
Abstract
The belief rule based (BRB) methodology is developed from the traditional IF–THEN rule based system and evidential reasoning (ER) approach. It can be used to model complicated nonlinear causal relationships between antecedent attributes and consequents under different types of uncertainty. In this paper, we present a new BRB structure for modelling uncertain nonlinear systems. It uses the weighted averaging operator to replace the ER approach in the inference process. With this change, the BRB structure could be simplified and faster speeds are obtained in both training and inference process, while universal approximation capability is maintained. By using the consequents of the new BRB model, an approach for reducing possibly redundant referential values of antecedent attributes is proposed for point estimate. Case studies are conducted on three well known benchmark datasets to compare the new model with the existing BRB model and other methods in the literature. Experimental results demonstrate the capability of the proposed method for identification of nonlinear systems.
Introduction
Identification of a nonlinear system is of funda-mental importance in predictive control, fault diagnosis and signal processing, etc., since most real-life systems are nonlinear. They are often associated with uncertainties due to noises, unpredictable disturbance, uncertain physical parameters and incomplete knowledge. Those uncertainties cause a great difficulty in applying traditional identification techniques. Over the past few decades, extensive studies have been conducted for identifying uncertain nonlinear systems, especially with the advent of neural network [12, 18] and fuzzy rule based system techniques [21, 28]. However, these methods usually involve some restrictive assumptions, such as Gaussian distributed noises, deterministic disturbances and bounded uncertain parameters [2]. Besides, fuzzy models for lower and upper bounds are independent from each other in some interval estimate methods, and it may incur improper identification results with invalid bounds if no enough training data is available in some regions of the input space [25].
Recently, the BRB methodology is developed on the basis of D-S evidence theory [22], decision theory [19], traditional IF-THEN rule based systems [13, 16] and relevant artificial intelligence techniques [9, 15]. In a BRB system, various types of information and knowledge with uncertainties can be represented using belief structures, and a belief rule is designed with belief degrees embedded in its possible consequents. The belief structure used in both belief rules and inference processes provides a unified scheme to model uncertain system outputs caused by vagueness, fuzziness, or incompleteness, etc [4]. Because of its advantages of dealing with uncertainty, it has been successfully applied in various areas, such as fault diagnosis [30], multi-attribute decision analysis [11] and classification [1]. It also provides an alternative for the identification of nonlinear systems [4, 23].
Making use of BRB’s capability of approximation and dealing with uncertainty, Chen et al. [4] proposed three approaches to construct BRB models for uncertain nonlinear systems. Like all other BRB models, ER approach [32] is applied to aggregate all activated belief rules to generate the final inference output. In a BRB model, most parameters come from the belief distributions of rule consequents. If this part of parameters can be cut down, much convenience can be brought to the training and inference process.
A BRB model can approximate any real continuous function over a compact subset and its accuracy could be improved by using more referential values for antecedent attributes [5]. However, the increase of referential values would cause problems such as the increase of belief rules and overfitting of the training data. Thus a tradeoff should be made and redundant referential values should be abandoned to achieve a good performance. Zhou et al. [33] defined the statistical utility to prune insignificant rules. Chang et al. [3] conducted a comparative study of four techniques for reducing redundant belief rules when the rules are given by expert. These methods depend on extra information or knowledge from experts. Wang et al. [29] put forward an objective rule reduction method based on rough set theory. However, these aforementioned methods are not designed for the identification problem in which belief rules are constructed directly using combinations of antecedent attributes and are generally not contradict.
The main contribution of this work is two folds. First, we investigate the feasibility of using an alternative combination rule to aggregate the activated belief rules. The weighted averaging operator is chosen after analysis and it is shown that this combination rule can simplify the structure of BRB model significantly while maintaining the universal approximation capability. Second, an approach for attribute reduction is proposed by use of the new BRB structure. Three commonly used case studies are exploited to demonstrate the performance of the proposed method.
The rest of this paper is organized as follows. Section 2 briefly reviews the BRB model. Section 3 states the motivation of this paper. Section 4 details a new BRB model along with an attribute reduction approach. Section 5 presents several numerical studies to demonstrate the approximation capability of the new BRB model and the attribute reduction approach. Finally a conclusion is drawn in section 6.
Belief rule based systems
To simulate an uncertain nonlinear system, a BRB model consists of two parts, first establishing the belief rule base, and then aggregating all activated belief rules using the ER approach.
Belief rule base
A belief rule base consists of a finite number of belief rules. Formally, a belief rule is defined as follows [31]:
To estimate the output given an input vector
Here, αi,j represents the similarity degree to which the input value x
i
matches the referential value Ai,j. After all the inputs are transformed into belief distributions, the activation weight of the kth belief rule can be calculated as follows:
Note that in Equation (3) the attribute weights are assumed to be identical in all belief rules. Further, the belief degrees on the inference output can be generated through the aggregation of all activated belief rules using the ER approach [32].
Suppose that the utility of each consequent element D
n
is denoted by u (D
n
) and all belief rules are complete. The inference output can be calculated by
In uncertain nonlinear systems, belief rules may not all be complete, and then we may have β
D
(
When observed input–output data pairs are available, optimal learning methods can be designed to train the BRB parameters. In [4], three different training approaches are introduced with the following objective functions, respectively.
More referential values for antecedent attributes usually can improve the approximation accuracy. Meanwhile, too many referential values would increase the complexity of the constructed model and lead to overfitting if there are noises in data. This problem is illustrated by the following example.
where ε is Gaussian noise with zero mean and variance δ = 0.05 [4]. To construct a BRB model to simulate this system with noises, 4 referential values of the input variable x within the interval [0, 10] are initially defined as {0, 3, 7, 10}. A training dataset with 100 data points is generated from the nonlinear function. Table 1 lists the trained belief rule base.
Trained belief rule base in Example 1
If we use 6 referential values for x with initial values {0, 2, 4, 6, 8, 10}, another BRB model could be established with the same training dataset. Figure 1 illustrates the estimated outputs of the trained BRB models with 4 and 6 referential values. The mean square error (MSE) between the actual output and the estimated outputs are 0.00212 and 0.00195, respectively. The BRB model with 6 referential values has a slightly better performance in terms of MSE. Nevertheless, different belief rules would be activated when x increase from smaller than to bigger than a referential value, which may make the curve not smooth at each referential value. We can see from the figure that the blue curve is very smooth while the pink curve has several turn points. As a result, appropriate number of referential values should be used and an approach for reducing redundant referential values is necessary.
