
Abstract
Nowadays, with the application of 5G, graph-based recommendation algorithms have become a research hotspot. Graph neural networks encode the graph structure information in the node representation through an iterative neighbor aggregation method, which can effectively alleviate the problem of data sparsity. In addition, more and more information graph can be used in collaborative filtering recommendation, such as user social information graph, user or item attributed information graph, etc. In this paper, we propose a novel heterogeneous information fusion based graph collaborative filtering method, which models graph data from different heterogeneous graph, and combines them together to enhance presentation learning. Through information propagation and aggregation, our model can learn the latent embeddings effectively and enhance the performance of recommendation. Experimental results on different datasets validate the outperformance of the proposed framework.
Introduction
With the application of 5G and Web 3.0, the problem of information overload has become more and more serious. In recent years, recommender systems have played an increasingly important role in various online services, which can provide users with personalized and accurate information by analyzing users’ behaviors. Traditional recommendation methods are roughly divided into three categories: collaborative filtering (CF)-based [11], content-based [24] and hybrid-based [27]. User item interaction data can be explicit feedbacks (ratings, reviews, etc.) or implicit feedbacks (browsing, click, etc.). CF-based recommendation methods need to utilize historical interactions to construct and factorize the interaction matrix, obtain the latent features of users and items, and then predict and recommend [40].
In recent years, graph learning (GL) methods have developed rapidly and have showed good application prospects [8]. It is an emerging artificial intelligence technology, which is essentially a machine learning method based on graph-structured data. Wang et al. [33] deeply researched and summarized the application of graph learning methods in recommender systems. Most of the data in recommender systems is in the form of graph structure, such as users’ ratings (or clicks) data on items and attribute information between users (or items) is essentially a bipartite graph. These latent features of data determine the complex relations between objects (users and items) and should be considered when designing recommendation algorithms. As one of the most promising ML methods, graph learning methods have natural advantages in learning complex relations between objects and have shown great potential in the ability to acquire knowledge from various graph structure data. For example, graph learning methods represented by random walk [23], graph representation learning [19], and graph neural networks [41], which have been widely used to learn specific types of relationships on graph structure data effectively. Therefore, it is natural and sensible to apply graph learning methods to the field of recommender systems.
Graph neural networks (GNNs) [5, 34] technology has stimulated strong interest in academia and industry in recent years, which can better combine node information with topology structure. Due to the excellent performance of GNNs in processing graph structure data, GNNs have been widely used in many field [16, 25, 38, 42, 43, 44], such as knowledge graph, recommender systems, CV, NLP and social networks. Graph neural networks with good interpretability and superior performance have become a popular graph analysis method and have broad research prospects. In addition to the problem of data sparseness, the following challenges still exist: how to learn users’ latent preferences on items effectively and how to extract latent embeddings from interactions history and side information (e.g., social relations or item attribute). Since most data in recommender systems are essentially in the form of graph structures, and GNNs have great advantages in graph structure data and representation learning.
Although graph learning technology has made some progress, how to apply it to recommender systems is still a hot research topic, and how to utilize different heterogeneous graphs to construct a unified model to extract the users’ preferences is still under explored.
Heterogeneous information graph.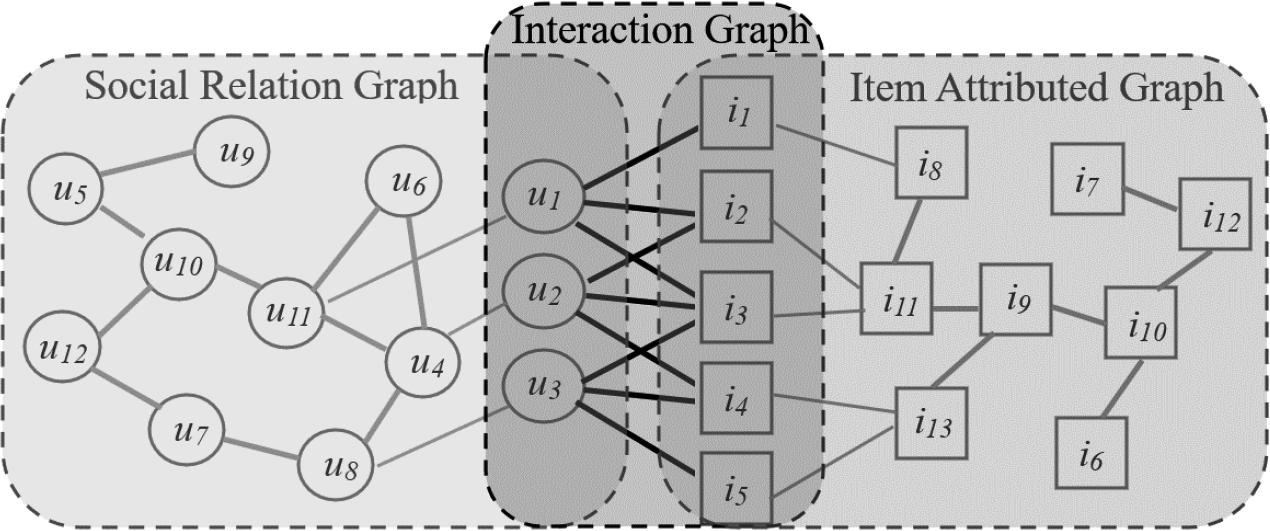
To sum up, in order to achieve an efficient personalized recommender system, this paper mainly integrates graph neural networks into recommender system application scenarios for research. This paper aims to solve some key problems encountered in traditional recommender systems: cold start (user cold start and item cold start) and data sparsity problem (user interaction data about items is very sparse), and integrate heterogeneous information (user social relations, and correlation information between items) into recommender system to improve recommendation performance, as shown in Fig. 1.
