
Abstract
Most Intrusion Detection Systems (IDS) nowadays are signature-based. They are very useful and accurate for detecting known attacks. However, they are inefficient with unknown attacks. Moreover, most of cyber attacks start with malicious URLs. Attackers try to trick users into clicking on malicious URLs. This gives attackers an easy way to launch attacks. To defend against this, companies and organizations use IDS/IPS to detect malicous URLs using blacklist of URLs. This is very efficient with known malicious URLs, but useless with unknown malicious URLs. To overcome this problem, a number of malicious Web site detection systems have been proposed. One of the most promising methods is to apply machine learning detection techniques. In this paper, we present a new lexical approach to classify URLs by using machine learning techniques which patternize the URLs. Our approach is based on natural language processing features which use word vector representation and ngram models on the blacklist word as the main features. Using this technique can help classifier distinguish benign URLs from malicious ones. Our experimentation shows that our approach can achieve a high degree of accuracy at 97.1% in the case of SVM. Moreover, it can maintain a high level of robustness with 0.97 precision and 0.93 recall scores.
Introduction
The Internet has become an essential part of our lives. Particularly, mail and Web interactions are currently the most popular applications. They are used as a mean of sharing data and communicating readily. Unfortunately, they have also become targets for cyber crimes. The most preferred method that attackers use nowadays is Drive-By-Download. The purpose of this attack is to trick users into visiting a Web site, or opening an email that contains an embedded malicious code. These malicious codes are then triggered when the users visit the Web pages or click on the emails. By exploiting users in this manner, computers can be damaged, or even worse sensitive customer information can be compromised.
Enormous efforts have been made by researchers to address this problem. The most current response is the IDS/Intrusion Prevention System (IPS). Additional efforts have focused on building blacklists of URLs. In this case, users or organizations report malicious URLs to the sites which maintain the blacklists. These lists are then shared widely with IDS/IPS vendors to block access to these malicious Web sites by users. For example, KISA (Korea Internet Security Agency), a government-funded security agency in Korea, maintains a list of blacklist URLs, and tries to generate signatures from that list [1]. Some companies have developed toolbars integrated into the browser that notify users when a malicious URL is detected or clicked. Nevertheless, the problem still remains. Since the primary method used to detect malicious URLs is static (also called a signature-based method), attackers can bypass the blacklist by slightly modifying the URLs, or moving the malicious code to other sites.
In this paper, we present a new approach which uses natural language processing techniques such as word representation vector and ngram models to develop a new, effective model to classify malicious URLs. The system achieves a higher level of accuracy rate on testing set while maintaining the level of robustness of classifier lower compared to the previous work. In our system, Support Vector Machine (SVM) is the machine learning algorithm used to perform classification with the features extracted from ngram model, word vector representation and other lexical properties. Moreover, we specifically implement system in the manner so that it can be applied in real world. We expose two interfaces from the classification model, one is used for training, and the other for submitting URLs for classification. As one example, this system can be applied in email protection, which can classify all the URLs in the email and block or notify users if it finds any malicious URLs. The summary of our contribution is as follows:
We achieve 97.1% accuray rate and 0.95 F1 score while maintaining the classification time 0.01 second on average. The classifier that we build relies on the lexical features with low overhead compared to the other approaches such as host-based and behavior-based. We develop a classification system model for experimentation which can be applicable to the real world.
The remainder of this paper is as follows: In Section 2, we detail our approach in using machine learning to classify URLs and describe the feature set that we use for experimentation. Section 3 explains how our system works, the data collection method used to obtain a given dataset in the system, and evaluation results of the proposed approach. Section 4 describe the limitation and future work. Furthermore, we describe related work in Section 5 and conclude this pape in Section 6.
Approach
Challenges
In this section, we discuss some challenges [2] using machine learning.
Lack of training data: We need training data that the classifier will learn from. If the training data is not clean, it may lead to unexpected result. To overcome this problem, we collect the so-called benign URLs from DMOZ [3]. All the URLs here are manually verified by human beings to make sure that they are benign. High cost of errors: The relative cost of any misclassification is often high when you just use the properties of URL itself without taking into consideration the content of the URL. Therefore, we try to use features so that the deviation between malicious and benign URLs is drawn clear. Achieving this can help classifier increase the ability to distinguish benign and malicious URLs. Difficulties in evaluation: Machine learning applications usually use the number of correct predictions as a metric to evaluate the effectiveness of the application. But practically, the ability to classify the future URLs is more important. Therefore, besides accuracy, we also use various metrics to evaluate the robustness, quality of the classifier. We detail the metrics in Section 3.2.1.
