
Abstract
To measure semantic similarity between words, a novel model DFRVec that encodes multiple semantic information of a word in WordNet into a vector space is presented in this paper. Firstly, three different sub-models are proposed: 1) DefVec: encoding the definitions of a word in WordNet; 2) FormVec: encoding the part-of-speech (POS) of a word in WordNet; 3) RelVec: encoding the relations of a word in WordNet. Then by combining the three sub-models with an existing word embedding, the new model for generating the vector of a word is proposed. Finally, based on DFRVec and the path information in WordNet, a new method DFRVec+Path to measure semantic similarity between words is presented. The experiments on ten benchmark datasets show that DFRVec+Path can outperform many existing methods on semantic similarity measurement.
Introduction
Measuring semantic similarity between words is a very important issue in the field of natural language processing and it is widely applied to areas such as text retrieval [1], identification of Gene Ontology [2], measurement of medical language [3], identification of entities in the biological field [4], word sense disambiguation [5], sentiment classification [6, 7] and topic sentiment analysis [8].
Using semantic resource including ontology and dictionary to calculate semantic similarity is a common method. An example of ontology is WordNet [9], which is a very mature and artificially organized database for storing semantic information. WordNet contains multiple semantic information of a word, including definition, POS, form and relation, etc. The existing WordNet-based methods for semantic similarity measurement mostly rely on semantic taxonomy [10], which is derived from the relations of hypernyms and hyponyms and contains the semantic information such as path, depth and density of synsets. For example, the method of Wu [11] is based on LCS (Least Common Subsume) of two synsets and depth, the method of Zhu [12] introduces edge and density information from WordNet into the path computing model, and the method of Lin [13] is similar to the method of Wu, except that Lin uses IC (information content, i.e. the information contained in a word) instead of depth. The main advantage of the WordNet-based methods is that they can separately represent the different senses of a word, and can simultaneously contain multiple-semantic information. However, the disadvantage is that they can only represent nouns and verbs, but not adjectives and adverbs. Being limited by size and structure of WordNet, these methods are difficult to make a breakthrough in performance.
In addition, using the cosine score between word’s vectors in a word embedding model to measure semantic similarity is another common method. In recent research, the commonly used word embedding models are word2vec [14] and GloVe [15]. Note that the GloVe model mentioned in this article only refers to Glove Common Crawl by Pennington et al. with vector size of 300 dimensions and corpora size of 42 billion. However, it is difficult for word2vec and GloVe to distinguish the same word’s senses, POS and forms, without introducing external semantic information. There are many improved models based on word2vec and GloVe, such as GloVe-d [16], GW597 [16], Paragram-sl [17], and Counter-fitting [18]. Both of Paragram-sl and Counter-fitting introduce external semantic information (i.e., similarity relations for Paragram-sl, and synonyms and antonyms for Counter-fitting) and encode the information into a vector space, so they can improve the performance. However, both Paragram-sl and Counter-fitting only introduce a single aspect of semantic information.
The above research shows that the methods combining word embedding with some semantic information of words can improve the accuracy of word similarity computation. To further improve the accuracy of semantic similarity measurement of words, this paper will focus on how to design a new model to encode various semantic information of words contained in WordNet into a vector space through word embedding, and how to use it to measure the semantic similarity between words. The main contributions of this paper are as follows. Firstly, it has proposed a novel model called DFRVec, which encodes the semantic information of definition, POS, form, and relation of a word contained in WordNet into a vector space based on word embedding. Secondly, based on DFRVec, a new method called DFRVec+Path is proposed to measure semantic similarity between words. Thirdly, the proposed method has been proved to be able to increase the performance of the semantic similarity measurement by comparison experiment with related methods on ten different benchmark datasets.
The rest of this paper is organized as follows: Section 2 introduces the related work; Section 3 gives a detailed description of our new model; Section 4 is the performance comparative experiment with the existing methods; and Section 5 is the summary of our work.
Related work
The existing research methods on semantic similarity measurement can be roughly divided into three categories: Knowledge-based methods, Corpus-based methods, and Combined methods, which are described in the following sub-sections.
Knowledge-based methods
The “knowledge” refers to some semantic resources, such as ontology, encyclopedias or dictionaries, which contain different semantic information, such as definitions, POS and relations.
