
Abstract
Focused crawlers, as fundamental components of vertical search engines, focus on crawling the web pages related to a specific topic. Existing focused crawlers commonly suffer from the problems of low efficiency of crawling pages and subject migration. In this paper, we propose a learning-based focused crawler using a URL knowledge base. To improve the accuracy of similarity, the similarity of the topic is measured with the parent page content, anchor information, and URL content. The URL content is also learned and updated iteratively and continuously. Within the crawler, we implement a crawling mechanism based on a combination of content analysis and simple link analysis crawler strategy, which decreases computational complexity and avoids the locality problem of crawling. Experimental results show that our proposed algorithm achieves a better precision than traditional methods including the shark-search and best-first search algorithms, and avoids the local optimum problem of crawling.
Introduction
With the rapid growth of data volume on the Internet, numerous people retrieve information using search engines such as Google and Baidu. Although those search engines can provide comprehensive search results, general search engines also have low recall when the required results belong to a specific topic, resulting in query quality degradation, which is often expressed as many irrelevant results and omission of some relevant results. To address these problems, many researchers propose to build vertical search engines that focus on the web pages related to a specific topic. Designing an effective focused crawler is a significant and challenging issue in implementing vertical search engines. The goal of the focused crawler is to fetch as many relevant web pages as possible and discard irrelevant web pages. To implement an effective and efficient focused crawler, several problems should be solved [1], including defining the topic being focused on, judging whether a web page is related to the topic, determining the order of scheduling web crawl, etc.
Several crawling strategies for focused crawlers have been proposed in the literature. These crawling strategies can be divided into three categories: Text-Based Crawling Strategies (TBCS for short) [2, 3, 4] that utilize the text content guiding the crawl trajectory; Link-Based rawling Strategies (LBCS for short) [5, 6, 7] that achieve a comprehensive description of web link information and reflect the entire web; and classification-based crawling strategies (CBCS) [8, 9, 10] that obtain topic web pages by classifying the web pages. TBCS crawlers achieves good performance in finding the pages relevant to a specific subject, but it is apt to fall into a local optimum. LBCS achieves better guidance than generic crawlers, but it is prone to “topic drift.” CBCS has difficulty in reflecting the overall structure of the web, and the prevalence of high computational complexity. Some focused crawlers are built based on a combination of CBCS and LBCS, but computation cost is high.
To address these problems, we designed a focused crawler named UCrawler, which is constructed based on URL information learning combined with content and link analyses. In UCrawler, potential information in the text and URL is mined to avoid locality problem, using the methods of web content analysis and link analysis. More specifically, the first step is to calculate the similarity between the target URL and the parent page content, and then obtain the information owned by the URL string using a machine learning method, to improve the accuracy of URL relevance computation. We also propose a novel crawling strategy that combines text-based content analysis and simple link analysis to avoid crawlers operating only in a local optimum and reduce the high computational complexity.
The rest of this paper is organized as follows. We discuss the related work on focused crawling in Section 2. Section 3 introduces the design of UCrawler. Section 4 describes the relevance calculation model. Details of the URL knowledge construction, URL learning, and URL knowledge update of UCrawler are presented in Section 5. Section 6 describes the crawling strategy. We evaluate our proposed focused crawler and compare it with two classic focused crawlers in Section 7. We conclude this paper and introduce our future work in Section 8.
Related works
A crawler is a program that downloads a portion of the web via a breadth-first search. Starting from seed URLs, a crawler will systematically download all links branching outward, and then the links branching from those web pages. The focused crawler of a special-purpose search engine aims to selectively seek out pages that are relevant to a pre-defined set of topics, rather than to exploit all regions of the web. A focused crawler is developed to collect relevant web pages of interesting topics from the Internet. Further, crawlers retrieve pages at rapid speed to keep the search engine indices up-to date.
Focused crawler architecture.
Figure 1 depicts the architecture of a focused crawler. The user only wants relevant results, so a focused crawler is required to maximize relevancy. This is accomplished by the use of a priority queue and a relevance classifier. This classifier is attuned to the interests of the user and is applied to each web page, only those with a high relevancy score are crawled. There are various vector space models used to determine relevancy as well as self-learning statistical models.
