
Abstract
Shadow detection is a significant preprocessing work that soil type is classified with machine vision. Thus, Density peak clustering based on histogram fitting(DPCHF) is proposed to segment soil image shadows. First, its clustering centers are adaptively obtained by constructing a new parameterless density formula and decision value measure. Then the Fourier series are drawn into it to approximate the gray histogram and a part of gray-levels are allocated by valley points of the histogram fitting curve. Finally, an optimization model is established to optimize the threshold of detecting the shadow in the soil image, and the remaining gray-levels are clustered by the threshold. The simulation results show that DPCHF is better than the contrast algorithm. The average brightness standard deviations of the shadow and non-shadow are respectively 20.9348 and 20.3081 with DPCHF. It can realize the adaptive shadow detection of soil images and there is not the “domino” error propagation in it.
Introduction
Due to the influence of uneven soil surface, cavity and photography angle, there are shadows in the soil images that are collected by machine vision. For identifying soil species, usually the soil images are cut for some sub-images that their size is standard and a sub-image is full soil. If there are many dark shadows in some of soil sub-images, the learning machine that is trained by the soil sub-images maybe mistakenly identify soil species of soil image. The principal reason is that shadows hide the inherent characteristics of the soil and mislead the learning machine. And it will reduce the accuracy of soil species identification with machine vision. In order to highlight the soil characteristics of the sub-image, it is avoided that more shadow areas are cut into soil sub-image for identification of soil species by machine vision. Thus, Shadow detection is a necessary preprocessing work for eliminating its influence.
The shadow detection of soil images is a segmentation work. Density peaks clustering (DPC) [1] is an efficient clustering algorithm, which is widely used in image segmentation. Predecessors have made many effective improvements on DPC algorithm [2–10] and it include two aspects. One is to solve the problem that DPC is strongly dependent on density kernel and empirical parameter cutoff distance d c [11–15]. For example, Zhen [11] introduced information entropy to improve the cutoff distance d c , and Wang [12] used Gini impurity to find the best cut-off distance d c , Hou [13] raised a new density kernel and normalized the density to reduce the dependence of DPC on the cutoff distance d c , and Jiang [14] proposed a method to calculate d c based on the Gini coefficient, and Chun [15] put forward an improved density peaks clustering algorithm based on the layered k-nearest neighbors and subcluster merging. The other is to solve the problem that DPC needs to select the cluster center manually, and a series of algorithms to obtain the cluster center automatically are proposed [16–20]. For example, Liang [16] came up with an improved 3DC algorithm to obtain clustering center adaptively, and Liu [17] proposed adaptive clustering algorithm which introduced the idea of K-nearest neighbors (named as ADPC-KNN), and Zeng [18] constructed center decision metric CDM i to obtain automatically cluster centers.
However, the above studies can not solved the problem of “domino” error propagation. That is a point allocation error leads to joint errors of other points and it is caused by the DPC algorithm because there is the same allocation strategy for all data in the DPC algorithm. Therefore, the DPC algorithm needs further research and improvement for the shadow detection of soil images.
The rest of this paper is organized as follows. Section 2 reviews the original DPC algorithm. The density peak clustering based on histogram fitting is introduced in Section 3. Experimental results are shown in section 4 and Section 5 is the conclusion of this paper.
Density peaks clustering(DPC)
The density peak clustering algorithm defines local density ρ i and relative distance δ i for each data point x i in the dataset. The local density ρ i is
Where d ij expresses the Euclidean distance from x i to x j , d c denotes the cutoff distance. If d ij - d c < 0, then χ (d ij - d c ) = 1, otherwise χ (d ij - d c ) = 0.
The relative distance δ i is
The original DPC algorithm manually selects the points with relatively large ρ and δ values as the clustering center. Then arrange the density of each remaining point in descending order to assign each point to the nearest neighbor whose density is larger than itself until all of the remaining points belong to their cluster centers.
