temporal trajectories and apply them practically in the construction of modern campus informatization. Our main contributions can be listed as follows:
We improve the shortest time distance-shortest time distance subsequences (STD-STDSS) model and apply it to the anomaly detection of spatial-temporal trajectories. Specifically, we introduce location popularity when measuring time similarity. Afterwards, we transform the initial similarity matrix into an undirected connected graph through the limitation of multi-scale thresholds. This improved model not only fully considers the similarity of the two dimensions of time and space, but also avoids the impact of the intersection between different clusters on the clustering results. We add the Principal Component Analysis (PCA) to save the need to manually specify the number of eigenvectors. We modify the defect that the spectral clustering algorithm could not determine the number of clusters automatically. In the original spectral clustering algorithm, the K-means algorithm is used to perform low-dimensional subspace clustering process, which causes different clustering effects due to different initial cluster center values. To solve the mentioned problems, we introduce the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm based on shared nearest neighbors. At the same time, by using this algorithm, the influence of parameters that need to be adjusted by multiple experiments on the clustering results of the algorithm is reduced, and thus the stability of the algorithm is improved. With the same simulation environment and parameters, it is proved that our pro-posed MSTDSNN-SC algorithm in anomaly detection based on spatial-temporal trajectory outperforms the classical algorithms (K-means algorithm [8], DBSCAN algorithm [1], Spectral Clustering (SC) algorithm [9] and Affinity Propagation (AP) Clustering [10]), some improved algorithms based on classical algorithms which were proposed in the last three years (MPSC [11], GS-DBSCAN [12] and LCSC [13]).
We propose a new anomaly detection technique based on spatial-temporal trajectory clustering based on real campus spatial-temporal trajectory data. In the process of preprocessing the dataset, the amount of data is compressed while retaining the implied semantic information. In terms of similarity measure, instead of measuring only spatial or temporal dimensions, a more comprehensive approach is adopted. The comparative experimental results show that the algorithm proposed in this paper not only shows better clustering performance than other clustering algorithms, but also the list of abnormal trajectories screened by this algorithm is effective and credible. In addition, it ensures a high degree of detection accuracy while minimizing the impact of adjusting different parameters on the experimental results. Finally, it is successfully used in real-life scenarios. This has great theoretical research and practical application significance for realizing the integration of digital technology with campus management and paying attention to the healthy development of students [14].
The rest of this paper is organized as follows. We summarize anomaly detection technology based on clustering algorithms in Section 2. In Section 3, we introduce the basic theory of SC algorithm. Based on SC algorithm, Section 4 describes the improvements of SC algorithm and the implementation of our improved MSTDSNN-SC algorithm applied to spatial-temporal trajectory anomaly detection. In Section 5, we pre-sent the real internet usage datasets of campus used in this paper firstly. Then we compare the performance of MSTDSNN-SC algorithm with those of several clustering algorithms. Finally, we make a conclusion for the advantages and disadvantages of the MSTDSNN-SC algorithm and suggest some future research directions in Section 6.
Taxonomy of trajectory outlier detection technique
Compared with other static data sets, the spatial-temporal trajectory data have certain particularities [15].
Uncertainty
The spatial-temporal trajectory data are limited by the accuracy of different collected positioning equipment or technologies, and there are spatial uncertainties such as signal attenuation and calculation errors. In addition, different timing lengths and different frequencies cause timing uncertainty. To sum up, the original spatial-temporal trajectory data have a large amount of position deviation.
Sparsity and skewed distribution
Spatial-temporal trajectory data can objectively reflect the activity law of moving objects (humans, animals, vehicles, etc.), and most of the activities of moving objects are periodic. Therefore, spatial-temporal trajectory data often exhibit sparse and uneven distribution characteristics.
Low density value
Despite the huge amount of spatial-temporal trajectory data, most of them are repetitive and useless.
So far, many researchers around the world have proposed many typical anomaly detection methods for spatial-temporal trajectory data based on the characteristics. According to different principles and application scenarios, the methods can be roughly divided into six categories: statistical methods, methods based on historical similarity, distance-based methods, methods based on grid division, cluster-based methods and classification-based methods. The statistical method is the simplest. It does not require any parameter input and derives parameters directly from the data in the dataset. Therefore, its effectiveness is greatly influenced by the amount of data and is more suitable to go for quantitative real data sets or quantitative fixed-order data distributions [16]. In contrast, the real situation data distribution is often complex and the actual data dimensionality is usually high, which is quite difficult to describe using the ideal probability distribution model and has a poor scope of application. The historical similarity-based approach can mine frequent patterns based on the large amount of historical trajectory data collected when the labels of the training data set are missing to build a global feature model. Then, the trajectory data that are different from the global feature model are determined as anomalous trajectories. The basic idea of distance-based anomaly detection algorithm is to first set the threshold parameter in advance with the help of the size of the distance. Then, the trajectories that are far away from the majority of trajectories in the spatial-temporal trajectory data set are judged as anomalous trajectories. The principle of grid-based anomaly detection is to transform the anomalous trajectory detection problem into the detection of anomalous grid cells by dividing the urban road network into grid cells of equal size. The classification-based anomaly detection method is to train a classification model that can distinguish between normal and abnormal. Such methods can usually be divided into two stages: firstly, the classification model is learned using the training dataset with labels, and then the classification model is used to judge the test instances. The clustering-based spatial-temporal trajectory anomaly detection generally uses some existing clustering algorithms to cluster the pre-processed trajectory data and then generate multiple data clusters. Next, the relationship between the object to be detected and the generated data clusters is examined. If it cannot be contained by any data cluster, it can be judged as abnormal trajectory. Further, deep learning has developed rapidly in recent years, and researchers often resort to the very strong learning ability of neural networks for anomalous behavior detection in video surveillance [6].
Considering aspects such as computational cost and algorithm efficiency, we adopt a clustering-based anomaly detection approach. One reason is because most neural network-based anomaly detection algorithms are based on publicly available datasets with labels, while our dataset is completely derived from real life without labels. Thus, many algorithms with good performance for supervised learning are not applicable on this dataset. Another reason is that although some articles use self-coding in deep learning for anomaly detection. However empirical studies show that the computational complexity of training autoencoders is much higher than traditional methods, such as principal component analysis. The efficiency of various detection techniques in applications is evaluated in the literature [17].
