
Abstract
Internet public opinion is closely related to our life in social network. The wanton growth of some negative public opinions has an extremely serious impact on the social stability and national security. After the guidance of government manually, some negative public opinion is well controlled and people’s life gain more positive energy. How to use Internet technology to automatically and promptly guide public opinion events and reduce the harm to society is currently challenging research. Therefore, in this paper, we propose a positive public opinion guidance model based on dual learning for negative Internet public opinion, hereinafter denoted to as the dual-PPOG model. Firstly, we use the Fast Unfolding algorithm to divide social networks into the public opinion guidance communities. In these communities, we detect the positive opinion guider and negative opinion receiver by our defined PageRank (PR) variant. Secondly, inspired by dual learning, we construct the public opinion guidance model and evaluate whether the guidance is successful through the feedback signal. Through the repeated guidance of the positive opinion guider to the negative opinion receiver, the public opinion guidance is successful. This is the main process for the dual positive public opinion mechanism. Finally, we guide the remaining nodes based on the opinion dynamics. The experiment demonstrates beneficial effects of our proposed model of dual-PPOG. Experimental results on three real-world datasets intercepted from Twitter, E-mail and Facebook show that the model of dual-PPOG can capture useful information in the network topology. Compared with the methods of HK, AE, Random and AIA on the three datasets from small to large in scale, the percentage of positive opinion increased by 4%, 6.9%, and 2.7% respectively, which shows our approach achieve significant improvements and effectiveness compared to all baselines.
Introduction
Public opinion is a collection of people’s emotional reflections on social events and social phenomena in a certain stage and geographical range. With the development of internet technology and the popularity of the Internet, social media usage is one of the most popular online activities. The latest data by Statista indicate that the number of social media users worldwide is estimated to be about 3.6 billion in 2020, a number projects to increase to almost 4.41 billion in 2025 [1]. It means more than one-third of the world’s population is using social media channels, such as Microblogs, Twitter, Facebook, and so on, to share their thought and opinions. Therefore, compared with traditional public opinion, internet public opinion has become one of the most important ways for people to express their opinions and get to know each other. During the formation of online public opinion, netizens would change their own opinions due to mutual interaction. When large-scale netizens hold negative opinions, it would have a huge bad impact on economic development and social stability [2].
In 2020, the COVID-19 pandemic is an ongoing global pandemic, which has caused global social and economic disruption. In addition to physical illness, people have to endure the intrusion of rumors psychologically. During the period, new media plays an important role in information transfer, including many official media such as the Central People’s Daily using the accounts on platforms of Microblog and Douyin to release important news in real time. Compared with the previous serious traditional media, due to their "official" attributes, they are slightly rigid in terms of public opinion guidance [3]. In addition, after the outbreak of the epidemic, many opinion leaders such as celebrities, business celebrities and public accounts with many subscribers, etc., posted information to support medical workers and exhort the public to pay attention to personal protection after the outbreak of the pandemic. The good guiding role of public opinion also establishes the correct opinion orientation. And some fake news and false information seriously affects social stability and makes people turbulent. Some negative public opinion incidents are guided by the government and celebrities, which often reduces the negatives and reduces the harm to society. Even some negative public opinion becomes positive public opinion, so that public opinion is completely controlled. This kind of guidance is artificial. The negativity of some public opinion events is sometimes discovered not in time, missing the guidance time, and the public opinion loses the opportunity to control. Therefore, it is a challenging and valuable work to study the guidance of public opinion. Therefore, we propose the positive public opinion guidance model based on dual learning, abbreviated as dual-PPOG.
The network is a virtual world, which is characterized by randomness, virtuality, and concealment [4], thereby, it is difficult to obtain all information of internet public opinion in time or control information dissemination [5]. The research of online public opinion has made great progress, but the research on the guidance is still in infancy which has many problems to be studied. Modeling the opinion formation must deal with the nonlinear and uncertain aspects of the opinions and their updates [6, 7]. Hence, not only is it a challenging process to define an opinion control problem, but the obtained problems are generally highly complex and difficult to solve. In the macro paradigm models such as SIR, where the diffusion process is not analyzed at the individual level, the input may be the part of social network [8]. And the input also can be the exact identity of influential nodes [9, 10], connectivity or weight of edges [11, 12, 13]. What’s more, in recent research, the influence of opinion leaders is also considered as another potential control variable [14]. Otherwise, the purpose of the opinion dynamics research is to find equilibrium and its stability [15] or the rate of convergence [16]. Existing methods mainly rely on a single feature (such as PageRank, betweenness centrality) to measure the importance of nodes, but it is difficult for a single feature to achieve good results in different network structures. Machine learning, as a data-driven method for selecting features, has better adaptability in different datasets. However, these important factors are considered and we combine the dual learning which is the a state-of-art sub branch of machine learning in this paper. Thus, in this paper, we improve the convergence rate to the positive leader’s opinion via allocating the guidance weight we proposed by dual learning.
The contributions of the dual positive public opinion guidance (dual-PPOG) we proposed are as follows.
We get the worthy communities named public opinion guidance community by Fast Unfolding algorithm. And we propose the positive opinion guiders in communities and negative opinion receiver in the process of dual positive public opinion guidance which is detected by our defined PageRank (PR) variant. We combine dual learning with opinion evolution and improve the formulae, and train the parameters through machine learning in order to achieve the optimal network in the dual-PPOG. In the dual public opinion guidance mechanism, the guider sends positive information, the guidance weight, to guide the receiver, then receiver accepts and is directed to change the node’s state. After that, the environment of the social network would change state and feeds back to the guider. Next, the guider receives and judges whether the guidance result is the better one. This is the main process for the dual positive public opinion mechanism we proposed. For the remaining ordinary nodes, we propose the propagation model combining the Friedkin-Johnsen (FJ) and Hegselmann-Krause (HK) model. The negative public opinion receivers become positive nodes after being guided by the above-mentioned dualPPOG, so that the remaining ordinary nodes in the community are guided and changed through the propagation model, so that the entire community becomes a positive public opinion. The experimental results show that our model is very promising. Especially, to compare with baseline model, the dual-PPOG approach has improved about the effectiveness and validation of public opinion guidance respectively. Using dual learning to guide public opinion broadens the horizon for the research and development of public opinion.
The remaining parts are organized as follows in this paper. In Section 2, we introduce some related models such as dual learning and opinion dynamics. In Section 3, we present the definitions of our proposed model dual-PPOG. In Section 4, we detail the concrete model for dual positive public opinion guidance, including the algorithm implement. And finally, Section 5 is the experiment and result for the validity of our proposed model.
