
Abstract
Recently, most studies in the field have focused on integrating reviews behind ratings to improve recommendation performance. However, two main problems remain (1) Most works use a unified data form and the same processing method to address the user and the item reviews, regardless of their essential differences. (2) Most works only adopt simple concatenation operation when constructing user-item interaction, thus ignoring the multilevel relationship between the user and the item, which may lead to suboptimal recommendation performance. In this paper, we propose a novel Asymmetric Multi-Level Interactive Attention Network (AMLIAN) integrating reviews for item recommendation. AMLIAN can predict precise ratings to help the user make better and faster decisions. Specifically, to address the essential difference between the user and the item reviews, AMLIAN uses the asymmetric network to construct user and item features using different data forms (document-level and review-level). To learn more personalized user-item interaction, the user ID and item ID and some processed features of user reviews and item reviews are respectively used for multilevel relationships. Experiments on five real-world datasets show that AMLIAN significantly outperforms state-of-the-art methods.
Introduction
In recent years, recommender systems have been widely used in e-commerce platforms [1, 2], e.g., Amazon and Taobao. Traditional recommendation methods are based on collaborative filtering [3, 4], which has achieved great success, due to its simplicity and effectiveness. However, it also presents some limitations. Specifically, such methods [5, 6, 7] only make use of the user’s rating information, while it is difficult for us to provide reliable recommendations for a user or item with few ratings (cold start).
Examples of user and item historical reviews.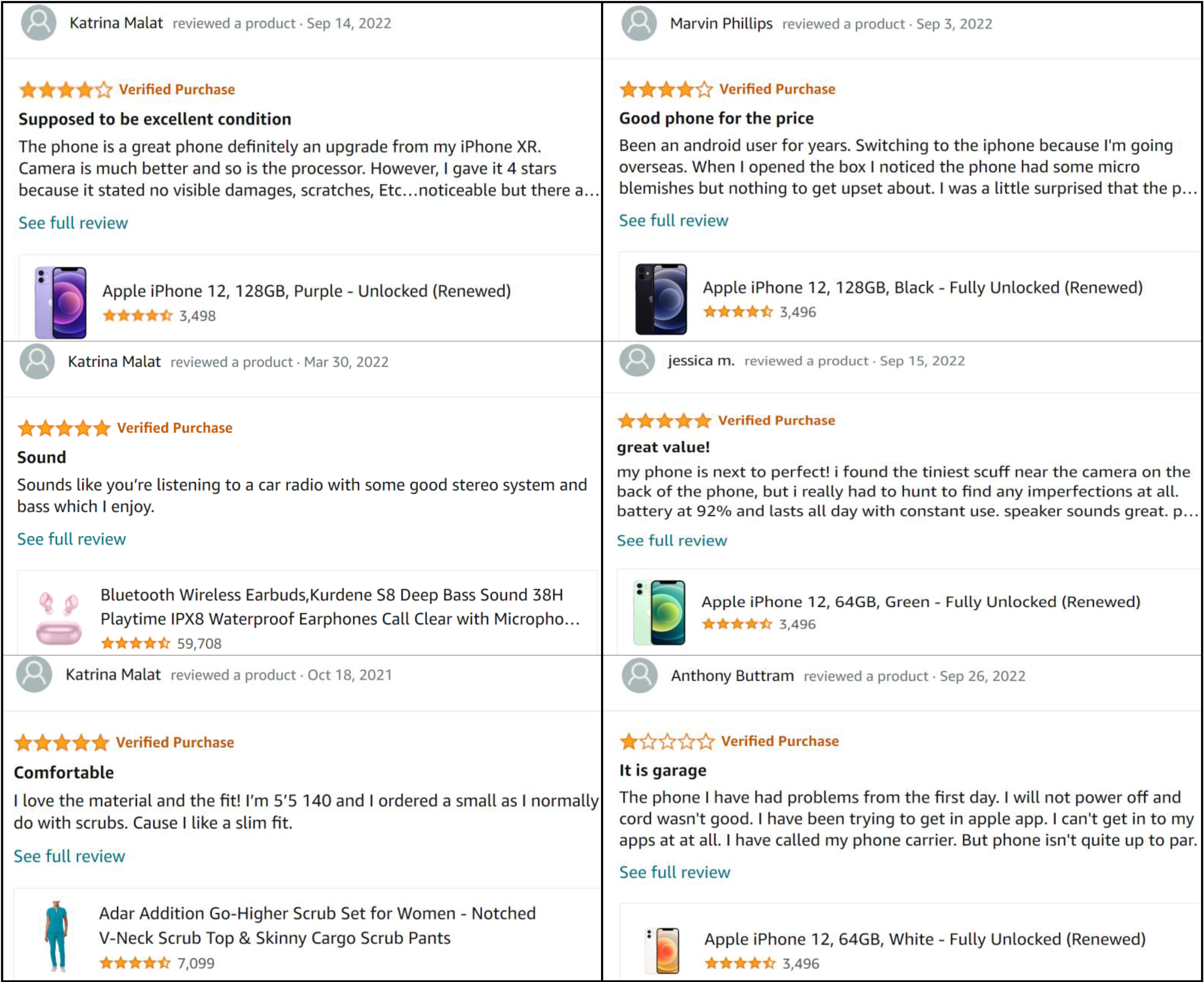
To address this problem, some studies [1, 8, 9, 10, 11] have begun to focus on the reviews written by users. Compared to ratings, the user’s reviews for the items can reflect the user’s interest intuitively and accurately on many aspects. The reviews accepted by the item are unified in the review target, which can reflect the significant attributes of the item. In Fig. 1, on the left side are a user’s reviews of a mobile phone, pair of headphones and clothes purchased. We find that users prefer items from specific brands, with high cost performance and that are comfortable (aspect features). On the right side are reviews written by several users on a specific mobile phone. System fluency, battery capacity and signal strength are found to be the significant attributes of this item. In addition, studies have proven that, especially for users and items with few ratings, using review information in recommender systems can effectively improve prediction accuracy [12, 13, 14, 15, 16].
In recent years, deep learning has made remarkable achievements in various fields, such as natural language processing. Inspired by these works [17, 18], we use the strong fitting ability of deep learning to help our recommendation task achieve better results. From the perspective of problem modeling, recent works on exploiting review information can be divided into two types [19]: those using document-level methods and those applying review-level methods. The former combine all reviews into a document before