To better tackle these problems, we aim to construct a novel heterogeneous information fusion-based graph collaborative filtering method, which fuses heterogeneous information with user item interactions to enhance recommendation accuracy. The major contributions are as follows:
We construct a new heterogeneous information fusion-based graph collaborative filtering method, which integrates social information (e.g., friend or colleague) and item attributed information (e.g., price or category) with interaction information (e.g., ratings or clicks) to learn latent embeddings effectively and accurately. Social information can better model users’ preferences by diffusing social influence, and item attributed information can help better inference users’ preferences by diffusing item attribute relation. We adopt information propagation and aggregation to integrate heterogeneous information with interactions to extract the latent embeddings, which can greatly enhance recommendation performance. We conduct empirical analysis on different datasets and compare to different variants of our proposed framework. Extensive results verify the effectiveness of our proposed framework.
The remainder is organized as follows. Section 2 gives related literatures to our work. Then, Section 3 describes our proposed framework completely. Next, Section 4 conducts extensive experiments. Finally, Section 5 gives conclusion with future directions.
In this subsection, we give some related literatures to our work: network representation learning, social recommendation and graph neural network.
Representation learning-based recommendation
Network representation learning is an important research field and branch of graph data mining and complex network analysis. It has developed rapidly in recent years and has also been favored by many researchers in the field of recommendation. Recommendation based on network representation learning has become an emerging research direction [3]. Most traditional recommendation methods generate recommendations based on user-item interaction data, item features and other factors such as time, location, etc. [28]. CF-based or content-based recommendation methods can perform general recommendation tasks, hybrid recommendation methods integrate multi-source heterogeneous side information to alleviate the problems of cold start and matrix sparse to a certain extent.
The essence of network representation learning is to map the network nodes to a low dimensional vector space while maintaining the node topology [31]. Many works have shown that recommendation results based on network representation learning have significant improvements over traditional models. At present, recommendation methods based on network representation learning mainly include: factorization machine model [35], tree model for recommendation [45] and deep learning models [39]. For instance, RNN to model user interaction sequences for sequential recommendation [20]; CNN to model user latent preferences, which treats user interaction data or features as images [13]; GNN to build and propagate information in the graph to get node embeddings for recommendation [17, 26].
Social-based recommendation
Social based recommendation methods utilize the user’s social relationships, which can reduce the sparsity of user behavior by using the preferences of neighbors of users and learn more accurate user preferences. Social recommendation [15, 32] refers to obtaining social behavior data from social networks, social media, personal blogs, online communities and other media, then integrating social behavior data with user’s historical ratings into recommender systems to generate recommendation results.
TrustSVD model proposed by Guo et al., which introduced explicit and implicit influences of user trust [6]. The model is based on the classic recommendation method SVD
GNN-based recommendation
In recent years, graph neural networks have shown superior performance on graph learning tasks and have been studied from the aspects of theory and application. Traditional deep learning-based algorithm has made great progress and application in extracting data features in Euclidean space, and many researchers have proposed algorithms based on deep learning, such as: DeepFM [7], CDL [36], AutoRec [29], etc. But the complexity of graphs makes traditional deep learning algorithms unable to learn graph representations efficiently, the key points of graph learning is how to describe graph topology and node attribute in the form of vectors.
GCN [16] proposed to use graph structure information for node representation learning. This method adopted multilayer graph convolutional network for information propagation and made a breakthrough in the semi-supervised graph learning task. GCN assigns the weight of edge based on the outdegree and indegree of node in the graph. GAT ı4 model proposed multihead self-attention method to give different weights to different edges, which input the representation vector of any two nodes to calculate the weights of edges according to the self-attention network. LightGCN [9] only uses the aggregation operation of traditional GCN, linearly propagates on the interaction graph to extract the latent embedding of nodes, then fuses the vectors of all layers to get the final featrues for recommendation, thereby reducing the complexity of the model. In 2017, Berg proposed GC-MC model(graph convolutional matrix completion) [1], which regards users and items as nodes, and rating information as labels on the interactive edges. The model transformed the prediction task into link prediction task and constructed graph AE-based recommendation method. In the encoder, adopted GCN to aggregate neighbor information of nodes and in the decoder predicted the edge labels.
Methodology
In this subsection, we present details of our framework and describe the process of fusing different heterogeneous information. Then, we give the complexity analysis.
