
Abstract
Incremental clustering algorithms can find wide applications in real-time streaming data processing and massive data analysis. Such algorithms need to continuously load data, and thus data transmission and access can induce non-negligible time overhead. Additionally, we have proposed two algorithms to exploit high data parallelism for incremental clustering on CUDA-enabled GPGPU: the Top-down (TD) algorithm and Moderate-granularity (MG) algorithm. In this paper, we adopt TD and MG algorithms as a case study to optimize data transmission and access based on CUDA. First, we reinterpret the two algorithms in the point view of overlapping read/write and computing operations on CUDA-warp level. Second, we adjust the flow of TD and MG algorithms to enhance data locality. As a result, shared memory can be sufficiently utilized. Third, we reorder input data points to raise data rate of global memory through coalesced memory access. Fourth, we hide part of data transmission latency by running multiple CUDA streams. Experiment results validated the efficiency of our optimizations.
Introduction
Background
Incremental clustering algorithms are essential for many application scenarios, such as time-limited applications, memory-limited applications and redundant data elimination. These typical application scenarios always place high demand on computing power of the hardware platform. Parallel computing is a common method to satisfy this demand. General Purpose Graphic Processing Unit (GPGPU) is a promising parallel computing device. GPGPU enjoys various advantages including but not limited to the following.
Dramatic computing power: A GPGPU integrates enormous processing cores into a single processor and has significantly stronger computing power than a single CPU. Moreover, the GPGPU is undergoing noticeably faster computing-power growth than the CPU. Affordability and low cost-effectiveness ratio: GPGPUs are common devices in modern desktops and laptops and thus furnish promising high performance computing devices with the absence of extra financial burden. In addition, the GPGPU is more cost effective than the CPU in terms of floating-point computation power per unit cost. Programmability: Compute Unified Device Architecture (CUDA) provides C/C++ like programming tools to parallel computing developers. CUDA enjoys superior programmability than specified acceleration devices like FPGA.
Our previous work proposed two GPGPU-friendly incremental clustering algorithms [5, 6], namely, the Top-down algorithm (TD algorithm) and the Moderate-grained algorithm (MG algorithm). These two algorithms focus on enhancing the data parallelism. Consequently, the computing power of GPGPU corers can be more sufficiently utilized.
Nevertheless, only high data parallelism is not enough if we aim at taking full advantage of GPGPU computing power. Even in the latest research works of high performance computing, decreasing data transmission and access latency is still indispensable [1, 2, 16, 19]. Data transmission and access latency may significantly slow the execution of an incremental clustering algorithm, due to the fact that the algorithm needs to continuously load newly arrived data.
The work of [16] enhances the task and data parallelism of H.264/ACV encoding on a CPU-GPGPU hybrid platform. Their method furnishes efficient task scheduling and load balancing at no cost of extra computational overhead. Experiments show that this method achieves significant speedup compared to existing GPGPU-only methods. The method of [16] is similar to our method in the sense that both methods emphasize data parallelism and leverage CPU-GPGPU hybrid platform. Nevertheless, our method focuses on incremental clustering.
Michael et al. improve DBSCAN algorithm and maximize throughput of spatial-data oriented clustering algorithms based on a CPU-GPU hybrid system [11]. This method identifies eps-near neighbors of every input data point and thus resolves a neighbor table. The neighbor table builds indexes for the input data, and thus data locality is enhanced. The data, which are pre-fetched into share memory, tends to be repeatedly accessed. Consequently, high bandwidth of shared memory is fully utilized and low-bandwidth global memory access is minimized. Additionally, CUDA kernel execution and host-GPGPU data transfer are overlapped by leveraging CUDA streams. This method significantly increases the throughput of GPGPU-powered DBSACAN algorithm. However, this improved DBSCAN algorithm cannot incrementally cluster data due to the fact that it requires accessing entire input data to build indexes. By contrast, the original DBSACAN can incrementally cluster input data.
Zhao et al. point out that high performance computing (HPC) systems are stepping into a data-centric era due to the fact that enormous emerging workloads are data intensive. They argue that existing distributed file systems (like Google File System, GFS, and Hadoop Distributed File System, HDFS) cannot accommodate metadata-intensive and write-intensive workloads due to the following two reasons: First, storage granularity of GFS or HDFS is excessively large while size of a metadata file is typically small. Oversized granularity leads to inefficiency of metadata storage and transmission. Second, existing fault tolerance mechanisms rely on data replication but not checkpoints. Consequently, such mechanisms generate limited writing operation and thus bypass optimization of writing. However, data-centric HPC systems adopt checkpoints and inevitably induce many writing operations. Consequently, optimization of writing operation requires reconsidering. Zhao et al. propose a file system to overcome these two drawbacks and validate the efficiency through simulation. The work of [9] designs a general-purpose file system to accommodate data intensive HPC applications. Whereas, our work focuses on optimizing the data transmission/access between diverse functional units of the CPU-GPGPU hybrid platform.
