
Abstract
The first major contribution of the paper is the proposal of using an improved DEtection Transformer network (named R2N-DETR) and Kinect-V2 camera for detecting multiple-size peaches under orchards with varied illumination and fruit occlusion. R2N-DETR model first employed Res2Net-50 to extract a fused low-high level feature map containing fine spatial features and precise semantic information of multi-size peaches from Red-Green-Blue-Depth (RGB-D) images. Second, the encoder-decoder was performed on the feature map to obtain the global context. Finally, all detected objects were detected according to each object’s global context. For the detection of 1101 RGB-D images (imaged from two orchards over three years), the R2N-DETR model achieves an average precision of 0.944 and an average detecting time of 53 ms for each image. The developed system could provide precise visual guidance for robotic picking and contribute to improving yield prediction by providing accurate fruit counting.
Introduction
Peach is one of the most economically important fruit species around the world, and the global yield reached 24.5 million tons in 2018 [1]. Considering the huge yield, peach harvesting is still a challenging task in the peach industry. Currently, manual harvesting is still the most commonly used method for fresh peach harvesting. However, the labor shortages, high labor costs, and inefficiency of manual harvesting force growers to employ more efficient methods for harvesting operations such as automated robot-based picking. Considering that fresh peaches are prone to be bruised due to collisions, most existing studies focus on harvesting peaches from trees by picking rather than bulk methods [2, 3]. A typical fruit picking robot first uses an optical sensor to take images of surrounding environments; then, detects fruits in the images using a machine vision algorithm and; finally, directs the manipulator to pick the fruits through the control system [4]. Due to the variation of peaches’ size, shape, color, and texture, as well as varied illumination and fruit occlusion, the collected images would have both complex foreground (peaches) and background surrounding environments [5]. Accurate and reliable detecting peaches from the images is an essential pre-step and one of the key challenges to robotic picking. To address the aforementioned challenge, this study developed a deep learning powered computer vision system to detect multi-size peaches from images collected in orchards, from which morphological features such as size and shape and the position of peaches can be derived. The information is useful for both peach robotic picking and peach growth and development evaluation.
For robotic picking, the vision system is only required to detect fruits in the target area, which is the area reachable by the manipulator. Information in non-target areas negatively affects the robotic picking, and thus should be removed. To this end, an RGB-D (Red, Green, Blue-Depth) sensor is suitable for image capturing. The Kinect v2 launched by Microsoft can capture RGB and depth information of the scene simultaneously and has been widely used to build low-cost vision systems for fruit detection in orchards [6]. RGB images provide rich color, texture, and geometric shape information of fruits, and the corresponding depth images record the distance between the camera (manipulator) and the objects. The non-target objects in the background could be removed by fusing the color and depth images [7]. After that, fruit positions could be detected from the fused images using object detection algorithms [8].
For the research topic of “general object detection”, which aims to explore the methods of detecting different types of objects under a unified framework, before 2014, traditional object detection algorithms, which were built based on hand-crafted features, attracted a lot of attention; after 2014, deep learning techniques achieved remarkable breakthroughs, which pushes the deep learning-based detection methods forward to a research hot-spot with unprecedented attention [9]. In deep learning rea, objection detection can be grouped into two branches: anchor-based detection and anchor-free detection. The anchor-based detection first presets numerous anchors on the image, then refine each anchor’s coordinates and classifies the object in it, and finally outputs the refined anchor as the prediction. This type of detection develops along two lines: “one-stage detection” and “two-stage detection”. The former (such as the Region-based Convolutional Neural Network (R-CNN) series) frames the detection as a “coarse-to-fine” process [10], whereas the latter (such as the You Only Look Once (YOLO) series) frames the detection as “complete in one step” [11]. Unlike anchor-based detection, anchor-free detections, such as CornerNet, CenterNet, and DEtection Transformer (DETR), eliminate the need of manually designing anchors and directly predict objects using a key or center point or region of the object [12].
