
Abstract
With the development of human-computer interaction, gesture recognition has gradually become one of the research hotspots. The cost reduction and the richer information of RGB-D images make the research of gesture recognition based on RGB-D images more and more. However, the current gesture processing methods for RGB-D images still can not fully utilize the information contained. Aiming at the above problems, this paper studies the feature extraction method of RGB-D image, and proposes a multimodal and multilevel feature extraction method. By extracting multimodal and multilevel image features for mapping and splicing, the utilization of RGB-D image information and the accuracy in recognition are improved effectively. Finally, the experiments verified the effectiveness and robustness of the proposed method based on the self-built gesture database. Compared and analyzed with several other RGB-D processing methods, the processing method of this paper is more advanced and effective, and can achieve better results in gesture recognition.
Introduction
Traditional human-computer interaction methods mainly need input and output devices to interact, such as keyboards, mice, monitors, etc [1]. Different from the human communication methods, the interaction with complex tasks is very difficult. Therefore, in order to realize human-computer interaction in a more natural and direct way, many scholars use visual methods to capture and collect human body behaviors and actions, and conduct corresponding research [2, 3]. As one of the most flexible and complex communicative limbs in the human body, hand is one of the cores of human-computer interaction research in the recognition of posture or behavior. The significance of the research on gesture recognition is to map the behavior or action produced by human hands into a machine-understandable behavior, so that the interaction between human and machine no longer requires complex and inaccurate manipulation of the intermediate media, but directly manipulates the machine through human hands. In recent years, the gesture manipulation has been widely used in various products of various industries. The large-scale intuitive experience of human-computer interaction methods changes has led to a broad application prospects on gesture recognition technology, such as virtual reality, entertainment games, industrial control and other fields [4].
With the development of sensors such as Kinect, RGB and depth images can be collected synchronously, which provides new research ideas and methods for how to achieve more intelligent human-computer interaction [5, 6]. The development of low-cost RGB-D cameras allows adding scene-to-camera distance information to RGB images. The color, texture, appearance and geometric information of the target can be obtained better by using both of depth images and RGB images, so as to perform better. Different methods are usually used to extract features from the two modes (RGB and depth) when using RGB-D data to recognize, such as using different handmade feature descriptors (SIFT, Textons and Depth Edges, etc) [7, 8] to match object in two modes. But there are many problems in the traditional feature extraction method, especially in gesture, the human hand is flexible, changeable, and has many degrees of freedom, also its motion speed will affect the change of gesture. The gesture change of human is complex and uncertain. When recognizing gestures in real environment, we need to consider the influence of environment, gesture size, different light intensity, hand movement speed and other factors on gestures. The accuracy, real-time and robustness of gesture recognition are required to be high, making gesture recognition still have a large room for improvement [9, 10].
In the remainder of this paper, Sect.2 reviews the research status at home and abroad. In Sect.3, the methods of collecting and preprocessing samples are introduced. And then, the multilevel multimodal fusion framework is introduced and a multilevel multimodal network structure is designed in Sect.4. Subsequently, the experimental results of gesture recognition are analyzed. In the last section, conclusions are presented.
Related work
At present, the precision of image sensor is getting higher and higher, and the cost of data acquisition is also decreasing. Therefore, gesture recognition based on computer vision has gradually become one of the research hotspots and core points, which has been widely concerned and studied by scholars [1].
Belgacem, S et al [2] proposed a novel markovian hybrid system CRF/HMM for gesture recognition, and a novel motion description method called gesture signature for gesture characterization. The model was applied to the recognize gestures in videos and achieved good performance, remained independent from the moving object type. Different from the recognition method based on image features [3], the model-based method detects the edge contour of the hand in the image firstly, establishes the hand model according to the edge contour, and finally recognizes the gesture through the geometric shape of the hand model [4]. The model-based gesture recognition method can get better recognition results, but it often needs to search and match in high-dimensional space, so that it is difficult to achieve real-time gesture recognition [5]. Li et al built a SAE-PCA gesture recognition network based on the combination of sparse self-encoder and CNN network. The network extracts RGB-D image features based on neural network and uses SVM classifier to recognize 24 static letter gestures successfully [6].
Since 2010, some classical 3D sensors, such as Kinect, Xtion and Leap Motion, have been appearing continuously, which greatly reduces the complexity of 3D human-computer interaction. The binocular and multi-eye cameras obtain distance information through multiple cameras and then determine the location of the target through camera calibration. In short, the images obtained by these devices have not only image information but also depth information [7].
