
Abstract
Self-training algorithm highlights the speed of training a supervised classifier through small labeled samples and large unlabeled samples. Despite its long considerable success, self-training algorithm has suffered from mislabeled samples. Local noise filters are designed to detect mislabeled samples. However, two major problem with this kind of application are: (a) Current local noise filters have not treated the spatial distribution of the nearest neighbors in different classes in much detail. (b) They are being disadvantaged when mislabeled samples are located in overlapping areas of different classes. Here, we develop an integrated architecture – self-training algorithm based on density peaks combining globally adaptive multi-local noise filter (STDP-GAMLNF), to improve detecting efficiency. Firstly, the spatial structure of the data set is revealed by density peak clustering, and it is used for empowering self-training to label unlabeled samples. In the meantime, after each epoch of labeling, GAMLNF can comprehensively judge whether a sample is a mislabeled sample from multiple classes or not, and it will reduce the influence of edge samples effectively. The corresponding experimental results conducted on eighteen UCI data sets demonstrate that GAMLNF is not sensitive to the value of the neighbor parameter

Introduction
Supervised learning is popular research in machine learning and data mining. Although supervised learning effectively make a wide variety of labeled samples build a classifier, labeling samples usually takes a long time and consume excessive money. On the contrary, semi-supervised learning (SSL) [1, 2] train a classifier using tiny labeled samples and a number of unlabeled samples, which has been successfully developed to many real applications, such as text classification [3], face recognition [4], medicine [5] and other fields. SSL algorithm includes self-training algorithm [6], deep generative models [7], co-training algorithm [8] and graph-based semi-supervised learning [9]. Self-training algorithm is widely used since it does not take account of initial assumptions of data set and is easy to be implemented.
In terms of the implementation of the algorithm, self-training algorithm contains three steps. (a) A small number of labeled samples are utilized to train an initial classifier. (b) The unlabeled samples with the highest confidence are selected and are predicted by the classifier. (c) The noise filter is used to detect mislabeled samples, and then remaining relabeled samples are added to the training set. The three steps are repeated until the stop condition is reached. Researchers generally concur that mislabeled samples in the self-training algorithm slash the accuracy of the trained classifier in practice. Hence, a diverse range of modified noise filters have been designed to reduce the impact of erroneously labeled samples on training. The main ideas of them are summarized as follows: The local noise filter judges whether the relabeled samples are the mislabeled samples by finding the spatial structure of the relabeled samples and the local adjacent samples, or computes the probability that the relabeled samples are the mislabeled samples by conducting hypothesis test. Despite these local noise filters do increase the classification accuracy of the classifiers, they have a number of technical defects:
Current local noise filters only focus on the spatial distribution of the nearest neighbors within one class. Considering the different distribution of samples in different classes, local noise filters need different Local noise filters based on The majority rule has been adopted as the decision rule of current local noise filters, which is less effective. The majority rule does not work when mislabeled samples are located in overlapping areas of different classes. Thus, closer nearest neighbor contributes more to detection, and it acquires more voting weights [10].
Based on the above analysis, a novel globally adaptive multi-local noise filter using harmonic mean distance (GAMLNF) is proposed. GAMLNF is grounded in the local mean-based
In order to better detect the mislabeled samples in STDP, an integrated self-training algorithm based on density peaks combining globally adaptive multi-local noise filter (STDP-GAMLNF) is designed in this study. Firstly, STDP-GAMLNF adopts DPC to reveal the whole spatial structure of samples [11], according to which the unlabeled samples are relabeled. Next, through the novel noise filter, a mislabeled sample is comprehensively detected from multiple classes, and the influence of edge samples and mislabeled samples is decreased effectively. Finally, the mislabeled samples are deleted, which will corrupt the spatial structure revealed by DPC. Space structure restoration (SSR) technology with a doubly-linked list is used for storing spatial structure, and automatically connects the unlabeled “previous” samples with the nearest density peak one in the deleted samples. In this regard, SSR ensures that every unlabeled sample is precisely relabeled.