There are three steps in the density peak clustering algorithm based on histogram fitting(DPCHF). It includes constructing a new nonparametric density formula for an adaptive decision value measure. Then introducing the Fourier series to approximate automatically the gray histogram and allocate a part of the gray-level by valley points of the histogram fitting curve. Finally, establishing an optimization model to search for the shadow detection threshold of the soil image and assign the remaining gray-level to complete the shadow segmentation of soil images. The flowchart of the DPCHF algorithm is shown in Fig. 1.
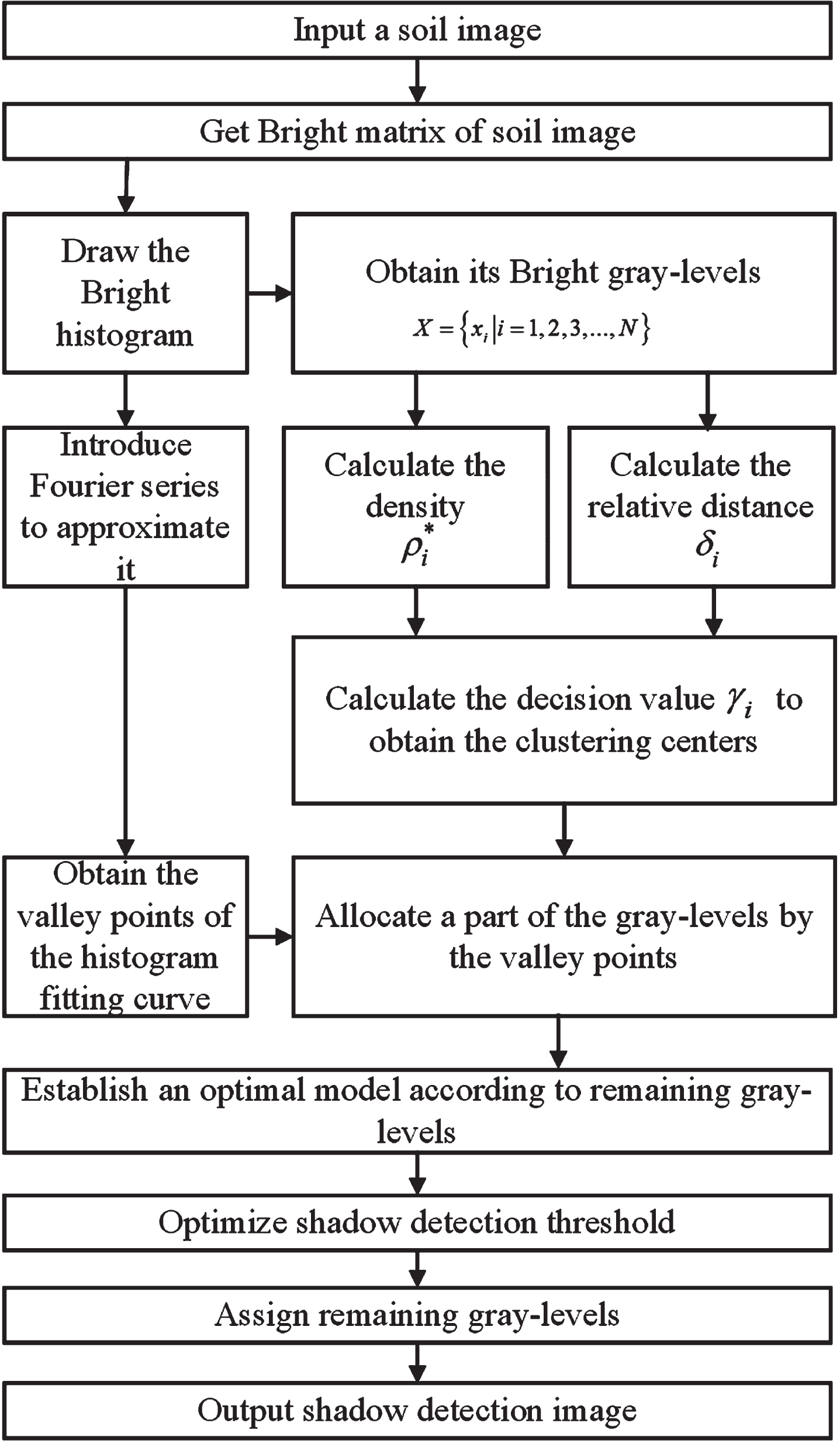
Flowchart of DPCHF algorithm.