Pigou, L [8] et al. explored deep architectures for gesture recognition in video and proposed a new end-to-end trainable neural network architecture incorporating temporal convolutions and bidirectional recurrence. He et al. [9] put forward an image feature set which contains three kinds of Haar features and applied it to pedestrian detection and face recognition and achieved good results. However, due to the fewer features, the use of this feature requires a larger training set, which makes its practical application difficult [10]. Since the hand is one of the flexible and variable parts of the non-rigid human body, there can be subtle differences in completing all kinds of movements, which makes each movement distorted. So Yimin Zhou et al. [11] proposed to extract palm and finger features separately to compensate for the robustness of gesture recognition. Bhuyan [12] et al. realized the detection of gesture area based on skin color features and assisted by face detection, and then realized the recognition of 10 gesture areas. Sharp T [13] took the prime difference of gesture image as feature and realized the detection and tracking of gesture. P et al [14] uses pixel histogram to show the relationship between the number of fingers, and distinguishes between gestures 1 and 9. Eventually, its average recognition rate reached about 90%. Escalante, HJ et al [15] detected the outline information of the finger and judged the category by its specific number and direction. Lenz et al. [16] proposed a multimodal deep learning method for robotic grabbing detection, which uses stacked automatic encoders for multimodal feature learning. In addition, the introduction of quantum computer system in the traditional neural network can improve the convergence of the network and the stability of the algorithm. The literature [23] proposed a new quantum watermarking scheme based on quantum wavelet transform including scrambling, embedding and extracting procedures, and the method is verified to be robust. Literature [24] proposed a quantum image coding scheme, randomly generating a binary key for each pixel of the image. Reference [25] presented sequre quantum key distribution based on a special Deutsch-Jozsa algorithm using Greenberger-Horne-Zeilinger states. Studies [26–29] conducted an in-depth study of Multipartite quantum correlations.
In summary, although there are many methods for gesture recognition, vision-based gesture recognition still faces many serious problems in practice [17–19]. Most of them use color images acquired by a single camera or grayscale images and binary images processed by color images to recognize, but it is constrained by environmental illumination, background complexity and human skin color [20, 21]. It is always a difficulty to extract target gestures from complex and uncontrollable background. In these feature learning methods based on RGB-D images, the relationship between different modes has not been studied in depth. Most methods either learn features from color and depth patterns separately, or simply treat RGB-D as undifferentiated four-channel data [22]. The main disadvantage of separated learning is that it ignores the relationship between the two modes. The characteristic learning of one mode is not adjusted by another mode [30]. The main disadvantage of a simple four-channel learning is that this combination may not have physical significance or utilize the different features of the form [31, 32].
Gesture sample collection and preprocessing
Sample collection
In order to verify the performance of the proposed multimodal fusion method for gesture recognition under different conditions, it is necessary to create an RGB-D gesture database, which considers the noise effects of different illumination intensity, angle and size gesture samples [33]. Kinect is used to collect ten kinds of gesture samples from different people to represent the number 0–9. In order to make the experiment more convenient, the 10 numbers of 0–9 are expressed by gesture 1–10, as shown in Fig. 1. Each type of gesture chooses 2000 samples, 500 samples as test samples, and 1500 samples as training samples. Therefore, the total number of gesture samples for self-built gesture data is 40,000, of which 20,000 RGB images and corresponding 20,000 depth images. Figure 2 is part of the samples collected in this paper. These samples are collected under different scales, rotation angles and illumination conditions. Figure 2 (d) is a noise-added image, which is used as a sample to verify the robustness of the algorithm. In this chapter, the frame number of Kinect is 30FPS, the resolution is 640*480, the hardware is CPU-i5, the memory is 8 G, and the Ubuntu 16.04 system is used.

10 RGB-D gesture samples.

Partial sample images collected under different conditions.
The data obtained by Kinect can not be directly used as input of computer vision algorithms [34, 35]. Most algorithms use both RGB data and depth data. In order to combine RGB image with depth data correctly, it is necessary to align the output of RGB camera with that of depth camera [36]. In addition, the original depth data is very noisy, and many pixels in depth images may not be able to accurately collect depth data due to reflection or surface scattering, such as human tissues and hair [37]. Those missing “holes” need to be restored before using, therefore, Kinect data needs to be recalibrated or filtered [38].
Depth data calibration
Assuming that the three-dimensional coordinate system of the depth camera is M
d
= [X
d
, Y
d
, Z
d
]
T
, the three-dimensional coordinate system of the color camera is M = [X, Y, Z]
T
, and the projection coordinate of the two-dimensional color image is m = [u, v]
T
, the corresponding relationship between the two coordinate systems is established by translating and rotating the matrix:
In the Equation (1), R is a rotation matrix and t is a translation vector [39]. According to the principle of keyhole imaging, there is the following relationship between the three-dimensional coordinates of the camera and the pixels of the two-dimensional projection:
In the Equation (2), K is the camera internal parameter matrix [40].