processing. For example, DeepCoNN [1] utilizes two identical convolutional neural networks (CNNs) to extract semantic features from a user and an item document, and then two features are fused to generate rating prediction. The latter model reviews separately and then fuse them. For example, NARRE [20] utilizes two same CNNs and a specific attention mechanism to extract the features of user and item reviews at the review level and integrates the features and user ID and item ID to complete the rating prediction. Although these approaches have improved the performance of the most advanced methods, some problems remain:
The types of user and item reviews are essentially different. User reviews are created by the user on a number of purchased items, which reflects the user’s wide aspect interests, and the importance of these reviews is necessarily varied. Therefore, it is appropriate to adopt review-level data and methods. Item reviews are created by different users according to the attributes of the given item, which are equal in aspect style. Therefore, it is suitable to adopt document-level data and methods. However, most works use the same data form and method to address user and item reviews, which may fail to capture more accurate user and item features. There is a lack of user-item multilevel interaction. For example, when measuring whether a user would buy a pair of headphones, we should determine the relevance of this product as indicated by the user’s reviews of digital products. Furthermore, it is necessary for each user to learn about specific multilevel (e.g., from coarse-grained colors to fine-grained price ratios) features related to the target item. However, most approaches lack consideration of multilevel interaction when capturing user and item features, which may lead to suboptimal recommendation performance.
To address these limitations, we propose a novel model, named Asymmetric Multi-Level Interactive Attention Network (AMLIAN). AMLIAN can use the user (item) review information and user (item) ID to generate more accurate prediction ratings. Specifically, the model uses an asymmetric multilevel interactive network and attention mechanisms to fuse different types of reviews and user and item IDs to achieve prediction ratings. The main contributions of this paper can be summarized as follows:
Our proposed AMLIAN adopts four attention layers. The user representation network includes a text attention layer and a review attention layer. The item representation network includes a word attention layer and an aspect attention layer. The former network is used to progressively select useful aspect features included in a single review and the useful aspect features of all reviews. The latter progressively selects useful words and aspect features at the document level. We propose a unified asymmetric multilevel interactive deep learning model that fuses ratings and reviews. The model considers both coarse- and fine-grained interactions between the user and item in constructing user-item interaction. In addition, as far as we know, AMLIAN is the first model to adopt different types of data according to the characteristics of user and item reviews. Experiments are performed on five real-world datasets, and the experimental results show that the proposed AMLIAN model achieves better rating prediction accuracy than the existing state-of-the-art methods.
