
Abstract
Fast-developing mobile location-aware services generate an enormous volume of trajectory data while adding value to people’s lives. However, trajectory data contains not only location information, but also sensitive personal information. If the original trajectory data is published directly, it could result in serious privacy leaks. Most of the existing privacy-preserving trajectory publishing methods only protect the location information or set the same privacy preservation levels for all moving objects. To meet the users’ personalized privacy requirements and ensure the utility of trajectory location and sensitive information, we propose a trajectory personalized privacy preservation method based on multi-sensitivity attribute generalization and local suppression. First, we set different security levels for each trajectory by calculating the correlation between sensitive attributes to establish a sensitive attribute classification tree. Second, we generalized sensitive attributes based on privacy preservation levels for each trajectory, the trajectory data still at risk of privacy leakage after generalization was locally suppressed. Finally, an anonymized trajectory dataset was generated. Experimental results on real datasets demonstrated that our method could improve data availability while preserving privacy.
Keywords
Introduction
With the popularization of mobile devices and the rapid development of positioning technology, researchers can easily obtain a large volume of trajectory data such as social interaction, check-ins, and travel. The collected trajectory data itself can serve myriad practical applications, for example, to provide more reasonable path planning references for urban traffic planning departments; to avoid traffic congestion and reduce traffic accidents; to provide decision support for the construction planning of governments and commercial organizations; or to provide the data for location-based advertising [1, 2]. Various applications use trajectory data to facilitate travel, bringing great convenience to the lives of users [3]. However, while trajectory data brings great benefits, it also poses potential threats. Trajectory data contains not only spatiotemporal information, but also sensitive personal information, including a user’s physical condition, occupation, and home address. If the original trajectory data is published directly, it could cause serious privacy problems. In particular, if an attacker has some trajectory data as background knowledge, all private information could be obtained by matching it with the published trajectory data. Consequently, trajectory privacy preservation has become a research hotspot in the field of trajectory data mining.
Presently, trajectory privacy preservation can be divided into two categories, namely, offline trajectory privacy preservation [4, 5], where organizations collect user trajectory data and store it in a database, analyze and mine useful information to feed back to users, which requires privacy preservation of the trajectory data prior to its publication, and online trajectory privacy preservation [6, 7, 8], such as location-based services, which provide related services for moving objects by locating them in real time. However, the real-time trajectory data needs to be provided to a server provider, which also faces the risk of privacy leakage. In this study, we examine the former, offline trajectory privacy preservation, as shown in Fig. 1.
Privacy-preserving trajectory data publishing structure in offline mode.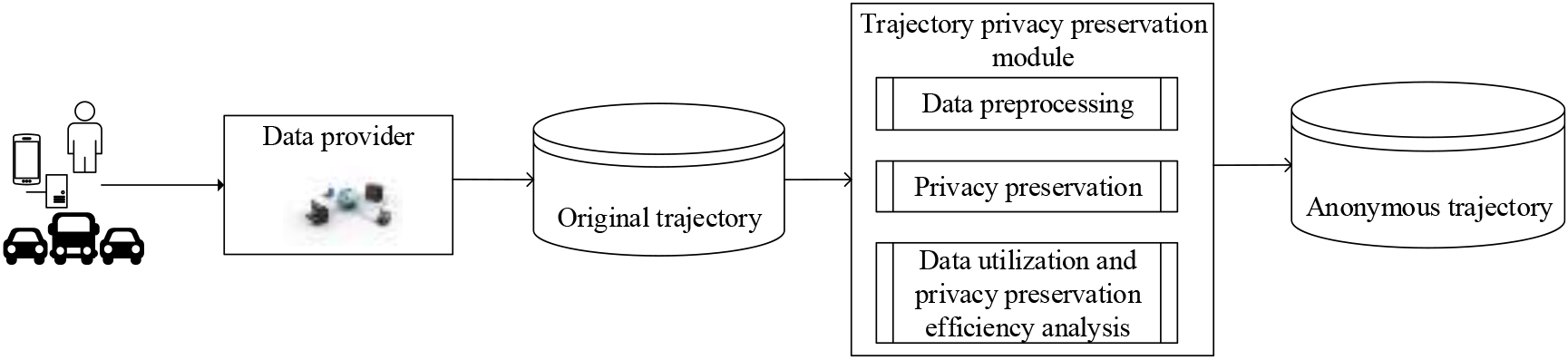
The trajectory consists of a series of ordered location points, including the current position and the passing time. In addition, the user’s sensitive attributes will be published along with the trajectory data. The privacy of the trajectory locations and sensitive attributes simultaneously must be protected. The purpose of this study is to protect the user’s sensitive attributes while protecting their trajectory information.
If the trajectory data were to be published together with sensitive attributes, attackers could infer sensitive attributes through the trajectory data, having more serious implications. Table 1 shows the original trajectory data without any preservation measures in which there are three types of attributes, namely, explicit identifiers, quasi-identifiers, and sensitive attributes. Explicit identifiers, typically used to uniquely identify a user, such as names, should be removed from the table before publishing. Generally, user information cannot be determined by a single quasi-identifier, but several quasi-identifiers can be combined to locate a specific user. The quasi-identifier we focus on here is trajectory information, which comprises a set of spatiotemporal trajectory points, with each point representing a location and a corresponding timestamp. Sensitive attributes are private information that users do not want to disclose, such as diseases and occupations, as presented in Table 1.
