
Abstract
Entity resolution refers to the process of identifying, matching, and integrating records belonging to unique entities in a data set. However, a comprehensive comparison across all pairs of records leads to quadratic matching complexity. Therefore, blocking methods are used to group similar entities into small blocks before the matching. Available blocking methods typically do not consider semantic relationships among records. In this paper, we propose a Semantic-aware Meta-Blocking approach called SeMBlock. SeMBlock considers the semantic similarity of records by applying locality-sensitive hashing (LSH) based on word embedding to achieve fast and reliable blocking in a large-scale data environment. To improve the quality of the blocks created, SeMBlock builds a weighted graph of semantically similar records and prunes the graph edges. We extensively compare SeMBlock with 16 existing blocking methods, using three real-world data sets. The experimental results show that SeMBlock significantly outperforms all 16 methods with respect to two relevant measures, F-measure and pair-quality measure. F-measure and pair-quality measure of SeMBlock are approximately 7% and 27%, respectively, higher than recently released blocking methods.
Keywords
Introduction
Integrating two or more datasets in the absence of a unique identifier is a challenging problem that causes redundancy of data and inaccurate knowledge extraction [1, 2, 3]. Entity resolution is used to identify, match and integrate the records of an entity in different datasets [4, 5, 6]. However, there are challenges in entity resolution such as computing similarities between all pairs of records in a large dataset, which is problematic because the number of comparisons grows quadratically with the size of the dataset. Even for a small dataset, calculating the total similarity matrix using costly similarity functions can be extremely difficult [7].
To meet these challenges, blocking in entity resolution is used to group the records into a set of blocks so that a block contains only similar entities [8, 9, 10, 11] and the entities in a block are more similar to each other than to entities in other blocks [12, 13]. A number of blocking methods [14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28] have already been proposed which are exclusively based on the textual similarity of records while not taking semantic information into account.
In this paper, we propose a novel blocking method called SeMBlock (Semantic-aware Meta-Blocking approach) that uses a locality-sensitive hashing (LSH) method based on word embedding (BERT) to discover semantic relationships among pairs of records. Text analysis techniques [29, 30, 31, 32] such as word embedding methods, Word2Vec [33, 34] and BERT (Bidirectional Encoder Representations from Transformers) [35], map words to a new space in which semantically similar words are placed adjacent to each other. Word2Vec applies a neural network to describe each word in the text with a vector [33, 34] and BERT pre-trains deep bidirectional representations from unlabeled text [35]. One of the major differences between BERT and Word2vec is that the BERT generates word embeddings based on the contexts in which the words appear. As a result, it generates different embeddings for each of the occurrences of a word, while in Word2Vec each instance of the word has the same representation even if it occurs in different contexts. Locality-sensitive hashing (LSH) is a popular method for nearest neighbor search in high-dimensional spaces. The basic idea is that the more similar two records are, the higher the probability is that they are hashed into the same block. LSH is a fast blocking technique over extensive data sets due to its probabilistic nature. Leveraging LSH techniques can reduce the time complexity of generating blocks to O(n). Additionally, the use of LSH techniques in semantic similarity space significantly improves the quality of blocking by removing record pairs that are textually similar but semantically different [12]. SeMBlock generates a graph of semantically similar records and applies a pruning method in order to improve the quality of blocking. The main contributions of SeMBlock are:
Creating fast and reliable blocking in a large-scale data environment that considers the context of the text. Constructing a semantic-aware blocking graph. Outperforming 16 state-of-the-art blocking methods on three real-world data sets.
SeMBlock has been proposed to take advantage of word embedding for extracting semantic similarity and locality-sensitive hashing in order to significantly reduce the time complexity of generating blocks and to improve the run-time and accuracy of entity resolution. Accurate and fast entity resolution has huge practical implications in almost all modern data management tasks such as information extraction [36], big data analysis [37], and knowledge base construction [38] and helps businesses in unifying their customer data and in improving their decision making.
The structure of this article is as follows: Section 2 overviews available blocking methods. Section 3 provides a formal description of the entity resolution problem. SeMBlock is described in detail in Section 4. The experimental results are described and discussed in Section 5. Section 6 provides summarizing conclusions and future work.