Many approaches have been developed to improve recommendation performance. Our work is related to two lines of literature focused on document-level and review-level methods. Document-level methods: concatenate all user or item reviews to form a document, and then extract the features of the document as the feature representation of the user or item. Review-level methods: model each review separately first and then construct the feature representation of the user or item according to the importance of each review.
Document-level methods
Compared to review-level methods, this is a coarse-grained method. For example, D-Att [21] followed the premise that different words had different importance for modeling users and items. It introduced two word-level attention mechanisms to find more informative words. DAML [22] focused on the importance of different words and the relationship between feature interactions by using two kinds of attention, and then fed the features into neural factorization machines to generate the predicted score. ANR [23] used user and item documents to model the features of a user and an item from aspect perspectives using a coattention mechanism. CARL [24] believed that the same word had different semantic information in different contexts, so the author that paired, interrelated and dynamic features should be learned with CNNs.
However, this paradigm is not suitable for dealing with reviews written by a user. These reviews reflect a wide range of user interests. For different target items, the importance of these reviews must vary. We treat these reviews in the same way as the item, which is not conducive to the hierarchical construction of user features.
Review-level methods
Compared to document-level methods, this is a fine-grained method. For example, NRPA [25] selected different important words and reviews for different users and items through an attention mechanism. It learned the feature representation of reviews from words and users or items from reviews. TAERT [26] used a temporal convolutional network to obtain the feature representation of user and item reviews and then took advantage of three interrelated attention mechanisms to generate rating predictions and explanations. EDMF
However, this paradigm is not suitable for dealing with reviews received by an item. Because such reviews come from reviews written by different users of an item, their reviews of the item are made according to the attributes of the item. Therefore, these reviews are the same in aspect style. It is not conducive to unified construction item attributes to treat these reviews in the same way as the user.
Problem formalization
Let
Let
The AMLIAN model can be formalized as follows:
Input: The input of interaction data is the identity of users and items. We use one-hot encoded vectors
Output: The whole training process can be expressed by function:
The proposed AMLIAN model