TBCS methods use web content, anchor text, context, and other information to select a direction to traverse the Internet. The procedure in TBCS can be described as follows. The crawler starts with a set of seed page URLs, which guide the search for pages of interest. They follow the criteria for assigning higher download priorities to links based on their likelihood of leading to pages on the topic of queries. Pages pointed to by links with higher priorities are downloaded first. The crawler proceeds to recursively fetch the links contained in the downloaded pages. Typically, download priorities are measured based on the similarity between the topic and the anchor text of a page link, or between the topic and text of the page containing the link. Text similarity is computed by similarity measurements such as the Boolean model or the Vector Space Model (VSM). The emphasis algorithms of the strategy include the fish-search algorithm, the shark-search algorithm, and the best-first search algorithm.
Fish-search algorithm dynamically maintains a list of non-crawled URLs in the order of priority of being gathered and downloads the web pages according to the URL queue. In this procedure, URLs in the relevant web pages are assigned with higher priorities than the others in the irrelevant web pages. The procedure for the fish-search crawler model is straightforward. Dynamic crawling and crawling as a guided strategy have some effects. Meanwhile, several shortcomings are identified, such as using string matching to judge whether a web page is related to a subject; this approach has limited judgement accuracy.
Shark-search algorithm improves on the fish-search algorithm by considering the effects of the characters in the hyperlinks when the priority of URLs is being calculated in this algorithm. At the same time, the VSM is utilized to calculate the similarity of web pages. The shark-search algorithm has the advantage of a good theoretical basis, and its relevance computation is simple. The algorithm shows good performance at a distance closer to the relevant page. However, because the text information lacks global semantics, the overall situation of the web is difficult to reflect. The crawler always downloads pages with high relevance scores, and discards other pages with low relevance scores. Qiu et al [23] proposed an improved version of shark-search algorithm, which evaluates the value of URLs by combining anchor text, the adjacent text of anchor text and the value of authority web. This method increases the speed of the topic crawler even with the increasing of number of crawled pages.
The best-first search estimates page-to-topic relevance as document similarity. Computing the similarity measured by traditional information retrieval models (e.g., using VSM as best-first crawlers do) is based on lexical term matching, that is, two documents are similar if they share common terms. However, the lack of common terms in two documents does not necessarily mean that the documents are unrelated. Despite its simplicity and rich theoretical foundation, good performance is difficult to achieve in environments where diverse topics exist. TBCS failed to take into account the information owned by hyperlinks, which contribute to the performance improvements generated by the focused crawler crawling strategy.
LBCS methods achieve a comprehensive description of the web link information and can reflect the entire web. Traditional examples of these algorithms include PageRank [5] and HITS [6] algorithms. Zong et al. [7] suggested improvements for the HITS algorithm. PageRank crawler can reflect link relationships among pages, and does not consider the relationship between the web pages and specific topics. Consequently, PageRank crawlers are apt to lose their directions to a specific topic, and thereby miss more topic-specific pages. An improved version of HITS [7] introduces a center website (Hub) and an authority website (Authority) through the Hub web pages and Authority web pages to reflect the overall situation of the web link. All these algorithms achieve high effectiveness for general crawlers. They are suitable for finding high-authority web pages rather than topic-specific pages. In addition, the calculation complexity is relatively higher and the update latency is larger, which seriously affects crawler crawling. Cai [24] combined fish-search and PageRank algorithm to calculate the relevance between the web content and the topic. Liu and Li [25] introduced HITS algorithm, and integrated the page content and web links to improve the topic relevance and authority.
Chakrabarti et al. [8] proposed CBCS for comprehensive crawler systems. Their research goals concentrate on the relations between web links and semi-supervised learning. In these systems, the focused crawler uses standard topic classification, and on the view of a user-specified starting point, labels web pages that are of interest to the user and classifies web pages according to user interests. Wang et al. [9] proposed a focused crawler based on the Bayesian classifier, using the naive Bayes classifier to calculate topic relevance. This classification-based focused crawler can deeply determine user interests. However, it cannot reflect the overall structure of the web, because its computational complexity is higher and the threshold is hard to determine.