Reconstructing density measure
The one-dimensional histogram of the Bright matrix of soil image is counted, and the gray-level (in ascending order) within [min(Bright) , max(Bright)] range from data set X = { x i |i = 1, 2, 3, . . . , N }
where R (i, j), G (i, j) and B (i, j) represent the pixel gray values of the i-th row and j-th column of the three RGB channels of the image respectively.
The density
Where d ij denotes the Euclidean distance from point x i to point x j , freq j is the number of gray values equal to x j in the Bright matrix, expressed as the frequency of x j points.
The clustering centers of DPC have the characteristics of high local density ρ
i
and large relative distance δ
i
. And it defined a decision value γ
i
to describe the local density ρ
i
and relative distance δ
i
. That is, the greater ρ
i
and δ
i
, the greater the value of γ
i
. Inspired by its idea, the decision value γ
i
is reconstructed with the density
As shown in Fig. 2, the decision value γ i should be redefined as
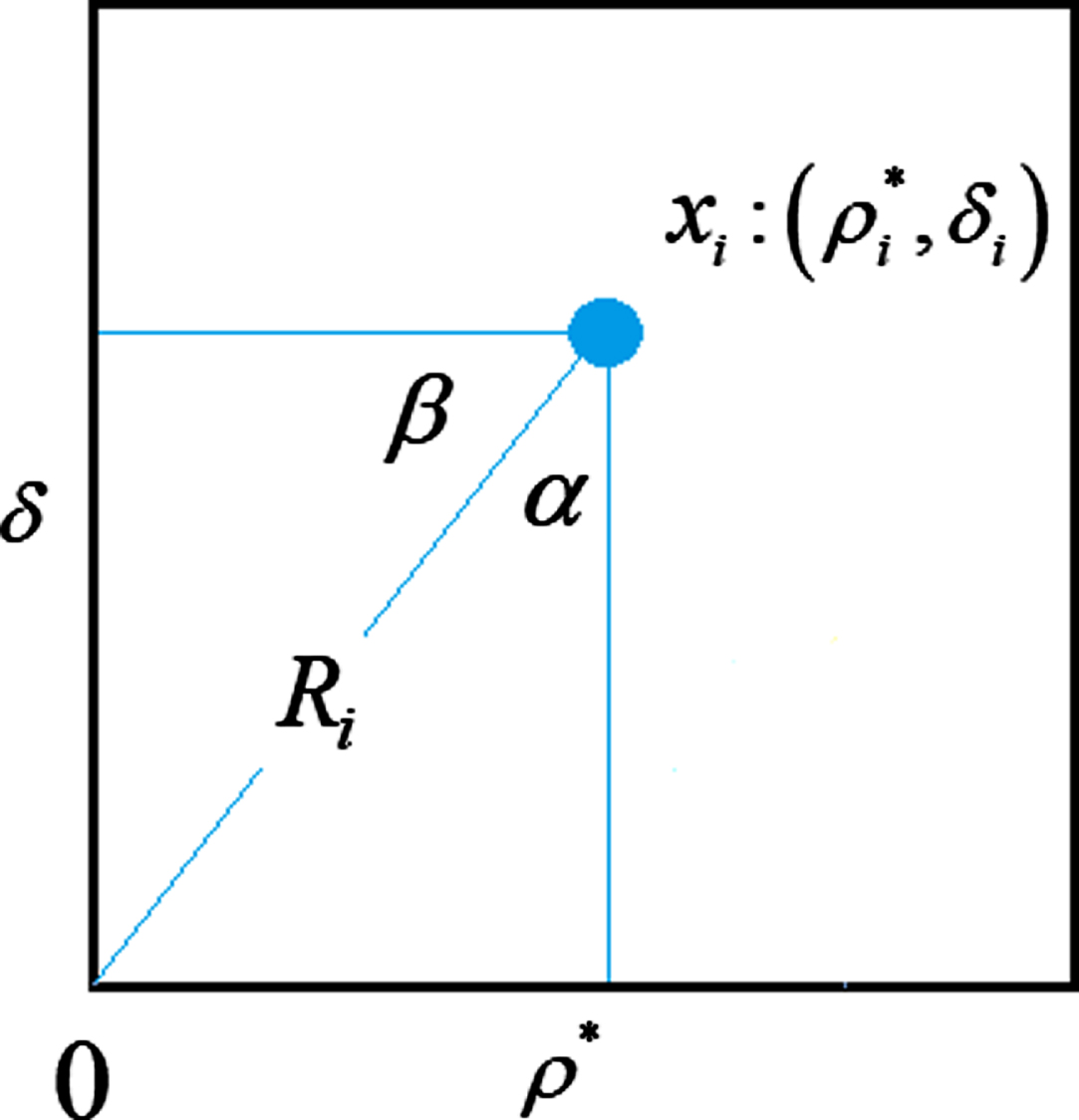
γ i is sorted in descending order. And the two x i points with the two largest γ i are chosen as the cluster centers of shadow and non-shadow because shadow detection is a typical binary classification problem. The smaller x i in the two cluster centers is the peak point of the shadow region, which is expressed as P left . The other matches the peak point of the non-shadow area, marked as P right .
Based on the above algorithm ideas, an algorithm of Obtaining adaptively the clustering centers is as Algorithm 1.
A soil image.
Shadow region peak P left and non shadow region peak P right .
1: The Bright of each pixel of the soil image is calculated with Eqs. (3) to form the Bright matrix A.
2: Count up a one-dimensional histogram of the Bright matrix A.
3: The Bright gray-level that frequencies are not equal to 0 are selected in the Bright histogram and are sorted in descending order to form gray-level
5: Calculate the δ i with Eqs. (2).
6: The decision value γ i is calculated with Eqs. (5).
7: Arrange γ i in descending order, and the two x i points with the two largest γ i are selected. Set P left equal to x i with smaller value and P right equal to the other.