Spatial-temporal trajectory anomaly detection based on clustering algorithm
Clustering is a method of data aggregation based on the principle of data or pattern similarity. The purpose is to make the differences between objects belonging to the same category as small as possible, and the differences between objects in different categories are as large as possible. We can identify dense and sparse areas, thereby discovering global distribution patterns and relationships between data attributes. Anomaly detection is to find objects that are not strongly related to other objects. Therefore, clustering can be used for anomaly detection. Cluster-based anomaly detection can be seen as a form of unsupervised learning. Thus, the clustering algorithm is suitable for the anomaly detection of trajectory data without knowing the data labels in advance.
The spatial-temporal trajectory anomaly detection based on clustering algorithm generally first uses some existing clustering algorithms to cluster the preprocessed trajectory data, and then multiple data clusters are generated. Finally, the relationship between the data point to be detected and the generated data cluster is examined. If it cannot be contained by any data cluster, it can be judged as an abnormal trajectory. Clustering algorithms commonly used for trajectory anomaly detection include the partition-based clustering algorithm [8, 18], hierarchical clustering [19, 20, 21], density clustering [22, 23], spectral clustering [24, 25], Multiview Clustering [26, 27], etc. Choosing different clustering algorithms according to the characteristics of trajectory data has a great impact on the effectiveness of detecting abnormal trajectories. The following is a brief description of how several common clustering algorithms are used for trajectory anomaly detection.
The partition-based clustering algorithm needs to specify the number of clusters or the clustering centers of clusters. This type of algorithm initially divides a given data set into several subsets and then traverses until the cluster is sufficiently cohesive and the clusters are sufficiently dispersed. In the end, the cluster center is obtained. The K-means algorithm is one of the most commonly used algorithms. A framework for trajectory anomaly detection is proposed in Reference [18]. The framework consists of a trajectory pattern learning model and a real-time abnormal trajectory detection model. In the trajectory learning model, a coarse-to-fine clustering strategy is used, i.e., the trajectory is first classified into coarse-grained clusters according to the main flow direction (MFD) vector, and then the K-means algorithm is used in each cluster to obtain fine-grained clusters. In the end, the path model of each cluster is established. In the real-time abnormal trajectory detection model, the new trajectory is compared with the existing motion pattern to determine whether it is an abnormal trajectory. Since the initial selection of data points as cluster centers is random, the accuracy of clustering is unstable. Although there are improved algorithms for this deficiency, such as K-means++, the division-based clustering algorithm always requires a predetermined number of clusters. This has to be done by adjusting the parameters through several experiments, which is difficult to determine in practical applications.
Hierarchical clustering, as the name implies, is clustering layer by layer to segment large categories from top to bottom. This method is called divisive hierarchical clustering. It is also possible to aggregate small categories from bottom to top, which is called agglomerative hierarchical clustering. Reference [20] proposed an abnormal detection method of driving behavior based on agglomerative hierarchical clustering. It first measures the similarity based on the structural distance. Then the idea of Laplacian feature mapping is added to automatically determine the number of clusters. Finally, agglomerative hierarchical clustering is used for the feature matrix after reducing dimension. The obtained cluster results are marked as normal or abnormal clusters according to the threshold value. Compare the objects to be tested with the clusters to determine whether they are abnormal. Hierarchical clustering produces multi-layer clustering results. So, we can choose the best result from the multi-layer results as the final result. However, when the spatial sample objects are unevenly distributed, the fixed split threshold and the aggregation threshold make the clustering effect of hierarchical clustering poor. Besides, hierarchical clustering is to connect corresponding nodes from strong to weak by calculating the similarity between nodes, so that the clustering result obtained may not be the global optimal. In 2020, Ding et al. [16] suggested a multi-dimensional feature clustering anomaly detection method based on time series. By extracting the multi-dimensional features of ADS-B data, such as longitude, latitude, speed and heading information, the Hausdorff distance is used to calculate the similarity of the trajectory data. Eventually, a hierarchical clustering method is combined to detect anomalous behavior in the trajectories. Hierarchical clustering avoids the trouble that division-based algorithms need to specify the number of clusters. However, when the spatial sample objects are unevenly distributed, the fixed segmentation threshold and aggregation threshold make hierarchical clustering ineffective. In addition, hierarchical clustering is done by calculating the similarity between nodes and connecting the corresponding nodes from strong to weak. The clustering results obtained by virtue of the distance between data alone are not necessarily globally optimal. The time complexity of the whole algorithm is too high because the distance between the new cluster and other clusters has to be calculated after each merge to form a new cluster.
The density-based clustering algorithm performs clustering based on the density distribution of samples. Normally, density clustering starts from the perspective of sample density and continuously expands clusters to obtain the final clustering results by considering the connectivity between samples. DBSCAN [1], LDBSCAN [28] and OPTICS [29] are typical density-based spatial clustering algorithms. Taking the DBSCAN algorithm as an example of the density clustering algorithm, the DBSCAN clustering algorithm can divide the regions with sufficient density into several categories under noisy conditions, and there is no need to specify the number of clusters. Bi-rant et al. [30] proposed a three-step abnormal spatial-temporal detection method. The first step is to use a modified DBSCAN algorithm on the large databases. The second step is to verify whether the potential anomalies detected by clustering are real spatial anomalies by checking their spatial neighbors. Finally, check the temporal neighbors of the spatial anomaly object determined in the previous step. If there is no difference between the eigenvalues of the spatial anomaly object and the eigenvalues of its temporal neighbors, it is not a spatial-temporal anomaly. Otherwise, it is judged as a spatial-temporal anomaly. In 2017, an approach based on an enhanced clustering algorithm was proposed to detect spatial-temporal trajectory outliers in Reference [31]. First, the minimum description length (VMDL) rule based on velocity is used to simplify the trajectory into ordered line segments. Secondly, the line segments are divided into different categories based on the DBSCAN algorithm to model local normal motion patterns. Thirdly, outliers are detected using the two-level detection algorithm. The DBSCAN algorithm is insensitive to noise and is able to find clusters of arbitrary shapes. However, the disadvantage of DBSCAN is that the convergence time becomes longer for too large sample data and is more influenced by the parameters.
In order to make the data not restricted by the shape and the clustering can converge to obtain the global optimal solution, a spectral clustering algorithm is proposed. The spectral clustering algorithm is based on the theory of spectral graph partitioning to gradually partition the graph into a number of disjoint subgraphs. Subgraphs with the same properties have high similarity and subgraphs with different properties have low similarity. In 2018, Li et al. [24] put forward an aircraft trajectory similarity model based on speed correction coefficients. Firstly, the aircraft trajectory points are extracted to construct the corrected trajectory, and the spectral clustering method is used to cluster to realize the trajectory classification consistent with the standard instrument departure procedure. Next, use statistical methods to identify the center trajectory in each cluster and calculate the similarity distance from each trajectory to the center trajectory. Then extract the similarity distance between the trajectories and the flight distance from each type of trajectory after classification, and use them as anomalous feature factors for identifying aircraft anomaly trajectories. Normalize and weight the two abnormal feature factors to obtain the suspicious degree. Lastly, verify the suspiciousness of the flight identified as an abnormal trajectory according to the abnormal detection rate. If it exceeds the given suspiciousness threshold, it is confirmed as an abnormal trajectory. The spectral clustering algorithm can cluster in any shape of the sample space and converge to the optimal solution. This algorithm requires only the similarity matrix between the data and is effective for dealing with clustering of sparse data. In addition, because of the dimensionality reduction involved in spectral clustering algorithms, the complexity of handling high-dimensional data is lower than the previous types of clustering algorithms.
According to the current research status in using clustering algorithm for anomaly detection, it is necessary to select the main features of data samples and construct a similarity function. Then the similarity between the data is judged in accordance with the similarity function. Finally, the data samples are clustered by the calculation results. the calculation results. Obviously, different clustering algorithms have different advantages and disadvantages as well as applicable conditions. Different similarity functions and different clustering algorithms can affect the final results. Therefore, considering the pre-condition required by the above clustering algorithms before execution and the ability to process the data, we choose a similarity measurement function that integrates both temporal and spatial dimensions. In addition, we use a spectral clustering algorithm and improve it for subsequent anomaly detection. These will be described in detail in Section 4.
Spectral clustering algorithm
The spectral clustering algorithm is based on graph segmentation. Specifically, we use
Although there are a variety of common spectral clustering algorithms due to different spectral mapping methods and criterion functions [9, 35, 36], the main implementation steps are roughly similar. It can be summarized as follows: Suppose there are
where
Then the degree matrix
where
Next, extract the eigenvectors corresponding to the top
After getting the new characteristic vector space
Finally, traditional clustering methods such as K-means algorithm are used for each row of
Algorithm 1 shows the detailed steps of the spectral clustering algorithm proposed by Ng et al [9].

Compared with the traditional K-means algorithm, the SC algorithm has a significant improvement. On the one hand, the K-means algorithm only performs well on circular datasets or spherical datasets. The SC algorithm is applicable to datasets without considering their sample space of any shape. On the other hand, the K-means algorithm is easy to fall into the local optimal problem when the datasets are non-convex, but the SC algorithm can converge to the global optimal solution.
Although spectral clustering algorithms have been extensively studied, many problems still need to improve, including the following three aspects:
The construction of similarity matrix. The earliest version of the SC algorithm directly uses the sample adjacency matrix to divide the graph [39]. The later SC algorithm uses the Gaussian kernel density function to construct the similarity matrix The selection of the figure for feature vectors. In machine learning feature extraction, the maximum eigenvalue usually contains the maximum information in the direction of the feature vector [39]. The SC algorithm usually selects the feature vectors corresponding to the first The determination of the number of clusters. The SC algorithm in low-dimensional solution space usually uses the K-means algorithm for two-stage clustering. Due to the randomness of the K-means algorithm in selecting cluster center points, it may cause empty clusters. It is also easy to fall into a local optimum. Besides, K-means algorithm needs to specify the number of clusters artificially. In a real-world scenario, it has no prior knowledge of the number of categories that are most appropriate for a given dataset. So, the determination of the number of clusters does affect the overall accuracy and stability of the SC algorithm.
By means of the analysis in Section 3, there is no doubt that the defects of the SC algorithm need to be optimized to meet the ever-changing application scenarios. A method on the basis of SC algorithm is proposed to solve all the above problems. In this part, we will elaborate on the improvements.
Optimization of similarity measures
Based on the characteristics of the spatial-temporal trajectory data collected by wireless network, it is far from enough to use the distance between the trajectories as a similarity measure. Most trajectory similarity measures are analyzed from the perspectives of time series of trajectories or spatial dimensions of trajectory points. The time series similarity focuses on the change of the series over time. The similarity based on the spatial dimension of trajectory points mainly considers the variation and distribution of trajectory points in geographic locations, and takes the spatial attributes as the main criterion for judging the similarity. The relationship between the information features of both temporal and spatial dimensions in spatial-temporal trajectories is independent of each other. Therefore, it is necessary to consider the time series and spatial information to quantify the similarity between the trajectories at the same time. We draw on the STD-STDSS model originally used to measure user similarity in the literature [40] and introduce the popularity of location visits to modify the time distance model.
In fact, the time and space characteristics are mutually constrained but independent of each other. In previous studies, the value of similarity results has been defined between 0 and 1. Similarly, we define a collection of trajectory sequences
First, we follow the method of calculating spatial similarity in the literature [40], i.e., we begin with the basic judgment of spatial similarity based on the longest common subsequence (LCSS) [41] and obtain a set of common subsequences
A larger
Then, the time distance between
Let
where
After adding the location popularity, here is the formula for calculating the redefined time distance.