The coordinate system is expressed in homogeneous form and the pinhole model is used to model the color camera.
In the Equation (3), α and β are the scale factors of the pixels on the image plane [41]. Since the upper left corner of the pixel coordinate system is the (0,0) point, (u0, v0) is the coordinate of the origin of the image coordinate system in the pixel coordinate system and γ is the skewness of the coordinate axis.
The pixels of the depth image are marked as x = [u, v, z]
T
, (u, v) is the pixel coordinates, z is the depth value, The mapping from x to M
d
is known, and denoted as M
d
= f (x). The rotation and translation between the color three-dimensional coordinates and the depth three-dimensional coordinates are expressed as follows.
From the above analysis, the internal parameters of the camera are related to the value of α, β, γ, u0, v0, and the external parameters are related to the value of R, t. Zhang [49] et al. provided a set of measurements of internal and external parameters.
The rotation angle and translation vector are expressed in spherical coordinates as follows.
3.2.2.1. Median filtering. Median filter is mainly used for noise reduction in image processing. Its characteristic is retaining the edge information of the image [50]. For the acquired images, the unprocessed images contain missing information, these missing values are more likely to have similar values with their neighbors [51]. Therefore, median filter fills the vacancies while preserving the edges. The D without depth data is given a pixel coordinate (u, v), ω is the neighborhood of (u, v), the depth value after median filtering is:
3.2.2.2. Bilateral filtering. The principle of bilateral filter is based on Gauss distribution and it is used to reduce noise and image smoothing in image processing [42, 43]. The filtered pixels are replaced by the weighted average of neighborhood pixels in the detection window [44]. The weight depends on the spatial distance between two pixels [45]. This method has been effectively used to solve discontinuities in Kinect images.
Assuming that D (x, y) is a depth image, Px,y is a pixel in the image, Wx,y is a weight normalization factor, ω is the neighborhood of pixel (x, y), G
σ
s
and G
σ
r
represent the weight of spatial range thresholds s and pixel range thresholds r in a Gauss function respectively, the depth value after bilateral filtering is:
3.2.2.3. Joint bilateral filtering. Joint bilateral filtering is an improvement of bilateral filtering. On the basis of bilateral filtering, color information is taken as additional information. Unlike the bilateral filtering formula, the color image I is used replace the depth image D to calculate the weight [46].
Median filter is mainly used to compensate missing data, while bilateral filter is used to smooth adjacent pixels. In depth images, median filtering can fill the missing data well, but it has no effect on the fluctuation of depth with time. In contrast, bilateral filter is used to smooth depth values, but it only works in the spatial domain [47]. Therefore, defining a comprehensive noise model is an important first step to achieve effective depth image filtering. As shown in Fig. 3, gesture samples are processed based on bilateral filters. The left image is the original depth image and the right image is the filtered gesture image.

Gesture sample preprocessing based on bilateral filter.
Multilevel and multimodal fusion framework
Conventional methods for recognition based on RGB-D images are: 1) separate learning features of RGB images and depth images. 2) simple processing of RGB-D images as four-channel data. 3) features are extracted by different networks firstly and fused in the last full-connection layer. 4) only use the last layer to output features for prediction or classification. the features of the front layer are not considered. 5) considering the difference of features among different modes and fusing them. 6) fusing and classifying the features of different levels [48–50].
There is a problem in these methods, that is, the relationship between different modes is not fully considered or the complementarity between different levels of features is not taken into account. Based on this, a pair of convolution neural networks is used to extract the features of RGB and depth images, and the features extracted at different levels are analyzed in this paper. The features extracted at the same level are mapped and stitched to get the feature core of multimodal fusion at the same level. Then the features of multimodal fusion at different levels are arranged according to the time sequence, and the low-level fusion features are used to assist the high-level features to form a more compact fusion feature core. Figure 4 shows a multimodal multilevel fusion feature extraction method framework.

Framework of feature extraction method based on multilevel and multimodal fusion.
There are multiple different levels of feature extraction layers in SSD (Single Shot MultiBox Detector, SSD) network structure [51, 52]. It is precisely because of this feature extraction method that it runs fast and has good recognition accuracy even in low resolution pictures [53]. Based on the idea, two CNN networks [54] with the same structure are used to extract different abstract hierarchical features of RGB modal data and Depth modal data respectively, and then fusing feature in appropriate ways to obtain more discriminative and robust RGB-D fusion features.