In short, the main works of this study are summarized as follows:
GAMLNF algorithm is proposed. It considers the global and local spatial structure simultaneously, and provides higher weight for the closer labeled samples by harmonic mean distance in the local detection voting process, which is not sensitive to the neighbor parameter The robust self-training algorithm STDP-GAMLNF, a valid solution for mislabeling in STDP, is verified. SSR is proposed in STDP-GAMLNF, which effectively prevents spatial structure from being corrupted by the deletion of mislabeled samples and ensures that each unlabeled sample is labeled. Compared with existing methods, the algorithm developed here remarkably increases the average accuracy and AUC value.
This paper is organized as follows. Section 2 presents related work. Section 3 describes preliminaries. Section 4 constructs STDP-GAMLNF. Section 5 evaluates the performance of STDP-GAMLNF through comparison experiments. Finally, the paper concludes Section 6, as well as future plans.
Self-training algorithm is a method of semi-supervised classification algorithm. The current studies of self-training algorithm highlights the need for selecting unlabeled samples with high confidence for labeling and detecting mislabeled samples.
Extensive research has explored the selection of unlabeled samples with high confidence for labeling. The innovative and seminal work of Adankon and Cherie [16] pioneered a new approach to self-training, that is, Help-training, where a support vector machine (SVM) is trained based on a naive bayes (NB). Nevertheless, this method still has a drawback in that the performance of Help-training entirely depends/is restricted to the number and distribution of labeled samples. Gan et al. [17] developed semi-supervised fuzzy C-means algorithm (SFCM) to find unlabeled samples which have a strong discriminant ability in the local data structure, and unlabeled samples are relabeled through fuzzy C-means algorithm. However, the algorithm does not take account of the global structure information of the data set nor does it obtain spatial structure on non-spherical distribution data. In view of this, Wu et al. [18] designed a self-training algorithm based on density peaks of data (STDP). The density peaks clustering (DPC) algorithm is adopted to discover the spatial structure of the data set, which accredits the self-training algorithm to relabel representative unlabeled samples.
Although STDP considers the global spatial structure of data sets, it still produce some mislabeled samples during the training process. If the mislabeled samples are added to the training data set, it will ultimately reduce the classification accuracy of the classifier [19]. Thus, numerous self-training algorithms based on the local noise filters have been proposed, such as self-training based on density peaks clustering and cut edge weight statistic (STDP_CEWS) [20], self-training method based on density peaks clustering with extended parameter-free local noise filter (STDPNF) [21] and multi-label self-training with editing (MLSTE) [22]. STDP_CEWS identifies mislabeled samples by cutting edges weight statistics. MLSTE adopts edited nearest neighbor (ENN) to filter out noisy samples while STDPNF uses natural neighbors to remove noisy samples.
Despite the current noise filters increase the accuracy of the algorithm, existing local noise filters only take account of the spatial distribution of the nearest neighbors within one class. At the same time, it is particularly vulnerable to the influence of noise point samples, so a novel globally adaptive multi-local noise filter using harmonic mean distance is proposed to solve the above problems. While using DPC to find the space structure of data, SSR technology is also introduced to prevent spatial structure from being destroyed by deleting incorrectly marked samples, so that each unlabeled sample has the opportunity to be labeled.
Preliminaries
In this section, notations used in this paper are first shown. In order to create a better noise filter to detect the mislabeled samples in STDP algorithm, we draw lessons from LMKNN. Meanwhile, the harmonic average distance is proved to be capable of giving more weight to the closer samples, improving the performance of LMKNN. Then, STDP, LMKNN and the harmonic mean distance are described concisely.
Notations
In this study, the notations are described in Table 1.
The notations used in this paper
The notations used in this paper
STDP algorithm adopts DPC to reveal the whole spatial structure of the samples [18]. DPC is a density-based clustering algorithm that discovers the global spatial structure of data and automatically find the number of clusters. DPC is based on the two assumptions:
The highest density sample in a cluster is the center sample of the cluster. There is a large distance between centroid samples.
Based on two assumptions, DPC first calculates the local density
STDP uses the global spatial structure revealed by DPC to select representative unlabeled samples for relabeling. The relabeling process is divided into two steps. Step 1 is iteratively to select and relabel all the unlabeled “next” samples of the labeled samples. Step 2 is iteratively to select and relabel all the unlabeled “previous” samples of the labeled samples. Figure 1 shows a general framework for STPD.
