
Abstract
In order to meet the real-time and robustness requirement of driverless cars driving on highway, this paper proposed a lane line identification method based on the Deep Learning. This method first built a lane line image library and then input the pictures of the lane line image for denoising and normalized processing. Secondly, the Lenet – 5 network model was used for classification and recognition, with a recognition rate of 99.4%, and the lane line type was displayed through GUI interface. Finally, this method was compared with the support vector machine and BP neural network, and the results effectively verified that the method can satisfy the requirement of real-time and accuracy of lane line identification.
Introduction
With the continuous development of image processing technology, many research schools have applied this technology to environmental awareness and achieved good result in lane line identification, an important technology in unmanned driving. This technology not only requires lane line image with recognition rate, but also strictly demands for real-time and robustness.
The research of lane line recognition mainly adopts the following methods: the Support Vector Machine (SVM) [1] method mainly uses prior knowledge and artificial designed machine model [2], which can identify whether a model design could affect the final recognition results or not, but it could not ensure the recognition rate; The BP neural network [3] method has a good self-learning ability, but the design model requires the manually designed weight, threshold value and the number of iterations, which can easily lead to the fitting; for the detection method of hough transform, [4] in case of a road with seriously damaged or blurred lane lines, the recognition rate will be low and the robustness is not good enough to meet the visual technology.
