
Abstract
Online social networks are considered to be one of the most disruptive platforms where people communicate with each other on any topic ranging from funny cat videos to cancer support. The widespread diffusion of mobile platforms such as smart-phones causes the number of messages shared in such platforms to grow heavily, thus more intelligent and scalable algorithms are needed for efficient extraction of useful information. This paper proposes a method for retrieving relevant information from social network messages using a distributional semantics-based framework powered by topic modeling. The proposed framework combines the Latent Dirichlet Allocation and distributional representation of phrases (Phrase2Vec) for effective information retrieval from online social networks. Extensive and systematic experiments on messages collected from Twitter (tweets) show this approach outperforms some state-of-the-art approaches in terms of precision and accuracy and better information retrieval is possible using the proposed method.
Keywords
Introduction
Recent years witnessed an exponential growth in the number of social network users due to the widespread popularity of mobile platforms and applications. This caused a huge volume of messages to be generated while these users communicate with each other [33]. People create and share pieces of text content that may be about some disasters such as earthquakes [20], or community view on elections [21], or new governmental agendas [25], or even opinions on a newly launched product in the market [22]. Thus retrieving relevant and useful information from those dynamically generated unstructured data is crucial as those messages may contain useful insights for any interested stakeholders. Information shared by social network users are archived at the service provider’s end and there may be situations where the users or other interested parties want to retrieve relevant messages from these enormous archives of data. So the need for intelligent and text understanding search, ranking, and retrieval algorithms is ever-increasing and crucial. The state-of-the-art algorithms that operate on a set of static documents may not always be a good choice in this situation due to the dynamic nature of information generated in social networks [23].
Text mining and information retrieval research communities devised many methods and algorithms for intelligent information retrieval from large unstructured text archives. These algorithms exhibited varying levels of accuracy when dealing with static documents but the performance was degraded on dynamic data such as social network messages [29]. Due to this dynamic nature, social networking platforms require more sophisticated algorithms to deal with the complexities in search and retrieval of relevant information. This is because social network platforms often use very short texts, non-standard language, and rich associated metadata. Even though a vast array of research on these dimensions has been reported to tackle this situation, there are still a lot of avenues where advanced natural language processing and information retrieval techniques can be used to design text understanding algorithms that can operate on such platforms.
Topic modeling is a suite of text understanding algorithms that can leverage hidden themes from large archives of unstructured text data [36]. Several variations of such algorithms with varying degrees of accuracy have been devised in the past with only difference in the assumption they made in the process of generating themes. Topic models were further extended for mining topics from social networks such as Twitter and are used by social network research communities in detecting change in topics over a while [34, 32, 24, 15]. On the other hand, neural network based approaches such as word2vec – distributed representation of words in a vector space [27], and phrase2vec – distributed representation of phrases in a vector space [28] etc. gained significant attention that considered the ‘context’ in which words or phrases have been used.
This work attempts to make use of topic modeling [36] and distributed representation of phrases (phrase2vec) [28] for scoring social network messages and shows the application on a phrase query-based information retrieval task. The main research objectives of this paper are (1) Introduce the task of topic modeling guided scoring of unstructured text and its applications in online social networks, (2) Propose a framework that combines topic modeling and distributional representation of phrases for better retrieval of relevant information from text messages, (3) Verify experimentally the effectiveness of the proposed framework in extracting relevant and useful information from social network messages, (4) Compare proposed approach with state-of-the-art models to establish the fitness of our method in scoring social network messages and phrase query-based information retrieval. The main contributions of this paper are summarized as follows:
Proposes a framework for retrieving relevant and useful content from a large collection of social network messages. Shows that a hybrid approach combining topic modeling and distributed representation of phrases can better retrieve and rank relevant information. Rigorous experimental comparison of the proposed method with other state-of-the-art approaches establishes the effectiveness of the proposed method.
The major research questions addressed in this manuscript are:
Can we use the dynamics of the topics generated by the topic modeling and phrase embedding generated by phrase2vec for better ranking and retrieving messages? Can the proposed approach be used to address the drawbacks of the existing approaches for information retrieval from social networks which are dynamic in nature.
Organization: The rest of this paper is organized as follows: Section 2 briefly outlines state-of-the-art in information retrieval from online social networks. Section 3 discusses the proposed framework in detail and Section 4 describes the experimental setup used in this work. A detailed evaluation of results is given in Section 5 and in Section 6, the authors give conclusions and discuss future work.
This section details some of the prominent works which are related to our proposed work that attempts to develop methods for retrieving information from a large collection of social network data. Due to the widespread development of social network platforms, the amount of data or messages accumulated in these platforms grew exponentially that attracted social network researchers to devise new methods to retrieve, analyze, curate and store such messages. Very recently, Xu et al. [1] proposed a novel approach that integrate social annotations into topic models for personalized document retrieval [1]. This approach uses social tags of documents to capture user preferences and reconstructs candidate documents for a given query. Then these reconstructed documents are used for achieving better retrieval performance. Experimental results showed that the proposed approach significantly outperformed state-of-the-art approaches for personalized retrieval [1].
An approach that automatically finds traffic-related reports and extract useful information is proposed by Vallejos et al. [2]. The authors addresses the problem of informal language usage in social networks and the lack of geographic metadata to extract traffic-related reports. When compared with a popular traffic-specific social network, the proposed approach obtained promising results [2]. A system called AMiner, which deals with the search and mining of academic social network was recently reported by Wan et al. [3]. The objective of AMiner is to help researchers and scientists gain a deeper understanding of the large and heterogeneous networks formed by authors, papers, conferences, journals and organizations [3]. The authors have used a generative probabilistic model to simultaneously model the different entities while providing a topic-level expertise search. Marco Brambilla et al. proposed a method for extracting emerging knowledge from social media [9]. Their proposed method discovered emerging entities by extracting them from social content and ranks the candidates by using their distance from the centroid of seeds, where those seed entities are provided by the experts. Another approach for information retrieval from social media was reported by Oostdijk et al. that used a linguistics based approach [16]. The authors specifically extracted traffic-related information from Tweets and claimed an accuracy rate of 74%.
An approach for retrieving disaster events from cross-platform social media was introduced by Shen et al. [8] in which the authors proposed a method to retrieve data on an event based on a preliminary collection of event-specific hashtags. This method could collect distinct sets of hashtags even for similar simultaneous events [8]. Another approach for text information retrieval by integrating global and local textual information [17] was reported recently in the literature by Wang et al., in which the authors combine Latent Dirichlet Allocation topic modeling algorithm and word2vec and proposed an approach for document retrieval. They claimed that the proposed method significantly enhanced the accuracy of classification analysis. A novel approach that implemented real-time social media retrieval with spatial, temporal and social constraints was introduced very recently by Gao et al. [10]. This paper proposed an interval-at-a-time framework to provide a solution to social media retrieval with spatial, temporal and social constraints. This algorithm relies on inverted lists and showed better performance when compared with other state-of-the-art methods [10].
A method for identifying search keywords for finding relevant social media posts was reported recently in the literature [18] by Wang et al. The paper proposed a novel technique to help the user identify topical search keywords. Their experiment on tweets dataset showed the effectiveness of their proposed approach in identifying potential keywords. Tolosa et al. introduced the concept of an integrated cache, a static cache that stores both individual postings list and its bigram intersections [11]. The authors devised an algorithm to re-write queries using this cache and showed that there is a speed improvement over previous methods. Kim et al. presented a simulation-based approach for selective search under many different hardware configurations. They used large query logs that provided the effectiveness of the selective search approach and distribution of shards across machines [12]. Another recent notable work that examines indexing for repetitive collections is reported by Gagie et al. [13]. Their proposed work included mechanisms for effective compression, methods for top-
On conducting this systematic literature review, we found that there exist an array of drawbacks with the state-of-the-art approaches in information retrieval, specifically from online social networks. A vast majority of the existing algorithms operate on static set of documents and significantly fails when it comes to the dynamic data. Also, the approaches discussed above are used for information retrieval from social networks such as Twitter that depends on techniques such as expert provided seed entities, global and local textual information, phrase embeddings, inverted lists, integrated static cache, and distributed query processing which may not be feasible in all the contexts. On the other hand, our proposed method makes use of the dynamics of the topics (generated by LDA) discovered from social network messages, key-phrases (from extracted phrases using natural language processing), phrase embedding (phrase2vec representation) all lead to multiple ways of reaching a target document/message from the user given query phrase, using which we may better retrieve and rank the messages.
Background: Latent Dirichlet Allocation (LDA)
Inspired from previous topic models, Blei et al. introduced a new topic modeling algorithm known as Latent Dirichlet Allocation (LDA) [37]. This model assumes that a document contains multiple topics and such topics are extracted using a Dirichlet Prior process. In the following section, we will briefly describe the underlying principle of LDA [37]. Even though LDA works well on broad ranges of discrete datasets, the text is considered to be a typical example to which the model can be best applied. The process of generating a document with
Choose the number of words, Choose the distribution over topics,
Choose a topic Choose a word
Thus the marginal distribution of the document can be obtained from the above process as:
where,
This section briefly outlines the necessary background on the distributional representation of words and phrases which are current hot research areas in text mining and natural language processing. This area of research is attempting to develop methods for measuring the level of semantic similarities among linguistic elements in large samples of unstructured data. The idea of distributional representation of words and phrases got significant attention from text mining and natural language processing practitioners as these representations could project the semantic similarities of those linguistic units in high dimensional vector space. The seminal work in this dimension that explored beyond traditional syntactic and probabilistic approach was introduced by Tomas Mikolov which represented word unigrams in high dimensional vector spaces [27]. This paper contributed two strong architectures – Continuous Bag of Words (CBOW) and Skip-gram – where the former can predict the current word based on the context and the latter can predict the context based on a given word. These models were initially used to work with word unigrams, later methods for distributed representation of phrases [28], sentences, paragraphs and even documents [26] have been reported.
Skip-gram model for phrases used in this work. 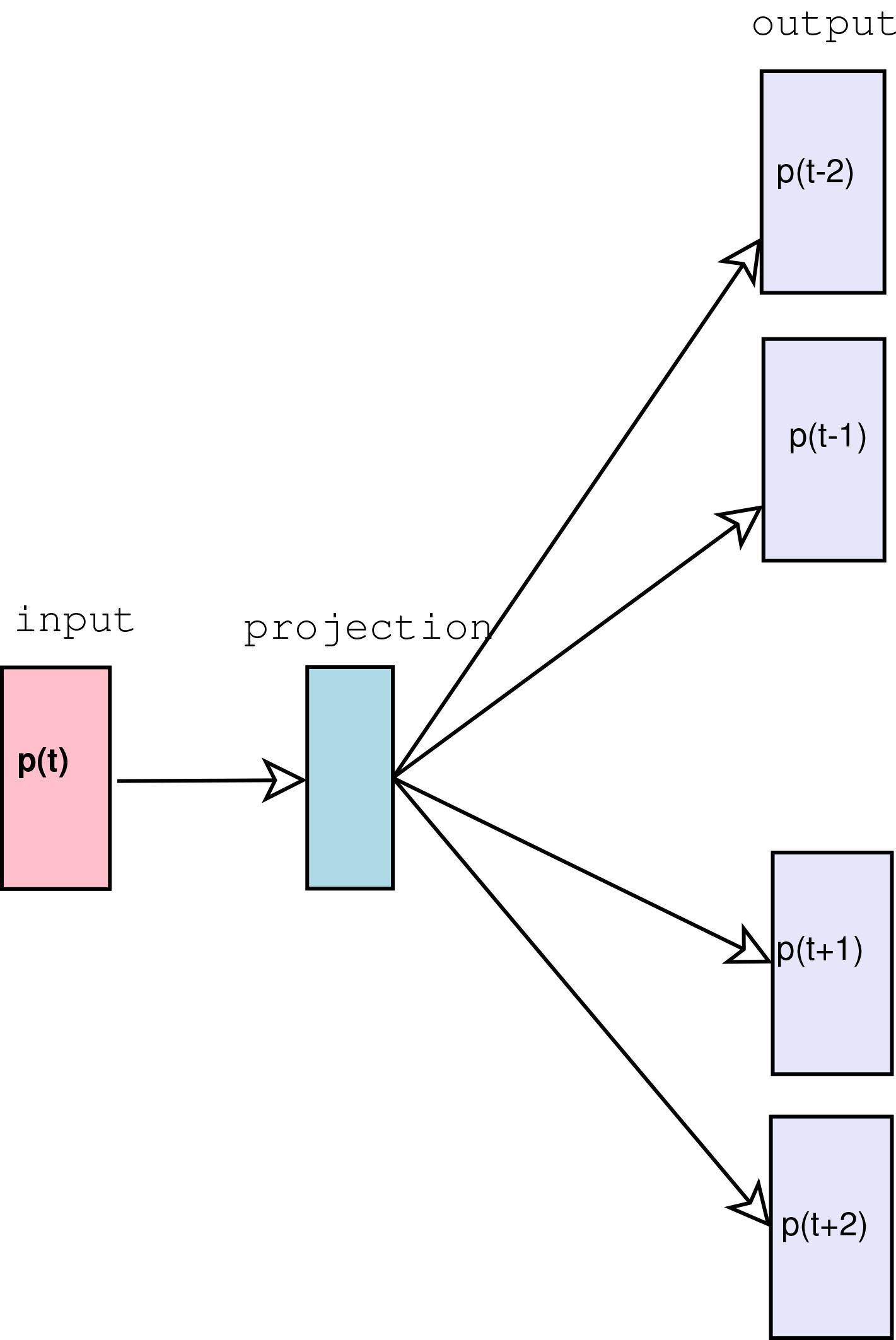
Overall workflow of the proposed approach.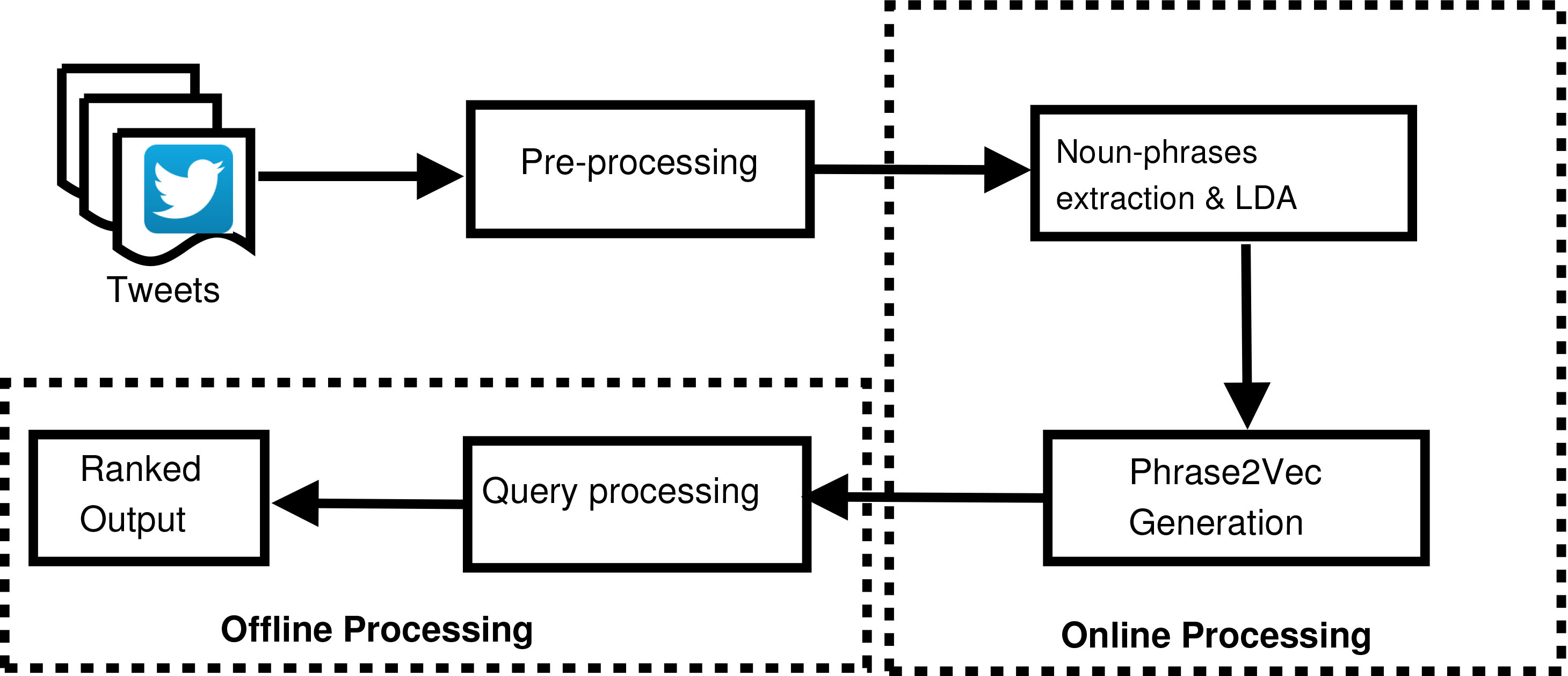
In this work, we use the Skip-gram architecture for learning distributed representation of phrases identified from tweets and is shown in Fig. 1. In phrase2vec model, a large number of key-phrases are identified and during training, they are treated as individual tokens, to find phrase representations that may predict surrounding phrases in a sentence or given document [28]. Given a phrase (query), this work also utilizes this intuition to find semantically related phrases that are identified from tweets beforehand and represented in a distributed high dimensional vector space.
This section details the proposed framework for topic modeling powered distributional semantics-based information retrieval from online social networks. The overall workflow of the proposed framework is shown in Fig. 2. The framework consists of two modules in which the first one requires online processing and the second one is executed offline. A detailed description of the modules is outlined in the subsequent sections.
Online processing
The online processing module of this framework is used for extracting noun-phrases, generating topics and creating distributed vector representation of identified noun-phrases. This proposed method uses an off-the-shelf tool for extracting noun-phrases from pre-processed tweets that will identify and extract semantically valid phrases. The decision of using an off-the-shelf tool was taken as we observed that the custom natural language processing rules based on part-of-speech tagging is computationally expensive in terms of both memory and time thus the scalability of such an approach is very weak. Latent Dirichlet Allocation (LDA) [37] algorithm is then executed on tweets for generating latent topics that are word unigrams. Now we introduce our formula for scoring noun-phrases in topics generated. The score for a noun-phrase
where
Topical scoring noun-phrases from tweetsInputInput OutputOutput function ComputeScore
Corpus of tweets,
Query enhancement and tweet messages scoringInputInput OutputOutput function RankAndRetrieveTweets
A phrase query
(2) Retrieve significant topics for
(3) Use score
(4) Select top-
The offline module of this framework deals with ranking messages, given a phrase query by the user. The algorithm we have devised for retrieving relevant messages for a user-specified query is given in Algorithm 3.1. Firstly, the phrase query given by the user is enhanced and this is achieved by using the phrase2vec embedding we have created during the online processing stage. The query
Experimental setup
This section details the experimental setup used for our proposed information extraction experiment. A complete description of the dataset used and the experimental testbed details are highlighted.
Dataset description
This work uses messages from Twitter (tweets) for this experiment and collected tweets for 5 hashtags – “#KashmirUnrest”, “#SurgicalStrike”, “#Demonetisation”, “#Election2016” and “#MakeInIndia”. We have collected 25000 tweet messages for each hashtag from March 2017 to August 2017, using SocioViz1
A snapshot of tweets collected for the hashtag “#DeMonetisation”
We generated noun-phrases from pre-processed tweets using two different methods. Initially, we have implemented a natural language processing (NLP) based approach and later using an off-the-shelf tool. For the NLP approach, we have first done a parts-of-speech (POS) tagging on pre-processed messages and written NLP rules by combining different POS tags extracted. Some of such rules used for keyphrase extraction are shown in Table 1. More information on POS tags can be obtained from the URL
https://textblob.readthedocs.io/en/dev/ [Last accessed on 13/03/ 2020].
Common NLP rules for extracting semantically valid phrases from tweets
All algorithms proposed in this paper were implemented using Python 2.7 and run on a server computer with AMD Opteron 6376 2.3 GHz 16 core processor and 16 GB of main memory. The collected tweets were thoroughly pre-processed to remove noises such as web URLs and special characters. Pre-processed tweet messages were saved in plain text files and prepared an experiment ready copy of the dataset. For topic generation from these tweets, we have executed the Latent Dirichlet Allocation (LDA) algorithm and used MALLET (Machine Learning for Language Toolkit) tool available at
After the online processing stage, the experiment has been extended for scoring or ranking messages, given a user query. For scoring, we make use of the dynamics of the topic (generated by LDA), phrases (generated by TextBlob) and the messages that all lead multiple ways of reaching the message from the query phrase. Firstly, the given query is enhanced using the phrase2vec embedding generated and stored in the online processing stage of the experiment. Given a phrase query, the pre-trained model will give a set of phrases that are semantically related to the given query and is calculated as the cosine distance between two vectors in the distributional vector space. We use this enhanced query set for extracting relevant messages, rather than using the simple query phrase based information retrieval. Thus the message would be scored high if it contains a lot of phrases that are similar to the query phrase which is our hypothesis for this experiment. We compare our proposed ranking approach with four state-of-the-art baselines such as BM25 [38], a flat position index-based approach [30], an inverted index-based approach [31] and an entity-based retrieval approach [19]. Out of these three approaches, BM25 [38] is a term matching based approach, other two phrase-based retrieval mechanisms that use flat position index and an inverted index as their primary data structures and an entity-language based approach. We implemented them using Python programming language with the help of public code repositories available at
Comparison of proposed method with BM25, flat position index, inverted index and entity based baselines for twitter hashtags – “#KashmirUnrest”, “#SurgicalStrike”, and “#Demonetisation”
Comparison of proposed method with BM25, flat position index, inverted index and entity based baselines for twitter hashtags – “#KashmirUnrest”, “#SurgicalStrike”, and “#Demonetisation”
Comparison of proposed method with BM25, flat position index, inverted index and entity based baselines for twitter hashtags – “#Election2016”, “#MakeInIndia”, and “#TrumpRussia”
In this section, we describe and evaluate our proposed framework for efficient information retrieval from online social networks. We compare our scoring method with four other state-of-the-art baselines:
BM25 (Best Match 25) [38]: In information retrieval, BM25, known as Okapi BM25, is a widely used ranking function by search engines to rank a large collection of documents given a search query. It is a probabilistic retrieval method that act on bag-of-words created from the document collection using the following equation [38]:
where,
Precision, recall and F-measure comparison for the hashtag – “#KashmirUnrest”.
Precision, recall and F-measure comparison for the hashtag – “#SurgicalStrike”.
FPI (Flat Position Index) based approach [30]: In this method, the authors propose a flat position index for phrase query evaluation. The entire document collection is treated as huge sequence of tokens and each token is represented by one flat position. This method could reduce the index size and speed up phrase querying substantially.
Inverted Index based approach [31]: This method introduced a set of inverted indexes that work for strings and phrases that works well for phrase searching. This approach also highlighted top-
Entity – Language Model based approach [19]: This paper introduced entity-based language models for document retrieval that utilizes information about single terms in the query and documents as term sequences marked as entities. This approach projected the merits of using language models for retrieval tasks and shows that language models can be effectively used for cluster based document retrieval [19].
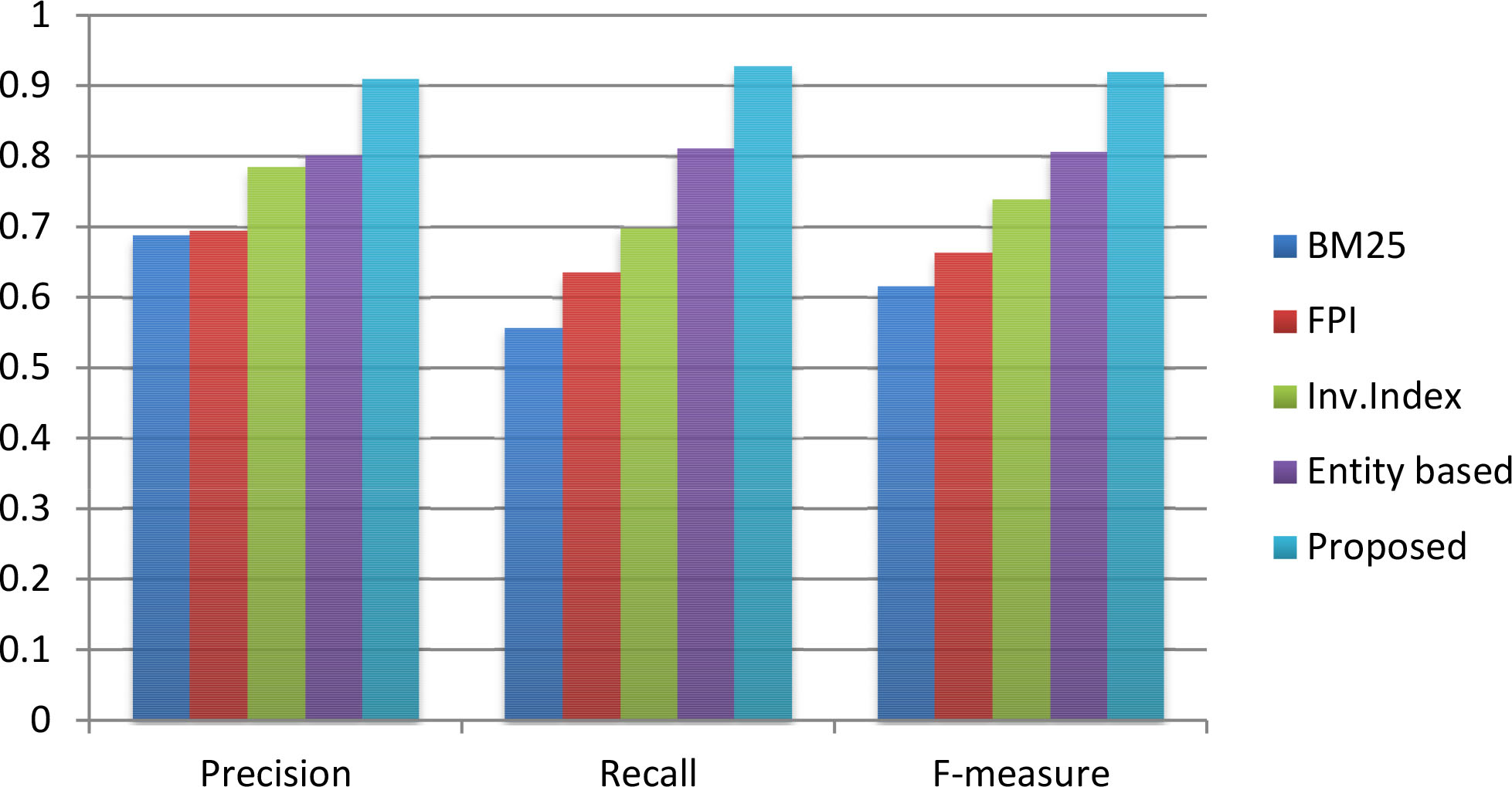
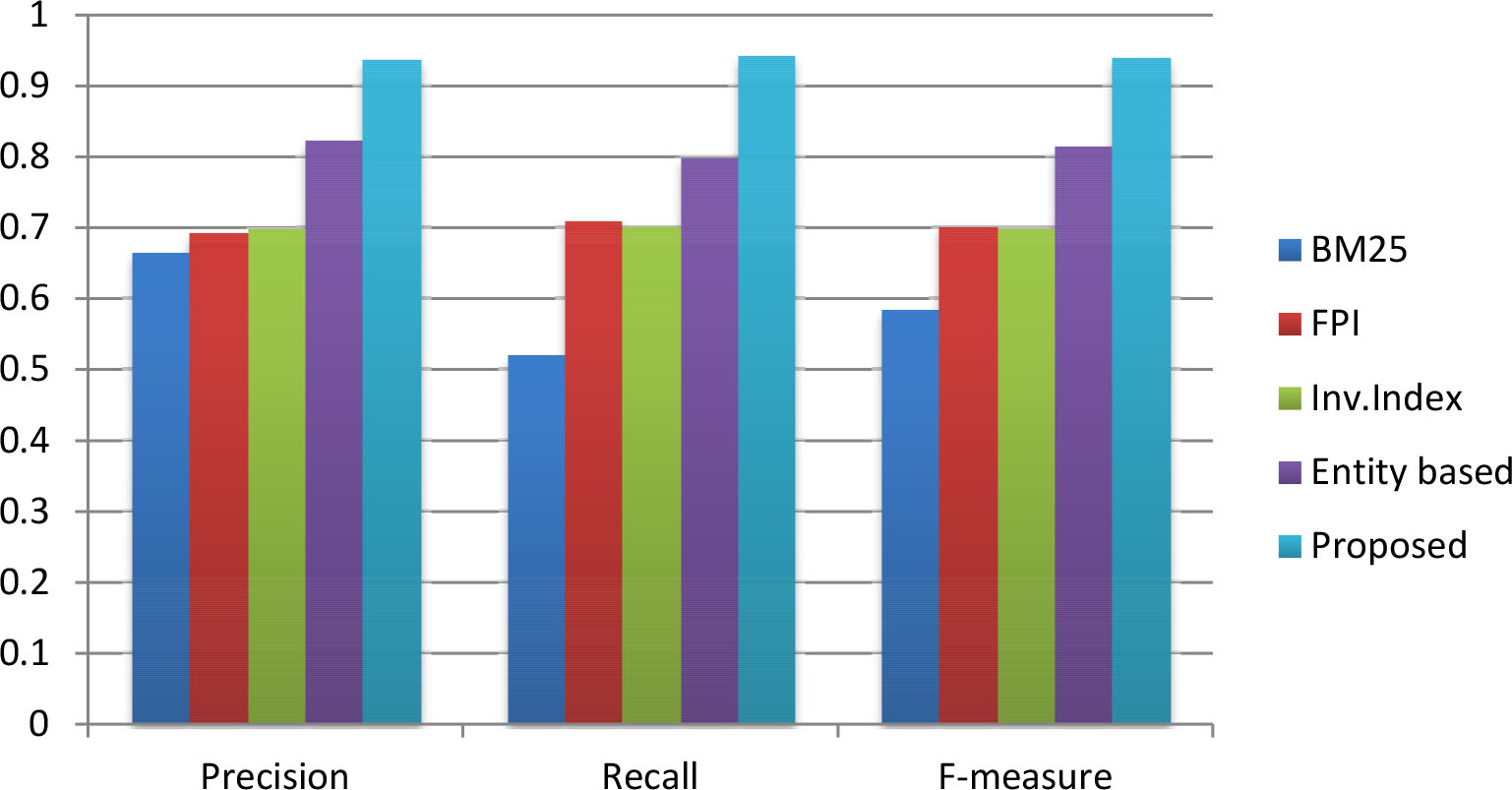
Precision, recall and F-measure comparison for the hashtag – “#Election2016”.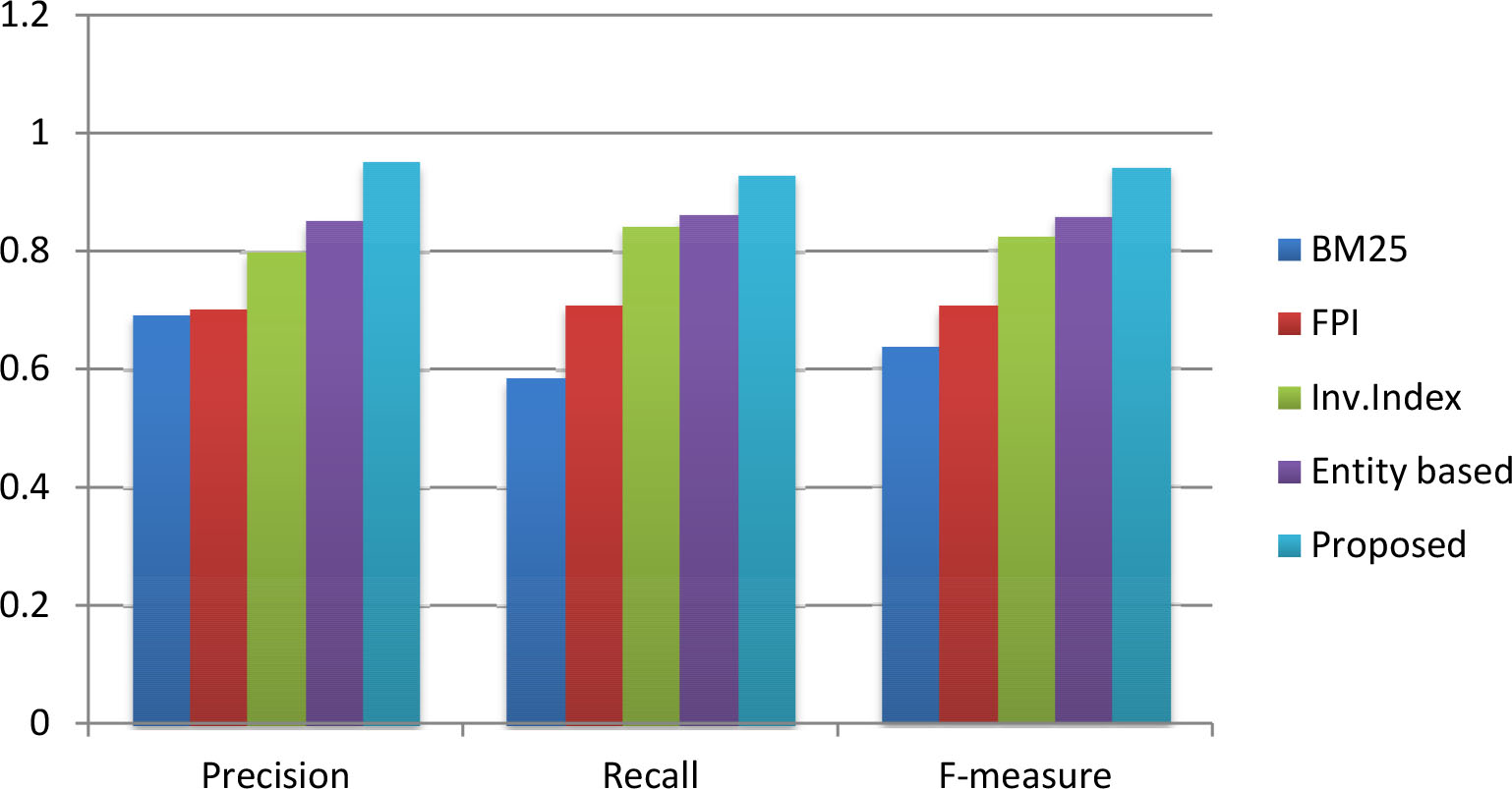
Precision, recall and F-measure comparison for the hashtag – “#Demonetisation”.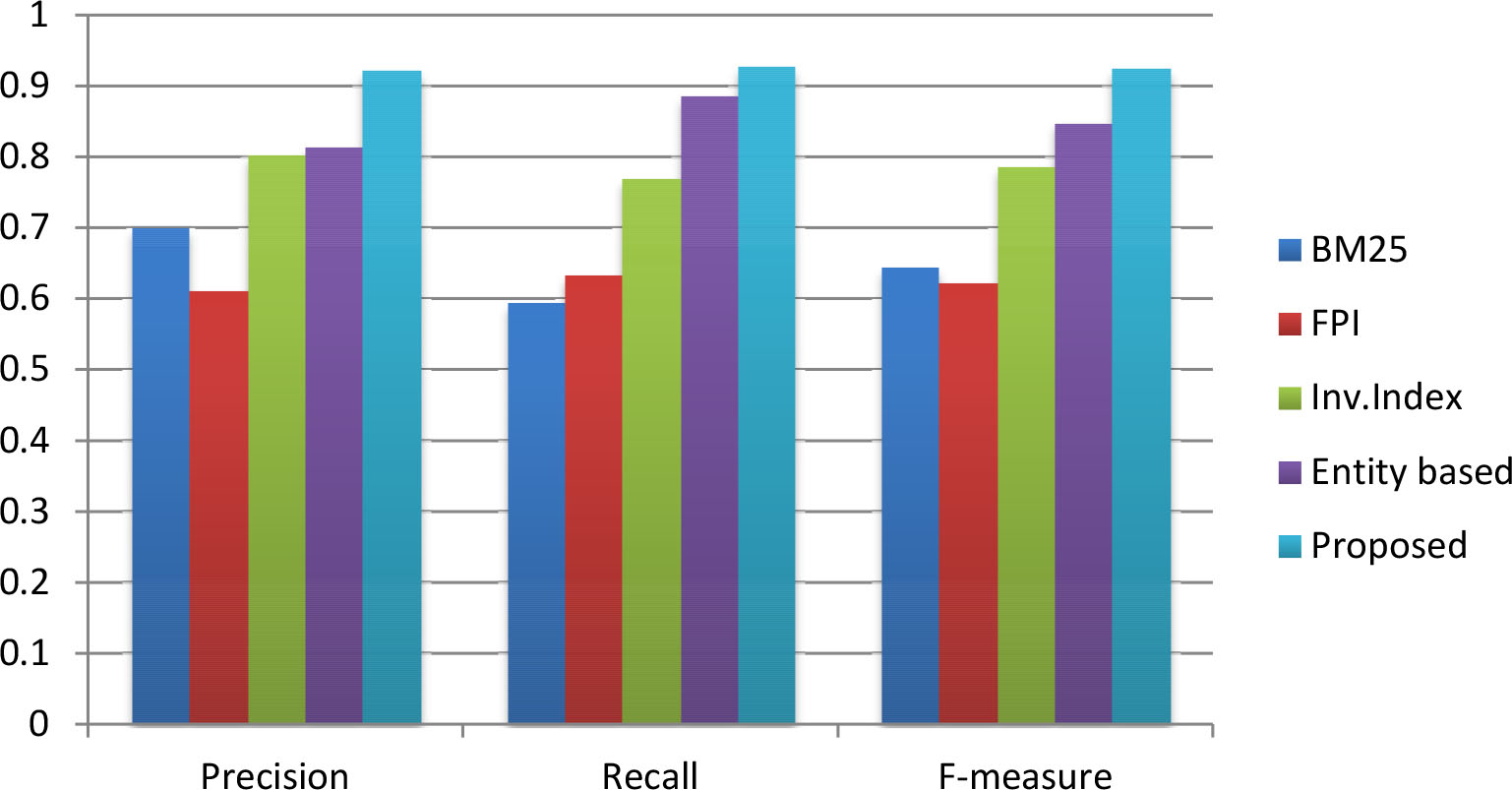
Precision, recall and F-measure comparison for the hashtag – “#MakeInIndia”.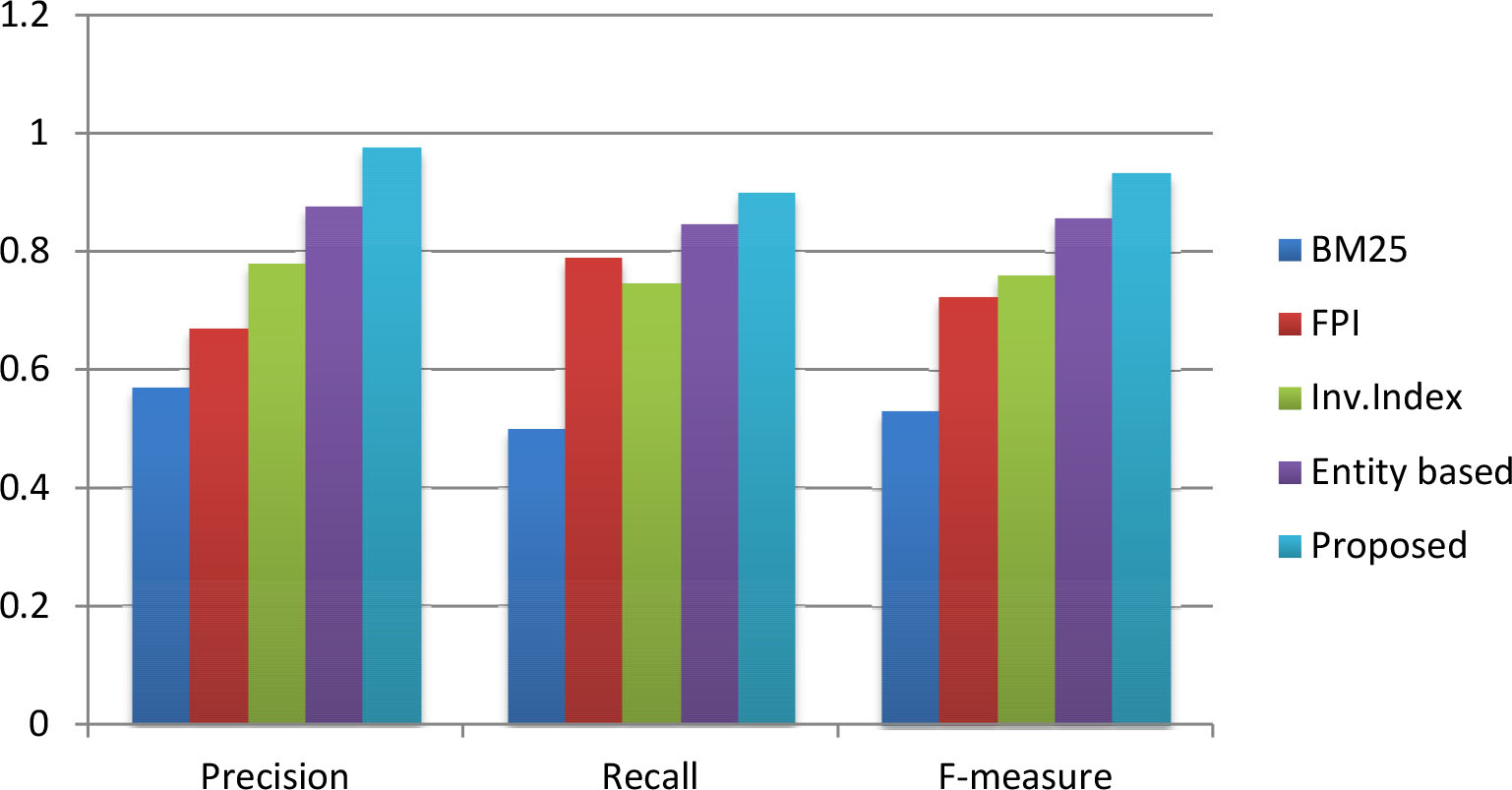
Precision, recall and F-measure comparison for the hashtag – “#TrumpRussia”.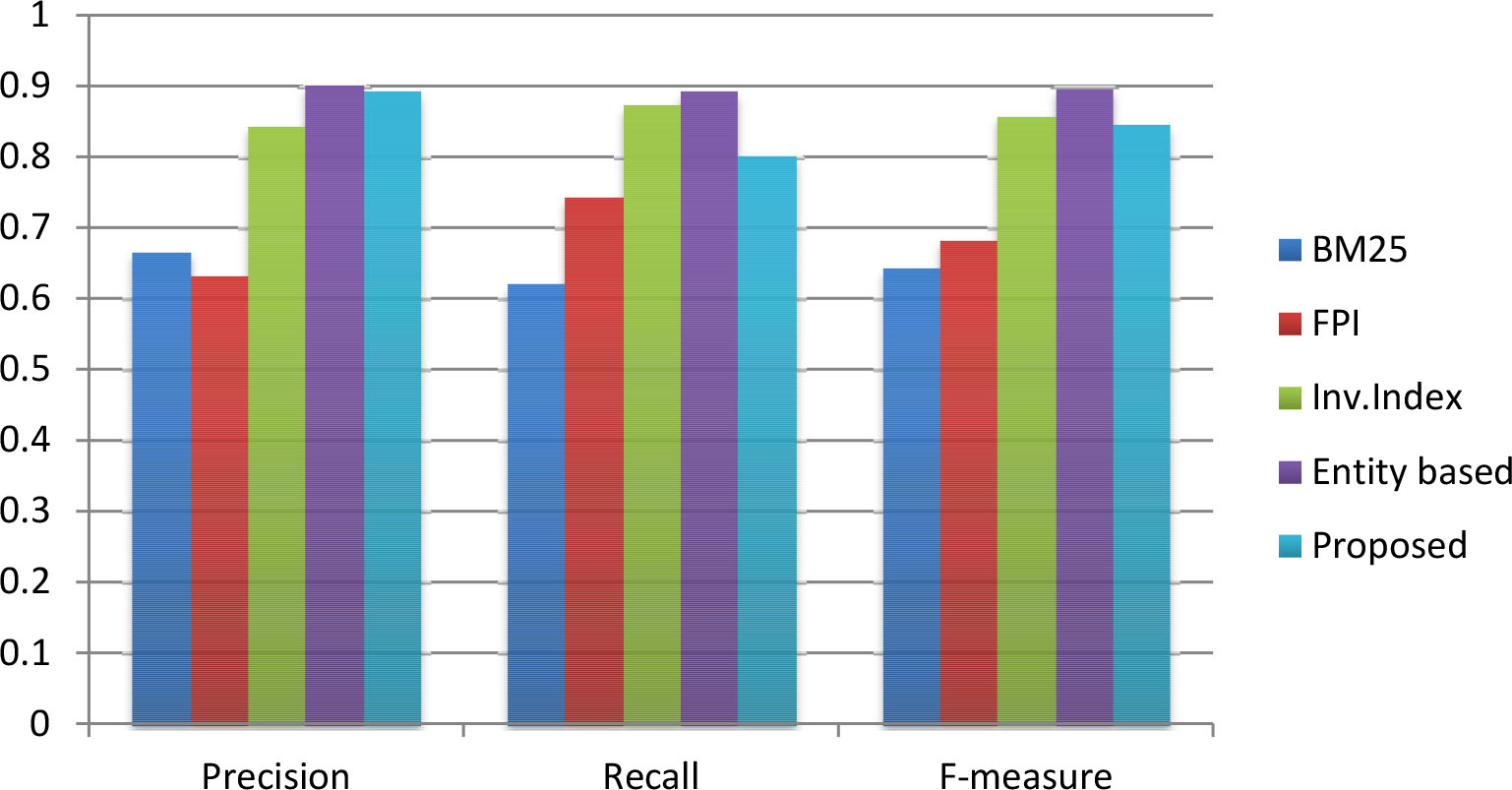
We compared our proposed algorithm for information retrieval with four different state-of-the-art approaches [38, 30, 31, 19]. The performance comparison in terms of precision, recall and f-measure for hashtags “#KashmirUnrest”, “#SurgicalStrike”, and “#Demonetisation” are shown in Table 2 and the hashtags “#Election2016”, “#MakeInIndia”, and “#TrumpRussia” are shown in Table 3 respectively. From Tables 2 and 3, it is clear that our proposed framework outperforms the chosen baselines in term of precision, recall and f-measure. For the hashtag “#KashmirUnrest”, our method achieved 0.9114, 0.9274 and 0.9193 as precision, recall and f-measure respectively and the entity based approach [19], which is the closest competitor that could achieve an f-measure value of 0.8065 only. For the next four hashtags such as “#SurgicalStrike”, “#Demonetisation”, “#Election2016” and “#MakeInIndia”, our method showed better f-measure which was 0.9393, 0.9226, 0.9422 and 0.9341 respectively. But for the hashtag “#TrumpRussia”, we found that our closest competitor for other hashtags, the entity-based approach [19] showed better performance in terms of f-measure. This method showed 0.8984 as the f-measure and our method could achieve an f-measure of 0.8472 only. Upon further and detailed analysis, we found that the number of noun phrases generated from the tweets against the hashtag “#TrumpRussia” was less compared to the other hashtags. In future work, we may address this by comparing different tools for key-phrase extraction and enrich the process of phrase generation by incorporating custom natural language rules.
This paper proposed a framework for better information retrieval from online social networks, using distributional phrase embedding and topic modeling. Our proposed method was successful in utilizing the dynamics of the topics generated by the topic model fused with the keyphrases and phrase embeddings. This addressed the major drawback of the vast majority of existing algorithms that fails to work with dynamic data. Experiments with messages collected from Twitter shows that better ranking and retrieval of relevant messages are possible if topic modeling is integrated with distributional semantics. We have conducted the baseline comparison with some of the state-of-the-art approaches and the proposed approach showed significant improvements. The main limitation of this study is that the proposed approach do not consider the informal nature of the messages and the amount of messages are limited. In the future work, the authors will be working on these dimensions. Also, some of the potential areas that worth investigating further are tuning the parameters of LDA algorithm for topic modeling and phrase extraction, use of sentence2Vec and doc2Vec with this experimental setup for better ranking and retrieval for a larger set of documents.