
Abstract
Graph Convolutional Network (GCN) is an important method for learning graph representations of nodes. For large-scale graphs, the GCN could meet with the neighborhood expansion phenomenon, which makes the model complexity high and the training time long. An efficient solution is to adopt graph sampling techniques, such as node sampling and random walk sampling. However, the existing sampling methods still suffer from aggregating too many neighbor nodes and ignoring node feature information. Therefore, in this paper, we propose a new subgraph sampling method, namely, Similarity-Aware Random Walk (SARW), for GCN with large-scale graphs. A novel similarity index between two adjacent nodes is proposed, describing the relationship of nodes with their neighbors. Then, we design a sampling probability expression between adjacent nodes using node feature information, degree information, neighbor set information, etc. Moreover, we prove the unbiasedness of the SARW-based GCN model for node representations. The simplified version of SARW (SSARW) has a much smaller variance, which indicates the effectiveness of our subgraph sampling method in large-scale graphs for GCN learning. Experiments on six datasets show our method achieves superior performance over the state-of-the-art graph sampling approaches for the large-scale graph node classification task.
Keywords
Introduction
In recent years, graph representation learning [1, 2, 3] has received growing attention in machine learning. Graph Neural Network (GNN) [4, 5, 6] has achieved great success in various classification tasks on graph data. Graph Convolutional Network (GCN) [7, 8] extends the classic Convolutional Neural Network (CNN) to graph-structured data. Note that CNN can deal with regular data, such as images and text, but fails to handle graph-structured data, e.g., social networks. Recently, many works [9, 10, 11] have studied the GCN for graph-structured data. Graph convolution is essentially different from conventional convolution. To be specific, the GCN updates the representation of the current node by aggregating the information of its neighbor. For example, Kipf et al. [12] used a convolution-like operation to aggregate features of all adjacent nodes of each node and performed linear transformations to generate a new feature representation of each node. However, most existing methods have focused on shallow-layer GCN and small-scale datasets. Scaling GCN to deeper layers of GCN is very challenging in large-scale graph data learning. The main problem is the neighbor explosion phenomenon when aggregating the node information, which makes the algorithm complexity high and the GCN training time too long.
Many graph sampling algorithms [13, 14, 15] have been proposed to reduce the training cost of GCN, such as node sampling, layer sampling, subgraph sampling, etc. Specifically, Hamilton et al. [16] proposed a node-wise sampling method, and Zou et al. [17] proposed a layer-wise sampling approach. However, the neighborhood expansion problem still exists. The neighbor explosion problem means that when considering higher-order neighbors or the graph scale growth, the recursive neighbor aggregation will lead to a sharp increase in the number of neighbors. It makes an exponential relationship between time complexity and graph size or GNN depth [18, 19]. More recent subgraph sampling methods have been proposed to avoid the neighbor explosion [20, 19, 21]. Zeng et al. [20] adopted a graph-wise sampling scheme to sample subgraphs for mini-batch training. They proposed four sampling algorithms, i.e., random node-based sampler, random edge-based sampler, simple random walk-based sampler (SRW), and multi-dimensional random walk-based sampler, among which the SRW performs best in their experiments. However, the above-mentioned sampling methods did not consider the features of nodes in the design of sampling probabilities. To bridge this gap, we propose a new subgraph sampling method, namely, Similarity-Aware Random Walk (SARW)-based sampling for training GCN with large-scale graphs.
