
Abstract
Feature selection has been shown to be a highly valuable strategy in data mining, pattern recognition, and machine learning. However, the majority of proposed feature selection methods do not account for feature interaction while calculating feature correlations. Interactive features are those features that have less individual relevance with the class, but can provide more joint information for the class when combined with other features. Inspired by it, a novel feature selection algorithm considering feature relevance, redundancy, and interaction in neighborhood rough set is proposed. First of all, a new method of information measurement called neighborhood symmetric uncertainty is proposed, to measure what proportion data a feature contains regarding category label. Afterwards, a new objective evaluation function of the interactive selection is developed. Then a novel feature selection algorithm named (NSUNCMI) based on measuring feature correlation, redundancy and interactivity is proposed. The results on the nine universe datasets and five representative feature selection algorithms indicate that NSUNCMI reduces the dimensionality of feature space efficiently and offers the best average classification accuracy.
Keywords
Introduction
Feature selection is used to select a group of the most informative and useful features. It has extensive application fields such as data analysis, data mining, and pattern recognition [1]. The way to choose the best feature set from all options is taken into account to be a subject merit study in varied learning tasks. In fact, high dimensional information can improve classification performance attribute to more features normally. However, many irrelevant features and redundant features in high dimensional information are not solely contributive to classification performance and classification accuracy however conjointly considerably increase the process complexness and memory storage needs [2]. Therefore, it is necessary for us to select a set of representative features before building a model or classifier.
In recent years, many researchers have proposed lots of feature selection algorithms. But most feature selection algorithms solely concentrate on distinguishing relevant features and removing redundant features as many as possible. Although some recent work has recognized the existence and impact of feature interaction, there is little work on the specific treatment of feature interaction [3]. But features may interact with one another and work along to replicate the character of the issues. Everything in the world is an interrelated organic whole. In the biological study, the changes of physiological and pathological processes during a complicated organism system square measure are sometimes tormented by molecular interactions. Another classic example of interaction is the well-known XOR problem. Therefore, when we built any model and algorithm, the essential factor of interaction is worthy of in-depth discussion and study.
In 1982, Z. Pawlak creatively put forward rough set theory (RST) based on the view that knowledge is a kind of classification ability. It has been widely applied to feature selection (also referred to as attribute reduction) in recent years [4]. But it is solely suitable for processing discrete data, not continuous data. Therefore, lots of scholars have extended the classical rough set model. For example, fuzzy rough set, dominant rough set, and so on. Hu et al. [5] introduced the thought of neighborhood into the RST and proposed a brand new neighborhood rough set (NRS) model based on neighborhood relationships. In recent years, various algorithms based on NRS have been widely used in feature selection, image labeling, hyperspectral classification, and other fields.
Feature subset selection can be viewed as a search issue. It targets choosing one feature subset that holds the information of original feature as much as possible under some predefined criteria [1]. Therefore, it is vital to live the relevance between classes and features and to live the redundancy and interaction between features. In recent years, information theory has been widely used to measure the amount of information contained in a feature. Research scholars have proposed a variety of feature selection algorithms to increase the relevance between features and classes and the interaction between features while reducing the redundancy between features [8]. Majority of strategies is summarized within the following framework [9]:
Where
A simple methodology termed as Mutual info Maximization (MIM) is projected in [18]. Dash and Liu [11] concentrate on a measure called consistency, which is the proportion of samples accurately recognized according to the larger part voting technique. Roberto [12] investigates the applying of the mutual information criterion to judge a group of candidate features and to pick out an informative set to be used as input file for a neural network classifier. Peng [13] study a way to choose sensible options in keeping with the highest applied mathematics dependency criterion supported mutual data. Mohamed [14] use mutual information and also the ‘maximum of the minimum’ criterion, which alleviates the matter of overestimation of the feature significance. a new info term denoted as freelance Classification info is projected during this paper [15]. It assembles the new provided info and also the preserved info negatively related to with the redundant info. By choosing options that maximize their mutual info with the category to predict conditional to any feature already picked, it ensures the choice of options that area unit each on an individual basis informative and two-by-two weak dependent [16]. the interaction weight factor which might mirror the data of whether or not a feature is redundant or interactive is projected [3]. Bennasar [17] introduced a replacement feature choice method: Feature Interaction Maximization (FIM), which employs trilateral interaction data as a live of feature redundancy. The planned technique employs interaction info to guide the search, consecutive adds one feature at a time into the presently hand-picked set, and adopts early stopping to prevent overfitting and speed up the search [19].
From the abovementioned, it can see that information theory has been utilized in countless feature selection algorithms. Some classic evaluation criteria for feature selection are summed up in Table 1 below.