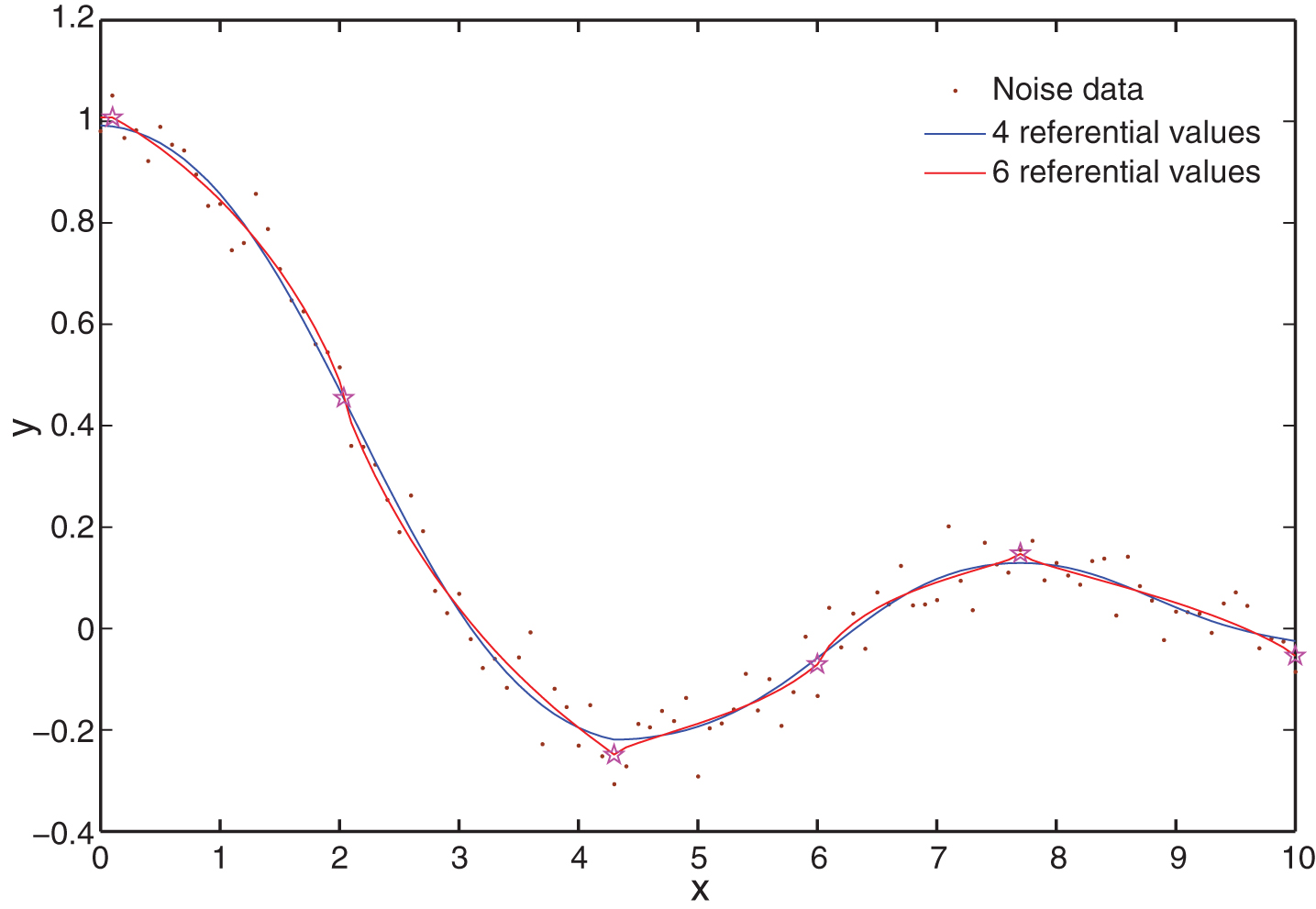
Estimated output with different numbers of referential values.
Suppose m1 and m2 are two basic belief assignments (BBAs). The degree of conflict between them is classically defined as [22]
By this definition, we can calculate the degrees of conflict between each pair of adjacent belief rules in Table 1: K12 = 0.8985, K23 = 0.8283, K34 = 0.9352. It implies that the belief distribution of activated rules are always in high conflict. In fact, this is not a unique case. Consider the trained belief rule bases in Table 3, Table 5(a) and Table 5(b) of literature [4], the average degrees of conflict of adjacent belief rules are 0.5920, 0.6391 and 0.6953, respectively. Note that belief rules are incomplete in these models, otherwise the degrees of conflict may be even higher. ER approach can achieve a good performance when aggregating conflicting BBAs with various weights, and it is applied in the inference process of BRB models. A variety of alternative rules are also capable of aggregating conflicting belief functions. Murphy discussed this problem and proposed an averaging method [17], and Deng et al. put forward a modified approach [8]. In this paper, we therefore investigate the feasibility of using weighted averaging operator in the inference process.
Initial belief rule base for Box-Jenkins gas furnace example
Comparison results for the Box-Jenkins gas furnace example
Comparison results for two dimensional Sinc function example
Initial modified belief rule base for point estimate
Initial modified belief rule base for interval estimate
In this section, the BRB model using weighted averaging operator in its inference process is presented. Based on this simplified model, an approach is put forward to reduce the possibly redundant referential values of antecedent attributes.
Inference using weighted averaging operator
Aggregating the activated belief rules with weighted averaging operator instead of ER approach would weaken the nonlinearity of the BRB model, especially in the case of one input. In order to improve its capability of approximating nonlinear systems, we use a nonlinear formula rather than Equation (2) when transforming the input
The belief degrees on the inference output generated by weighted averaging operator is as follows:
Let
Let
The inference output could then be calculated as
If all rules are complete, i.e., β
k
= 1, k ∈ {1, ⋯ , L}, then the inference output could be unified as follows
In the BRB model (1), there are design parameters in total. In the modified model (20), the number of design parameters is . Thus more than (N - 2) L parameters are reduced in the general case and (N - 1) L parameters can be reduced when all rules are complete. As M and N are very small compared with the number of rules which is designed to be , usually more than half of the parameters can be reduced. The reduction of design parameters and the usage of weighted averaging operator in the modified BRB model not only reduce the model complexity, but also significantly cut down the time needed for training and inference process. Besides, it is easier to set initial values for these design parameters.
In the training of BRB models, parameters must satisfy the constraints (15-a)–(15-f). When training the modified BRB system, constraints (15-a),(15-b) and (15-f) should be replaced by the following inequalities.
Though a different inference rule is used, the modified BRB model possesses the universal approximation capability. According to the proof provided in [5], the Stone-Weierstrass theorem [7] is applied to prove its approximation capability.