Feature category for URL classification
There have been many attempts made to distinguish malicious URLs. Four categories of features are typically used for machine learning algorithms:
Lexical features: The idea behind lexical features comes from a user’s perspective. It means that when we examine a URL, we say that it is malicious by identifying any suspicious parts. At an example of http://devil.com/bot.exe, we can identify the suspicious word ‘bot.exe’, which is a apparently suspicious term, potentially containing a malicious attack. Lexical features are the properties of a URL itself. They do not involve any other information such as the content or behavior of a URL. MacGrath and Gupta et al. [4] and Kolari et al. [5] suggested some lexical features in their studies such as the length or number of dots in a given URL. Another approach to model lexical features is bag-of-words. This approach splits a URL into tokens using delimiters (’/’, ’-’, ’=’, etc.). Each token is given a binary feature in the feature set. When a token exists in the URL, it is given a value of 1. Otherwise it is 0. Host-based features: These do not indicate the representation of a URL but rather information related to a URL. The motivation behind this category is that an attacker usually uses an unknown host to avoid being detected while launching attacks. It means that malicious URLs are usually from unknown hosts. Some of the host-based features can be listed as follows:
Domain name information: The attacker makes a domain before the attack. Therefore, the TTL information of the domain name is usually different from other sites. WHOIS information: This refers to the information of the person who registers the domain such as: Who is the registra? What was the date of registration? When did the last update to the URL occur? Geographic information: If an attacker plans to launch an attack, he tends to use unknown hosts. Therefore, geographic information is important. The extracted information usually includes: What is the location of the URL? What is the speed of uplink/downlink? URL content-based features: With this approach, the system has to inspect the retrieved content of a URL to identify whether an unsafe code such as Active X, JavaScript or redirection code is embedded within the URL. This feature category requires a great deal of efforts and may lead to a high false positive rate. URL behavior-based features: The principle behind this feature category is that the system of a normal user will not do anything abnormal while browsing a URL. Abnormal behavior in this case could refer to modifying a registry, creating a new strange process, or modifying the file system. By using this feature category, we can achieve a very high accuracy rate. However, the main drawback to this approach is that it may involve heavy computations because every action caused by the browsed URL should be logged and analyzed.
Proposed features
Our aim is to build an effective and robust URL classification system. If the system is effective, it can work together with a signature-based IDS which requires extremely fast processing speed for known attacks but useless for unknown attacks. Therefore, being effective is the first priority in building our system. Another priority is the robustness of the classifier, which is reflected by the metrics of the classifier in a testing phase. The robustness of the classifier also depends on the way we select requisite features. To achieve those requirements, we basically select fewer essential lexical features and focus on their effectiveness. We note that the other features can cause much overhead during feature extractions. Traditional lexical approaches [6, 7] relies on a bag-of-words. However, malicious URLs nowadays tend to be normal tokens or words in order that they may not be readily noticed. This makes the bag-of-words approach inefficient for URL classifications. To address this issue appropriately, we attempt to take advantage of certain URL characteristics such as a URL containing sensitive words, a malicious URL encoded to bypass user notices, and shortened URLs generated by the attacker by using shortening services [8, 9], for example. In this way, we patternize the malicious URLs based on certain selected lexical properties as shown in Table 1, which is quite different from the traditional lexical features. In the following, we explain major proposed features in detail.
Feature Set
Feature Set
Length feature: We compute the length of URL parts such as hostname, path and parameters. These are the common features used to classify malicious URLs. A malicious URL tends to be similar to the benign one, but is longer in hostname or path.
Unsafe extension: Some attacks embed the malicious code in the URL, and attackers often trick users into clicking the link. In this case, the malicious software is downloaded and run. Hence, a unsafe extension is an important feature that we use for our system, where we use extensions such as exe, dll and js. If an input URL contains one of these patterns, we turn on its corresponding binary feature bit 1, otherwise 0.
Special characters: We choose this as the features for our system because an attacker usually makes the malicious URLs hard to be read by human beings. Therefore, the special characters are usually embedded in the URLs to avoid being detected. To implement this feature, we count the occurences of the special characters such as ’-’,’@’, ’?’,’=’,’#’,’% ’, etc. in a URL and use that value as a feature. The total number of features extracted in this group is 28.
Ratio of URL parts: We calculate the ratios between different types of characters and digit such as vowel/consonant, digit/letter, ASCII characters / non-ASCII characters, for example. The total feature size of this ratio feature is 8.
In addition to the above selected lexical properties, we utilize some effective natural language processing techniques, that is, the ngram model on the blacklist patterns and the vector representation model on the classification.
Blacklist word ngram: A malicious URL often contains many blacklist words in various forms. Therefore, we can use blacklist as an indicator in order to decide whether a URL is malicous or not. To find blacklist words in an efficient way, we apply ngram technique in this feature. However, if we just simply lookup the word in a URL, then the result will be only yes or no. It will not represent a probability value. What we want is a probabilistic result which still allows us to count even when the blacklist words are not fully found but parts of them are found in a URL. Therefore, if a URL contains blacklist word, then the probability that the gram of the blacklist exists in a URL will be high. The more malicious indicator in the URL, the more it will be predicted as malicious. Our blacklist word list is from [10]. Some blacklist word can be listed such as porno, xxx, sharedkey, shell, paypal. To extract this feature, we first make 2-gram and 3-gram list based on the blacklist above, and then check whether the gram exists in a URL or not. In the example with the keyword paypal, the extracted 2-gram will be { pa, ay, yp, al, etc.}, and the 3-gram extracted can be { pay, ayp, ypa, pal, etc.}. For each gram, if the URL contains the gram, we add value 1 to the vector, otherwise, 0. The total number of this kind of extracted features is 38. Word representation vector: Word Representation Vector [11] is a popular model used in natural language processing. Using this model, a machine can understand relationships between the words, not by mapping but by semantics. Inspired by that, we apply that approach to the URL classification area, where we make it learn the URL tokens instead of letting the model learn the scopus. The words vector representation model, ’word2vec’ in short, takes advantage of the skip-gram which is very useful in predicting surrounding words in a given word. In this case, the word2vec model can understand the tokens related to malicious URLs and the tokens related to benign URLs. Therefore, we can expect that integrating this model into our model can help our model distinguish between the benign and malicious URLs more accurately. It is because it can understand what malicious tokens look like, what benign tokens look like, and what the related tokens of those two classes look like. The objective of the skip-gram model is to maximize the average log probability given by
The first implementation of this model is word2vec [12] which is written in C. For our implementation, we use gensim [13], another implementation of words vector representation in python, to extract features and integrate with our model. The total number of extracted features from word2vec model is 100.
