
Abstract
The recognition of sports action is an important research subject, which is conducive to the improvement of athletes’ own level. To improve the accuracy of multi-modal data action recognition, based on the Transformer module, this study introduces a multi-head attention mechanism, fuses multi-modal data, and constructs a multi-stream structured object relationship inference network. Based on PointNet++ network and combining five different data fusion frameworks, a motion recognition model that integrates RGB data and 3D skeleton point cloud is constructed. The results showed that the Top-1 accuracy of multi-stream structured object relationship inference network was 42.5% and 42.7%, respectively, which was better than other algorithms. The accuracy of the multi-modal fusion model was improved by 15.6% and 5.1% compared with the single mode, and by 5.4% and 2.6% compared with the dual mode, which showed its superiority in the action recognition task. This showed that the fusion of multi-modal data can provide more abundant information, so as to improve the accuracy of action recognition. The accuracy of the action recognition model combining RGB data and 3D skeleton point cloud was 84.3%, 87.5%, 90.2%, 90.6% and 91.2% after the combination of different strategies, which effectively compensated for the problem of missing information in 3D skeleton point cloud and significantly improved the accuracy of action recognition. With a small amount of data, the Top-1 accuracy of the multi-stream structured object relationship inference network in this study was superior to other algorithms, showing its advantages in dealing with complex action recognition tasks. In addition, the action recognition model that fuses RGB data and 3D skeleton point cloud also achieved higher accuracy, which is better than other algorithms. This study can meet the needs of motion recognition in different scenarios and has certain reference value.
Introduction
In the field of sports, scientific and accurate analysis of athletes’ technical movements is the key to improve training effect, prevent sports injury and improve competition results. However, traditional motion analysis methods often rely on manual observation and subjective judgment, which has problems such as low efficiency and poor accuracy [1]. With the rapid development of computer vision and artificial intelligence technology, sports action recognition algorithm comes into being. These algorithms can automatically extract the movement features of athletes from video or sensor data, and classify and recognize them, so as to achieve objective and accurate evaluation of athletes’ technical movements. In addition, sports action recognition algorithm also has a wide range of application prospects [2]. For example, in the field of intelligent fitness, by recognizing the user’s movement, it can provide users with personalized fitness guidance and exercise prescriptions. In the live broadcast and playback of sports events, key actions can be automatically identified and marked to improve the spectator experience. In the training and competition of athletes, accurate action recognition and analysis can help athletes improve their technical movements and enhance their competitive level [3]. Therefore, the research of sports action recognition algorithm has important theoretical significance and application value, and is also one of the current research hotspots in the field of sports science and technology [4]. Multi-modal data refers to a variety of different forms of data collected from the same object or scene at the same time, such as image, video, sound, text and sensor data. These data not only provide complementary information, but also enhance the understanding of the target object or scenario through the correlation between them. In the field of sports, multi-modal data is especially widely used [5]. For example, in basketball, by fusing video data and sensor data on players, players’ shooting, running and jumping can be accurately identified, thus providing coaches with scientific training recommendations. In football matches, the combination of image data and physiological data of players can monitor the fatigue degree and movement state of players in real time, so as to help coaches make reasonable substitution strategies. The fusion of multi-modal data can not only improve the accuracy of action recognition, but also enhance the robustness of the system. When the data of one mode is disturbed or missing, the data of other modes can provide supplementary information to ensure the successful completion of the identification task. In addition, multi-modal data can provide more contextual information to help understand the semantics and intent of actions. Therefore, this study is based on the Transformer module, integrating multi-modal data, and constructing a multi-stream structured object relationship inference network (MSORIN). Based on PointNet++ network and combining five different data fusion frameworks, an action recognition model integrating RGB data and 3D skeleton point cloud is constructed to meet the requirements of dynamic action recognition.
This study is divided into four parts. The first part is the research on action recognition algorithms based on RGB data and skeleton by domestic and foreign scholars. The second part constructs an MSORIN and an action recognition model that integrates RGB data and 3D skeleton point clouds. The third part tests and analyzes the model, while the fourth part summarizes the article and proposes shortcomings.
Related works
RGB data is commonly used for action recognition, and some scholars have conducted relevant research on the application of RGB data in action recognition. To identify the spatio-temporal information of human actions, Li S et al. constructed a dual-flow structured human action recognition model based on RGB images and optical flow. This model determined the beginning of the video by calculating the joint positions between bone data, and then used RGB images and optical flow to train spatial and temporal networks to predict actions. The information was fused using an average fusion method. The experiment outcomes demonstrated the effectiveness of this method in recognition [6]. Li X et al. proposed a converter-based RGB-D self centered action recognition framework that utilized a self attention mechanism (SAM) to model the time structure of data from different modalities. The features from each modality interacted through the proposed fusion blocks and were combined through simple and effective fusion operations. The test results on a small first person dataset denoted that the proposed action recognition framework outperformed existing models [7]. Cheng J et al. found that the existing action recognition model based on RGB data could not realize the interaction between different modal information, so they proposed a cross-modal compensated convolutional neural network for action recognition. This network jointly learned the compensation features of RGB and deep mode to enhance discrimination ability, and extracted compensation features from RGB and deep mode across modal compensation blocks, which was beneficial for improving the performance of the model. The findings expressed that the model achieved optimal performance on all three datasets [8]. Weiyao X et al. found that existing action recognition methods based on RGB data overlooked semantic relationships. Therefore, a multi-modal action recognition model was constructed based on bilinear pools and attention networks. Firstly, an efficient data preprocessing method was adopted for RGB and skeleton data, and a multi-modal fusion network was constructed by combining RGB video and skeleton sequences. The experimental outcomes indicated that this model could effectively extract RGB and skeleton data, and had better performance compared to other methods [9].
