
Abstract
Video condensation or synopsis is an effective solution for problems regarding video storage and video browsing. The proposed model contributed to developing the video condensation framework for efficient video browsing and video retrieval. In the first stage, the videos are gathered from the surveillance videos. Here, the frames are generated, and then the video backgrounds are extracted. The objects from the frames are acquired through the support of Yolov3. Next, the optimal stitching is done based on the time and object activity of video frames using the Improved Blue Monkey Optimization (IBMO) algorithm. Moreover, video condensation is performed to get the compact video for making better browsing and retrieval of video. The video browsing and retrieval are performed under two phases such as training and testing phases and both phases are done by gathering the videos and followed by the feature extraction using VGG16, where the heuristic improvement is made by the same IBMO algorithm. Then, the extracted deep features from video segments are clustered based on Fuzzy C-means (FCM) clustering for combining the extracted features. These features are stored in the feature database in the training phase. Next, in the testing phase, video browsing and retrieval are performed by considering the queries gathered from the standard dataset. The features of query videos are extracted, which are compared based on Multi-Similarity Function (MSF) with the features in the database for retrieving the video segments. Experimental results show that the developed IBMO-VGG-MSF-based video condensation saves computational loads compared to the previous methods without compromising the condensation ratio and visual quality.
Keywords
Introduction
Humans have implemented various manual video retrieval schemes, which are more tedious and time-consuming. Moreover, these manual systems are highly prone to errors and produce incorrect retrieval results. The current technological era needs automatic schemes for the retrieval of videos concerning offline videos and internet videos to support users’ specifications [1]. The video retrieval systems are applicable in diverse areas of data science that include education, entertainment, video archiving, surveillance, news, advertising, and also over the medical domain. In large cities, human activities are monitored and recorded by surveillance cameras, which have been fixed widely in outdoor and indoor environments [2]. A large set of surveillance cameras are adopted for recording all events 24 hours/a day. The specific targets are searched by watching surveillance videos, which are highly sensitive to labor-intensive [3]. The important task is to effectively utilize the surveillance videos and obtain valuable information from the recorded surveillance videos. This may generate more time for retrieving, so the video condensation methods are developed. Here, the relevant segments are retrieved from the original surveillance videos based on the user queries, and the video condensation methods can acquire specific targets very quickly [4]. The retrieval of exact segments from large surveillance videos based on semantic queries is a challenging issue nowadays [5]. Several minutes of browsing on a several-hour video extraction are more helpful for the users since it assures minimum time for video retrieval. The main aim of this developed browsing system is to filter only the relevant segments by preserving all other object activities to get the specific target from the long duration of surveillance videos [6], which provides better support to the users. Many researchers considered the video retrieval systems in the good literature reviews that have been published. The challenging task is understanding the semantic gap between video content and user intentions [7].
The surveillance video contains a wide range of behavior, and hence, the retrieval of videos based on the understanding ability of the user requests and user query is very difficult [8]. This difficulty arises since there is no clear idea about the specific targets for making the video retrieval system. In addition, another challenge is to extract the moving objects from the original surveillance video and segment the moving objects related to the specific condition under a real-world environment [9]. The factors such as occlusion, shading, and lighting may affect the segmentation results. In usual scenarios, unexpected factors make it difficult to retrieve moving and tracing objects [10]. The collection of all compact frames is condensed and preserved based on the location and also gets customized for the target objects on the background images [11]. The three main characteristics of the compact video are that (a) it is short enough for video browsing; (b) it is considered as the significant component related to moving objects in the source video, and (iii) it preserves the temporal features of moving objects partially for the users to understand the original video. The system directly displays the appropriate video clip by localizing the targets rapidly when the user can browse the compact video [12]. The main aim of this video condensation and video retrieval system is to spend a short period of time watching and monitoring long surveillance videos.
Deep learning achieves greater success in video retrieval in several applications like visual tracking, object recognition, and visual analysis, where the deep features are directly learned from the pixels and voxels in the videos [13]. Moreover, the objects with background and moving targets are effectively identified based on this deep learning structure [14]. The features for video representation are efficiently extracted using Deep learning networks like Convolutional Neural Networks (CNN), and the temporal features are eliminated with the support of hashing function [15]. The manual detection process needs more time to retrieve the objects from the image or video, which can be resolved by deep learning techniques. The hidden factors are learned automatically by using multi-level nonlinear mappings in the neural networks [16]. The accuracy of the video retrieval process is highly increased using these approaches [17]. Hence, this research focused on developing a new video browsing and retrieval system using a deep learning structure.
The major contribution of the developed deep learning-based video browsing and retrieval system is described below.