The goal of our model is to predict a rating given a user and an item. For example, as shown in Fig. 1, the user “katrina Malat” reviewed on headphone, underwear and so on. The target item “Apple iPhone 12” received reviews from different users. We construct user feature representation according to the user review information and item feature representation according to target item review information. Then they are fused and sent to the prediction layer (NFM) to generate the prediction ratings of the target item “Apple iPhone 12” by the user “katrina Malat”. The overall architecture of our proposed AMLIAN is shown in Fig. 2. It consists of three key modules:
The AMLIAN model architecture.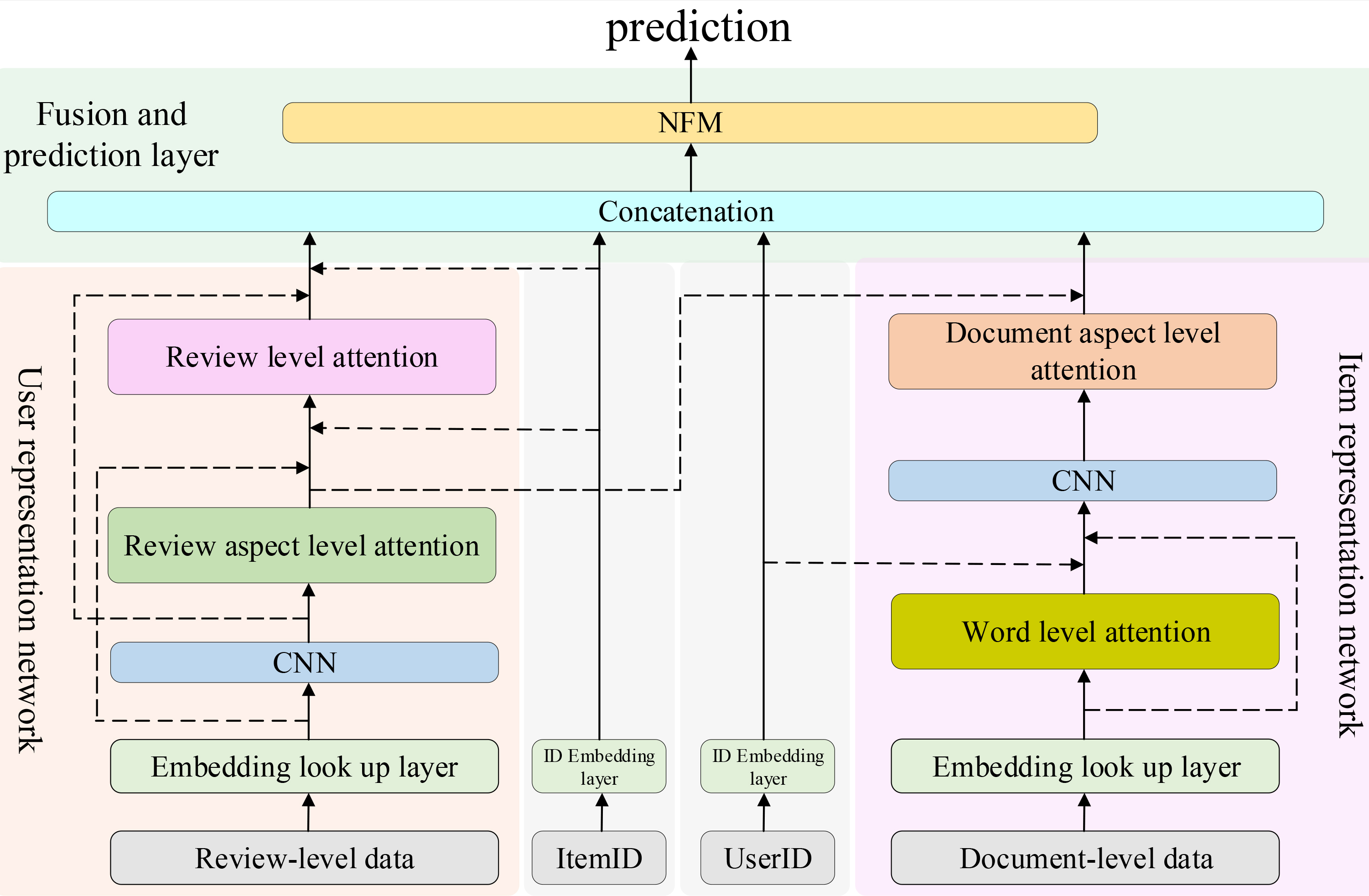
User representation network: This network uses the user’s review-level data to learn the feature representation of the user’s reviews, including the review aspect level attention layer and review level attention layer. Specifically, the review aspect level attention layer uses the attention mechanism of the item ID, the single aspect features extracted by CNNs and single review features to learn the multiaspect feature distribution weight in each user review to make it more relevant to the aspects of target reviews. According to the characteristics of the target item, the review level attention layer uses the attention mechanism of the item ID, all aspects extracted by CNNs and all review features to learn the weight distribution of all reviews of the user. Finally, according to the attention score, all features of the user are fused as the feature representation of the user. Item representation network: This network uses document-level data of the target item to learn the feature representation of the target item, including the word level attention layer and document aspect level attention layer. Specifically, the word level attention layer uses the attention mechanism of the word sequence, user ID and word set around the center word to learn the weight distribution of words in the document to make it more relevant to the user’s preferences. The document aspect level attention layer uses the attention mechanism of Euclidean distance between the fitting features of aspects of the weighted document and the fitting features of aspects of the user’s weighted reviews to learn the weight distribution of the aspect features of the target item. Finally, according to the attention score, all features of the target item are fused as the feature representation of the target item. Prediction layer: the user feature representation, item feature representation, user ID and item ID are integrated, and the feature is fed into the NFM prediction layer to generate the final prediction rating. Specifically, NFM is a classic recommendation prediction model, which introduces Bi-interaction Pooling layer on the basis of Factorization Machines (FM), so that it can deal with high-order and nonlinear features.
Review aspect level attention layer
This layer is shown in detail in Fig. 3a. The user’s interests are extensive, and the purpose of this layer is to extract the most relevant aspects of the target item from each user’s review according to the single characteristics of the target item.