The proposed SARW sampling strategy considers the similarity between the current node and the next node using both features and degree information. In addition, the SARW merges both the similarity and dissimilarity between nodes, which can adjust the impact of similarity by a parameter
We evaluate our proposed approach on six large-scale graph datasets and explore the influence of the number of sampling nodes for model training. We also study the training time of our method and the training efficiency for different depths of GCN in our method. Experiments present that our method achieves superior performance over the state-of-the-art sampling methods. The node number change in the sampled subgraph has a smaller impact on our model than SRW within GraphSAINT, which indicates that our method is stable and effective. Our source code is available on the GitHub website.1
The main contributions of our work are as follows:
A new subgraph sampling method, namely, similarity-aware random walk (SARW), is proposed for GCN learning on large-scale graphs. In the GCN training stage, we use the mini-batch training strategy and the normalization technique to reduce the sampling bias. Under some mild conditions, our proposed sampling method, the simplified SARW (SSARW), is unbiased towards node representations for GCN training. The corresponding variance is much smaller than that of SRW in GraphSAINT. The effectiveness of our subgraph sampling algorithm for GCN learning is demonstrated from the theoretical aspect. Experiments are conducted on six large graph datasets for node classification tasks. Results show that our SARW outperforms the state-of-the-art sampling methods in F1 scores. In addition, we study the effects of both the number of nodes in a sampled subgraph and the weight
GNN has been successfully applied to various real-world domains, such as social media [22, 23], recommender systems [24, 25], text classification [26, 27], graph classification [28], node classification [29], link prediction [30], community detection [31, 32], computer vision [33], etc. GCN [29, 34] is powerful and effective in dealing with graph data, and can learn representations of nodes with desirable performance. Bruna et al. [35] first proposed the application of an improved convolutional neural network to graph data. In recent years, researchers [36, 37] have proposed some convolutional neural networks for graphs. For example, Kipf et al. [12] proposed accelerating graph convolution calculations based on Chebyshev expansion. However, these methods can only deal with relatively small datasets, which are difficult to analyze large-scale graphs. The graph sampling technique [15, 38, 39] has been designed to learn large-scale graphs with GCN. There are mainly three kinds of graph sampling methods, i.e., node-wise sampling [40, 16], layer-wise sampling [41, 17] and graph-wise sampling [18, 20].
Hamilton et al. [42] conducted graph convolutions on a part of nodes in the neighborhoods to reduce the computational burden. Node-wise sampling is conducted only on a batch of nodes instead of the entire graph. Chen et al. [43] proposed layer-wise sampling to tackle the over-expansion of neighborhoods, where the nodes in each layer are only directly connected to the nodes in the next layer. But, the neighborhood expansion problem still exists using node-wise sampling and layer-wise sampling. Therefore, Zeng et al. [44] and Chiang et al. [18] performed mini-batches from subgraphs, which were obtained by graph-wise sampling. Zeng et al. [21] designed a graph sampling method to maintain the connectivity between the mini-batch of nodes. Chiang et al. [18] performed a preprocessing step, which calculated non-overlapping clusters of a graph.
More recently, Zeng et al. [20] studied different sampling schemes for subgraphs that perform well. Moreover, Cong et al. [39] proposed a variance reduction strategy with a fast convergence speed. Hasanzadeh et al. [38] proposed a unified graph neural network architecture similar to the Bayesian GNNs. More recent subgraph sampling methods have been designed [19, 21]. Bai et al. [19] proposed a subgraph-based ripple walk training framework for the deep and large graph neural network. Zeng et al. [21] use a deep GNN to pass messages within a localized shallow sampled subgraph to improve both the GNN efficiency and accuracy. However, many works ignored the important information when designing sampling probabilities, that is, the features of nodes and common neighbor nodes. Our sampling method is more effective and stable than Zeng et al. [20]. Generally, there are two ways to learn GCN, namely, transductive learning [45, 46] and inductive learning [42, 20]. Note that our proposed SARW is suitable for both of them and uses inductive learning in this paper.
Methodology
In this section, we will introduce the proposed method in detail. We propose a novel and general random walk method SARW for GCN with large-scale graphs, and SARW has several variants according to the different parameter
The SRW method is simplistic and does not take full advantage of the node attribute information. In contrast, our proposed sampling method incorporates feature information, degree information, and common neighbor set information to design the sampling probability node expression between adjacent nodes. We also introduce a cosine function to calculate the similarity index between two adjacent nodes, which captures the similarity between nodes and describes the relationship between a node and its neighbors. During the GCN training stage, we use the mini-batch training strategy and normalization techniques to reduce the sampling bias and improve the accuracy of the training.