The framework of STDP.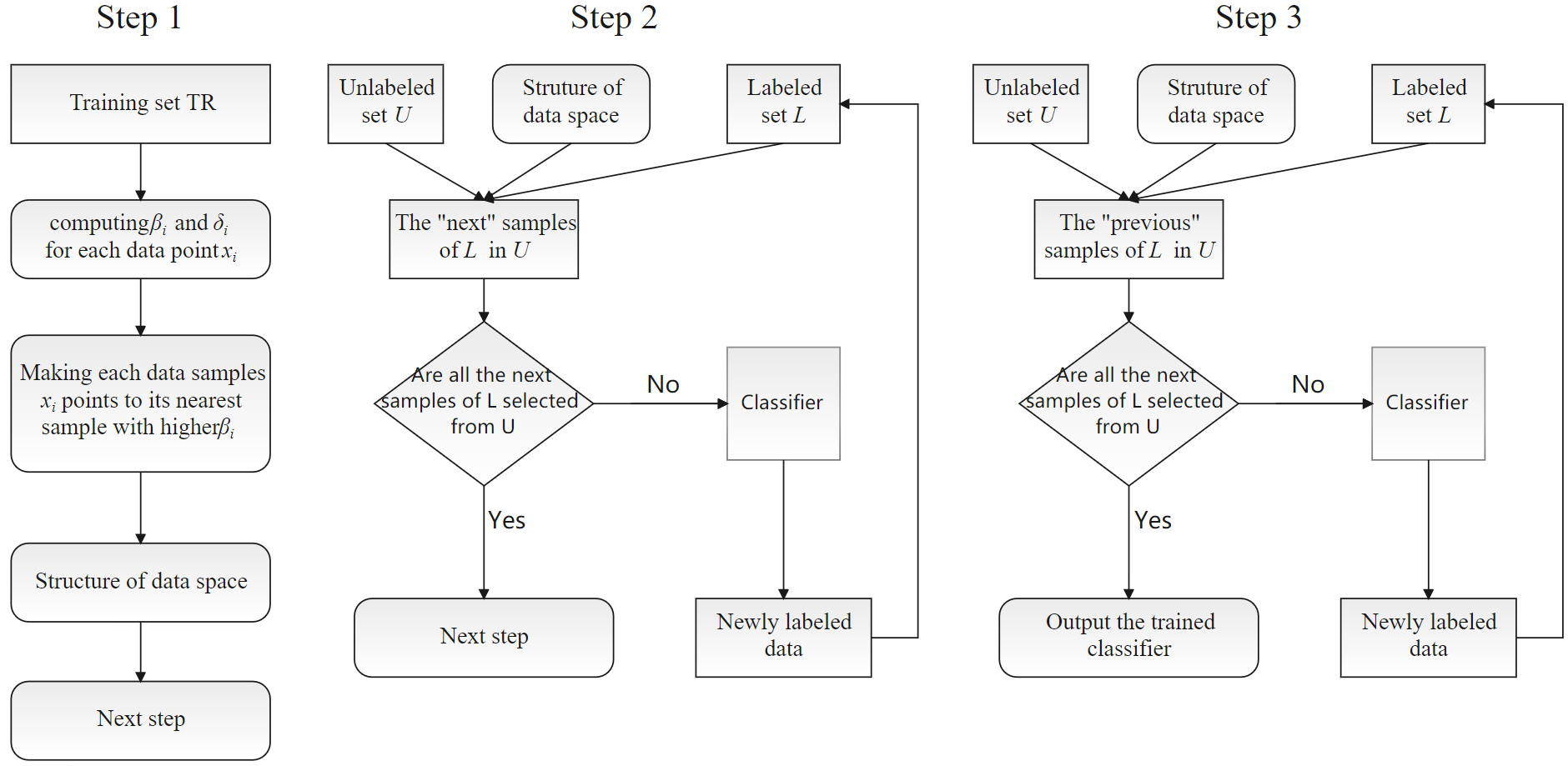
LMKNN algorithm is a very effective and simple classification algorithm in supervised learning [11]. It adopts a local mean vector and distance decision rule and considers the spatial distribution of the nearest neighbors of each class. The algorithm is immune to edge samples and significantly improves the accuracy of classification.
Suppose that
Firstly,
After that, the local mean vector
Finally, the local mean vector closest to unlabeled sample
where Euclidean distance is used to find the local mean vector nearest to
The harmonic mean distance is defined as HMD(
In order to explain the difference between harmonic average distance and arithmetic mean distance, the proof is given.