We developed a crawler in order to collect URLs automatically. By taking advantage of Cron - a Linux utility designed to support task scheduling, our crawler can periodically collect new URLs from given sources.
There are two types of URL feeds: One is from benign URL sources, and the other is from malicious ones. It is critical that we teach the machine learning system how to distinguish a benign URL from a malicious one. In this way, it can predict whether the future incoming URL will pose a threat or not.
Table 2 shows the data structure of URL in the database. The sources from which we collect URLs are as follows:
DMOZ Project [3]: Also known as Open Directory Project, this source was founded by Rich Skrenta and Bob Truel in 1998. This site maintains a list of benign URLs. All of the URLs in this site are checked by the members of the project. The dataset is then published and made available to the public for free. Malware Domain List [14]: This is a non-commercial community project that contains a list of malicious domains and IP addresses. The malware domain list allows anyone to query its content, or download the data in various formats such as CSV, RSS feeds, or txt for free. Malc0de [15]: This source maintains a list of malicious URLs and allows anyone to use its database for free. This site also supports blacklist URL checking as well as viral detection through its VirusTotal [16] software. CleanMX [17]: Founded in Feb 2006, this site supports a rich malicious URL database, which is updated hourly.
URL Information In The Database
URL Information In The Database
In order to make a dataset, we randomly selected 150,397 URLs from the data collection, where the number of benign URLs is 107,615 and the number of malicious URLs is 42,782 as shown in Table 3.
Dataset Information
URL classification system
Environment
We develop our system on Intel Core i7 machine installing Linux, shipped with Python version 3.4.3. Other open sources are added to complement the system. For instance, for partial implementation of the machine learning algorithm, we use scikit-learn [18], an efficient machine learning library for analysis. We use Pandas [19] for data manipulation and computation as well as Pyro4 [20] to bring the primary component (Classifier) online so that the other interfaces can be accessed such as Trainer in the training phase or Predictor in the classifying phase. Other modules that we use are BeautifulSoup4 [21] for XML and HTML parsing and FeedParser [22] for RSS feed parsing.
System overview
This system is designed for complementing other signature-based IDSs such as Snort [23]. If a URL goes through the blacklist of a signature-based IDS which filters out all the known malicious URLs, it will be fed into our system to be rapidly checked again by the classifier. Rapid checking is a mandatory requirement of the classifier. If the classifier is not prompt, then significant damage might be made to the target even though the malicious URL is detected by the machine learning system.
Figure 1 shows our system model. As we described in Section 2.4, the Crawler component is used for collecting benign URLs as well as malicious URLs and save them into database. These URLs are later used for training and testing the classification model. In the system model, we can see that the core component of this system is the Classification Model component. This component is made by the machine learning algorithms such as SVM and is trained with the training data. It exposes two interfaces: one is for training, and the other is for predicting. We intentionally implement like this because we want to seperate the training and predicting in real applications. By using Pyro [20], the classification model is shared across the training and the classifying tasks. By doing this, we can continously train and classify at the same time. In training phase, we get the URLs from the dataset which are already labeled, and pass them to the Feature Extractor component. This component does the feature extraction and outputs the feature vector for model training. The feature vector is the input to the Trainer component, which consists of two parts: training and testing. We firstly train the model and verify the trained model with the testing part. We have another component called Submitter. This component is used to submit the URL to the classification model for prediction. The result clearly indicates the type of URL, benign or malicious.
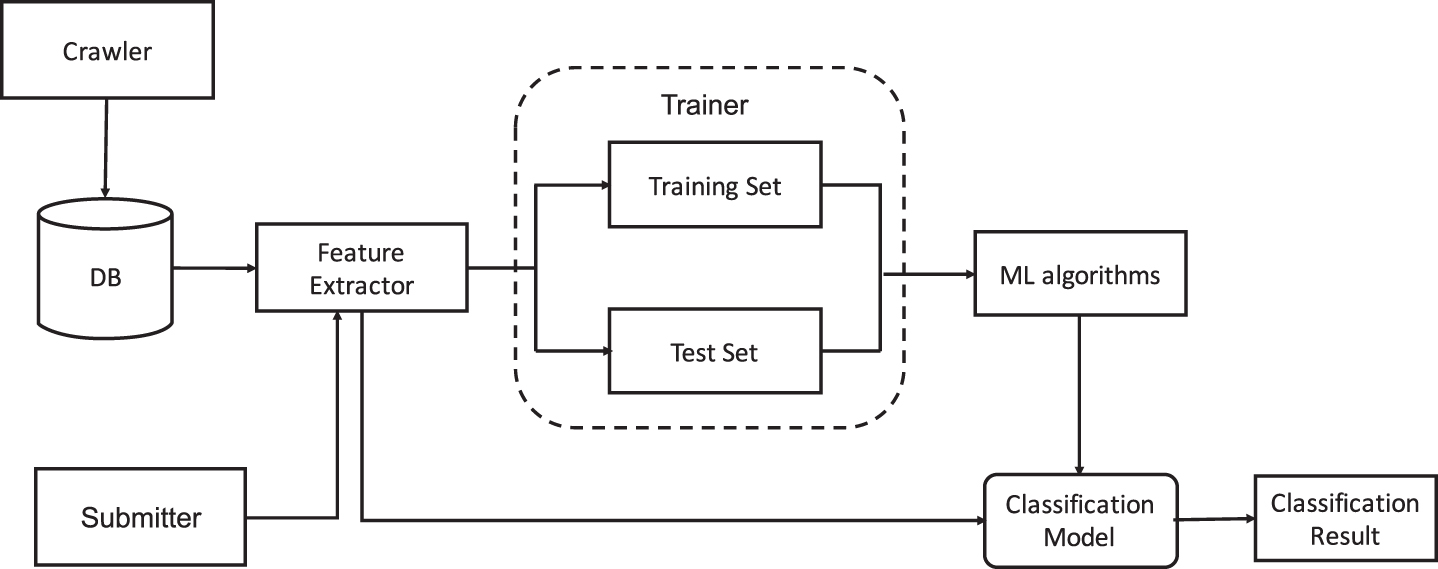
ML-based url classification.