Nowadays, there is almost no research on public opinion guidance in social networks, and most of the researches control the public opinion rather than guide it. The public opinion control means the control for the public opinion dissemination after the outbreak of public opinion, which only controls the scope of public opinion. The public opinion guidance defined in our research is to guide the specific development of public opinion by taking the emotional polarity of public opinion into account, and mainly guides negative public opinion towards the positive direction. The researches on the public opinion control in social networks mainly focus on detecting special nodes, such as opinion leaders and structural holes, and network structures, and then reach the result of the guidance work simply. However, there are no specific methods to solve the public opinion guidance. Therefore, in this paper, we focus on the specific guidance process of public opinion guidance and leverages the dual learning combination research in machine learning. And, in order to make the result of the guidance better, we use the positive opinion guiders to guide public opinion with the higher appeal and influence to surrounding nodes, so that the guidance can be better to achieve the best effect. The related works in this paper mainly include dual learning and opinion dynamics.
Dual learning
Machine learning (ML) is the computer algorithms that can improve automatically effectiveness through experience and by the use of data. Mathematically, the basic algorithm mechanism of machine learning can be expressed.
Based on machine learning, Xia et al. [18] propose dual learning to solve the machine translation problem by using neural network algorithm. It is a dual-learning mechanism, including two translation task: a dual task with English-to-French translation and a primal task with French-to-English translation. In 2017, Xia et al. [19] propose an approach called dual supervised learning(DSL) applied to three applications: machine translation, image processing, and sentiment analysis. In the same year, they improve the training process of dual learning which can leverage both existing models from two dual tasks, without retraining to improve the inference performance of each individual task [20, 21]. Later in 2021, Zhao et al. [22] focus on theoretical research on dual learning and extend the dual learning to multi-step dual learning.
We take the translation between English and Chinese as an example. There are two independent translation models
Opinion dynamics is a fusion process of individual opinions, in which the interacting agents within the group continuously update and merge their opinions on the same issue according to the established fusion rules and reach a consensus, polarization, or fragmentation in the final stage [23]. In the opinion dynamics model, let
The equation can be also compactly written as:
where
The basic models in opinion dynamics include DeGroot model, the bounded confidence model and the voter model. In DeGroot model, the weight metric
The Eq. (4) is that a randomly selected pair of connected users meet each other at each time step. Then, in the case where their opinions are close, each user updates its own opinions through the opinions of the close partners. Otherwise, they will not change their opinions, and the process will continue. Here,
As for the HK model [26], it is similar to the DW model [25]. The differences are in their fusion regime. In HK model,
Based on the definitions in the aforementioned opinion dynamics model, the equation of opinion dynamics can be written bellow [28].
In the equation above,
where
Denote a social network
.
Public Opinion Guidance Community. The communities are with the guidance significance based on the influence and popularity of public opinion in the social network
.
Positive Opinion Guider and Negative Opinion Receiver. The Guider or the receiver are the most influential opinion leaders with the positive opinion or the negative opinion respectively in the each community. They are detected by the variant we defined of PageRank (PR) algorithm ranking the values of the influential nodes. The positive opinion guider is represent by
.
Dual Positive Public Opinion Guidance. In the social network
.
Ordinary Nodes. The ordinary nodes mean the remaining nodes which is not the
The figure of the specific relationship is as Fig. 1. The dual-PPOG model is available for the same community and different communities.
Definition’s relationship of dual-PPOG. The big red node is the 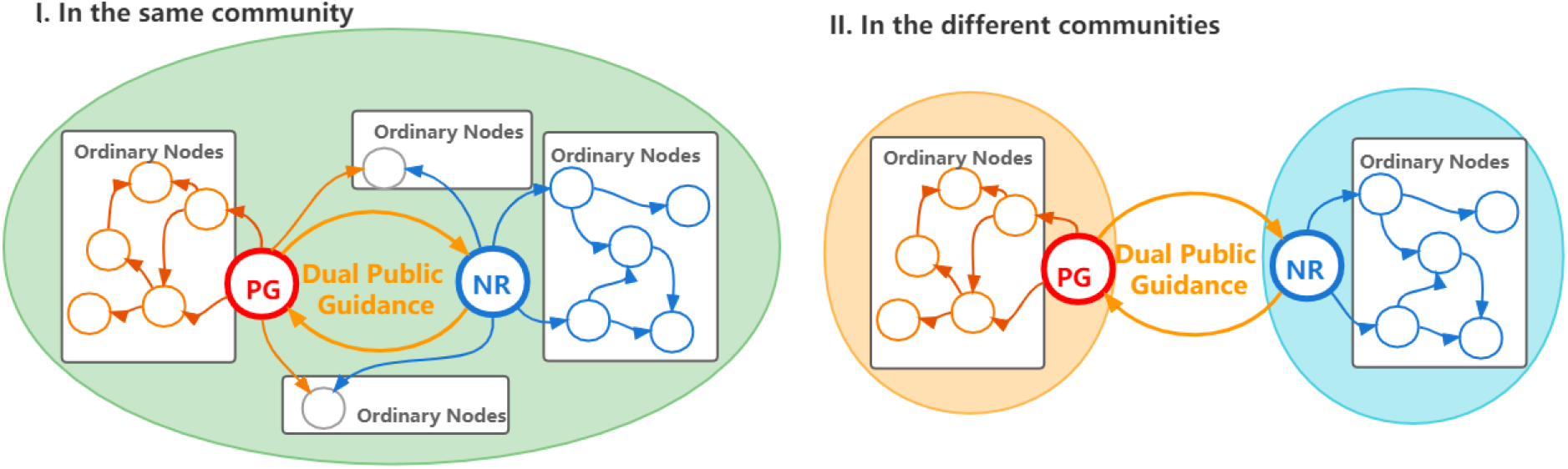
In this section, we mainly describe the methodology of the concrete process of dual-PPOG. Specifically, we elaborate on dual-PPOG in three parts. Firstly, we introduce the detection of positive opinion guider and negative opinion receiver in social network. Then, the dual positive public opinion guidance is explained with the specific mechanism in detail. And, we present the model of public opinion guidance with the algorithms. Finally, it is the opinion evolution of ordinary nodes in the social networks.
Detection of positive opinion guider and negative opinion receiver
In the social network
where,
In the equations above,
For the detection of the influencer, we implement it by the following algorithm.