SARW
An example of neighborhoods of nodes 1 and 2.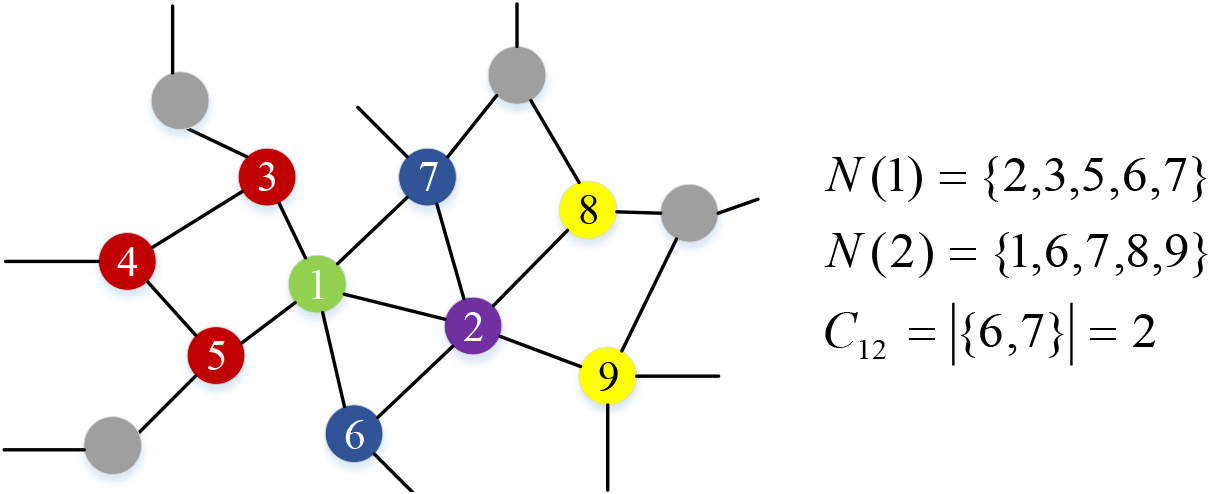
For GraphSAINT, the simple random walk (SRW) is the most effective sampling method. However, the SRW ignores the features. To alleviate the drawback of SRW, we propose a new sampling method SARW, which captures the nodes, edges, and features simultaneously. Suppose that
For SRW, nodes are uniformly sampled from the current node’s neighbors. Intuitively, similar samples with different labels are highly informative for training, while dissimilar samples with the same labels are also highly informative for training. To motivate the SARW, we describe the similarity between two adjacent nodes
where
where
where
The main advantage of Eq. (3) is that it can describe the relationship between two nodes by feature-related statistics. Furthermore, it is more flexible for considering both the similarity and dissimilarity with the hyperparameter
Case 1: For Case 2: For Case 3: If the features are missing or not considered,2
When the feature dimension is high for some graphs, the computational complexity for SARW is relatively high.
In this case, the Eq. (1) is reduced to
where
[ht] : Subgraph sampling algorithm with SARW
In Algorithm 1, we propose a novel SARW-based subgraph sampling method to perform the large-scale graph node classification task. Because the probability distribution
where
where
where
During the training stage, our model adopts the mini-batch training strategy and the normalization technique to reduce the sampling bias [20], as follows:
where
The architecture of the proposed model.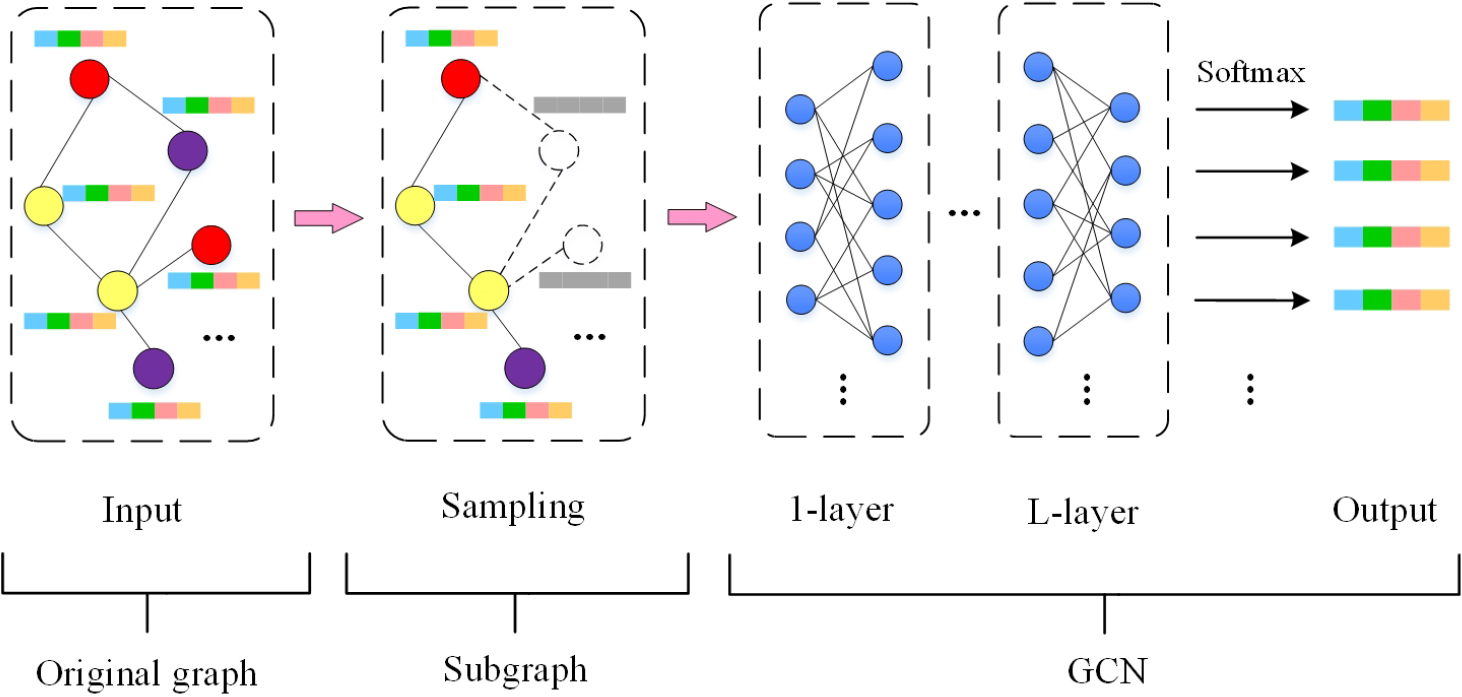
An example about SRW and SSARW.
As mentioned earlier, when the dimension of node features is high, the similarity calculation for nodes is time-consumption. Therefore, a simplified version of SARW is investigated in this subsection.
In Case 3 of SARW with
where