Entity Resolution is the process of identifying different entity records that represent the same real-world object. Performing entity resolution tasks over large data sets is computationally challenging due to the quadratic complexity
The four main steps of SeMBlock.
An illustration of the semantic-aware LSH method.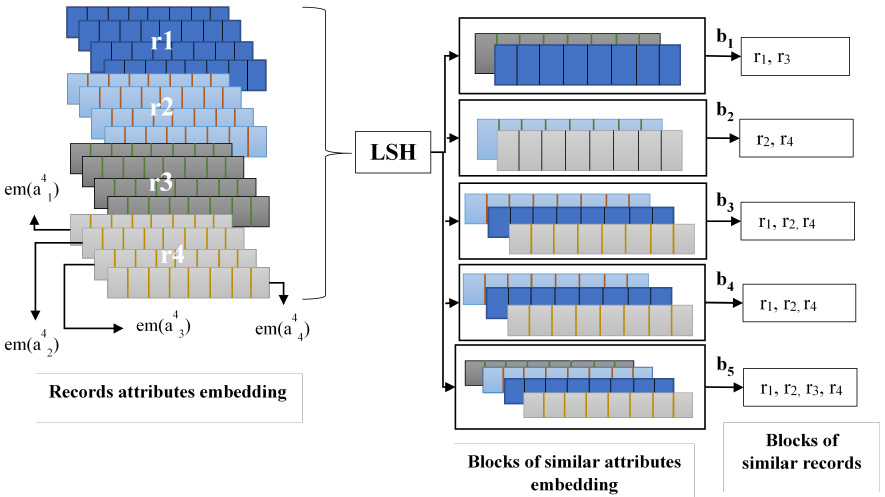
Traditional schema-based blocking techniques such as standard blocking [41, 18], sorted neighborhood [42], extended sorted neighborhood [19], q-grams blocking [43], extended q-grams blocking [19], MFIBlocks [44], canopy clustering [45, 46], extended canopy clustering [19], suffix arrays [47] and extended suffix arrays [19] generate blocks based on the blocking keys, which depend on the schema of the dataset [48]. The main drawback of these methods is the choice of selecting features for the blocking keys, which is a laborious and error-prone process and requires domain expert knowledge [21, 49].
In comparison with schema-based blocking techniques, schema-agnostic blocking approaches such as token blocking [50, 51, 52], attribute-clustering blocking [22], TYPiMatch [20] do not use any schema information [48]. They place each record in multiple blocks and create overlapping blocks which decrease the probability of a matching loss and increase the probability of inserting non-matching records in the same block (high recall but at the expense of low precision) [21].
Meta-blocking approaches such as WNP and CNP meta-blocking [24, 14], BLAST [21], BLOSS [17], supervised meta-blocking [15] and multi-core meta-blocking [53] have been proposed which rebuild a set of blocks to keep the most promising comparisons [14]. To do so, the set of blocks are shown by a weighted graph, called a blocking graph [14]. In this graph, each record is represented by a node and an edge exists between two nodes if the corresponding records together appear in at least one block. The weights of the edges are calculated for the matching probability. Then, a pruning algorithm is applied based on the weights of the edges. Eventually, each pair of nodes connected by edge create a new block [54, 24].