As shown in Fig. 5, i
rgb
∈ I
rgb
represents the input RGB image, idepth ∈ I
depth
represents the input Depth image, l
True
∈ L
True
represents the corresponding label of the image, where I
rgb
IdepthL
True
represent RGB image set, Depth image set and label set respectively.
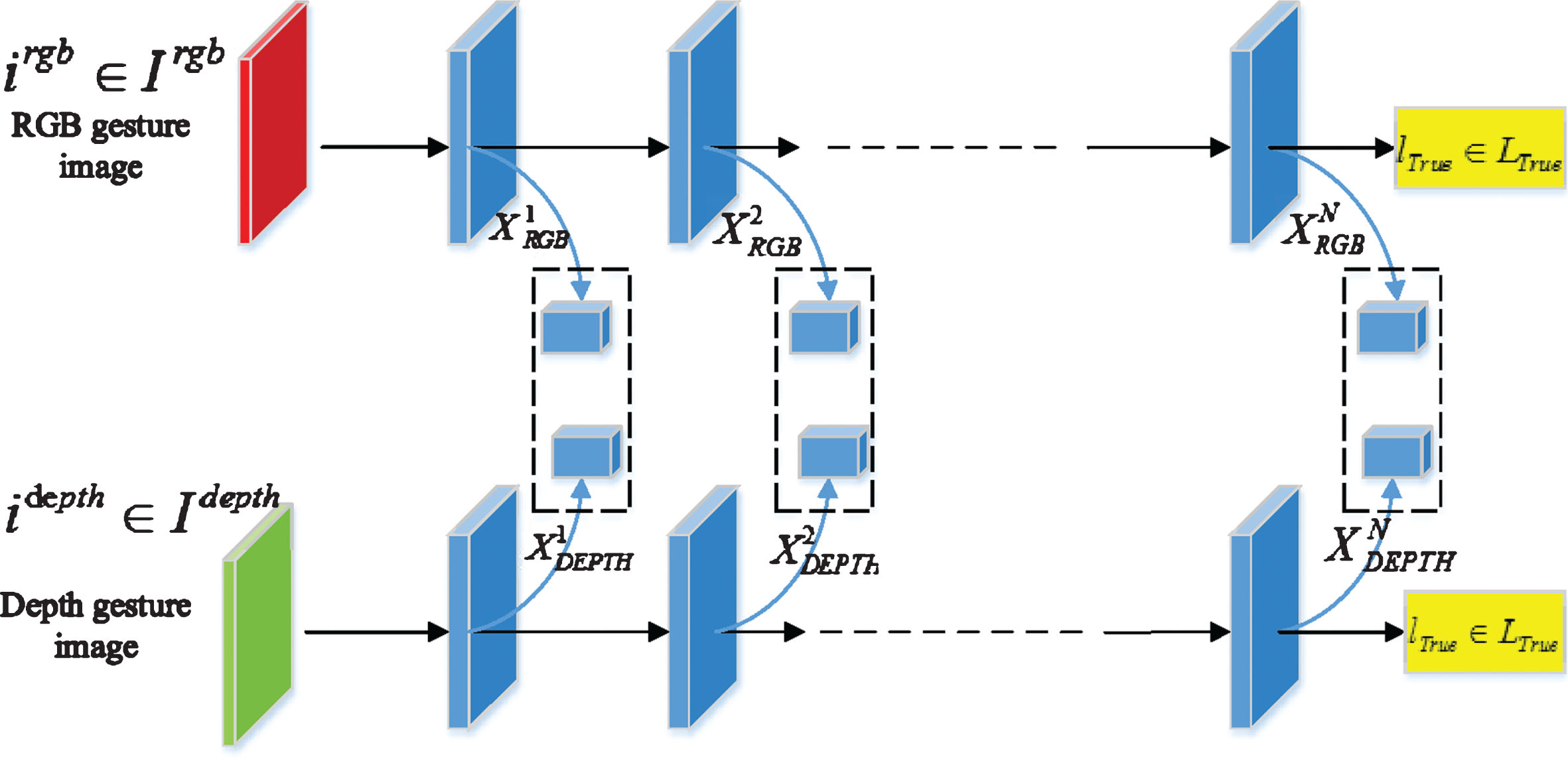
Characteristic extraction diagram of dual-stream convolution neural network.
