
Abstract
The purpose of this study is to analyze the application of cloud computing in power security monitoring. In this study, firstly, cloud computing technology, open source Hadoop platform and HDFS distributed file system are introduced. Secondly, based on the Gap Statistic Algorithm (GSA) for adverse data identification in power system, an optimization scheme of GSA based on cloud computing is designed. Finally, the implementation process based on cloud computing, map process and reduce process of GSA algorithm are introduced. The results show that the application of cloud computing to power system can improve the existing power grid data computing and storage capacity, and improve the status quo of state estimation of power system. Therefore, it is of practical engineering significance to study the adverse data identification algorithm of power system based on cloud computing, which conforms to the development demand of power system informatization.
Introduction
Power equipment in operation is divided into normal state, abnormal state and failure state [1]. State monitoring of power equipment refers to the use of sensor technology and computer technology to monitor the running state of equipment in real time. It judges the state of the equipment through the collection of operating state parameters of the equipment and timely diagnose and maintain the equipment before the abnormal state or failure occurs, so as to ensure the safe and stable operation of the power grid [2]. State monitoring of power equipment is mainly divided into online monitoring and offline monitoring [3, 4]. Online monitoring is a technology that uses monitoring equipment to record the running state of the equipment in real time. The online data collected have obvious dynamic time sequence characteristics, mainly including pulsed quantities such as temperature, voltage, and current [5, 6]. Offline monitoring is an important supplement to online monitoring. Offline data are stored in the database of power company in a static way and remain unchanged in the process of equipment status monitoring, mainly including configuration data during substation installation, specific information of equipment, fault diagnosis and maintenance records of equipment, etc. [7, 8].
Cloud computing is a technology based on Internet technology that virtualizes resources to provide dynamically scalable storage and computing services. It is the result of the fusion development of virtualization technology, cluster technology, distributed computing and parallel computing [9, 10, 11]. Cloud computing virtualizes distributed computing resources and storage resources, and provides users with super-large data processing and storage services through unified management and scheduling [12, 13]. Cloud computing is the development and extension of distributed computing, parallel computing and grid computing, and its rapid development provides new solutions for data sharing and processing in power system [14, 15]. The introduction of cloud computing technology into the power system can fully integrate the data resources and computing resources distributed in different places in the system under the condition of unchanged infrastructure, so that they can work together and greatly improve the data analysis ability of power grid, which has important research value for information integration in the smart power grid environment.
Methodology
Cloud computing technology
Cloud computing is an emerging business computing model. It distributes the computing tasks on the resource pool composed of a large number of computers, so that various application systems can obtain computing power, storage space and various software services as required. Because the uncertainty of its computing position is similar to the motion of electrons, this resource pool is called “cloud”. Cloud computing centralizes all computing resources to achieve automatic management, and its operation details are shielded from users. This enables application providers to focus more on their own business, which is conducive to innovation and cost reduction. Cloud computing can be roughly divided into three types of services: infrastructure as a service (laaS), platform as a service (PaaS) and software as a service (SaaS), as shown in Fig. 1.
Service type of cloud computing.
Hadoop is a distributed computing platform developed by Apache foundation based on Google cloud computing platform. It is a distributed system focusing on the storage and processing of massive data. The Hadoop framework is shown in Fig. 2, and its core design is MapReduce and Hadoop Distributed File System (HDFS). HDFS provides the underlying support for distributed computing and storage.
Technical architecture of Hadoop.
HDFS is an open source implementation of the Google file system (GFS), a file system that reliably stores large data sets on large clusters. At the same time, the HDFS system is very fault tolerant and can be deployed on cheap machines to realize large-scale data set applications, which can provide high throughput data access, reduce maintenance costs and improve data fault tolerance ability. HDFS adopts a master/slave architecture. The three main components of HDFS are: NameNode, DataNode, and Client.
An HDFS file system consists of a Namenode and multiple Datanodes. The Namenode is a scheduling hub that manages the namespace of the file system, cluster configuration information, replication of storage blocks, and client access to files. HDFS essentially divides a file into one or more data blocks that are stored on a set of datanodes. The Namenode performs the operations of opening, closing, and renaming a file or directory of the file system’s namespace. The Namenode is also responsible for determining the mapping of a data block to a specific Datanode node.
The Datanode is responsible for handling read and write requests from file system clients. It creates, deletes, and copies data blocks under the unified scheduling of the Namenode. Client is an application that obtains files on HDFS. HDFS is developed in the Java language, so any Java-enabled machine can deploy Namenode or Datanode. Its Namenode and Datanode are designed as nodes that can run on normal commercial machines. And a single Namenode structure simplifies the system architecture.
Results and discussion
GSA optimization scheme based on cloud computing
GSA is an algorithm used to determine the optimal number
Cloud computing implementation idea of GSA.
Referring to Fig. 1, the parallel feature of the maximum and minimum distance method is utilized to design and optimize the cloud-based GSA scheme as follows.