Ontology-based method is the most popular knowledge-based method. Over the past thirty years, ontology-based methods have been the main solution to semantic similarity measurement. WordNet is the most widely used ontology in this field. The basic unit of WordNet is a synset, which includes a unique definition and a set of synonyms. For example, the synset “smile.v.02” means the second verb sense of smile, and its corresponding definition is “express with a smile”. Only the word “smile” belongs to this synset.
Most WordNet-based methods rely on the semantic taxonomy. There are three main kinds of methods for calculating semantic similarity based on WordNet:
(1) Path-based methods: The semantic similarity between two words can be represented by the length of the path between their synsets of the words in WordNet. For example, according to Rada [19], Path model, which uses the path information to compute semantic similarity between two synsets, is defined as follows:
(2) Feature-based methods: The main idea is to represent a synset as a set of features that can reflect its attributes or aspects [10]. Feature-based methods measure the semantic similarity between words according to the structural feature of semantic taxonomy, including nodes and edges. The more common features and the fewer non-common features two synsets have, the more similar they are. Taieb [21] presented a new method to measure the semantic similarity between concepts and words based on the “is-a” semantic taxonomy. Their method combines the hyponyms and depth parameters.
(3) IC-based methods: Information content refers to the amount of information in a synset in WordNet. Early information content was measured by the reciprocal of the frequency of words. As more and more researchers continue to explore, the computing model of information content has developed to be very complex, containing more and more comprehensive semantic information. The calculation of semantic similarity has also been greatly improved such as the methods proposed by Meng [22], Adhikari [23], Cai [24], and Zhang [25]. The first step of such methods is to calculate the information content of each synset, and the second step is to compute the similarity between words based on the calculation results.
Corpus-based methods, such as the well-known word embedding of GloVe and word2vec, are commonly trained by some neural network on a very large corpus, and based on the well-known distribution hypothesis introduced by Harris, if the probability of two words appearing in similar contexts is higher, the similarity is considered higher. Compared with knowledge-based methods, corpus-based methods provide wider vocabulary coverage, and there are no restrictions on artificially constructed semantic resources. For example, WordNet-based methods are mostly unable to measure semantic similarity between adjectives and adverbs. Recently, many researchers have proposed various models of word embedding, and achieved good results. For instance, FRAGE [26] is an improved word embedding model related to semantic similarity measurement. It can solve the problem that the embeddings of a rare word and a popular word can be far from each other even if they are semantically similar, and make learned word embeddings more effective. In general, word embedding maps words in a vocabulary to the corresponding dense vectors and has different linear characteristics determined by its training algorithm [16].
In the field of semantic similarity research, corpus-based methods are better than knowledge-based methods in general. But word embedding also has its weaknesses. For example, in processing the problem of polysemy, word embedding is powerless as it does not consider the senses, POS, forms and relations of words.
Combined methods
Combined methods, which combine the advantages of knowledge-based methods and corpus-based methods, have become a popular research area in recent years. Especially, the combination methods of WordNet and word embedding have achieved better results.
For example, Lee [16] proposes several simple and feasible ideas for optimizing the word embedding and for combining word embedding and WordNet, and then presents three methods, i.e. GloVe-d, GW597 and GW597 + Path. The GloVe-d with three abnormal dimensions removed achieves very good performance. The GW597 with 597 dimensions that combines GloVe-d and word2vec is a state-of-the-art method on semantic similarity measurement. The GW597 + Path that combines GW597 with Path outperforms GloVe-d and GW597.
In GW597 + Path, the semantic similarity between words wi and wj is defined as follows:
The Counter-fitting model proposed by Mrkšić [18] uses the antonyms and synonyms in PPDB (Pesticide Properties Database) and WordNet to tune word vectors. Another model Paragram-sl proposed by Wieting [17] is tuned with SL999 dataset [27] by rewarding exclusively similarity relations in word vector model. Scheepers [28] proposes a new idea, which is to combine the semantic information contained in the definitions of word’s synsets in WordNet with word embedding, and uses a data set that consists of the definition sentences to train and test a new model. All of these models are combined with external semantic information to tune word vector model, and have achieved very good results. However, the vocabulary of their models is relatively small, and both the size of the vocabulary and the scale of external semantic information need to be further expanded. In addition, various types of semantic information should be considered to improve the capability of the vectors to represent different types of words.