(1) The input space U can be decomposed into multiple local regions by the referential values, which can be represented by the hyperspace [A1,1, A1,J1] × ⋯ × [AM,1, AM,J M ]. In a modified BRB model, each input falls into a specific local region or on the boundary of adjacent local regions. It is obvious that the inference output of a modified BRB model is continuous within a local region. Thus we only need to prove the continuity at the intersection rule points.
If the input
It shows that the limit of the estimated output f (
(2) Let f1, f2 ∈ F, so we can write them as follows
(3) Without loss of generality, considering a single input modified BRB model with two different belief rules as follows:
(4) We can simply construct a modified BRB model in which v i > 0, i = 1, ⋯ , L. The output of the BRB model is surely bigger than zero for each x ∈ U.
This completes the proof of theorem.□
Generally the approximation accuracy can be increased by using more referential values for each antecedent attribute. However, the increase of referential values may cause several problems: 1) the increase of belief rules, making it more complex to train and inference; 2) overfitting of the training data; 3) many turn points in the fitting curve, since each referential value is the intersection of two or more belief rules. Therefore it is not that the more referential values are used in the BRB model, the better is the performance.
In the modified BRB model, the consequent of each rule v k is a numeric number and is roughly equal to . The referential values of each rule R k and its consequent v k together constitute a referential point , which is on the fitting curve (or surface). In the case of using 6 referential values in Example 1, 6 such referential points are plotted by pentagrams in Fig. 1, and four of them are at the positions of extreme points of the nonlinear function. Intuitively, to achieve a good approximation performance, the referential points should be at least as many as the extreme points of the nonlinear function. Using more referential points cannot achieve significant increase of performance in most cases. For instance, when we increase the referential values from 4 to 6 in Example 1, the MSE decreases slightly from 0.00212 to 0.00195. Thus, to model a nonlinear system, relative more referential values can be set at the beginning of constructing a modified BRB model. Then all possibly redundant ones should be found after training and abandoned. Afterwards the modified BRB model should be trained again and its performance should be compared with the one before reduction. If its performance decreases dramatically, we abandon only half of the possibly redundant referential values and verify its performance once more. Repeat this process until the number of referential values is determined.
To find the possibly redundant referential values, we can make use of v k . There is generally no preference between v k and vk+1. However, if there exists a certain i ∈ {1, ⋯ , L} such that v i < vi+1 < ⋯ < vi+k or v i > vi+1 > ⋯ > vi+k, k ⩾ 2, it implies some useful information. In the case of one input variable, it means that referential points vi+1, ⋯ , vi+k-1 lie between two extreme values v i and vi+k, and that they are possibly redundant. In Fig. 1, the second and forth referential points meet this condition, and their corresponding referential values for x can be considered as redundant. In the case of two input variables, we arrange all the v k in a matrix [vi,j] of J1 × J2, where J1 and J2 are the numbers of referential values for x1 and x2, and vi,j stands for the consequent of the rule with and as antecedent attributes. If there exists a j ∈ {1, ⋯ , J2} such that vi,j < vi,j+1 < ⋯ < vi,j+k or vi,j > vi,j+1 > ⋯ > vi,j+k, k ⩾ 2 for each i ∈ {1, ⋯ , J1}, then we think k - 1 referential values for x2 are redundant. Similarly, if there exists an i ∈ {1, ⋯ , J1} such that vi,j < vi+1,j < ⋯ < vi+k,j or vi,j > vi+1,j > ⋯ > vi+k,j, k ⩾ 2 for each j ∈ {1, ⋯ , J2}, then we think k - 1 referential values for x1 are redundant.
The proposed approach can only be applied to point estimate. As to interval estimate, some rules are incomplete and their inference output are intervals rather than a certain value v k , thus the proposed approach cannot be used in that case.
Case study
To demonstrate the performance of the modified BRB model, we exploit case studies on three well known benchmark datasets. The Box-Jenkins gas furnace experiment was employed in the original BRB model [5] Approximation-property, thus it is used to compare the performance of the modified model with the original one. The Sinc function is compared with some reported results on the same dataset to show the effectiveness of the proposed attribute reduction approach. The third case study is used to justify the ability of the proposed method in the uncertain case.
All simulations are implemented on the PC with 2.90 GHz CPU and 2 GB RAM. The nonlinear optimisation solver fmincon in the Optimisation Toolbox of Matlab is used for training parameters.
Box-Jenkins gas furnace experiment
In the Box-Jenkins gas furnace experiment, the original dataset was recorded from a combustion process of a methane air mixture, and consists of 296 data pairs {(u (t) , y (t)) ; t = 1, ⋯ , 296}, where u (t) is the input gas flow rate, and y (t) is the observed output CO2 concentration at the sampling time t. For the sake of comparative study, the same model from [5] is used.
Thus there will be 292 input–output data pairs. We use the same parameter setting in [5] to construct the BRB model: five linguistic terms are used to define u (t), which are negative large (NL), negative small (NS), zero (Z), positive small (PS), and positive large (PL). These linguistic terms are associated with the following numerical referentialvalues:
Given the above referential values, there are 25 referential combinations of the two antecedent inputs y (t - 1) and u (t - 4), leading to 25 belief rules in total. Table 2 lists the initial BRB parameters. There are 167 parameters in the original BRB model while only 67 parameters are remained in the modified one. The estimated outputs of the two BRB models with the initial parameters are plotted in Fig. 2. From the figure we can see that the two estimated output curves almost overlap, and there is little difference between their estimated errors. This is also reflected by the MSE between the actual output and the initial estimated outputs of them, which are 0.6223 and 0.6655, respectively. The result shows that using weighted averaging operator to replace ER approach in the BRB model would not cause obvious decline in its approximation capability.