The arithmetic mean distance is used to measure the distance between an unlabeled sample
Similarly, Eq. (8) demonstrates that
Figure 2 shows the framework of STDP-GAMLNF, which is mainly divided into three steps. The first step in this process is to discover the spatial structure of the data set via DPC. The second step is to relabel the unlabeled “next” samples of labeled samples according to the spatial structure, and use GAMLNF to detect mislabeled samples. If it is detected as a mislabeled sample, SSR is adopted to repair the spatial structure to ensure that each unlabeled sample is relabeled. Otherwise, the unlabeled sample is added to
The framework of STDP-GAMLNF.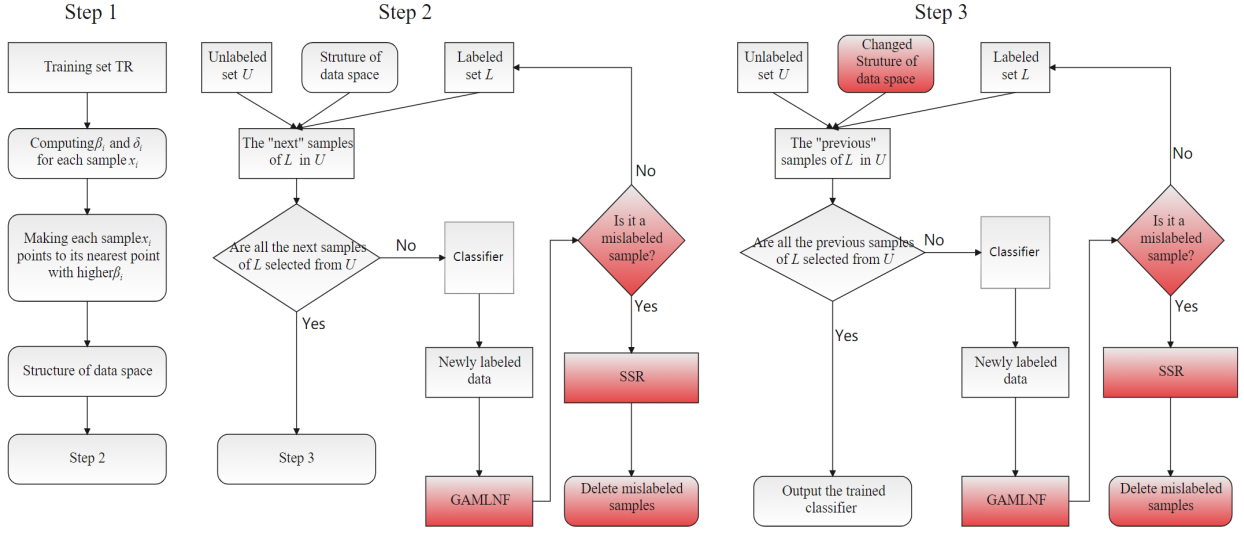
In the semi-supervised learning environment, GAMLNF adaptively find the appropriate
Inspired by the modified algorithm GAKNN of LMKNN summarized in 2.3, we use GANN to find the neighbors of the labeled sample around relabeled samples. Specifically, the labeled sample set
When GANN adaptively finds
A closer local average vector contributes more to detection, so it requires more voting weights. Thus, HMD(
The computational complexity of GAMLNF mainly occurs in the search of the global nearest neighbor (Stage 1), the pseudo average vector calculation (Stage 2), and the Euclidean distance calculation (Stage 3). In Stage 1, GAMLNF obtains
In Stage 2, GAMLNF needs to calculate
In Stage 3, GAMLNF obtains the closest pseudo-average vector to
GMLNF is used to detect and delete the mislabeled samples. However, it tends to corrupt the spatial structure revealed by DPC. As can be seen in Fig. 3, the circles and triangles represent real class
Space structure restoration step diagram.
Accordingly, SSR algorithm is proposed. As shown in Fig. 3c, the doubly-linked list structure functions as the storage of the spatial structure. When
The whole algorithm is shown as Algorithm 5. At Step 1–Step 4, the DPC algorithm is used to reveal the spatial structure of the data set. The spatial structure is stored in the doubly-linked list. At the same time,
STDP-GAMLNF focuses on both the global spatial structure revealed by DPC and the spatial structure in each class by GANN algorithm. Simultaneously, GAMLNF adaptively finds
Experiments
Data sets and setting of experiments
We use a PC with 32 G memory, Core i5 CPU and 64-bit operating system to run some experiments, in order to verify the efficiency of the proposed algorithm. Furthermore, MATLAB2016b and PyCharm2021 are utilized to program.