Original trajectory data
Directly publishing original trajectory data could cause serious privacy leakage problems. There are three types of privacy attacks that could typically be used against published trajectory data should an attacker have sufficient background knowledge as follows:
Identity link attack. In the trajectory database, several trajectories may appear relatively few times, with essentially no moving objects matching it. At this stage, an attacker with sufficient background knowledge could uniquely identify a user’s data records and obtain their sensitive attributes. For example, if an attacker knows that Freeman’s data are in the trajectory database and that he has visited
Attribute link attack. Attackers could infer sensitive attributes of users based on their background knowledge. For example, if an attacker knows that Bob visited location
Similarity attack. Some sensitive attributes differ, but attribute values with similar meanings frequently appear in a trajectory database. Even if an attacker cannot uniquely identify a user’s record, they could infer the category of the user’s sensitive attribute. For example, if an attacker has the location point
In research related to trajectory sensitive attribute preservation methods, most researchers study the preservation methods for a single sensitive attribute and cannot protect trajectory datasets containing multiple sensitive attributes. However, the trajectory datasets published often have multiple sensitive attributes, so many existing methods cannot meet the privacy requirements of users.
To this end, we propose a trajectory personalization privacy preservation method based on multi-sensitivity attribute generalization and local suppression. This method achieves anonymity requirements by analyzing the correlation between sensitive attributes, assigning privacy preservation levels, generalizing multiple sensitive attributes, and adopting local suppression of trajectories. It achieves a good balance between data availability and privacy preservation and meets users’ personalized privacy preservation requirements.
The main contributions of this paper can be summarized as follows:
A personalized privacy preservation method in trajectory data publishing is proposed, which can achieve different degrees of privacy preservation based on different users’ needs and avoid the waste of resources. We propose a method to set the privacy preservation level based on the correlation between sensitive attributes, which combines the generalization of sensitive attributes and local suppression of trajectories to preserve the utility of anonymous datasets as much as possible. We define a balance suppression coefficient for achieving the balance between privacy preservation levels and trajectory suppression, which effectively avoids deleting too many location points and ensures a reasonable trajectory retention ratio while satisfying privacy preservation requirements. The experimental results on a real trajectory dataset showed that the proposed algorithm could achieve a good balance between data availability and privacy preservation.
The rest of this paper is organized as follows: Section 2 reviews the related work. Section 3 presents the problem definition. Section 4 describes the methodology of this study. Section 5 outlines the experimental results, and Section 6 summarizes the work and future research directions.
In the face of enormous volumes of trajectory data, the problem of privacy leakage has become increasingly serious. Traditional (GPS-type) trajectory data only contains latitude and longitude locations and time information, while high-dimensional (semantic) trajectory data contains much semantic information, including time, semantic location, and sensitive attributes. Consequently, the preservation of trajectory data can be divided into two types, namely, traditional trajectory privacy preservation and semantic trajectory privacy preservation. The former refers to the adoption of particular measures regarding the GPS locations of the original trajectories to reduce the probability of an attacker correctly identifying a user’s trajectory and achieve the required anonymity; the latter refers to the consideration of the relationship between the semantic location information and sensitive attributes, while protecting the semantic locations and the sensitive attributes of the trajectory.
Traditional trajectory privacy preservation methods
Fake trajectory method. This method adds particular fake trajectories to the original trajectory dataset to achieve the purpose of protecting privacy information. The fake trajectory method is simple, but it can be difficult to meet privacy preservation requirements and ensure data utility after adding the fake trajectories. Many scholars have researched this problem with some success. Lei et al. [9] proposed a privacy preservation method for fake trajectories based on spatiotemporal correlation that analyzed the spatiotemporal correlation between adjacent positions in a single trajectory and the similarity between trajectories, and it could effectively blur the lines between fake trajectories and real trajectories. Dong et al. [10] proposed a trajectory privacy preservation method based on frequent path mining. It first removed uncommon trajectories from the trajectory dataset, before proposing a new method to find frequent paths, and then selected representative trajectories to represent all trajectories within a group, adding virtual trajectories to satisfy
Suppression method. This method suppresses or deletes some sensitive locations or those visited frequently by moving objects before the trajectory data are published. Gruteser et al. [12] first proposed dividing the trajectory data into sensitive and non-sensitive areas. Only when a moving object was in a sensitive area would the corresponding trajectory be suppressed before being published. Mohammed et al. [13] proposed a high-dimensional sparse trajectory privacy preservation method, which used a global suppression method to suppress trajectory data. It ensured that the
Generalization method. Compared with the aforementioned two methods, the generalization method can achieve a better balance between data availability and data preservation efficiency. The current mainstream trajectory privacy preservation technology based on the generalization method is
Semantic trajectory privacy preservation
Trajectory data includes not only single location information, but also semantic information and sensitive attributes such as gender, home address, and occupation. Simply protecting location information could cause privacy leakage. Most privacy preservation principles are to constrain the disclosure of sensitive information, removing identifying attributes, such as name and id, from the trajectory database before the data are published. However, such methods cannot resist similarity link, identity link, or attribute link attacks, particularly when an attacker’s background knowledge could include partial trajectories. To solve the problem that
In conclusion, published trajectory data often contain semantic location and sensitive attribute information. Simply protecting GPS location information is not sufficient. Moreover, each user has different privacy preservation requirements. Most of the existing methods do not consider the different privacy requirements of different users and cannot resist all the linking attacks, perhaps just one or two of them at best. Consequently, this study considers the correlation between multiple sensitive attributes and proposes a trajectory personalized privacy preservation method based on multi-sensitive attribute generalization and local suppression, which can meet a user’s personalized privacy preservation requirements and resist all linking attacks.