Evaluation criteria of the algorithm
Evaluation criteria of the algorithm
In NRS, neighborhood mutual information (NMI), a very important method of information theory, is usually utilized by research scholars to access the relativity between features and classes and between features in classification issues [6]. Because NMI favors variables with multi-values. A new way of information measurement is proposed, which is called neighborhood symmetric uncertainty(NSU). Meanwhile, neighborhood conditional mutual information (NCMI) is introduced to evaluate the interaction between features, which may be accustomed to replicating the influence of a newly further feature on the connection between features and classes [4]. Accordingly, during this work, a completely unique neighborhood symmetric uncertainty and neighborhood conditional mutual information-based interaction feature selection algorithm (NSUNCMI) is proposed. The main contributions of this article are as follows [7]:
Inspired by symmetric uncertainty, we propose a new information measure, namely neighborhood symmetric uncertainty (NSU) in the neighborhood rough set, to measure how much information feature In this paper, the characteristic of the interaction is explored thoroughly. Further, the characteristics of feature correlation, feature redundancy, feature interaction are summarized and analyzed from different angles.
The remainder of this paper is coordinated as follows [3]. In Section 2, some fundamental information-theoretic notions are assessed. In Section 3, we give different definitions of feature relevance, feature redundancy, and feature interaction from different angles. Then put forward a new feature selection algorithm in Section 4. Experimental results and analysis are introduced in Section 5. At last, we give a concise end and provide the future research direction in Section 6.
Basic concepts
A neighborhood decision system can be expressed by a quin-tuple
Given a
Non-negativity: Symmetric: Triangular inequality:
Given a
Given a
The neighborhood mutual information can be used to measure the contribution of feature subset
The neighborhood conditional mutual information is defined as the reduction within the uncertainty of
In this segment, we will make a comprehensive analysis from different angles and provide the different definitions of feature relevancy, feature redundancy and feature interaction.
John et al. [20] classified features into three disjoint categories, namely, strongly relevant, weakly relevant and irrelevant features from the purpose of view of probability.
Yu and Liu [21] give the definition of feature redundancy from the point of view of Markov blanket.
From the point of view of information theory, Zeng et al. [3] give another definitions of feature relevance, feature redundancy and feature interaction.
Jakulin [22] study the relationship between features and features from the point of view of Interaction Gain (IG). The formula of the IG of the variables
Zeng et al. [11] adopt the normalization of IG to evaluate whether or not the two variables area unit redundant or interactive with one another objectively. The Normalized Interaction Gain (NIG) of variables
In this part, a novel feature selection method considering feature relevance, feature redundancy and feature interaction is introduced in the structure of neighborhood rough set. In Section 4.1, we give the definitions of feature relevance, feature redundancy and feature interaction in neighborhood rough set environment. In Section 4.2, we give the pseudo code of feature selection algorithm and give the analysis of time complexity and space complexity [23].
The evaluation criteria of feature correlations
The relevance measure
Neighborhood mutual information is generally used to measure the relevance between features and classes. However, NMI favors variables with multi-values [2]. Inspired by NMI, here a new method of information measurement is proposed by us. For a feature
Given a
In the second step of the proposed methodology, so as to get rid of the redundant features within the selected feature set. We are supposed to select the feature with the lowest redundancy.
When it comes to interaction between features, from the angle of information theory, it is expressed as the quantity of information contributed by the addition of a new feature for classification once a explicit feature is known. In this paper [4], the author focuses on the interaction between the current candidate feature and the features within the remaining candidate feature set. In our work, we also consider this similar situation.
Given a
This section summarizes feature correlations, which include the relevance between features and classes, redundancy, and interaction between features [25]. We propose an assessment criterion for distinguishing ability of a feature or a feature subset. It’s also known as the feature or feature subset that determines how well distinct classes are distinguished [26]. Consequently, a novel feature objective evaluation function is established as follows.
From this evaluation function, we consider relevance, redundancy and interaction comprehensively when choose a feature. The neighborhood conditional mutual information is used to evaluate the interaction between the selected feature and the candidate features, and the neighborhood symmetrical uncertainty is used to measure the relevance between features and classes and the redundancy between the feature and the selected features in this evaluation function. In this way, we can not only ensure the representativeness of the selected features, but also ensure that we do not lose any useful information.
feature selection algorithm
Based on the comprehensive analyses of feature and class relationships in Section 4.1 [27]. As a consequence, a feature selection algorithm is demonstrated, as shown in Algorithm 1.