In our proposed model DFRVec, various semantic information, which is described artificially and elaborately in WordNet, such as definitions, POS, forms and relations of synsets of a word, is applied to generate a new vector representation of the word. DFRVec encodes the multiple semantic information of a word into a vector space (a set of vectors) by using an existing word embedding model. DFRVec not only includes three new sub-models, DefVec (to encode the definitions), FormVec (to encode the POS and forms), and RelVec (to encode the relations), but also combines the word embedding (to retain the semantic information learned from a corpus).
The process of DFRVec model is shown in Fig. 1. Here, it is supposed that word w has r synsets in total, Synsetw,1, ... , Synsetw,r. DFRVec’s encoding result for w is a set of vectors, DefVecw,1, ... , DefVecw,r, each of which consists of the vectors from DefVec, FormVec, RelVec and the vector vw from word embedding model.
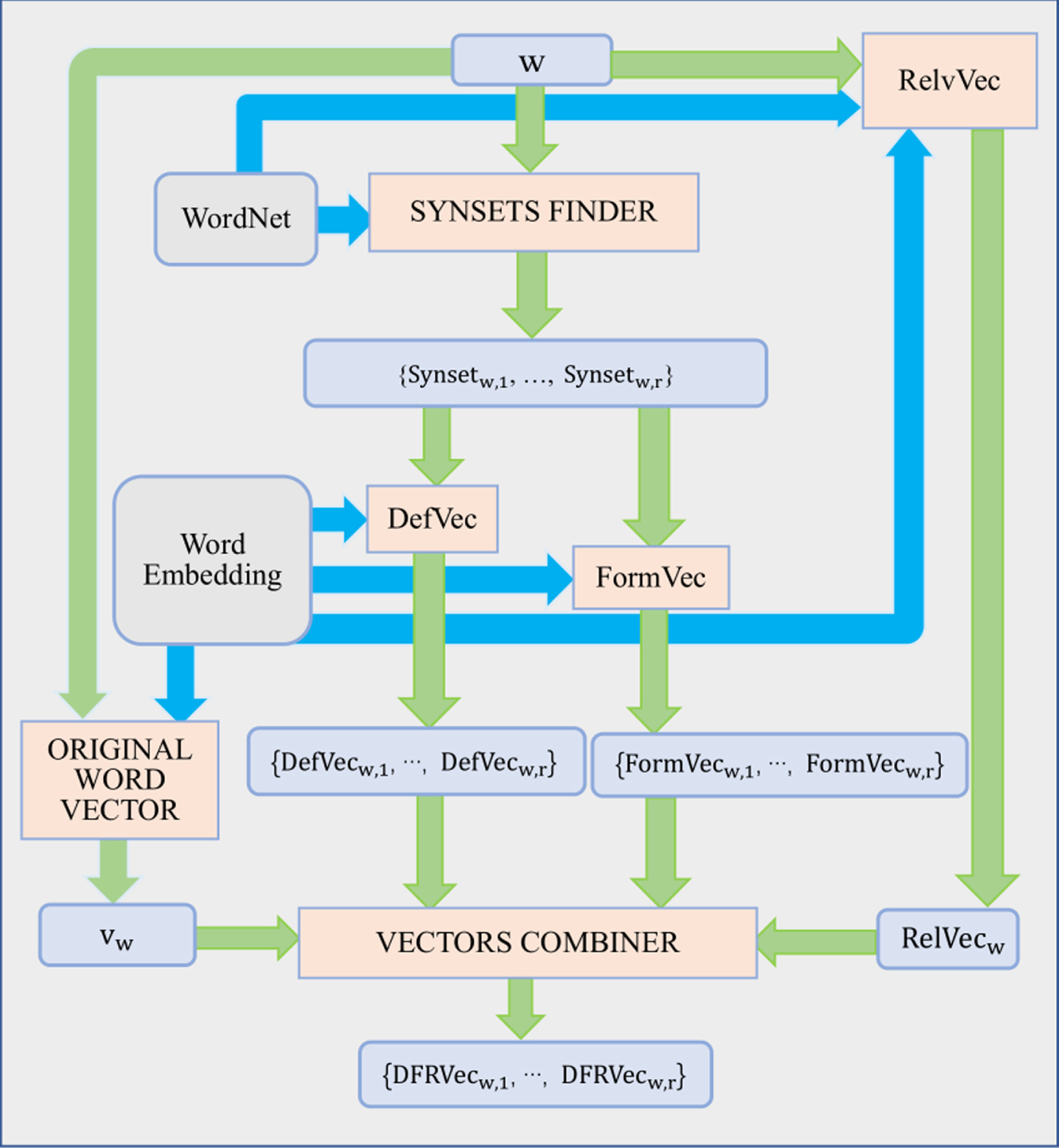
The process of DFRVec model of encoding various semantic information of a word in WordNet into a vector space.