After having the URL data, we need to understand the data that we have. Generally, when we add a common feature such as length for example, we need to know how this feature reflects the data. We first start with some common characteristics such as length of URL part, ratio of digit and alphabet in URL. We implemented the script to extract information about the data we have based on the common things mentioned earlier. To explain in detail, we extract these information by group. First group is related to length features. For example, we compute the average lengths of benign and malicious URLs to see the difference between them. The second group is related to ratio property. For example, we expect the malicious URLs tend to have higher ratio of non-ASCII over ASCII characters than the benign URLs. Therefore, we compute these ratio values in benign and malicious URLs, respectively and compare them. Any deviation can be an indication to take it as a feature.
In Table 4, we can see that the deviations between the malicious URL and bengin URL are drawn clearly. For instance, the average length of the benign URLs (48.35 characters) is much shorter than that of malicious URLs (92.01 characters). We can also see a clear difference in length features except for the fragment length and the param length which results from the fact that the fragment or param part rarely exists in URLs. The ratio characteristics are also good indicators for malicious URLs because malicious URLs tend to have more non-characters than digitletters, and more digits than letters. In contrast to length features, the deviation of the ratio characteristics is not so big that the classification model may not easily identify the differences. However, they are still useful in the feature set because although it may not be good when used alone, the performance may be better when they are used together combined with other features. To this end, we use such useful information to extract the features in subsequent steps. And we expect these features will help the classifier achieve pretty good performance because of the data exploration. The detailed result will be discussed later in the following Evaluation section.
Data Exploration
Data Exploration
Performance metrics
In this section, we describe the metrics that we used for evaluation.
Positives and negatives: The common way to evaluate performance of a classifier is to use true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). They are defined as follows: (1) TP are the URLs which are actually malicious URL and predicted as malicious by a classifier. (2) FP are the malicious URLs which are predicted as benign URLs. (3) TN are the benign URLs which are correctly predicted as benign by a classifier. (4) FN are the benign URLs which are predicted as malicious URLs. In order to measure the prediction ability of a classifier, we examine the error rate of the prediction which includes false positive rate (FPR) and false negative rate (FNR). TPR and FPR can be computed as
Confusion Matrix: also known as error matrix allows the visualization of the performance of machine learning algorithm, where rows represent actual values and columns represent predicted values. ROC curve: An ROC curve features the false-positive and the false-negative rate on X and Y axes, respectively. Therefore, the curve represents the quality of a classifier. This metric is very important, because in a practical system, any misclassifications may cause very serious consequences. Precision and recall: These two metrics indicate the robustness of a classifier. Precision (also called Positive Predictive Value) is an actual measure of result relevance, while recall is a measurement of how many truly relevant results are returned. Intuitively, precision is the proportion of URLs predicted as malicious which are truly malicious. The higher the precision is, the more accurate the classifier does not misclassify a benign URL as a malicious URL. Recall (also known as sensivity) is the ability of a classifier to detect all malicious URLs. The higher recall is, the more the classifier can avoid misclassifying a malicious URL as a benign URL. Therefore, if the accuracy rate is very high, but the precision and recall scores are low, then the system is not reliable. The precision score is computed as
The recall is computed as
F-measure: Instead of measuring the performance of the system by two measurements, precision and recall, we can see how well the system is doing in malicious URL classification by just a single measurement, F-measure (or F1 score). F1 score is the mean of the precision and recall. Using F1, we can have an insight in the overall robustness of system and the possibility of a classifier to predict unknown URLs accurately. F1 score is computed as
System evaluation
After having some features from the data exploration step, we implemented the features as above. We chose several machine learning algorithms to compare. As there are many machine learning algorithms, we chose Logistic Regression (LR) as the baseline to compare with the other algorithms. For implementation, we used LR with L2 regularized from LibLinear package provided by scikit-learn [18]. The other algorithms are used to compare such as SVM, Random Forest (an implementation of Decision Tree), KNN and Naive Bayes.
Figure. 2 shows that the overall result is fairly good, which means that any features which we use to help seperate the URLs into malicious and benign will make the classification more accurate. But the F1 score is not so high, which means that the classifier capability to predict future URL is not so good.

Experimentation result with initial features.
Next, we apply the blacklist ngram and word2vec models into our model. Since malicious URLs tend to contain suspicious words as we stated previously, the probability that the blacklist words exist in the malicious URLs is much higher than the probability that the blacklist words exist in the benign URLs. This will help the classifier see the differences between malicious and benign URLs. In this way, the classifier will make a better decision. The second improvement is achieved by using the word2vec model. We let the word2vec model learn all the tokens extracted from all the URLs that we collected from DMOZ [3]. Because the word2vec model only knows the pattern of benign URLs by benign tokens, the feature vectors of malicious URLs are far different from those of benign URLs. This will help improve the accuracy of the classifier.
In summary, the classifier will easily recognize the malicious URL by the blacklist ngram model features, and easily confirm that the URL is not benign by the word2vec model.
In Figure 3, the result is very good. In the case of SVM, the performance achieves 97.1% accuracy with very low false positive, only 1.36%. We achieve this result by performing cross validation with 10 folds on total 150,396 URLs. The above result comes from the confusion matrix as shown in Table 6.