To prove the effectiveness of STPD-GAMLNF, 18 benchmark data sets of experiments are selected from UCI [23] repositories. The data sets are depicted in Table 2. The selection of data sets is in light of different size, Attributes and Class. In order to display the applicability of the algorithm to different distributed data sets, the data sets with flow pattern distribution and spherical distribution are selected. The missing values are supplemented by the mean value. The available evidence supports the conclusion that our algorithm is immune to noise samples.
The descriptions of UCI data sets
The descriptions of UCI data sets
The training set is randomly divided into the labeled sample set
Experiment 1 is a comparative experiment between STDP-GAMLNF and other representative algorithms. Mean accuracy, variance, ROC, AUC work as evaluation indexes, and the ratio of Experiment 2 compares the effect of the noise filter with the representative noise filter in STDP. Kappa coefficient is used as an evaluation index, and the ratio of Experiment 3 studies the influence of the Experiment 4 studies the impact of the proportion of labeled samples on the noise filter. The evaluation indexes are accuracy and variance, and the ratio of
This experiment compares our algorithm with some representative algorithms to demonstrate the effectiveness of STDP-GAMLNF. To prove the ability of our noise filter to detect mislabeled samples, the following parameters are used: Mean accuracy, variance, ROC, AUC. The ROC curve for multi-classification is calculated as:
Suppose the number of test samples is
Under each class, the probability of
Comparison algorithms and parameters in experiment 1
Comparison algorithms and parameters in experiment 1
Comparison algorithms and our algorithm are shown in Table 3. And dc parameter of the proposed algorithm will be discussed in detail in STDP [18], so the dc of the algorithms is set as recommended in STDP. The introduction of the comparison algorithms are as follows:
Self-training hierarchal prototype-based [24] for semi-supervised classification by extending the recently introduced HP classifier with a self-training mechanism based on the widely used pseudo-label technique. After being primed with labeled samples, the STHP classifier continues to self-evolve its multi-granular structure from unlabeled samples via pseudo-labeling without human supervision. Multi-label self-training with editing (MLSTE) [19] uses ENN to