These models will be introduced in detail in the following sub-sections respectively.
Each synset of a word in WordNet has a corresponding unique definition, which describes important semantic information of the synset. Duong [2] represents each gene ontology term by the vector obtained by using an existing sentence encoder to encode the term’s definition given in Gene Ontology Database, and then estimates the similarity of two terms through their vectors. It is a good way to map the definition of a word into a vector to represent the word. However, different from Duong’s method [2], a new encoder DefVec sub-model is designed in this paper to encode the semantic information in each definition into a vector representation through word embedding.
Let w be the target word, to calculate the DefVecw,i vector of i’th synset of w, DefVec model firstly represents w and the words in the definition of the synset as vectors through word embedding; then calculates the cosine similarity score between each word in the definition and w; thirdly removes those words in the definition whose scores are less than a given threshold; finally, takes an average vector of the remaining words’ vectors.
The detailed computation process of DefVecw,i is described as follows:
Step 1. The word set Defsw,i of length D is obtained from the synset’s definition after tokenizing and removing numbers, punctuations, and stopwords from NLTK. Defsw,i is represented as follows:
Step 2. Defsw,i’s corresponding vectors set Vw,i is represented as follows:
Step 3. Applying an average value function to Vw,i, we can obtain a vector:
POS is a basic semantic feature that is available for each synset of a word in WordNet. Many word embedding models do not pay attention to the semantic features such as POS. In word embedding, on the one hand, a word with more than one POS may correspond to the same vector representation; on the other hand, one POS of the word may have one or more different forms which have different vector representations in the word embedding. For example, the word ‘smile’ has two POS: noun and verb. Its noun forms are “smile” and “smiles”, while its verb forms may be “smile”, “smiles”, “smiled” and “smiling”, and those forms may have different vector representations.
Therefore, the proposed FormVec sub-model is designed to encode the semantic information of POS and forms in each synset into a vector space through word embedding. The new model can distinguish the different POS of a word, and at the same time bring the synsets of the word with the same POS closer to each other.
Given a target word w, the FormVecw,i vector of the i’th synset of w is computed by the following three steps:
Step 1. Find the set of all possible and different word forms for the i’th synset of w (note that the target word w must be excluded in it), which is represented as follows:
Step 2. The vectors set Vw,i of length S (S is the number of words in Formsw,i) from word embedding model is represented as follows:
Step 3. The vector to encode the POS of the i’th synset of w is represented as follows:
In WordNet, there may be manually defined relations between two synsets of words. Therefore, a word may be connected with other words through their relations. Based on a word’s related neighboring words, including words from definitions and lemmas of related synsets, Jimenez [29] propose a new method called word2set to obtain a word representation, and then find two words’ intersection sets of related neighboring words to measure their similarity. The method is effective but may be too simple to achieve high performance on semantic similarity measurement. We think that by encoding these words into a vector space it may get a better word representation for semantic similarity measurement. Therefore, a new RelVec sub-model is designed to encode the related words of a word into a vector space through word embedding. Otherwise, when computing the related neighboring words, RelVec considers only the words from related synsets.
In this paper, the following relations can be considered: Hypernyms, Instance Hypernyms, Hyponyms, Instance Hyponyms, Member Holonyms, Member Meronyms, Substance Holonyms, Part Holonyms, Substance Meronyms, Part Meronyms, Attributes, Entailments, Causes, Also See, Verb Groups, and Similar To. For example, as is described in Fig. 2, “smile.n.01” is one synset of word “smile”, and it has three related synsets, “smirk.n.01”, “simper.n.01” and “facial_expression.n.01”, respectively connected by relations Hyponyms, Hyponyms and Hypernyms. In addition, it is connected by no other relations. Note that antonyms are not considered, because the vectors of antonyms and target word in word embedding usually have a high cosine similarity.
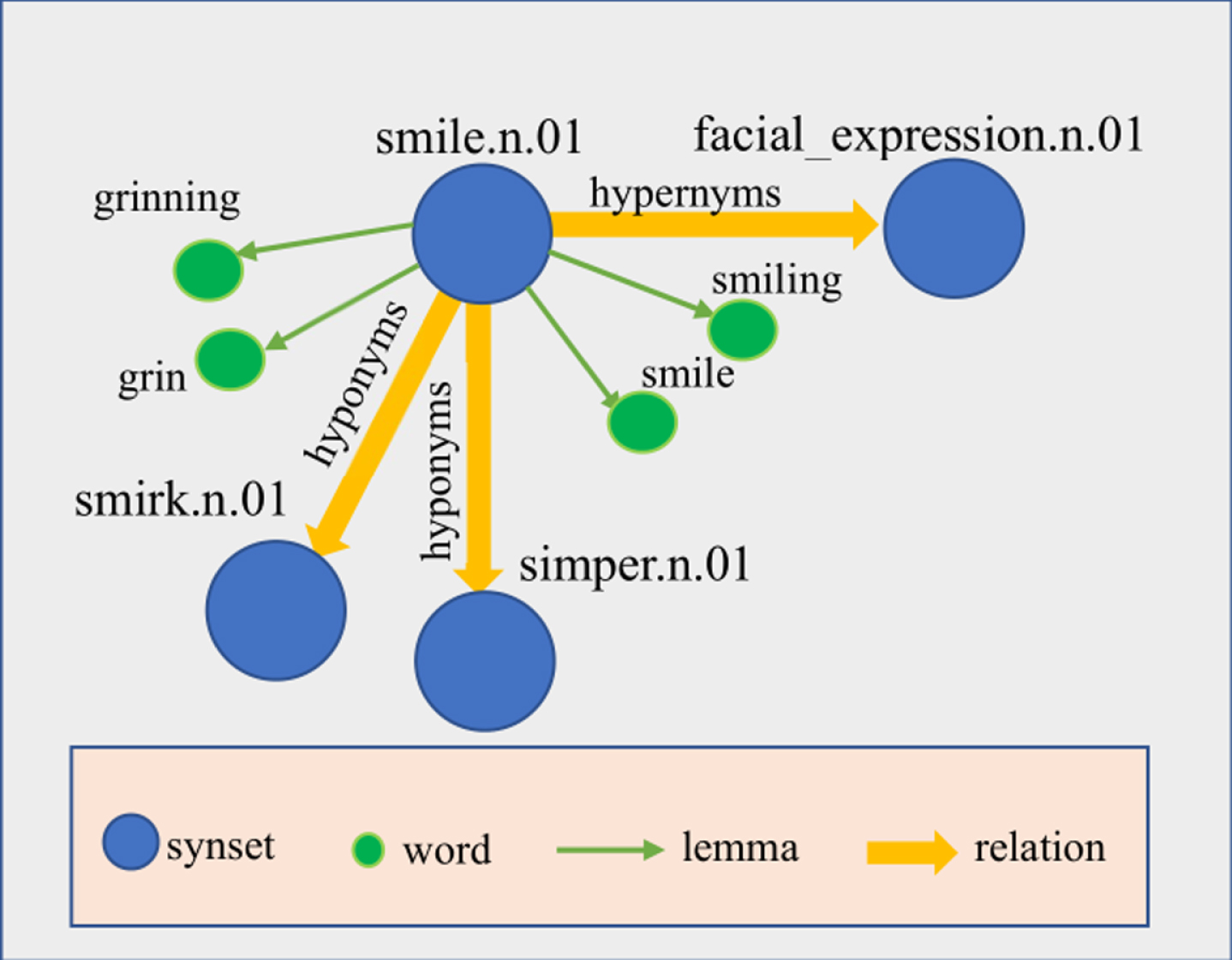
Elements involved in RelVec method using WordNet.