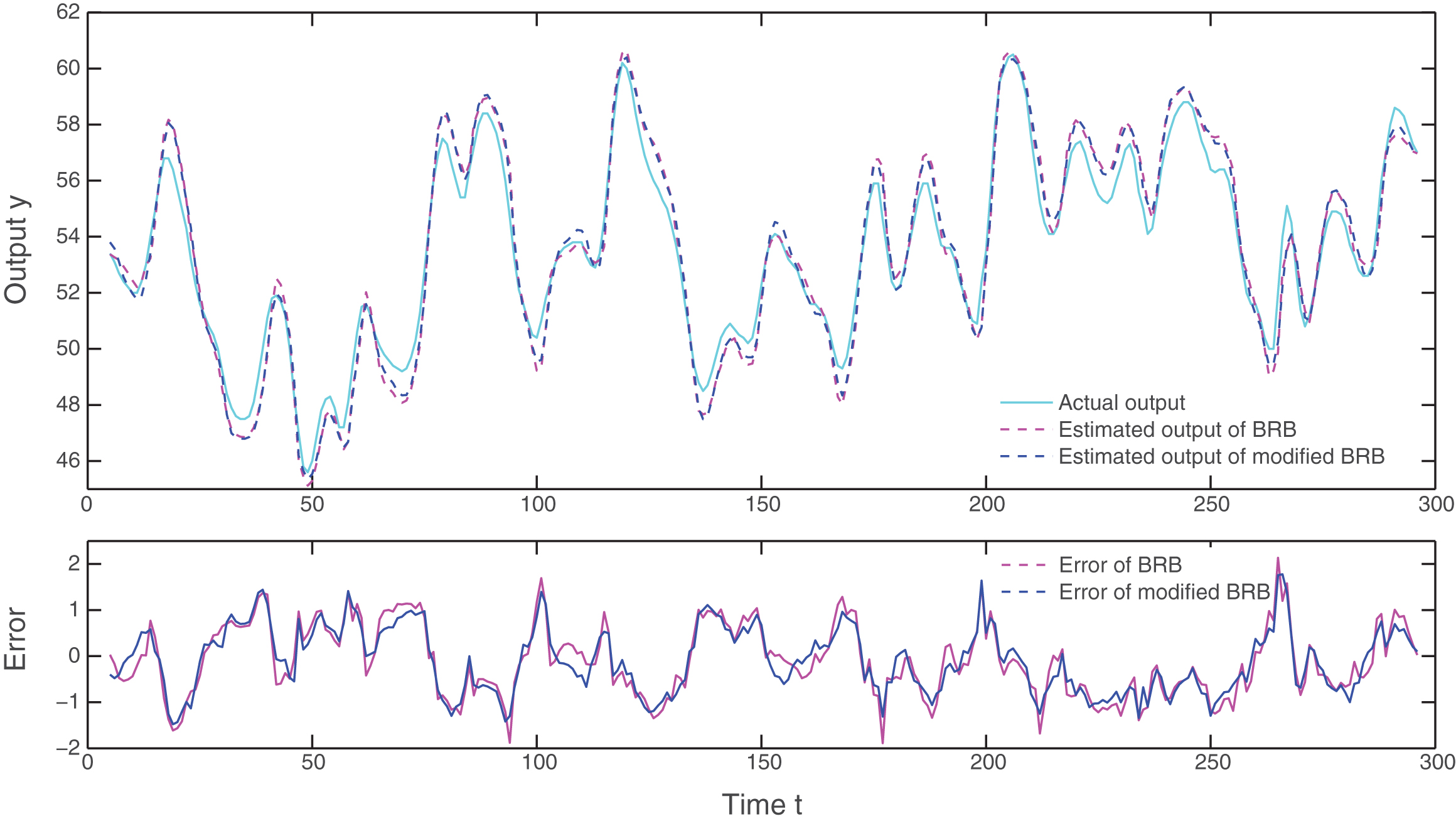
BRB with initial parameters.
To train the BRB models, the first 150 data pairs are used as training set, and the remaining part of the dataset is used to test the training effect for validation purpose. Figure 3 shows the estimated outputs of the two trained BRB models for both training and testing datasets. It can be seen from the figure that the trained models have much better performance than the initial BRB models, and the modified BRB model is as good as the BRB model.
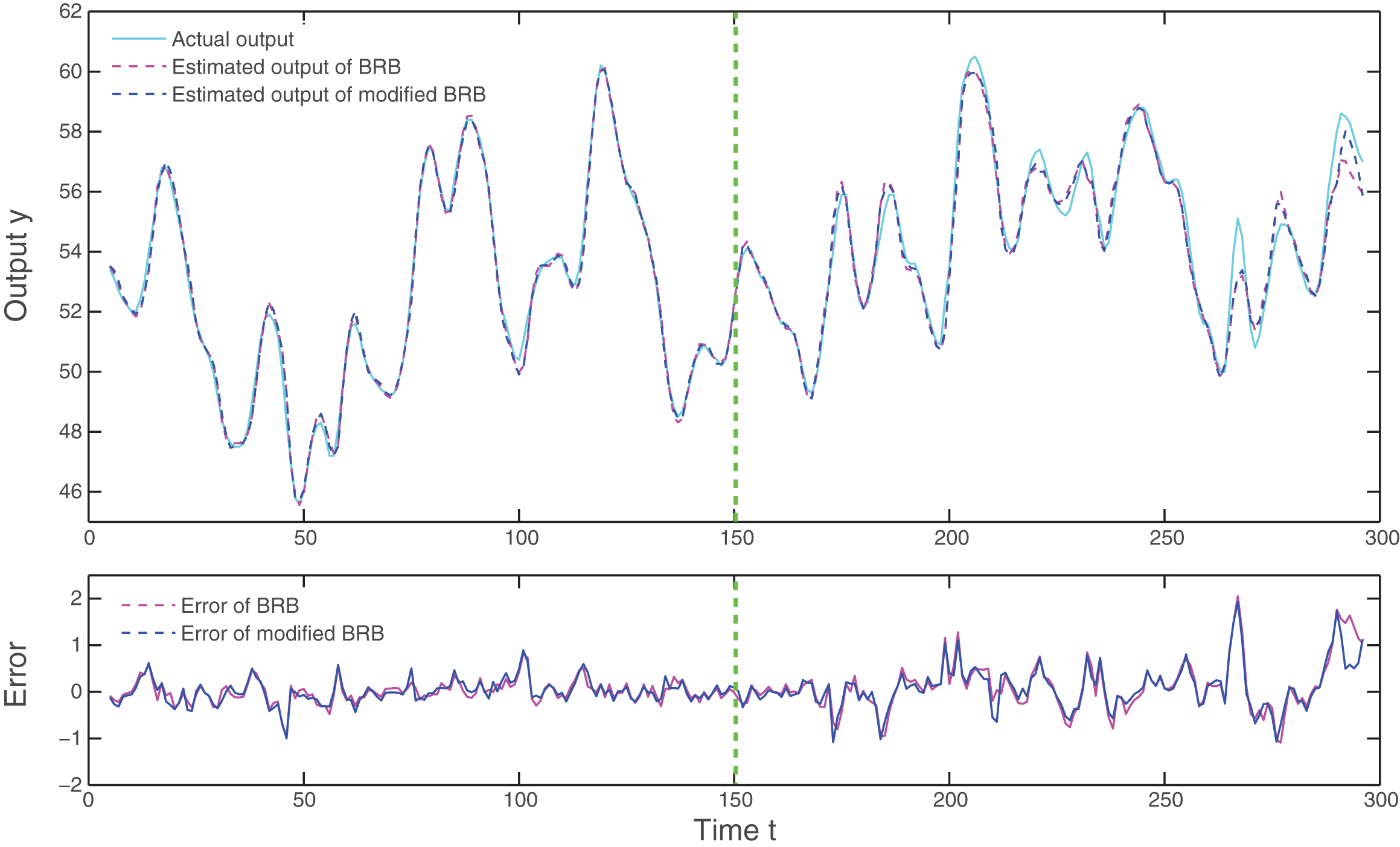
BRB with trained parameters.