: The Detection of Positive Guider and Negative Receiver[1] Social network
In Algorithm 4.1, we use the Fast Unfolding algorithm to divide the network
For the dual positive public opinion guidance, the dual positive guidance mechanism is introduced firstly. There are two tasks including primal task and the dual task in dual positive public opinion guidance. Recently, the public guidance has attracted great but it has no concrete model and definition, which only get the result: consensus, polarization or fragmentation in the final stage. Meanwhile, the result might lead in the circumstance of “echo-chambers”, which refers to relatively closed environments, where voices with similar opinions are repeated in the media. This is why we leverage dual learning to deal with the current situation. Therefore, we achieve the result of public opinion guidance by connecting the positive and negative influencers to guide the negative nodes via dual learning. This process is the dual positive public opinion guidance (abbreviated as dual-PPOG) mechanism. Specifically, the dual-PPOG mechanism is described as the following two-agent communication game and the specific diagram is as follows in Fig. 2.
The positive guider ( The negative opinion receiver, which is the negative influencer in the public opinion guidance, changes the opinion state of node after receiving the information. Then, the feedback signal of network’s new state sends the information to the After receiving the feedback information, the After the process, we get the feedback signal and judge wether the guidance is good or not to adjust the parameters of guidance weight allocation. Then by the networks’ status, the parameters are training and getting the feedback. If the
Dual positive public opinion guidance mechanism. There are two kinds of nodes. 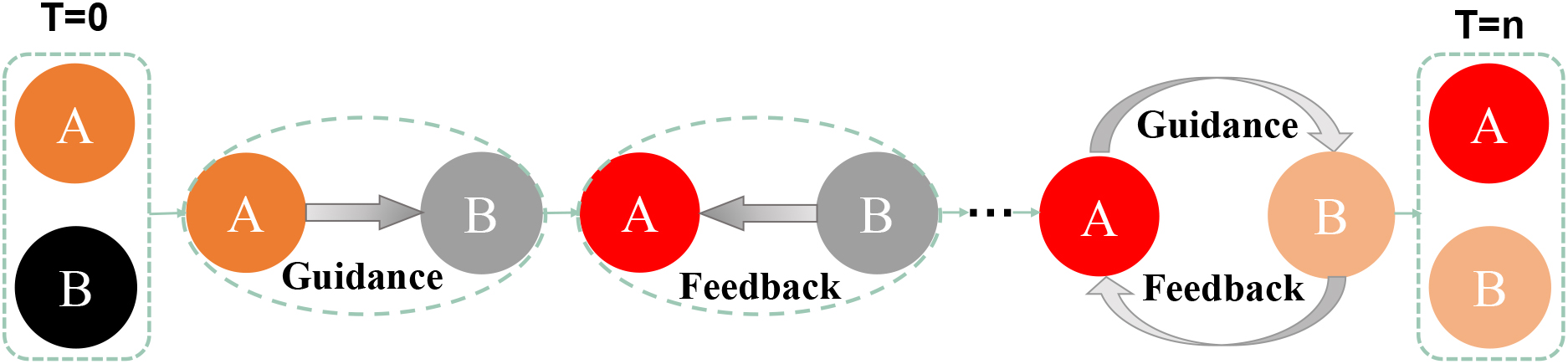
To explain Fig. 2, we take a public opinion event as an easy-to-understand example-a student in Chengdu 49 middle school falls from a building. The incident stems from the parents posted an article on microblog saying that their son fell from the school and died, but that the school did not notify the parents in time, and even get the cremation directly without going to the hospital. This statement triggers intense discussions among users on the Internet and verbal criticism of the school, which causes serious negative public opinion. A few hours after the incident broke out, the school responded that the police had begun an investigation. But the parents stated that the incident was not monitored. The incident triggered intense discussions on the Internet again, and they were basically fighting against the school’s inaction. Then the truth of the incident was restored only two days after the incident occurred. Regarding the school’s failure to notify the parents in time, the reason was that the body could not be identified and the cremation was carried out after the parents signed and agreed. In this incident, because the truth of the incident was not disclosed to the public in time, negative public opinion on the Internet developed wantonly, which had a serious impact on the honor of the school and the stability of the society. However, after new media and government reporting, the truth of the incident becomes clear, and Internet public opinion is developing in a positive direction. Mapping this event in the Fig. 2, node
In the process of dual positive public opinion guidance, we improve the DW model of the opinion dynamics mentioned in the related work to conduct the guidance from the positive opinion guiders to the negative opinion receivers.
In this paper, the guiders and receivers are not the close opinion nodes. On the contrary, we aim to solve the problem of public opinion guidance. Therefore, it is directed to the guidance of the negative node to the positive node, so the two agents have opposite opinions, that is, the sign is opposite. In order to represent the mechanism of the dual positive guidance more accurately, we propose Eq. (8) for opinion evolution based on the Deffuant model. From the above description, we can see that the difference between the opinion of the bounded confidence is
where,
In the equations,
Based on Eq. (8), we present dual positive public opinion guidance based on reinforcement learning (RL) according to dual leaning mechanism aforementioned. The model maps to machine learning described in Fig. 3.