detect noisy samples by self-training algorithm. Although MLSTE is applied to multi-label tasks, it is applied to single-label tasks as well. Self-training with FCM (ST_FCM) [17] is a clustering algorithm, which is used to guide self-training method to train an effective classifier. Self-training with DPC (STDP) [25] integrates the structure of feature space revealed by DPC into the self-training process to train an effective classifier. STDP integrated by parameter-free local noise filter (STDPNF) [6] is parameter-free and removes mislabeled samples by exploiting the information of both labeled data and unlabeled data.
From Table 4, it is clear that the accuracy of STDP-GAMNF is better than that of the comparison algorithms. Compared with STDPNF, it accurately detects mislabeled samples and takes account of the spatial structure within each class. 12 out of 18 data sets’ average accuracy of STDP-GAMNF is better than that of the comparison algorithms, and good stability is demonstrated from the variance. However, in AVI and MM data sets, the average accuracy of STDP-GAMLNF is lower than that of STDP. The distribution of the two data sets is totally even, and the correctly labeled samples are deleted during the noise filter detection, causing massive samples reductions in
Experimental results (MCA
Experimental results (AUC) of comparison algorithms
Comparison algorithms and parameters in experiment 2
Experimental results of kappa with KNN as base classifier
ROC of biodegradation data set.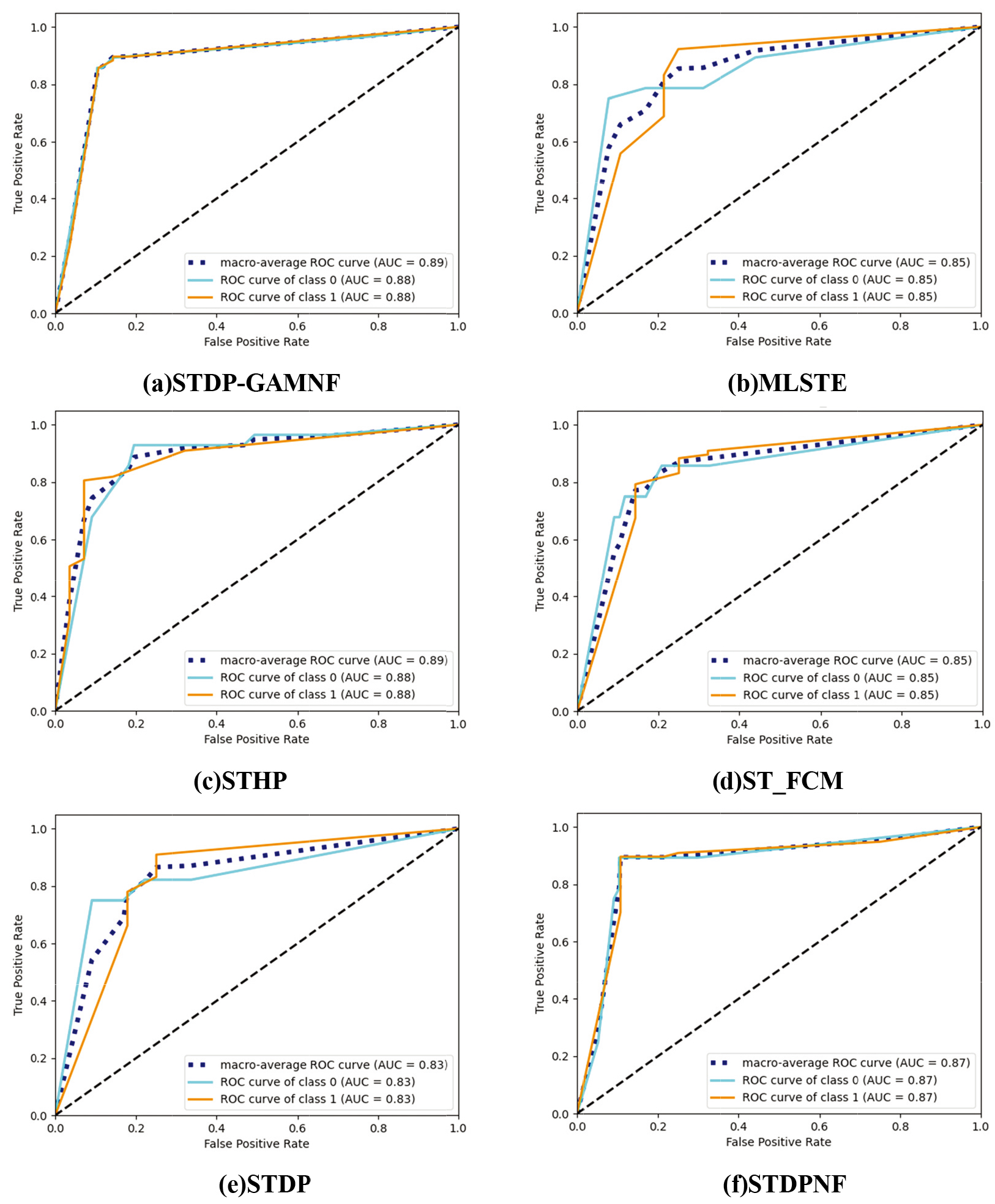
ROC of Contraceptive_Method_Choice data set.
In order to prove the effectiveness of GAMNF, we selects 6 representative noise filters ENN [26], RNN [27], ALLKNN [21], MENN [28], CEWS [20], PNF [21] for comparison. To compare their abilities of solving the problem of mislabeling, STDP algorithm is chosen to combine the 6 noise filters (STDP_ENN, STDP_RNN, STDP_ALLKNN, STDP_MENN, STDP_CEWS, STDP_PNF). Table 6 shows the comparison algorithms and related parameters.
Experiment 2 uses the kappa coefficient to judge the quality of the noise filter, which not only checks the consistency and measures the classification accuracy, but also judges the ability of unbalanced classification [29]. The calculation method of kappa coefficient is shown in Eq. (10) where
Tables 7 and 8 shows the experimental results of GAMNF in STDP and other comparison algorithms. The base classifiers in Tables 7 and 8 are respectively KNN and CART.