To design an efficient deep learning-aided video condensation model for video browsing and retrieval system to quickly retrieve video clips or contents from long-duration videos based on the user queries in surveillance video. To develop an effective video condensation system, where the background is extracted from the long video initially, and then the moving objects are detected using the YOLOv3 classifier. Frame stitching is carried out, where the stitched frames are optimally selected using the developed IBMO based on the objects’ activity and time interval to get the condensed video with a highly minimized object uncovered rate. To implement an IBMO for selecting the frames to be stitched in the condensed video and optimizing the parameters such as epochs and the steps per epochs in the VGG16 network to enhance the F1-score in the retrieval system. To develop a video browsing and retrieval process in a surveillance system based on user queries, where the features are extracted from the condensed video using VGG16 and then generated the clustered segments using FCM, and then MSF is used to check the similarity of the query and stored data to appropriately retrieve the respective videos. The efficiency of the developed model is validated over various heuristic algorithms and existing video retrieval models in terms of precision, recall, and F1-score.
The remaining section used in the developed video browsing and video retrieval system is given as follows. Section 2 describes the existing video retrieval systems with their features and challenges. Section 3 summarizes the dataset details and the description of the structural model. Section 4 explains YOLOv3-based object detection, the proposed IBMO algorithm, and video condensation. Section 5 illustrates the VGG16-based feature extraction, FCM-based clustering, and testing and training phase with user queries. Sections 6 and 7 provide the experiment results and conclusion of the developed video browsing and retrieval system.
Related works
In 2015, Chieh and Fang [18] have recommended a surveillance video browsing and retrieval system for locating the desired targets quickly to the appropriate users. The most significant information regarding moving objects was gathered from surveillance videos for constructing the relevant compact video. The compactness of the video was increased by rearranging the temporal coordinates of the moving objects from the relevant compact video. The essential activities from the original surveillance video have been preserved based on the visual appearance of moving objects. The watching time of the compact video has been highly minimized by using the developed model by avoiding the monitoring of long surveillance videos for several hours. Moreover, several experiments have been conducted to demonstrate the quick look at specific targets from the surveillance videos via the newly implemented system.
In 2017, Ding et al. [19] have designed a large surveillance video retrieval system by exploiting the data characteristics and big data processing procedures. The entire system has been functioning based on the motion information from the videos. Initially, the video was segmented concerning the relevant data, and then the basic unit was named M-clip after segmentation. The data volume was highly reduced by neglecting the redundant video content via the M-clips. The human detection and extraction of motion or appearance features have been done via the MapReduce framework for processing the M-clips. Only the sub-areas instead of entire frames have been processed through vision algorithms on the significant motion vectors. The developed model outperformed by evaluating the experimental results based on satisfactory human retrieval accuracy with computational time.
In 2020, Cheng et al. [20] have proposed a deep learning and cloud-based face video retrieval system to provide greater accuracy. Initially, the gathered data was pre-processed to remove the blurs and then performed the face alignment on the remaining images. After that, pre-training was done via FaceNet, ArcFace, and VGGFace for face recognition. The final results have been compared to three different models to choose the most efficient one to develop the system. Moreover, the system’s feasibility has been verified by the implementation of the prototype in the proposed system. The implementation outcome ensured that the developed system performed well than the other models concerning computational time and recognition accuracy.
In 2020, Poornima and Saleena [21] have presented a deep learning strategy that adopted a video retrieval scheme, where keyframe extraction was performed for the retrieval of useful keyframes from the original video. The retrieved keyframe features were stored in the feature database. For instance, the FCM procedure has been utilized to cluster the retrieved features. Consequently, these clustered features have been given into the deep structure to determine the optimal centroid. Different categories of videos have been considered for the experimentation for performing the retrieval based on both the video query and the text query. From the test results, the developed video retrieval system attained improved performance than other video retrieval systems based on the consideration of certain measures like F-measure, recall, and precision.
In 2022, Kumar and Seetharaman [22] have offered a Modified Visual Geometry Group _16-based deep learning strategy for the extraction of features from the video. The indexing value has been assigned to all video files to improve the efficiency of the video retrieval process. The experimental results were compared among various video extraction approaches such as Convolution Neural Networks (CNN), Local Binary Patterns (LBP), and Histogram of Oriented Gradients (HOG). The developed system has provided elevated video retrieval performance when analyzing measures like precision, F1 score, recall, and accuracy.
In 2020, Ullah et al. [23] have introduced a pre-trained 3D-CNN-based event-oriented feature selection framework by deeply investigating the response and weights to a particular event. Here, the neurons were semantically eliminated from the original video, which did not respond to an event. Additional storage was needed for storing the event-oriented convolutional features because they have huge dimensions and require more time to retrieve features. Then, the Principle Component Analysis (PCA) was utilized for generating compact binary codes from these features. The major benefit of this developed video retrieval system was to provide very efficient results over large-scale databases. The implementation results have been verified over HMDB51 and UCF101 datasets, and the created compact codes accomplished greater effectiveness according to the recall, precision, and execution time.
In 2020, Nguyen et al. [24] offered a video condensation scheme to fast monitoring of moving objects in surveillance videos, which has a long duration for the entire video. The effectiveness of the video condensation algorithm has been analyzed based on the condensation ratio and computational complexity. At first, the non-moving objects from the video frames were discarded. Secondly, frame grouping has been done via the intra condensation over the moving objects and then done inter- condensation. The temporal static pixels and the spatiotemporal static pixels among Intra and inter-condensation were dropped to shorten the temporal distances. The effectiveness of the developed model was observed to be high when analyzing the experimental results of this video condensation without sacrificing the visual quality and condensation with a less computational load than the conventional video condensation methods.