Yuki et al. [11], Chen and Zhang [12], and Luo et al. [13] proposed a combination of content and link strategies. References [11, 12] combine a web content analysis and PageRank algorithm, and [13] is a combination of the shark-search and HITS algorithms. Although these algorithms improve the precision rate, the implementation is complex and the computation cost is high.
Zheng et al. [14] proposed a learnable semantic-focused crawling framework based on ontology. An artificial neural network (ANN) was constructed using a domain-specific ontology and applied to the classification of web pages. Batsakis et al. [15] used multiple sets of experimental verification: semantic crawlers based on the ontology did not improve performance over text-based crawling, with better results obtained when semantic relations were restricted to synonymous terms. However, expecting that their performance can be improved is plausible using application-speci?c ontologies, instead of general purpose ontologies such as the WordNet [16]. Therefore, this group of crawlers is unsuitable for guiding most focused crawlers.
Hsieh et al [21] introduced an extensible crawler, a utility service that crawls the Web on behalf of its many client applications. The extensible crawler lets clients specify filters that are evaluated over each crawled Web page. The act of crawling the Web is decoupled from the application-specific logic of determining if a page is of interest, shielding Web-crawler applications from the burden of crawling the Web themselves.
Ahlers [22] developed a focused crawler with an adaptive geospatial focused on efficiently retrieves and identifies location-relevant documents on the Web. Based on geospatial features of both Web pages and the link graph, the crawler prioritizes promising links and pages, leading to high-efficiency access of the desired geospatial topic.
Jiang et al [26] described the design and implementation of a university focused crawler that runs on BP network classifier for prediction of the links leading to relevant pages. These work in [21, 22, 26] are orthogonal to our research and can be easily combined with UCrawler.
To Address the disadvantages of various existing focused crawlers, we present a focused crawler based on the URL knowledge base combined with content and link analyses. To guide the URL to calculate URL relevance, URL knowledge is updated iteratively by URL learning. Extensive experiments demonstrate that our proposed crawler can achieve good performance.
In a focused crawler system, we mainly focus on the design of three modules: a feature vector extraction module, a relevance calculation module, and a web scheduling crawl module. The feature vector extraction module is used to extract the characteristics of the topic and expressed them as a weighted vector. The relevance calculation module calculates the relevance between the web page and the topic. The web scheduling crawl module prioritizes pages according to the scheduling strategy. High-priority pages are crawled preferentially, thus ensuring the high quality of the page that has the highest relevance to the topic and that can be crawled in a short time, as well as the ability of the crawler to better extend to the entire web.
Design goals
UCrawler architecture has been guided by several principles and system goals:
High efficiency. The primary goal of a focused crawler is to reduce the number of irrelevant Web pages, while preserving pages that users interest. To minimize the cost of page crawling, the crawler is required to pre-evaluate the relevancy of a page before the page is download. For guiding the crawling process, a topic filter with topic-specific knowledge base, is used to make sure all crawled pages are limited to a given topic. High coverage. Relevant pages for a given topic are always distributed in a large number of websites. Focused crawler should starts from a small set of seed sites, and finding the relevant sites as many as possible. Achieving a high recall is one of key challenges for focused crawlers. High Adaptivity. Topic locality is a traditional problem for focused crawler. New terms or topics rise all over the time. Recognition of new terms put forward a significant challenge to the crawler. UCrawler is constructed based on a URL knowledge base, which is continuously updated. High extensibility. A focused crawler should support various web page analyzer and, relevance calculation model and topic filters. One of our specific goals is to design these components of UCrawler as pluggable parts, and make UCrawler extended to more generable models and topics.
Ucrawler design
The architecture of UCrawler is illustrated in Fig. 2. The UCrawler workflow is executed as follows: (a) The web crawler starts downloading from a given URL seeds that are center web pages and authority web pages of the specific topic. (b) The web page analyzer analyzes the web content and links of the download to eliminate noise information and extract web page content, anchor information, web link information, and some topic-related information. (c) The relevance calculation is conducted based on content, anchor information, and URL information. (d) From the result of the relevance calculation, the topic filter analyzes whether the content of parsed pages is related to the topic or not. (e) URL learning learns information that is relevant to the topic, extracting the topic information. (f) The web crawl scheduler formulates a crawling strategy to prioritize each URL, and then adds them to the priority queue. The web crawler downloads the seeds in the URL after the priority queue has been established.