Jo et al. propose a framework to integrate CPU, GPGPU and Intelligent Solid State Device (iSSD) into a collaborative computing system [18]. CPU is suitable for executing sequential high-time-complexity tasks; high-data-parallelism task can readily fit into GPGPUs; iSSD is capable of in-storage parallel processing and thus significantly reduces latency of data transmission. Diverse computing tasks are scheduled among the three computing devices based on synchronous dataflow model (SDF) and best imaginary level scheduling (BIL). Jo et al. apply their framework to data-intensive algorithms (k-means, Page Rank and Sim Rank) and validate the efficiency of this framework. However, this framework mainly focuses on integration of heterogeneous devices and does not explain maximizing GPGPU computing power utilization under the background of incremental clustering.
Main contribution
We optimized the data transmission and access of both TD algorithm and MG algorithm based on CUDA. Our optimizations include: First, we reinterpret our previous work (TD and MG algorithms) from the point view of warp-level data access. Second, we reform the flow of the two algorithms and compare their speedups achieved by utilizing share memory. Third, we reorder the input data to coalesce global memory access. Fourth, we overlap the data I/O operation and the computation operation among CUDA streams.
The rest of this paper is organized as follows: Section 2 introduces CUDA features relevant to our methods and outlines our optimizations. Section 3 describes our optimization methods in detail. Section 4 presents and analyzes the experiment results. Section 5 concludes this paper and points out the future work.
CUDA features relevant to the optimization methods
Execution mode of CUDA threads
A GPGPU contains a certain number of Streaming Multiprocessors (SM). Inside an SM, the basic unit of thread scheduling is a warp. Threads within the same warp are scheduled together and execute the same instruction (but the operands can be different). One SM contains a warp scheduler, an instruction dispatch unit, a data read/write unit, a load/store unit, processor cores, and a special function unit.
Taking the NVIDIA Fermi architecture as an example, a warp contains 32 threads; an SM contains 2 warp schedulers, 2 instruction dispatch units, 16 data read/write units, 32 processor cores, and 4 special function units.
Under Fermi, an SM can schedule two warps simultaneously. Two warp schedulers select a warp in ready state, respectively. Afterwards, both schedulers execute the selected warp. Computing operations of a warp can be overlapped with read/write operations of another warp on the premise that two or even more warps of thread run simultaneously on one SM. That is, the number of threads running on a GPGPU should two times or even more than the total number of processing cores on the GPGPU. The situation is similar under other NVIDIA GPGPU models like GTX 660.
Data transmission concurrency in a GPGPU-CPU hybrid system
In CUDA, GPGPU is a co-processor of CPU. The serial code and parallel code (i.e. CUDA kernel) run on CPU (host) and GPGPU (device), respectively. It is a requirement to load the input data of a kernel into GPGPU global memory before the kernel can be launched.
Figure 1 shows the data flows in a GPGPU-CPU hybrid system and summarizes our optimization methods. The data are transferred from the external storage (disk) to GPGPU’s global memory through two consecutive transmissions: disk-to-host transmission and host-to-device transmission. Subsequently, read/write units read data from global memory into registers of processing cores (for computing) or shared memory (for prefetching).
Data flow in a GPU-CPU hybrid system and our optimization methods.
The input data volume to an incremental clustering algorithm can be huge. However, the output data volume is generally small. Consequently, we focus on the input data transmission, i.e. disk-to-host and host-to-device transmissions in Fig. 1. CPU and GPGPU have separate I/O units. Consequently, the two transmissions are parallelizable. Moreover, CUDA stream [8] can leverage this parallelism. A single CUDA stream contains a series of serial instructions. Multiple CUDA streams can run concurrently. Access latency of shared memory is dramatically lower than that of global memory.