Taking the tracing point
If the locations of the recording points are not the same, it can be considered that there is no similarity between
Therefore, the time similarity of trajectory
From the calculation process, it can be found that the calculation results of the WSTD model have asymmetry. Thus, the time similarity between
Eventually, the spatial-temporal similarity
The preliminary result of the trajectory similarity measurement calculated through the above steps should be between 0 and 1. Moreover, if
Based on the above process, the construction of each element in the initial similarity matrix
According to the description in Section 3, the SC algorithm clusters the data uses the similarity matrix or the eigenvectors in the Laplacian matrix to divide the data during the clustering process. Therefore, each of the clusters can be regarded as connected components to a certain extent. The intersections between different clusters affect the construction of the similarity matrix, leading to the propagation of misinformation. The accuracy of the final clustering is affected [44]. For these considerations, taking the trajectory
where
The spatial scale threshold is chosen to make sure that the set of neighbors of each data point has a sufficient number of samples, which may include some intersection points to ensure the connectivity between each small subset. At the same time, the value of
If
Step 3 of Algorithm 1 mentioned in Section 3 is essentially statute of the dimension, i.e., reducing the dimensionality from
With this method, the number of eigenvectors does not need to be manually specified. Then the selected
Finally, the matrix
Generally, after dimensionality reduction, it is also necessary to use the traditional K-means clustering algorithm to cluster each row vector of the matrix
There have been many algorithms in the research of density clustering. DBSCAN algorithm is a typical density clustering algorithm. Compared with K-Means, it is suitable for both convex and non-convex data sets. The DBSCAN algorithm clusters based on the idea of ??high-density connected regions, that is, the regions in the space that are sufficiently dense and meet the connectivity conditions are marked as the same cluster. It requires the input of two parameters
Although the parameters required by the DBSCAN algorithm are often determined by the k-distance graph, the position of the inflection point in the image may be difficult to determine in actual applications. So, we consider improving the selection of the parameters of the algorithm. In response to this problem, many different density definitions and corresponding clustering algorithms have appeared in recent years [46]. We noticed that in contrast to the DBSCAN algorithm, which defines the density as the number of data points in a given neighborhood, the k-nearest neighbor model can dynamically represent the local distribution characteristics. What’s more, only one parameter needs to be set and it is easy to select. However, when the k-nearest neighbor model is used to deal with high-dimensional data sets, it also becomes inaccurate in measuring local density due to the sparsity of the high-dimensional data space. Then a special similarity measure based on the K-nearest neighbor algorithm was proposed, named The Shared Nearest Neighbor (SNN) [47]. It is different from the traditional similarity measure. SNN is based on a kind of intermediate information to express similarity, i.e., the similarity of objects is measured by the “neighbors” shared between them. The specific realization of SNN is to find common neighbors from the set of k-nearest neighbors of two objects. The more common neighbors, the higher the similarity of the two objects, and vice versa. This method not only maintains the advantages of the k-nearest neighbor model, but is also suitable for high-dimensional spaces. We are inspired by the literature [48] and decide to combine the DBSCAN algorithm with shared neighbor affinity to solve the above shortcomings. The specific implementation process is as follows.
Considering each row of the matrix T obtained in Section 4.2 as a data point, it can be written as
The KNN distance reflects the local distribution of the data point. The smaller the KNN distance, the denser the neighbors around the data point. Then the data point is more likely to be distributed in the dense area. Otherwise, the more likely it is to be distributed in the sparse area.
As for the number of SNN of
where
Based on Eqs (20) and (4.3), the concept of shared neighbor affinity is now given, that is, the ratio between the number of shared neighbors of the object and the KNN distance. We denote the shared neighbor affinity as
It can be found from Eq. (22) that the greater the number of shared neighbors of an object and the smaller the KNN distance, the greater its SNN affinity. This indicates that the greater the degree of affinity between an object and
The above formula shows that the affinity of the core points is higher than the average level of their neighbors, so the core points are distributed in dense areas in space and have a greater similarity with their neighbors.
To sum up, we restate a DBSCAN algorithm process based on shared nearest neighbors as shown in Algorithm 2.

The whole process of the MSTDSNN-SC algorithm still includes three major steps: the establishment of similarity matrix, the construction of feature vector space, and low-dimensional subspace quadratic clustering.
Suppose a trajectory sequence dataset

Experiments
In order to verify the accuracy and effectiveness of the MSTDSNN-SC algorithm for detecting abnormal trajectories, we use a real campus network data set of from a certain area of China as an example, and compares it with several clustering algorithms, including the K-means algorithm, Spectral clustering algorithm, DBSCAN algorithm, Affinity Propagation (AP) clustering algorithm, Spectral Clustering Algorithm Based on Message Passing (MPSC) algorithm, DBSCAN algorithm based on the similarity matrix between the geodesic distance and share nearest neighbors (GS-DBSCAN) algorithm and spectral clustering algorithm based on local covariance matrix (LCSC) algorithm, etc. The MPSC algorithm is a combination of AP clustering and spectral clustering, while the GS-DBSCAN algorithm constructs a similarity matrix based on geodesic distances and shared nearest neighbors and then performs clustering using the DBSCAN algorithm. The LCSC algorithm uses the local covariance matrix to set a threshold to construct a similarity matrix and then uses the spectral clustering algorithm.
Experimental data set and metrics
In fact, the real university spatial-temporal trajectory data comes from the log records of 6202 student users who stayed at nearby access points after accessing the campus wireless network, which spans four months. Each of these folders stores the Internet log files of all student users for each day. Table 1 shows the format of the original spatial-temporal trajectory data. Each row represents a trajectory sampling point, including phone MAC address, access point MAC address, received signal strength indicator(RSSI), time and other information data.
Original data format
Original data format
As we know, the evaluation metrics of the clustering algorithm usually include internal and external indicators. Internal indicators are suitable for the situation of unknown data labels, while external indicators have a good reflection on the data with known data labels. As the datasets used in this experiment do not have labels, several internal evaluation metrics are used to judge the accuracy of clustering results, with the inclusion of Silhouette Coefficient (SI) [49], Davies-Bouldin Index (DB) [50], Calinski-Harabasz Index (CH) [51] and Dunn Index (DVI) [52]. The meaning and calculation methods of these indicators are illustrated below.