The process pseudocode of the crawler system to build the URL knowledge base is shown in Table 1.
URL knowledge base learning
URL knowledge base learning
Design of UCrawler.
The topic crawler selectively crawls topic-related web pages, it filters the less relevant pages by calculating the relevance of each page to a particular topic. In this paper, the vector space model (VSM) is used to calculate the correlation between web pages and topics. Therefore, the establishment of topic vectors becomes the primary problem in the calculation of topic relevance.
Establishment of the topic vector
The topic relevance of web pages is largely dependent on the topic vector, which directly determines the crawling effect of a focused crawler. The topic vectors are extracted from hub and authority web pages, formed as a set of representative keywords with corresponding weights.
In the UCrawler, the calculation of web page topic relevance relies on the two vectors: the keywords vector for web content and the keywords vector for anchor, which are denoted as Vc and Vn, respectively. Based on Vc and Vn, the similarity of a crawled page can be measured. The list of initial keywords can be selected by some experts at the beginning, and then the keywords can be evolved with more pages are crawled and analyzed. Meantime, the weights for individual keywords will be iterated and converged, forming the topic vector.
Relevance calculation model
The UCrawler system uses the contents of the parent page, URL anchor information, and the URL string information to determine the relevance between a web page and a topic. Web pages and topics are represented as keyword vectors, and relevance between them is calculated using VSM. The model formula is defined as Eq. (1):
Where
The relevance between a web page and a topic is defined as follows:
where
To find optimal values for alpha, beta and omega, two groups of training data are required. One group contains the relevant urls and pages, the other groups contains the irrelevant urls and pages. At the intial stage, these three parameters are set to 1/3 uniformly. Then the similiarty scores are calculated and used for judging a given URL relevant or not. The parameters are iterately updated for minimizing the error times of url relevance judgement.
In [17], a focused crawler based on URL rule learning is proposed. URL rules related to the topic, represented by regular expressions, are obtained by classifying and clustering. In order to mine more URL rules, a URL knowledge base is built, and updated iteratively by URL learning methods [18, 19, 20].
URL information learning structure.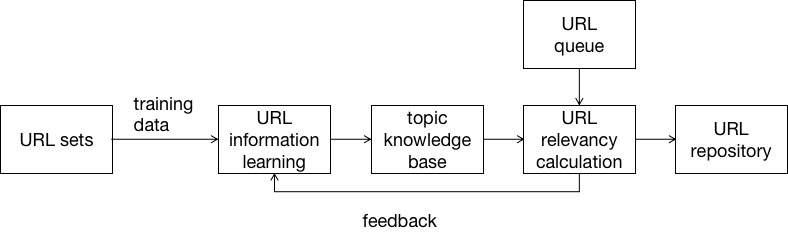
As illustrated in Fig. 3, the basic process of learning URL information is described as follows: First, the URL of a given number of pages is specified to obtain a training data set. Second, a topic knowledge base is acquired by learning the obtained URL information using a selected learning algorithm. Third, the topic knowledge base guides the URL to calculate URL relevance and feedback relevance to guide the learning of URL information. Finally, after learning the URL information, the topic knowledge base is updated for further learning and improving system performance.
In order to build accurate topic keyword vector, weights of keywords are dynamically updated during learning process, and new keywords are also added automatically. The URL learning process is as follows.
Training data
We analyze a large number of different web pages, which contain not only the authority and center web pages that are relevant to the topic, but also some unrelated pages. Training data on these web pages were collected and categorized into two groups of URL types. Based on the training data, two threshould values,
Data processing
The URLs are divided into words. The meaningless stop words such as “a,” “an,” and “is,” are removed. The word that can feed back some information is subsequently extracted.
For example, after splitting and processing the URL “http://sports.sina.com.cn/nba/,” we obtain the words “http,” “sports,” “sina,” “com,” “cn,” and “nba.” We then remove the words “http,” “com,” and “cn,” which do not contain useful information. Finally, we acquire the words “sports,” “sina,” and “nba,” which can feed back some information.