Model overview
In our model, there are three heterogeneous information, i.e., rating information, social information and item attribute information. Let
Then, three heterogeneous information graphs can be defined as follows:
We formulate the task as: given different heterogeneous graph
The overview of framework.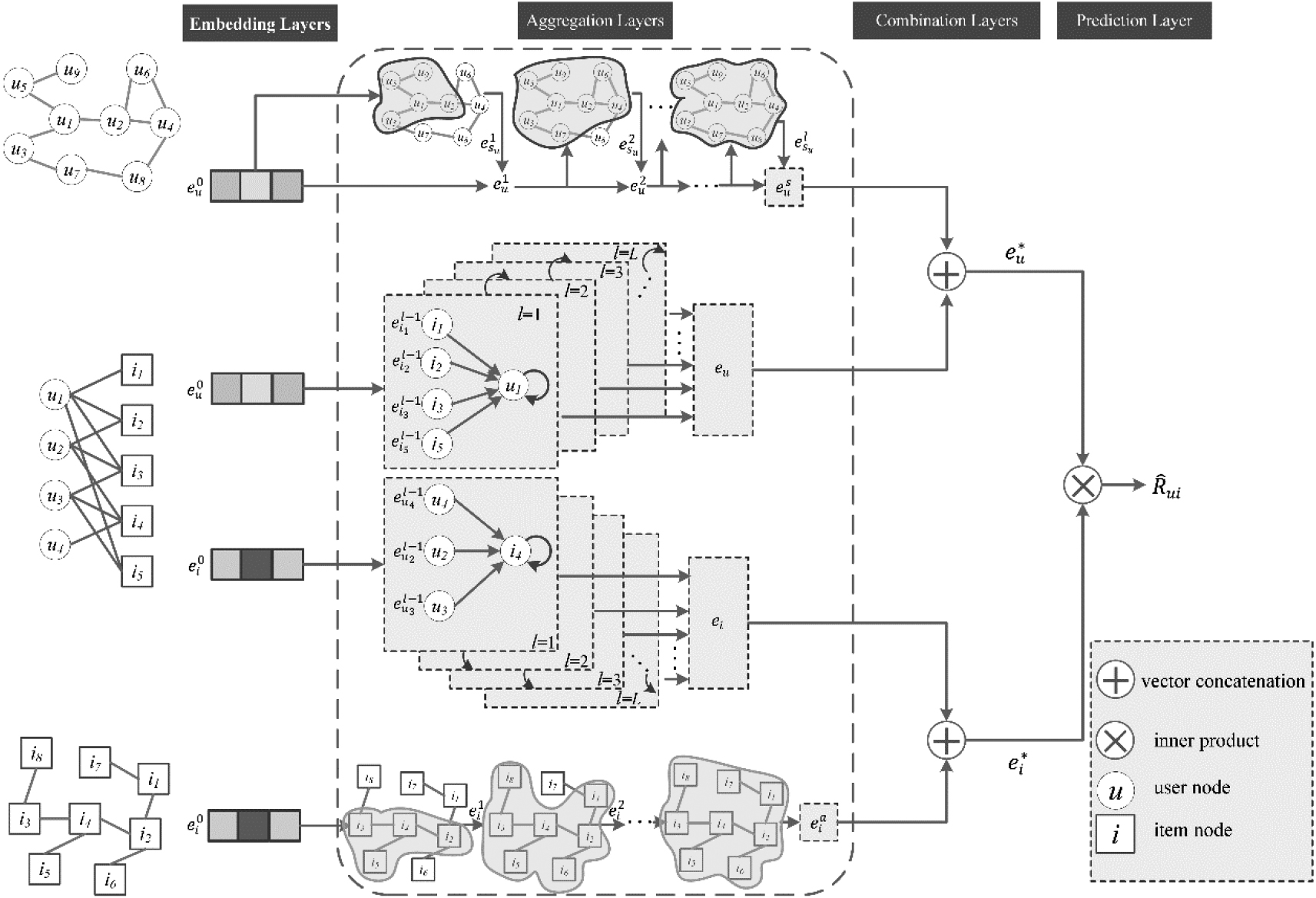
Here, we present the model framework, which is shown in Fig. 2. The proposed model consists of four main parts: 1) embedding layer, its main function is to parameterize each node while maintaining the topology of graph; 2) aggregation layer, which updates node representation by propagating embeddings from its neighbors. In this component, three aggregations are adopted to extract the latent embeddings from three different graphs, respectively. The interaction graph aggregation can be used to extract the latent embeddings of users and items from the interaction graph, the user social graph aggregation can be used to extract the latent embeddings of users from the user social graph and the item attributed graph aggregation can be used to extract the latent embeddings of items from the item attributed graph. 3) combination layer, which combines the final latent embeddings together, i.e., fuses the latent embeddings of users and items from different heterogeneous graphs to get the final latent embeddings of them; 4) prediction layer, its main function is to predict the rating of a user-item pair.
We convert the ID embeddings of user
Aggregation layer
Interaction graph aggregation
Generally speaking, graph data have node features and structural features, and need to consider both node information and structural information. Graph convolutional network can automatically learn not only node features, but also the association information between nodes. The core idea of graph convolution is to use “edge information” to “aggregate” “node information” to generate a new “node representation”. We can define the aggregation as:
Where
In the graph
Where
Then we can get the representations of user and item by propagating message from their neighbors. The process can be defined as:
Where
Then, we stack more embedding propagation layers so that messages can be continuously propagated from higher-order neighbors, the representations of user
Where
In different propagation layers, the representations of user and item emphasize messages passed through different connections, and contribute different on user’s preference. After
According to the common sense of sociology, the interests and hobbies of users are usually directly or indirectly influenced by their friends, and at the same time, the interests and hobbies of friends are also directly or indirectly influenced by them. Therefore, users want to propagate their preferences, and diffuse their latent preferences to their friends. In social graph, we also adopt graph convolution network to model the influence diffusion effect for user embedding modeling.