Theory: Problem description and related definitions
Trajectory model
where
Table 1 shows a trajectory dataset
where
The trajectory dataset studied here contains two sensitive attributes: disease and occupation. For example, for the second trajectory
There are two types of nodes in ST, one being the leaf node, which records sensitive attribute values, and the other being the internal node, which represents possible attribute values after generalization of the sensitive attributes. Each node can be denoted as
Using the disease-sensitive attribute as an example, we use the classification tree shown in Fig. 2 to classify a user’s disease. The leaf nodes (19 in total) represent the values of sensitive attributes; the parent node of each node represents the previous category to which they belong. The name of each node is unique. Particularly, the classification tree can be expanded as user disease types increase in the dataset.
For example, Flu and SARS are both pulmonary infections; pulmonary infections are pulmonary diseases, and pulmonary diseases are diseases. The classification tree height shown in Fig. 2 is ST.h
Sensitive attribute classification tree.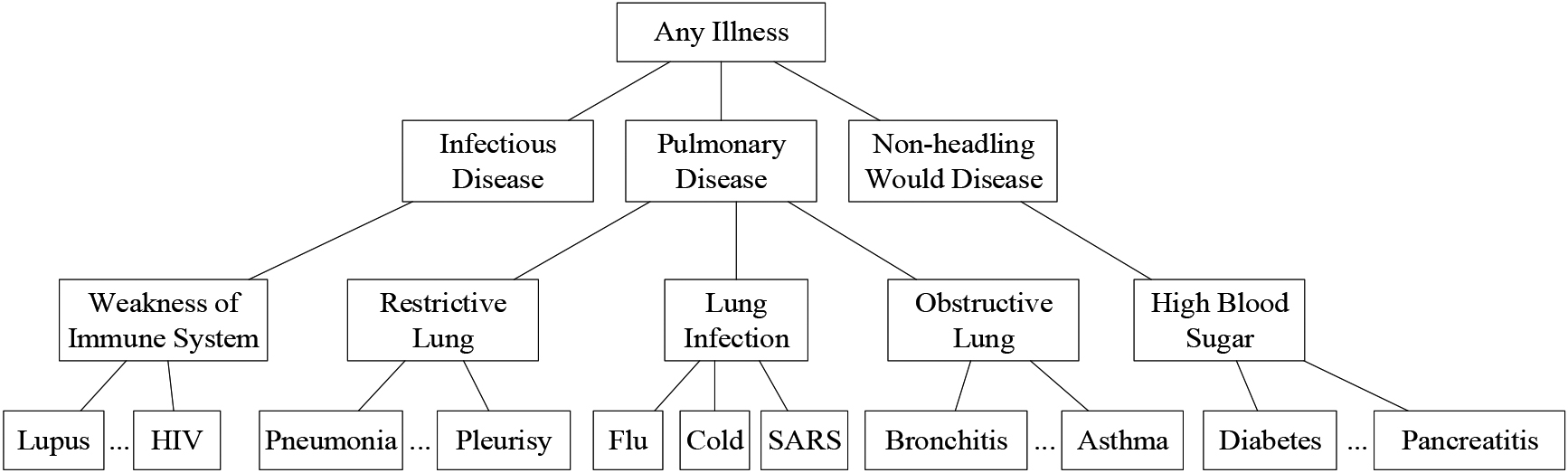
Different moving objects have different privacy requirements. As presented in Table 2, we provide users with four levels of privacy preservation, namely None, Low, Middle, and High. Each privacy preservation level corresponds to a value, that is, “None” corresponds to 0, “Low” corresponds to 1, “Middle” corresponds to 2, and “High” corresponds to 3. For example, the privacy preservation level of trajectory
Trajectory data with privacy preservation level
Trajectory data with privacy preservation level
where
Using the mastered location,
As presented in Table 2, assuming that the attacker masters the location
The leakage probability of trajectory
where
Algorithm idea
Because attackers have partial location information as background knowledge, simply removing explicit identifiers cannot effectively protect user privacy. We propose the personalized trajectory privacy preservation algorithm based on multi-sensitive attribute generalization and local suppression (PTPPMGLS). If the privacy leakage probability of each trajectory is less than or equal to the privacy parameter
Before using the PTPPMGLS method proposed in this study, data pre-processing is required. The pre-processing generally considers missing values and the length of the trajectory. Here, the trajectory with missing data is safe by default, and no protection measures are required, because our purpose is to protect sensitive attributes and trajectory information. The trajectory data is considered safe if either of them is missing. In addition, we need to delete trajectories with too few locations, because these trajectories are usually matched to the users by the attacker with a high probability.
The PTPPMGLS algorithm can prevent different degrees of privacy attacks while ensuring data availability. It can be divided into three steps – that is:
Setting the privacy preservation level. Use the Apriori algorithm [28] to obtain the correlation between the sensitive attributes of each trajectory, and set the privacy preservation level for the trajectory accordingly;
Generalization of the sensitive attributes. For the trajectory data for which the privacy preservation level has been set, generalize the sensitive attributes based on the correlation between them and the constructed classification tree;
Trajectory local suppression. The generalized trajectory data can be further protected. The remaining trajectories that may run the risk of privacy leakage being subjected to location point suppression. Section 4.2 introduces the setting method of privacy preservation level. Sections 4.3 and 4.4 implement multi-sensitivity attribute generalization and trajectory local suppression, respectively. The algorithm flow diagram is shown in Fig. 3.