In this paper, Deep Learning is applied to the classification and identification of lane lines, and the feature extraction and recognition of lane lines is made by constructing a seven-layer network model. Meanwhile, the image preprocessing of binarization and denoising is added in the experiment, and the collected images are made into training sets and test sets. By comparing different methods, it is effective to verify that this method has a good recognition effect.
The research methods
SVM (support vector machine)
Support vector machine (SVM) is a general machine learning method which is trainable and based on the principle of structural risk minimization. The principle of SVM method is the process of linearization and dimensionality. SVM is developed from the optimal classification hyperplane in the case of linear separability. As shown in the Fig. 1, hollow points and solid points represent two types of samples respectively. H is the h-dimensional classification hyperplane, HI and H2 are hyperplanes that are over various points and closest to the classification hyperplane for example and parallel to H. The optimal classification hyperplane theory requires the classification hyperplane to maximize the classification interval on the basis of correctly separating the two types.
SVM schematic.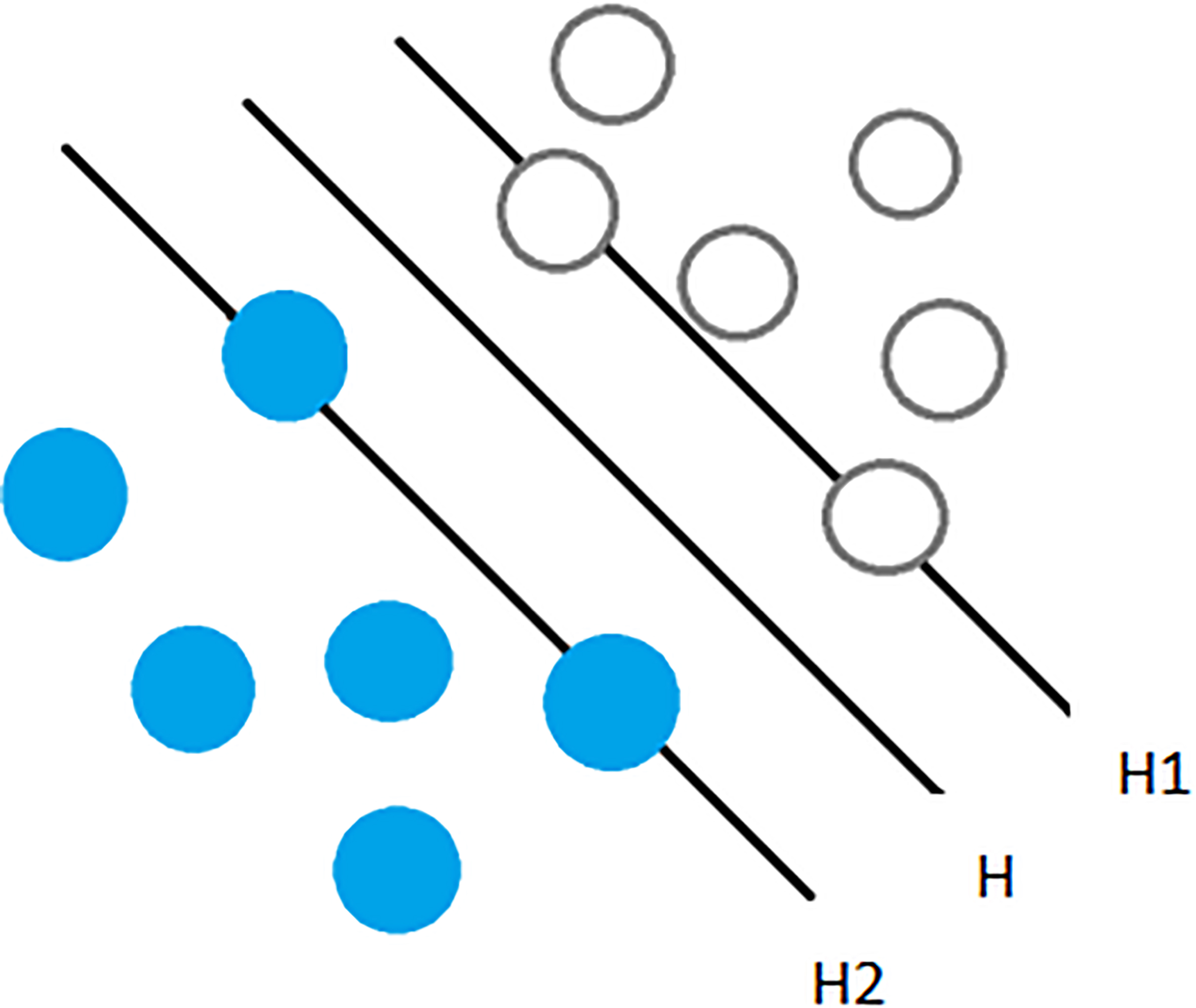
Obviously, the SVM has a better classification, but it’s harder to train for large-scale data training. Therefore, SVM is not adopted as the research method in this paper.