The SSARW has a higher probability to select the next node, which has less common neighbors with the current node and a larger degree. Figure 3a and b are diagrams for SRW and SSARW, respectively (the dark lines and nodes are sampled subgraphs). Figure 3c gives an illustrative example of a two-layer GCN on the sampled subgraph with SSARW. With the same experimental settings (the same root node size and random walk length), the length of the subgraph coming from SSARW is much longer than that of SRW. Moreover, the SRW is easy to fall into a circle and visits previously sampled nodes.
Below, we conduct mathematical analysis for SSARW based on statistical sampling theory. A random walk on a graph could be viewed as a finite Markov chain in mathematics. First, we introduce some preliminaries. Let
For SSARW, the transition matrix
where
The stationary probability of node
so
In the following theorem, we establish the unbiasedness of node representations of SSARW-based subgraph GCN learning.
.
For SSARW-based subgraph GCN learning, let
Proof..
Under the condition that
where
Then, it can be derived that
Hence,
The following Theorem 2 shows that the variance of SSARW-based subgraph GCN learning is much smaller than that of SRW in GraphSAINT.
.
For SRW and SSARW on GCN learning, if
Proof..
Let
where
So, the expectation of
Hence,
Thus, in the SSARW algorithm, the sampling variance of the representation vector
where
where
Then, we can deduce that
Hence, a larger
For SRW, the transition probability from node
It is easy to know that
(1) Case 1:
Suppose that
From assumption, we have
So, we have
Therefore,
(2) Case 2:
If
Similar, from assumption, we have
So, we get,
Therefore,
In summary, for both different cases, Theorem 2 holds. This ends the proof. ∎
In addition, we supplement the proof of the unbiasedness of GraphSAINT-SRW using the knowledge of Markov chain in statistics. By the relevant derivation of the transition matrix and stationary distribution of SRW, we obtain the Theorem 3.
.
For the GraphSAINT-SRW, the
Proof..