SI measures how similar each point is in its own cluster compared to the points in other nearest clusters. The expression of SI is explained as Eq. (24).
where
After calculating SI for each point, the average value is computed to obtain the SI of the clustering results. A higher SI value means a better class division.
DB is the maximum value of the ratio of the sum of the average distances between any two categories of within-class distances to the centroid distance between the two clusters. It can be calculated by Eq. (25):
where
CH measures the compactness within the class by calculating the sum of squares of the distances between each point in the class and the center of the class, and measures the separation of the dataset by calculating the sum of the squares of the distances between various centers and the center of the dataset. CH is obtained from the ratio of separation and compactness. The definition of CH is shown in Eq. (26).
where
The definition of DVI is the ratio of the shortest distance between any two clusters to the maximum distance within any cluster.
The larger the DVI value, the closer the clustering results are within the same cluster, and the farther the separation between different clusters.
Due to many factors such as signal strength of base station, user type, storage method, etc., the collected spatial-temporal trajectory data cannot be directly applied to subsequent data mining work. Hence, the spatial-temporal trajectory data must be preprocessed first. In detail, we collect the list of all enrolled students and extract the valid information including student name, apartment number, gender, mobile MAC address, college, class, and major. The first step is to match the cell phone MAC address of each trace sampling point in the original data set with the device MAC address of Stu A. If the match is successful, it means that the trace sampling point is Stu A’s trace, then the trace data point will be temporarily saved. Thus, we create a separate trace log file for each student user, and set the name as Class-Name-Number-Trace. Here, we take Class1-Stu A-No.0001-Trace file as an example to show the detailed process of data pre-processing. The first step is to match the cell phone MAC address of each trace sampling point in the original data set with the device MAC address of Stu A. If there is a successful match, it means that the trace sampling point is Stu A’s trajectory. So, we temporarily save the trajectory data point. Then, we do the following processing on these temporarily saved trajectory sampling points.
Format conversion
The original spatial-temporal trajectory data is recorded in computer language format, involving UNIX time format and base station code. Therefore, it is necessary to transform the data into a special format before it can be used in the subsequent data mining work. We represent the time data of each trajectory point in the data set as the whole number of days and their fractional values since January 0, 0000, so that the 24-hour time of a day is converted to between
Data cleaning
Students will produce duplicate redundant information in the process of surfing the Internet, and we compress and merge the trajectory points with the same location area and time interval within 5 minutes according to the actual demand. And the intermediate value of the time data is taken as the new time data after merging. In addition, the noise data caused by abnormal acquisition equipment and other reasons can also have an impact on the subsequent method. Here we combine the RSSI and reject it by judging whether the time stamp of the latter track point is larger than that of the previous track point.
Anonymous processing
In order to protect the user’s private information, the key private information in the original spatial-temporal trajectory data must be anonymized to make it impossible to trace the source.
Map matching
Suppose Stu A creates a series of behavior records in the wireless network as
The trajectory information data obtained after the above processing is stored in the trajectory log file of Stu A. In the log file, trajectories are points ordered by time. Each point contains normalized x and y coordinates, Internet access location, time and other information. Given that the spatial-temporal trajectory data recorded in the wireless network covers a long period of time, in order to reduce the subsequent computation time, a parallel sliding time window method is also needed for adaptive segmentation before the similarity metric is performed.
After obtaining the preprocessed trajectory data, we randomly select 50 users with complete Internet records, and extract their trajectories within four months to form their individual spatial-temporal trajectory dataset, referred to as the ISST dataset. In addition, we select any 5000 trajectories from all users to form the group spatial-temporal trajectory dataset, which is referred to as the GSST dataset. These two datasets are used in our experiments in subsequent chapters.
Parameter selection
In this paper, several different clustering algorithms and MSTDSNN-SC algorithm are used for comparative experiments. Among them, K-means algorithm, DBSCAN algorithm and AP clustering algorithm all use the results of similarity matrix W_final for subsequent clustering. MPSC, GS-DBSCAN and LCSC use the similarity matrix calculated by the similarity function proposed in their respective papers. In addition, in order to better verify the necessity and rationality of the improved MSTDSNN-SC algorithm, we set up the following comparative experiments, which are: the traditional SC algorithm by using the initial similarity matrix
The parameters that need to be determined in the MSTDSNN-SC algorithm is the number of nearest neighbors
To select the optimal nearest neighbors, we increase the number of neighbors
It can be seen from Fig. 1 that when
The specific parameter settings of the above algorithm used in ISST dataset are summarized in Table 2. Table 3 shows the specific parameter settings of the above algorithm used in GSST datasets.
Comparison experiment parameter in ISST dataset
Comparison experiment parameter in ISST dataset
Comparison experiment parameter settings in GSST dataset
Changes in the various metrics of the ISST dataset.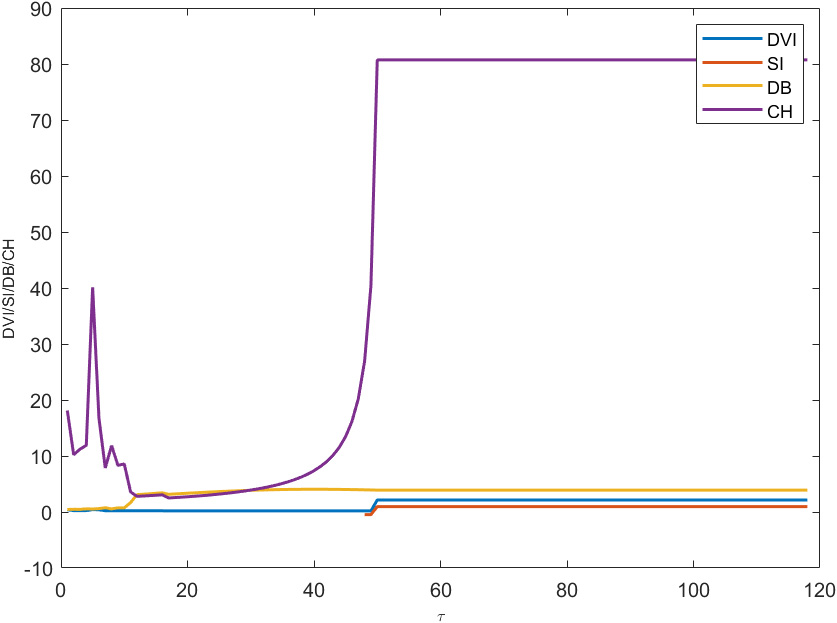
The simulation environment is MATLAB R2019a and executed on a 1.60 GHz Intel Core i5-8265U CPU equipped with 8 GB RAM and Windows 10.