From Tables 7 and 8, when the base classifier is KNN, 11 out of 16 data sets’ kappa coefficient of our algorithm are better than those of the comparison algorithms. When the base classifier is CART, 7 out of 16 data sets’ kappa coefficient of our algorithm are better than those of the comparison algorithm. In summary, the overall accuracy of STDP_GAMLNF is higher than that of the comparison algorithms, and the effectiveness is better when the base classifier is KNN. However, the two base classifiers on the MM and TTTE data sets fail to perform well. In particular, all the noise filters on the TTTE data set lead to the accuracy reduction, because the spatial structure revealed by DPC has already been sufficient to support the training of the self-training algorithm, but the noise filter interferes the relabeled samples, resulting in the deletion of too many unlabeled samples, which will corrupt the complete spatial structure. While STDP_GAMLNF effectively detects mislabeled samples by multi-local mean vectors, and uses harmonic average distance to focus on local mean vectors close to the relabeled samples in each class, it secures better detection ability. GAMLNF adopts the idea of multi-local. By synthesizing multiple average vectors in different categories, the errors caused by edge samples are reduced by averaging, which decreases the influence of the algorithm for edge samples.
Experimental results of kappa with CART as base classifier
Variance results of different 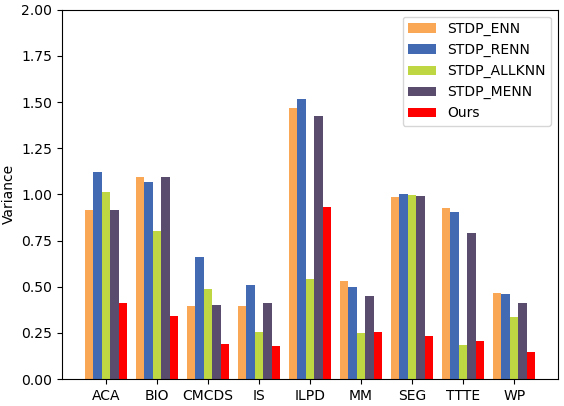
ACC of different algorithms with respect to different percentages of L on 6 data sets.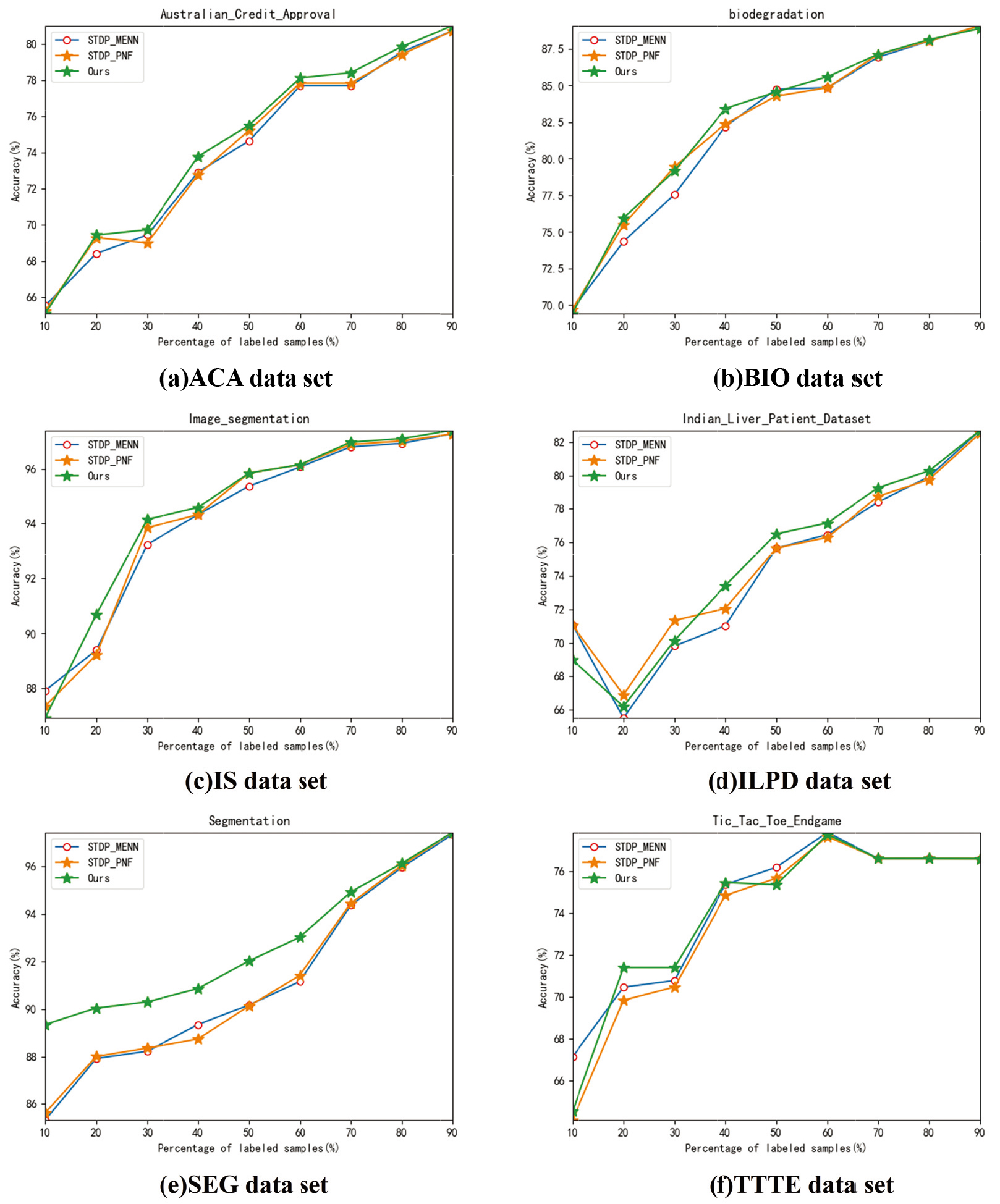
In GAMLNF
The experimental results are shown in Fig. 6. It is clear that the variance of GAMLNF is much lower than other noise filters, and it can achieve an adaptive global search for the appropriate
Experiment 4: The impact of ratio of labeled samples
The experimental parameters are consistent with Table 6. Simultaneously, STDP_MENN, STDP_PNF and STDP_GAMLNF perform better than other algorithms in Experiment 2, so they are used as compared algorithms. Figure 7 shows that the ratio of
As shown in Fig. 7, GAMLNF performs better than the comparison algorithms on ACA, BIO, IS, ILPD, SEG, and TTTE data sets. GAMLNF calculates the most suitable local average vector for each class globally, which improves the classification accuracy through multiple average centers. But on IS, ILPD, and TTTE data sets, when the ratio of