Clustering based on histogram fitting curve
The original DPC algorithm assigned data point x i to its nearest neighbor whose distance δ i from x i to the nearest neighbor is minimum, and the local density of the nearest neighbor is higher than the local density of data point x i . It may cause the misclassification of data points to affect the segmentation effect. In order to avert the guise valley and find out the real valleys, the gray histogram fitting curve is constructed to allocate part of the data for solving the misclassification problems. An optimization model is established for the remaining gray-level in [x g , x q ] to optimize the threshold of detecting shadow in soil images.
Fitting gray histogram with Fourier series [21]
Fourier series can fit the histogram’s discrete two-dimensional point set
The x
i
is mapped to the range [0, 2π], let
where f i = f (x i ) = freq i .
The expression of fitting error about S n (x) is
The RMSE is smaller means the approximation of S n (x) to histogram is better. The histogram fitting curve is shown in Fig. 3.

Fourier series fitting curves of different histogram shapes.
The first derivative of histogram approximation curve S n (x) is , i = 1, 2, . . . , N. In the interval [P left , P right ] of data set X, the data points x j are found out, when or. The data points searched are valleys, and their count is stored in num.
(1) If num = 0, as shown in Fig. 2(a), the whole field of soil image is shadow or non-shadow. Here, its shadow detection and segmentation have been completed, and the subsequent work of the algorithm does not need to continue.
(2) As shown in Fig. 2(b), if num = 1, let g = i - r, q = i + r, where i is the index of valley and r = int (2 % · N).
(3) As shown in Fig. 2(c), if num ≥ 2, let g = min(i), q = max(i), where i is the index of valley.
Dividing the [x1, x N ] _ th gray-level into [x1, x g ], [x g , x q ] and [x q , x N ]. The gray-level are classified into shadow domain in [x1, x g ], and belong to non-shadow areas in [x q , x N ], and aren’t assigned in [x g , x q ].