Network architecture
Because of the difference between the two modes, this paper constructs a smaller network for each network, so as to ensure that the data of the two modes can be placed in GPU memory at the same time. The size of the input image is adjusted to 150 * 150. In RGB mode, the convolution kernels of layers 1, 2, 3, 4 and 5 are 7*7*3, stride 2, number 96; 5*5*96, stride 2, number 96; 3*3*96, stride 1, number 112; 3*3*112, number 128, stride 1; 3*3*128, number 128, stride 1, respectively. The size of the two full-connected layers is 1024 and 512, respectively. The first full-connected layer dropout size is 0.5. For each 150 * 150 image, the overlapped 142 * 142 image is clipped for data expansion. There is a maximum pooling layer after the first, second and fifth convolution layers, and the ReLU nonlinearity is applied to the output of each convolution layer and each full-connected layer. When the CNN is initialized by independent training using RGB and depth images, the size of the final full-connected layer equals the number of categories, and then it is input into the final SoftMax layer. In addition to the size of the convolution core in the first convolution layer (RGB image has three channels, that is, the first convolution core is 7*7*3. Depth image has one channel, that is, the first convolution core is 7*7*1), the same network architecture is used for RGB mode and depth mode in this paper.
Feature mapping mosaic
For the output characteristics of different convolution layers, if we want to apply them jointly, we should first consider how to solve the problem of lack of one-to-one correspondence among the elements of different feature vectors caused by different dimensions [55, 56]. More formally, different eigenvectors generally have different dimensions [57], so two different dimensions have different eigenvector spaces. In order to fully consider the characteristics of different abstract levels, it is necessary to map all the features of different dimensions into a unified feature space, so as to achieve feature mosaic [58, 59].
The feature mapping model consists of two convolution layers (including ReLU) and a global maximum pooling layer. The feature input of different abstraction layers is transformed into the same size vector (1*n), where n represents the number of convolution kernels. As shown in Fig. 2. This paper designs a feature mapping model in this way: the first convolution layer uses n convolution kernels of size 7*7 to extract the spatial size, width and height of feature vectors, while the second convolution layer uses n convolution kernels of size 1*1 to extract the depth information of feature vectors. Finally, the global maximum pool computes the maximum of each depth slice. The size of convolution core is tried according to the rule of thumb, and the best performance is selected to determine its size after this attempt. Figure 6 is the structure diagram of feature mapping module, through which features
The feature mapping module is shown in Fig. 6, the above mapping operation is expressed by a formula as follows:

Feature mapping module.
In the formula,
In order to demonstrate the superiority of the multimodal gesture recognition method in this paper, based on the self-built gesture database, several deep learning methods for RGB-D gesture recognition are constructed by ResNet [60, 61], and compared with the methods in this paper. Several different methods are designed as follows: 1) building ResNet network with only depth image as input, as shown in Fig. 7(c). 2) building ResNet network with only RGB image as input, as shown in Fig. 7(c). 3) using RGB-D data as four-channel data to identify ResNet network, as shown in Fig. 7(a). 4) The RGB-D bimodal data is used and combined in the full-connected layer of the last layer, as shown in Fig. 7(b). Four network structures are shown in Fig. 7, in which the left-most part is the input sample, the large cube represents the RGB image and the small one represents the Depth image; the right-most red cube represents the output of the network. In the middle part of the network structure, the deep blue cube represents the convolution layer, the light blue cube represents the pooling layer, and the green cube represents the full-connected layer; the dotted line represents the input RGB. Or Depth image, it is optional input.
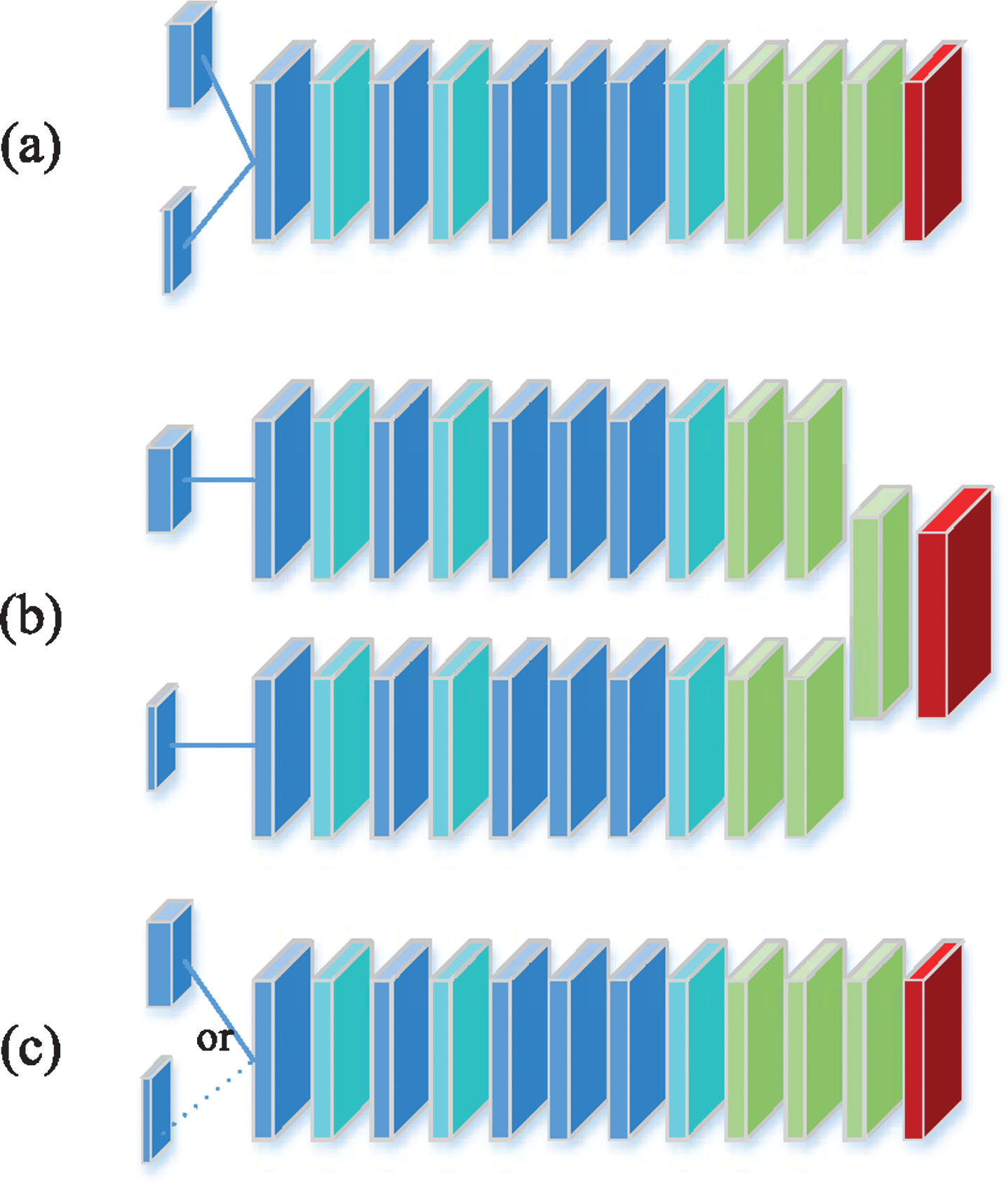
Different processing methods for RGB-D data.
After completing the above feature extraction, the extracted features are connected to the LSTM network for classification and recognition, and the output of the LSTM network is connected to the Softmax layer, then output the classification result. The models of three different methods in Fig. 7 above are constructed, and the final classification accuracy can be obtained by running the models on the self-built gesture database. As shown in Table 1, the accuracy comparison of different methods on the self-built gesture database is shown. The comparison of the tables, proves that the accuracy of the network which simply uses RGB-D data as four-channel data input is higher than that of the single-mode network, but the gesture recognition rate on the fusion network is better than that of other methods.
Experimental results of different network structure methods in RGB-D gesture dataset
According to the recognition accuracy of several different structure methods on the self-built gesture database, the feasibility and accuracy of the proposed method are verified. However, the recognition accuracy of the proposed method is unknown compared with the most advanced methods. Therefore, several current cutting-edge object recognition methods or gesture recognition methods based on RGB-D images are discussed. The effectiveness and accuracy of the proposed method are compared and analyzed and the experimental results are shown in Table 2.
Experimental results of different network models on self-built gesture data sets
In order to understand the quality of the proposed method more intuitively and clearly, the confusion matrix [63] of this method is calculated on the basis of RGB-D gesture database, as shown in Fig. 8.