Conclusions and future study
In this paper, we firstly explain in detail how we use GAMLNF to detect mislabeled samples. Secondly, we introduce how to repair the spatial structure damaged by the noise filter. In the end, we propose our STDP-GAMLNF algorithm framework. Specifically, the spatial structure of the data sets is revealed by DPC, and then the spatial structure is used to empower self-training to label unlabeled samples. Meanwhile, GAMLNF is used to detect whether the relabeled sample is mislabeled sample or not, after each epoch of labeling. SSR technology reconstructs the corrupted space structure. Together, all the experiments confirmed that (a) Compared with mainstream methods, the proposed algorithm effectively improves the average accuracy and AUC value. (b) GAMLNF’s ability to detect mislabeled samples is better than other comparison algorithms. (c) The presented algorithm is not sensitive to the neighbor parameter
Future research should focus on how to modify the noise filter to promote the detection of mislabeled samples when there are tiny labeled samples. Our study finds that the increasing number of labeled samples significantly improve the accuracy of the algorithm. Thereby, we will also explore how to relabel the erroneously labeled samples through the updated spatial structure so as to prevent labeled samples from being simply deleted.
Compliance with ethical standards
Ethical approval: This article does not contain any studies with human participants or animals performed by any of the authors.
Funding details: This work is supported by the scientific and technological innovation project of double-city economic circle construction in Chengdu-Chongqing area (No. KJCX2020024), Chongqing University Innovation Research Group funding (No.CXQT20015).
Conflict of interest: The authors declare that they have no conflicts of interest.
Informed consent: Informed consent was obtained from all individual participants included in the study.
Authorship contributions
Shuaijun Li: Conceptualization, Methodology, Validation, Formal analysis, Data Curation, Writing-Original Draft. Jia Lu: Supervision, Writing-Review & Editing.