Table 3 compares the original and modified BRB models with different numbers of referential values. We can see that the MSE is monotonically decreasing with the increase of the referential values, and that the modified BRB model achieves a comparative performance with BRB model in all cases. When it comes to the training time, the proposed method has a much better performance as shown in the last column. The training time of the modified BRB model is less than 1/10 of the original BRB model, and it increases slower as more referential values are used. Thus the modified BRB model is more suitable for complicated systems with a large scale belief rule base.
The data for this case study are generated from the following two-variable nonlinear function:
Figure 4 shows its original surface. The training set consists of 1681 data points, arranged in a regular grid within the [–10,10]×[–10,10] domain. Initially, 9 referential values {–10, –7, –5, –2, 0, 2, 5, 7, 10} are used for both x1 and x2. Similarly to the first case study, a BRB model with 81 belief rules could be established. The initial values for θ
k
and δ
i
are all set to be 1, and v
k
is arranged in a square matrix as explained in section 4.2 and initial values are defined as follows.
Using MSE as the objective function, a trained BRB model could be obtained. The trained values for v k are listed in the following matrix.
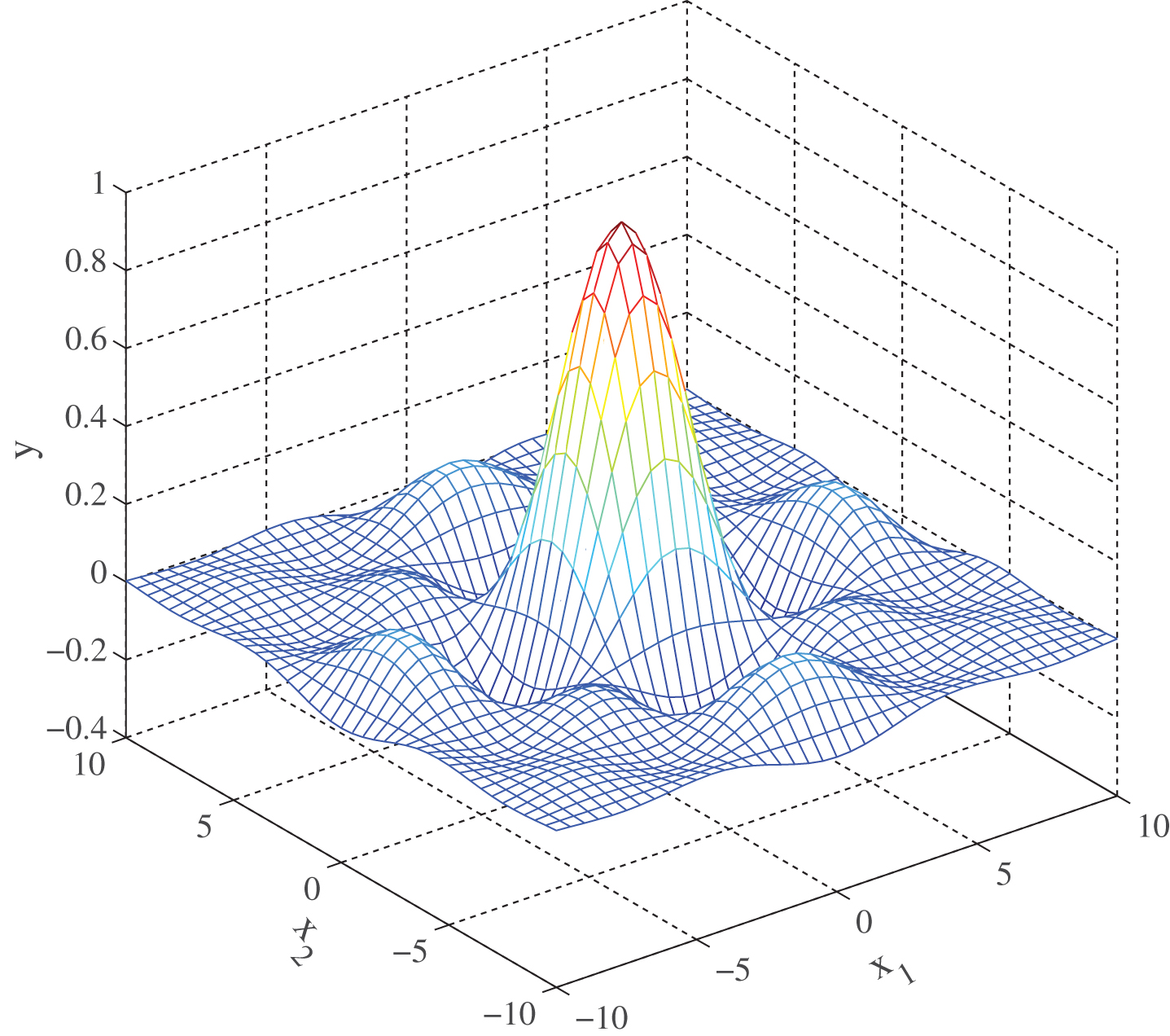
Original surface of two dimensional Sinc function.