Results of ISST dataset
The ISST data in this experiment is derived from the real campus wireless network Internet dataset after preprocessing. The related introduction is described in Sections 5.1 and 5.2. In the experiment, we select all the trajectory datasets of the same user in four months (September 2019 to December 2019). After the data preprocessing operation as described in Section 5.2, anomaly detection is performed separately for each user in the ISST dataset using the MSTDSNN-SC algorithm. We take the trajectory datasets of several users with relatively comprehensive data records as an example, and use the various clustering algorithms mentioned above to evaluate them separately. Table 4 shows the results in terms of SI, DB, CH and DVI on ISST dataset, where the symbol “/” indicates the meaningless parameters.
Performances of clustering algorithms for ISST dataset
Performances of clustering algorithms for ISST dataset
As reported in Table 4, for the above three users, the SI of the MSTDSNN-SC algorithm is better than other clustering algorithms. Not only that, the SI of the MSTDSNN-SC algorithm is close to 1. According to the description in Section 5.1, it indicates that our algorithm can perform better in the clustering. What’s more, this conclusion can also be proved from the DVI indicator. As it is known for the introduction of Section 4.3, several related algorithms based on the DBSCAN algorithm can directly identify outliers, so the NO column shows the number of outliers that are temporarily classified as a cluster
For User_1, our algorithm achieves the best performance in the index evaluation of SI, CH and DVI, and the performance of CH and DVI is far higher than other algorithms. In the DB index, although the best DB value is obtained by using the GS-DBSCAN clustering algorithm, which is 0.7154. It can be known that the clustering result of the algorithm is not reasonable enough according to the value of NC and NO. The DB value of the AP algorithm ranks second in the order from small to large. The same reason is applicable to the AP clustering algorithm. In contrast, the MSTK-SC algorithm performs better than our algorithm in the evaluation of DB, but the results of the other three indicators are slightly inferior to MSTDSNN-SC algorithm. Moreover, the K-means algorithm is used in the MSTK-SC algorithm, so the result is not stable.
For User_2, there is also such a problem that the AP clustering algorithm is used to obtain the best DB value. It can still be inferred from the value of NC and NO that the clustering result of the algorithm is not reasonable enough. Additionally, the MSTK-SC algorithm, GS-DBSCAN algorithm and K-means algorithm achieve better DB values, but the results of the other three indicators are not as good as our algorithm. Furthermore, the parameter adjustment process in the above algorithms is also more troublesome.
For User_3, several algorithms that are better than our algorithm on the DB indicator also have the problem that their performance of the other three indicators is not as good as our algorithm. Especially for the Original-SC algorithm, SI even appears negative. Such a clustering result is obviously unjustifiable. In inclusion, the data in the NC and NO columns show that the class clusters divided by the GS-DBSCAN algorithm are not reasonable.
In reality, when evaluating the overall ISST dataset using the SI metric, our algorithm achieves a mean value of 0.9528 among 50 users. As described in Section 5.1, the closer the value of the SI metric is to 1, the better the clusters are. In other words, the clusters partitioned using the MSTDSNN-SC algorithm are reasonable. Through the analysis of the table, considering the clustering index evaluation results and the rationality of the number of clusters, our algorithm performs best and is the most stable. This is due to the fact that the construction of the similarity matrix not only fully considers information on the temporal and spatial dimensions of the trajectory and location popularity, but also processes the intersection points through multi-scale thresholds. And in the last step, the DBSCAN algorithm based on shared nearest neighbors is used to directly identify the abnormal trajectories while clustering. To sum up, the result is extremely reliable.
In this part, MSTDSNN-SC algorithm is subjected to further test with GSST dataset. Again, the performances of several algorithms are benchmarked in terms of SI, DB, CH and DVI. Table 5 displays the performance of clustering algorithms. The symbol “/” in the table means that the entries had no actual values.
Performances of clustering algorithms on GSST dataset
Performances of clustering algorithms on GSST dataset
As can be seen from Table 5, although the MSTDSNN-SC algorithm does not perform as well as K-means and DBSCAN algorithm in the evaluation of DB metrics, it performs best in all the other three metrics compared to the four classical algorithms. In particular, the DBSCAN algorithm achieved the best results in DB metrics, but its SI metrics showed negative values, which is obviously undesirable.
In a comparison between the Original SC algorithm and the DB-SC algorithm, it is not difficult to find that the metrics of all four categories are improved after replacing the K-means algorithm with the DBSCAN algorithm. Observing the metrics of MSTK-SC and Original SC algorithm separately, we can see that all four metrics improve after using the similarity matrix W_final. And our algorithm not only greatly outperforms the Original SC algorithm in the evaluation of the four categories of metrics, but also has fewer parameters compared to the MSTD-SC algorithm. Moreover, it is more stable than the clustering results obtained using MSTK-SC algorithm.
Before comparing with several clustering algorithms proposed in the last three years, the first thing to note is that the GS-DBSCAN algorithm has good evaluation results on the four indicators. But combined with the number of outliers as high as 4979 categories, it can be seen that the actual division effect of the algorithm is not convincing. Therefore, the performance of the GS-DBSCAN algorithm is not being analyzed below. Like the ISST dataset, the MSTDSNN-SC algorithm achieves very good evaluation results in the SI and DVI indicator, indicating evidence of great potential in clustering. Furthermore, our algorithm ranks second in the CH indicator evaluation. Although the MSTDSNN-SC algorithm does not look very good at first glance in the indicator DB, the LCSC algorithm performs poorly in the other three indicators. It should be noted that the MPSC algorithm did not achieve good results on our dataset, which is more suitable for low-dimensional datasets, depending on the analysis of the literature [11].