Given a target word w, the RelVecw vector is computed by the following four steps:
Step 1. Get all the related synsets set of w, RelatedSynsetsw, which is defined as follows:
Step 2. Get a set of related words by merging the words contained in each of the related synsets set RelatedSynsetsw except w itself, as follows:
Step 3. According to Relsw, find the corresponding set of related word vectors Vw in word embedding, as follows:
Step 4. An average value function is applied to Vw and RelVec is obtained as follows:
As shown in Fig. 1, DFRVec is composed of the above three sub-models (DefVec, FormVec, and RelVec) and the original word embedding. The composing process is shown in Fig. 3. N is the dimension of vw, and the vector representation DFRVecw,i of the i’th synset of a target word w is defined as follows:
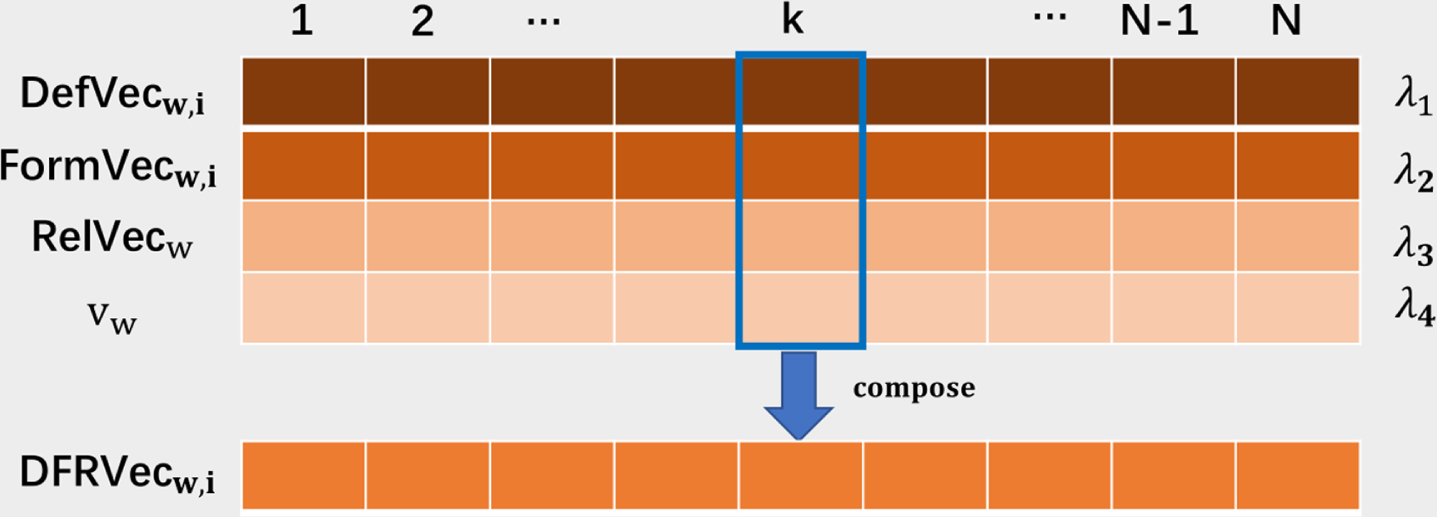
The DFRVec vector of composing the vectors of DefVec, FormVec, RelVec and the original word embedding.
After encoding the various semantic information of a word into a vector space by DFRVec model, a new semantic similarity calculation model can be derived based on it. Through the DFRVec model, for a pair of words we can obtain respectively two sets of vector representations of all their synsets, which correspond to all senses of the two words, and so the similarity of the pair is defined as the maximum value of the cosine values between their vectors in our research.
Formally, given two words w
i
and w
j
, the semantic similarity between them is computed as follows:
According to the research of Lee [16] and Lastra-Díaz [20], when calculating the semantic similarity, a linear combination of the two similarity scores, a word-embedding-based method with a WordNet-based method, can achieve good results. In that case, by combining DFRVec and the Path method, the new semantic similarity between two words w
i
and w
j
in this paper can be finally computed as follows:
As the influence of choosing different WordNet-based method on the final model in formula (9) is not the research focus of this article, also for comparison with method GW597 + Path, the simpler Path method that only considers path information is chosen to combine with DFRVec.
When training DFRVec model, the vocabulary of this model is based on the vocabulary of the selected word embedding model during the encoding process of DFRVec model, and all the words with zero synset in WordNet are eliminated.
The training process can be described as the following four steps:
Step 1. The vocabulary W of size N used in both word embedding and WordNet (their intersection) can be defined as follows:
Step 2. According to Sections 3.1, 3.2, and 3.3, we can find out respectively the definition words’ collection Defs, the POS and form words’ collection Forms, and the relation words’ collection Rels by W.
Step 3. The vector collection V of size L, which is the union of the four vector collections that are computed from the four models of DefVec, FormVec, RelVec, and word embedding respectively according to Defs, Forms, Rels, and W as described in Sections 3.1, 3.2, and 3.3, can be defined as follows:
Step 4. According to the DFRVec model in Section 3.4, we can generate our target vector collection V′ based on V:
In this section, the evaluation of measuring semantic similarity using DFRVec model and different combinations of the three sub-models are described. Also, this section evaluates the performance of multiple existing word embedding models working with the proposed model.