As a “detection application”, the methods used to detect fruit in the orchard closely follows the “general object detection” in the past. Tu et al. [13], Wu et al. [3], and Wu et al. [14] detected fruits using hand-crafted feature-based classification methods. Considering the poor generalization of well-designed hand-crafted features, recent studies developed deep learning methods, which have efficient learning capability, robust generalizability, and plasticity, to detect fruits on trees. For example, Song et al. [15] applied a Faster R-CNN to detect kiwifruits in the orchard, taking 347 ms to detect an image and achieving 87.61% average precision (AP). Chu et al. [16] used a suppression Mask R-CNN with an F1-score of 0.905 and a detection time of 250 ms for apple detection and segmentation. Both two-stage R-CNN-based detection models have achieved good detecting performance but needed a long time for fruit detection. Tian et al. [17] employed an improved YOLO version 3 (YOLO-V3) model for real-time apple detection during different growth stages in orchards. YOLO-V4 was employed by Mirhaji et al. [18] to detect oranges in real-time, obtaining an mAP of 90.88% and a processing speed of 23.6 ms. The two researchers reported that the two types of one-stage YOLO detection models have made a tradeoff between accuracy and time consumption. However, the aforementioned four anchor-based detectors need to be fed with prior knowledge to set up anchor boxes. In the training model, massive redundant boxes would cause a serious imbalance of positive and negative samples, which reduces the detection accuracy of the model. Furthermore, the detection requires post-processing, namely non-maximum suppression (NMS) procedure, to remove redundant detected object boxes [17]. The inherent characteristics would undoubtedly reduce the detection accuracy of the models. Moreover, due to the fixed scales and aspect ratios of anchor boxes, the detection models encounter difficulties to handle object candidates with large shape variations [17]. The size and shape of the fruits in the images vary due to different shooting distances and occlusions. Hence, it is challenging to use the anchor-based models to accurately detect fruits with multiple shapes and sizes in orchards.
From the perspective of “information perception”, disturbances such as illumination variations, occlusions, and color changes are common in orchards. As a result, the object area is composed of a fruit and its background appears in the captured images in various forms. Facing the difficulty of detecting objects from complex backgrounds, the interaction between regions on the image helps to determine the attributes of each region [19]. However, the above four detection models extracted spatial features in the image through convolution neural networks (CNNs). Each convolutional module of the CNNs can only focus on the information in a specific area on the image, that is, local convolutional features. The CNNs split the connection between different spatial positions of the image, and cannot perform local feature interaction, which reduces the accuracies of the fruit detection models [20].
An anchor-free DETR, which involves a backbone, the encoder-decoder transformers, and a detect head, was proposed to address the limitations [21]. The implementation of DETR is independent of human-designed prior (including anchor and region proposal) and is completely dispensed with the use of NMS, performing truly end-to-end detection. Meanwhile, the encoder-decoder transformers of DETR can deeply exploit the relationship between the spatial positions of the feature map. In this way, each position is added with attention from other positions, which makes DETR achieve 42.0%–44.9% AP on the COCO dataset [22]. However, struggling to detect small objects is the main disadvantage for DETR. Further analysis, to save DETR from a huge amount of computational cost, its backbone provides subsequent transformers with a low spatial resolution map containing single-scale convolutional features [23]. Because several fruits in the image are defined as small objects [24], fruit detection in the orchard using the DETR continued to pose challenges.
The overall goal of this research was to develop an improved DETR to enhance the accuracy of identification and localization for peaches with various sizes, including small and medium size objects, in orchards. The specific objectives of this study were to (1) apply Res2Net module [25] to optimize the backbone of the DETR; (2) compare the performance of the improved DETR, named R2N-DETR, with DETR and two popular CNNs, e.g., Faster R-CNN and YOLO-V4; (3) verify that the improved backbone optimizing the detection of multi-size objects by the R2N-DETR model.