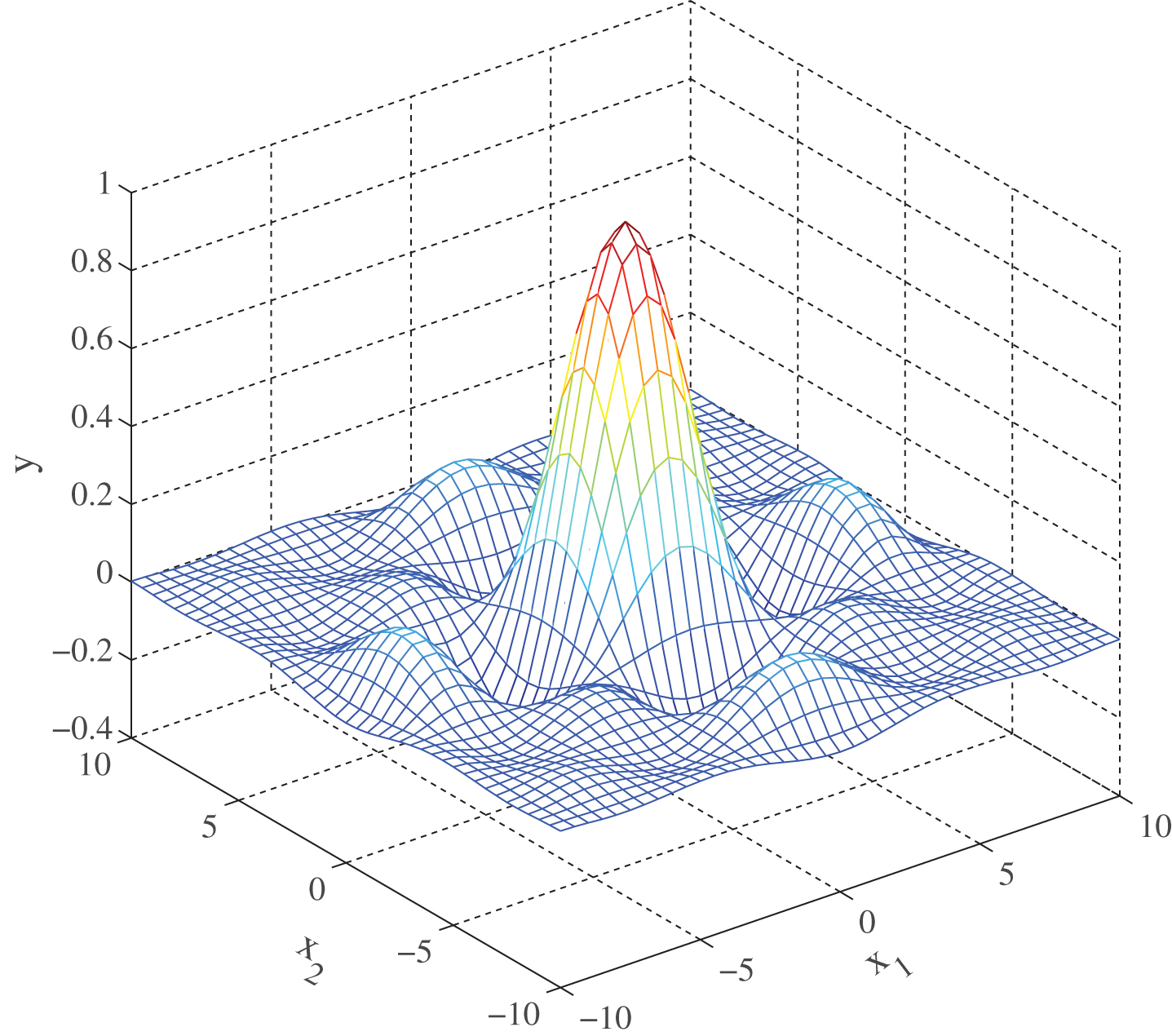
Estimated surface of modified BRB with 7 referential values.
In this matrix, we have vi,3 > vi,4 > vi,5, vi,5 < vi,6 < vi,7, i = 1, ⋯ , 9 and v3,j > v4,j > v5,j, v5,j < v6,j < v7,j, j = 1, ⋯ , 9. According to the attribute reduction approach introduced in section 4.2, two referential values could be reduced for both x1 and x2. Using the remaining parameter values as initial values and training it in the same way, another modified BRB model is established. The estimated surface is presented in Fig. 5.
Table 4 compares the results of the modified BRB models with some existing methods. The results obtained by our models are much better in terms of MSE. With the same number of rules, the modified BRB model with 7 referential values has a much smaller MSE than the 49-rule method provided by Evsukoff et al. Compared with the fuzzy model proposed by Rezaee, we also obtain a much smaller MSE, but more rules are used in our model. Note that the MSE decreases a lot after reducing the referential values from 9 to 7, but it would increase if referential values are further reduced to 6, this demonstrates the effectiveness of the proposed attribute reduction approach.
In this example [4, 26], there are a class of nonlinear functions G = {y = g norm (x) + Δg (x)} with the nominal function g norm (x) = cos(x) sin(x) and the uncertain part Δg (x) = γ cos(8x), 0 ⩽ γ ⩽ 0.2. The function from the class is defined in the input domain U = {x|-1 ⩽ x ⩽ 1} and the set of measured input is X = {x t |x t = 0.021t ; t = -47, - 46, ⋯ , 47}.
Firstly, we consider the approximation of the nominal function. The initial values for the modified BRB model are listed in Table 5. Training the model with the 95 input-output data pairs (x t , g norm (x t )), trained values for A j and v k are obtained: A = { –0.9968, –0.7529, –0.5203, –0.3064, –0.1122, 0.1122, 0.3064, 0.5203, 0.7529, 0.9968} and [v k ]=[–0.4679, –0.5070, –0.4321, –0.2902, –0.1227, 0.1161, 0.2901, 0.4390, 0.5084, 0.4656]. It is easy to see that –0.5070 < –0.4321 < –0.2902 < –0.1227 <0.1161 <0.2901 <0.4390 <0.5084, thus we can at most reduce 6 referential values according to section 4.2. Set the new initial referential values for x as { –0.9968, –0.7529, 0.7529, 0.9968} and the values for v k as [–0.4679, –0.5070, 0.5084, 0.4656], then train the model again. Figure 6 shows the estimated outputs of the modified BRB model with 10 and 4 referential values. We can see that the modified BRB can achieve an even better performance after reducing 6 referential values. In fact, the MSE decreases from 1.0 × 10-5 to 2.7 × 10-6 after 6 redundant referential values are abandoned. Generally, more referential values would lead to a higher approximation accuracy. However, one rule changes to another rule at each referential value, which may reduce the smoothness of the fitting curve as well as the overall approximation accuracy if many redundant referential values are used. This could be seen from the partial enlargement in Fig. 6.