Let
Hence, we can conclude that
Data and settings
In this section, we evaluate both SARW and its simplified case SSARW with node classification tasks on six datasets, namely, Flickr, PPI, PPI-large version, Reddit, Yelp, and Amazon [20]. The details of the six datasets are shown in Table 1. For our multi-classification task, “s” represents that each node has a single label and “m” means multi-label. Our experiments are conducted under inductive and supervised learning. Inductive learning refers to the training set without using the information of the test set or verification set samples. Its advantage is that the information of known nodes can be used to generate embedding for unknown nodes. To evaluate the performance of SARW, we report the F1-micro score and standard deviation (std). F1-micro calculates metrics globally by calculating the total number of true positives, false negatives, and false positives, which is suitable for measuring multi-class imbalanced data. The larger the F1-micro, the smaller the standard deviation, indicating the better the model performance. Our model is implemented using Tensorflow3
The details of the experimental datasets
Similar to GraphSAINT-SRW [20], the fixed partitions of the training set, the verification set and the test set are presented in the last column of Table 1. For example, the Amazon dataset is used to classify products on the Amazon website. One node in the Amazon graph represents a product, and one edge represents that the products of two nodes are purchased by the same user. Node features include the information of all comments on the product, using word to vector technology. The label of each node represents 107 categories of products, such as books, movies, shoes, etc. In the process of training, we minimize the loss function using the Adam Optimizer with a learning rate being 0.01. We set the dropout rate as 0.1 or 0.2 (0.2 for Flickr, 0.1 for other datasets). The activation function is ReLu. The dimensions of hidden vectors for those six datasets are 256, 512, 512, 128, 256, and 512, respectively. The depth of GCN is set to 3 on Flickr, PPI-large, Yelp, and Amazon datasets. On PPI and Reddit datasets, the depth of GCN is set to 4. Each experimental result in this section is an average of five runs. For the parameters, we test multiple options and finally choose the best set of parameters. For the sampling process, the hyperparameters will be introduced in the concrete experiments. Other datasets, configurations, system specifications, and parameters are introduced in detail in the code.
To evaluate the performance of our GraphSAINT-SARW, we compare it with the following seven baselines, including
vanilla GCN [12] (2016) is a standard graph convolution neural network. GraphSAGE [42] (2017) randomly selects a fixed number of neighbor nodes for each node in a graph to aggregate information. FastGCN [43] (2018) samples a fixed number of nodes in each layer and reconstructs the graph convolution as an integral transform of the embedding function, which is faster than GraphSAGE. S-GCN [16] (2018) designs a sampling algorithm based on control variables, which allows the GCN to sample any small neighbor scale during training. AS-GCN [41] (2018) designs an adaptive layer by sampling, which can effectively accelerate the training of GCN. ClusterGCN [18] (2019) uses a graph cluster algorithm to cut the whole graph into several small clusters. During training, multiple clusters are randomly selected to form subgraphs as a batch, and then GCN is calculated on the sample graph. GraphSAINT-SRW [20] (2020) uses a simple random walk method to collect the graph from the original graph. Multiple subgraphs are sampled in advance in the preprocessing stage, and mini-batch acceleration can be carried out to improve efficiency.
The F1-micro scores of the competing methods
In Table 2, we report the F1-micro scores for all competing methods on Flickr, Reddit, PPI, and PPI-large datasets. The results of the top six methods are retrieved from published papers and we reproduce the GraphSAINT-SRW method according to their released codes. In the experiments, the similarities among nodes are calculated in advance, which does not increase the training time. The complexity of similarity pre-calculation between the current node and the next node is
Compared with the GraphSAINT-SRW, our GraphSAINT-SARW achieves high accuracy of improvement on these three datasets. Specifically, on Reddit dataset, the F1-micro score of GraphSAINT-SARW (with
The F1-micro scores of GraphSAINT-SARW without feature and GraphSAINT-SRW
Table 3 shows the experimental results of the comparison between GraphSAINT-SARW without features and GraphSAINT-SRW on six datasets. When features are not considered (Case 3), we set
In Table 4, we report the performance of SSARW and SRW with different settings on Flickr, PPI, PPI-large version, Reddit, Yelp, and Amazon datasets in Table 1. The first column of Table 4 represents the settings of the number of root nodes and the walker length. For the convenience of observation, we draw Figs 4–6, which show the trend of SSARW and SRW about F1 and std on Reddit, PPI, and PPI-large datasets. The horizontal axis of Fig. 4 is walker length when the number of root nodes is 2000. In Fig. 5, the number of root nodes is 3000, and the number of root nodes is 1000 in Fig. 6. Under some mild conditions, we can prove that the variance of SSARW can be smaller than the variance of SRW in Section 3.2. However, it is very difficult to accurately give the measure of variance reduction, and we provide some numerical results to verify the conclusion as shown in Table 4, Figs 4–6. Based on the survey results in our sample works, an increase of around 1–2% of F1-score is considered significant. As shown in the Table 4, our model outperforms the baseline models in terms of F1-score, lower standard deviation values, and shorter training time.