Data collection and processing
Experimental orchards
The plant materials used in this study were planted in two orchards - Yangshan Town (YT) orchard and Hongsha Bay (HB) orchard - located at Wuxi City, Jiangsu Province, China. There are two cultivars in the YT orchard, named ‘Hujin’ and ‘Baifeng’. Mature ‘Hujin’ peaches appear shadow light red and light green, and the surface of mature ‘Baifeng’ peaches is mostly light green. The height of trees is less than 3 m and the distance between the trunks for two adjacent trees ranges from 2.5 m to 3.5 m. The tree height and planting density in the HB orchard were the same as those in the YT orchard. Imaging data collection was conducted in open orchards with changing illumination and weather conditions. Figure 1 presented representative RGB images collected in the two orchards under different weather conditions (cloudy and sunny) and illumination conditions (overcast, direct lighting, back-lighting). Consequently, there is a big diversity for the peaches in terms of color and size, and the images are with complex backgrounds. All the peaches were mature based on the judgment of the orchard manager.
Four sample images from the collected dataset: (a) ‘Huji’ peaches imaged in the YT orchard on July 26, 2018, under cloudy and overcast conditions; (b) ‘Huji’ peaches imaged in the YT orchard on July 07, 2019, under sunny and direct lighting conditions; (c) ‘Baifeng’ peaches imaged in the YT orchard on July 15, 2021, under sunny and overcast conditions; (d) ‘Hujin’ peaches imaged in the HB orchard on July 24, 2021, under sunny and back lighting conditions.
A Microsoft Kinect-V2 sensor interfaced with iai_kinect2 Robot Operating System (ROS) (URL:
Imaging datasets for peach detection in the two orchards
Imaging datasets for peach detection in the two orchards