At the core of entity resolution lies the concept of the entity record, which forms a unique set of attribute name-value pairs. An individual entity record is specified by
SeMBlock
SeMBlock comprises four sequential main steps, as overviewed in Fig. 1. These steps are as follows:
For each record
Basic statistical information on the three chosen datasets
To avoid the quadratic complexity of calculating the pairwise similarity of attributes’ embedding, SeMBlock applies Locality-Sensitive Hashing (LSH), which hashes similar attributes’ embedding into the same block with high probability and creates a set of blocks
where
After building the set of blocks
where
SeMBlock constructs a blocking graph in which each
SeMBlock prunes the graph in order to further increase accuracy. If the weight of an edge
PC, PQ, and FM for SeMBlock and different values of 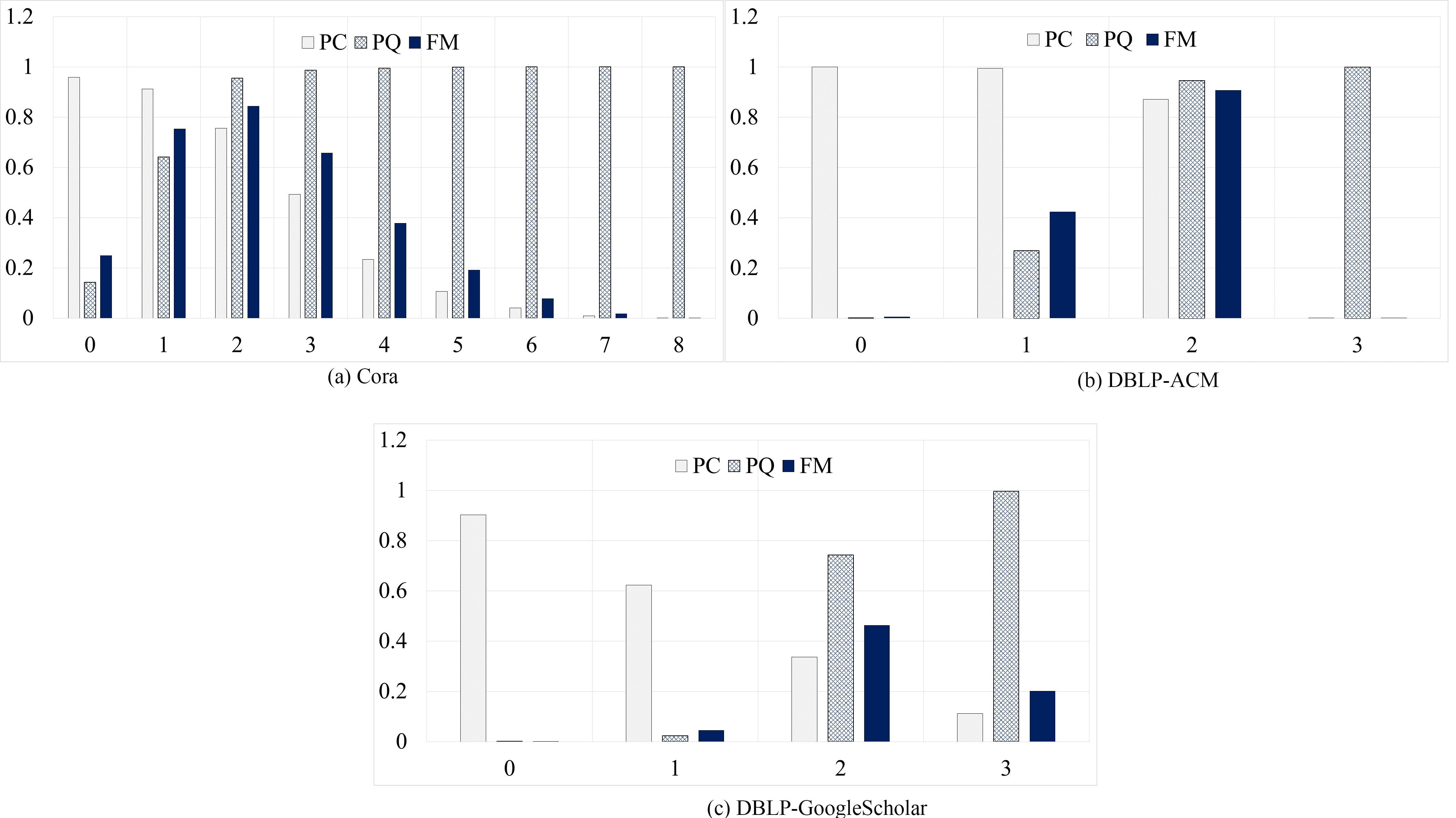
This section is divided into three subsections, describing the three real-world data sets used for evaluation, the blocking evaluation measures used to evaluate SeMBlock, and the performance of SeMBlock in comparison to the 16 blocking methods.
Data sets
We use three real-world data sets: Cora [56], DBLP-ACM [57] and DBLP-Scholar [57]: Cora contains bibliographic records of machine learning papers, DBLP-ACM contains bibliographic data from DBLP and ACM, and DBLP-Scholar contains bibliographic data from DBLP and Google Scholar. Table 1 shows details of each data set. The experimental results of our baseline models are only available on these three datasets, so we use these three datasets for a fair comparison.
Evaluation measures
We use three common measures [10, 9, 18, 58, 59] to evaluate blocking quality: Pair Completeness (PC), Pairs Quality (PQ), and F-Measure (FM).
PC, which is also known as recall, estimates the portion of the duplicate entities that co-occur at least once in a set of blocks
where
PQ, also known as precision, measures the portion of comparisons that correspond to real duplicates (see, e.g., [18]) and is given by
where
Finally, FM is the harmonic mean of PC and PQ (see, e.g., [9]):
We evaluated SeMBlock with the datasets and measures described above. According to SeMBlock, for each dataset the BERT embeddings of the records are calculated, LHS is applied, a blocking graph is constructed, and graph pruning is executed. As described in Section 4, pruning the parameter
We compared SeMBlock with the following standard blocking approaches (The parameters of each method are determined based on the best values specified for them in the associated papers):
Schema-based approaches: Sorted neighborhood blocking (SN)[42], Extended sorted neighborhood blocking (ESN) [19], Canopy clustering (CC) [45, 46], Extended canopy clustering (ECC) [19], Suffix arrays blocking (SA) [47], Extended suffix arrays blocking (ESA) [19], Q-grams blocking (Qg) [43], and Extended q-grams blocking (EQg) [19]. Schema-agnostic approaches: Token blocking (TB) [50], Attribute clustering blocking (AC) [22], and Unsupervised blocking technique (BL) [60]. Meta-blocking approaches: BLAST [21], Redefined WNP (Wnp1) [24], Reciprocal WNP (Wnp2) [24], Redefined CNP (Cnp1) [24], and Reciprocal CNP (Cnp2) [24].
We calculated the PC, PQ, and FM measures for these 16 methods in the three datasets. The results of this comparison are shown in Table 2 (where SeMBlock was executed with
Additionally, we evaluated the efficiency of the blocking methods by the number of record pairs each method generates, as blocking aims to reduce the number of pairs to be compared in entity resolution. Table 2 shows the number of record pairs (i.e.,
PC, PQ, and FM for SeMBlock and 16 other blocking methods in the Cora, DBLP-ACM, and DBLP-Scholar datasets and comparison on the number of record pairs generated by different approaches
Moreover, we compared SeMBlock with recently released blocking methods (Rebo-I and Rebo-II) [61] in the Cora dataset. The results showed that SeMBlock outperformed both methods with respect to FM and PQ (i.e., Rebo-I (PC: 0.928, PQ: 0.694 and FM: 0.794), Rebo-II (PC: 0.935, PQ: 0.656 and FM: 0.771), and SeMBlock (PC: 0.76, PQ: 0.96 and FM: 0.85)).
Entity resolution is the process of identifying records in a data set that refer to the same entity across different data sources. To avoid the quadratic complexity of entity resolution, many attempts have been made to group similar records into blocks, prior to record matching, using blocking techniques. Available blocking methods typically do not exploit semantic criteria for the task of blocking. We introduced a semantic-aware Meta-Blocking approach called SeMBlock that exploits word-embedding based locality-sensitive hashing (LSH) for calculating semantic similarity and identifying relationships among records. The experimental results show that considering semantic relationships in the blocking process can significantly improve the quality of blocking. The size of the blocks generally gets smaller because semantic features can effectively eliminate record pairs that are textually similar but semantically different. We also compared SeMBlock with 16 available standard blocking methods. Overall, SeMBlock can be an effective blocking technique compared to these methods when the priority is to achieve high pair-quality and f-measure, without giving up a high level of pair-completeness.
In the future, first, we plan to extend SeMBlock by leveraging context information within a network environment for enhancing the applicability of SeMBlock to real-world ER problems. Second, we want to investigate the effect of combining several semantic features on the quality of blocking. Third, we intend to find an alternative to the LSH method that increases the accuracy of our method.