The basic principle of BP learning algorithm is gradient descent method. By adjusting the power values, the network is minimized. At the time of the signal propagation phase, the input is processed through the input layer, the sublayer is processed, the output is processed through the layer, and finally the output is processed. In the phase of error back propagation, the output signal value of the output layer is compared with the expected output signal value to obtain the error. If the error is large, the error signal will be sent back to the hidden layer until the input layer. In each layer of neurons, the error signal is used to modify the weight coefficient, and then the next iteration is conducted. The Fig. 2 shows a simple BP neural network model.
BP neural network model.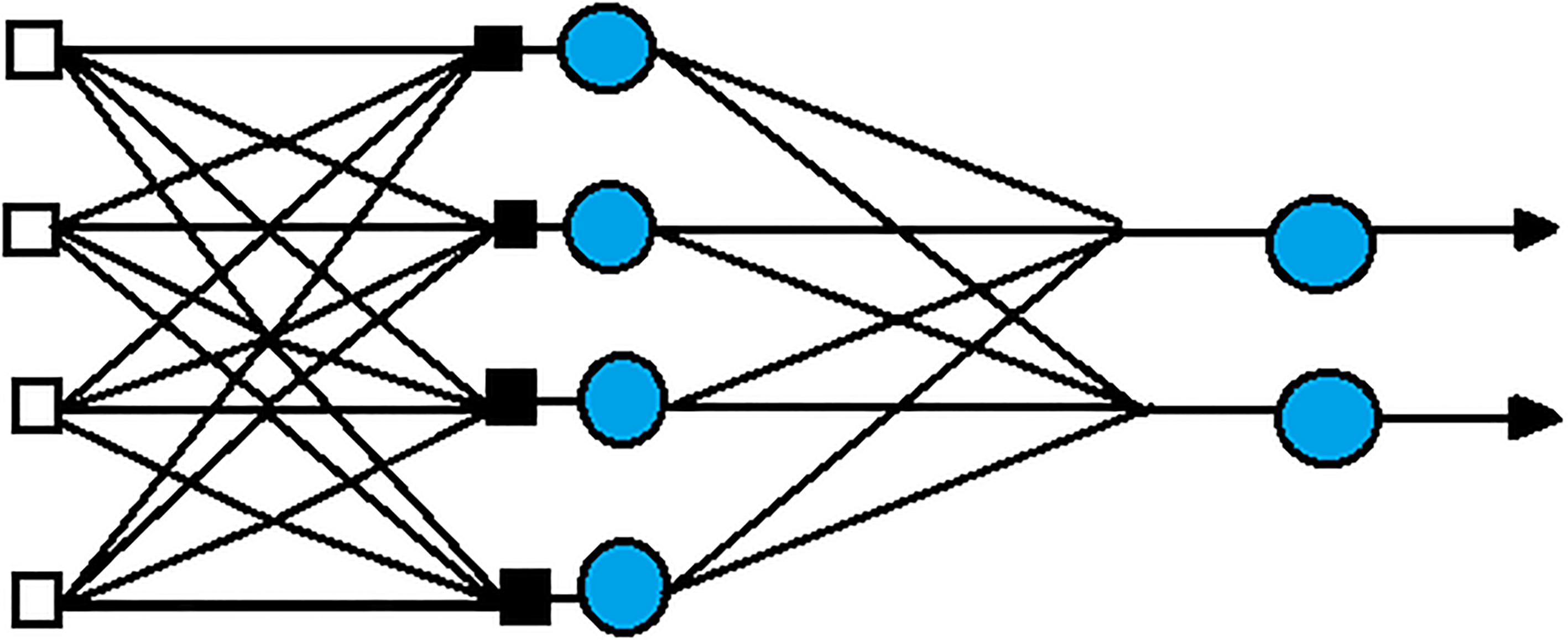
According to the above principle, BP neural network has a better fault tolerance. However, the complex processing results in a slow operation speed, so this paper does not use BP neural network as recognition method.
In 2006, the field of artificial intelligence, Hinton published an article about Deep Learning in science [5], which caused a new wave of Deep Learning in all walks of life. Deep learning [6] is designed to imitate the visual perception of human brain. By taking the convolution layer and the lower sampling layer, the image can be extracted and transformed layer by layer, so that the characteristics can be studied more effectively. At present, Deep Learning has been applied in many fields, such as handwriting recognition [7], license plate character recognition [8], traffic sign recognition [9], face recognition [10] and so on. In this paper, lane line identification is based on deep learning framework. The recognition under classification is different from general models, such as convolutional neural network (CNN) [11], which is the deep learning under a model framework. The network structure of the design is shown in Fig. 3.