The interaction process of dual-PPOG mechanism maps to dual learning. The left part of the figure is a step of the intermediate interaction process in the dual positive guidance mechanism of Fig. 2, and the right part of the figure is the interaction after mapping the left part to the machine learning. The middle of the figure on the right mainly shows the interaction between 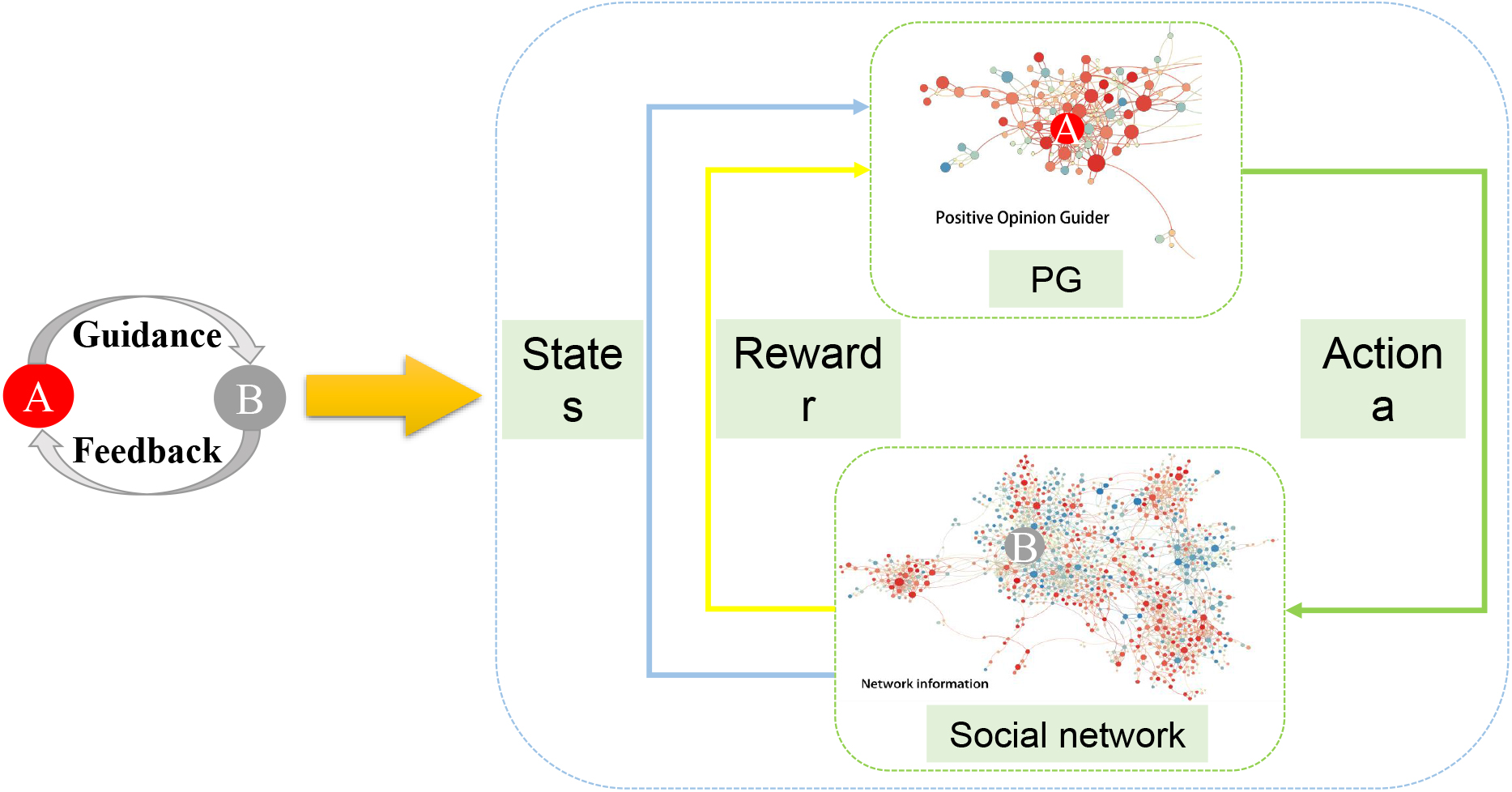
As for reinforcement learning, the control problems in which the
From the description for the dual positive public opinion guidance above, the procedure are regarded as symmetry or duality. What’s more, the nodes’ dual positive guidance machine are defined and laid the foundation for the subsequent model of guiding public opinion. Then, the important part, weight allocation, presents in the next section.
In this section, we mainly present the weight allocation of the dual positive public opinion process. This part is one of the most important parts of dual positive public opinion guidance. And this section will implement the algorithms of dual positive public opinion guidance, which is the important description of the dual-PPOG. Noticing that the weight allocation is the main part of the dual-PPOG based on reinforcement learning according to dual learning. Therefore, it is necessary to describe the process of weight allocation in detail.
The core idea of weight allocation is that we believe that the opinion value of each guided negative opinion receiver, the opinion value of neighboring nodes and the topology of the social network determine the effect of guiding the node, so we can use these conditions to judge whether we should allocate this node more guidance weight.
The difficulty in the allocation of guidance weights is that the guidance is not completed at one time, but requires multiple rounds of evolution and guidance. In this process, the guidance weights need to be dynamically changed, and the result of the guidance cannot be judged by people. So the weight allocation is not a traditional machine learning task. Thus we use reinforcement learning to build our model, because reinforcement learning can support this multi-round interactive learning, and does not require people to evaluate the results.
As for reinforcement learning, the control problems in which an agent acts in a stochastic environment by sequentially choosing actions over a sequence of time steps are studied in order to maximise a cumulative reward. We model the problem as a Markov decision process (MDP) which comprises:
Action space
State space
Reward
Policy
Time
As for action
The guidance weights allocation process by reinforcement learning. In the figure, reinforcement learning is used to allocate the guidance weights from 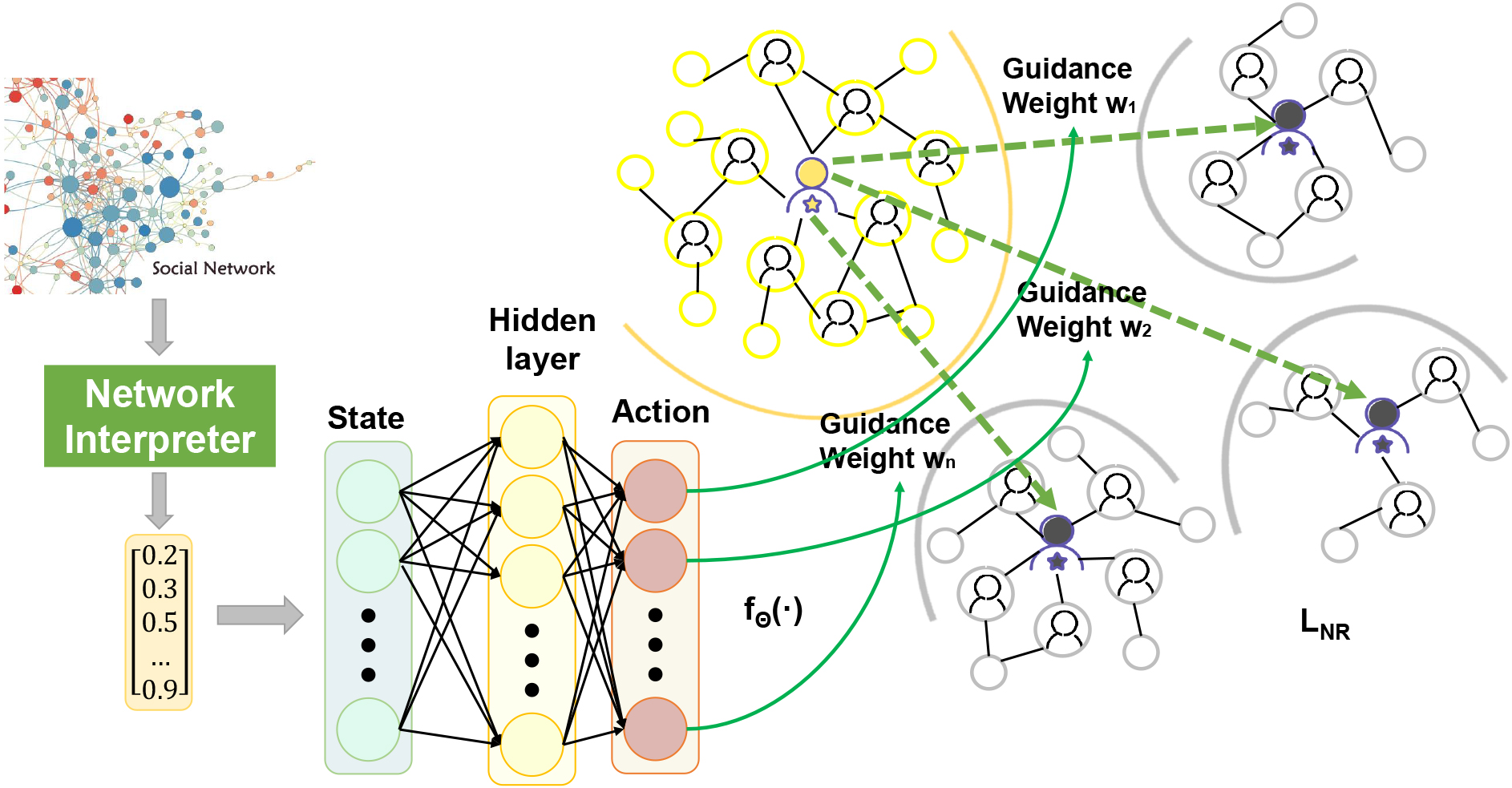
Besides, considering that the assigned weights are limited and not completely assigned to one nodes, the feedback obtained after assigning the weights determines whether the policy is the optimal. The agent uses its policy to take an action, then get states and rewards from environment.