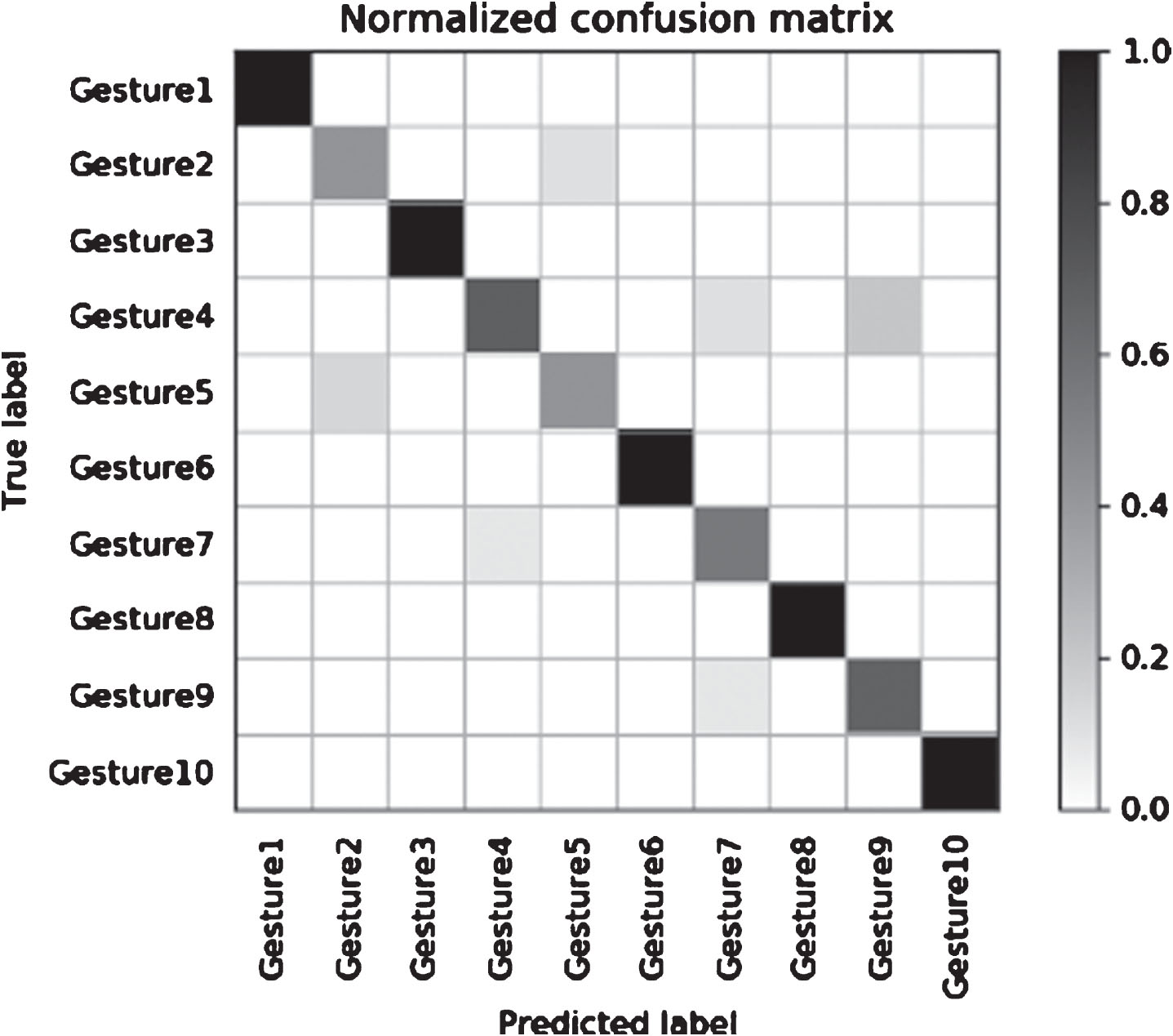
The confusion matrix of the method proposed in this paper on the self-built gesture database.
As shown in Fig. 8, the diagonal line of the obfuscation matrix represents the recognition accuracy of each category, with the value from 0 to 1 and 1 is the highest. From the figure, we can see that there are still some misunderstandings in the classification of some gestures, but the overall accuracy of gesture recognition is quite good.
In order to verify the generalization performance of the model, the method is compared with several methods with superior performance in American Sign Language (American Sign Language, ASL) [64, 65]. The results are shown in Table 3.
Experimental results of different network models in the ASL gesture dataset
At the same time, in order to understand the validity and accuracy of the method in the ASL database, the confusion matrix on the database is calculated, as shown in Fig. 9.