The comparison between our SSARW and SRW on six datasets
The comparison between our SSARW and SRW on six datasets
The comparison between SSARW and SRW on Reddit dataset.
From the results, we have the following conclusions:
For the same parameters, the SSARW has a higher F1-micro than SRW. Moreover, both the standard derivation and training time of SSARW are much smaller than those of SRW. For the fixed number of root nodes, the SSARW and SRW have better performances as the walker length becomes longer. As the total number of sampling nodes increases, the training subgraph is more close to the original graph. For the fixed number of root nodes, the SSARW is much better than SRW for a long walker length. This suggests that a long walker length has a high classification accuracy. As the number of total sampled nodes increases, the standard deviation of SSARW decreases. The standard deviation of SSARW is much smaller than SRW, and the accuracy of SSARW is higher than SRW. However, the standard deviation of SRW is unstable. This demonstrates that our SSARW sampling strategy is more reliable than SRW for the GCN training task on large-scale graph datasets.
The comparison between GraphSAINT-SARW and GraphSAINT-SSARW is presented in Sections 4.2 and 4.3. The comparison results are shown in Tables 2–4. When
The comparison between SARW, SSARW and SRW on sampling times and total training time for GCN
The comparison between SSARW and SRW on PPI-large dataset.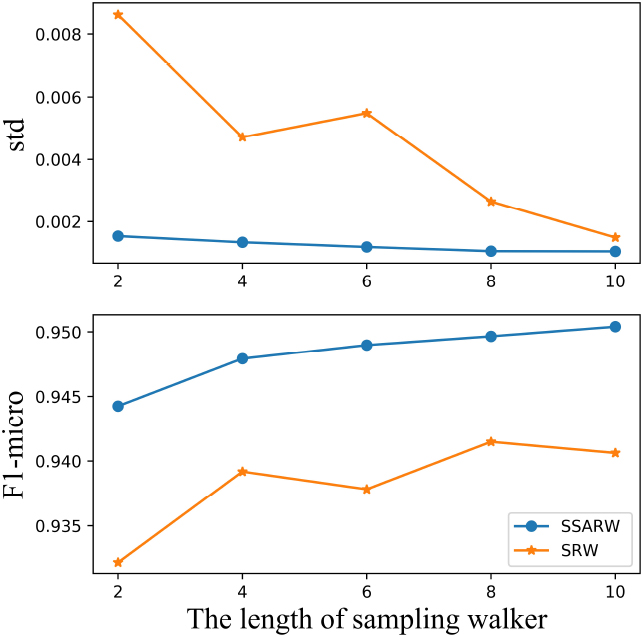
The comparison between SSARW and SRW on PPI dataset.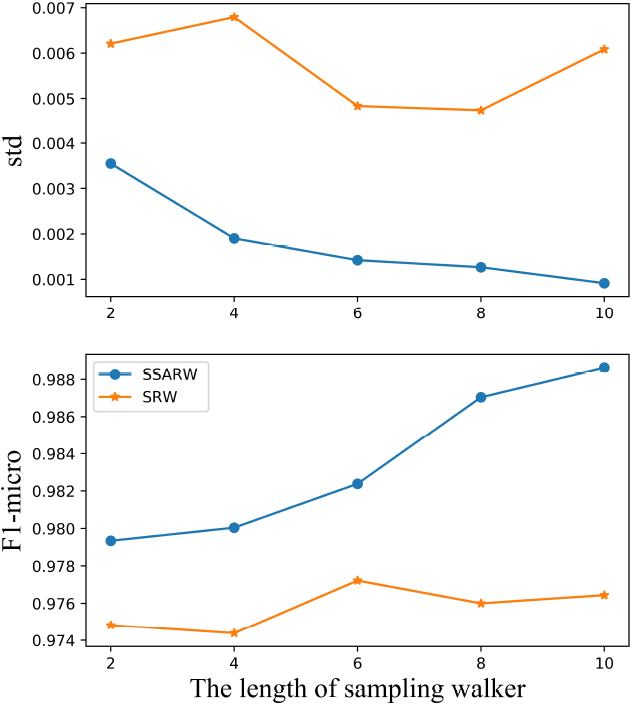
The relationship between GCN depths and training time.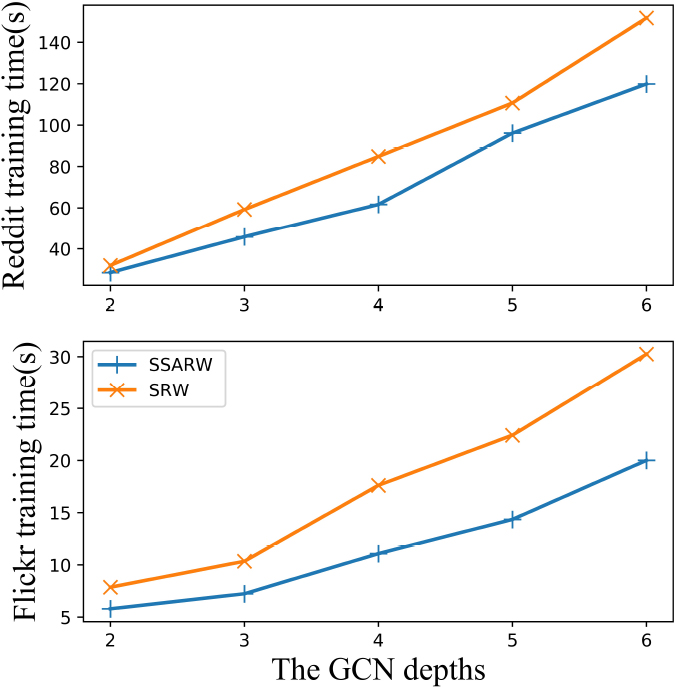
In addition, we discuss some additional experiments. The training time of the SARW and SSARW methods are shorter. In Table 5, we compare the total training time and sampling time of our methods and the GraphSAINT-SARW approach. The GCN depth and the number of root nodes are the same in Table 2. The length of the walker is set as 10. We find the sampling time of the SARW and SSARW methods are both slightly higher than SRW, which may be because our sample method requires some judgment statements and calculations. However, the sampling time of our method is still a small order of magnitude, and the sampled subgraphs can be sampled in advance without taking up training time. From Table 5, the training time of the SARW and SSARW methods are less than that of the GraphSAINT-SRW method, which shows the superiority of our method. Moreover, the training time of the SARW is shorter than the SSARW, indicating that it is useful for SARW to consider the additional information of similar nodes. The sampling time of the SARW is longer than the SSARW, which shows the computation of the SARW is more complex.