Skeleton data, as the foundation of a 3D action recognition algorithm, can provide more comprehensive information in action recognition, and some scholars have conducted relevant research based on this. Yangzhi L I et al. found that the existing human skeleton action recognition algorithms could not mine the spatio-temporal characteristics of action, so they proposed a skeleton action recognition model based on the spatio-temporal attention graph convolution network model. This algorithm consisted of spatial and temporal attention mechanisms, utilized instantaneous action information of optical flow features to locate spatial regions with significant motion, and automatically extracted time-domain fragments from long-term complex videos. The research outcomes indicated that this algorithm improved the recognition accuracy compared to existing skeleton recognition algorithms [10]. Ahmad T et al. found that graph convolution neural network was the most suitable network for skeleton recognition. However, human skeletons stacked on the length of video sequence would lead to many nodes being very complex. Therefore, a graph sparsization technique using edge effective resistance was proposed to better model global contextual information. Combining self attention graph pooling, local effective information could be preserved and redundant nodes and edges in the graph could be eliminated. The experimental findings illustrated that this method effectively retained useful information, removed the influence of impurities, and improved the accuracy of testing [11]. Zhao J et al. proposed a lightweight and efficient method to solve the problem of low efficiency of most algorithmic efficiency based on skeleton data. This method embedded the graph convolution operator into a simple recursive unit and constructed a graph convolution simple recursive unit. At the same time, to enhance the distinction between nodes, spatial attention network and multi-stream data fusion were used to expand the simple recursive unit of graph convolution to the simple recursive unit of multi space of flows attention graph convolution. The recognition results showed that the testing accuracy of the model under three datasets was 93.1%, 92.7%, and 87.3%, respectively [12]. Kawamura K et al. found that skeleton data must be measured by depth sensors or extracted from video data using estimation algorithms, resulting in extraction errors. To realize skeleton based action recognition, a deep state space model was proposed, which is a deep generative model of potential dynamics of observable sequences. The outcomes denoted that this method improved the classification performance of the baseline method and was superior to the most advanced methods [13].
To sum up, most of the existing action recognition methods study RGB data and skeleton data separately, lacking the research on their fusion algorithm. Therefore, this study combines RGB data and skeleton data to extract multi-modal data, and the constructed action recognition method has high reference value.
Construction of a sports action recognition model based on multi-modal data recognition
To better recognize human actions, this chapter is divided into two parts to construct an action recognition model. The first part is based on the Transformer module, introducing a multi-head attention mechanism (MHAM), using the inflated 3D (I3D) network and optical flow algorithm to extract appearance representation data and optical flow data, and integrating them to construct an MSORIN. In the second part, based on PointNet++ network, five fusion frameworks for 3D skeleton point clouds and RGB data are designed to improve the accuracy of action recognition.
Construction of an MSORIN model based on multi-modal fusion
Sports action recognition technology is mainly used to capture, analyze and understand the human body’s action in sports, and it has a wide range of applications in many fields, including athlete training, sports medicine, fitness, games and so on. Compared with the traditional mechanical, acoustic and electromagnetic action capture technologies, the modern sports action recognition technology has higher precision and real-time performance. Traditional action capture technology requires the installation of sensors or markers on the human body, which not only affects the natural movement of the human body, but also the data processing process is more complex. The action recognition technology based on computer vision can capture human action through the camera, without installing any equipment on the human body, so it is more convenient and practical. Multi-modal data refers to information or data that contains multiple types, usually in different data forms, structures, or representations. Multi-modal data uses methods such as cross-modal learning, multi-modal feature extraction, and fusion to combine different types of data to obtain more comprehensive and accurate information. To improve the correlation recognition of objects in action recognition and distinguish between human behavior and objects, a Transformer-Target relationship inference network (Relation_Transformer) is constructed based on the Transformer module. The network structure is shown in Fig. 1.