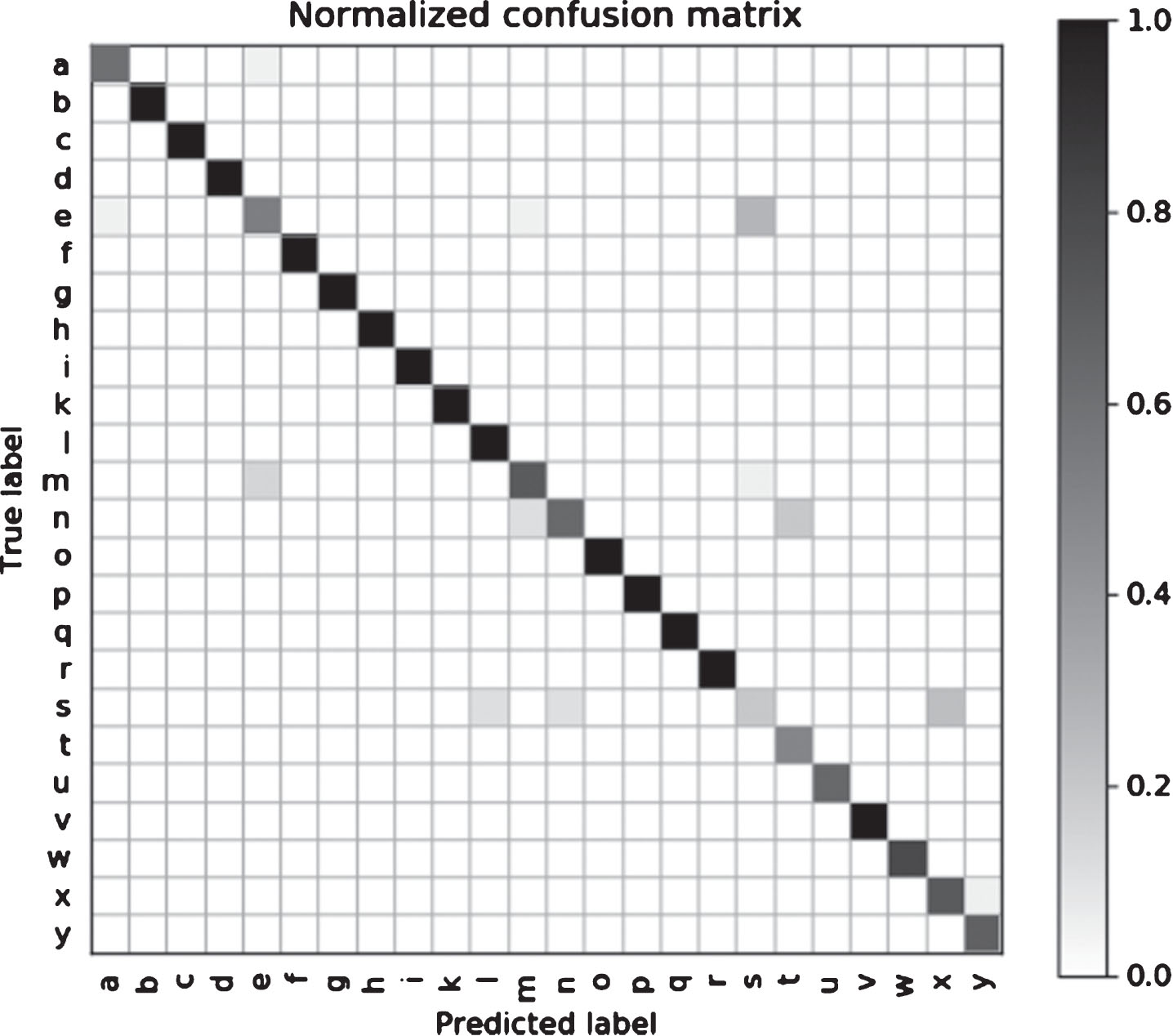
The obfuscation matrix of the proposed method on ASL gesture database.
From the comparison results of the maximum recognition rate, the minimum recognition rate and the average recognition rate in Table 3, the method in this paper is superior. The 24 types of static gesture samples in the ASL database are selected as data samples. From Fig. 9, it can be seen that the proposed method has better recognition effect.
Firstly, introduced the sample database of RGB-D gesture image and preprocessed the sample. Then designed the multimodal and multilevel fusion gesture recognition framework. On the basis of the above, designed the structure of convolutional neural network with two modes, and extracted the feature of different abstract levels under different modes. In order to solve the problem of different feature dimensions of different modes, a feature mapping model is designed to map the features of two different modes into the same feature space, and then completed the feature mosaic. The multilevel and multimodal fusion features are obtained by arranging the multimodal fusion features of each level in time sequence. Finally, input the feature into LSTM network, and connected the output of the network to the Softmax layer to output the classification and recognition results. By comparing different RGB-D gesture image processing methods, it is demonstrated that the proposed method has better processing effect and higher recognition rate. Then compared with other advanced methods, the recognition rate and feasibility of this method are superior.
Footnotes
Acknowledgments
This work was supported by grants of National Natural Science Foundation of China (Grant Nos. 51575407, 51505349, 51575338, 51575412, 61733011); the Grants of National Defense Pre-Research Foundation of Wuhan University of Science and Technology (GF201705) and Open Fund of the Key Laboratory for Metallurgical Equipment and Control of Ministry of Education in Wuhan University of Science and Technology (2018B07).