Embedding look up layer
Consider review text
The architecture of four attention modules: (a) Review aspect level attention layer, (b) Review level attention layer, (c) Word level attention layer and (d) Document aspect level attention layer.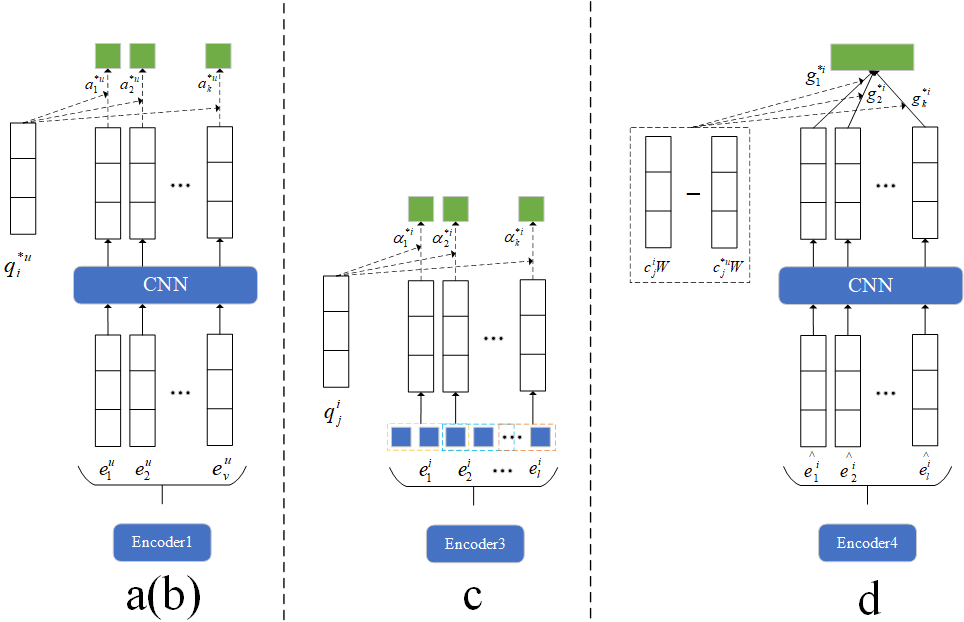
Convolution layer
We use CNNs to extract multiaspect aspects of
where
where
where
Attention over review aspect level
We obtained the aspect feature vectors of all words through CNNs. However, as mentioned above, the word aspect features in user reviews are not all equally important compared to the aspect features of the target items. Therefore, we use the review aspect attention mechanism to learn the importance distribution of the user’s aspect features according to the aspect feature of the target item. The attention weight
where
Review level attention layer
Since we have obtained the weighted representation vectors of all reviews of the user, we can now explore how to aggregate them to construct user feature representation. The reviews written by the user are varied, and they always exhibit different preferences for different items. Therefore, the importance of different user reviews to the target item varies. As shown in Fig. 3b (The structure is consistent, just remove the stars in the symbol), we propose a review level attention mechanism to learn user representation. Given review feature set
where
Word level attention layer
Inspired by the work of [9], as shown in Fig. 3c, the purpose of this layer is to better combine document-level information and filter out unnecessary words.
Embedding look up layer
Given item document text
Attention over word level
There is considerable noise in the item document set, and every word within it is not equally important. Therefore, we use the word level attention mechanism to learn the importance distribution of words according to the characteristics of the item itself and the characteristics of the user associated with the target item.
The i-th word in our word matrix
where
where
Document aspect level attention layer
An all-round search for the relationship between item aspect features and the user is helpful to build the item features that better satisfy the preferences of the target user. Since we have obtained the purified document information of the item, we can explore the relationship between the aspect features of the purified target item and the aspect features of the user’s purified review information, as shown in Fig. 3d.
Convolution layer
The process is similar to that of the user convolution layer. By inputting
Attention over document aspect level
Then, we map the item and user features to the same feature space and calculate the Euclidean distance between the filtered item aspect features and filtered user features. The filtered user features are as follows:
We use
where
where
The weight distribution of the features of the
Then, we obtain the aspect-level feature
Because some users or items have few reviews, we combine the ID embedding vectors of the user and item into their final feature representation with the following formula:
where
where
where
To train the parameters of the AMLIAN model, We utilize the regression with squared loss as the objective function.