In 2015, Zhu et al. [25] have proposed an online content-aware framework for providing a video condensation system. The tube rearrangement of the optimization problem has been converted into a stepwise optimization problem in this video condensation system. Hence, this developed model has achieved a higher convergence rate and less memory requirement when compared to the offline framework. The condensed videos have been obtained simultaneously by using this transformation technique, and the proposed system has been highly suitable for real-time endless surveillance videos. The experimental result has been analyzed over various video condensation schemes, and the results were shown that the developed model achieved higher performance in terms of execution speed.
Problem statement
Some recent video retrieval techniques are reviewed in Table 1. Temporal sequencing [18] is more helpful in discovering the specific targets for users in surveillance videos and increases the compactness of the video by minimizing the processing time. It does not apply to the GPU implementation of our system. MapReduce framework [19] achieves better human retrieval accuracy and takes less computational time even processing large-scale surveillance videos. It suffers from breakages in video semantics during the video segmentation process. CNN [20] has reached higher recognition accuracy on the face from the videos and reduces the computational time, and increases the feasibility of the system. The real-time design of this framework is limited. DBN [21] efficiently retrieves the data regarding F-measure, precision, and recall and achieves superior performance because of the enhanced key frame extraction process. It suffers from a high processing time when retrieving text and video queries. CNN [22] shows better performance on video frame retrieval regarding metrics like F1 score, precision, recall, and accuracy and achieves better performance with the help of extracting the video image frames. It is not applicable for processing larger datasets. 3D-CNN [23] effectively retrieves videos from huge-scale databases and reduces the execution time, and attains superiority in terms of recall and precision. It suffers from processing small-scale datasets. Intra-GoFM [24] achieves faster and order-preserving condensation and reduces the computational burden, and enhances performance. It suffers from processing long sequential videos. SILTP [25] attains better video condensation performance and achieves higher outcomes regarding condensed video with lower memory. It suffers from background consistency. Thus, there is a need to suggest a video condensation model for effective video browsing and retrieval, especially for surveillance applications. The advantages of the offered video retrieving system are listed below. While retrieving the text and video queries, the designed method provides better performance and it provides a low processing time. Moreover, it can perform in real-time large complex datasets to provide the enhanced performance of the designed model. Hence, it provides a clear background consistency from the retrieved videos. Consequently, it provides sufficient results to enhance the reliability of the system’s performance.
Features and challenges of existing deep learning-based video retrieval systems
Features and challenges of existing deep learning-based video retrieval systems
Video condensation with video browsing and retrieval framework
For security and monitoring purposes, video surveillance systems are adopted in many venues, such as shopping malls, railway stations, and airports. Searching for people in crowded places is very challenging with long-duration surveillance videos based on feature representations due to the changes in weather and climate conditions. Rapid retrieval of moving objects in surveillance videos is necessary and desirable in a broad spectrum of real-world applications. Watching surveillance videos for searching specific targets with the support of humans are highly labor intensive, and extracting valuable information from long-duration videos is also very difficult. Several techniques are designed for retrieving video segments from a specific period to provide proper content corresponding to the user requirement, which is observed to be a very difficult task in video surveillance systems. The important challenge is that the skipped frames have missed some necessary content from the video. Several video condensation algorithms are developed based on extracting spatial and temporal features from the video, which gives a low condensation ratio, but if the nearest objects are in different directions, then the condensation performance is very poor. Hence, several tube filling-based condensation algorithms are developed to provide efficient results, but they suffer from the requirement of excessive memory storage for storing the videos. To address these issues, a deep structure-based video condensation and video browsing and retrieval system are developed by adopting heuristic algorithms to provide quick results over user-specified videos from large-duration videos. The structural representation of the developed video browsing and retrieval system is given in Fig. 1.
Architectural illustration of developed deep structure-based video browsing and retrieval system.
An efficient video condensation adopted video browsing and video retrieval system are designed, which helps users quickly look into the target of interest that is highly required over the long surveillance videos. The basic idea is to gather all the objects that, include the background and the moving objects, which carry the most relevant information in the surveillance videos and then construct a single compact video based on the extracted information. Firstly, the required large surveillance videos are taken from publicly available databases, and the background is extracted from the videos. The background is extracted in the format of keyframes. Secondly, the moving objects from the videos are extracted using the YOLOv3 model based on the time and object activity in the video. Consequently, the frame stitching is carried out over the detected objects, where the frames to be stitched are determined with the help of the developed IBMO algorithm. Thus, the selected frames with detected objects are stitched in the background frame, and finally, the condensed video is obtained. The objective function of the developed IBMO algorithm is to minimize the rate of objects uncovered from the surveillance videos. Thirdly, the condensed video is given to video browsing and retrieval operation, where the condensed video is segmented into many frames, and the deep features are extracted using the VGG16 network. In this VGG16, the epochs and the steps per epoch are optimized using developed IBMO to maximize the F1-score. These extracted deep features are clustered into more segments using the FCM clustering algorithm to get segmented videos, and then the clustered segments are stored in the feature database. This storing process is done in the training phase, and the testing phase, user queries (image or text) are stored in the database, and the features are extracted from the queries, which are subjected to MSF concerning Euclidean distance and cosine similarity for comparison of previously stored clustered video segments. If the Euclidean distance and cosine similarity values are observed to be low, then the retrieval of the appropriate video from the database occurs based on a user query within a few minutes. The efficiency of the developed video browsing and video retrieval system is analyzed with various conventional models regarding precision, recall, and f1-score.