Convolutional neural network structure.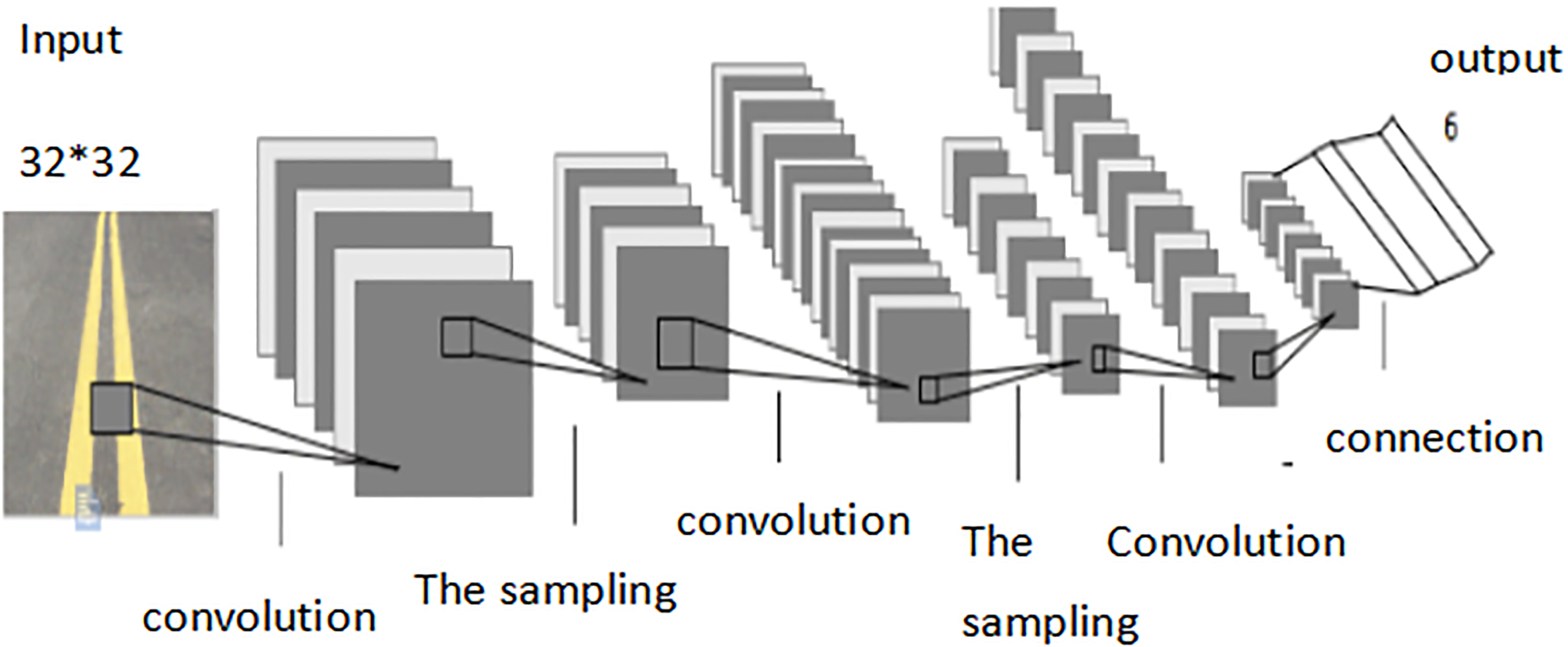
Before the feature extraction of the image, it is necessary to preprocess the image, so the image input to the network is generally 32*32 pixels. Considering the number and parameters of the network structure layer, the image input into the network should be small as possible, so that the real time can be improved. The network structure is shown in Table 1.
A seven-layer convolution neural network layers
A seven-layer convolution neural network layers
In the process of acquiring lane line images, there are many factors that may lead to interference, such as vehicle, shade, long-term wear of lane line and so on. In order to make the image characteristics better, so you need to do image preprocessing. The image preprocessing in this paper is to expand the sample size, mainly including image binarization, image denoising and others.
The characteristics of the convolutional neural network
The three characteristics of the convolution neural network are: local sensing field [12], descending sampling and weight sharing [13], which enables the network model invariable to translate, scale and deform in other forms. The local perception field is to reduce the number of training parameters, shorten the time and meet the real-time requirement. Weight sharing is designed to reduce the number of parameters per layer and network complexity. The convolutional neural network not only has the self-learning ability of traditional machine learning, but also has the advantages of automatic feature extraction [14].
The operation of the convolutional neural network
Forward propagation
In the forward propagation process of the convolutional neural network, the collected images are taken by the convolution layer. The characteristics of convolution layer is extracted and transferred to the pooling layer. Then the whole connection layer is processed, and the output layer is finally classified and recognized.
In the convolution process, the convolution layer is the two-dimensional convolution of the input image of the input layer or previous pooling layer and the non-linear excitation function, which can be expressed in Eq. (1):
In the formula:
In the formula:
The pooling layer is the sampling of the convolution layer output. The characteristics of the output after the pooling will be reduced by k, and the Eq. (3) can be expressed as:
In the formula:
The reverse propagation of the convolution neural network is the process of weight and threshold correction in the model, and the propagation error is minimized. Therefore, the activation function chosen is expressed as follows.