Where
For the review aspect level attention layer, the time complexity value is
Experiments
To comprehensively evaluate the performance of our proposed AMLIAN model, we conduct experiments to answer following question:
(RQ1) How does AMLIAN model our proposed compare to the state-of-the-art recommendation models? (RQ2) How do some model hyper-parameters affect the AMLIAN? (RQ3) How do four attention layers our proposed above affect the experimental results?
Datasets
We conduct experiments based on Amazon product data,1 including user reviews and ratings. Furthermore, we choose the 5-core version, for which all users and items have at least 5 reviews. To alleviate the long tail effect, we adopt the same preprocessing method as [20] to adjust the length of reviews. The statistical information of these datasets is presented in Table 1.
Statistics of datasets used in this paper
Statistics of datasets used in this paper
Note that we randomly divide each dataset into a training set (80%), verification set (10%) and test set (10%). The comparison results of the models come from the test set.
To evaluate the performance of the proposed algorithm, we use the mean absolute error (MAE) and mean square error (MSE) as standard metrics.
where
To evaluate the performance of the proposed model, ten baselines are selected, including two classical methods: PMF [29] and HFT [30]; three document-level baseline methods: DeepCoNN [1], CARL [24], and DAML [22]; five review-level baseline methods: NARRE [20], NRPA [25], TAERT [26], EDMF
Parameter setting
The parameters of the baseline methods are selected based on the setting strategies reported in past papers. For the AMLIAN model we propose, learning rates of [0.00001, 0.00002, 0.0005, 0.006, 0.06] are examined. The dropout ratio range is explored within [0.1, 0.2, 0.3, 0.4, 0.5] to avoid overfitting. The size of the training batch is tested within [32, 64, 128, 256], and the dimension of latent factors is changed with in [25,50,100,150,200]. By adjustment, the learning rate is set to 0.006, the dimension of latent features is 50, the batch size is 128, and its value is 64 for the word embedding size. The number of convolution filters is set to 100, and the sliding size is set to 3. The output dimension of the CNNs is set to 50. The vocabulary value is set to 50,000, the maximum length of the input text is 1,000, the regularization parameter is 0.0009, and the dimension of the latent feature for User u and Item i is set to 8.
Performance comparison (RQ1)
The performance of our proposed AMLIAN model and baselines on the task of rating prediction is shown in Tables 2 and 3. We can infer the following conclusions from Tables 2 and 3:
Performance comparison of five datasets for all methods by MAE. Boldface and underlining are used to highlight the top two results.
% indicates how much better AMLIAN performed than the best baseline. All the results are reported as “mean (
std)” across 5 random runs
Performance comparison of five datasets for all methods by MAE. Boldface and underlining are used to highlight the top two results.
Performance comparison of five datasets for all methods by MSE. Boldface and underlining are used to highlight the top two results.
PMF has the worst performance of the algorithms. The user-item interaction matrix of these datasets is fairly sparse. PMF is outperformed by HFT. The topic distribution of the user and item evaluations may have been used to identify potential features. HFT is outperformed by the majority of review-based deep learning methods. This demonstrates that reviews are a crucial information source for improving the effectiveness of recommendations. For example, DeepCoNN extracts the semantic features of review information, which helps alleviate data sparseness and generate better recommendations. Regardless of document- or review-level methods, attention-based approaches (e.g., NARRE, CARL, NRPA, DAML, and NRCA) typically outperform methods without attention (e.g., DeepCoNN). This is due to the possibility of noise from words or sentences in reviews or documents, which is detrimental to the learning of the user or item feature. The attention mechanism can assist the model in choosing more informative words or reviews. Among document-based baseline methods, DAML performs better than CARL, and the reason for its good performance lies more in NFM, which ensures that the extracted user-item interaction can be fully fitted. Among review-based baseline methods, NRPA outperforms NARRE because it considers not only the importance of each review but also the importance of the words included in each review. TAERT typically outperforms NARRE. One reason might for this be the relatively thorough use of the attention mechanism by TAERT at all review levels. EDMF We find no observable distinction between the review-level method and document-level method used by the application alone. Our model applies these two methods according to the characteristics of user and item reviews. We observe that AMLIAN improves MAE and MSE by 3.56% and 4.35% on average, respectively, compared to the best baseline. This result validates the effectiveness of our method and denotes the significance of using the review-level method for the user and using the document-level method for the item, which facilitates learning of more accurate feature representation.
We demonstrate our examination of the parameters of the validation sets in this section. The MAE is employed as an evaluation index for presentation.