Illustration of the preprocessing of the raw imaging data. (a) Raw RGB image captured by Kinect-V2; (b) Aligned depth image extracted from the point clouds; (c) Preprocessed RGB-D image; and (d) Cropped RGB-D image.
In general, a deep learning-based detection model requires tens of thousands of images for training to increase accuracy, generalization, and robust performance. The self-collected training dataset contained only 770 images which is not enough for the training. To augment the training data, five operations, including flipping, rotation, scale, translation, and noise, were applied to the raw training dataset using Python 3.8. Specifically, firstly, all images were flipped horizontally (770 flipped images); secondly, each raw and flipped image was rotated at an angle in {
In this research, an anchor-free framework, named R2N-DETR, was developed for peach detection (Fig. 3). The R2N-DETR consists of four parts, including backbone, encoder, decoder, and prediction heads. (1) Res2Net-50, which has a strong multi-scale representation ability, was used as the backbone for learning a 2D convolutional feature from an input image. (2) The feature map was flattened and supplemented with a positional encoding, and then was used to feed an encoder to obtain a hidden map containing the position of the objects. (3) A small fixed number of object queries and the output of the encoder were imported to a decoder to obtain the fixed number of output embedding. (4) In the prediction heads, each output embedding was fed to a shared feed forward network (FFN) to predict either a detection (peach and bounding box) or a “no peach”.
Structure of the R2N-DETR.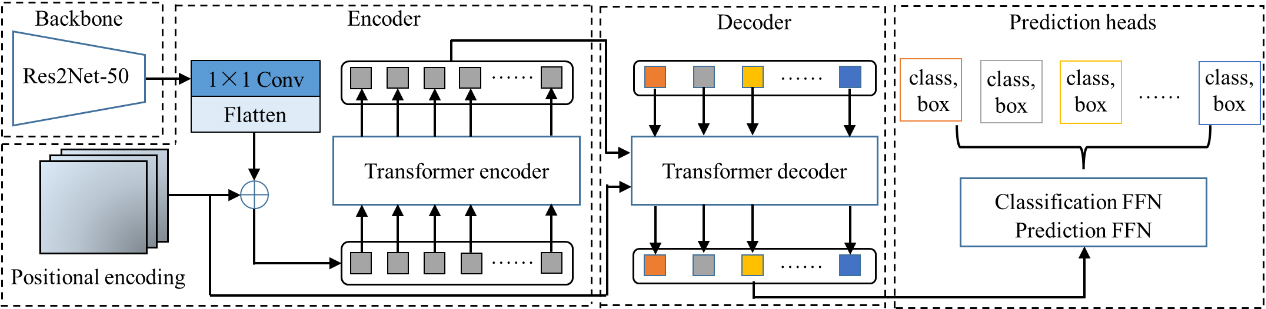
Illustration of the Res2Net-50.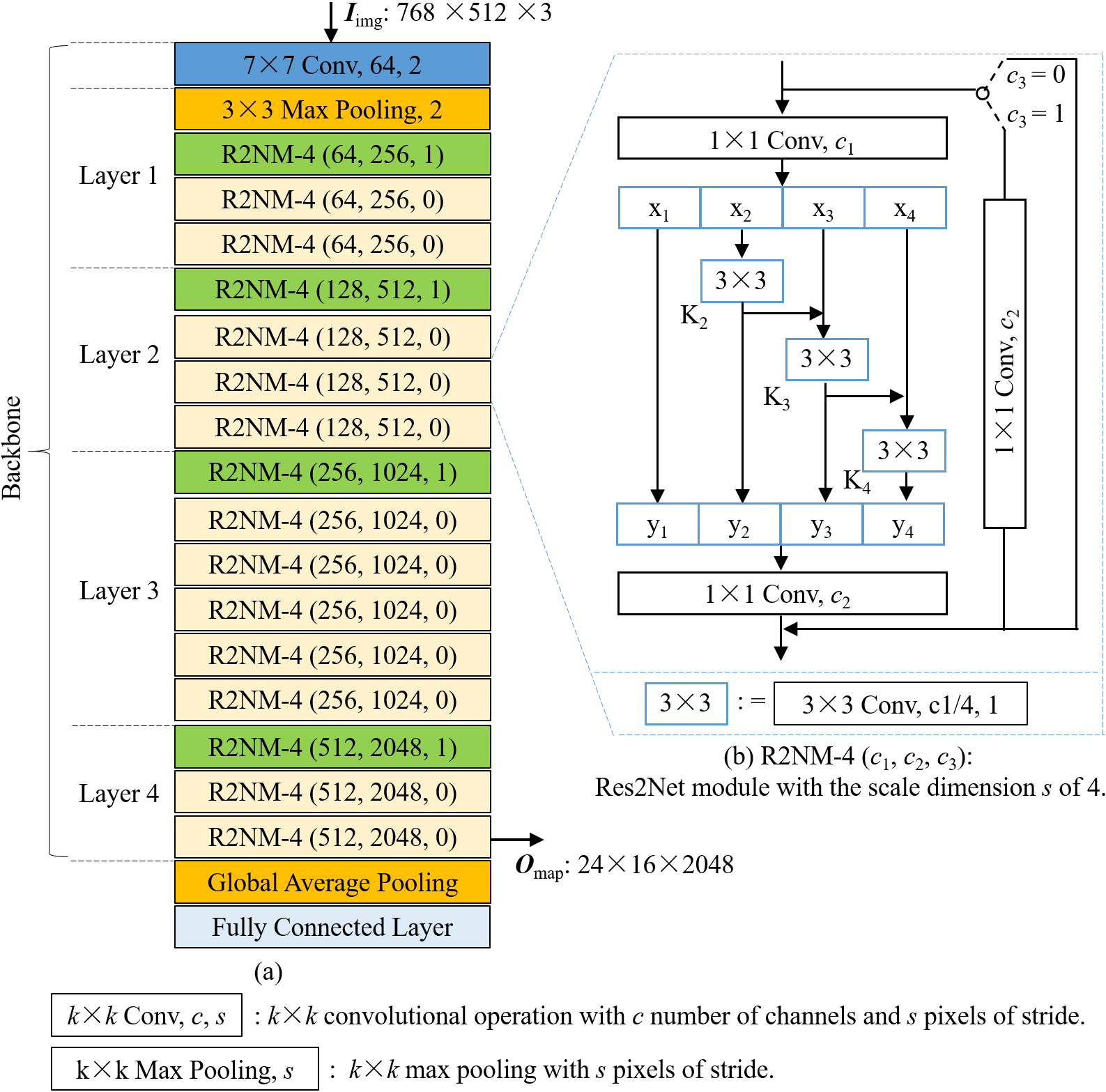