We use social information to model user embeddings, defined as:
Where
Then, we concatenate the embedding of
Where
Through the layer-wise GCN operation, we simulate the social relationship diffusion process of user preferences in the user social graph and obtain the user’s final embedding.
In item attributed graph, some items belong to the same categories or price, and so on. It means they are similar or related to each other. For example, a user who likes Huawei notebooks may also like Huawei mouse because these items have common attributes. Thus, the relations between items can provide more information to enhance the items’ latent embeddings.
We also adopt aggregation operation to learn the item’s latent embedding from similar or related items, defined as:
Where
Then, we obtain the final embedding of item, defined as:
Where
Given these different representations of users and items from different perspective, i.e.,
We obtain the final latent embeddings of users and items by embedding propagation and aggregation, then adopt inner product to make predictions of users on items, defined as:
We concentrate on the implicit feedbacks of users, so adopt pair-wise BPR loss as objective function to learn the model parameters. The core idea of BPR loss is that observed user-item pair should have higher predicted values than its unobserved counterparts:
Where
We adopt dropout method and adaptive momentum to optimize the model and update the parameters. In the training process, it drops out some messages and nodes randomly and only updates some of parameters.
Next, we present the complexity analysis. In three heterogeneous graphs, the main computational loss is the aggregation process. Given m users and n items, assuming the number of edges are
Experiment
In this subsection, to validate the overall effectiveness of our proposed framework, we conduct a series of experiments. Firstly, three different datasets are introduced, and then the evaluation metrics and comparison algorithms are given. Finally, the experimental results and analysis are presented.
Experimental settings
Datasets
We select three different dada sets to validate the effectiveness of our framework. Table 1 shows the statistics of three datasets.
Statistics of Epinions, Yelp and Ciao, where rating density and social density are calculated by using #ratings/(#users
#items) and #social relations/(#users
#users), respectively
Statistics of Epinions, Yelp and Ciao, where rating density and social density are calculated by using #ratings/(#users
Ciao is a consumer review website with social network, which users can rate, comment on products and make social relationships with each other. The dataset contains 7,317 users and 104,195 items, with a total of 283,319 user ratings and 111,781 social connections. The density of ratings and relationships are 0.037% and 0.21%, respectively.
Epinions is a review website, which users can make ratings and social relationships. In order to add reviews, users can register and post their own comments on products, movies or other users’ reviews. Each user maintains a “trust” list and a “distrust” list, which shows social information between users. According to social information, the website can rank users’ comments on items in a certain order, so that the opinions expressed by the most trusted users will be ranked first. In this experiment, the social trust relationships are used, and distrust relationships are ignored. The dataset contains 18,202 users and 47,449 items, with a total of 298,173 user ratings and 355,813 social connections. The density of ratings and relationships are 0.035% and 0.041%, respectively.
Yelp is the largest review website in the United States. It provides users with review services for restaurants, hotels and travel. Users can rate and comment on businesses through the Yelp website. The Yelp dataset collects users’ ratings, comment records and users’ social relationships. The dataset contains 17,237 users and 38,342 items, with a total of 185,869 user ratings and 143,765 social connections. The density of ratings and relationships are 0.048% and 0.028%, respectively.
In order to better evaluate Top-k recommendation quality of our framework, we adopt the commonly used protocols: NDCG@k, HR@k and Recall@k. The former measures the position of items which user prefers in the ranking list, the latter measures the number of items which user prefers in the ranking list. To better prove the performance of our framework, we add another metric Recall@k to measure Top-k recommendation quality, which refers to the proportion of samples with positive prediction and correct classification to the positive category, mainly measuring the ranking performance of model. The larger values of metrics indicate better performance. For each user, we randomly select 100 samples as negative and combine with the user’s positive samples to calculate the evaluation metrics.
Baselines
To verify the performance of our framework, we consider the following compared baselines:
BPRMF [30]: it proposed by Steffen et al., which adopts BPR loss to optimize MF. MF is a frequently adopted collaborative filtering method. SoREC [21]: This method is a PMF model designed by Ma et al. it decomposes user social information data and user item interaction information data at the same time and shares the user’s latent preference features. TrustSVD [6]: This method proposed by Guo et al., which uses direct social information data to mine the latent preference features of different users. It is an extension of SVD TrustMF [2]: It is based on SoRec proposed by He et al., which uses user social information to model and sharing users’ latent preference features from the perspectives of trusters and trustees. NFM [10]: It is a hybrid recommendation method, which combines user feedback information and item content information. It integrates user implicit feedback information and item content information through factorization machine and neural network. NEUMF [37]: It is proposed by He et al., which uses neural network to extract the latent features of historical interactions. ContextMF [22]: It is a collective MF method, which combines social information and context information to recommend.
The dimension of embedding is set to the value of {16, 32, 64, 128, 256}, the learning rate is set to 0.001 and mini-batch size is set to 1024. The depth of neural component layer and regularization coefficient are set to three layer and 1e-4, respectively. We adopt early stopping strategy and Adam optimizer. The parameters of comparison methods are tuned to achieve optimal performance in the corresponding papers.
For these three datasets, we select items with more than 2 rating records, select users with more than 2 social connections and 3 rating records, and removed users and items with no rating records or social connections. We randomly sample 80% for training, 10% for testing and 10% for validation.