The impact of the ID embedding dimension.
The user and item generate rating feature representations through the ID embedding layer. Therefore, we study the effect of various ID embedding dimensions on the AMLIAN model. As demonstrated in Fig. 4, the MAE initially decreases before increasing after it reaches its optimal value as the ID embedding dimension steadily increases. When the dimension is too small, the rating feature cannot accurately represent the variety of the user and item. However, overfitting can occur if the dimension is too large. Figure 4 demonstrates that 50 is the ideal choice for the ID embedding dimension.
The influence of the number of CNN filters.
CNNs are utilized to extract user and item review feature representations; hence, this paper investigates how the recommendation effect is affected by various CNN filter counts. The model’s performance steadily improves with the number of CNN filters, according to the experimental findings displayed in Fig. 5. As the number of filters increases, the performance tends to remain stable. As a result, in our experiments, we choose 50 as the CNN filter number.
The impact of the number of MLP layers in the NFM structure.
As the number of MLP layers in the NFM structure increases, the MAE value starts to gradually rise, as shown in Fig. 6. This illustrates how having too many layers may result in overfitting. As a result, we use two MLP layers in the NFM.
In this section, we analyze four attention layers, review aspect level attention (U1), review level attention (U2), word level attention (I1) and document aspect level attention (I2), and verify their impact on recommendation performance. The outcomes of the experiment are displayed in Table 4. The findings of the experiment show the following:
Impact of the attention layers. No_U1: the combination of U2, I1 and I2 attention. No_U2: the combination of U1, I1 and I2 attention. No_I1: the combination of U1, U2 and I2 attention. No_I2: the combination of U1, U2 and I1 attention. No_A: no attention layers. All_review: User-items use review-level data. All_document: User-items use document-level data
Impact of the attention layers. No_U1: the combination of U2, I1 and I2 attention. No_U2: the combination of U1, I1 and I2 attention. No_I1: the combination of U1, U2 and I2 attention. No_I2: the combination of U1, U2 and I1 attention. No_A: no attention layers. All_review: User-items use review-level data. All_document: User-items use document-level data
No_A is compared to other networks with attention layers. No_A shows the worst experimental results. This proves the effectiveness of the combination of the four attention mechanisms we designed. Next, we analyze the effects of these attention mechanisms on the performance of the whole model in more detail. All_review and All_document are compared to other methods that use different types of data. On the one hand, we find that replacing user review data at the document level or replacing item text data at the review level results in decreased performance for all datasets. On the other hand, All_review and All_document have similar results. This proves that using document-level or review-level features for the user or item at the same time has little impact on recommendation performance. Furthermore, using document-level and review-level features can further improve performance, which is effective for using corresponding data types according to the respective characteristics of the user and item. We also compare No_U1, No_U2, and No_I1, No_I2, which contain other three attention mechanisms. We draw the following conclusions. 1) No_I1 performs the worst on the evaluation metrics. This demonstrates that I1 can help select more informative words to reduce noise disturbance at the document level. 2) No_I2 is inferior to No_I1 with regard to MAE and MSE. The I2 attention layer is able to improve recommendation performance by identifying relevant information for user-item pairs. I2 can focus on useful review aspects related to target users. 3) No_U1 shows poor performance on evaluation metrics. This proves that U1 can help select more informative word aspects from user reviews. 4) No_U2 is superior to the other methods. We find that when the attention mechanism is applied, the performance of rating prediction is improved significantly. This justifies our assumption that the usefulness of reviews varies, and different reviews should have different representations of user preferences and item features. Moreover, our U2 can learn this representation well and lead to better performance by the recommender algorithm.
In this paper, we propose a novel neural recommendation method that combines review-level and document-level features of a user and item, which can extract corresponding representation features according to the characteristics of a user and item. Review-level features are learned within a user representation network that includes review aspect level attention and review level attention layers. Document-level features are learned within an item representation network that includes word level attention and document aspect level attention layers. This could help capture more accurate feature representation according to the characteristics of a user and item. Experiments on five real-world datasets from Amazon demonstrate that our method can consistently outperform existing state-of-the-art methods. In the future, we will consider adding the time dimension, which will help in considering a user’s long- and short-term interests such that the recommender system can better meet the user’s preferences.
Footnotes
Available at:
Acknowledgments
This work is supported by Tianjin “Project