Afterwards, the opinion leader nodes are guided by the model of dual positive public opinion. For the remaining ordinary nodes, they are guided by FJ and HK model aforementioned. And the training process for dual-PPOG model is implemented as the Algorithm 4.
: Training Process of Dual-PPOG model[1] Social network
Algorithm 4 is the training process of the Dual-PPOG model. First, we need to initialize the network parameters
The development and evolution of social networks are based on opinion dynamics or opinion evolution. Therefore, the research is based on the FJ and HK models for the development of each community in the social network, and each node decides whether to accept the opinions from the neighborhood they follow [5]. And after the dual positive public opinion is guided, the remaining nodes in the social network also change their opinions according to the FJ and HK models. The HK model is used instead of the DW model because the HK model mentioned above is more suitable for interaction in large groups and can achieve group convergence faster. The dual positive public opinion guidance proposed in the paper is based on a variant of DW model, because the DW model is better suited for pairwise interactions within large populations. Therefore, we use different models to conduct the entire public opinion guidance to make the guidance result reach the optimum. The rules for updating the opinions of the community and the remaining nodes are given by:
where
: The Implementation of Dual-PPOG Model[1] Social network
The specific dual-PPOG algorithm is explained in detail as Algorithm 4.3. Algorithm 4.3 is about the implement of the Dual-PPOG model. First, we input the opinion value of each candidate influencers into the trained neural network, and then obtain the guidance weight corresponding to each node in steps 3–6. Finally, we use the weight to guide the node. This process is repeated for
In this section, we used common synthetic benchmarks to test the performance of our proposed dual-PPOG algorithms on real-world networks. Firstly, we present the detailed information of the experimental datasets and the experiment setup including the specific setting for parameters. Secondly, we describe the evaluation criteria of the experiment and the baselines for comparison including percentage of opinions and state of network. Finally, it is the experiment performance of our proposed model in public opinion guidance compared with all methods.
In the experiment, we mainly carried out the following process:
We preprocess the datasets described below, label the values of the nodes’ opinions, and use the nodes’ first expressed opinion as the initial opinion that we set the value in We use the Fast Unfolding algorithm aforementioned to divide the social network into communities, which not only take the network structure into account, but also consider the opinion value. The opinion leaders in the communities are detected. For the opinion leader detection, we set an influence score to detect opinion leaders accurately. The influence score combines the score obtained by the PageRank algorithm with the opinion value of the node. The opinion leaders found based on the influence score would have better and wider influence, which is more conducive to the following guidance work. Implement the public opinion guidance. Use the model of dual positive public opinion guidance model proposed above to guide.
Table 1 demonstrates the basic information of three social networks used to verify the effectiveness and quality of the model of dual positive public opinion guidance. In Twitter dataset, the agents are associated with their account ID, the following relationships containing followers and followees. In email dataset, it comprises that each user is associated with a set of emails under one topic, each of them contains a sender ID, email textural content and recipient ID. And in Facebook dataset, there are the agents’ a set of reviews containing the agent ID and timestap textual content. All of the datasets provides the relationships among the agents. In all datasets, we utilize the Jaccard Index to estimate graph connectivity and extract the largest connected subgraph.
Summary of three datasets used for experimental validation
Summary of three datasets used for experimental validation
The neural network of each data set is a three-layer fully connected network, and we use ReLU as the activation function of the neural network. The network training configurations of the three data sets are shown in Table 2,
Training configuration
Training configuration
We evaluate the result of the dual-PPOG model based on the two kinds of evaluation criteria.
Percentage of opinions
The specific equations are the percentage of both negative and positive opinions.
where
After the guidance of dua-PPOG model in the social networks, we set another evaluation criterion, which is the average opinion to judge the value of networks’ opinions as Eq. (12).
The following baseline methods are introduced to evaluate the comparative performance of the proposed dual-PPOG model.
HK model [31]. HK model is a kind of bounded confidence model, it rely on the idea of repeated averaging under bounded confidence. AE(Add edge) [32]. AE forms opinion leaders in the community by adding edges (the opinion leaders expressed that they can directly or indirectly convey their opinions to all other users’ nodes in the community), and adds edges between the communities so that the opinions can develop in the preset direction. Random [33]. The Random model randomly selects receiver from the candidate nodes to guide. AIA(Add informed agent) [34]. AIA defines a kind of informed users, who are employed or voluntary individuals, and they will guide the value of the network in the expected direction. By addition the number of informed users, the opinion value of the network will change in a positive direction.
To validate the performance of dual-PPOG model, we apply the model to guide three different networks, and compared with 4 different methods. The comparison indicators include the proportion of positive nodes after the guidance and the average opinion value of the social network. In the end, our proposed method is significantly better than other methods in this two criteria.