Algorithm flow diagram.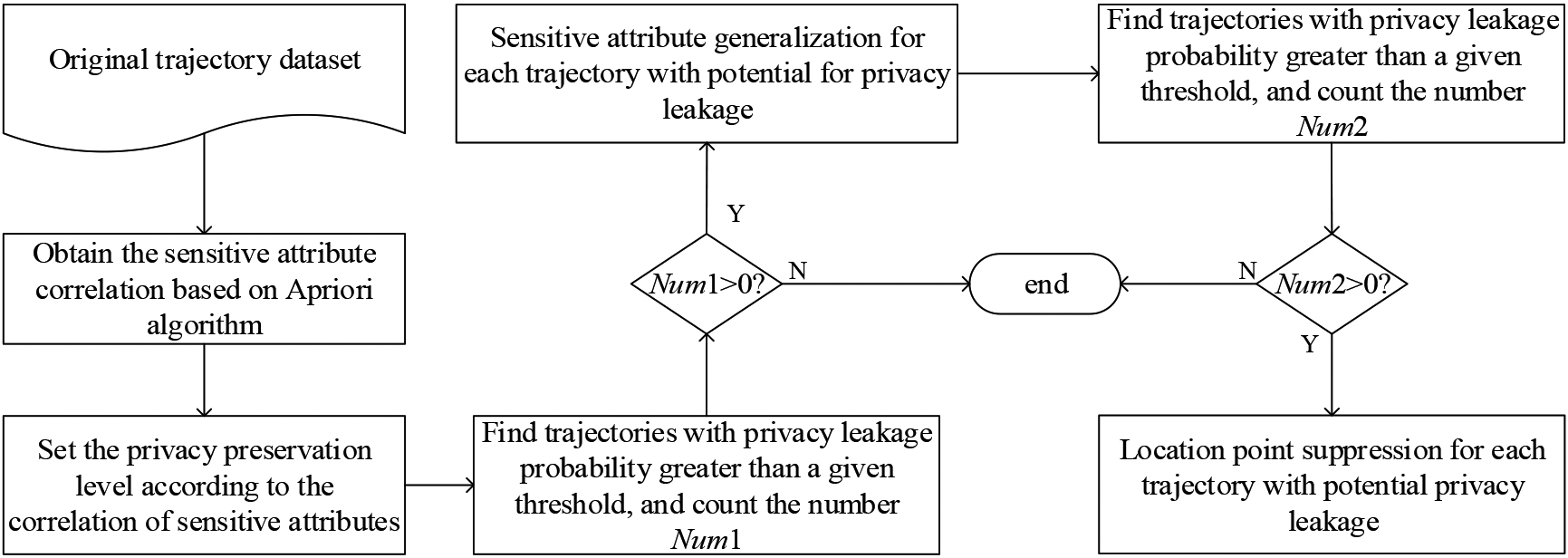
Different users have different requirements for the degree of privacy preservation. It is not necessary to adopt the same privacy preservation level for each user, otherwise it could waste resources. Consequently, we use the Apriori algorithm to calculate the correlation between sensitive attributes and set the privacy preservation level according to the correlation.
where
Based on the correlation of each trajectory, its privacy preservation level can be set as follows:
The sensitive attributes can be generalized based on the maximum generalization strength (
The pseudo-code of the sensitive attribute preservation (SAP) algorithm is shown in Algorithm 1. The SAP algorithm first builds a disease-sensitive attribute classification tree for the trajectory dataset
Using the trajectory dataset shown in Table 2 as an example, the generalized trajectory information is summarized in Table 3. Given
Assuming that the background knowledge mastered by the attacker
Trajectories after generalization of sensitive attributes
Trajectories after generalization of sensitive attributes
Algorithm 2 shows the pseudo-code of the MSAG algorithm. First, it initializes
After generalization of sensitive attributes, there may still be trajectories at risk of privacy leakage in the trajectory dataset, so further preservation measures must be taken. We use the trajectory local suppression (TLS) algorithm to suppress the publishing of location points and process the remaining trajectories with privacy leakage risks to meet the privacy utility.
Although suppressing the location points in the trajectory can effectively reduce the risk of privacy leakage, it also greatly increases information loss. Consequently, we set a balanced suppression coefficient, which can comprehensively consider the risk of information loss and privacy leakage based on the privacy preservation level of the trajectory and achieve a better balance.
where
The pseudo-code of the TLS algorithm is shown in Algorithm 3. This algorithm can be used to process the trajectory dataset that still has the risk of privacy leakage after SAP processing. First, it initializes the dangerous background knowledge set
If the TLS algorithm is used again, the processing cost could be high. Consequently, we propose to re-identify the dangerous background knowledge (RDBK) algorithm to regenerate the dangerous background knowledge set
The anonymous trajectories are shown in Table 4. It can be seen that
Trajectories after local suppression
The pseudo-code of the RDBK algorithm is shown in Algorithm 4. It first initializes the dangerous background knowledge set
This section will demonstrate that the PTPPMGLS algorithm not only ensures that the anonymized dataset does not have trajectories at risk of privacy leakage but can also resist three similarity attacks and analyze the time complexity of the algorithm.