Although programming-visible cache like shared memory is available in CUDA, its capacity is limited. Access latency of GPGPU global memory is comparably high (400
After the reordering, threads of a CUDA warp will always read valid data from consecutive memory addresses, namely, the memory access is coalesced. More reading operations are required to copy the same amount of data with the absence of memory coalescing. The principles of CUDA data reordering is amply illustrated in reference [8]. More details related to our data reordering method will be discussed in Subsection 3.3.
Optimization methods
Basic terminologies
Fundamental terminologies were detailedly introduced in our previous works [5, 6]. For integrity of this paper, we explain some basic terminologies as follows.
If
A data analysis task adopts discrete time system. Time stamps are labeled as 1, 2, 3, … This task is incremental clustering if and only if:
When When
An algorithm intended for incremental clustering is an incremental clustering algorithm. The time interval [
Some incremental clustering algorithms divide step
In the first part,
The first part can be accomplished by a batch-mode clustering algorithm, and it is the batch clustering part of step
We exploit high data parallelism for incremental clustering in pursuant to the hardware structure of NVIDIA GPGPU [5, 6].
Pursuant to Subsection 2.1, we need to run thousands of threads in single-instruction-multiple-data (SIMD) mode if we aim to fully utilize every core of GPGPU as well as hide the read/write latency of warps.
However, our previous works [5, 6] find that incremental algorithms are facing an accuracy-parallelism dilemma on GPGPU. On one hand, block-wise algorithms first clusters
Flows of two high data-parallelism incremental clustering algorithms.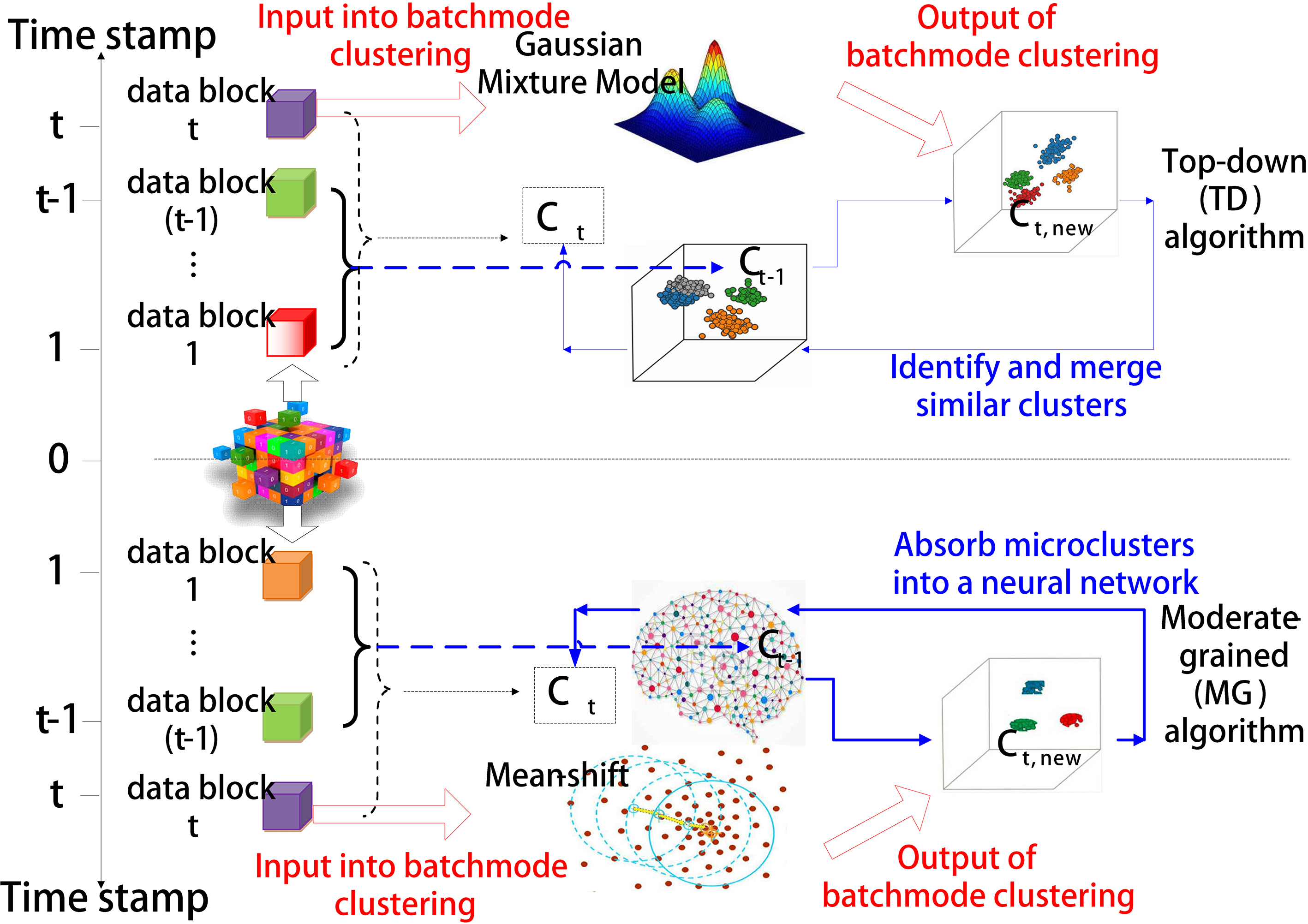
Our previous works propose two incremental clustering algorithms to seek balance between accuracy and parallelism: the Top-down algorithm (TD) and Moderate-granularity algorithm (MG). Figure 2 illustrates the flows of both algorithms. We summarize similarities and differences between these two algorithms in Table 1.