The surveillance videos are obtained from the Kitware database, and the name of dataset 1 is ‘VIRAT’ which is available on the online source of “
Dataset 2 utilized for this video retrieval scheme is “Visor” which is available in the online source of “
Sample surveillance videos from Dataset 1 and Dataset 2.
The input videos are indicated by
YOLOv3-based object detection
The frames from the large surveillance videos
The detection kernel used by the YOLOv3 model is
Residual box and skip connections: The residual layers are used in the YOLOv3 object detector to vanish the gradients by determining the deviations in the identity layers. The output obtained from one layer is subjected to an input of the next layer to avoid convergence degradation problems. Instead of performing direct mapping, skip connections are used in the YOLOv3 object detector to ensure the direct transfer of input from the immediate layer to the further layer.
Grid cells: The real-time video is divided into
Bounding box regression: The objects are highlighted by providing outlines in the video frame with the help of bounding boxes. The output layer determines the confidence probability, dimensions, objectness score, and the coordinates of the bounding boxes.
IoU: The essential feature of the YOLOv3 object detector is the IoU, which helps to describe the overlapping of bounding boxes. It evaluates the similarity between the round truth bounding box and the predicting bounding box. Then, the comparison is made between the ratio of the overlapping region to the total combined area that is represented below Eq. (1).
Finally, object detection is done in the YOLOv3 with the help of IoU and bounding boxes. The detected objects are denoted by
Moving object detection using YOLOv3 from original videos.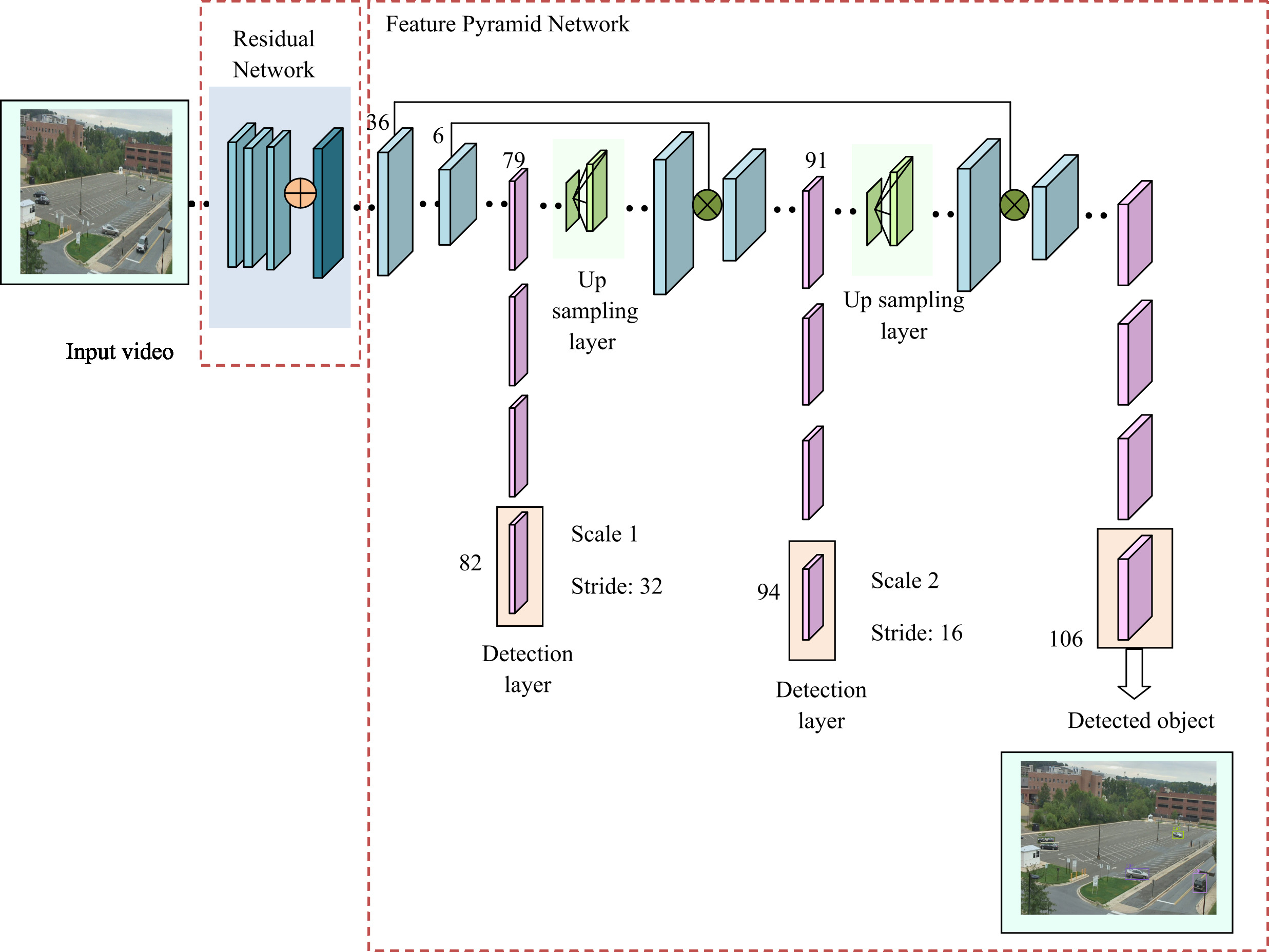
The developed IBMO is helpful for the selection of video frames that are to be stitched during video condensation to minimize the object uncovered rate, and it is also useful to optimize the parameters like epochs and steps per epochs in VGG16 during deep feature extraction to enhance the F1-score of resultant video retrieval results. This algorithm is selected in the developed video browsing and video retrieval system because of its flexibility, simplicity, and also avoiding local optima problems. But, it faces several problems like gradient and low probability during optima stagnation. Hence, improvement is needed in the BMO [27] to rectify these issues and thus, the IBMO is made. In the conventional algorithm, the parameter