Table 3 shows the number of positive and negative nodes in the network of 5 methods after 50 rounds of evolution and guidance in the case of random initialization. From the table we can see that our model’s performance has the best results.
The experiment results of percentage of opinions
The experiment results of percentage of opinions
The experiment results of average opinion over time
Percentage of opinions.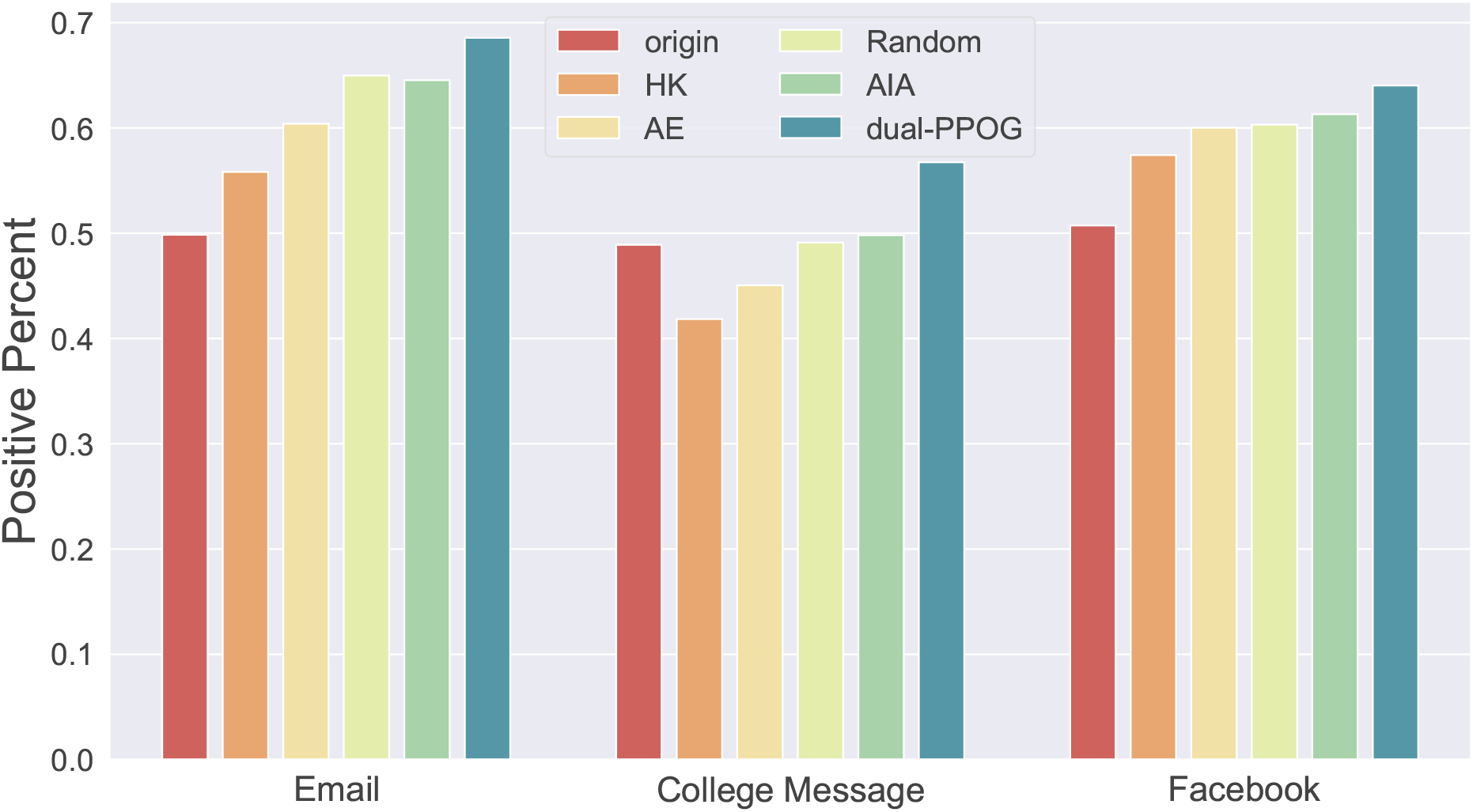
Average opinion over time.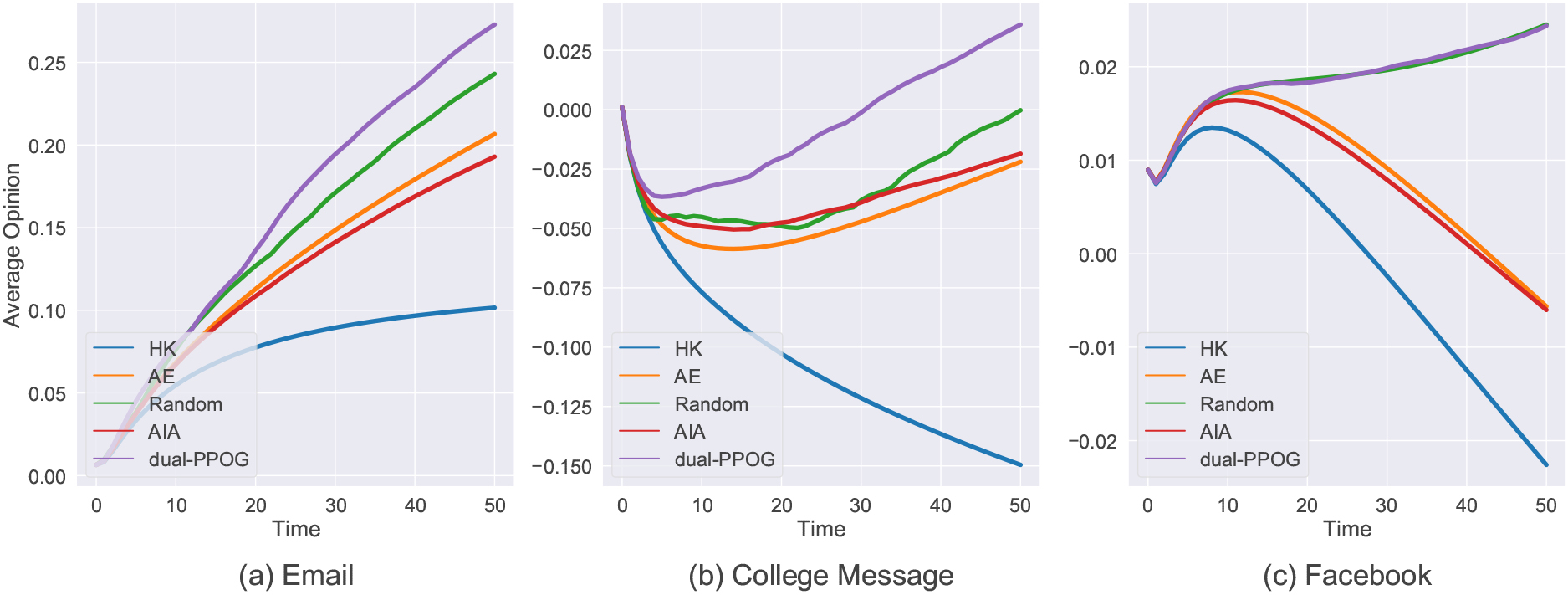
Email: Visualization of opinions evolution over time.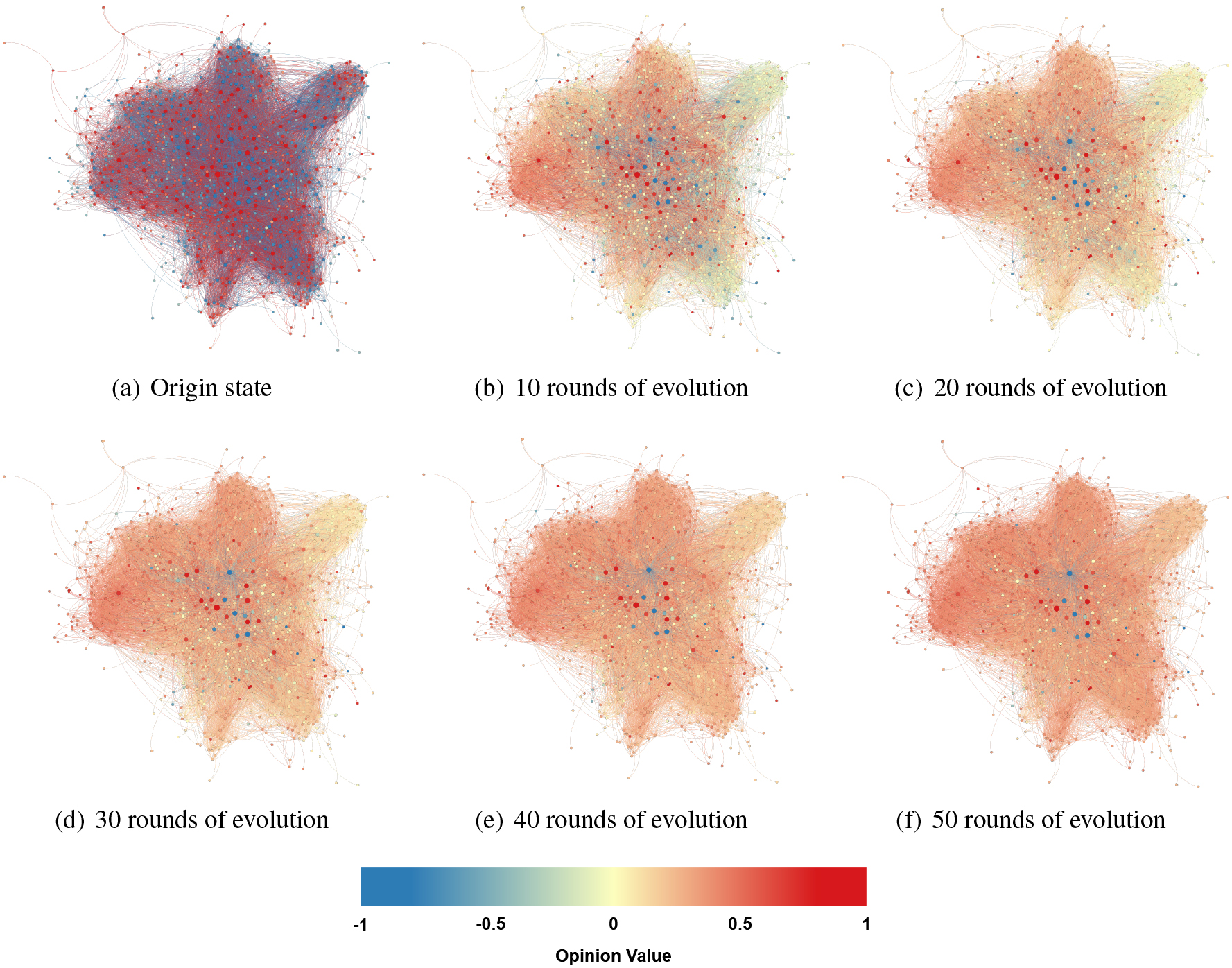
College message: Visualization of opinions evolution over time.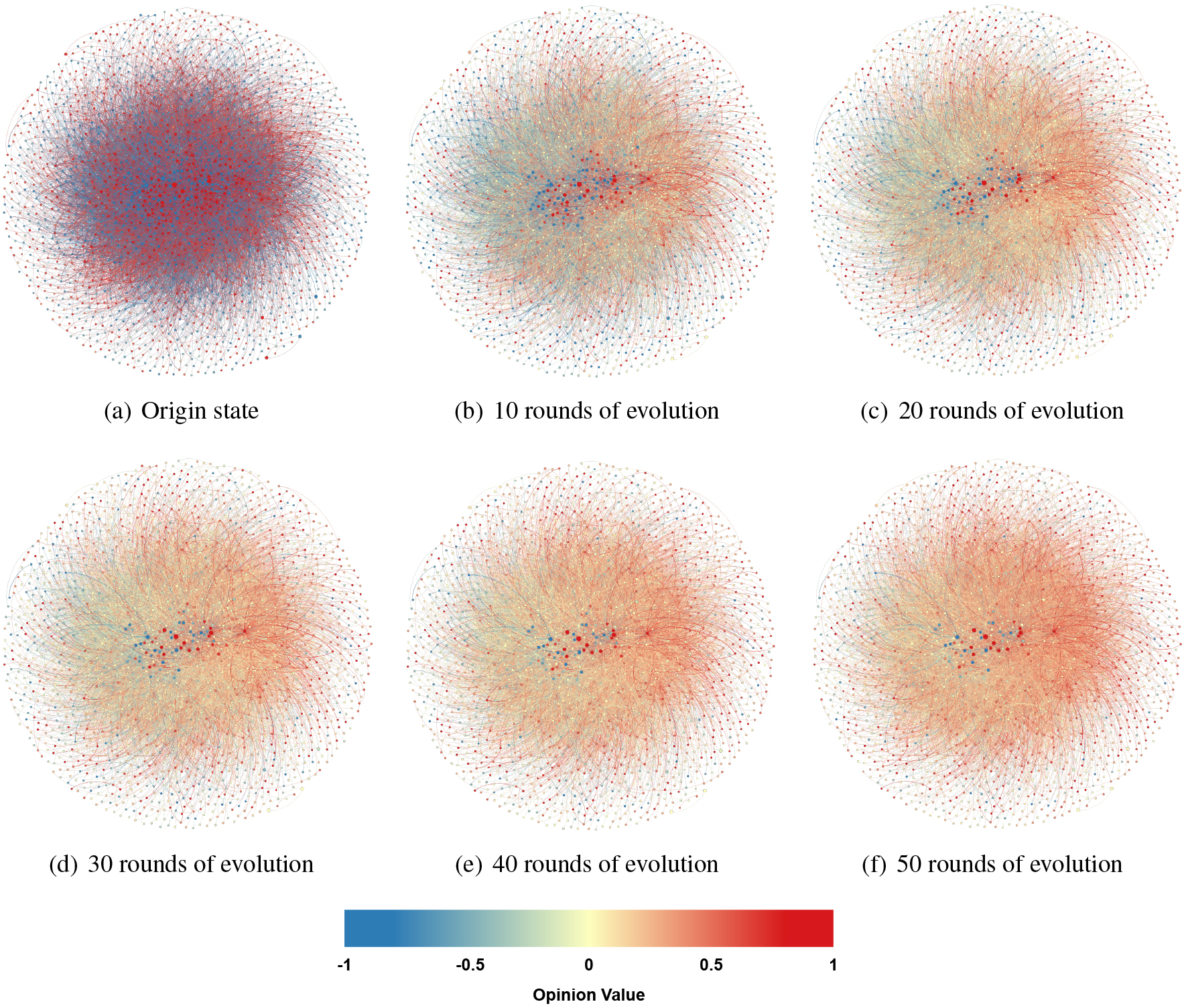
Facebook: Visualization of opinions evolution over time.
In Fig. 5, it is a comparative experiment on the percentage of opinions on three datasets among the five methods. In the Email dataset, we can find that since its initial state has fewer negative nodes than positive nodes. Even without guidance, its average opinion will change to a positive direction. In this case, we can see that our method has achieved good results, and as a comparison method AIA, the result is between the two baseline methods (random and average). In the College Message dataset, the opinion values of original network tends to be negative, after 30 rounds of evolution and guidance, only our method can reduce the negative nodes in the network, while other methods cannot make the network develop in a good direction. This proves that our method can also achieve better results when the overall public opinion is unfavorable. In the Facebook dataset, the biggest difference between this network and the other two networks is that there are more nodes and edges in this network. Compared with the Email dataset, its point value changes less obviously, we believe that the increased complexity of the network leads to the weakening of the guidance effect. In this dataset, we also found that the results of our method are only slightly better than other methods, We believe that this is because the network complexity has increased, which has made it difficult to train the model, in the end, the model failed to get results like two datasets.