The above-mentioned clustering evaluation indicators can only reflect the credibility of the results of the clustering algorithm. Whether the MSTDSNN-SC algorithm can effectively screen out possible abnormal trajectories still needs further verification. For this purpose, we treat each data point in cluster
First, we analyze from the perspective of the user’s abnormal trajectory. Analyzing trajectory anomalies based on periodic historical trajectories is a common method for anomaly detection. Taking User_3 as an example, since the user’s periodic activities have a certain regularity, a certain period of four months (September 2019 to December 2019) is selected according to the week corresponding to the abnormal trajectory. We divide a day into 12 time periods, each time period is 2 hours, which is convenient for displaying the abnormal characteristics of trajectory segments within a time period. We search for the trajectory sequence that meets the periodicity and the same time period within four months based on the list of abnormal trajectories. In order to avoid affecting the verification process, the comparison date of records with less than two records in the specified time period is excluded. Then separately display the locations visited by User_3 during the same period of time on different dates with a periodicity, as shown in Fig. 2.
Distribution of Internet locations from 2 pm to 4 pm every Monday.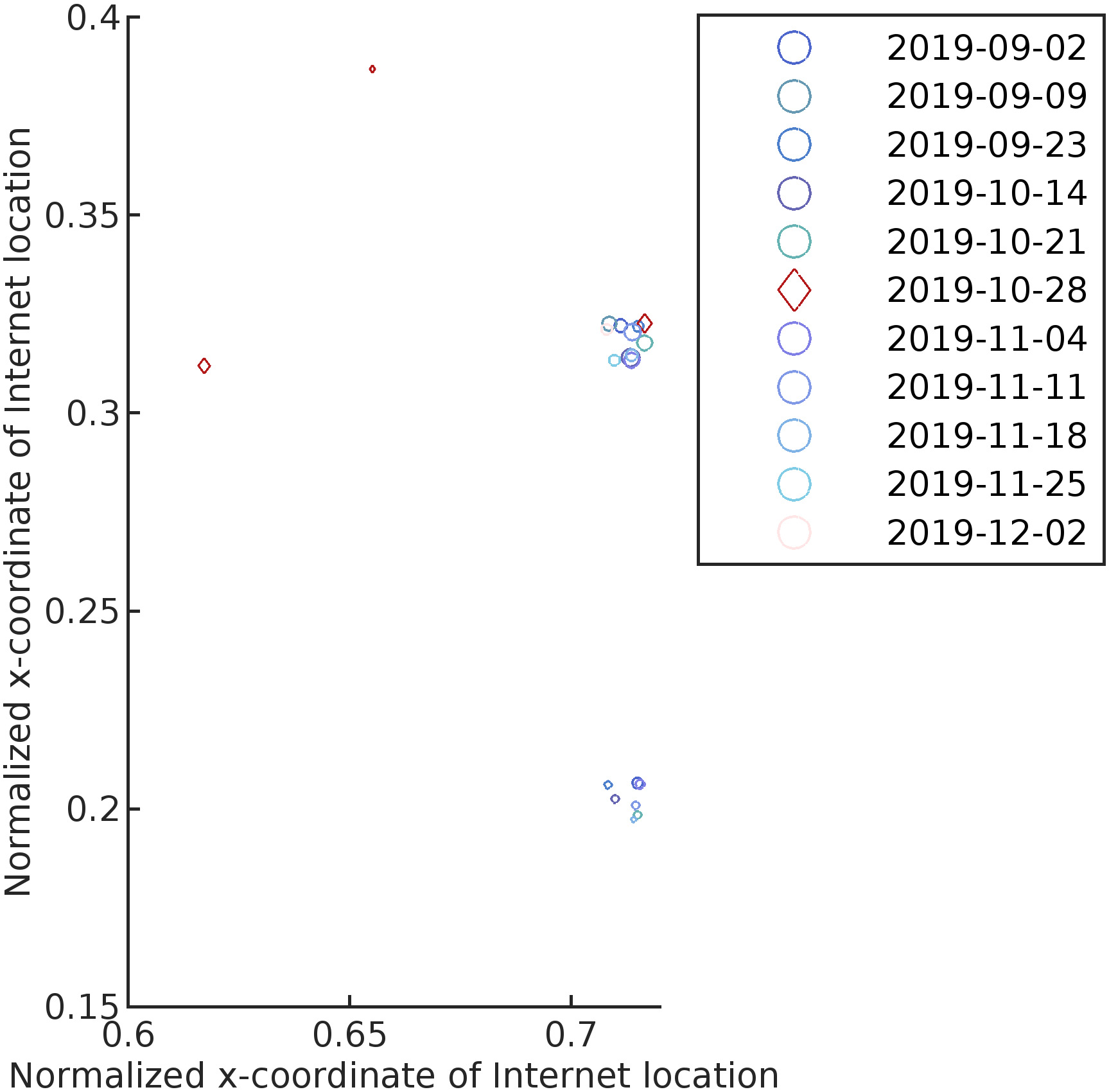
As it can be seen from Fig. 2, provided that there is a sufficient trajectory sequence, User_3 basically visited two locations between 2 and 4 pm on Mondays. On October 28th, two additional locations were visited. Compared to other Monday afternoons in the same time period, this trajectory is indeed abnormal.
Next, we analyze the abnormal trajectory pattern of the group. Take one of the filtered abnormal trajectories as an example, trace the source to the corresponding User A and date. Select User B who is in the same major and class with high similarity and extract one-day spatial-temporal trajectory data of the two people. For convenience, we divide one day into 6 time periods, each time period contains 4 hours. The number of places visited by Users A and B during each time period in this day is shown in Fig. 3. Figure 4 shows the number of Internet loggings generated by two users over time periods of the day.