Experimental results
Overall performance
To verify the performance of our framework, we compare it with baselines. Experimental results as shown in Fig. 3. In this experiment, Top-K is set to {5, 10, 20, 30} and the dimension of embedding is set to 64.
From Fig. 3, We have the following observations:
BPRMF only uses the user item interactions to factorize and adopts inner product to recommend, ma The social-based methods (SoREC, TrustSVD and TrustMF) utilize social relationships as side information to reduce data sparsity and enhance the effectiveness of feature extraction. Therefore, the recommendation performance is better than BPRMF. SOREC and TrustMF are based on MF method, while TrustSVD is an extension of SVD Although NEUMF only uses user-item interactions for recommendation, because NEUMF adopts neural networks to model user-item interactions, it performs better than SoREC, TrustSVD and TrustMF, which is due to the strong modeling ability of neural networks. NFM is a hybrid recommendation method, which combines user’s implicit feedback information and item’s content information through factorization machine and neural network, so it achieves better performance than NEUMF method. ContextMF is a collective MF method, which combines social information and context information to recommend. Copared to other baselines, the performance of it achieves best. On three different datasets, our framework outperforms other baselines and obtains the best results, which demonstrates the importance of mining higher-oder user social relationship and item attribute information, e.g., comparison results on SoREC, TrustSVD and TrustMF on Epinions dataset, the NDCG@20 of our proposed model improved 21.72%, 13.87% and 16.66%, respectively. Compared with the optimal results of NFM and NEUMF on Ciao dataset, the NDCG@20 of our proposed model improved 10.94% and 12.21%, respectively. Compared with the strongest baseline ContextMF method on Yelp dataset, our proposed model obtains improvement of 18.34% on NDCG@20. Our proposed model can learn more accurate latent embedding by information propagation and aggregation. The effective use of information propagation and aggregation demonstrate more important for the sparsity of user item interatciton.
Performance comparison on three datasets.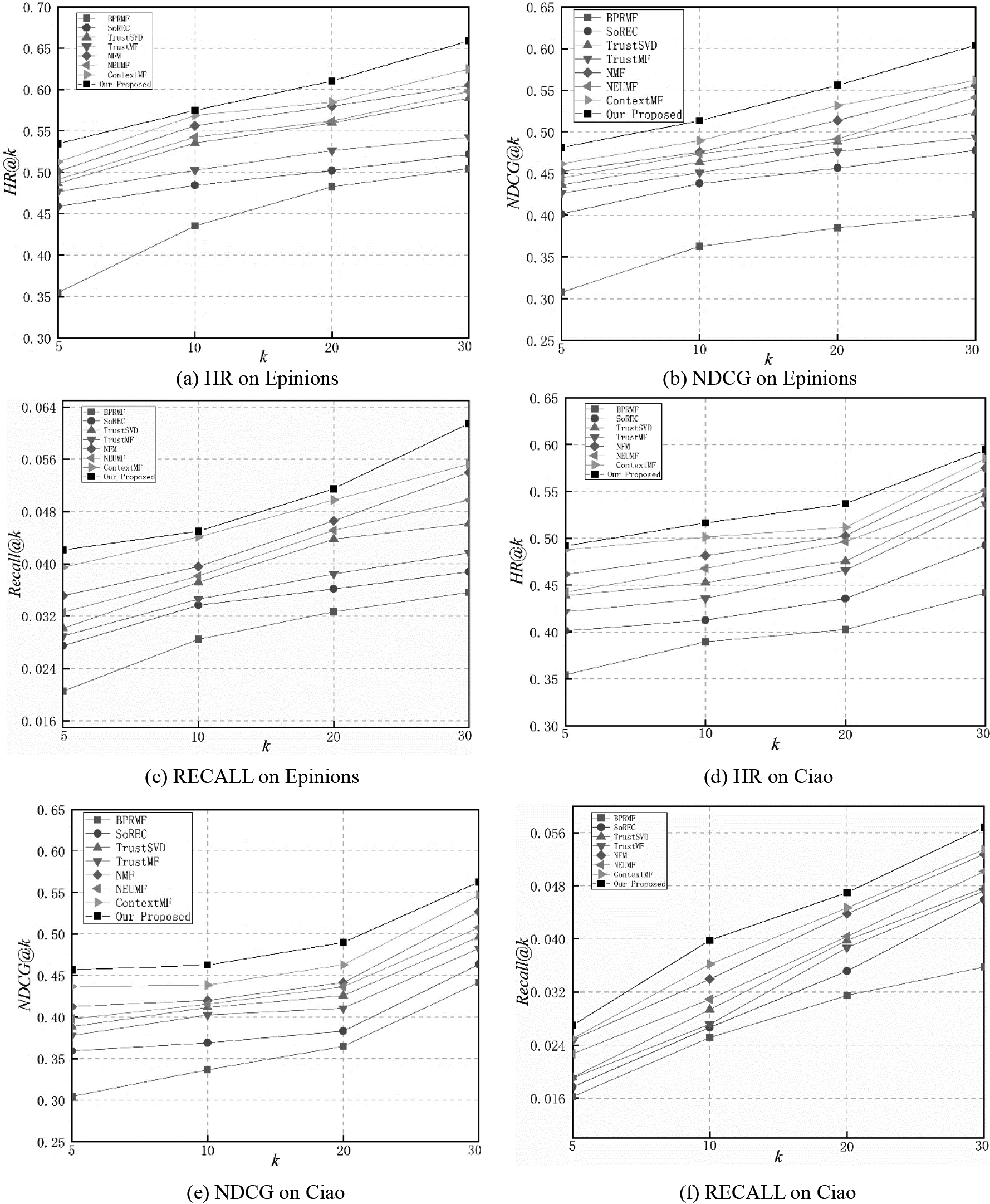
Continued.