Optimizing shadow detection threshold
Through steps 3.2.1 and 3.2.2, the shadow detection threshold is reduced to the range [x g , x q ] gray-level. In order to obtain the optimal shadow detection threshold in the [x g , x q ] gray-level, the shadow detection threshold search optimization model is established.
The threshold x T is searched out from [xg+1, xq-1] according to the step size of 1. The data points in [xg+1, x T ] are classified into [x1, x g ], and in [xT+1, xq-1] are attributed to [x q , x N ] by threshold x T . So far, all gray-level in the histogram are divided into shadow and non-shadow by threshold x T .
A clustering algorithm based on histogram fitting curve is obtained, and see algorithm 2 for details.
2: Shadow region peak P left and non-shadow region peak P right .
1: Obtain the S
n
(x) by fitting
2: Get the first derivative of S n (x).
3:
4: Get a data point x i from interval [P left , P right ] of data set X.
5:
6: Write i into the index set valley of valley points.
7:
8:
9: num = valley . lenth ().
10:
11: Algorithm is ended.
12:
13:
14: r = int (2 % · N).
15: Get i from valley.
16: g = i - r, q = i + r.
17:
18: g = min(valley), q = max(valley).
19:
20: Divide the [x1, x N ] gray-level into [x1, x g ], [x g , x q ] and [x q , x N ].
21: Assign the gray-level in [x1, x g ] into shadow domain, and in [x q , x N ] into non shadow areas. And the points aren’t assigned in [x g , x q ].
22: Solve optimization model Eqs. (10) to obtain the best segmenting threshold x T .
23: Segment all data points with threshold x T into shadow and non-shadow.
Experiment and analysis
Getting the experimental samples
According to classification and code for Chongqing soil [DB50 / T 796-2017] [22], there are four soil genera and 34 soil species of Purple Soil at Chongqing, China. A spade obtains the natural fault of soil (core soil) in 0-20cm tillage soil, and it keeps the original features of the soil. Then, the natural fracture of the soil (core soil) was photographed, and core soil accounted for more than 50% of the total image area.
Randomly, 60 soil color images with partial shadow in the soil region are selected from 1442 soil images. The core soil region images of 60 soil color images are segmented out to form the experimental samples with adaptive density peaks clustering [18] and the 60 core soil region images are randomly divided into 15 sample groups for experiment.
Experimental samples of full shadow or non-shadow are mainly composed of shadow or non-shadow sub-blocks cut out from the core soil images. It also includes some artificial composite sub-graphs replaced by non-shadow parts instead of shadow part pixels. The sample-set is named a robust sample set, and the size is 60 * 45 pixels. There are 20 images in the robust sample set, and the process of obtaining robust samples images is as shown in Fig. 4.

The process of obtaining full shadow and non shadow images.
This experiment is based on Intel (R) Xeon (R) silver 4114 CPU @ 2.20GHz (2 processor), 64GB memory, NVIDIA Titan V graphics card, windows 10 professional workstation 64 bit, and Matlab R2018a.
Experimental design
To verify the effectiveness of the algorithm, simulation experiments are designed as follows.
Experiment 1: Verifying the shadow detection accuracy of DPCHF. DPCHF and four comparison algorithms, such as Ref. [23] algorithm, DPC [1], EDPC [13] (local density is calculated by DPC Gaussian density kernel) and ACCDPC [18], are used to test shadow detection accuracy with the 15 sample groups.
Experiment 2: Comparing the time cost of DPCHF. The algorithms of Experiment 1 are also cited to test the shadow detection efficiency with the 15 sample groups.
Experiment 3: It is a robust experiment for the detection of full shadow or non-shadow images with DPCHF.
Experimental results and analysis
Image results of shadow detection
Experiment 1 is done with the 15 sample groups. The shadow detection image results of No.4 and No.13 sample groups, which are randomly selected, are shown in Figs. 5 and 6.

Image results of Experiment 1 with No.4 sample group.

Image results of Experiment 1 with No.13 sample group.