The following phases make up the majority of Algorithm 1 [28]. First of all, the selected feature set is initialized as an empty set, and the neighborhood relation matrix of samples about the feature
Now, we will give the analysis of time complexity and space complexity of NSUNCMI algorithm [29]. In steps 2–5, the computational complexity of the neighborhood relation matrix is
Experimental results and analysis
Experiment setup
The following experiments are run on a personal computer with 2.5 GHz Intel Core CPU, 4 GB memory, and Windows 7. Each dataset is divided into 70% as a training set and 30% as a test set. The experimental results compared with the other five different kinds of feature selection algorithms upon nine real world datasets respectively [31]. The algorithms embrace five well-known and regularly used MIFS, MRMR, IWFS, Relief-F and FCBF. Among these feature selection algorithms, Relief-F can be found in the WEKA1 environment and others are all implemented in Python. The SVM classifier is used to select the top k features to produce the highest accuracy. The quality of feature selection outcomes is assessed by means of utilizing the average classification accuracies of three classifiers, i.e., KNN, SVM and C4.5.
Experimental datasets description
Experimental datasets description
To verify the adequacy of our methodology on universe issues, nine datasets (i.e., Nos. 1–9) from UCI machine learning repository is utilized [32]. The overall characteristics of datasets are introduced in Table 2. The eight datasets include two classifications problem and multiple classification problem, the sizes of datasets vary from 150 to 846, the numbers of candidate features vary from 4 to 2000.
Experimental results
Number of selected features
For each dataset, we run every one of the six feature selection algorithms to acquire the number of selected feature subsets, and results are shown in Table 3.
Number of features selected with different algorithms
Number of features selected with different algorithms
Table 2 shows that all the eight feature selection algorithms can apparently reduce the data dimension. Compared with these algorithms such as MRMR, Relief-F, MIFS, FCBF, IWFS, and our proposed NSUNCMI algorithm can select a relatively small number of features.
Classification performance is taken into account to be one of the most effective and direct ways to verify the standard of the feature selection algorithm [34]. In order to avoid the influence of a certain data set and calculation error. The classification accuracies of the same feature selection algorithm on totally different datasets square measure averaged, which is shown in the row named as “Avg.” [35]. The comparisons of the average classification accuracies of various feature selection algorithms on the three classifiers are given in Tables 4–6.
Classification accuracy (%) of selected features (SVM)
Classification accuracy (%) of selected features (SVM)
Classification accuracy (%) of selected features (KNN)
Classification accuracy (%) of selected features (C4.5)
From the comparisons in Tables 4–6, we will notice the subsequent results [36].
Compared with the raw data, the classification performance of the NSUNCMI algorithm is improved conspicuously. The average classification accuracies of the proposed algorithm are improved by 8.12%, 9.02% and 7.41% individually on the three classifiers. On the entire, the performance of the proposed NSUNCMI algorithm is healthier than other feature selection algorithms on most datasets. For instance, when C4.5 is employed as a classifier for testing, the NSUNCMI algorithm achieves the most effective classification performance on seven datasets.
For those feature ranking algorithms, one technique to examine effectiveness of selected features are to add features for learning one by one within the order that the features are selected [3]. In this paper, six datasets with completely different range of the selected features square measure tested on SVM, KNN and C4.5 classifier. Figure 1 shows the common classification accuracy on the six datasets [37].
Average classification accuracy versus different number of selected features.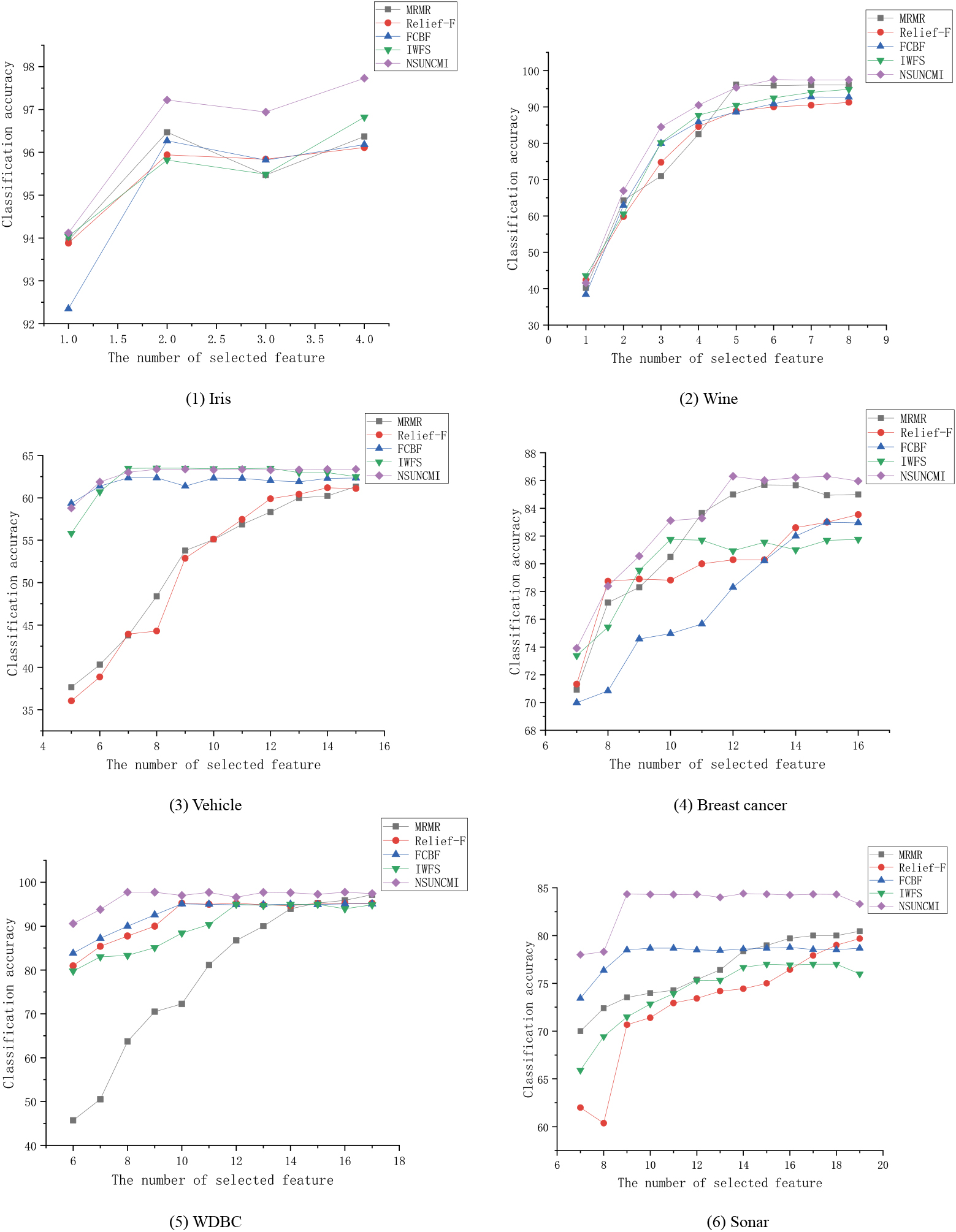
From careful observations and analyzes of Fig. 1, our projected NSUNCMI algorithmic program will get an improved result compared with different five feature selection algorithms [38]. For instance, the highest average accuracy of Iris, Wine, Glass, WDBC achieved by NSUNCMI is 98.20%, 98.68%, 98.72%, 98.05% respectively. On the whole, the classification accuracy of each data set increase slowly with the increase of the number of features, and finally reaches the peak value and tends to be stable.
The calculation time is also one of significant measures to evaluate algorithms [39]. It is well known that MRMR is a feature selection method with high computational complexity. We contrast the running time of NSUNCMI and that of MRMR and IWFS. In Table 7, we compare the computing time of three feature ranking algorithms of NSUNCMI, MRMR and IWFS on eight datasets.
Running time of three algorithms
Running time of three algorithms
From the Table 7, we can find that the running time of NSUNCMI algorithm on Iris, Vehicle, Breast, WDBC, Credit and Glass is lower than the other two algorithms. However, the running time on the three data sets of Wine, Sonar and Colon Tumor are higher than the other two algorithms, but it is within the range of our acceptance.
The main purpose of feature selection is to select the feature sets that can represent the original data [40]. The problem of feature interaction is interesting, which can be further discussed in the future work. In this article, we will introduce a new feature selection algorithm that not only removes unrelated and redundant features, but also takes into account interactions that are very effective [30]. First, inspired by mutual information, a new method of information measurement is proposed in the neighborhood rough set environment. Then considering comprehensively from three aspects, we put forward an evaluation standard of feature selection. Based on the evaluation standard, we present the NSUNCMI feature selection algorithm. Experimental results from synthetic datasets showed that NSUNCMI is able to effectively identify related features, while eliminating unnecessary features and preserving interactive features.
As a matter of fact, feature selection has been widely used in data mining, image annotation, data analysis [41]. As an important data preprocessing method, the study of feature selection is an intriguing hot topic. For example, how to find better information measurement tools and how to propose more effective and reasonable algorithms. learning information shared by four or more features and using N-directional interaction to select more relevant and interactive features. There are many complex problems that need to be solved [42]. They are all the contents of our next stage of research.
Footnotes
Acknowledgments
We appreciate Jingjing Hu, Jing Yu and another person for their contributions to this paper. This research is supported by the Software Project Development Contract (No. 13028001).