In this subsection, we conduct comparative experiments with the proposed model and its variants. Our proposed model mines information from different heterogeneous graph. To fully compare the impact of different heterogeneous information, we set up three variants of our proposed model, defined as follows:
w/o I: it removes the item attributed graph from our proposed model. w/o S: it removes the user social graph from our proposed model. w/o S&I: it removes both user social graph and item attributed graph, which is equivalent to graph convolution network which only captures higher-order user item information.
We conduct experiments on three different datasets, the experiments results as shown in Fig. 4. In this experiment, K is also set to {5, 10, 20, 30} and the dimension of embedding is set to 64.
Effect of different heterogeneous information on three datasets.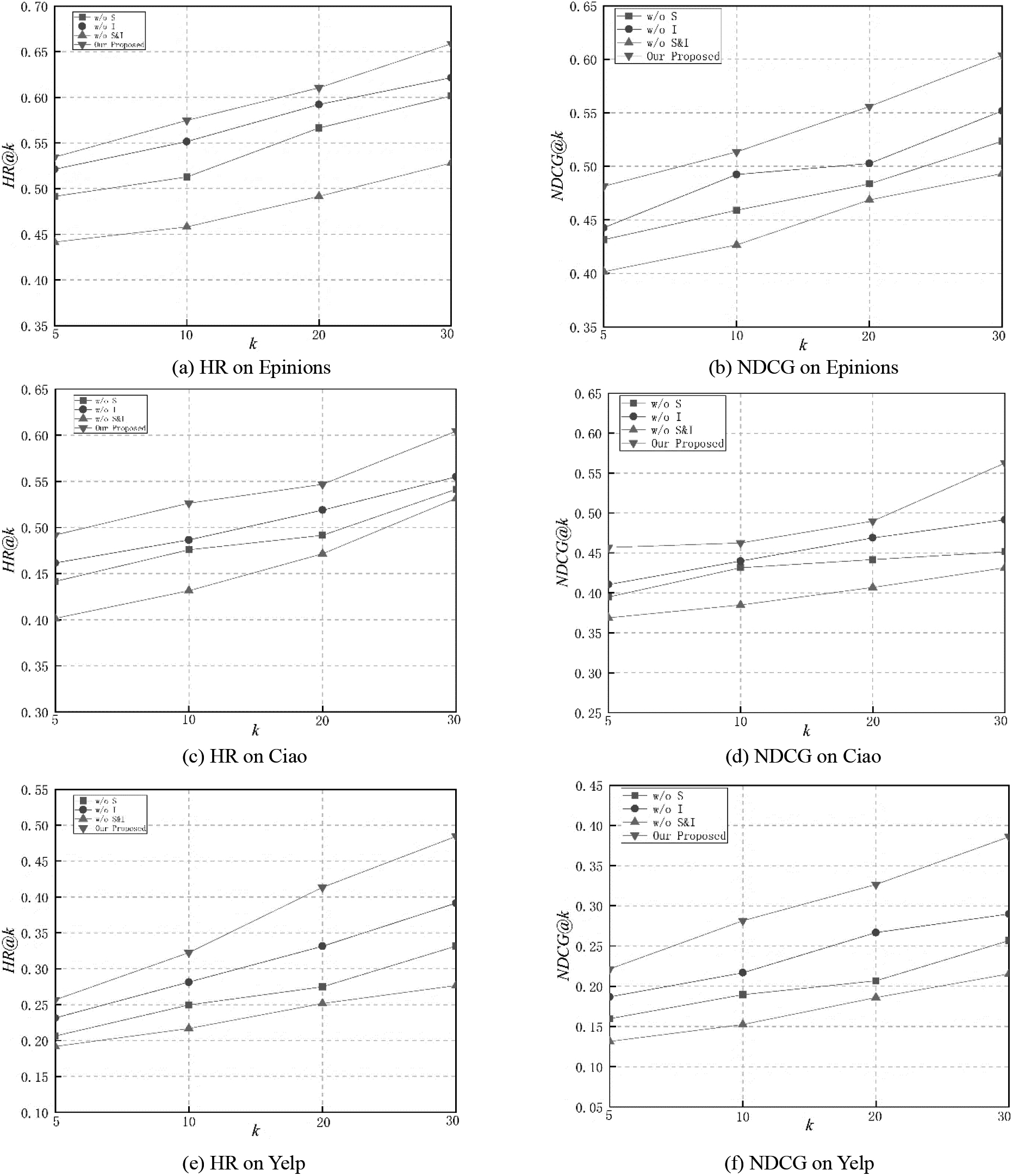
Effect of embedding size on three datasets.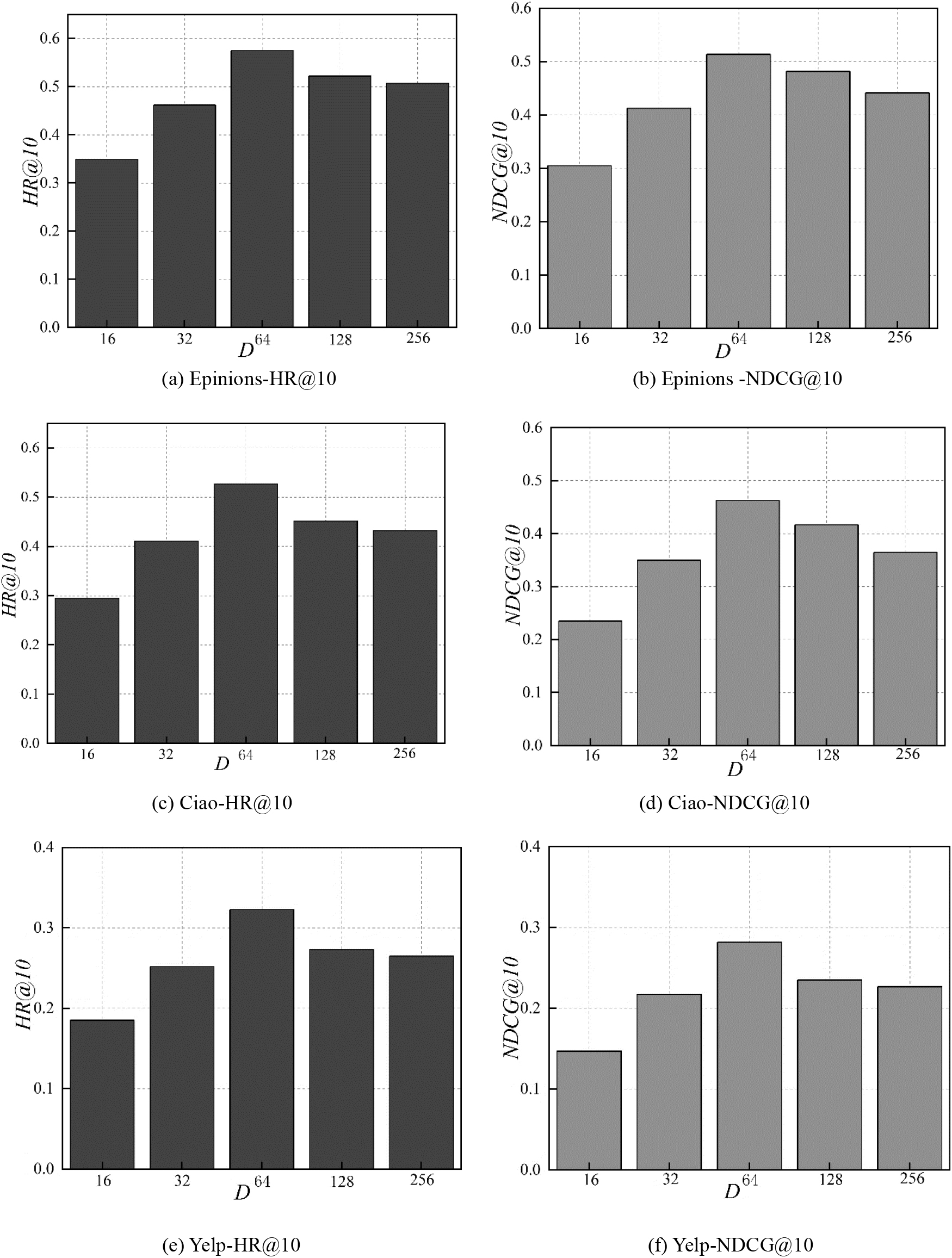
Effect of regularization coefficient 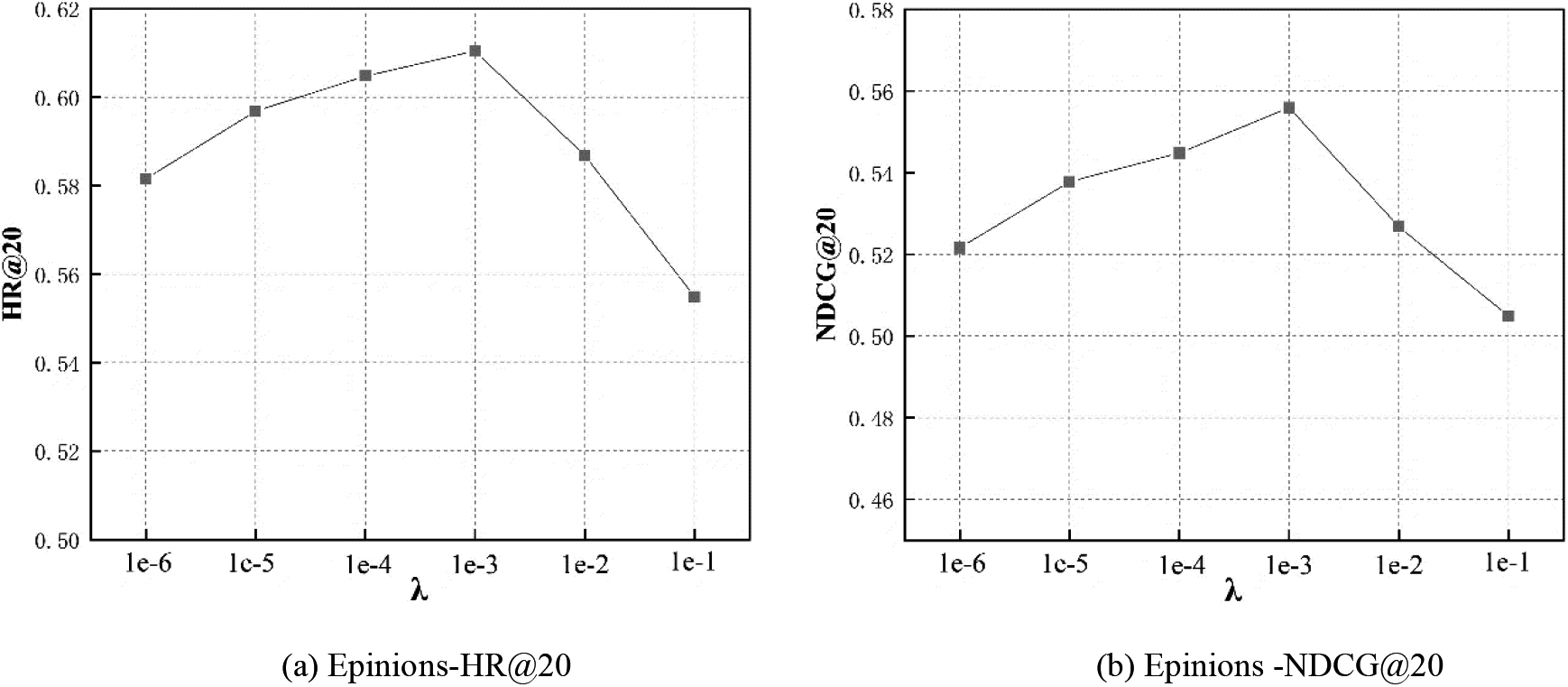
From Fig. 4, we can find:
Our proposed model consistently achieves better performance than its variants, which indicates that our model integrate social graph and item attributed graph can better extract user and item latent embeddings, therefore enhance the performance of recommendation, e.g., comparison results of w/o S, w/o I and w/o S&I on Ciao dataset, the HR@10 of our proposed model improved 10.61%, 8.2% and 21.99%, respectively. w/o S&I variant performs worst in all comparions, which demonstrates the importance of fusion different information, and verifies the different information have different impact on extracting embeddings and improving the accuracy of recommendation. w/o S is slightly worse than w/o I in all datasets, which indicates that social graph has more useful