The accuracy results of shadow detection of Experiment 1, which are described by brightness standard deviation, are written into Table 1.
Segmenting accuracy of experiment 1
Segmenting accuracy of experiment 1
Experiment 2 is that DPCHF executed 10 times. Their average and standard deviation of time cost exhibited in Table 2.
Time cost of Experiment 2
Figures 5 and 6 declare that DPCHF algorithm has better segmentation effect than Ref. [23], DPC, EDPC and ACCDPC algorithm.
Table 1 exhibits that the mean of brightness standard deviation of shadow and non-shadow segmented by DPCHF are 20.9348 and 20.3081, and the mean values of brightness standard deviations of shadow and non-shadow segmented by the comparison algorithm (Ref. [23], DPC, EDPC and ACCDPC algorithm) are 19.9548 and 28.9746, 6.5932 and 40.5124, 42.9106 and 10.6489, 21.5532 and 21.4025 respectively. It is seen in Table 1 that the sum of the standard deviation mean of shadow and non-shadow segmented by DPCHF is far less than the result segmented by Ref. [23], DPC, EDPC and DPCHF. It bears out that the accuracy of the DPCHF algorithm is higher.
At the same time, it appears in Table 1 that the standard deviation of shadow cut out by DPC is very small and the standard deviation of non-shadow is very large. It illustrates that partial shadows are carried into non-shadow. Similarly, Ref. [23] is the same as DPC, EDPC is opposite to Ref. [23] and DPC, and partial non-shadows are cut into shadow by it. It has fully emerged in Table 1 that shadows and non-shadow may be misclassified by ACCDPC because the standard deviations of shadow and non-shadow are not nearly equal.
Analysing the time cost and algorithm efficiency
Table 2 appears that the average time cost of 15 groups experimental samples based on DPCHF is 0.4992±0.0806, and the average time cost of 15 groups experimental samples based on comparison algorithm(Ref. [23], DPC, EDPC and ACCDPC algorithm) are 0.1470±0.0287, 0.2478±0.0393, 0.2619±\\ 0.0653, 0.3600±0.068 respectively.
The data of time cost demonstrate that the DPCHF algorithm has the largest average time cost. After research and analysis, it is found that the algorithm in Ref. [23] is a self-defined Otsu algorithm with a single measure, which takes less time. However, this method is mainly effective for regular shadow detection of buildings shadow, and its adaptability of soil shadow detection is very poor, which can not meet the accuracy requirements of soil images shadow detection. DPCHF algorithm in this paper is more time-consuming than DPC, EDPC and ACCDPC, because these three algorithms all use the allocation rule from the original DPC algorithm. DPCHF algorithm uses Fourier series to search for valley points and establish an optimization model to obtain shadow and non-shadow optimal segmenting threshold points. These two steps increase the time cost of the algorithm, but it improves the accuracy of shadow detection in soil image and solves the problem of “domino” error propagation caused by the original DPC algorithm.
The above analyses present that DPCHF algorithm increases the second level time cost solves the “domino” error propagation problem. Hence, it’s worth improving the accuracy of soil image shadow detection.
The detection of full shadow or non-shadow image
The DPCHF algorithm detects full shadow or non-shadow images with the robust samples, and finds the unimodal characteristics of all samples. The unimodal characteristics of the robust sample are Fig. 7.