Experimentation result with full features including ngram and word2vec.
Confusion Matrix
Confusion Matrix Result after Running System with 10-fold Cross Validation
In Table 6, the number of benign URLs predicted as malicious URLs are 1,481, that is, the false positives of the system. And the number of malicious URLs which are predicted as benign URLs is 2,873, that is, the false negatives of the system. This shows that the false positives and the false negatives are pretty low as we already figured out above.
We also evaluate our approach in various algorithms as stated above. In this evaluation, we split our dataset into 2 parts: one is for training and the other is for testing. The result is shown in Fig. 4.
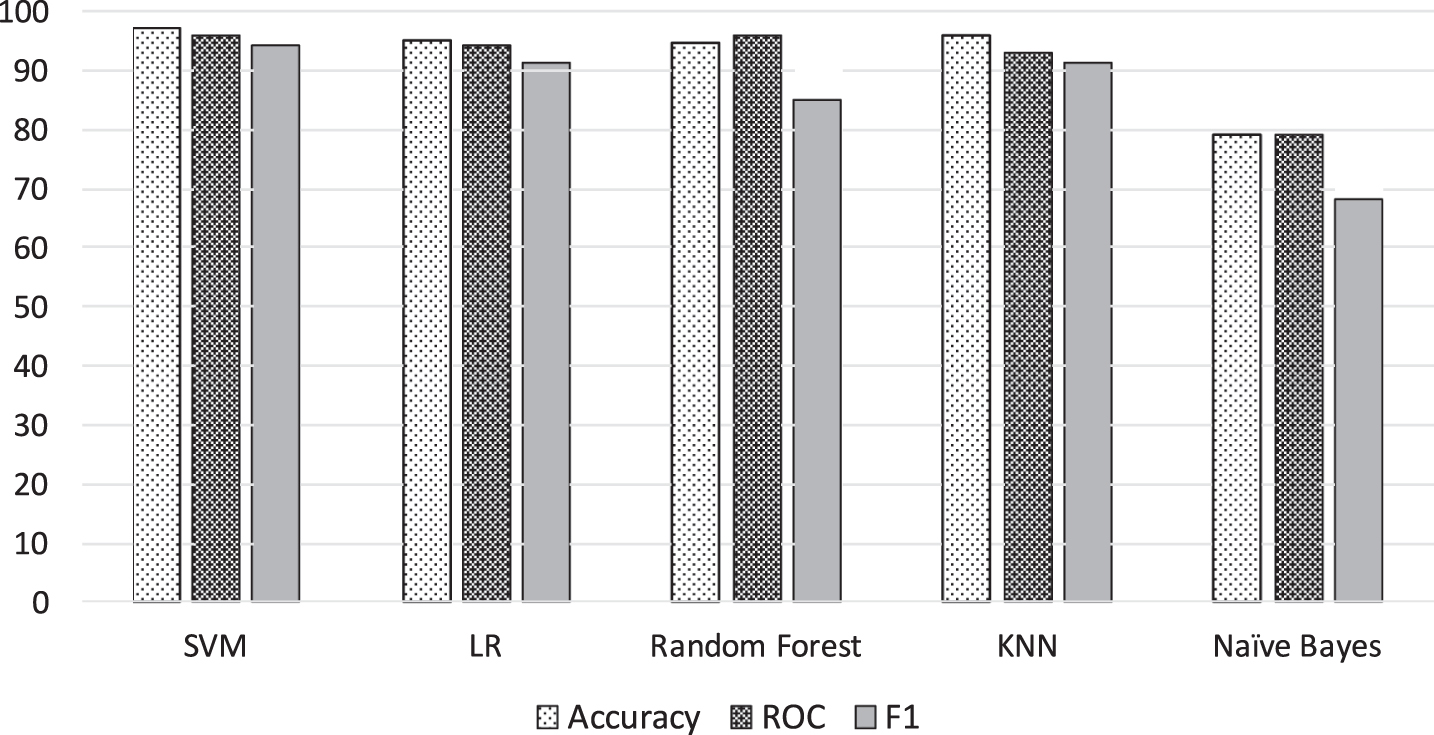
Experimentation result running the system with various algorithms.
Figure 4 shows the performance of the system using various machine learning algorithms with our approach. We can see that SVM achieves the highest level of accuracy rate of 97.1%. Since the accuracy tells nothing about the robustness of the classifier, we also add ROC score and F1 score.
We also implemented a very famous model, bag-of-word, to compare with ours. The bag-of-word model is a very popular model in natural language processing. In this model, the document is splitted into scorpus. Each scorpus in this case represents a feature in the feature vector. Since the feature vector is a collection of scorpus, this approach is called bag-of-word. Next, for each sentence to extract features, it scans all the scorpus in the features vector. If the scorpus exists in the bag of words, the feature at that position is represented by the number of ocurrence of that scorpus in the sentence. Otherwise this feature is written as 0. In [7], LR achieved the best performance using this model. We run the experiment with a dataset of 85580 URLs. And the ratio between benign and malicious URLs is 1:1. Figure 5 shows the FPR and FNR of the bag-of-word model when running with the LR algorithm. We can see that FPR and FNR stay stable when the feature size reaches 5000, 4% FPR and 5% FNR. Therfore, we decide to choose the value of feature size as 5000 when doing comparison with our approach. Also, we tried to run our model with LR to determine approriate feature vector size of word2vec model used in the comparison.