Comparison between Top-down (TD) and Moderate-granularity (MG) algorithm
Adjusted flow of bath clustering part of TD algorithm.
GPGPU shared memory enjoys significantly higher bandwidth than global memory. However, capacity of shared memory is much smaller than that of global memory. In CUDA, shared memory is a program-visible cache; pre-reading data into shared memory and using them properly can effectively reduce data access latency of CUDA threads.
Assuming that time overhead of a CUDA thread read a data point
Prefetching can reduce data access latency if
We adjust the flow of batch-mode parts of both TD and MG algorithm to fully utilize shared memory. Take the TD algorithm as an example, the algorithm runs EM algorithm of GMM in batch-mode part of each step. Suppose TD algorithm receives
Calculate the probability density of Calculate the probability that
where Update the weights Update mean vectors Update covariance matrixes
Under the conventional flow, data dependence exists between two successive parts, and thus each part is required to start after the previous part completes. As a result, data points prefetched into shared memory during the current part cannot be reused by the subsequent parts. Subsequent parts inevitably reload data points from global memory into shared memory if they tend to utilize shared memory. Pursuant to Eq. (1),
As illustrated by Fig. 3, we adjust the flow to decrease
Let
The adjusted process flow enhanced data locality. We optimize shared memory usage of MG algorithm in a similar manner.
In the
Typically, all these data are stored in a one-dimensional array.
Data reordering in GPGPU global memory: (a) memory access pattern before reordering, (b) memory access pattern after reordering.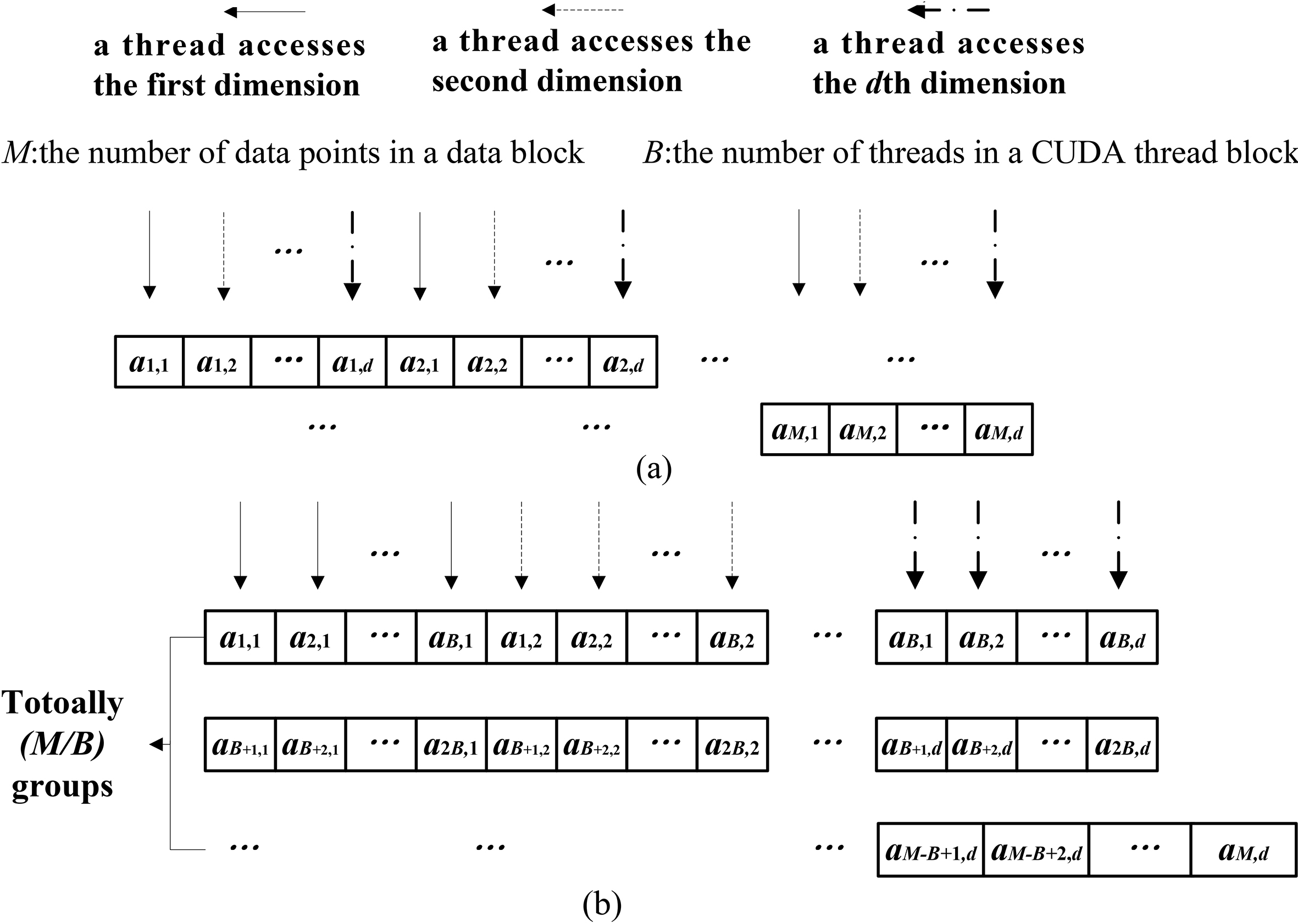
Figure 4 illustrates the effectiveness of data reordering. Let
As illustrated in Fig. 5, part of the data transmission latency can be hidden, if the following conditions are satisfied: First, multiple CUDA streams execute concurrently. Second, every CUDA stream covers disk-to-host transmission, host-to-device transmission, and execution of CUDA kernels. Relevant symbols are explained as follows:
Comparison between non-pipeline and pipeline patterns: (a) Non-pipelined pattern; (b) pipelined pattern.
We consider the speedup of pipelined pattern up to step