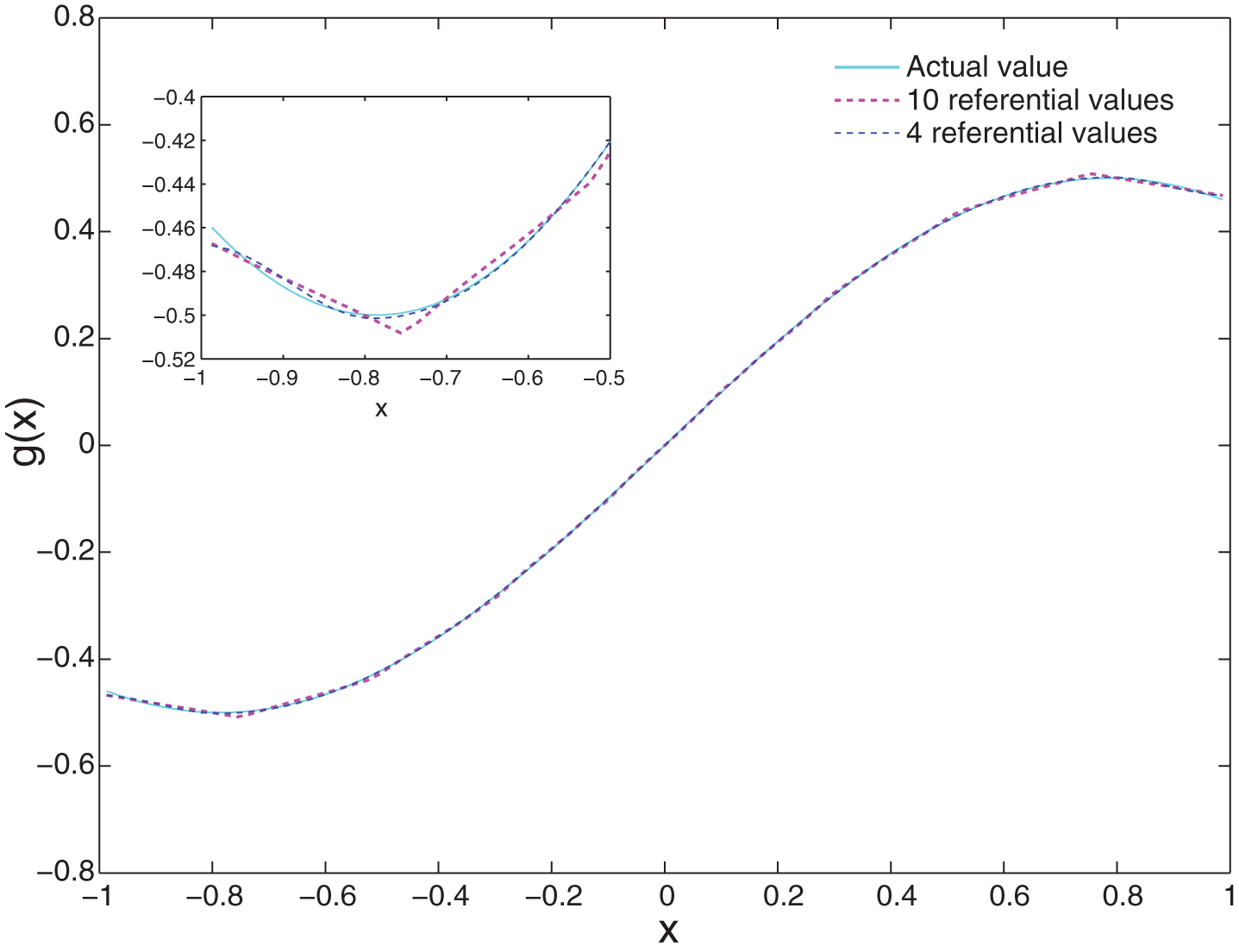
Comparisons of modified BRB with different numbers of referential values.
In the following, we consider the nominal function combined with the uncertain part. In [26], eight triangular and equidistant membership functions are used for the first-order fuzzy model, thus generating 8 rules for upper bound and lower bound separately. Firstly, we also use 8 referential values for x, and the initial modified BRB model is listed in Table 6. The L∞ norm in Equation (13) is used to train the model. The min-max problem can be solved as the nonlinear programming problem of minimizing σ subject to the following inequalities [4]:
Figure 7 plots the estimated lower and upper bounds of the trained modified BRB model and the fuzzy model. We can see that the red curve covers all the uncertain outputs and gives a good estimation of the upper and lower bounds. Compared with the fuzzy model, it achieves smaller approximation errors in some local regions, but in regions near the nodes it has much bigger approximation errors. This is caused by lack of enough referential values.
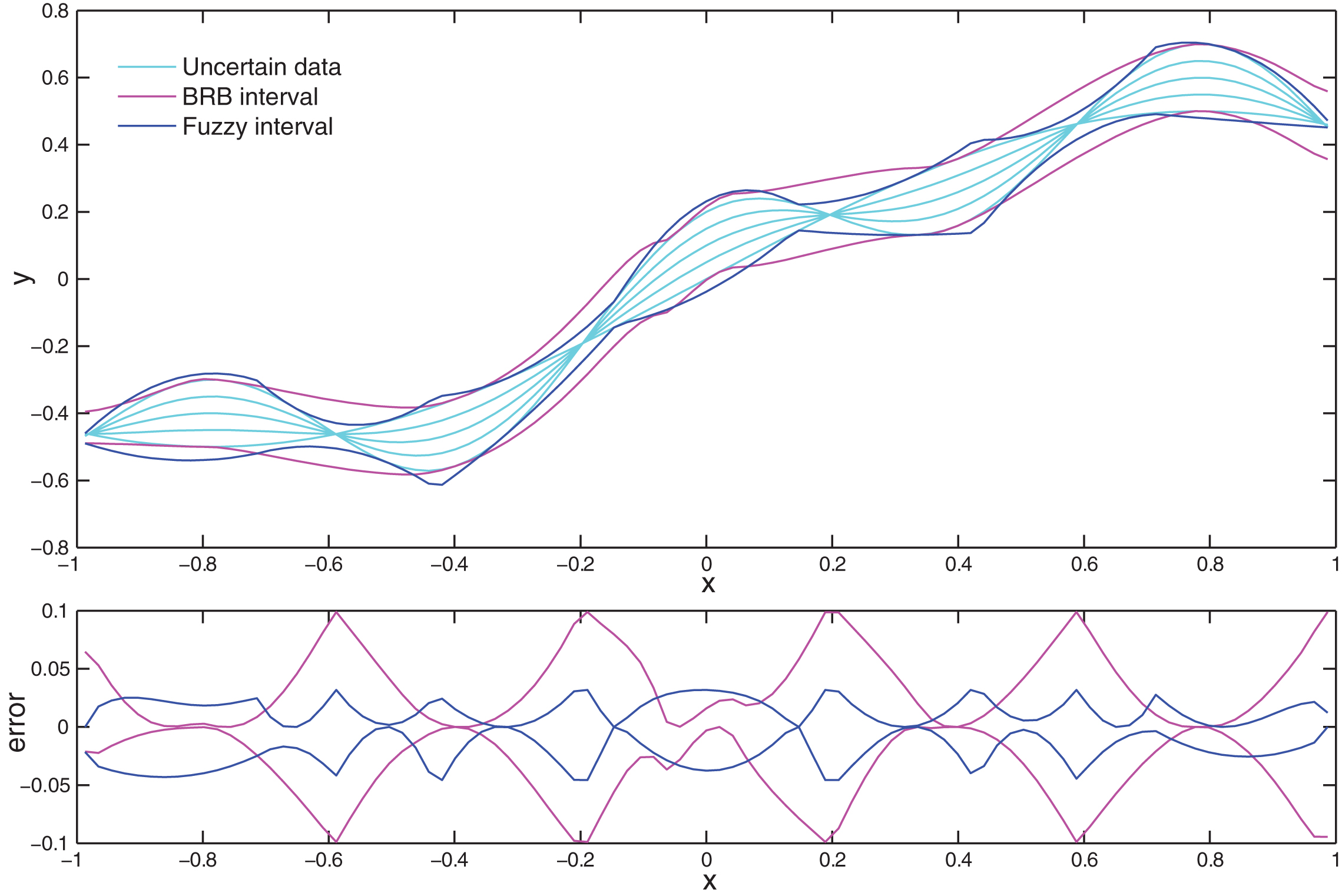
Comparison of modified BRB(8 ref.) and fuzzy model.
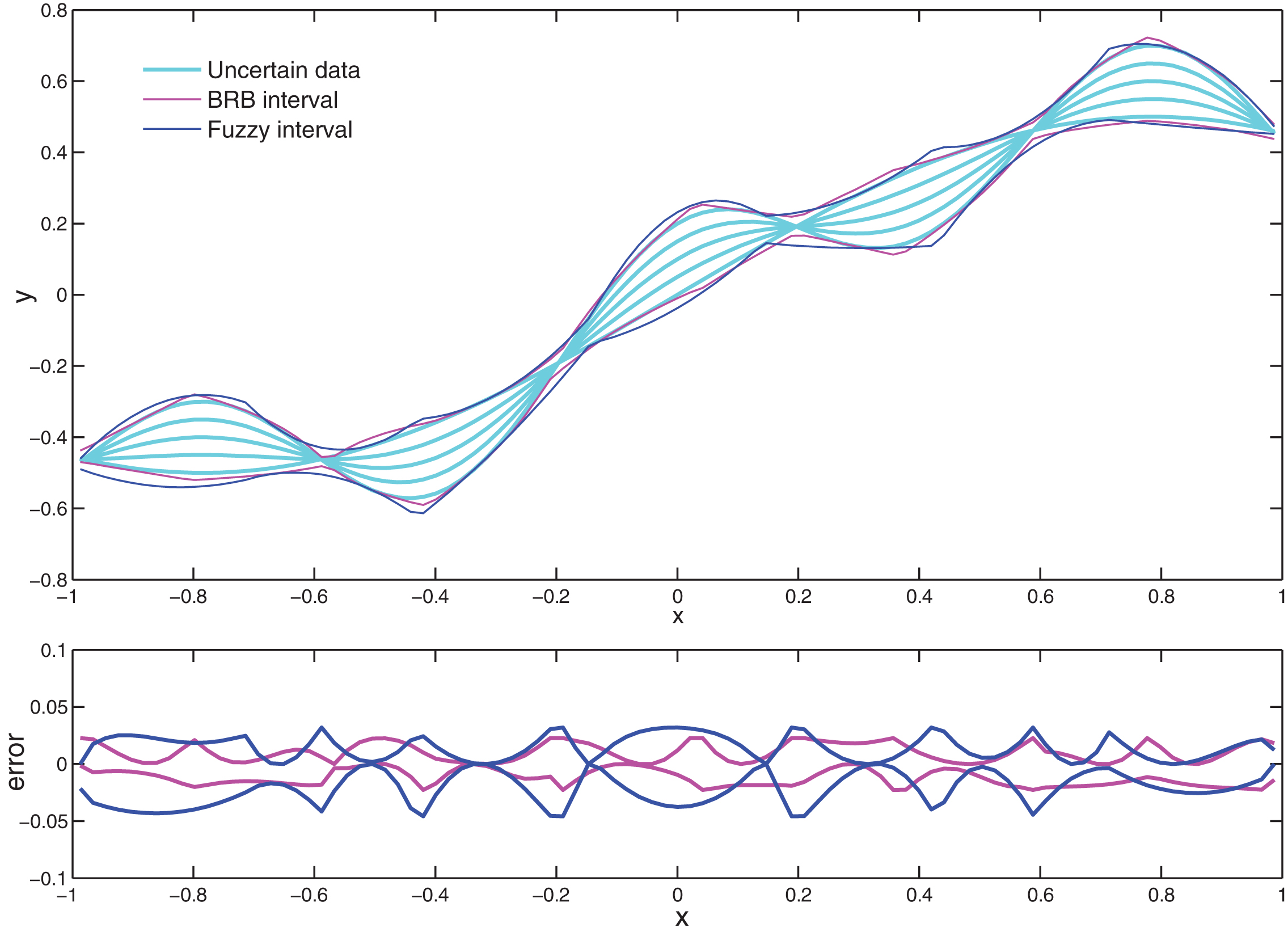
Comparison of modified BRB(11 ref.) and fuzzy model.
In the fuzzy model, the lower and upper bounds are estimated by independent fuzzy models. Though 8 membership functions are used, there are 16 fuzzy rules in total. In the modified BRB model, both bounds are estimated by one model and there are only 8 belief rules. If we increase the number of belief rules to 16, a better performance could be obtained. In fact, when 11 belief rules are used, the modified BRB model would outperform the first-order fuzzy model, as shown in Fig. 8. It is easy to see that the modified BRB model obtains a better interval estimation.
In this case study, we can also use two independent modified BRB models with complete belief rules for the upper and lower bounds respectively, just like the fuzzy model. However, one BRB model with incomplete belief rules is more preferred in the uncertain case since it has a simpler training process with comparative approximation results.
BRB models are capable of modelling uncertain nonlinear systems. In this paper, weighted averaging operator is applied in the inference process in place of ER approach to aggregate all activated belief rules. This substitution together with some algebraic transformations generates the modified BRB model, which has a simpler model structure. Compared with the original BRB model, it reduces model parameters significantly and cut down the time for training rapidly. Besides, its universal approximation capability is guaranteed by the Stone–Weierstrass theorem. Based on the special structure of the modified BRB model, an approach for reducing possibly redundant referential values is put forward to achieve a tradeoff between approximation accuracy and model complexity.
Comparisons between the modified BRB model and the original one show that they have comparative performance though the former one has a much simpler structure. The performance of the modified BRB model with the attribute reduction approach is further validated by two well known case studies. It should be noted that the method is not proposed to replace the existing methods, but to improve the efficiency of the original BRB model and provides an alternative to the uncertain nonlinear systems identification problem.
The proposed attribute reduction approach is designed for point estimate problems. In the case of interval estimate, belief rules are incomplete with different degrees of uncertainty. Both consequents and degrees of uncertainty should be considered when reducing referential values, which will be researched in our future work.