Experiment setup
All experiments described in this section are performed on an Intel Core I5, 2.9 GHz processor machine with 16 GB RAM, 500 GB hard disk, and Windows 10 system. All algorithms are implemented in python.
Evaluation metrics
Pearson correlation (r), Spearman rank correlation (ρ), and the harmonic mean score (h) of Pearson correlation and Spearman rank correlation are used in this paper. Pearson and Spearman correlations are defined between the human judgments X and the values of the semantic similarity Y. These formulas are defined as follows:
As far as any scaling or translation of the data is concerned, the Pearson correlation is invariant, while the Spearman rank correlation is rank invariant, which means that it has the same value for any arbitrary monotone data transformation. In order to compare the performance of the methods evaluated in our experiments, we introduce the average values of Pearson correlation, Spearman correlation, and Harmonic mean score in all datasets.
In order to evaluate the general performance of the proposed model, the experiments have been performed on ten benchmark datasets. The detailed information of the datasets is introduced in Table 1.
Detailed information of the 10 datasets
Detailed information of the 10 datasets
Notes: The column Content describes the POS of each dataset.
Two word embedding models, word2vec [14] and GloVe-d [16] (GloVe with three dimensions removed), are used to encode sematic information in our experiments to verify the performance of the proposed model on sematic similarity measurement.
When using a word embedding model to train DFRVec model, the vocabulary is the intersection of the two vocabularies of the word embedding model and WordNet. When using word2vec to train DFRVec model, the size of the vocabulary is 207119, and about GloVe-d, the size is 116823.
Evaluation results
Performance of the three proposed sub-models
In order to evaluate the performance of DefVec, FormVec, and RelVec proposed in Section 3, we consider three situations in this experiment: 1) only one sub-model is composed of the original word vector model; 2) only one sub-model is not composed of the original word vector model; 3) the three sub-models are composed of the original word vector model. In all the three cases, the weighting factors (λ1, λ2, λ3, λ4) in formula (7) are evenly distributed. For example, in the third case, the parameter is set to (0.25, 0.25, 0.25, 0.25).
The experiment results are shown in Table 2 and Table 3. In the two tables the semantic similarities of words w i and w j of all the methods are the cosine value between their corresponding vectors.
Pearson(r) values for DFRVec models in different sub-models and existing word embedding models
Pearson(r) values for DFRVec models in different sub-models and existing word embedding models
Spearman (ρ) values for DFRVec models in different sub-models and existing word embedding models
Notes: In Tables 2 and 3, DFRVec_word2vec means the specific DFRVec when uses word2vec to encode sematic information, and DFRVec_Glove-d is the same meaning but uses Glove-d. Each value of the column Avg(.) is the average value of the 10 datasets’ values in the same row.
It can be seen from Tables 2 and 3 that, to semantic similarity measurement, DefVec, FormVec and RelVec models have a significant improvement when working with word2vec and GloVe-d. Furthermore, according to the avg values, among the three sub-models, DefVec has the best performance and FormVec performs the worst. So, when composing the three sub-models in DFRVec model according to formula (7), DefVec may take a larger weight and FormVec smaller.
On RW dataset, the three models perform relatively poorly, although most of their results still improve. The reason may be that the words contained in this dataset are mostly rare words, and their semantic information in WordNet may be insufficient.
The second experiment compares the performance on semantic similarity measurement of our DFRVec model, which encodes the sematic information of definition, POS, forms, and relation described in WordNet with different word embedding model, with the eight existing methods described in Section 2, including one knowledge-based method: Path [19]; four corpus-based methods: word2vec [14], GloVe [15], GloVe-d [16], GW597 [16]; and three combined methods: GW597 + Path [16], Paragram-sl [17], Counter-fitting [18], GW597 + Path [16]. In this experiment, it is very important to decide the weighting factors of λ1, λ2, λ3, andλ4. To find out a set of relatively better weighting factors for all the ten datasets, the grid-search method was used, and the changing range of λ1 is 0.3, 0.35, 0.4, λ2 is 0.1, 0.15, 0.2, and λ3 is 0.2, 0.25, 0.3, based on experience.
When applying DFRVec model to word2vec (called DFRVec_word2vec) and GloVe-d (called DFRVec_ GloVe-d), the best weighting factors of both cases are 0.3, 0.15, 0.3 and 0.25.