For the experiment results of average opinion over time, the Table 4 shows our dual-PPOG model has a better performance than other methods. And we visualize the data in Table 4 through Fig. 6. In the Fig. 6a, it shows the comparison of five methods in the email dataset.(Notice that the Time is for the time step in the cascade model rather than the day) In email dataset, all methods can make the opinion value change in a positive direction over time. Compared with other methods, our method has achieved the best results. Figure 6b shows the comparison of the College Message dataset. We can see that the public opinion on the network will change in a worse direction without guidance, even under the guidance of some methods, it takes a long time for the opinion value in the network to change in a good direction. Under this initial condition, our method can still control the average public opinion to a positive direction in a relatively short period of time. Figure 6c shows the comparison of five methods in the Facebook dataset. We can see that the lines of the best two methods are almost overlapped, while the other methods have developed in the opposite direction over time. We believe that the main reason for this situation is that other methods cannot play a big role in this large-scale network. Our method and random selection of nodes for guidance are similar in this data set. This is because in a large network, due to the increase in the state space, the choice of our strategy will be more random, resulting in similar results.
Figure 7 shows the opinion value of the social network over time in the email dataset. Red nodes represent the positive ones, blue nodes represent the negative ones, it is visual in the initial state at the Fig. 7a. Since the opinion value is randomly generated, the two kinds of nodes cross together. After a period of social network dissemination, most of the nodes’ color turned yellow, that is, in a neutral attitude. After several rounds of iterations, the value of the entire social network tends to be positive eventually.
Figure 8 is a visualization of the opinion values of the college message dataset over time. The difference from Fig. 7 is that when the opinion value of college message is initialized, there are more negative nodes than positive ones, so the effect in the previous rounds of evolution is not as good as in email. It is obvious in the data concentration. Even so, in the final stage, our proposed model can still guide the whole network’s opinion value to a positive direction.