Structure diagram of Relation_Transformer.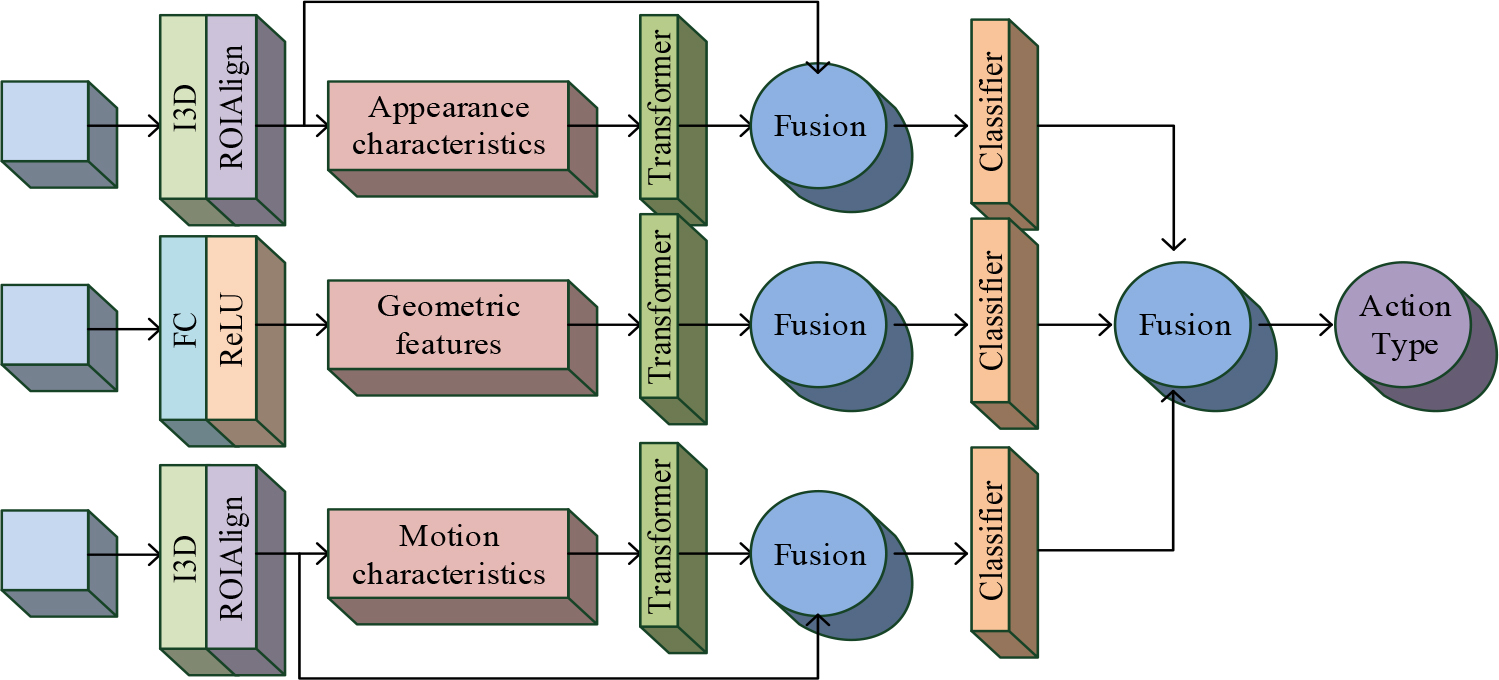
The network is divided into three stages: multi – modal feature extraction stage, object relationship inference stage, and multi – modal fusion stage. In the multi – modal feature extraction stage, object detection and multi – object tracking algorithms are used to obtain the geometric position coordinates, RGB data, and optical flow data of the target object [14]. The detection target is set to
In Eq. (1),
In Eq. (2),
In Eq. (3),
SAM diagram.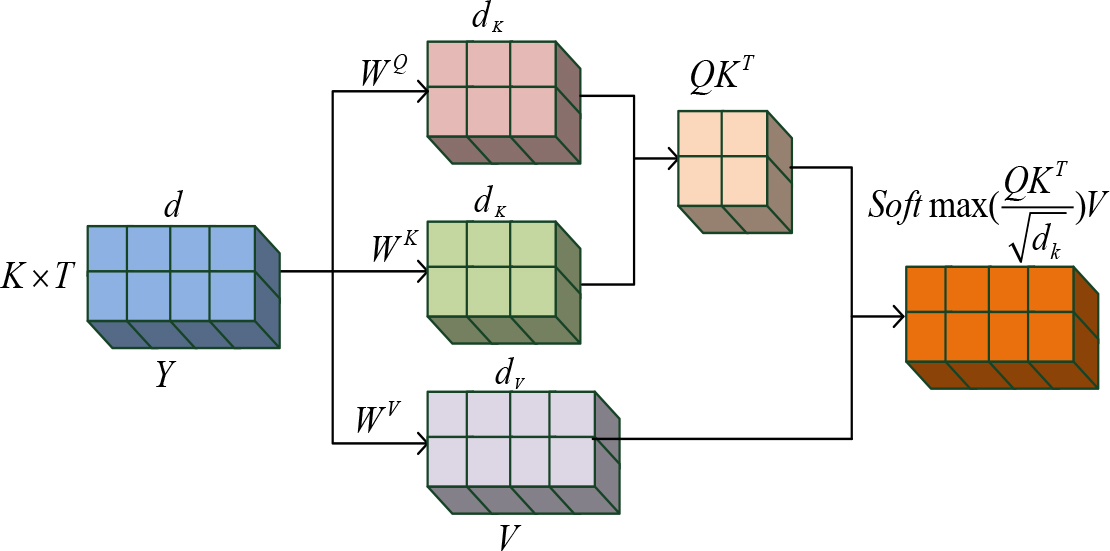
To enhance the network’s ability to infer target relationships, the process calculation expression of the MHAM is shown in Eq. (4).
In Eq. (4),
In Eq. (5),
In Eq. (6), Layer Norm stands for the method of normalizing the input data in the neural network. In the FNN, the output expression of the previous MHAM layer is shown in Eq. (7).