Using gradient descent method, the weight and threshold of the hidden layer and the output layer are adjusted. The adjustment is as follows:
Changes to the weight and threshold of the input and hidden layers are as follows:
In the convolution neural network model, the convolution layer is trained by extracting the characteristics of the input layer. When the image size is large, the network training time will be very long. In order to maintain the real time, the convolutional neural network will connect a lower sampling layer after the convolution layer. The basic principle of the bottom sampling is that the image has a relatively static property, and the statistical property of the image in one region is similar to that of the adjacent region [15]. In addition to reducing the occurrence of the fitting, it can also reduce the operation time.
Experiment and analysis
Sample selection and pretreatment
The six types of lane lines that are common in China are selected as subjects: double yellow solid line, single yellow solid line, single white solid line, single white dotted line, single yellow dashed line and cross road crossing line. Training samples and test samples of lane line are selected from the shot images. Then, the samples receive denoising, binarization processing and other image pre-processings, to obtain more samples and make their network to adapt to severe environment. As shown in Fig. 4, after image preprocessing, such as binarization, noise processing and acquisition of the original image. In the process of filming, both the used camera and lane lines have relative velocity, and the shades of the trees and other factors may bring interference, so the obatined images may be not so clear, with much reflection. However, the designed network can adapt to various bad environment.
Part of lane line samples.
The collected lane line images were made into training set and test set. Before inputting the pictures in the model, they have to be pre-processed first, such as binarization and denoising. After that, the images were normalized to 32*32 pixels and input in the CNN network. In total, there are 548 training samples and 230 test samples.
Image binarization is to set the image pixel to 0 to 255, and at the same time reduce image data quantity. This highlights the image edge, thus improving the image detection and the real-time and accuracy of image recognition.
Contrast of image binarization effect.
After image preprocessing, there will be some noise, which may degrade image quality and affect image detection and image recognition. Denoising can not only provide better image but also better support for recognition system.
Contrast of image denoising effect.
Image normalization is a uniform format image obtained after image processing. This is to ensure that the processed images do not affect the experimental results.
The main interface display
The following figures show the interface of lane identification, which is based on the GUI interface compiled by the tensorflow. It is mainly a recognition of the test sample and identified by inputting images under different conditions. This is shown in Figs 7 and 8.
Double yellow lane line identification.
Crosswalk identification.
Some existing lane line location methods are used to classify the training samples and test samples, and convolution neural network is utilized to test the test samples. Totally, 230 test samples are classified into 6 types.
After the analysis of the experimental results, a total of 6 types of input networks were put into the lane line. After network classification, the detection accuracy reached to 99.4% and the experimental results were very significant.
In order to validate the advantage of the network, BP neural network and SVM were compared. The classification method used in this paper has a high accuracy, can adapt to the scenes under weak light, high salt and pepper noise and gaussian noise as well as with fuzzy lane line.
Compared with the traditional support vector machine and BP neural network, the recognition rate of the convolution neural network method is significantly higher. The comparison results are shown in Table 2.
Comparison of recognition rates
Comparison of recognition rates
The learning rate is 0.001, the number of iterations is 50, and the error rate and the recognition rate are shown in Fig. 9. The error rate and the recognition rate at the step 40 to 50 are basically stable, and the final recognition rate is 99.4%.