Under the non-pipelined pattern, algorithm execution time up to step
Speedup of pipelined pattern is:
Theoretically,
Under the non-pipelined pattern, the throughput is:
Under the pipelined pattern, the steady-state throughput is:
As a result, speedup of pipelined pattern is:
Hardware and software environment
Hardware and software parameters are shown in Table 2. All experimental codes are written in C++.
The double-precision floating-point data type was adopted for both CPU and GPGPU codes.
A single step of both TD and MG algorithms includes two parts: the batch clustering part and the incremental part. The batch-mode and incremental parts are executed on GPGPU and CPU, respectively. In the batch clustering part of TD algorithm, Bayesian Information Criterion (BIC) was adopted to identify the number of clusters contained by a single data block. The searching range of BIC is 50
Hardware and software parameters
Hardware and software parameters
As shown in Tables 3 and 4, 256-color grayscale images from USC-SIPI data set [17] were used as inputs. A data point includes three components: grayscale, X-coordinate and Y-coordinate. Clustering results are incrementally segmented images. Clustering accuracy is measured by Rand Index [15]. We need a benchmark to calculate Rand-Index-value of a clustering result. The clustering results of conventional batch-mode GMM EM algorithm and mean-shift algorithm are adopted as benchmark for incremental clustering results of TD and MG algorithms, respectively. The value of Rand Index is within the range [0, 1]. Larger Rand Index means higher accuracy.
Accuracy of TD algorithm on the datasets
Accuracy of TD algorithm on the datasets
Tables 3 and 4 show clustering accuracy of TD and MG algorithms, respectively. With regards to MG algorithm, the bandwidth parameter of batch clustering part is (4, 2); this is a balance point between accuracy and parallelism on the basis of experience [6]. Pursuant to these two tables, we select baboon and usc223.03 as input to validate acceleration performance on TD algorithm. Additionally, we choose baboon and usc2.2.17 to validate acceleration performance of MG algorithm. In other words, we choose images with highest accuracy. Our optimization methods exhibit similar speedup on images of Tables 3 and 4. As a result, we only adopt images with best accuracy to avoid repetition.