In Eq. (7),
In Eq. (8),
In Eq. (9),
In Eq. (10),
Position coordinates of joint points in two – dimensional coordinates.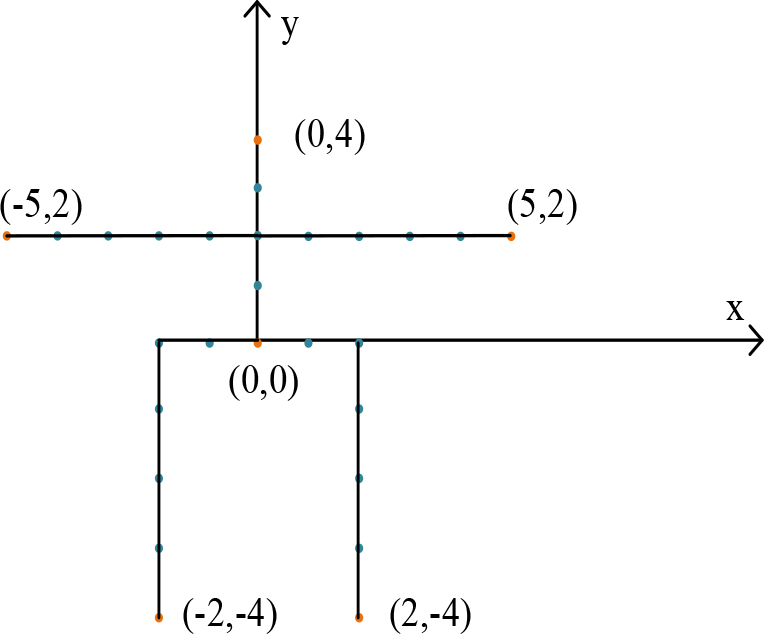
Skeleton sequence stacking is a technique of stacking or combining multiple skeleton sequences. In the field of action recognition, skeleton sequence stacking is widely used to extract and represent action features in human motion. A 3D skeleton point cloud is a type of 3D point cloud data used to represent the motion of a human body or object, consisting of a series of joint positions, each represented by a 3D coordinate point [21]. Each joint position represents the posture information of the human body or object at a specific moment. By connecting multiple joint positions, a hierarchical representation can be formed, reflecting the overall posture and shape of motion. However, there is a problem of disorder in 3D skeleton point clouds, including temporal, spatial and action information [22]. Using the decimal transformation method, a three – dimensional vector
In Fig. 3, six coordinate points are specifically selected to represent the coordinates of the head, hands, feet, and tail vertebrae of the human skeleton. Based on the fact that human motion is a dynamic process, vector
Framework of skeleton point cloud feature extraction network based on PointNet++ network.
Due to the ordered input of unordered point cloud data in traditional PointNet networks, the classification results of all data are consistent. To address this issue, PointNet++ has improved on PointNet by using a sampling grouping aggregation strategy to extract local features. Firstly, the farthest point sampling method is used to obtain the set of key points in the skeleton point cloud. The center of the key points is selected and the point set is divided into multiple spherical regions with the same radius. The closest
In Eq. (11),
After pooling processing, it is fused with the output feature
In Eq. (14),
In Eq. (15),
Framework flowchart for integrating 3D skeleton point cloud and RGB data.
To test the performance of the model’s action recognition, this chapter is divided into two parts for testing. The first section tests and analyzes the MSORIN, and the second section tests and analyzes the performance of the action recognition model that integrates RGB data and 3D skeleton point cloud.