The DETR framework has limited ability to detect multi-size objects, especially small ones, because the feature map output from the backbone has low spatial resolution and contains only a single-size feature. However, on one hand, a high-resolution feature map may destroy the detection model, because the computing resources used by the encoder and decoder would increase with the square of the spatial size of the feature map. On the other hand, each layer of the backbone could perceive information of one size area on the input map. To address this problem, the R2N-DETR integrated the first 7
Note that each
Illustration of the transformer encoder.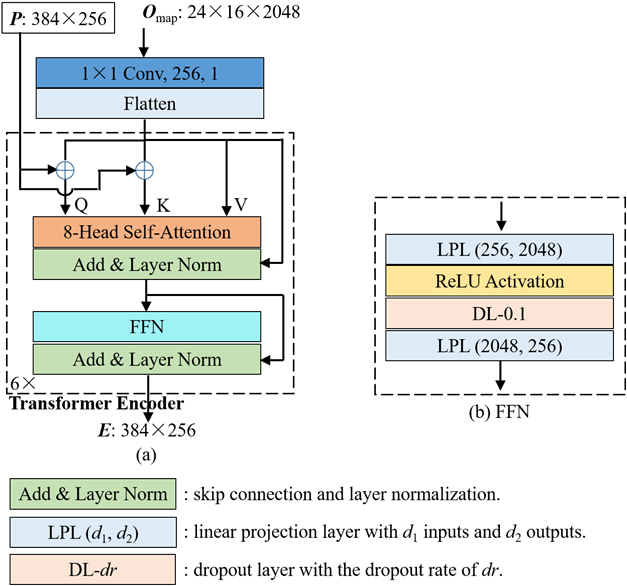
The encoder consisted of one 1
Illustration of the Res2Net-50.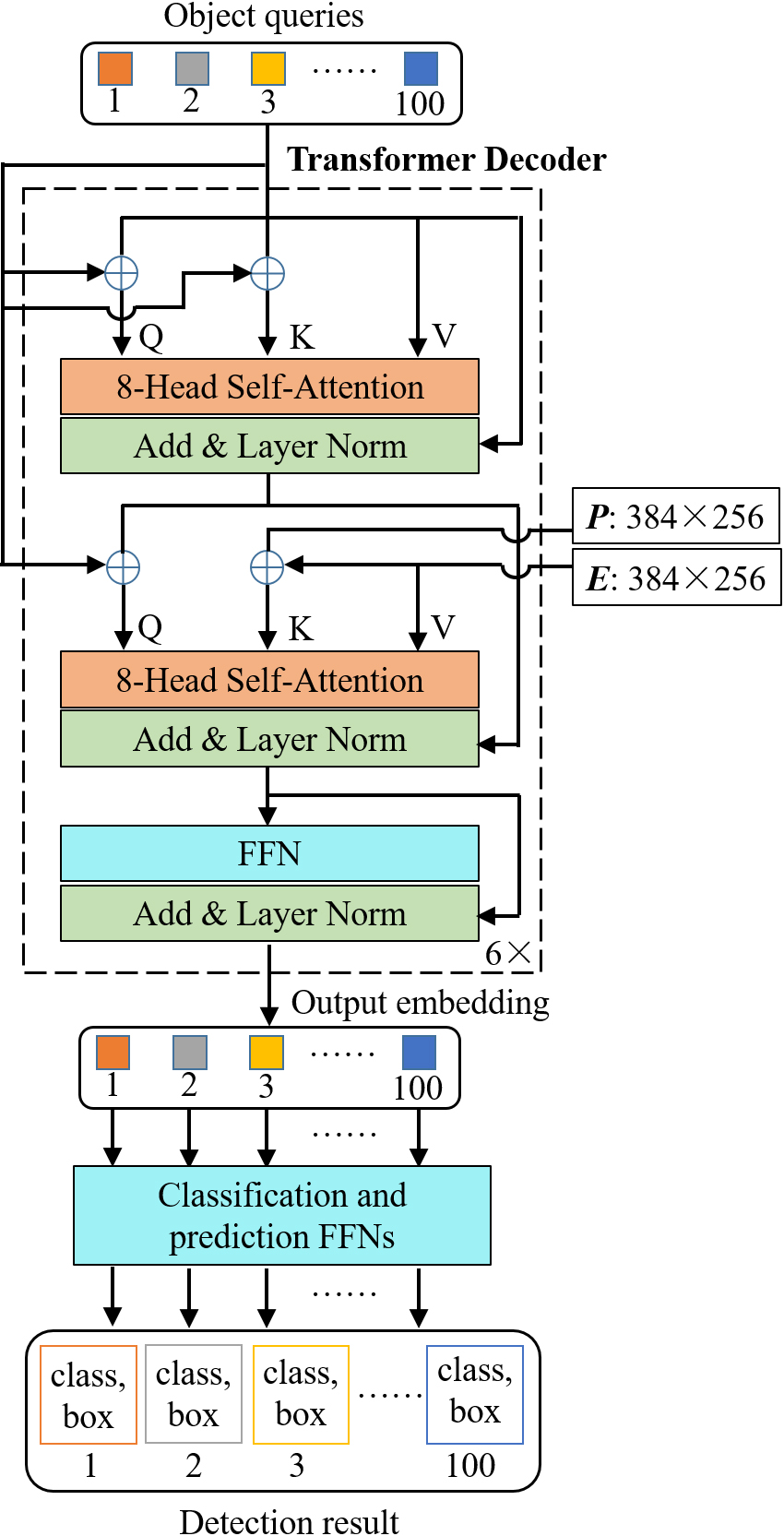
Following the DETR, the decoder of the R2N-DETR was used to transform the standard structure (Fig. 6). The R2N-DETR preset 100 tokens (object queries) for peach detection. Because the transformer decoder was permutation-invariant [21]. To detect peaches at different locations, the 100 tokens must be different. The tokens were fed into the first 8-head self-attention module to generate the attention between each token. Then, the feature map
Results and discussion
Network training
The R2N-DETR model had the same characteristics as the DETR model, and both were trained end-to-end based on a linear combination of a negative log-likelihood for class prediction and a bounding box loss [21]. The parameters and resources used in the training R2N-DETR model process were summarized in Table 2. A popular AdamW optimizer was used for updating network weights in training iterations [28]. Note that, the initial learning rates of the backbone and transformers were set to 1e-5 and 1e-4, respectively, and both were updated every 100 epochs. A dropout probability of 0.1 was used in the FFNs of all transformer encoders and decoders. Additionally, each self-attention module contained 8 heads.