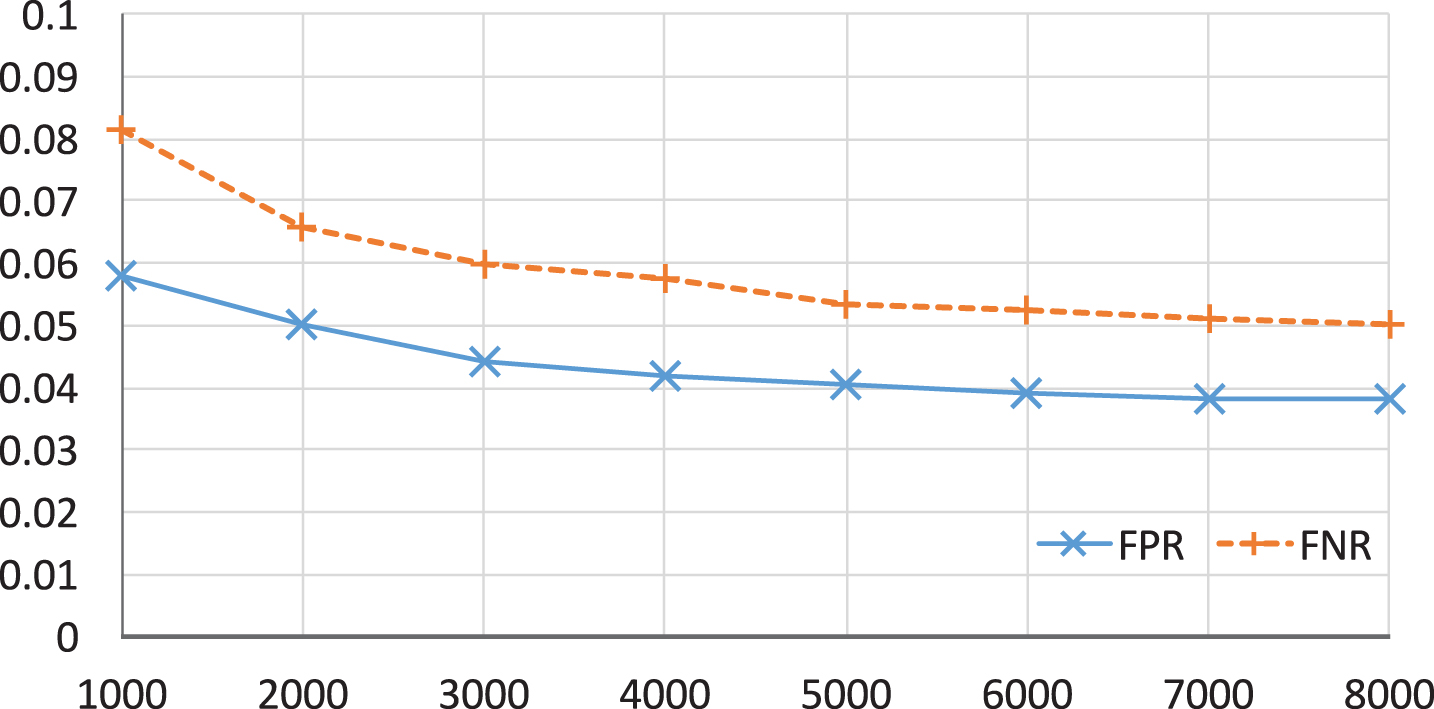
FPR and FNR due to the change of feature size in the bag-of-word model.
In Fig. 6, we can see that FPR and FNR slightly reduce when the feature size of the word2vec model increases. With the size 100, FPR and FNR achieve the highest, 6.25% for FPR and 7.77% for FNR. When the feature size increases up to 700, FPR decreases to 5.3% and FNR falls to 6.18%. To show the efficiency of our model, we keep the feature size of the word2vec model as 100 to compare with the bag-of-word model.
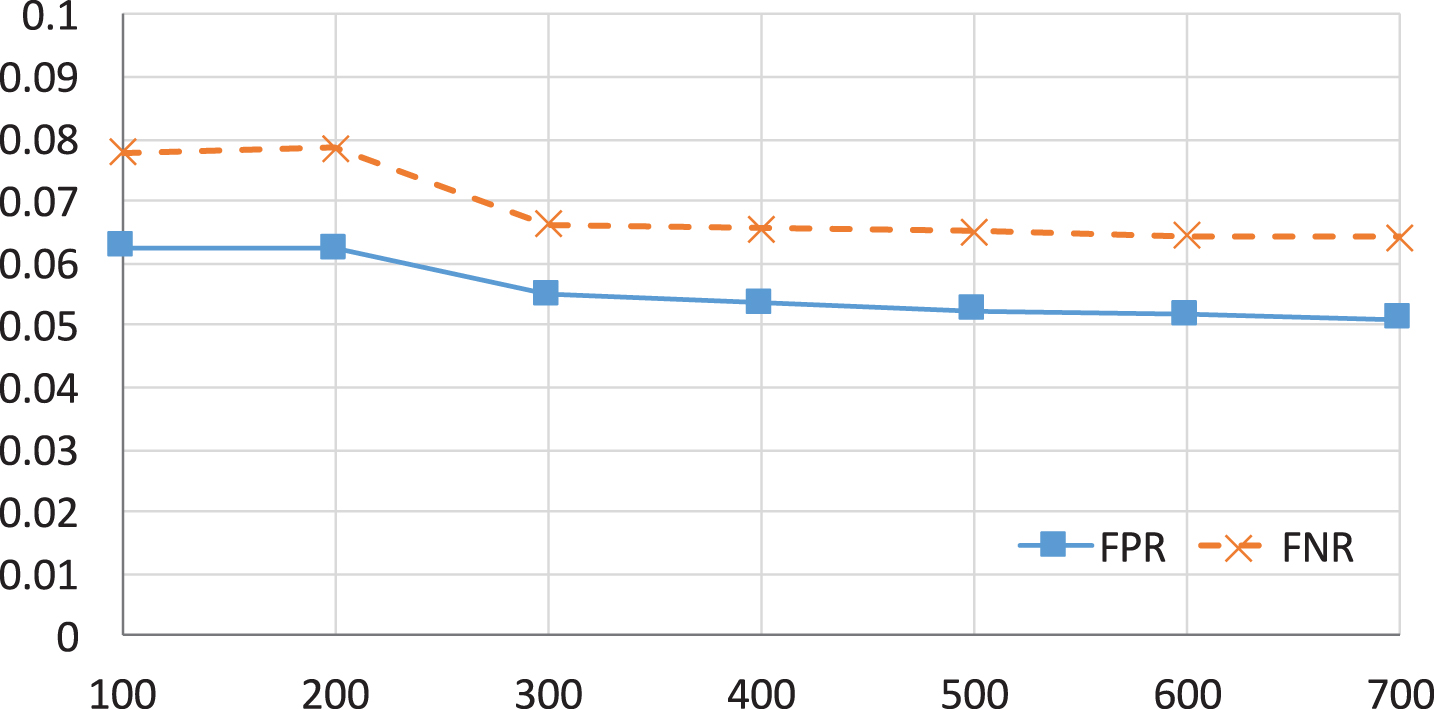
FPR and FNR due to the change of feature size in the word2vec model.