Recognition rate and error rate.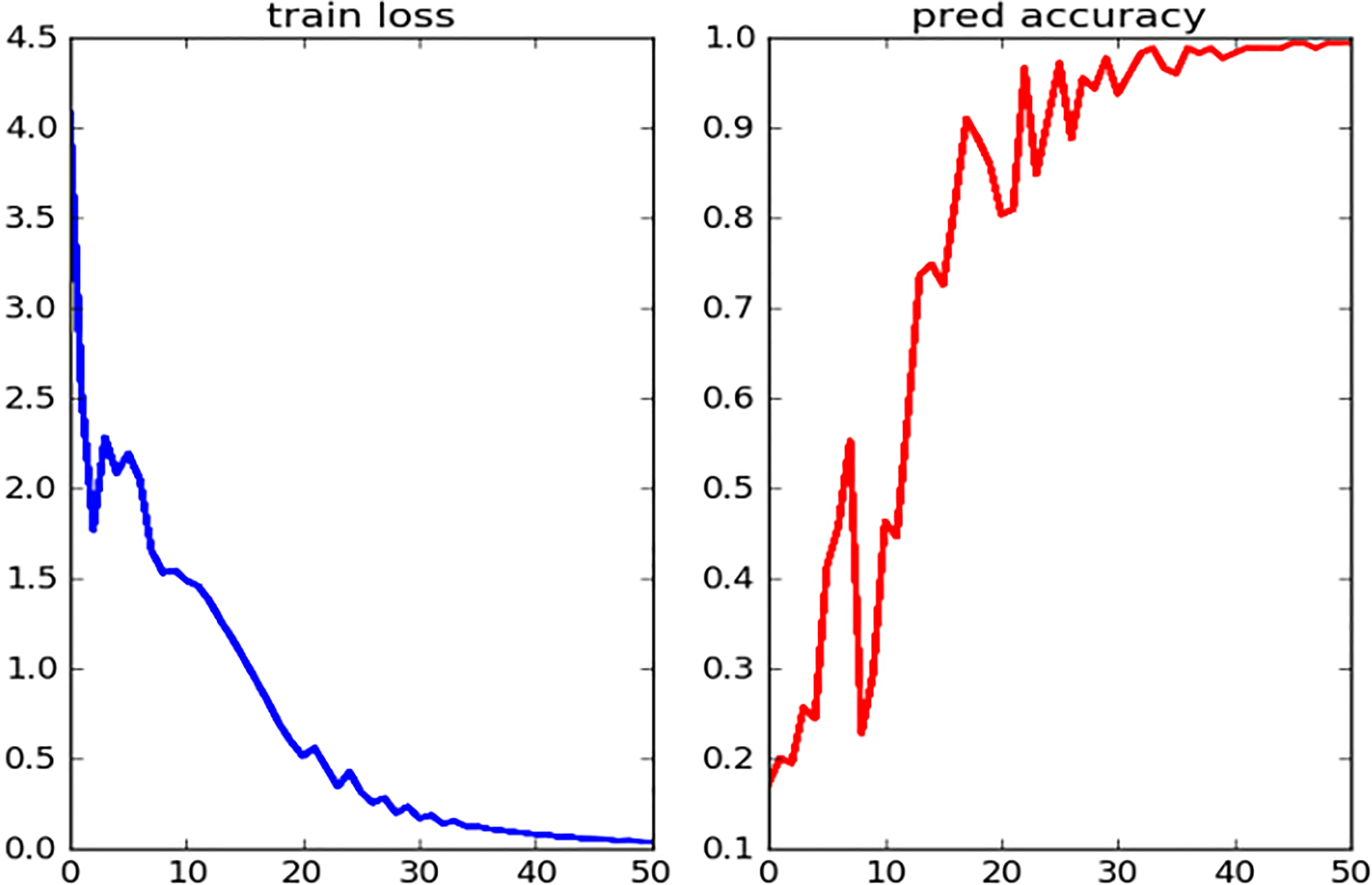
A seven-layer convolutional neural network was used to classify the lane lines using images provided by training samples. The experimental results show that, for the scenes with low light intensity, high pretzel noise and high gaussian noise, fuzzy lane line scene can be well adapted. The network structure has a recognition rate of 99.4% and can be tested in different scenarios. Compared with traditional methods, deep learning has higher recognition rate and so is of great significance in research. However, this method could not well recognize lane lines shot at night, which will be the main research content in the next step.
Footnotes
Acknowledgments
The authors acknowledge the National Key R&D Program of China (2018YFC0808203), Supported by Foundation of Shaanxi Key Laboratory of Integrated and Intelligent Navigation (SKLIIN-20180101).