Accuracy of MG algorithm on the datasets
Every input image was divided into equal-size data blocks. These blocks were processed consecutively. “Data block size” (the fourth column of Table 5) describes the number of data points within a single data block.
Input data
Table 6 illustrates the optimization effects on TD algorithm.
Optimization methods’ effects on TD algorithm
Optimization methods’ effects on TD algorithm
MG algorithm: Speedup gained by pipeline pattern.
Ten CUDA streams are used. With regards to MG algorithm, Figs 6 and 7 show the speedup achieved by the pipeline pattern and data reordering, respectively.
With regards to TD algorithm, speedup achieved by data prefetching is not eligibly low. By contrast, acceleration obtained through prefetching is eligibly small in terms of MG. We discuss the reasons as follows. During step
As is shown by Table 6 and Fig. 6, MG algorithm achieves much higher speedup through pipelined pattern than TD algorithm. The time complexities of EM and mean-shift algorithms are
Although mean-shift exhibits quadratic complexity in terms of
In the case of this paper, TD algorithm is computation-intensive. In contrast, MG algorithm is much more data-intensive. As a result, MG algorithm obviously benefits from the pipeline pattern (Fig. 6). Nevertheless, the pipeline pattern can exert almost no influence on TD algorithm (Table 6).
Overall speedup of GPGPU-powered MG algorithm: Effects of data reordering.
Incremental image segmentation results.
Table 6 and Fig. 7 demonstrate that both TD and MG algorithms achieve significant speedup by utilizing data reordering. The reasons are explained as follows. First, global memory is the primary storage unit of GPGPU. TD and MG algorithms both necessarily read large amount of data from global memory. Second, both algorithms place most of computation in the batch clustering part. In addition, batch clustering parts of the two algorithms possess high data parallelism (GPGPU-friendly). Third, high data-parallelism is a vital precondition that data reordering can work successfully.
For MG algorithm alone, larger bandwidth means less iterations of mean-shift (uniform kernel is used). Consequently, total time overhead of the algorithm is smaller. Meanwhile, the data transmission time remains unchanged. As a result, larger bandwidth leads to a more data-intensive MG algorithm.
From our previous work [6], we know that larger bandwidth means that higher percentage of MG algorithm’s computation run on GPGPU. Hence speedup obtained by data reordering rises with the increasing bandwidth (Fig. 7).
In the disk-to-host transmission, we copied the whole data block all at once. If the data points of a data block had been copied one by one, the pipeline pattern would have achieve much higher speedup.
Representative incremental segmentation results are shown in Fig. 8.
Figure 9 compares the overall speedup between finely-optimized multithreaded CPU algorithms and GPGPU-powered algorithms. The multithreaded versions are implemented using POSIX thread; they run 12 threads concurrently and are optimized as follows. (1) Compiled using compiler option -xo4; (2) Use t mmap() calls to map files into the address space but rather call read(); (3) reorder data points to enhance data locality; (4) Identify fine-grained locking through performance tuning; (5) Use asynchronous I/O to overlap computing and I/O operations. Our GPGPU-powered methods can obtain significant speedup over the multithread implementation.
Speedup of multithread-CPU and GPGPU-powered algorithm over single-thread implementation.
Our methods exploit multi-level optimizations (especially optimizations relevant to data access/transmission) in a CPU-GPGPU hybrid system to accelerate the incremental clustering algorithm. First, warp level: The basic idea of TD and MG algorithms require that most computation of an incremental clustering algorithm should possess high data parallelism. As a result, enormous threads can execute simultaneously to overlap computing operation and read/write operations. Second, shared-memory level: Prefetching data into shared memory can reduce data access latency if the data are repeatedly accessed. The precondition that this optimization can work successfully is strong data locality. Third, global-memory level: Memory coalescing through data reordering is a wide-applicable method to optimize global memory access. In addition, coalescing tends to achieve higher speedup if data parallelism is higher. Fourth, data I/O level: CUDA streams can overlap disk-to-host transmission, host-to-device transmission and kernel execution. Larger proportion of data transmission time means higher speedup achieved by CUDA streams.
Our future work will focus on data transmission and access optimization for GPGPU-powered clusters.
Footnotes
Acknowledgments
This work was financially supported by the following research funds: