
Abstract
Feature extraction for blind image steganalysis produces much features or high dimensional data, which bring about time consuming and even a low detection percentage. As being one of the most important phases of preprocessing, feature selection can reduce these extracted features, and improve the performance of steganalysis. Firstly, we introduce the Neighborhood Rough Sets (NRS) to the field of blind image steganalysis. Then, some concepts of feature significance and feature reduct are presented based on NRS. Furthermore, we propose a Feature Selection approach by NRS for blind image steganalysis (FSNRS). The FSNRS has the ability to delete redundant features, meanwhile maintaining the classification accuracy of a steganalysis system. The FSNRS is a filter feature selection technique for blind image steganalysis, which filtrates extracted features depending on a positive region preserving in NRS. The compact feature subset with a shortest feature dimension for blind image steganalysis is selected. Moreover, some experiments for blind steganalysis using SVM and KNN classifiers on selected feature subset are carried out. The experimental results show that our proposed approach can obtain compact features for blind image steganalysis and the performances of classifiers on those selected features are improved. Since the FSNRS is used with an adjustable neighborhood parameter, as a result, the classification performance of selected features is better than that of original whole features in most cases.
Introduction
Steganography is a technique of hiding a secret information in a carrier. In history, the kings used it for sending private messages by embedding them into the body parts of messengers. Now, this technique of hiding has turned to digital carriers, such as images, texts, videos and audios. The resultant image carrying private or sensitive data is called as a stego image. In the past two decades, various steganographic algorithms [1–5] have been developed for hiding secret messages into digital images without changing the color noticeably. However, steganography may be used by criminals or illegal persons. For example, terrorists use this technique for sending their messages to various corners of the world through internet without being discovered. Therefore, a counter technique known as steganalysis is appeared to detect such stego images.
Steganalysis is a skill of detecting any message in a digital image. With this technique, the existence of secret messages can be discovered. As a matter of fact, steganalysis is simultaneously a part of cryptanalysis and a branch of art. Steganalysis has two types, which are targeted [6, 7] and blind [8, 9]. Targeted steganalysis refers to the technique of identifying the stego image where the steganography algorithm used for hiding the message is known. In case of blind steganalysis, the steganography algorithm is unknown. Therefore, blind steganalysis becomes more difficult to research than targeted steganalysis. The significant process of blind steganalysis has an extracting of features to a classifier for training, while the trained classifier assists in recognizing hidden messages.
According to whether an image hides messages or not, images can be classified into two types: cover image with no information hidden and stego image with an information hidden. Thus, steganalysis can be considered as a classification problem to determine which class a test image belongs to. The significant problem of steganalysis just similar to a classifier is feature extraction. The extracted features from images must be sensitive to a steganography process. In recent years, several feature extraction methods [10–13] for steganalysis have been proposed to recognize cover images or stego images. However, these methods using different feature extractors produce massive high-dimensional data, which will degrade the performances of steganalysis. And these features may include some irrelevant or redundant information affecting recognition rate. Thus, a preprocessing technique named feature selection emerges to remove the irrelevant and unimportant features from the whole feature set.
Feature selection identifies the important features and deletes redundant features from the extracted features while simultaneously maintaining the meaning of the whole data sets. The technique chooses the optimal subset of features that can represent the whole contents of the data set with the minimum error and information loss. On the one hand, feature selection methods can be classified into three categories according to different search strategies: complete [14], stochastic [15] and heuristic [16]. On the other hand, algorithms of feature selection can be classified into two categories: filter [17] and wrapper [18] methods. A filter method is a preprocessing step that selects a feature subset by a predefined evaluation function without using any learning algorithm. The chosen subset has a better generalization ability, since it is independent of a specific learning algorithm. Furthermore, the filter method usually has a lower time complexity. A wrapper method adopts the classification accuracy of a particular classifier to assess the worth of feature subsets. Thus, the wrapper method can achieve a better classification performance for a specific classifier with a cost of time complexity. However, the selected features by wrapper methods are less generalization on other classifiers. Hence, many researchers use rough set feature selection techniques [19–21], which are filter approaches through varies positive dependent functions.
Rough set theory [22], proposed by the Polish scientist Pawlak Z. in 1982, is a valid tool in mathematics to deal with the imprecise, uncertain and inconsistent data sets. Feature selection also called attribute reduction is one of significant research topics in rough set theory. It can delete redundant features while maintaining the classification ability of a data set. The Pawlak rough set theory is mainly applicable to the decision systems with discrete data. As for a steganalysis data set, a discretization should be implemented. However, this preprocessing will result in the loss of information, reducing the classification accuracy. The notion of neighborhood rough sets was firstly introduced by Yao [23, 24], which is built on a basis of a neighbor defined by a distance function. It has an ability to granulate continuous data by a neighborhood parameter. The model of neighborhood rough sets was utilized to classification by Hu et al. [25], which can handle the knowledge classification system with not only continuous data but also discrete data. There is a wide applications on neighborhood rough sets including feature selection [20], rule extracting [26], classification [27], cluster [28], gene selection [29], image processing [30] and other fields [31]. Since feature extractions for steganalysis systems produce high-dimensional data sets, which result in time consuming and even poor forecasting accuracy on steganalysis classifiers. Considering the characteristics of steganalysis data, we propose a steganalysis frame based on neighborhood rough sets to obviously reduce extracted features. After carrying out steganography and feature extraction on images, we achieve a steganalysis data set which values are continuous. Firstly, by granulating the data set using a distance function and a neighborhood parameter, we construct some neighborhood class sets. Secondly, we define the concepts of neighborhood positive region and neighborhood dependency to evaluate the classification accuracy of a steganalysis system. Furthermore, the neighborhood dependency-based feature significance is proposed for contributing to search an optimal feature subset. Finally, we deploy SVM and KNN classifiers to test the performance of the selected feature subset. The theoretical analysis and several experiments show that the proposed feature selection method for blind image steganalysis is practical and effective.
The rest of this paper are organized as follows. An introduction to rough sets and neighborhood rough sets are presented in section 2. In section 3, the feature selection for blind steganalysis by neighborhood rough sets is introduced. Then we propose a positive-based feature significance, which is used for measuring the blind steganalysis features. Furthermore, we present a rough set frame for blind steganalysis and propose a feature selection algorithm by neighborhood rough sets, contributing to improve the performance of blind steganalysis. In section 4, some experiments are implemented to indicate the effectiveness of our proposed method. Finally, this paper is concluded with some remarks and discussions in section 5.
Rough sets and neighborhood rough sets
In this section, some basic concepts of rough sets and neighborhood rough sets used in a steganalysis system are presented. The further details of rough sets and neighborhood rough sets can be found in [22, 25].
Rough sets in steganalysis
The theory of rough sets begins with the concept of an information system, which is a quadruple IS = (U, A, V, f), where U is a nonempty object or sample set, and A is a family of features or attributes. V is the value domain of A and f is a mapping information function, f : U × A → V. In a particular situation, an information system is called a decision system if the feature set is A = C ∪ D. The decision system is formalized by DS = (U, C ∪ D, V, f), where C is the condition feature set, and D is the decision feature set.
In an information system, when features are extracted from gray scale images using the moments of characteristic functions, an information system of blind steganalysis is generated. The information system of blind steganalysis is simply represented as SI = (U, A), where U is a set of gray scale images, named as a sample set, and A is a family of extracted features. While the sample set includes cover and stego images, the set can be categorized into two classes. The information system of blind steganalysis is named as a decision system of blind steganalysis, which is expressed as SD = (U, C ∪ D), where C is the extracted feature set, and D is the classified feature which values label a state: hiding or no hiding. Then the decision system of blind steganalysis can be trained and tested using a machine learning classifier.
The IND (P) satisfies reflexivity, symmetry and transitivity. If (x, y) ∈ IND (P), then x and y are equivalent on feature subset P. The partition of U generated by IND (P) is defined as U/IND (P) = {[x] P |x ∈ U}, where [x] P is an equivalence class of an image x related to the equivalence relation IND (P). The partition is simply denoted as U/P, which is a set of all the equivalence classes on P in U. The elements in [x] P are equivalent on feature subset P. Equivalence classes, also called information granules, are used to characterize any subsets of U.
The tuple <P* (X) , P* (X)> is called a rough set of X. The set X is definable, if the lower approximation is equal to the upper approximation. Otherwise, the set X is undefinable. The lower approximation is also called positive region, denoted as POS P (X). And BN P (X) = P* (X) - P* (X) is called a boundary set.
The theory of classical rough sets is used to evaluate a set or a classification for categorical data in knowledge representation systems. As for a steganalysis system which values are real, a discretization should be implemented. However, this preprocessing will lead to an information loss. In the follows, a model of neighborhood rough sets [24, 25] is presented to tackle real-value data in a steganalysis information system.
A distance function is a metric on a set of images, mapping pairs of images into the non-negative real values. Suppose x and y are two images with an N-dimensional feature space A = {a1, a2, . . . , a N }, v (x, a i ) and v (y, a i ) denote the values of images x and y in the ith feature a i , a general distance metric is defined as:
Obviously, the neighborhood relation satisfies reflexivity and symmetry, which is a similarity relation. A neighborhood relation can induce numerous neighborhood classes. A neighborhood class
That is, the neighborhood lower approximation P* (X) δ is the union of all neighborhood classes which are contained in X, and the neighborhood upper approximation P* (X) δ is the union of all neighborhood classes which have a nonempty intersection with X. The tuple <P* (X) δ , P* (X) δ > is called a neighborhood rough set. Specially, a neighborhood rough set degenerates to a classical rough set when δ = 0. The neighborhood lower approximation is also called neighborhood positive region, denoted as POS P (X) δ . And BN P (X) δ = P* (X) δ - P* (X) δ is called a neighborhood boundary set.
A pre-analysis processing for blind steganalysis aims to separate the irrelevant and unimportant features from the relevant and important features. This process mainly includes two steps of feature extraction and feature selection. The former step is to generate a data set by extracting multidimensional features from the original images. The latter step is to simplify the extracted data by selecting an important feature subset from the whole set of candidate features. In the following subsections, we introduce a feature measure based on a dependency of neighborhood rough sets into a system of blind steganalysis. Furthermore, a feature selection algorithm by neighborhood rough sets for blind steganalysis is proposed. The framework of blind steganalysis is illustrated in Fig. 1.
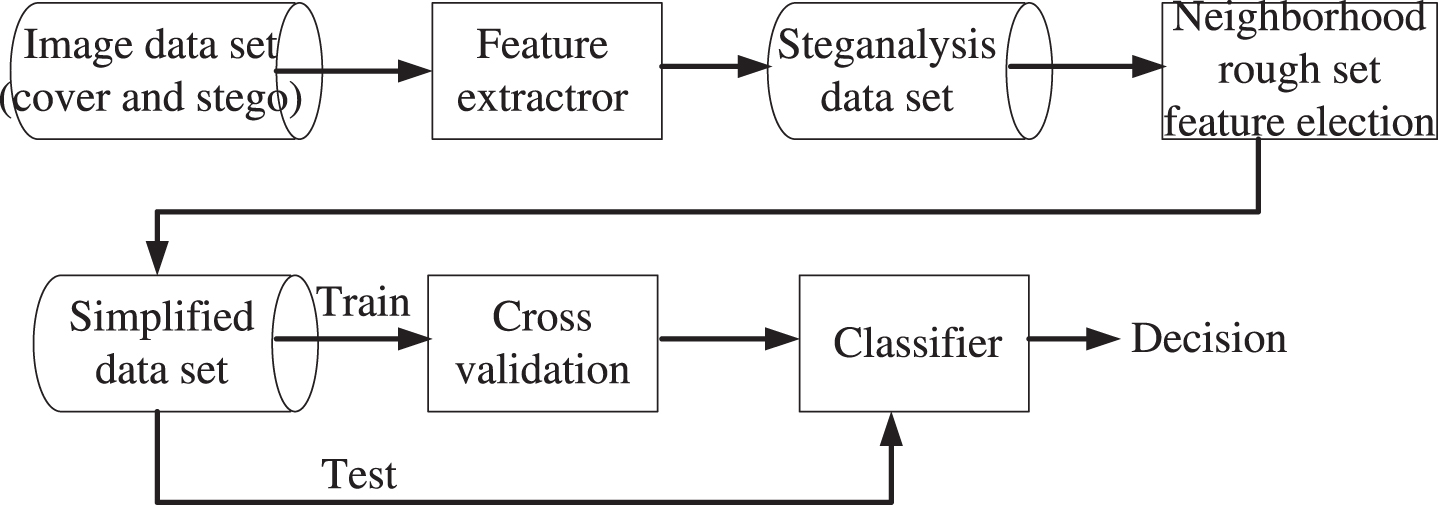
The framework of blind steganalysis.
The first condition guarantees that there is a same classification ability for B and C since POS B (D) δ = POS C (D) δ . The second condition indicates that there is no superfluous features in the reduct. Therefore, a reduct is a minimal subset of features which has the same classification ability as the whole feature set.
(1) γ B (D) = γ C (D);
(2) ∀b ∈ B, γ B (D) ≠ γB-b (D).
The reduct is not unique. It is a combinational optimization problem to find all of the reducts. There are 2|C| combinations of feature subsets. It is does not worth reaching all of the reducts by an exhaustive method. In practice, we usually construct a greedy search algorithm to obtain a reduct, which will be used to train a classifier.
By calculating the change in dependency when a feature is added into the set of candidate features, an estimate of the significance of that feature is obtained. The higher the change in dependency, the more significant the feature is. If the significance is 0, then the feature is dispensable.
(1) SGN (a, B, D) =0;
(2) ∀b ∈ B, SGN (b, B, D) >0.
This Theorem 2 presents a practical scheme to find optimal feature subsets of a steganalysis system. Hence, we design a feature selection algorithm for blind steganalysis by neighborhood rough sets in the following subsection. The Definition 7 measures the significance of a feature, which can be utilized as a heuristic information for searching a reduct.
As it is discussed in the previous section, the dependency reflects the classification ability of a feature subset. Therefore, it can be used to measure the significance of a candidate feature. The goal of feature reduction is to find a minimal subset of features which has the same classification ability as the original whole features. Therefore, the feature reduction is also called as feature selection. Although there are usually many reducts for a given steganalysis data set, it is enough to find one for training the data set. With the proposed measure of feature significance, a greedy search algorithm can be formally designed as follows.
The algorithm FSNRS starts from an empty set, until it stops when the addition of any feature increases no change of the dependency. If there are m images and n condition features, the computational complexity for calculating a neighborhood class is O (m * n) by a hash sort [32]. So the computational complexity of dependency is O (m * n). Furthermore, the worst search time for a reduct will bring about n evaluations of the dependency. Therefore, the overall computational complexity of the proposed algorithm is about O (m * n2).
Preparation of data sets
In experimental studies, the breaking out steganography system (BOSSbase 1.01) has a gray scale image database, which is used for preparing the training and testing data sets. It can be downloaded from the web site: http://dde.binghamton.edu/ download/feature_extractors/. We select 3000 images from BOSSbase 1.01 and change them into jpeg format. These images are each of 512 × 512 resolution, with sizes varying from 5.64 KB to 73.1 KB. In the 3000 images, 2400 images are used for preparing a training data set and 400 images are used as a testing data set. Before a feature extracting process, a steganography need be employed in these images.
Methods of steganography
In the 3000 images, odd number images are used as clean images and the even number images are used for hiding text messages by two well known steganography algorithms. Hence, these images are classified into two categories: cover(clean) and stego. The two steganography algorithms used for embedding text in stego images are F5 [1] and UNIWARD [4]. The rates of hidden text embedding vary from 0.2 to 0.6 per pixel with step of 0.2, which are marked with payloads 0.2, 0.4 and 0.6 respectively. In the follows, a feature extracting process resulting in high dimensional data is used for evaluating experimental images.
Simplified rates with different steganography methods, feature extractors and neighborhood parameters
Simplified rates with different steganography methods, feature extractors and neighborhood parameters
In these experiments, two extractors are employed to achieve the features for blind steganalysis, which are the subtractive pixel adjacency model (SPAM) [11] and the Chen’s algorithm (CHEN) [12]. SPAM has 686 condition features and one decision feature, and CHEN has 486 condition features and one decision feature. Since there are massive and high dimensional data produced by the feature extraction of JPEG images, a rough set feature reduction is carried out for selecting some significant features. Then, the SVM and KNN classifiers have been used for training on these selected features from high dimensional extracted features. Also the final classification of test images, whether clean or stego, is done by the trained models. Gaussian kernel is used in SVM, while k = 5 is set in KNN. All the classification experiments are implemented by a five-fold cross-validation on selected features. The classification accuracy is the mean of five tests. The experimental scheme of blind steganalysis is illustrated in Fig. 2.
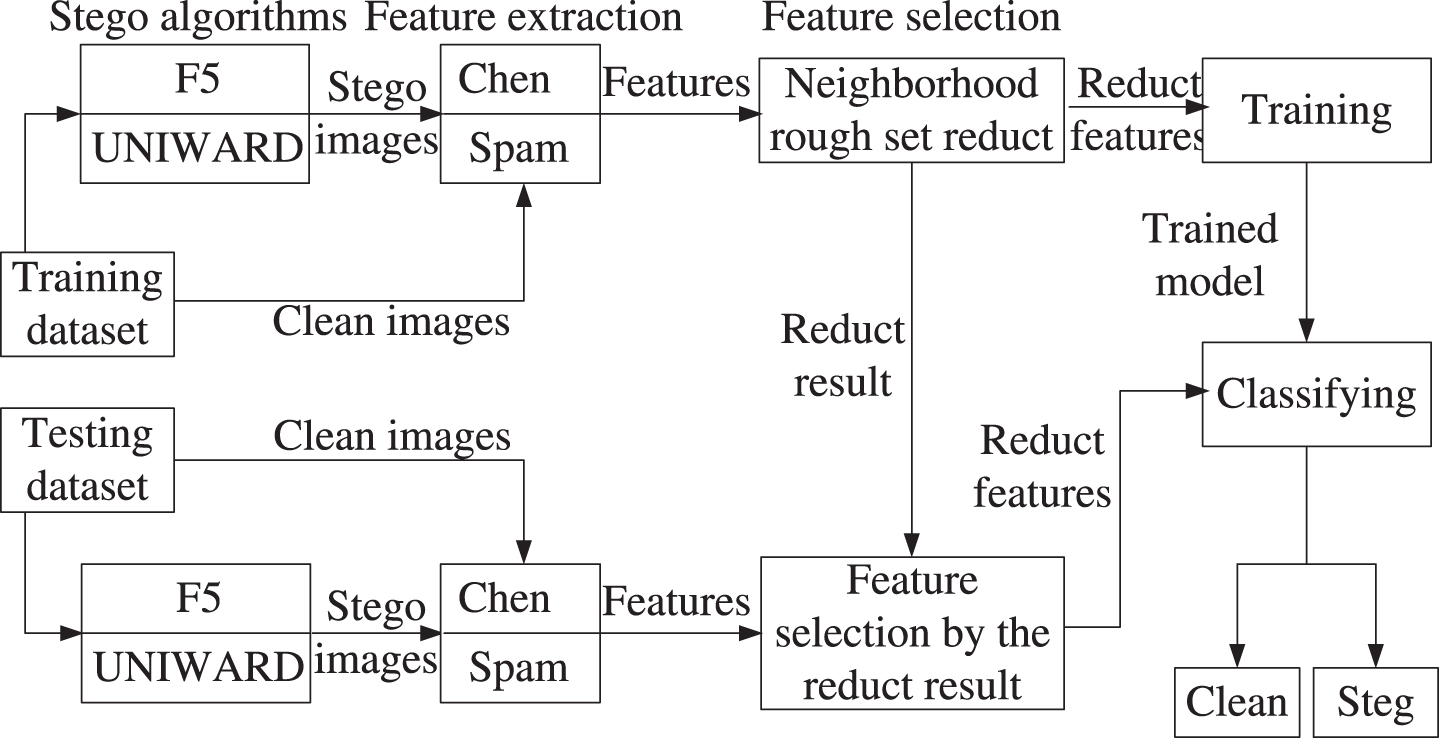
The experimental scheme of blind steganalysis.
In this subsection, the performance of the proposed feature selection method by neighborhood rough sets (FSNRS) for different steganographies and extractors is investigated. The steganographies are UNIWARD and F5 with different payloads 0.2, 0.4 and 0.6. The extractors are SPAM and CHEN methods. The values of the extracted features are normalized between 0 and 1. In the FSNRS, the Euclidean distance is used and the value of neighborhood parameter varies from 0.05 to 0.95 step by 0.05. In order to evaluate the simplification of selected features, we adopt a concept named simplified rate, which is defined as follows:
The Figs. 3, 6, 9 and 12 demonstrate the numbers of selected features with different neighborhood parameter values in the proposed method. The abscissa is neighborhood parameter, while the ordinate is the number of selected features. In Figs. 3 and 6, the data hiding method is UNIWARD with different payloads, while the extractors are SPAM and CHEN respectively. In Figs. 9 and 12, the data hiding method is F5 with different payloads, while the extractors are SPAM and CHEN respectively. As we know, the SPAM extractor produces 686 dimensions of features and the CHEN extractor produces 486 dimensions. From the illustrations in Table 1, Figs. 3, 6, 9 and 12, it is obvious that our feature selection method can strongly reduce these features. It will save more training time and testing time.

The number of selected features with UNIWARD steganography and SPAM extractor via different neighborhood parameters.

The SVM accuracy of selected features with UNIWARD steganography and SPAM extractor via different neighborhood parameters.
The SVM predictive accuracy of selected features with UNIWARD steganography and SPAM extractor is illustrated in Fig. 4. The ordinate is predictive accuracy of selected features, while the abscissa is the value of neighborhood parameter. But the last value in abscissa labeled as 686 represents the total features which are extracted by SPAM. It can be seen that the SVM predictive accuracies of total features are 0.9544, 0.9564 and 0.9582 under different payloads 0.2, 0.4 and 0.6. As for our selected features under payload 0.2, the SVM predictive accuracy of those is reaching the maximal value with 0.9912 at neighborhood parameter 0.8. While the payload is 0.4, the SVM predictive accuracy of selected features is reaching the maximal value with 0.999 at neighborhood parameter 0.7. All the SVM predictive accuracies of selected features under different neighborhood parameters with payloads 0.2 and 0.4 are higher than that of whole features. As for payload 0.6, the SVM predictive accuracy of selected features is reaching the maximal value with 0.996 at neighborhood parameter 0.9. Only one time, the SVM predictive accuracy of selected features at neighborhood parameter 0.05 is lower than that of whole features.
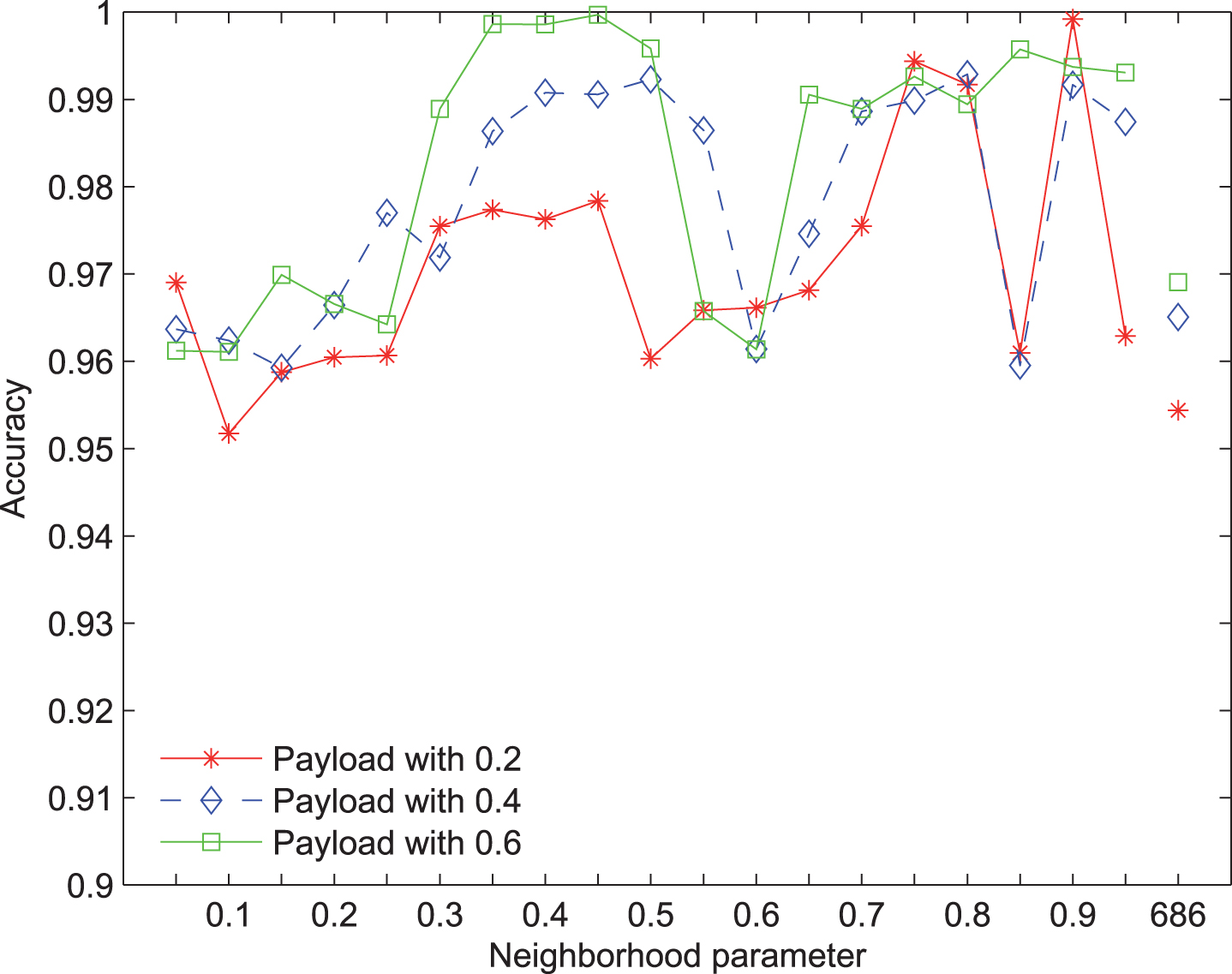
The KNN accuracy of selected features with UNIWARD steganography and SPAM extractor via different neighborhood parameters.
The KNN predictive accuracy of selected features with UNIWARD steganography and SPAM extractor is illustrated in Fig. 5. It can be seen that the KNN predictive accuracies of total features are 0.9544, 0.9651 and 0.9691 under different payloads 0.2, 0.4 and 0.6. As for our selected features under payload 0.2, the KNN predictive accuracy of those is reaching the maximal value with 0.9992 at neighborhood parameter 0.9. Only one time, the KNN predictive accuracy of selected features at neighborhood parameter 0.1 is lower than that of whole features. While the payload is 0.4, the KNN predictive accuracy of selected features is reaching the maximal value with 0.9929 at neighborhood parameter 0.8. Fourteen times in nineteen times, the KNN predictive accuracies of selected features are higher than that of whole features. As for payload 0.6, the KNN predictive accuracy of selected features is reaching the maximal value with 0.9997 at neighborhood parameter 0.45. Fourteen times in nineteen times, the KNN predictive accuracies of selected features are also higher than that of whole features.
From the results of Figs 3, 4, and 5, they indicate that our proposed feature selection method has an ability to find valid features, which are not only more compact but also higher predictive accuracies in SVM and KNN classifiers.

The number of selected features with UNIWARD steganography and CHEN extractor via different neighborhood parameters.
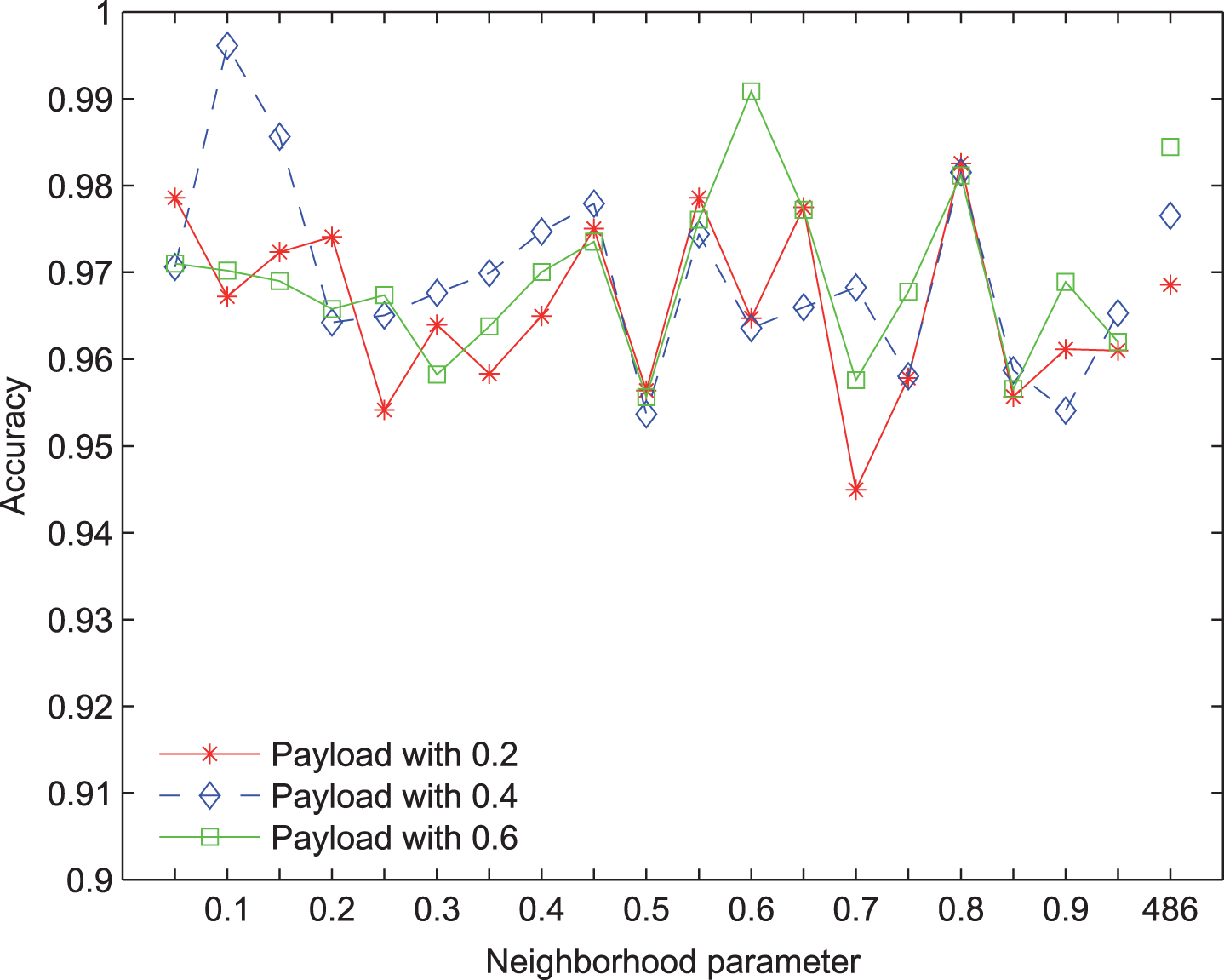
The SVM accuracy of selected features with UNIWARD steganography and CHEN extractor via different neighborhood parameters.

The KNN accuracy of selected features with UNIWARD steganography and CHEN extractor via different neighborhood parameters.
The Figs. 6, 7 and 8 illustrate numbers and predictive accuracies of selected features with different neighborhood parameter values and different payload hiding information. In Fig. 6, the abscissa is neighborhood parameter, while the ordinate is the number of selected features. In Figs. 7 and 8, the abscissa is neighborhood parameter, while the ordinate is the predictive accuracy of selected features. The data hiding method is UNIWARD with different payloads, while the extractor is CHEN. As we know, the CHEN extractor produces 486 dimensions of features. In Fig. 6, it can be seen that our feature selection method can simplify these features. In Fig. 7, the SVM predictive accuracies of the whole features are 0.9686, 0.9765 and 0.9844, respectively with payloads 0.2, 0.4 and 0.6. As for our selected features, the SVM predictive accuracies of those are reaching maximal values which are 0.9826, 0.9961 and 0.9909, at neighborhood parameters 0.8, 0.1 and 0.6, and with payloads 0.2, 0.4 and 0.6 respectively. In Fig. 8, the KNN predictive accuracies of the whole features are 0.9701, 0.9782 and 0.9847, respectively with payloads 0.2, 0.4 and 0.6. As for our selected features, the KNN predictive accuracies of those are reaching maximal values which are 0.9773, 0.9953 and 0.9924, at neighborhood parameters 0.55, 0.1 and 0.6, and with payloads 0.2, 0.4 and 0.6 respectively. From these results in Figs 7 and 8, the predictive accuracies of our selected features can be higher than those of whole features at suitable neighborhood parameter values.
According to the above analyses we can see that our proposed method is capable of improving the performance of a steganalysis system. Since our proposed feature selection method is used with an adjustable neighborhood parameter, the classification performance of selected features is better than that of the original whole features in most situations. As for the next Figs. 10, 11, 13, 14, we can draw the same results.