In Fig. 7, we evaluate the training efficiency for different depths of GCN. We compare SSARW with GraphSAINT-SRW training on the two large graphs (Reddit and Flickr). We increase the number of layers and measure the average time per training execution. The GCN depth is set to 2, 3, 4, 5 and 6. Other settings are the same in Table 5. From Fig. 7, the total training time of GraphSAINT-SSARW and GraphSAINT-SRW are both roughly linear relationships with the GCN depth. This alleviates the “neighbor explosion” phenomenon (i.e., when increasing the depth, the training cost of GCN increases exponentially). Moreover, the training time of our method is less than that of the GraphSAINT-SRW method on both two datasets.
Conclusion
In this paper, we propose a new subgraph sampling method, SARW, which uses the edges, features and degree information to determine sampling probabilities. Our similarity-aware random walk subgraph sampling method achieves competitive performance for GCN training on large-scale graph data. Furthermore, we implement a simplified version of SARW called SSARW, which does not consider node features. We conduct a detailed theoretical analysis of SSARW, including unbiased learning of SSARW-based subgraph GCNs and a variance analysis. Extensive experiments on public datasets demonstrate the effectiveness of our proposed approach. Additionally, we study the influence of the sampling walker length, the relationship between GCN depths and training time. We also compare the sampling time between our method and the GraphSAINT-SRW method.
Our method addresses the problem of subgraph sampling on large-scale isomorphic and static graph data, but it is not suitable for non-isomorphic and dynamic graphs. In the future, we plan to extend our method to non-isomorphic and streaming graph data. Additionally, we aim to improve the manual sampling parameters to automatic parameters.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant (No. 62172372), the Natural Science Foundation of Zhejiang Province, China (No. LQ22F020033, No. LZ21F030001), and the Exploratory Research Project of Zhejiang Lab (No. 2022KG0AN01).