information in exatracting user latent embeddings and boosting the recommendation performance, e.g., comparison results of w/o S variant on Yelp dataset, the HR@10 of w/o I variant improved 12.69%. w/o I variant performs worse than our proposed model, but better than the other two variants, which means that the attribute information of item play a smaller role in extracting users’ latent preferences for the item compared with the other two variants. After removing the item attributed information, the recommendation performance has little impact, e.g., comparison results of w/o I variant on Epinions dataset, the NDCG@10 of our proposed model improved 4.29%.
In this subsection, we conduct comparative experiments on the impact of embedding size. we conduct experiments on dimensionality D of embeddings on three datasets. In this experiment, K is set to 10. As shown in Fig. 5.
From Fig. 5, we can find:
Firstly, the embedding size has a certain impact on the recommendation performance, with the increasing of dimension, the performance of recommendation first increases and then degrades. Secondly, with the dimension increases from 16 to 64, the predictive accuracy increases significantly, and achieves the best performance when the embdding size is 64. Then with the dimension increases from 64 to 256, the performance of recommendation degrades. It indicates that a large dimension has a good performance. However, if the dimension is too large, the complexity of the model will increase, thus reducing the recommendation performance. Therefore, we need a suitable dimension to balance performance and complexity.
In this subsection, we make comparative experiments on the impact of regularization coefficient. we conduct experiments on regularization coefficient
From Fig. 6, we can find:
Firstly, our proposed framework is relatively sensitive to the regularization coefficient, with the increasing of Secondly, with
In this work, we presented a new heterogeneous information fusion-based graph collaborative filtering recommendation, which extracted the embeddings from social graph, historical interaction graph and item attributed graph, respectively. Through information propagation and aggregation, our model can obtain the embeddings of users and items effectively and enhance the performance of recommendation. Firstly, we adopted graph convolution network to catch the latent relations from historical interaction graph. Then we modeled influence diffusion effect for user embedding from user social graph to enhance the user’s latent factors and modeled the item’s latent embeddings by aggregation operating to enhance item’s latent representations. Finally, we conducted different comparative validations on three different datasets, and comparison results demonstrated the excellent performance of our framework.
In future work, we plan to utilize more heterogeneous data to learn the latent preferences of users, such as review information or sequential information and so on. In addition, group recommendation is a trend in the development of recommender systems. How to analyze complex group relationships, group scenarios, group preferences, and build a more accurate and intelligent group recommendation model will be the future research direction. Finally, our framework assumes that the user’s preference is invariable and static, but with the change of time, the user’s preference will shift. How to model dynamic graph to enhance the accuracy of recommendation, and increase user’s satisfaction and experience will be another future research direction.
Footnotes
Acknowledgments
We thank the anonymous referees for their helpful comments and suggestions on the initial version of this paper.