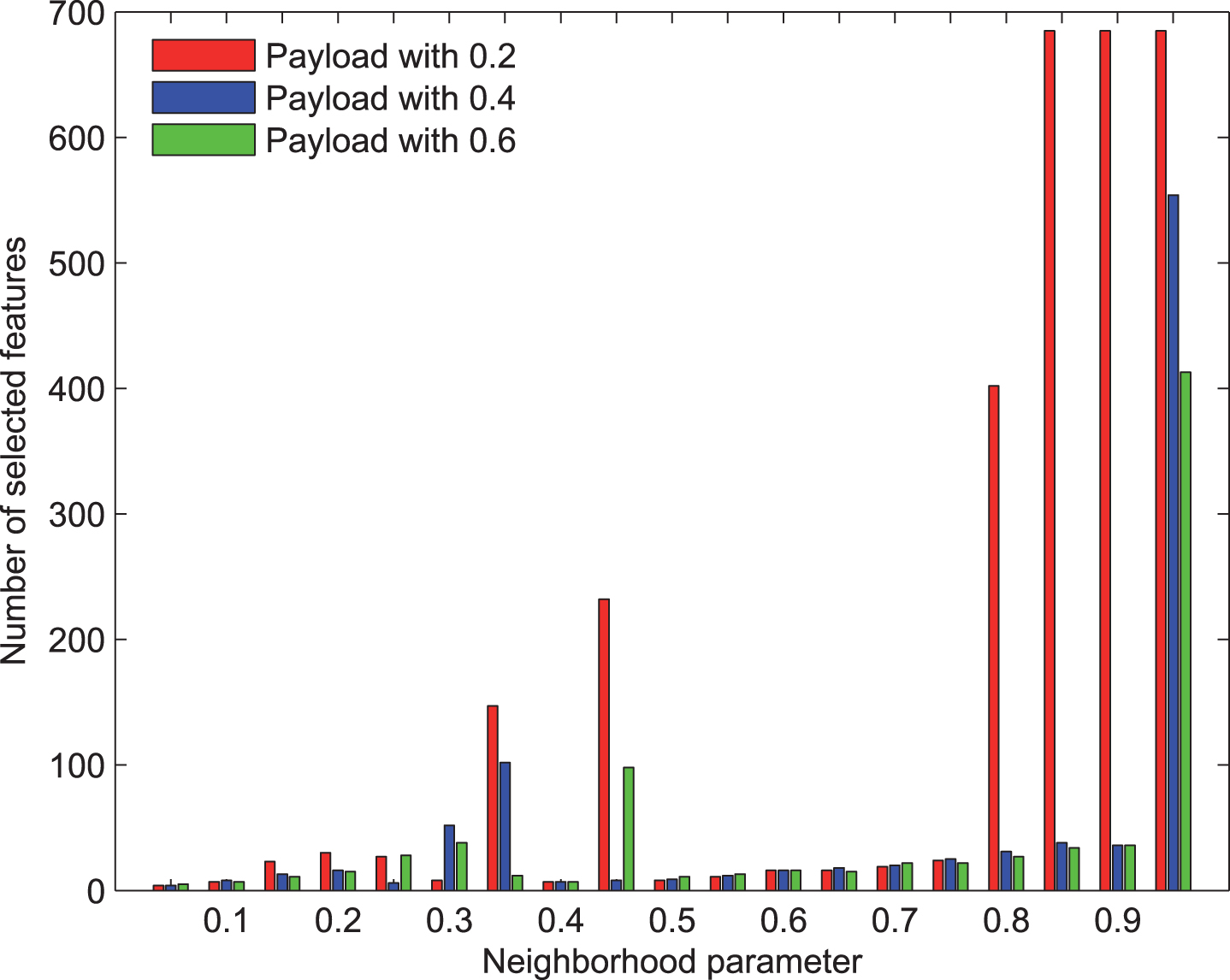
The number of selected features with F5 steganography and SPAM extractor via different neighborhood parameters.

The SVM accuracy of selected features with F5 steganography and SPAM extractor via different neighborhood parameters.
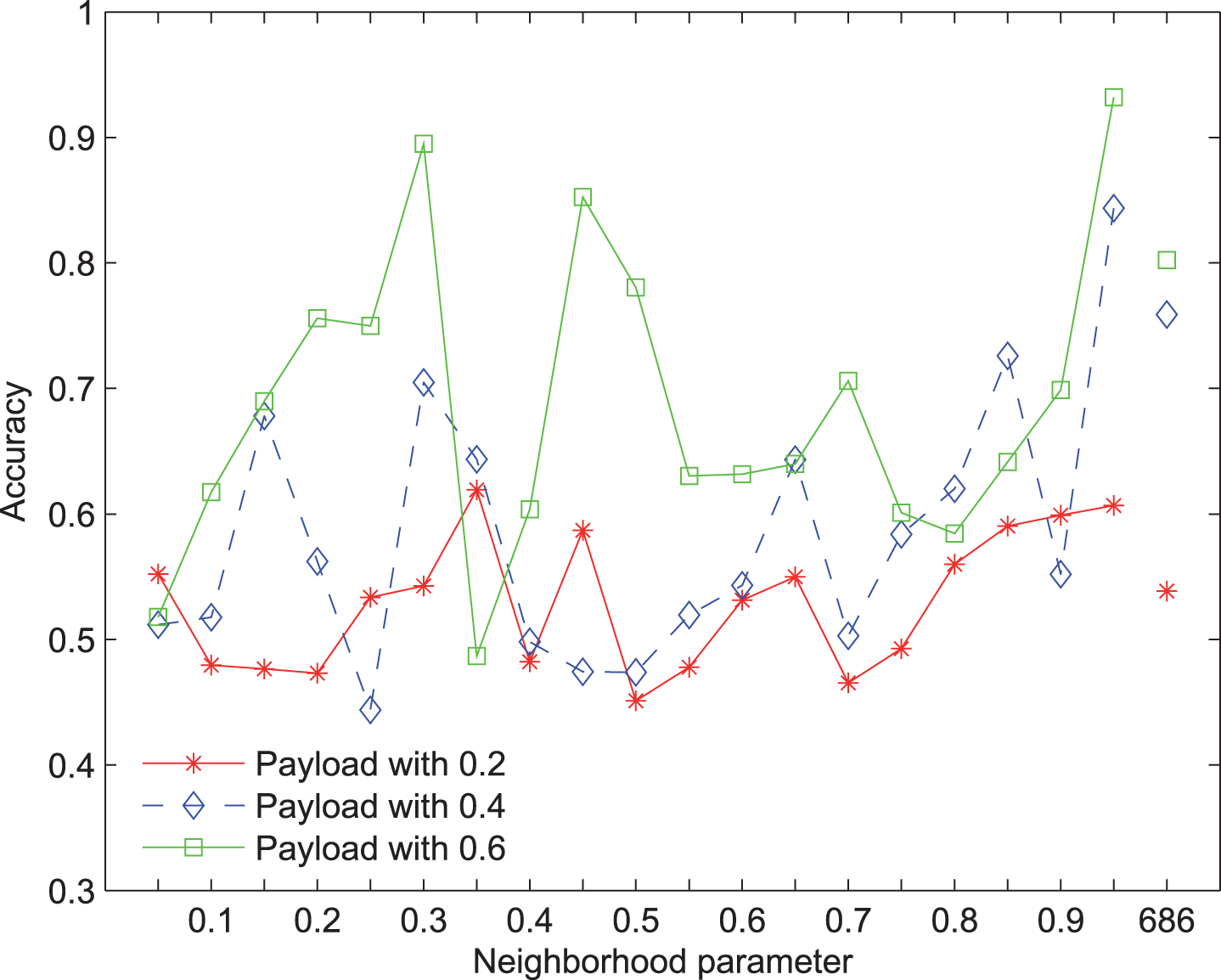
The KNN accuracy of selected features with F5 steganography and SPAM extractor via different neighborhood parameters.
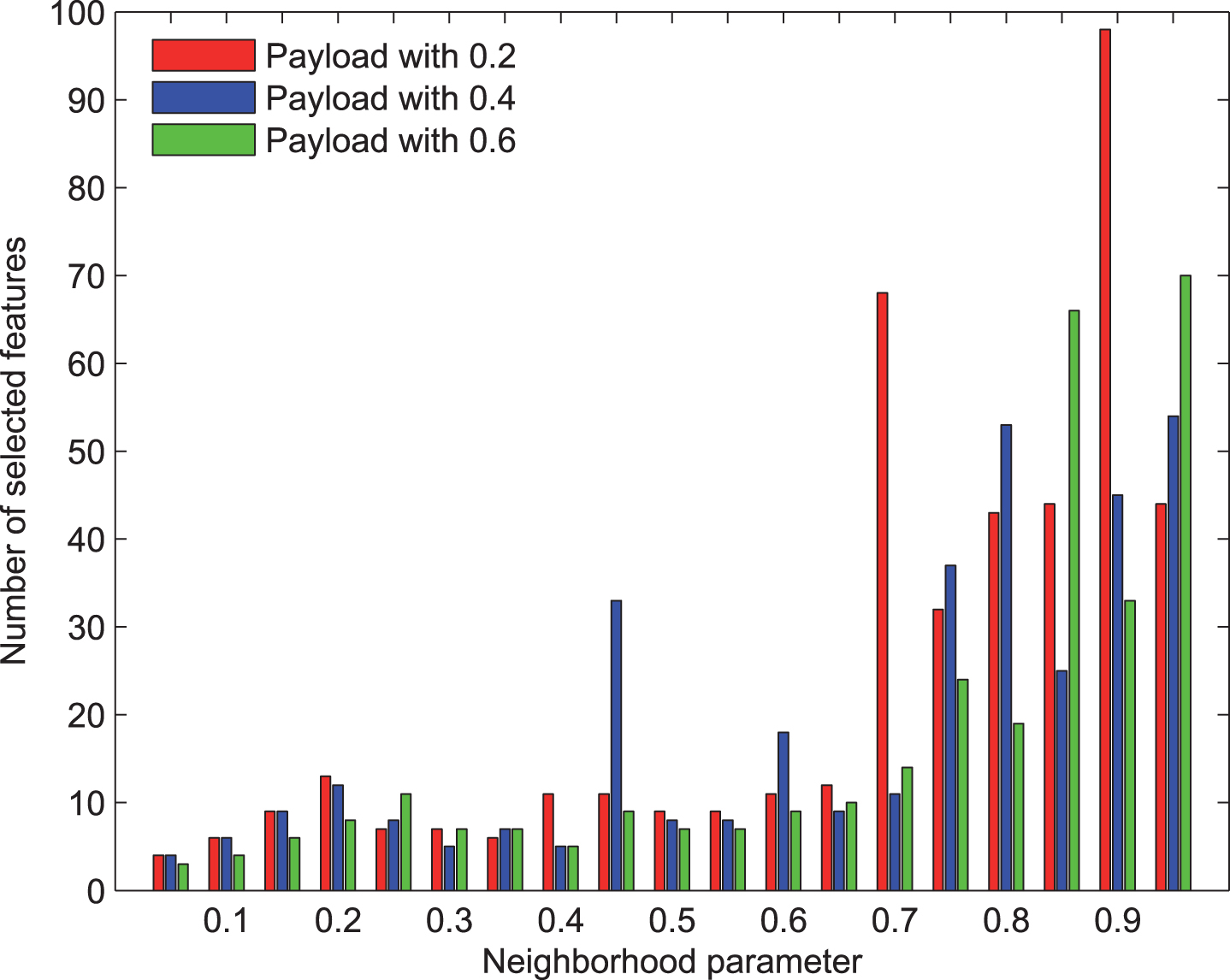
The number of selected features with F5 steganography and CHEN extractor via different neighborhood parameters.
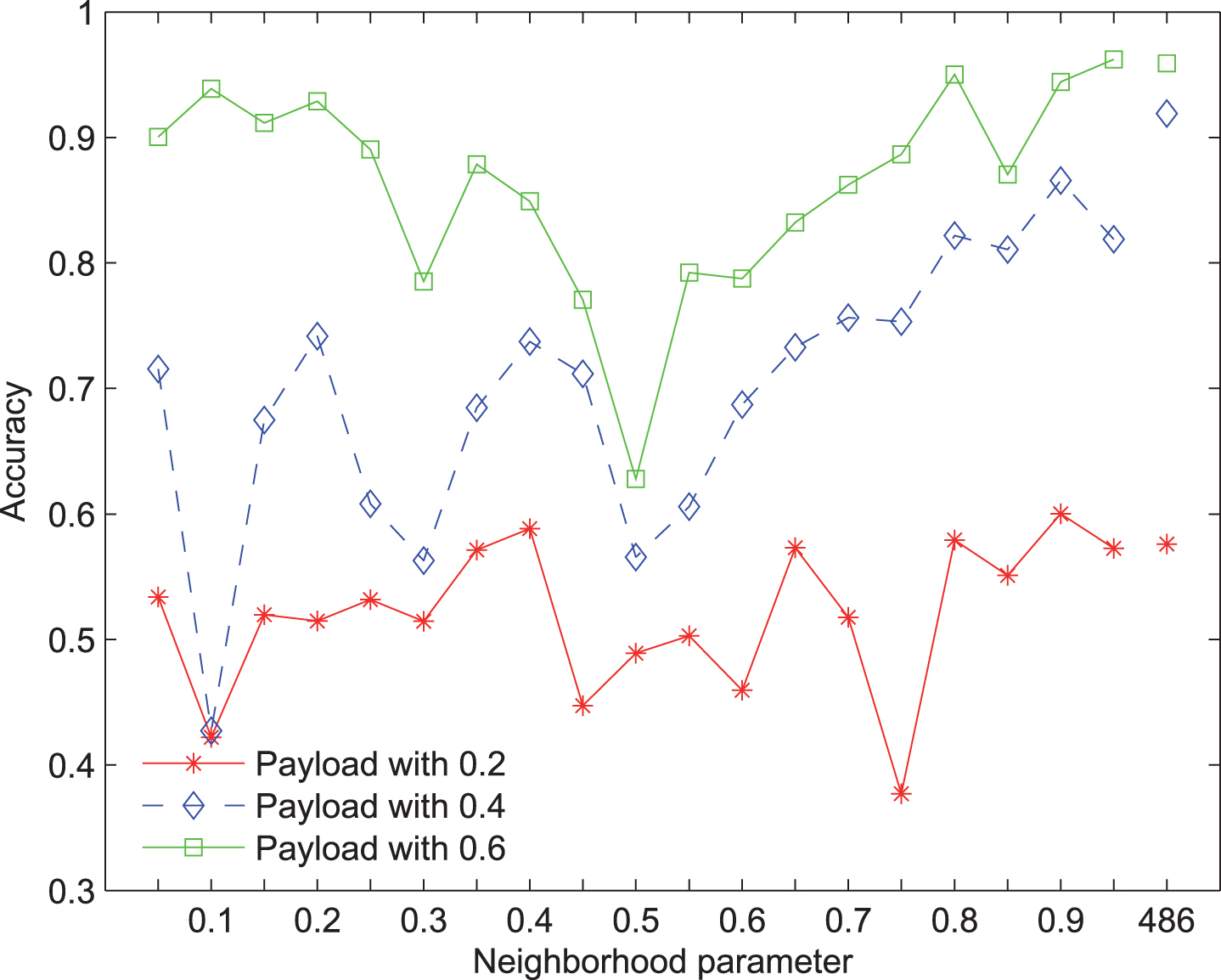
The SVM accuracy of selected features with F5 steganography and CHEN extractor via different neighborhood parameters.
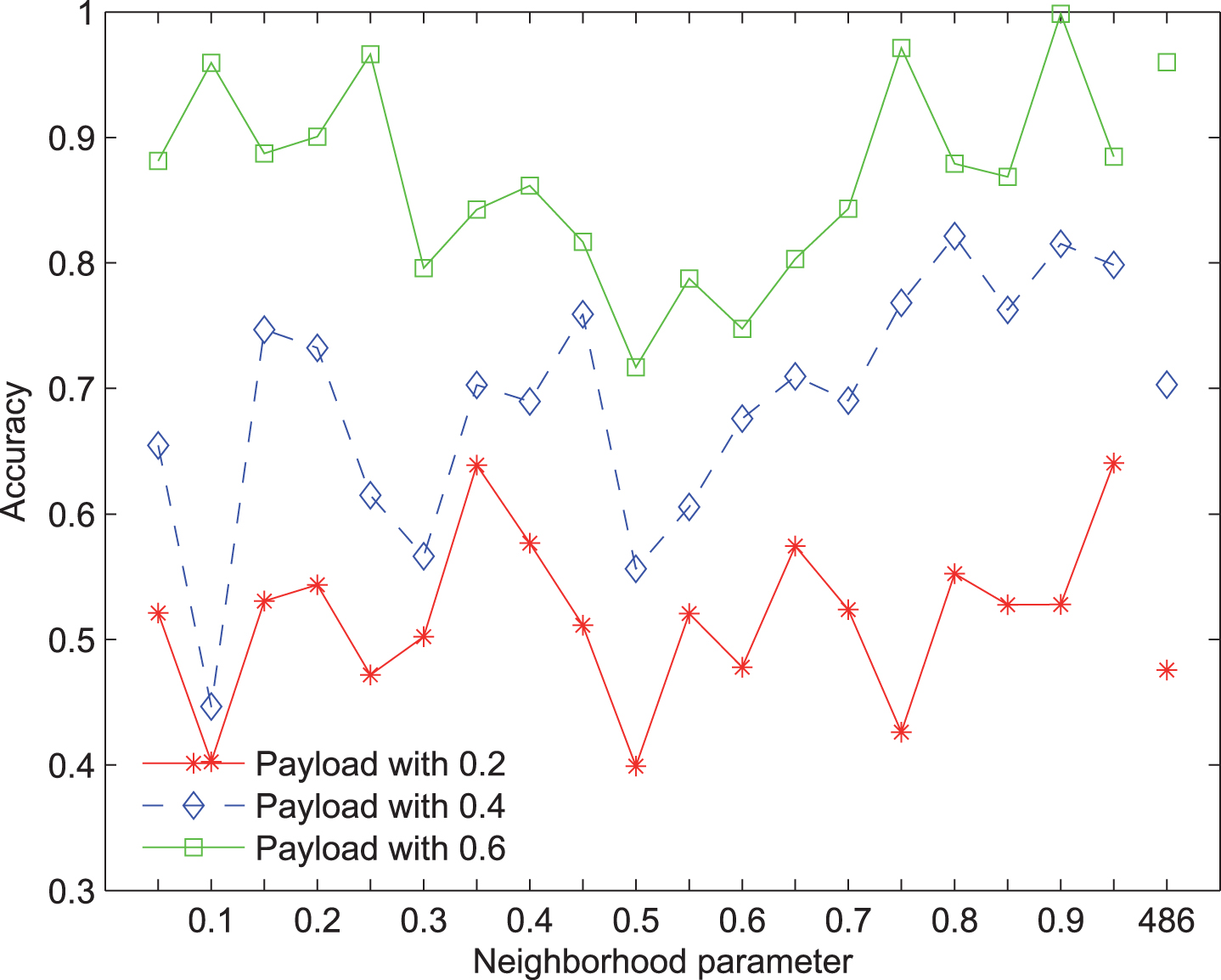
The KNN accuracy of selected features with F5 steganography and CHEN extractor via different neighborhood parameters.
This paper has focused the development of information security fields, tackling the problems of dimensionality curse of high-dimensional data, as well as dealing with real values of an image steganalysis system. We have achieved this by introducing the neighborhood rough set theory and proposing a feature selection method for blind image steganalysis. Considering the continue values of steganalysis systems, we granulate these values by a neighborhood parameter and construct neighborhood granules. Consequently, a positive region of neighborhood rough sets is developed to measure the uncertainty of a steganalysis system. Based on the positive region, a dependency is proposed to evaluate the significance of extracted features in a steganalysis system. Furthermore, a feature selection algorithm by neighborhood rough sets is designed. To show the usefulness of the proposed algorithm, various experiments of feature selection and learning algorithms are carried out on extracted features which are achieved by both SPAM and CHEN extractors in an image steganalysis system. The performance of selected features by our proposed method has been compared with that of original whole features and the classification accuracy under different neighborhood parameter values has also been studied. Experimental results show that our proposed feature selection algorithm for blind image steganalysis has a good advantage over reducing dimensionality and classification performance. In the future, the proposed feature selection method will be expeditiously employed to solve the steganalysis engineering problems with high dimensions.
Nowadays, the technologies of dealing with big data are deeply influencing both present and future life. Big data usually includes data sets with large sizes beyond the ability of commonly used methods to tackle within a tolerable elapsed time. The size of a big data reflects two aspects with large samples and high dimensions. In a big data of image steganalysis system, high dimension means ten of thousands of extracted features, while large samples means massive image samples. Our work provides an optional strategy for tackling the big data with high dimensions in the future. But for the big data with massive image samples, our proposed algorithm should be improved by a parallel computing.
Compliance with ethical standards
Funding: This study was funded by the National Natural Science Foundation of China (grant numbers 61976183 and 61573297), the Natural Science Foundation of Fujian Province (grant number 2019J01850) and the Program for New Century Excellent Talents in Fujian Province University.