After the above process, we derive three thesauruses, each consists of keywords and corresponding weights. A topic relevant thesaurus is obtained from positive training data, i.e. Sample 1. A topic-irrelevant thesaurus is built from negative training data Sample 2, with all weights initialized to zero. We also build a learning thesaurus, which is used to record the keywords and the weights of the keywords related to the topic that are obtained by machine learning. These three thesauruses form the URL knowledge base, which guides the URL relevance calculation.
URL feedback learning
A set of phrases is obtained after splitting the URL as described in the process above. The weights for these phrases are defined on basis of
If
If
If the phrase contained in topic-irrelevant thesaurus, then it is discarded. If the phrase contained only in topic relevant thesaurus, the weight of the phrase is updated in the topic-relevant thesaurus, as shown below:
If the phrase contained in none of the three thesauruses contain the phrase, including the phrase in the learning thesaurus, the number of occurrences of this phrase is set to 1. The phrase is then added to the topic-relevant thesaurus, and the weight of this phrase is initialized as
If the phrase contained in both the learning thesaurus and the topic-relevant thesaurus, the number of occurrences If
If
The
As a large number of URLs are generated and disappeared, the URL knowledge base needs to be updated. The update policy is described as follows:
The phrase in the topic-relevant thesaurus with weight lower than a threshold is removed, because these phrases may be topic-irrelevant. The phrases in the topic-irrelevant thesaurus are sorted ascending by weight, then first h% phrases are removed, because they may be topic relevant phrases.
With the URL information learning process, new topic-related phrases are found and existing phrases’ weights are updated continuously. Therefore URL relevance calculation become more accurate.
The main gain of web page crawl scheduling policy for a focused crawler is to discover and download more topic-related pages, and to crawl high-quality pages with a high priority.
The web page content evaluation scheduling crawling model mainly uses text information in the page text as an analytical basis and calculates the relevance between the page text or the anchor text and the intended topic to determine whether a link is worthy to be crawled. The URL analysis model mainly considers the unique semi-structured characteristics of the web pages and analyzes the relevance, to which hyperlinks point among the web pages to calculate the relevance between the page and the intended topic.
UCrawler adopts a combination of content analysis and simple link analysis crawling strategy. In the web-crawling process, UCrawler, according to the topic relevance of the web content and the URL link analysis, evaluates the priority of the URL. Using Eq. (2) in Section 4.3, URL relevance is calculated as a measure of the web crawl, and then a simple analysis of the number of topic page outputs and the number of new topic web page links found on the web page is performed. The detailed process of the UCrawler web crawl strategy is as follows:
First, we calculate the relevance between the URL and the topic and obtain the relevance value A queue named list is created, and all the distinct hosts visited by the crawler are recorded. When the number of topic-related pages pointed by this page is greater than a given threshold, a bonus score When the host of current page isn’t contained in list, a bonus score When the topic web page has a different host than its parent web page, a bonus score rom the above steps (1)–(5), we obtain the final score of a URL as:
According to the URL’s final score, a priority queue is generated, and determine the web page crawling order.
The crawling strategy proposed above is a combination of the advantages of content-based methods and link-based methods. Step (3) emphasizes the role of the center web pages, which points to many high quality topic-relative web pages. Steps (4) and (5) give reward to cross host web links, so that more topic-related web pages can be discovered. Otherwise, the focused crawler may fall into local optimum, i.e. crawling only within the same host.
We implemented UCrawler based on the methods proposed in this paper, and evaluate the algorithm performance, the scope of the crawler to crawl, the maintenance of the knowledge base, and the URL learning effect. Precision metric is defined as follows to evaluate crawler performance.
where
This study tests the algorithm performance of the focused crawler UCrawler using the topics movie, mobile phone, and finance, and compares the algorithm performance with those of the shark-search algorithm and the best-first search algorithm. Each algorithm crawls 10,000 web pages.
Figures 4–6 compare UCrawler with the shark-search and best-first search algorithms on movie, mobile phones, and finance and economics fields.