Testing and analysis of MSORIN
The experimental system selected for this experiment was Ubuntu 16.04, with Intel Xeon 4114 CPU, TITAN RTX graphics card, and Python 3.7 software environment. Momentum was set to 0.9, weight attenuation was 0.0005, initial learning rate was 0.01, and epoch number was set to 40. I3D network, temporary shift module (TSM), structured attention fusion for composite action recognition (SAFCAR), and Relationship_Transformer model were selected and tested on the Something_Else dataset. Top-1 and Top-5 accuracy were utilized as measurement indicators, Top-1 and Top-5 accuracy were chosen as metrics to make the results distinguishable and to increase applicability. The results are shown in Fig. 6.
Top-1 and Top-5 curves of different models.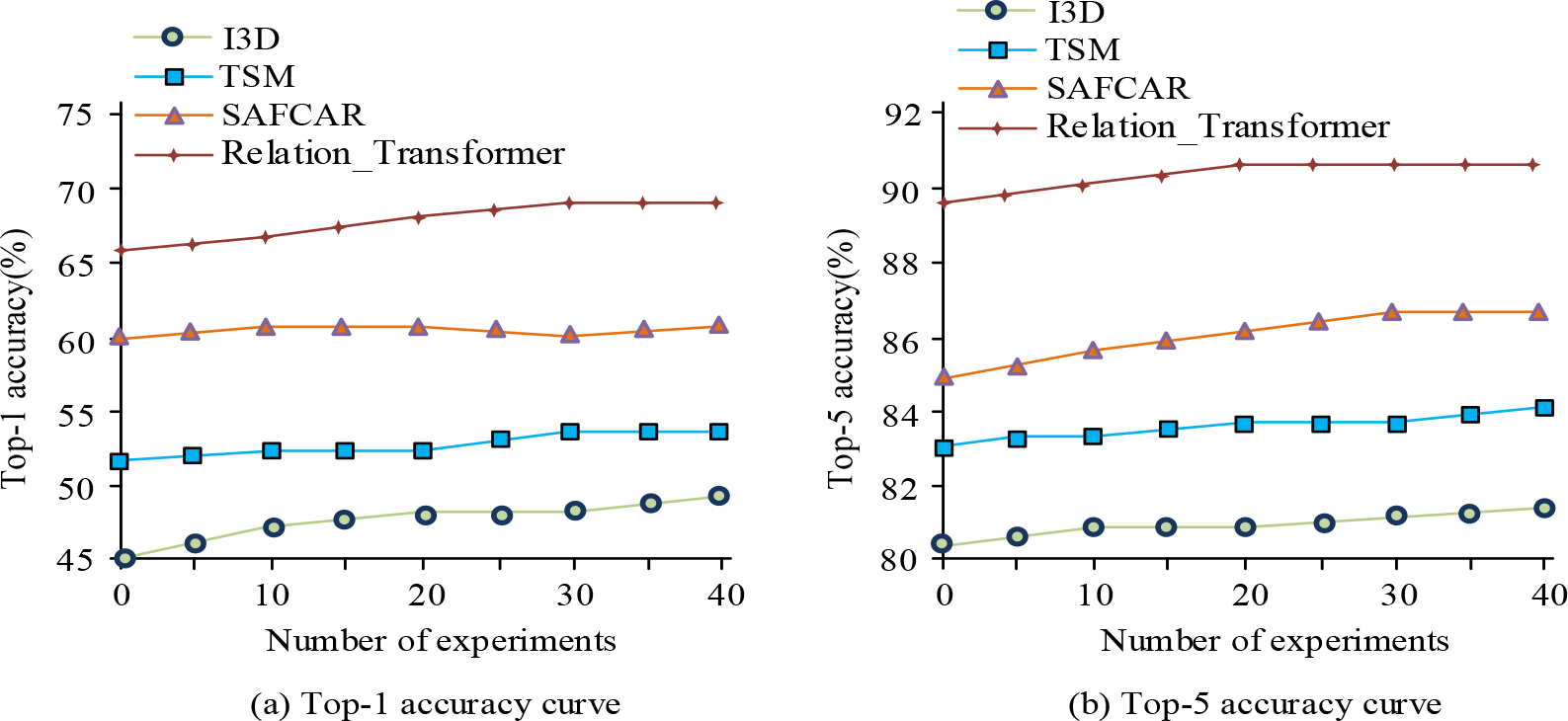
Figure 6(a) shows the Top-1 accuracy curves of the four models. The Relation_Transformer model had the highest accuracy value of 68.8%. Figure 6(b) shows the Top-5 accuracy curves of the four models. The Relation_Transformer model still had the highest accuracy value of 90.2%. This proves that the motion representation features of motion information contained in optical flow data are important information for action recognition. To test the algorithm’s spatio-temporal feature extraction ability under a small amount of data, 5 and 10 data were selected as samples. The Top-1 accuracy was used as an indicator, and the test results are shown in Fig. 7.
Top-1 accuracy curve under different data.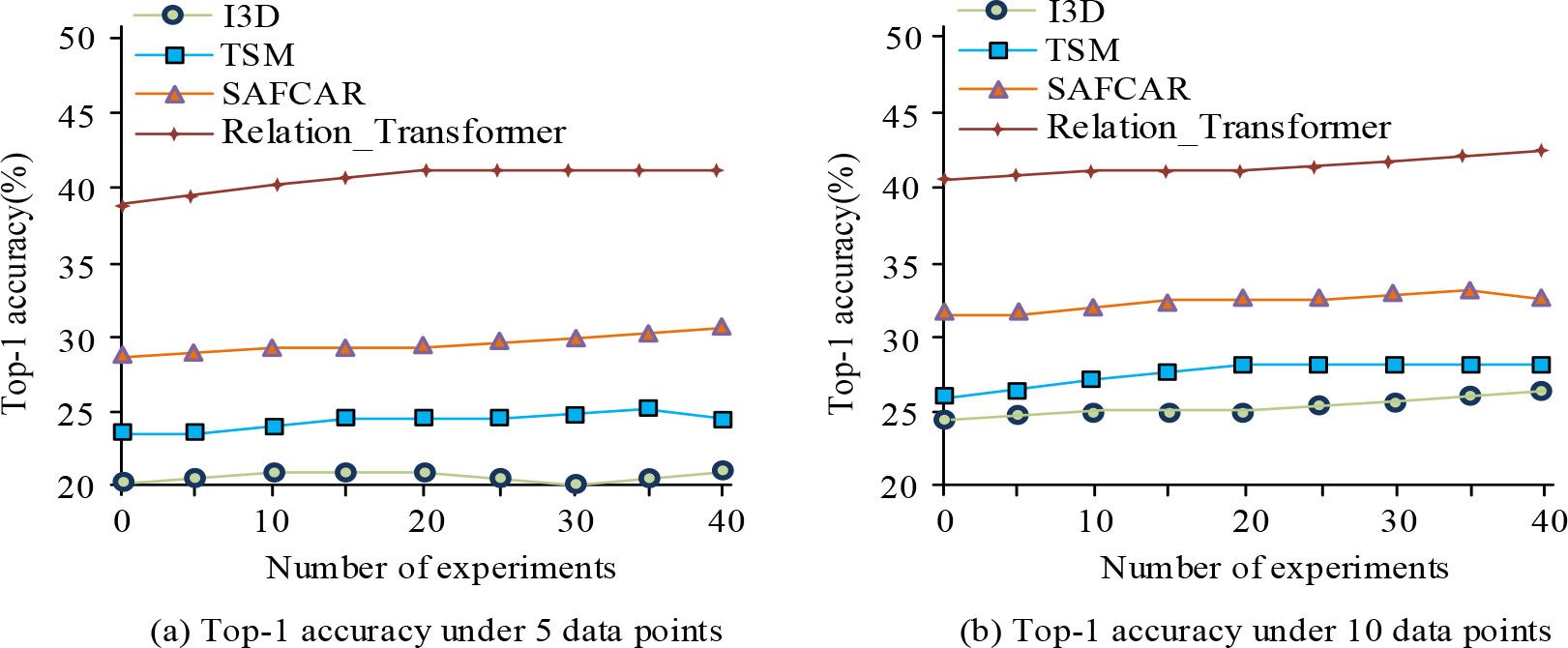
Figure 7(a) shows the Top-1 accuracy curves of four models under 5 data sets. The Relation_Transformer model had the highest accuracy, at 42.5%. Figure 7(b) shows the Top-1 accuracy curves of four models under 10 data sets. The Relation_Transformer model still had the highest accuracy value, at 42.7%. Therefore, the accuracy value was higher than other algorithms in a small amount of data, and it still had effectiveness in action recognition. To demonstrate the promoting effect of multi-modal fusion on action recognition, models with single-stream, dual-stream, and multi-stream network structures were compared and tested. The data modes were Boxes, Boxes+RGB, and Boxes+RGB+Flow, respectively. The fusion method was used for 10 tests, and the test results are shown in Fig. 8.
Figure 8 shows the Top-1 and Top-5 accuracy curves of the three modal network structures. The average accuracy values of Boxes single-stream were 56.5% and 86.2%, respectively. The average accuracy values of Boxes+RGB dual-stream were 66.7% and 88.7%, respectively. The average accuracy values of Boxes+RGB+Flow were 72.1% and 91.3%, respectively. Multi-modal fusion could effectively improve accuracy. Compared to single-modal data fusion, multi-modal data fusion has improved accuracy by 27.6% and 5.9%, and compared to dual-modal data fusion, it improved accuracy by 8.1% and 3.8%, respectively.
To test the performance of an action recognition model that integrated RGB data and 3D skeleton point clouds, the experimental system selected Ubuntu 16.04, with Intel Xeon 4114 CPU, TITAN RTX graphics card, and Python 3.7 software environment. The NTU RGB+D 60 dataset was selected as the test data. It set momentum to 0.9, weight Attenuation coefficient to 0.0001, epoch to 60, and initial learning rate to 0.1. The action recognition model that combines RGB data and 3D skeleton point cloud (model 1), the Temporal Segment Networks model (model 2), Temporal Relational Reasoning in the videos action recognition model (model 3), Temporal Shift Module action recognition model (model 4) and SlowFast action recognition model (model 5) were compared. The metrics compared include: accuracy, recall, relative error, running time, and F1 value. The details are shown in Table 1.
Comparison of indicators between models
Comparison of indicators between models
Accuracy curves of models with different modes.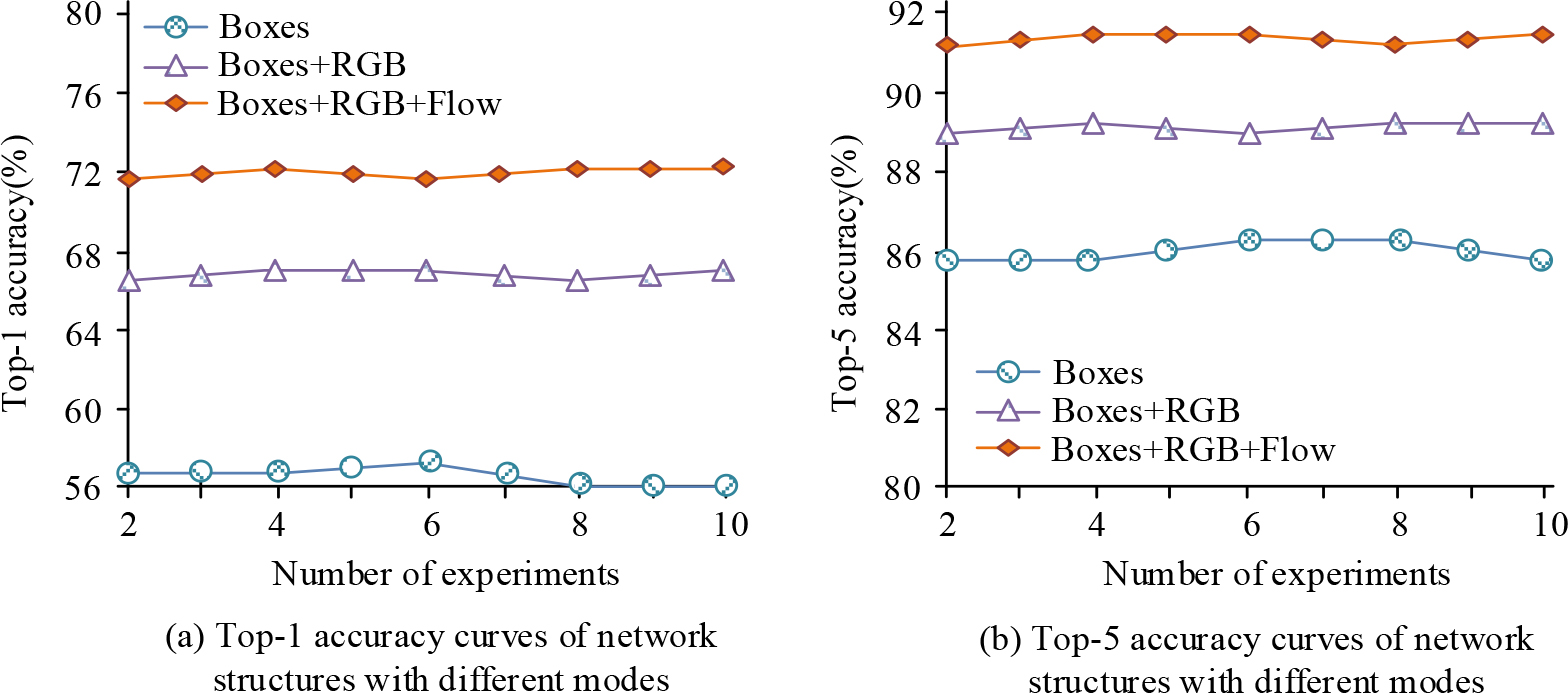
In Table 1, the accuracy, recall, relative error, running time, and F1 value of model 1 were 92.58%, 91.20%, 0.003, 33.59s, and 90.28%, respectively, which were significantly higher than the other four models. The results showed that model 1, which combines RGB data and 3D skeleton point cloud, had the best performance. The deep semantics-long short term memory networks (DS-LSTM), spatial-temporary graph convolutional network (ST-GCN), and biosynthetic gene cluster-long short term memory networks (BGC-LSTM) models were chosen for comparative testing with model 1. The results are shown in Fig. 9.
From Fig. 9, the RGB+3D model Top-1 had an accuracy of 81.2%, and Top-5 had an accuracy of 91.2%, which was higher than other algorithms and had good performance in human action recognition. To verify that the accuracy of the fusion model for temporal information, spatial information, and motion information was better than that of single information features, the three information features were combined in pairs to form different dual information fusion models. The test results are shown in Table 2.
Accuracy of testing different fusion information models
Accuracy test curves for different models.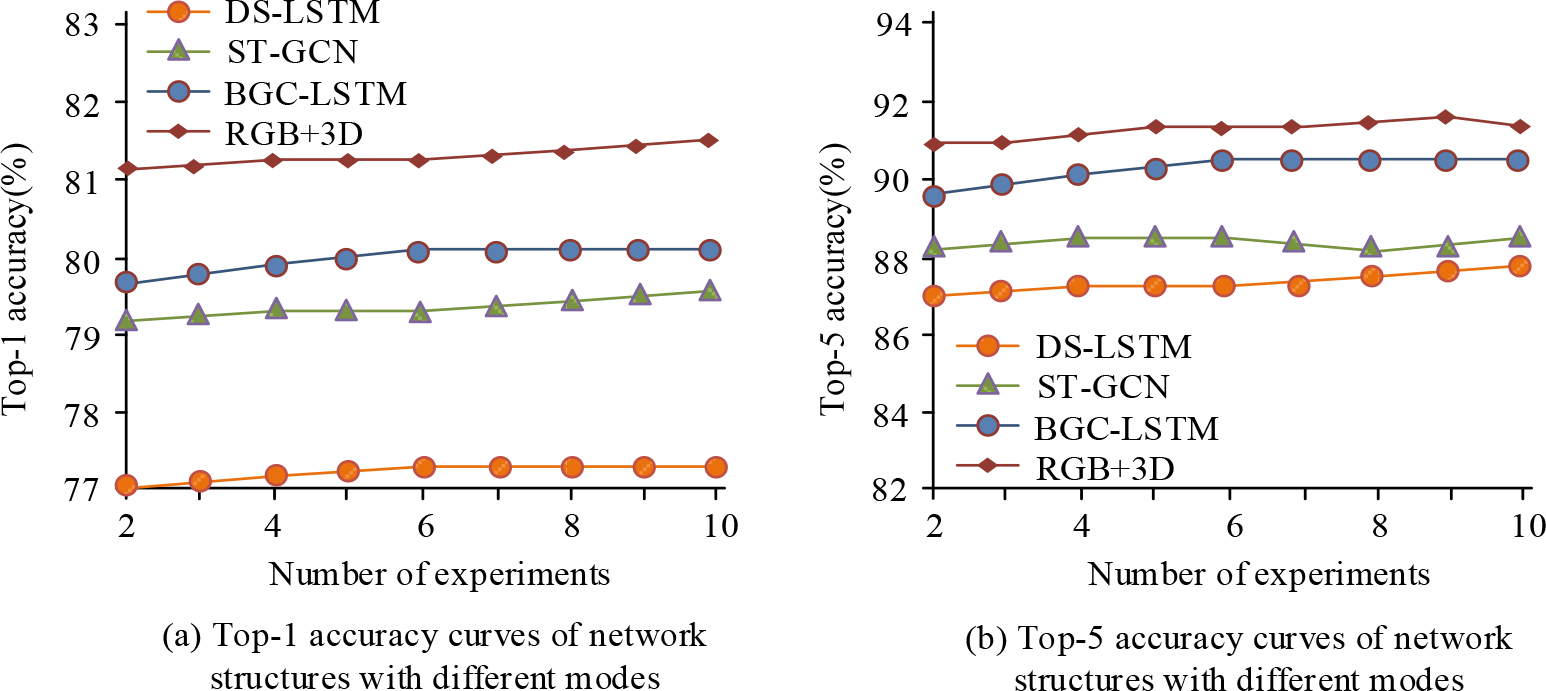
From Table 2, the baseline 3D skeleton point cloud model had the lowest recognition accuracy. After integrating the 3D skeleton point cloud with temporal, spatial, and motion feature information, the accuracy values of Top-1 and Top-5 were 77.6% and 85.1%, 76.2% and 84.3%, and 76.2% and 84.3%, respectively. After combining the 3D skeleton point cloud with feature information, the accuracy values of Top-1 and Top-5 were 79.8% and 86.9%, 80.5% and 88.4%, and 81.3% and 90.6%, respectively, which were improved compared to single feature accuracy. After fusing the 3D skeleton point cloud with three features, the accuracy rates were 82.6% and 92.7%, respectively, achieving the optimal recognition accuracy. Therefore, it was proved that the temporal, spatial, and motion feature information in RGB data could effectively compensate for the problem of missing information in 3D skeleton point clouds and improve the accuracy of recognition models. To verify the effectiveness of the sampling grouping strategy, five different fusion strategies were compared and tested, with Top-1 as the indicator. The results are shown in Fig. 10.
Comparison curve of Top-1 accuracy for five different fusion strategies.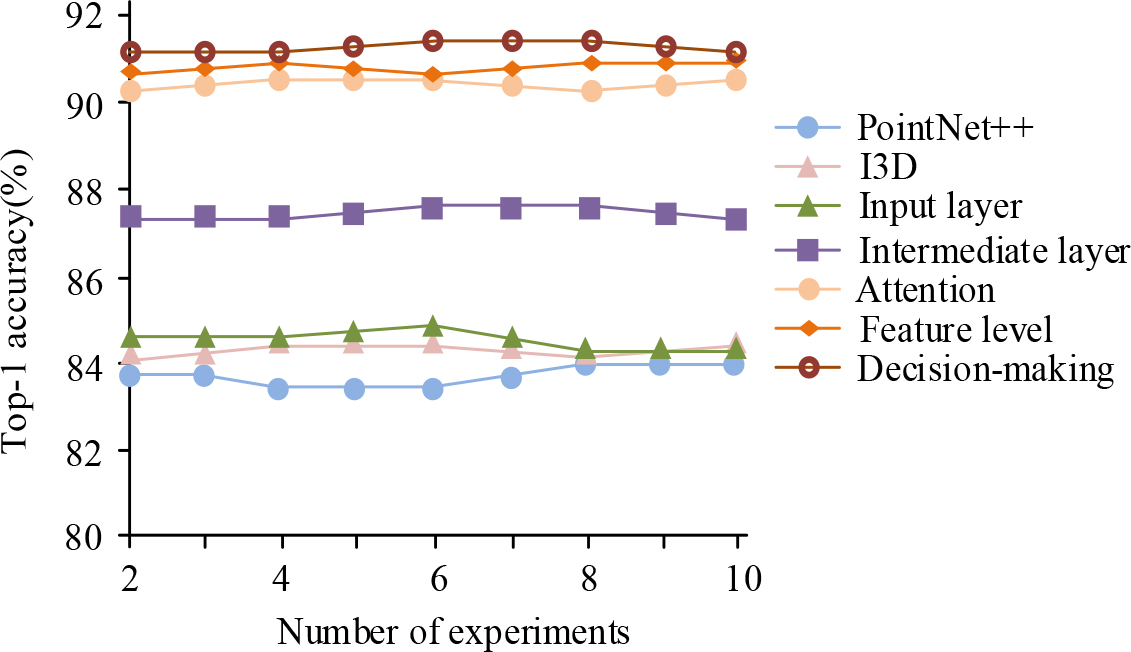
From Fig. 10, the individual PontNet++ and I3D achieved accuracy of 83.9% and 84.1%, respectively. After integrating the input, intermediate, feature level, attention, and decision-making layers, the accuracy rates were 84.3%, 87.5%, 90.2%, 90.6%, and 91.2%, respectively. The accuracy of the model fused with five strategies was improved, proving that the fusion strategy had an improved effect on the accuracy of action recognition, which was conducive to better action recognition. Images from real motion scenes were selected, and recognition tests were performed on individual 3D skeleton point cloud models and fusion models in real scenes. The test results are shown in Table 3.
Recognition results in real scenarios
From Table 3, a single skeleton point cloud model could only recognize the basic information of human actions, but could not recognize specific scenes. The fused model could accurately recognize the information of interactive objects, increasing the accuracy of recognition and reducing the difficulty of recognizing similar actions.
To better identify human actions in sports, an MSORIN was constructed based on the Transformer module and multi-modal data. Based on PointNet++ network, 3D skeleton point cloud and RGB data were integrated to construct an action recognition model. The experimental results showed that the Relation_Transformer model had a significant advantage in comparison with the other three models, and its Top-1 and Top-5 accuracy rates reached 68.8% and 90.2%, respectively. Especially in the test of a small number of data sets, the model still maintained a high accuracy, proving its strong generalization ability and stability. In addition, the multi-modal data fusion strategy also greatly improved the recognition accuracy, and the Top-1 and Top-5 accuracy rates were significantly improved compared with single-modal and dual-modal data. In the RGB+3D model, it achieved satisfactory results, and the accuracy of Top-1 and Top-5 reached 81.2% and 91.2%, respectively, which was better than other similar algorithms. After the 3D skeleton point cloud was fused with the three features, the recognition accuracy reached a new height, with the accuracy of 82.6% and 92.7%, which fully proved the effectiveness of the multi-modal fusion strategy in the field of action recognition. Through the gradual fusion of input, intermediate, feature level, attention and decision-making layers, the fusion of each layer brought performance improvement to the model, which further validated the important role of multi-modal data in making up for the missing information of 3D skeleton point cloud. By combining Transformer module and multi-modal data, remarkable achievements were made in the field of action recognition, which provides new ideas and methods for research in related fields. However, there are potential limitations in the research. The action recognition model currently studied can only recognize single action, and the model may not be able to process the action recognition conducted by multiple people at the same time, or distinguish the actions of different individuals in a multi-person scene. The testing and training of a model may depend on a particular data set, which may lead to limited generalization of the model in other data sets or real-world scenarios. The use of Transformer modules and PointNet++ networks requires high computing resources, which may limit the application of the model in resource-constrained environments. Constraints that may affect the generalizability of results include that the model overfits on a particular dataset, limiting its ability to generalize on other datasets or data from different sources. The research does not fully consider the diversity of different motion scenes and backgrounds, and the changes of scenes in practical applications may affect the recognition effect of the model. The complexity and variety of movements in sports may be beyond what is covered when the model is trained, especially for the recognition of subtle or unconventional movements.
Footnotes
Conflict of interest
The author declares no conflict of interest.