Security analysis
Analyze the trajectory dataset, find the trajectory Perform sensitive attribute generalization and local suppression on trajectories whose privacy leakage probabilities are greater than the Assign different privacy preservation levels to different users and generalize the sensitive attributes of users to different degrees in the anonymous trajectory dataset, with users with similar trajectory characteristics having different sensitive attribute values such as disease. Even if an attacker has the background knowledge that can infer similar users, it is impossible to determine sensitive attribute values such as disease. Therefore, it can resist similarity attacks.
For example, Table 1 shows the original trajectory dataset, and Table 4 shows the anonymized trajectory dataset. If an attacker has the location point
Time complexity analysis
The PTPPMGLS algorithm consists of three steps as follows:
Setting the privacy preservation level. The Apriori algorithm is used to calculate the correlation between attributes, and the privacy level is set based on the correlation. The time complexity of the Apriori algorithm is
Generalization of sensitive attributes. The worst time complexity of the SAP algorithm is
Trajectory local suppression. Eliminate the location points based on the balance suppression coefficient. In the worst case, the time complexity of the RDBK algorithm is
Results and discussion: Experimental analysis
Experimental environment and datasets
The experimental environment used an AMD Ryzen 7 4800H processor, running a CPU 2.9 GHz, on a Windows 10 operating platform, and the experiment was completed using Visual Studio 2019 programming. The experimental dataset was City80k [26], and 10,000 trajectories were randomly selected for the experiment. The format of the dataset is presented in Table 1.
Evaluation indicators
In this study, the sensitive attribute retention ratio and the trajectory information loss ratio were used to measure the utilization of trajectory data, and the disclosure risk was used to judge the privacy preservation degree of trajectory data.
Information loss
where
where
where
Sensitive attribute retention ratio analysis
Setting the maximum length of the attacker’s background knowledge to 2, the maximum generalization boundary
Figure 4 shows the sensitive attribute retention ratio under four privacy preservation levels. Figure 4a and b are the results of the sensitive attribute retention ratio showing changing values of
As
Sensitive attribute retention ratios under different privacy preservation levels.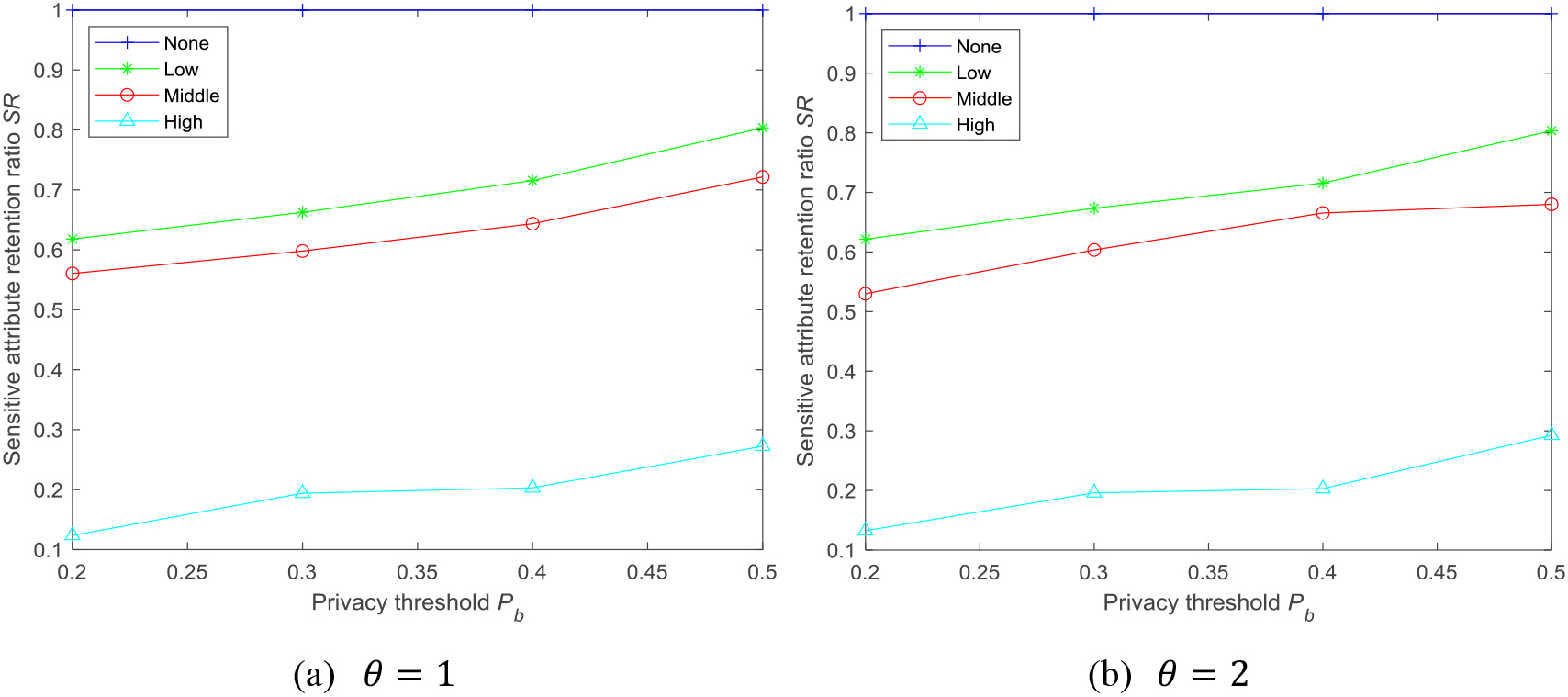
Figure 5 shows a comparison between the PTPPMGLS and PPTD algorithms [26] in terms of sensitive attribute retention. Setting
Sensitive attribute retention ratio for different methods.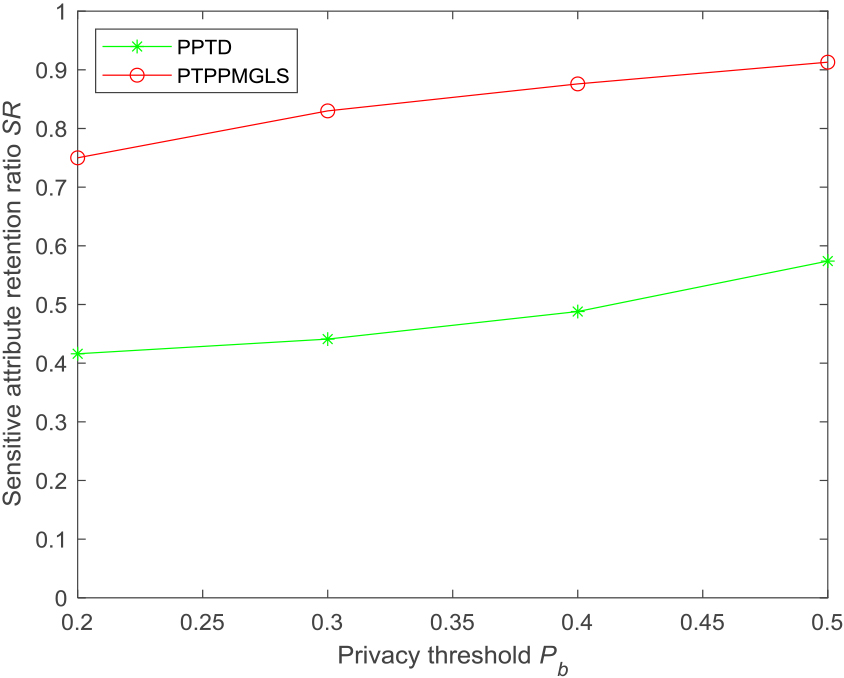
Trajectory information loss ratios under different privacy preservation levels.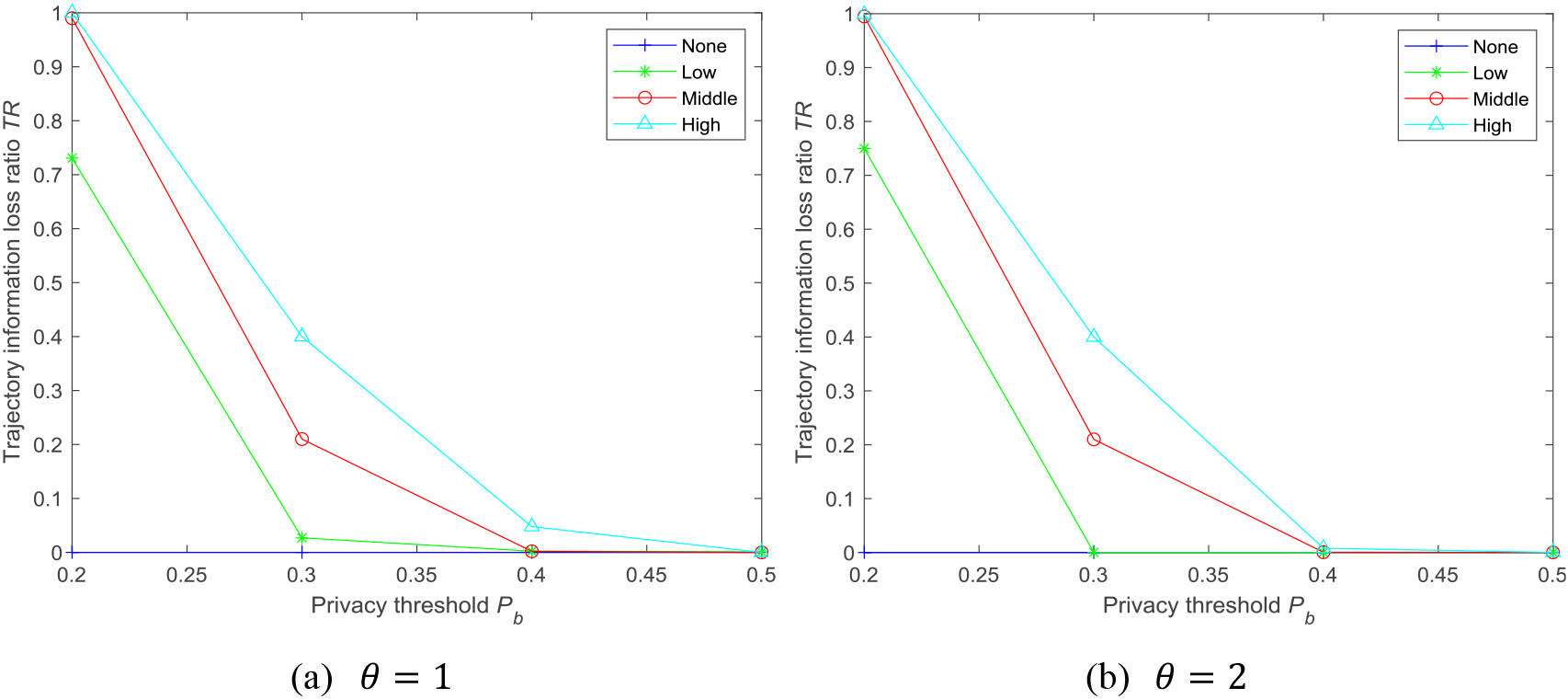
Trajectory information loss is a valid measure of the utility of an anonymous trajectory dataset. Experiments were conducted under the four privacy preservation levels proposed in this study and compared with the PPTD and KCL-Local methods [29] in terms of trajectory information loss.