Parameters and resources used in training models
Parameters and resources used in training models
In this research, the weights of the R2N-DETR were initialized based on transfer learning. First, the weights of the backbone used the ones from the ImageNet-pretrained Res2Net-50 model with the global average pooling layer and fully connected layer removed. Second, the weights of the pre-trained DETR by the COCO dataset were used as the initial weights for the proposed encoder-decoder model. Further, the R2N-DETR model was fine-tuned using our training dataset, and the training ran 1000 epochs. Forthe competitors, DETR, Faster R-CNN, and YOLO-V4, the hyperparameters, and initial weights were set according to the studies by Carion et al. [21], Fu et al. [7], and Mirhajiet al. [18].
After training, all peach detection models were evaluated using Precision (
Where TP, FP, and FN correspond to true positives (the peach objects were detected correctly), false positives (the peach objects were detected incorrectly), and false negatives (the peach objects were missed), respectively. The Precision measures the model’s ability to correctly detect peach objects. The Recall represents the detection model’s ability to find all peach objects in the image. The AP combining
The feature maps extracted by ResNet-50 (the backbone of DETR) and Res2Net-50 (the backbone of R2N-DETR) were visualized in Fig. 7. The ‘7
Visualized feature maps from ResNet-50 and Res2Net-50.
Overall, the proposed R2N-DETR model achieved a better AP while having smaller weights compared with the other popular used detection modes, i.e. YOLO-V4, Faster R-CNN, and DETR (Table 3). The R2N-DETR model achieved an AP of 0.94 for the tested peach images, which was 8.9%, 3.6%, and 3.2% higher than the ones obtained by YOLO-V4 (0.867), Faster R-CNN (0.911), and DETR (0.915), respectively.
Performance comparison between the three popular networks and R2N-DETR
Performance comparison between the three popular networks and R2N-DETR
Further, the one-stage model YOLO-V4 showed the lowest accuracy. The reasons were as follows. (1) YOLO-V4 mixed the box regression loss function and the object classification loss function, which increases the difficulty of the model learning weights [29]. (2) YOLO-V4 model regressed and classified an anchor using the convolutional features of a point on the deep feature map. Because a single point could only supply little information to the detection head and the widespread noise in the orchard would reduce the recognition of the point. The above shortcomings made YOLO-V4 often misidentify peaches in the orchard [30]. As presented in a representative peach detection example in an RGB-D image (Fig. 8), several peaches were missed by the YOLO-V4 model, such as a ‘Baifeng’ peach in a bright light area and a ‘Hujin’ peach whose surface was mostly covered with leaves.
Two examples of peach detection using the four deep learning models. The red, yellow, and purple bounding boxes denoted the truly detected, falsely detected, and missing peaches, respectively.
Compared with YOLO-V4, Faster R-CNN, DETR, and R2N-DETR set up separate branches for regressing object locations and classifying objects, which can learn weights in both branches independently. The separate setting resolved the mutual interference of regression and classification and improved the accuracy of detection models [31]. In addition, each of the Faster R-CNN, DETR, and R2N-DETR models comprehensively utilized region-specific deep convolutional features (anchor for Faster R-CNN model, query for DETR and R2N-DETR models) to regress and classify objects. Region-level features were both more expressive and robust than point-level features [30].
In terms of detection accuracy, the Faster R-CNN model was lower than DETR and R2N-DETR models (Table 3). For the Faster R-CNN model, some areas were falsely identified as peaches, additionally, a ‘Baifeng’ peach was detected as two objects due to interference from the leaves (Fig. 8). Because the Faster R-CNN model (1) only used local features with losing information to detect peaches, they were prone to low precision and recall rate; (2) during the training model, the dense anchor caused a serious imbalance of positive and negative samples. The encoder and decoder of DETR and R2N-DETR models were constructed using transformers, and the two models could extract long-range visual dependencies from deep feature maps, enriching the available information. Even if a region was losing information or contained a great deal of noise, its properties could be determined from information in other regions of the feature map [32]. Compared with the Faster R-CNN model, in DETR and R2N-DETR models, only 100 object queries (similar to anchors) were set for each detection, and each query was matched to a ground truth or background through the Hungarian algorithm, alleviating the imbalance impacts [21].
From Fig. 8, we observed that although some small-size peaches could be detected by the DETR, the leaves were false positives detected in the DETR model. Because ResNet-50 could not fuse low- and high-level features in the extracted feature maps as described in Section 3.1. The R2N-DETR model used Res2Net-50 and self-attention to address the problems of feature fusion and the use of global context, respectively, making it outperform DETR.
Regarding the weight size and the detection time for the four peach detection models, the YOLO-V4 model contained 64 M weights and averagely spent 32 ms to process an image. It has the lowest requirements for hardware devices. However, this model has low detection accuracy, which makes it difficult to be applied in the field. Although the Faster R-CNN model has excellent detection accuracy, and acceptable field application value, it contained the weights of 128 M and thus required numerous computing resources for detection, and it took 110 ms to detect each image resulting in insufficient real-time performance [7]. Both the DETR model and R2N-DETR model contained 41 M weights, and one GPU unit (GeForce GTX 1080Ti 11 GB) could execute the two models, and they spent 51 ms and 53 ms respectively to detect an image. Compared with Faster R-CNN, the two models have lower requirements for hardware devices, faster detection speed, and high detection accuracy, so they should be widely used in the field. Furthermore, considering the real-time and detection accuracy comprehensively [33], the R2N-DETR model seems to be the most suitable for field applications among the four models. This research achieves the preset objective Eq. (2).
In general, according to the pixel area of the corresponding object ground truth box, each object in the images was defined as a small object (area
Performance comparison between the DETR and R2N-DETR model on small and medium object subsets
Performance comparison between the DETR and R2N-DETR model on small and medium object subsets
Small and medium object detection examples using the DETR and R2N-DETR. The red, yellow, and purple bounding boxes denoted the medium, small, and missing objects, respectively.
In a previous study using an improved Faster R-CNN for small fruit detection, Mai et al. [36] reported 0.6743 P and 0.8522 R, which is lower than the P of 0.852 and R of 0.948 for small peaches obtained by the R2N-DETR model. Chu et al. [16] developed a suppression Mask R-CNN model to detect apples on trees. They reported 0.88 P and 0.93 R, the former metric higher than the R2N-DETR model’s 0.87 P but the latter metric lower than the R2N-DETR model’s 0.93 P. Using an improved YOLOv3-tiny (named DY3TNet) model to complete the real-time kiwifruit detection in the orchard, Fu et al. [24]reported 0.9005 AP which is 4.83% lower than the AP of 0.944 obtained in this research. Considering the differences in datasets, this study retrained DY3TNet using the peach training dataset, and the novel DY3TNet model achieved an AP of 0.873, which is also lower than that of the R2N-DETR model. Wan et al. [37] reported 0.9251, 0.8894, and 0.9073 AP values for apples, mangoes, and oranges detection using an improved Faster R-CNN, which are all lower than the AP of 0.944 obtained by the R2N-DETR model. However, caution should be taken when comparing the results for different studies, as factors like fruit type, image data type, and the size of the fruit in the image could all have affected the detection results. Nevertheless, the viability of using the Kinect-V2 camera combined with the R2N-DETR to detect multi-size peaches on trees was demonstrated in this study.
There is still room for the R2N-DETR model to improve peach detection in orchards. Specifically, (1) On the construction of the training dataset: The R2N-DETR is data-hungry deep learning that requires a large amount of image data to train detection models. To meet the data requirements, this study applied five data augmentation techniques to expand the size of the image dataset. However, these technologies inevitably introduced noise and ambiguity into the training process, resulting in reduced accuracy of the detection model. Hence, a data augmentation technique that can always keep important regions untouched during augmentation could improve the performance of the R2N-DETR model [38]. (2) On the size of the model; Both the encoder and decoder of the R2N-DETR consist of six standard transformer modules with fully connected layers, which results in the network having a large number of weights for learning. So it is difficult to train the R2N-DETR model. A reliable solution to the above problem is to construct the encoder and decoder of R2N-DETR by using two lightweight transformers with recursive atrous self-attention [39]. The improved encoder and decoder will apply fewer weights to achieve similar functions to the original encoder and decoder. (3) On the small peach detection: Although the R2N-DETR model performed well for small peaches detection, the detection accuracy for small objects could be further improved if the encoder and decoder of the R2N-DETR model are replaced by a dynamic encoder and dynamic decoder, respectively, and the typical feature pyramid is used to connect the backbone with the encoder [40]. We will work on the improvement in the future.
Conclusion
This research examined an improved DETR, called R2N-DETR, for multi-size peach detection using RGB and depth images collected by a Kinect-V2 sensor in open orchards, which could help improve robotic fruit picking by providing reliable detections for small- and medium-size fruits. In the R2N-DETR network, the Res2Net-50 extracted multi-scale convolutional features from an input image, and the transformer module improved the R2N-DETR model’s ability to capture long-range visual dependencies. They significantly contributed to the reliable peach detection in orchards. Also, the R2N-DETR model contained 41 M weights and had a detection speed of 53 ms/image, which could be used for real-time field applications. Overall, the R2N-DETR can efficiently and effectively detect multi-size peaches in orchards. The Kinect V2 sensor combined with the R2N-DETR model could be suitable for peach-picking robots. Further work will focus on exploring the fusion method of RGB and depth images, as well as exploring 3D point cloud object detection in recognizing peaches in orchards.
Footnotes
Acknowledgments
This project is supported by the National Natural Science Foundation of China (Grant no. 62273166; 61772240), the 111 Project (B12018), and the Natural Sciences and Engineering Research Council of Canada Discovery Grants program (Grant no. G256643). The authors thank China Scholarship Council (CSC) for the financial support to the author (Yu Yang) to conduct his doctoral research in the Department of Bioresource Engineering at McGill University. The authors also gratefully thank Meng Zhang and Liang Wang for the help on data collection in Yangshan Town orchard and Hongsha Bay orchard, Wuxi City, in China.