Comparison of the precision ratio in the field of movies.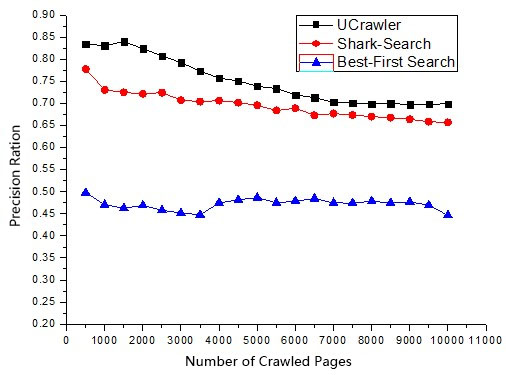
Comparison of the precision ratio in the field of mobile phones.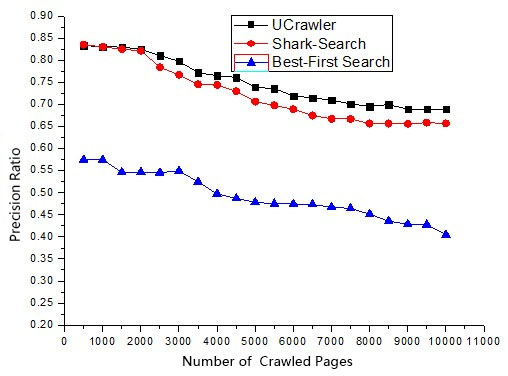
As shown in Figs 4–6, the precision ratio of the proposed algorithm is higher than those of the shark-search and best-first search algorithms. The precision of the proposed algorithm decreases moderately even with the increasing of number of crawled pages. Note that the precision will decrease with the number of crawled pages increasing. This is caused by more irrelevant pages are fetched and retrieved. However, the precision of UCrawler decreases moderately even with the increasing of number of crawled pages.
The number of crawled pages is counted to evaluate whether UCrawler exists locality problem. The number of hosts visited by the crawler is shown in Table 2.
Comparison of the number of hosts visited
Comparison of the precision ratio in the fields of finance.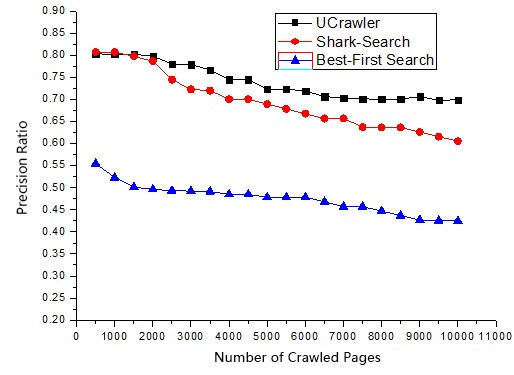
In Table 2, the number of hosts related to the topic the UCrawler algorithm has visited is higher than that visited by the shark-search algorithm. This result shows that UCrawler achieves a higher ability of tracing the entire web and finding more topic-specific pages than Shark-search.
Base on the number of crawled web pages, we found that shark-search algorithm visits web pages from a limited number of hosts, while UCrawler visits web page from a comprehensive and dispersive hosts. Therefore, we can conclude that the UCrawler has a higher ability of avoiding crawling only in the local optimum compared with the other two.
URL knowledge base maintenance and URL learning are also analyzed in this experiment. The URL knowledge base is constantly updated and improved by URL learning. Table 3 presents the URL knowledge base update process in the field of films. The dash (–) means that the word does not exist in the URL knowledge base.
Update of the URL knowledge base in the field of movies
In Table 3, the process of URL learning of the topic-relevant thesaurus exhibits irrelevant phrases, such as lph
During the URL learning, the weight of the phrase in the topic-relevant thesaurus will change iteratively, and we learn some phrases that are related to the topic, such as oscar
Experimental results shows that, the URL knowledge base is constantly improved by URL learning. Therefore the relevances between web page and topic can be calculated more accurately.
One of the key problems of vertical search engines is to construct a focused crawler, which can crawl topic specific web pages accurately and completely. We presented UCrawler, an effective focused web crawler that calculates the topic similarity using parent page content, anchor information, URL content. Our crawling strategy is based on combination of content analysis and simple link analysis. Experimental results show that our approach has better performance than the shark-search and best-first search focused crawlers, and avoids the local optimum problem of crawling. Although the initial results are encouraging, extensive work needs to be done to improve crawling efficiency. A major open issue for future work is to do a more extensive test with a different topic, allowing the crawler to automatically adapt to a different topic.