The method DFRVec597 of 597 dimensions is a combination of DFRVec_word2vec and DFRVec_GloVe-d by concatenating vectors of corresponding words and synsets. The method DFRVec597 + Path is a linear combination of DFRVec597 and Path. But in the two methods, the weighting factors are 0.3, 0.2, 0.25, 0.25 for word2vec and 0.3, 0.15, 0.25, 0.3 for GloVe-d.
Although DFRVec597 + Path is similar in form to GW597 + Path, both of which use ideas of concatenating vectors of two word embedding models and linear combination of word embedding model and WordNet-based method, DFRVec597 + Path is fundamentally different from GW597 + Path in that GW597 directly concatenates word2vec and GloVe-d, but DFRVec597 firstly encodes multiple types of semantic information from WordNet into vectors DFRVec_word2vec and DFRVec_GloVe-d through word2vec and GloVe-d based on our DFRVec model respectively, and then concatenates them.
The results of the second experiment are described in Table 4.
Pearson(r), Spearman (ρ) and Harmonic(h) values of our models and the other compared methods
Pearson(r), Spearman (ρ) and Harmonic(h) values of our models and the other compared methods
In Table 4, the sematic similarity of words w i and w j , for Path is formula (3); for GW597 + Path is given in formula (2); for Counter-fitting, Paragram-sl, word2vec, Glove, Glove-d, GW597, and DFRVec597 are all the cosine similarity cos(vwi, vwj); and for DFRVec597 + Path is a linear combination of the similarities of DFRVec597 and Path, which is computed by formula (9), as the same as those of GW597 + Path, which is given in formula (2). The best value for each dataset is shown in bold.
It can be seen from Table 4 that: 1) For each of the three evaluation values of Pearson, Spearman and Harmonic score, the proposed method DFRVec597 + Path obtains the best result on the ten datasets among the compared methods (including the times of getting the best result and the average value on the ten datasets); 2) The performance of DFRVec597 is better than that of DFRVec_word2vec and DFRVec_GloVe-d, which indicates that it is effective to concatenate their corresponding vectors; 3) Compared with DFRVec597, the performance of DFRVec597 + Path is significantly improved, which means that the linear combination of DFRVec597 and Path is effective; 4) Counter-fitting and Paragram-sl perform better than our methods on SL665, SL999 and RW. This is because that Counter-fitting and Paragram-sl were trained on SL999, and SL665 is a subset of SL999. In addition, in RW the numbers of words, which are actually measured by Counter-fitting and Paragram-sl, are only 873 and 1015, more than half words fail to represent.
We have also compared our DFRVec597 + Path with FRAGE [26]. Since on semantic similarity measurement only the experimental results of spearman(ρ) on RG65, WS353 (named as WS in [26]) and RW datasets have been done in [26], in Table 5 there are only three datasets and the results are directly copied from Gong’s paper. As we can see in Table 5, our proposed method is better than FRAGE except on RW dataset.
Spearman(ρ) values of our DFRVec597 + Path and FRAGE
This study focuses on how to improve the measurement accuracy of semantic similarity between words, from the perspective of how to encode the various semantic information of words of WordNet into a vector space through word embedding by designing a new model, and how to use it to measure the semantic similarity between words.
Firstly, three sub-models DefVec, FormVec and RelVec, which are used to respectively encode the semantic information of definition, POS and relation described in WordNet into a vector space by using an existing word embedding model, are presented in this paper. Then by combining the three sub-models with the word embedding, a novel model DFRVec is designed. Lastly, based on DFRVec and the path information in WordNet, a new measuring method DFRVec+Path for semantic similarity between words is proposed, which can achieve better performance when compared with many existing methods of semantic similarity measurement.
The significance of the proposed model is that it encodes various semantic information included in WordNet into a word embedding vector which can be used to measure semantic similarity of words more precisely. It can solve the problems that the methods based on word embedding cannot distinguish the senses and POS between two words, and that the performance of the methods based on WordNet is relatively low. However, the model proposed in this paper also has some limitations. For example, the method of encoding semantic information is relatively simple and the source of semantic information is not diverse. Future research may involve the following aspects: (1) apply more effective methods to the process of encoding semantic information, such as neural networks; (2) introduce more external semantic resources, such as PPDB.
Footnotes
Acknowledgments
This work was supported in part by the Humanities and Social Sciences Research Project of the Ministry of Education of China (No. 18YJA740015), and by Chongqing Key Laboratory of Software Theory and Technology, Chongqing, China.
A natural language processing toolkit based on python.