Firstly, the data to be detected is divided once, the data block is represented as {split
Secondly, the GSA algorithm is executed on the i compute nodes in accordance with the
Thirdly, when the compute node executes the GSA algorithm to select the initial cluster center: the first cluster center Z is randomly selected and stored; the data is divided into blocks for the second time, expressed as {split
Flow chart of the map function.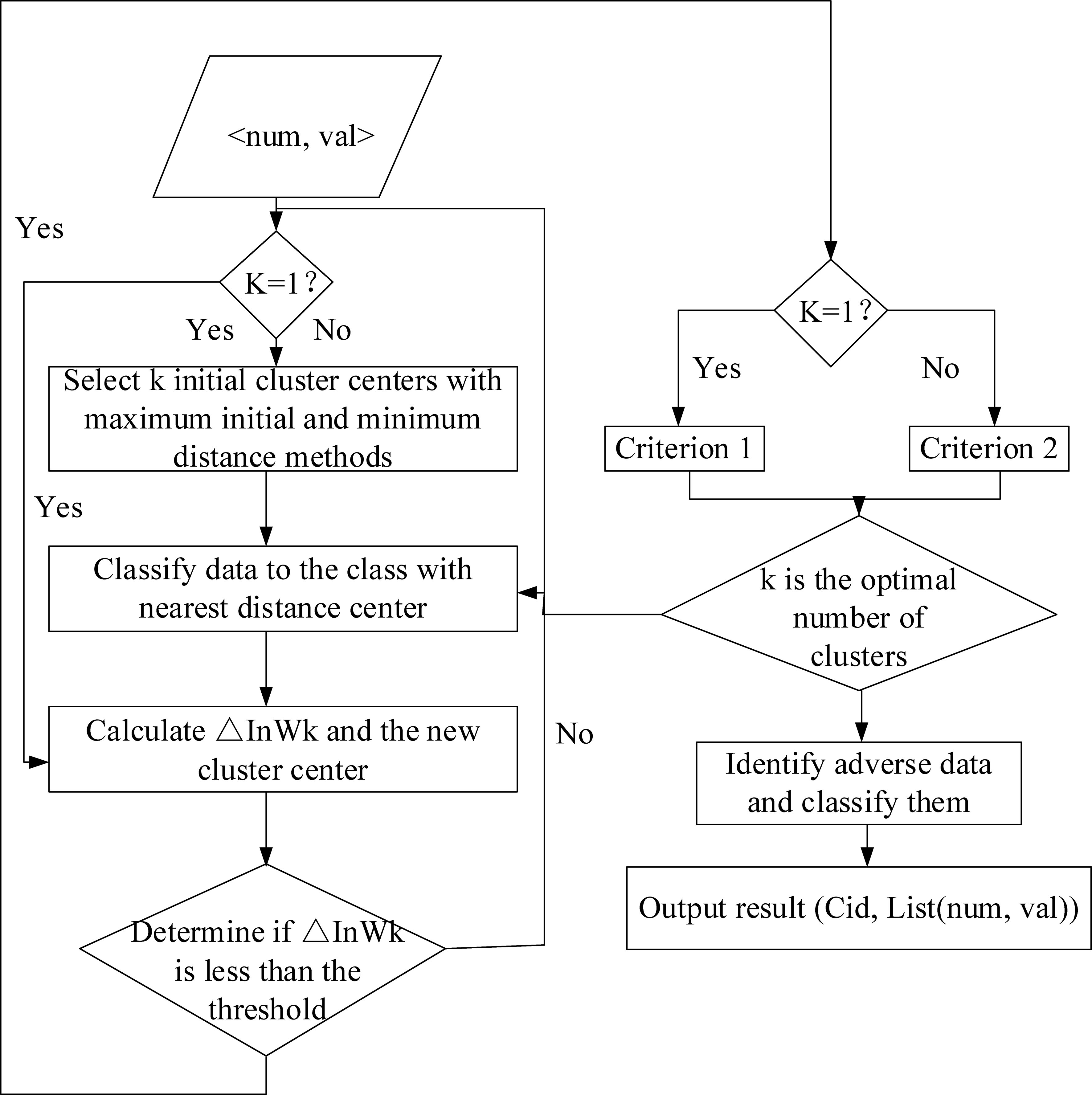
Flow chart of the Reduce function.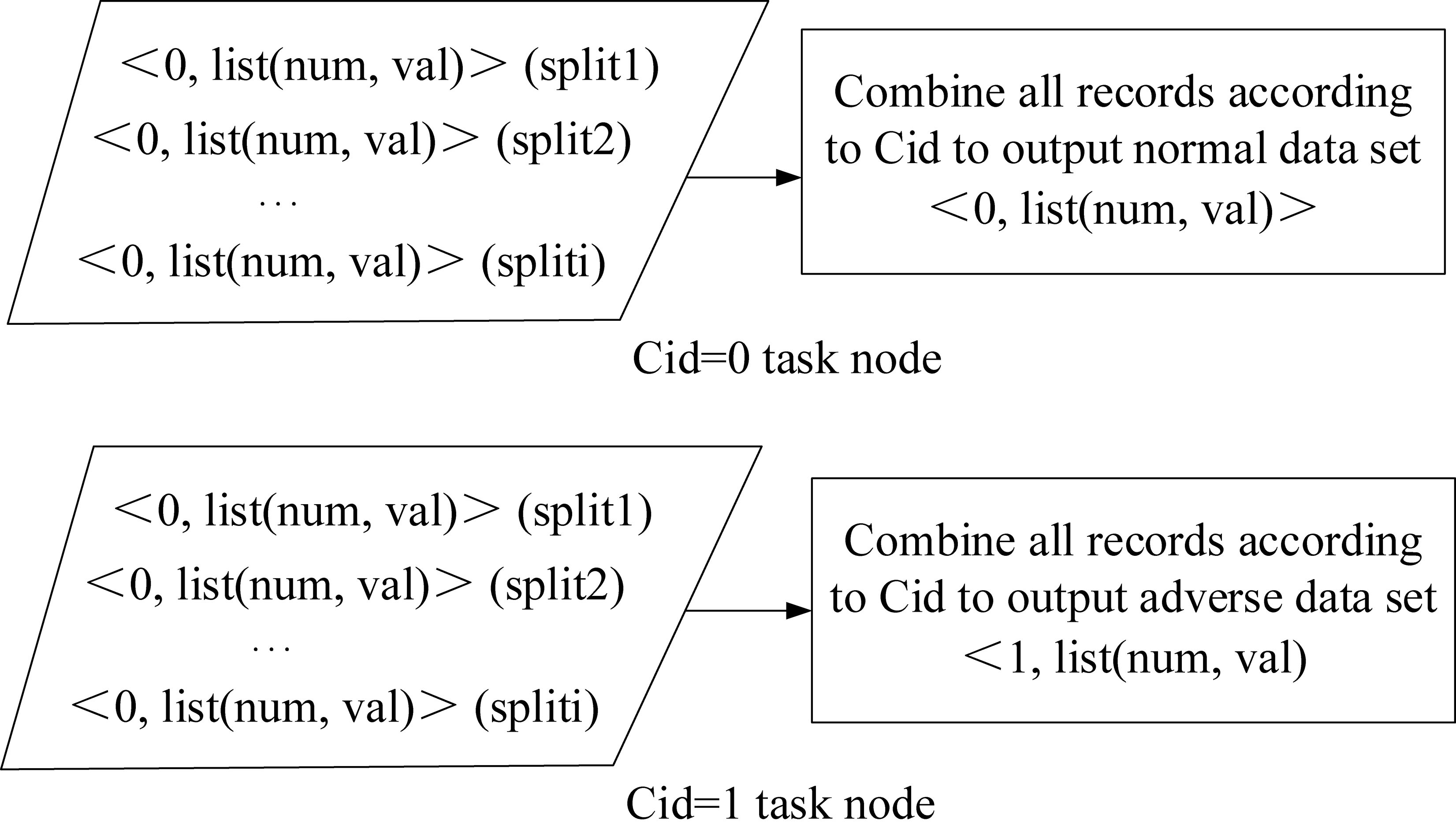
Firstly, divide the data. For a one-dimensional data set, the data file is split into multiple splits blocks, and then each splits block is split into key-value pairs
Secondly, a compute node is assigned to each split, and a Map function is executed on the corresponding node. The Map function inputs a key-value pair
Thirdly, the Reduce function is executed, and the result set of the Map process is combined by the k2 value and the result is output.
Map process
The Map process is the main part of the implementation of the GSA cloud computing model. The role of this part is to apply the GSA algorithm to the data set
Reduce process
When executing the Reduce process, the nodes assigned to perform the Reduce task are processed according to the record of the same key value from the Map result. The default HashPartitioner class in the MapReduce framework can be used to send key-value pairs of the same key (Cid) value to the corresponding Reduce node for processing. The Reduce task flow of GSA cloud computing model is as shown in Fig. 5.
Conclusion
In view of the similarity between cloud computing and power system in operation mechanism, cloud computing can be applied to the security monitoring of power system to improve the power grid’s information processing and data storage capacity. In this research, based on the Hadoop cloud computing platform and the MapReduce software framework, the implementation process of the existing cloud computing technology and the open source Hadoop platform computing model are studied. Combined with the adverse identification algorithm of GSA power system, a cloud computing method for adverse data identification in power system is propose. In this method, in order to avoid the influence of random selection of reference distribution and initial clustering value on the accuracy of GSA algorithm, the maximum and minimum distance methods are used to optimize the GSA algorithm. The research results provide a basis for the practical application of cloud computing in power system and also prove the feasibility of the application of cloud computing technology in power system. However, this study has not completely solved the dependence of GSA algorithm on the reference distribution, and it still needs to be calculated when judging whether there is adverse data. On the research of the new GSA algorithm, there is no real large database environment to verify its performance in the environment of large data sets. Therefore, in future studies, the dependence of GSA algorithm on the reference distribution should be analyzed, and the performance of the optimized GSA algorithm in the big data set environment should be verified.