Setting the maximum background knowledge of the attacker to be 2, Fig. 6 shows how the trajectory information loss ratio changes as the privacy threshold
Since KCL-Local algorithm adopts the
Trajectory information loss ratio for different methods.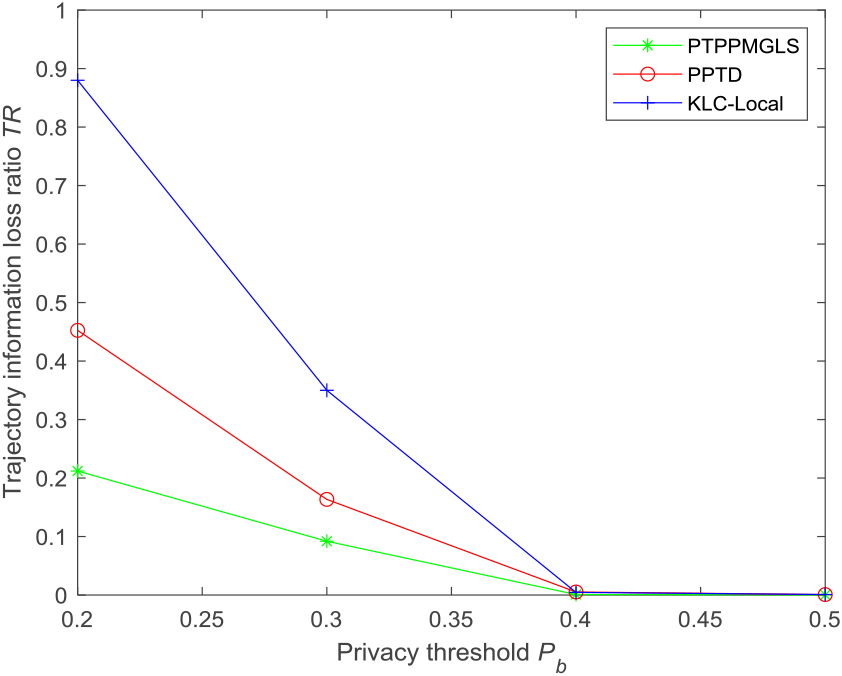
We use disclosure risk to measure the privacy preservation ability of the trajectory dataset. The average disclosure risk of the entire trajectory dataset can be given by adjusting
Setting the attacker’s background knowledge to a maximum of 2, Fig. 8 shows how the disclosure risk changes as
Average disclosure risk under different privacy preservation levels.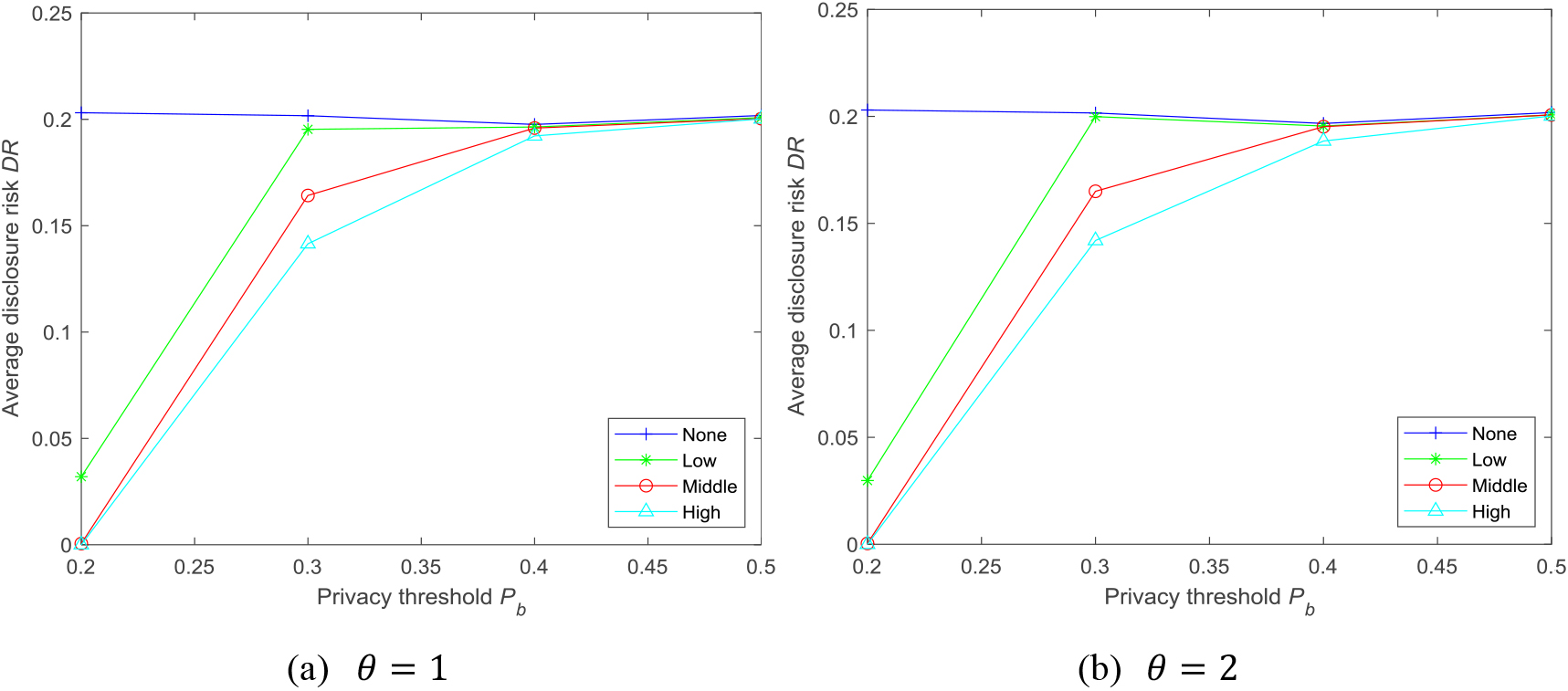
Figure 9 shows a comparison between the PTPPMGLS and PPTD algorithms in terms of average disclosure risk. Setting
Average disclosure risk of different methods.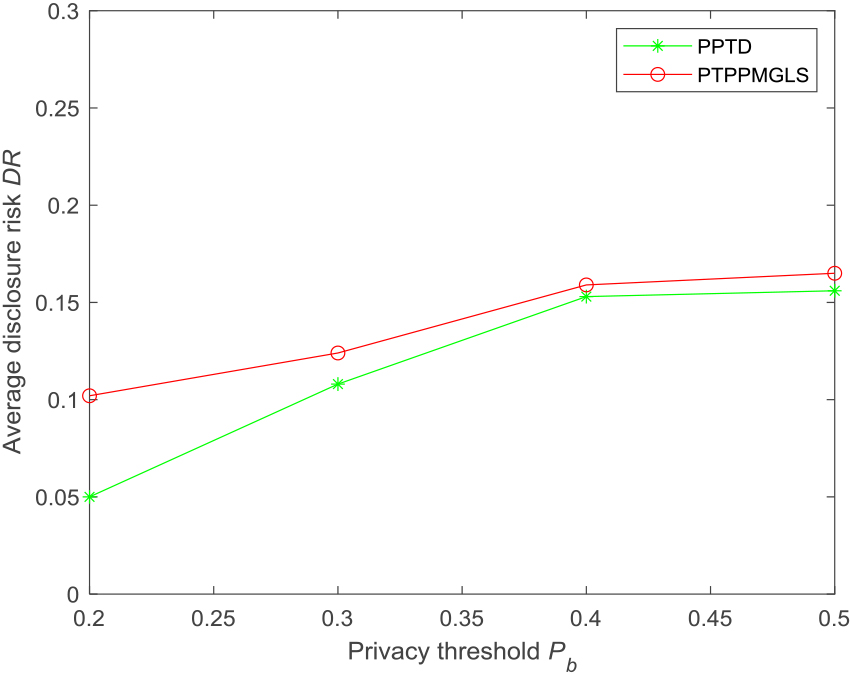
Under the premise of ensuring data security, the PTPPMGLS method exhibited better results in terms of data utility and sensitive attribute retention with lower information loss ratio, which could meet the needs of users, thus effectively achieving a balance between security and usability.
In this study, a trajectory personalized privacy preservation method based on multi-sensitive attribute generalization and local suppression was proposed to protect users from attacks when attackers have partial location information as background knowledge. First, the privacy preservation level was set for each trajectory based on the correlation of sensitive attributes. Then, sensitive attribute generalization was performed for trajectory data at risk of privacy disclosure. Finally, location point suppression was performed for trajectory data. The algorithm improved the degree of privacy preservation during trajectory publishing to a certain extent and could protect users’ privacy more effectively when the given threshold was high. However, analysis of the correlation between sensitive attributes, resulted in high time complexity and a lengthy running time, and only two sensitive attributes were considered to be correlated. Additionally, the differential privacy preservation method currently under study does not care about the background knowledge possessed by the attacker [30]. The quantitative analysis of the risk of privacy leakage needs to be adopted to the method proposed in this study. In the next work, we will conduct research on differential privacy techniques to improve the usability of the proposed method. In addition, more correlations between sensitive attributes will be established, so that the proposed method can be applied to more realistic scenarios.
Footnotes
Acknowledgments
The authors would like to thank the reviewers for their useful comments and suggestions for this paper. This work was supported by the National Natural Science Foundation of China (Grant Nos. 61702010, 61972439), the Anhui Provincial Natural Science Foundation of China (Grant No. 2208085MF164, 2108085MF214), the University Natural Science Research Program of Anhui Province (Grant No. KJ2021A0125), and the Key Program in the Youth Elite Support Plan in Universities of Anhui Province (Grant No. gxyqZD2020004).
Ethical statements
The authors claim that no conflict of interest exists in the submission of this manuscript, and the manuscript is approved by all co-authors for publication. None of the material in the paper has been published or is under consideration for publication elsewhere.