When we compare, we chose two algorithms to compare between bag-of-word approach and ours: LR and SVM. We then, run the 10-fold cross validation for each algorithm using bag-of-word features and ours to achieve the result as in Fig. 7.
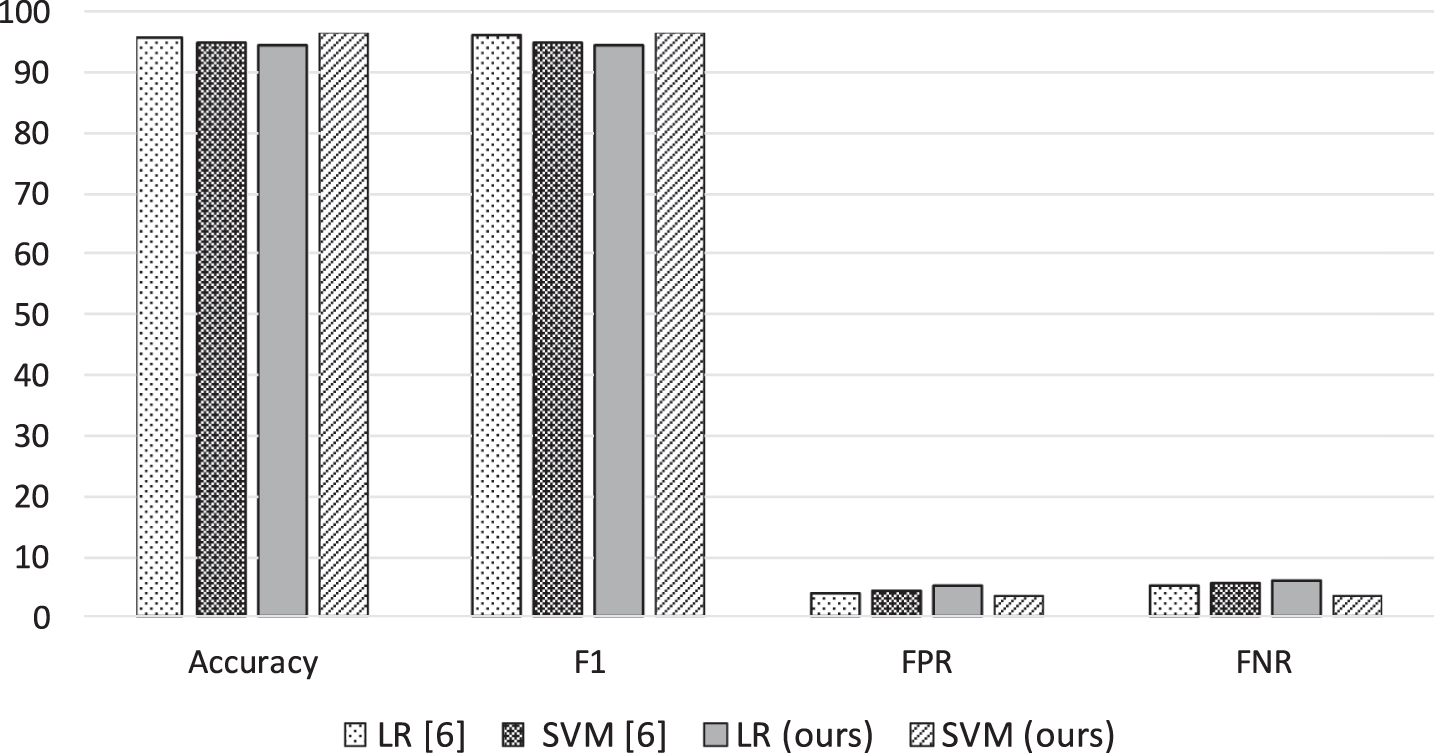
Comparison between the bag-of-word and our approach.