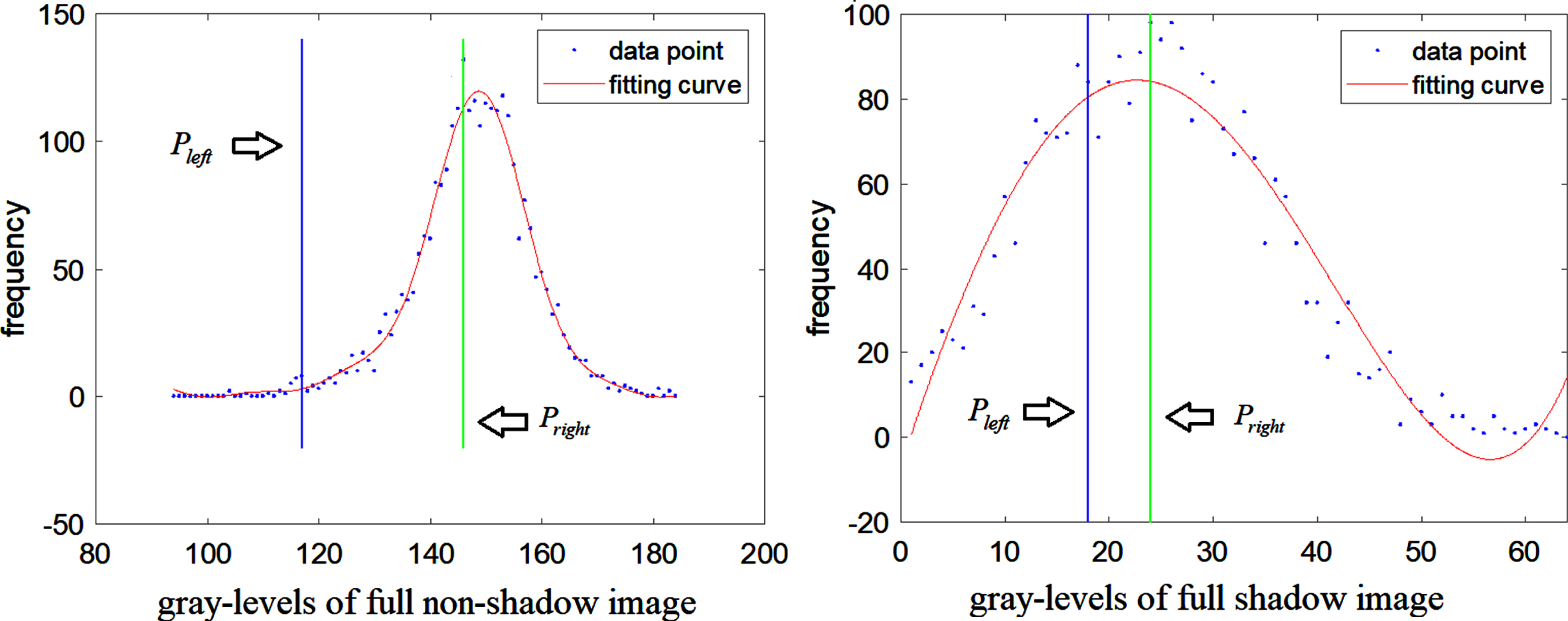
The unimodal characteristics that is detected by DPCHF in Experiment 3.
Shadow detection of soil image is a typical binary classifying problem, and its brightness histogram has bimodal characteristics. Thus, a curve of its brightness histogram is fitted, and its two peak points obtain as the clustering centers, and a valley point between its two peak points is optimized as the segmenting threshold for shadow detection. The conclusion of this work is as follows.
(1) Reconstruct the nonparametric density formula and decision value measure for obtaining the clustering center adaptively.
(2) Fourier series are drawn into approximating the brightness histogram, and a part of brightness points are allocated by valley points of the histogram fitting curve.
(3) Establishing an optimizing model to optimize the shadow detection threshold, and the optimized threshold classifies the remaining data. So, the problem of “domino” error propagation caused by the allocating strategy of clustering data based on the original density peak clustering algorithm is effectively solved by the DPCHF algorithm because it is a threshold segmentation.
(4) Simulation results manifest that the DPCHF algorithm has higher detection accuracy for soil image shadow detection than the contrast algorithm and solves the problem of “domino” error propagation. Although it increases the cost of time, this is valuable for the shadow detection of soil images.
Although the effectiveness of the proposed algorithms is promising, some open issues remain to be solved in the future. The time cost of the shadow detection algorithm of soil images can be further improved.
Footnotes
Acknowledgments
This work supported by the Key Science and Technology Research Program (No. KJZD-K201900505) and Chongqing University Innovation Research Group funding (No. CXQT20015) of Chongqing Municipal Education Commission, China.