Here, the parameter
In Eq. (3), the parameter
BMO: It has converged through the global optima with the support of optimization problems. The unidentified search space and the real-world problems with restrictions are effectively resolved through this algorithm. The inspiration and the mathematical model are briefly summarized below.
Inspiration: The BMO has been developed based on the behavior of the blue monkey. Based on the place searching for food at long distances, the monkeys are divided into teams, and the male mitis has no interaction with the younger ones. One male and more females with babies are presented in the divided groups.
Update position: The position updating depends on the position of the best blue monkey in the divided groups, and that position is delineated by the below Eq. (4).
Here, the power of the monkeys is indicated by
The updated position of the leader monkey is mathematically represented the below Eq. (5).
The updated power rate of the monkey is indicated by the term
Then, the position is updated for the child blue monkey based on the monkey power rate and position of the previous iteration, which is shown in Eq. (6).
Here, the child power rate is represented by
The updated position of the leader child monkey is given in Eq. (7).
The updated power rate of the child monkey is indicated by
The flowchart of the developed IBMO is given in Fig. 4.
Flowchart of the developed IBMO.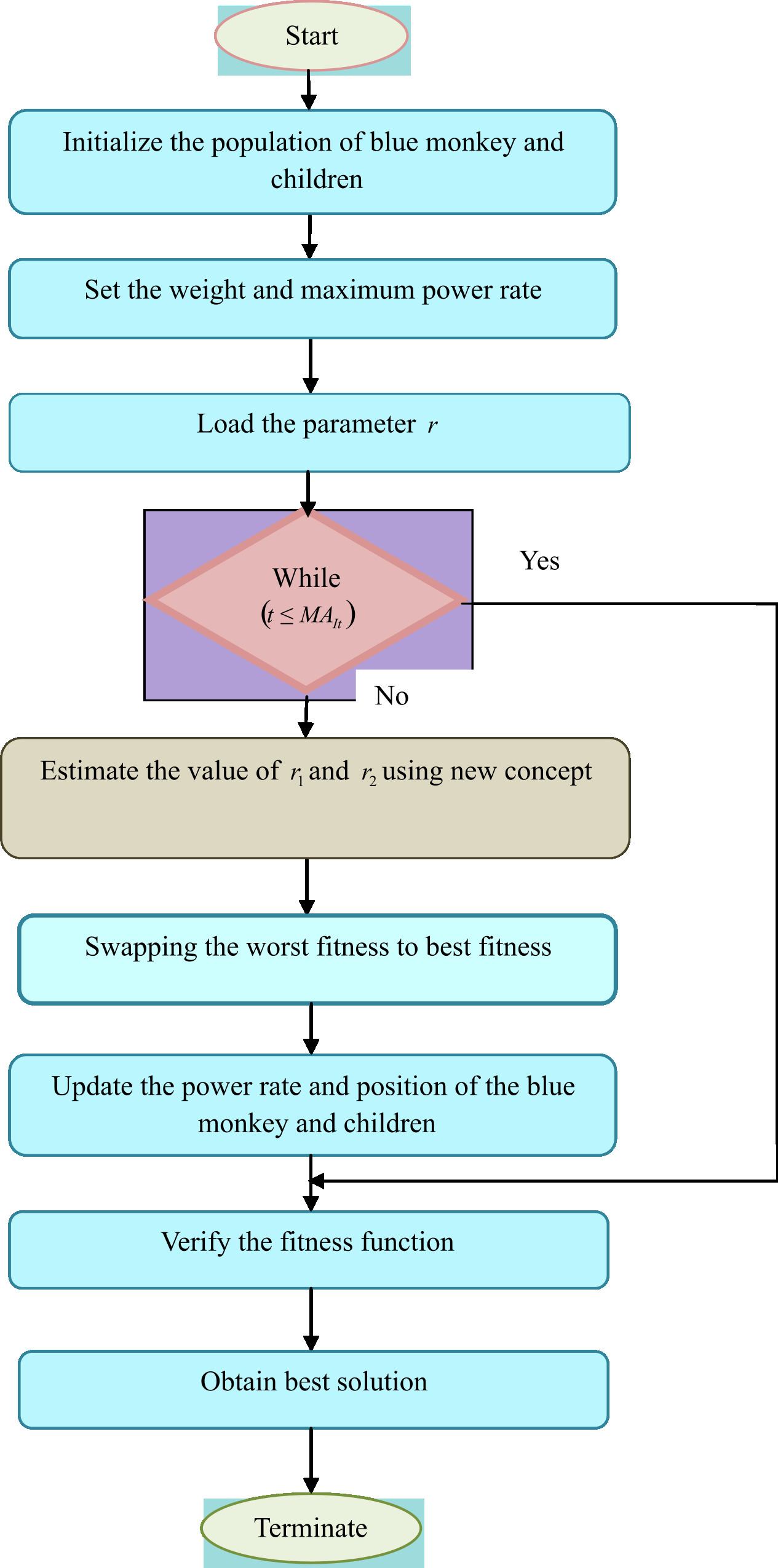
Video condensation is mainly used for compressing long-duration videos. This video condensation is required to achieve quick and efficient retrieved videos based on the user’s queries from the lengthy surveillance videos. This video condensation helps to reduce the inactive density of the videos to enhance the speed of the retrieval process. Initially, the keyframes from the background are extracted because the background frames are fixed. Then, the moving objects are extracted from the surveillance video, and the patterns related to moving objects are noted and stitched into a single frame. If any unexpected changes in the background, then they are specifically saved. The extraction of moving objects is done by the Yolov3 classifier, and then the extracted moving objects are stitched based on the time interval and the activity of the objects. While stitching frames, the appropriate frames are selected using the developed IBMO algorithm that is indicated by the term
Video condensation based on IBMO-based frame stitching.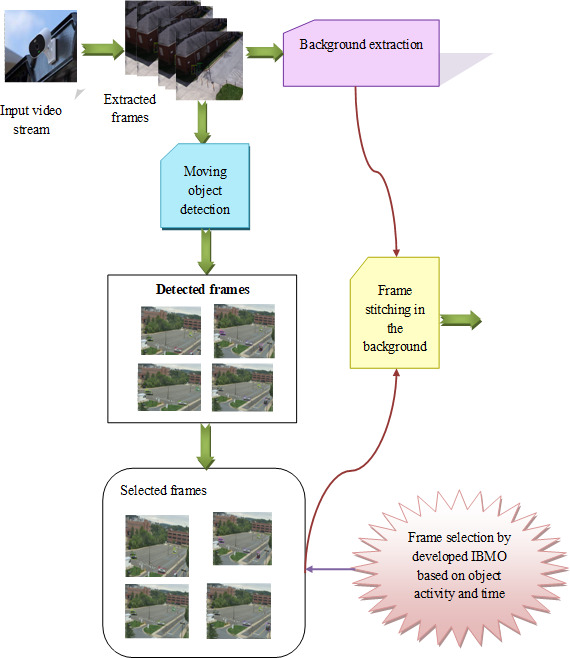
Here, the term
Here, the term
Proposed video browsing and retrieval process
The compressed video is given to the video browsing and retrieval process. The deep structure-based video browsing and video retrieval system are used to provide appropriate videos based on user queries regarding specified times and objects from the long-duration surveillance videos. The time duration required to give appropriate videos is very less compared to other models. Initially, the compressed videos are segmented into separate frames based on the moving objects, and then the segmented frames are stored in the library. From these stored frames, the deep features are extracted using the VGG16 network, where the epochs and the steps per epoch are optimized using the developed IBMO for maximizing the F1 score of the video retrieval process. Then, the FCM clustering approach is used to get the clustered video segments that are stored in the feature database. Then, the user gives a query about the long-duration video with a particular object, and that query will be saved in the feature database. From these stored data, the desirable features are extracted, and the features are subjected to the multi-similarity check with the previously stored clustered data. If the multi-similarity score is high and then the video segments are retrieved from the clustered video segments. This video browsing and retrieval process are done via two phases like training phase and the testing phase. In the training phase, the user queries are stored, and features are extracted from the queries and in the testing phase, checking the multi-similarity score between the user queries and the already stored video segments. Similarity checking is carried out with the help of computing the Euclidean distance and cosine similarity. If the Euclidean distance and cosine similarity values are less, then the video related to those queries is retrieved from the database very quickly. The training and testing during video browsing and retrieval are given in Fig. 6.
Training and testing process in video browsing and retrieval model.
In the developed video browsing and retrieval system, the VGG16 network extracts features from the appropriate keyframes. The VGG16 [28] architecture consists of a maximum pooling layer, twelve convolutional layers, four fully connected layers, and finally, the softmax layer. The applied frames are transformed into different sizes before the extraction of features. In the 1
The reduced dimension frame is passed through the 3
Finally, two sets of convolutional layers are present inside the seventh to twelfth layer, which follows the maximum pooling layer that uses the 512 feature maps with filter size 3
Here, the term
The F1-score value mainly depends on the true positive and negative measures and the true negative and false negative measures. The term
FCM clustering algorithm combines the deep features from the VGG16 model for segmenting the videos. The input given to the FCM is
The constraints are represented in Eqs (13) and (14), respectively.
Here,
The use of this developed IBMO-VGG16-MSF-based video browsing and video retrieval system is to provide appropriate content based on the user queries from the large surveillance videos. The MSF is used in the testing phase for checking the similarity of the features of user queries with previously stored clustered features in the feature database. The metrics to be utilized for performing the MSF are Euclidean distance and Cosine similarity. The value of Euclidean distance and Cosine similarity needs to be low between the query features and features in the database for retrieving appropriate video segments from the database respective to the query. The MSF is given in the below Eq. (15).
Here, the term EDt represents the Euclidean distance, and the term Csim denotes the cosine similarity. Euclidean distance is the distance between the two videos, and it is given in Eq. (16).
Here, the term
Cosine similarity is the ratio of the dot product of the feature vectors to the product of video lengths given in Eq. (17).
If the Euclidean distance and Cosine similarity value are low, then the appropriate video is retrieved from the condensed video.
Experimental setup
The newly suggested IBMO-VGG16-MSF-based video condensation with video browsing and retrieval system was implemented in Python v.3.9.13. The population size to be taken for conducting experiments was 10, the chromosome length was two, and the maximum number of iterations to be taken was 25 by comparing with various video browsing and retrieval systems. Recently developed video browsing and video retrieval models were taken to compare the performance of the developed model in terms of precision, recall, and F1-score. The previously used video browsing and video retrieval models like CNN [20], DBN [21], K-Means [30], and FCM [29]. Moreover, the heuristic algorithms to be considered for evaluating the effectiveness of the developed video browsing and video retrieval system were Artificial Gorilla Troops Optimization (AGTO) [31], Water Strider Algorithm (WSA) [32], Deer Hunting Optimization Algorithm (DHOA) [33] and BMO [27]. The implementation platform used in the research work is Python v.3.9.13. Moreover, the processor is an Intel Core i3 of 64-bit processor and the operating system of 64-bit in Windows 10. Hence, the RAM size is 16 GB.
Performance metrics
Precision, recall, and F1-score are the performance measures used to analyze the effectiveness of various video browsing and video retrieval algorithms. The formula for Precision, recall, and F1-score are explained as follows.
Precision: Precision is a good measure, which is computed by dividing the number of correct results by the number of all the returned results. It is mathematically defined in Eq. (18).
Here, the term
Recall: Recall is determined by dividing the number of true negatives by the total number of elements in the positive class. It is given in Eq. (19).
F1-score: F1-score is calculated using Eq. (11).
Resultant retrieved frames from the condensed video.
Comparing the efficiency of the developed video retrieval system on dataset 1 among different heuristic strategies in regards to (a) Precision (b) Recall and (c) F1-score.
Comparing the efficiency of the developed video retrieval system on dataset 1 among conventional video retrieval techniques in regards to (a) Precision, (b) Recall, and (c) F1-score.
Comparing the efficiency of the developed video retrieval system on dataset 2 among different heuristic strategies in regards to (a) Precision (b) Recall and (c) F1-score.
Comparing the efficiency of the developed video retrieval system on dataset 1 among conventional video retrieval techniques in regards to (a) Precision, (b) Recall, and (c) F1-score.
The results obtained from the developed video browsing and retrieval system are given in Fig. 7.
Statistical comparison on developed IBMO-VGG16-MSF-based Video retrieval system using dataset 1 among different heuristic algorithms
Statistical comparison on developed IBMO-VGG16-MSF-based Video retrieval system using dataset 1 among different heuristic algorithms
Statistical comparison of the developed IBMO-VGG16-MSF-based Video retrieval system using dataset 1 among different Baseline Video Retrieval Techniques
Statistical comparison of the developed IBMO-VGG16-MSF-based Video retrieval system using dataset 2 among different heuristic algorithms
Statistical comparison of the developed IBMO-VGG16-MSF-based Video retrieval system using dataset 2 among different Baseline Video retrieval systems
Performance analysis of the offered model of dataset 1 regarding epochs (a) Testing accuracy, (b) Testing loss, (c) Training accuracy, and (d) Training loss.
Performance analysis of the offered model for dataset 2 concerning epochs (a) Testing accuracy, (b) Testing loss, (c) Training accuracy, and (d) Training loss.
The performance comparison of the developed IBMO-VGG16-MFO-based video browsing and video retrieval system over different heuristic algorithms and distinct existing video retrieval systems using dataset 1 is correspondingly depicted in Figs 8 and 9. The precision, recall, and F1-score measures are taken for the analysis according to the number of received frames. From this plot, the developed video retrieval system accomplished an improved recall of 12.65% than BMO, 13.37% than WSA, 14.10% than AGTO, and 15.58% than DHOA according to the received frames at 10. In addition, from Fig. 9, the developed video retrieval system performed better than CNN, DBN, K-means, and FCM regarding the performance measures like precision, recall, and F1-score.
The performance analysis of the developed IBMO-VGG16-MFO-based video browsing and video retrieval system adopted with various heuristic algorithms is illustrated in below Fig. 10, and a comparison among various baseline video retrieval systems is depicted in Fig. 11 while considering dataset 2. This performance analysis is carried out following the number of received frames. The newly proposed video retrieval system is 14.70% superior to CNN, 18.18% superior to DBN, 27.86% superior to K-means, and 39.28% superior to FCM, while considering the received frame number is 20 on precision analysis. Furthermore, the effectiveness of the developed video retrieval system is higher than the other conventional video retrieval systems and other optimization algorithms.
Statistical analysis using data set 1
Statistical analysis is used to provide better decision support in terms of performance over the developed IBMO-VGG16-MFO-based video browsing and video retrieval system based on median, best, standard deviation, mean, and worst. Comparison among different heuristic algorithms using dataset 1 is given in Table 2, and among various conventional video retrieval systems is depicted in Table 3. From this statistical analysis, the developed model achieved a precision of 0.42% than AGTO, 3.50% than WSA, 2.93% than DHOA, and 1.47% than BMO concerning the improved mean value. Moreover, the performance of the developed video retrieval process is high in terms of precision, recall, and F1-score.
Statistical analysis using data set 2
The statistical analysis of the developed video retrieval system using dataset 2 over different heuristic algorithms and different video retrieval systems are depicted in Tables 4 and 5, respectively. The developed model is 18.37% superior to CNN, 21.13% superior to DBN, 6.79% superior to K-means, and 30.86% superior to FCM while regarding the measure of F1-score based on analysis of median value. The overall effectiveness of the developed model is higher than the other heuristic algorithms and baseline video retrieval systems.
Validation of hyperparameters used in the designed method for dataset 1
The overall performance analysis of the designed IBMO-VGG16-MSF-based Video retrieval system using training loss, testing loss, training accuracy, and testing accuracy for dataset 1 regarding epochs is shown in Fig. 12.
Validation of hyperparameters in the designed method for dataset 2 regarding epochs
The overall performance analysis of the designed IBMO-VGG16-MSF-based Video retrieval system using training loss, testing loss, training accuracy, and testing accuracy for dataset 2 regarding epochs is shown in Fig. 13.
Discussion
A few drawbacks of the existing research method are shown here. In practice, monitoring of the overall activity of the moving object in various cameras is quite challenging. Sometimes, it may fail due to the variation of speed and directions of the adjacent moving object. In some cases, it is not effectively focused on object detection and tracking, as well as the background. While screening the entire video, it is not well performed for the complete trajectories. Hence, it contains poor performance with the presence of visual complexities in the video. Thus, a new model is developed for effectively browsing and retrieving the system for video in the wider range of large surveillance systems. Moreover, the developed model can be performed in less amount of time. Hence, it is utilized in larger datasets to validate the effective performance of the designed method. Additionally, it can effectively speed up the training time in the complex network. Moreover, the developed model helps to solve issues like gradient vanishing, overfitting and underfitting, which helps to improve the efficiency of the system performance. While validating with the standard performance metrics, the developed model achieves better performance when compared with other conventional approaches. Here, the PSNR value is maximized with the help of the designed method.
Conclusion
A new video condensation method for video browsing and video retrieval system was developed to provide appropriate videos based on user requirements from the large surveillance videos with less utilization of time. The required dataset has been gathered and given to the video condensation stage, where the background frames were initially extracted, and the YLOv3 network was used to detect objects. Here, the developed IBMO algorithms were used to minimize the object uncovered rate by selecting appropriate frames for frame stitching. The stitched frames were constructed based on the object’s activity and the time interval. Finally, the stitched frames were stored in a single video that was the condensed video. In the video browsing and retrieval stage, the condensed video was given as input, and this video was segmented into many portions, followed by deep feature extraction from video segments using VGG16, and these segments were clustered with FCM for segmenting the videos. These clustered segments were stored in the feature database, and this was performed in the training phase. In the testing phase, the user was given queries to get specific contents that were stored in the database, and the features were extracted from the queries and fed to MSF over previously stored clustered segments concerning Euclidean distance and cosine similarity. Finally, the appropriate content was provided for users based on their queries very quickly. The experimental results were compared with previously used video retrieval systems, and the mean value of the developed model is 17.80% superior to CNN, 17.38% superior to DBN, 12.26% superior to K-means, and 20.85% superior to FCM according to the F1-score. The efficacy of the developed video retrieval system was excessively high when compared to other algorithms and conventional video retrieval systems.