The difference between Fig. 9 and the previous two figures is that the Facebook dataset has more nodes and the community structure is more obvious. Then, after the guidance, the distinct negative communities and the positive communities will eventually emerge.
In this paper, we propose the model of dual positive public opinion guidance (dual-PPOG) to deal with the novel problem of guiding negative public opinion in social network. We systematically define the entire process of dual-PPOG and professional terminology. Through our definition of opinion dynamics model, opinion leaders are detected in the public opinion guidance community and named as positive guiders and negative receivers. Then use dual learning to guide the receivers and train the required parameters. For the remaining ordinary nodes, we use the defined FJ and HK models to influence them. Repeat this entire process until the negative public opinion guidance is successful and the network is in a stable state. Our paper combines social network public opinion guidance with machine learning, which is a big breakthrough, and the process is defined in detail. In order to evaluate our proposed approach, we applied it on the three datasets, including email, college message and Facebook network, which has the best experiment result. Therefore, our research on dual positive public opinion guidance has an important significance for current negative public opinion development.
In the future, we will introduce much newer machine learning techniques into our method to improve the performance of our method. More evaluations and experiments will be conducted to improve the proposed methods in more complex situations. After that, we will expand the scope of use of the model, and we will select the guided nodes from all nodes, not just among opinion leaders. At the same time, we will consider the help of domain experts, who can give suggestions in the construction of opinion evolution models in different fields, so that the model can better simulate the real propagation process.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation (Grant Nos. 61872298, 61802316, and 61902324), the Sichuan Regional Innovation Cooperation Project (Grant No. 2021YFQ008).