The number of places visited at various times on the same day.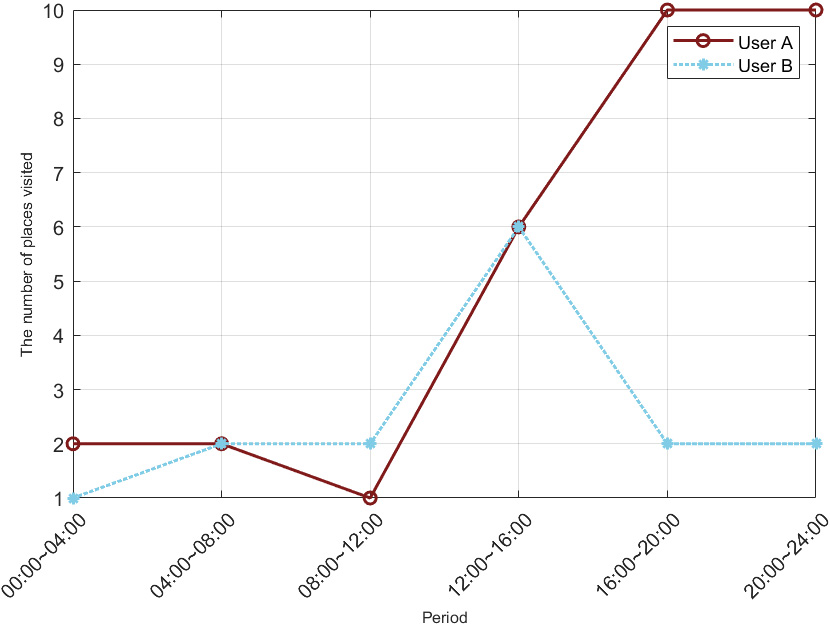
The number of log records generated by going online in a day.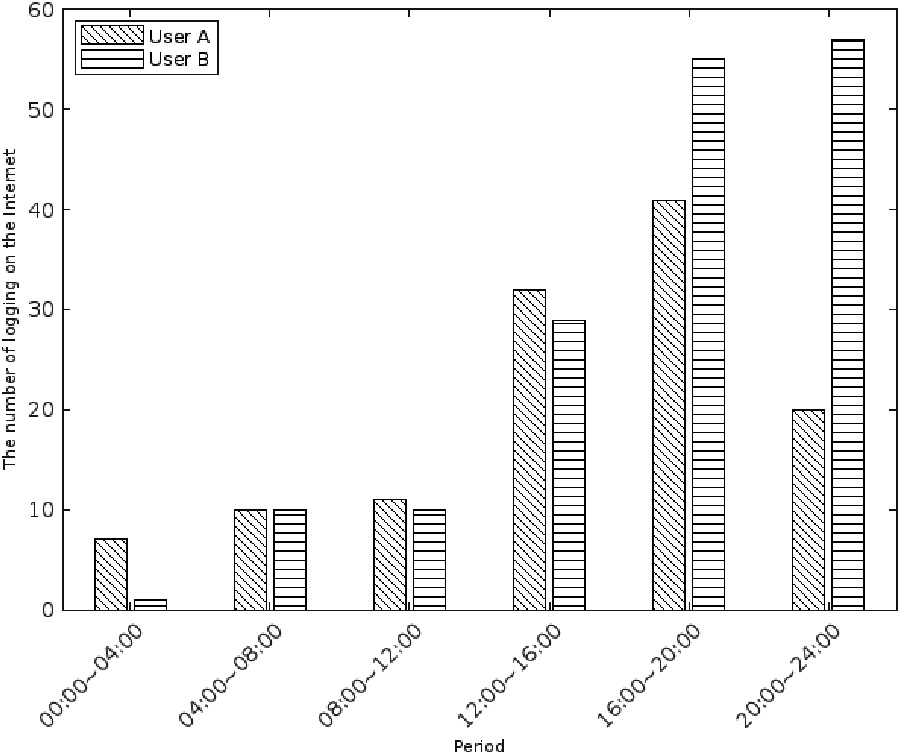
Distribution of Internet locations in 16:00 to 20:00 and 20:00 to 24:00.
As can be seen from Fig. 3, there is a significant increase in the number of places visited by User A during the period 16:00–20:00 and 20:00–24:00. Based on the number of loggings in Fig. 4, both users surf the Internet at a high frequency during two periods, so we can rule out error detection due to too little data.
We can also refer to the user’s individual trajectory anomaly detection analysis method, to map out two users s in 16:00 to 20:00 and 20:00 to 24:00 two time periods online location distribution as shown in Fig. 5.
In Fig. 5, four different color and shape legends represent User A and B two different time periods. It is easy to see that User A’s Internet locations visited some other locations in addition to overlapping with some of User B’s locations. The interference factor of signal strength from different access points is excluded. It can be determined that User A’s trajectory on this day is indeed abnormal.
Therefore, the MSTDSNN-SC algorithm for spatial-temporal trajectory anomaly detection proposed in this paper is reasonable and effective. It should be aware that the results of the above-mentioned anomaly detection analysis are only to provide reference information for relevant campus managers and play a role in decision support. Whether to pay more attention to a certain student based on the test results still requires school administrators to make a choice based on the specific real situation.
This paper introduces a method for abnormal detection based on the spatial-temporal trajectory extracted from the user’s Internet records. This method takes full account of the characteristics of space-time track data and measures the correlation between trajectories from the two dimensions of time and space. We propose corresponding improvement measures for other defects of the spectral clustering algorithm, which can be used for anomaly detection of spatial-temporal trajectories. Specifically, first of all, we improve the accuracy of spatial-temporal similarity measurement by introducing covariance scale threshold, spatial scale threshold, and location popularity. Secondly, we Skillfully use the PCA algorithm to avoid the trouble of manually selecting the number of feature vectors. Finally, we applied the MSTDSNN-SC algorithm to the ISST dataset and GSST dataset respectively and the rest 10 algorithms for comparison experiments. The experimental results show that the MSTDSNN-SC algorithm performs well in the evaluation of SI, DB, CH and DVI metrics. In particular, the experimental results are very close to 1 in the evaluation of the silhouette index, which has a fixed interval from
Considering the evaluation performance of the four metrics as well as the reasonableness of the number of clusters and the number of detected outlier points, the clustering results obtained by the MSTDSNN-SC algorithm are reliable. What’s more, after visual analysis and validation, the screened outlier data also do have anomalies.