Figure. 7 shows the comparison between bag-of-word approach and ours. With the bag-of-word approach, LR and SVM are similar in the performance aspect. But LR is slightly better when FPR is 4.1% and FNR is 5.3% compared to 4.5% FPR and 5.8% FNR of SVM. The accuracy rate of LR is also better, 95.29% compared to 94.68% of SVM. The last two rows of the table shows the performance of our approach, meaning that our approach is good when SVM is used rather than LR. Although the performance of LR is not as good as those of LR and SVM in the bag-of-word approach: 5.2% FPR and 6.2% FNR, the performance of SVM with our approach achieves the best result: 96.39% accuracy rate, only 3.5% FPR and 3.6% FNR. One more thing to note is that the feature vector size that we use in the bag-of-word model is 5,000 while in our model this number is just around 500, which is very helpful in designing a fast processing classifier. In addition, as shown in Figure 3, our model can achieve even better result by using more benign URLs to train. We will discuss this more in detail in the Tuning section.
In order to estimate the effectiveness of the features that we use, we compare the performance of these features using the metrics. We conducted various expermentations by running multiple machine learning algorithms with a group of features.
Figure 8 shows that the feature group n-gram and feature group word2vec have the highest scores in terms of accuracy and low positive rate which is represented by F1 and ROC scores. This confirms that our approach works very well as expected. Intuitively, the ngram features help the classifier find the malicious pattern which isolates malicious URLs from benign URLs in decision function. Whereas the word2vec model is trained with benign tokens only, this helps the classifier lengthen the deviation between benign URLs and malicious URLs in decision making phase. That’s the reason we combine these two features, because they can complement each other to increase the accuracy rate as well as the reliability of the classifier.
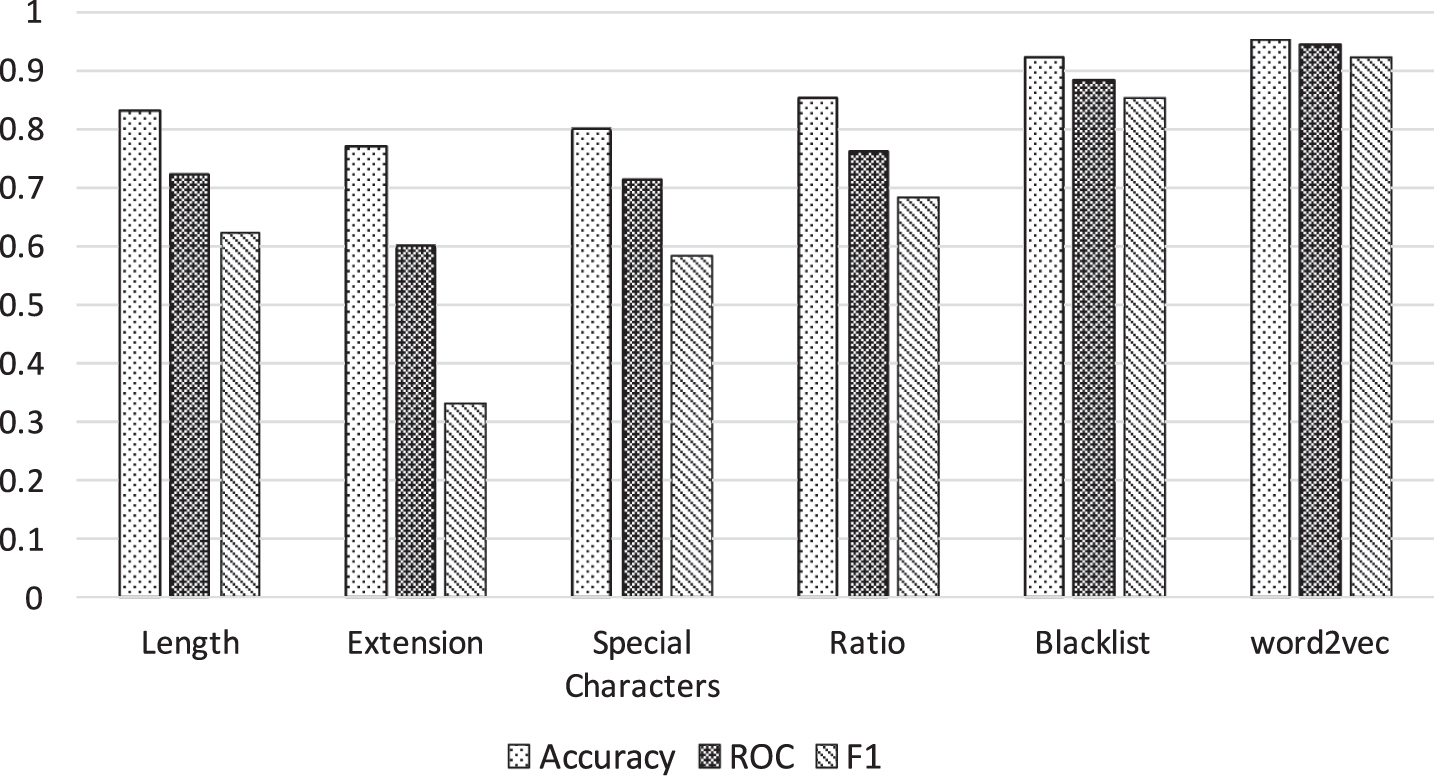
Feature performance by group features.
Tuning
In practice, system administrators care about the false positive rate and false negative rate more than the accuracy rate. This is because they want to mitigate infection as much as possible caused by the wrong classification. False positives and false negatives come from wrong classification. And these rates can be reduced by adjusting the ratio of the benign and malicious URL samples in the training set. Fig. 9 shows the classfication result with different ratios. We can see that with the ratio 3 benign and 1 malicious, both the false positive rate and the false negative rate are reduced, which is represented by the precision and recall scores. The higher the precision and recall scores are, the lower the false positive and false negative rates are.
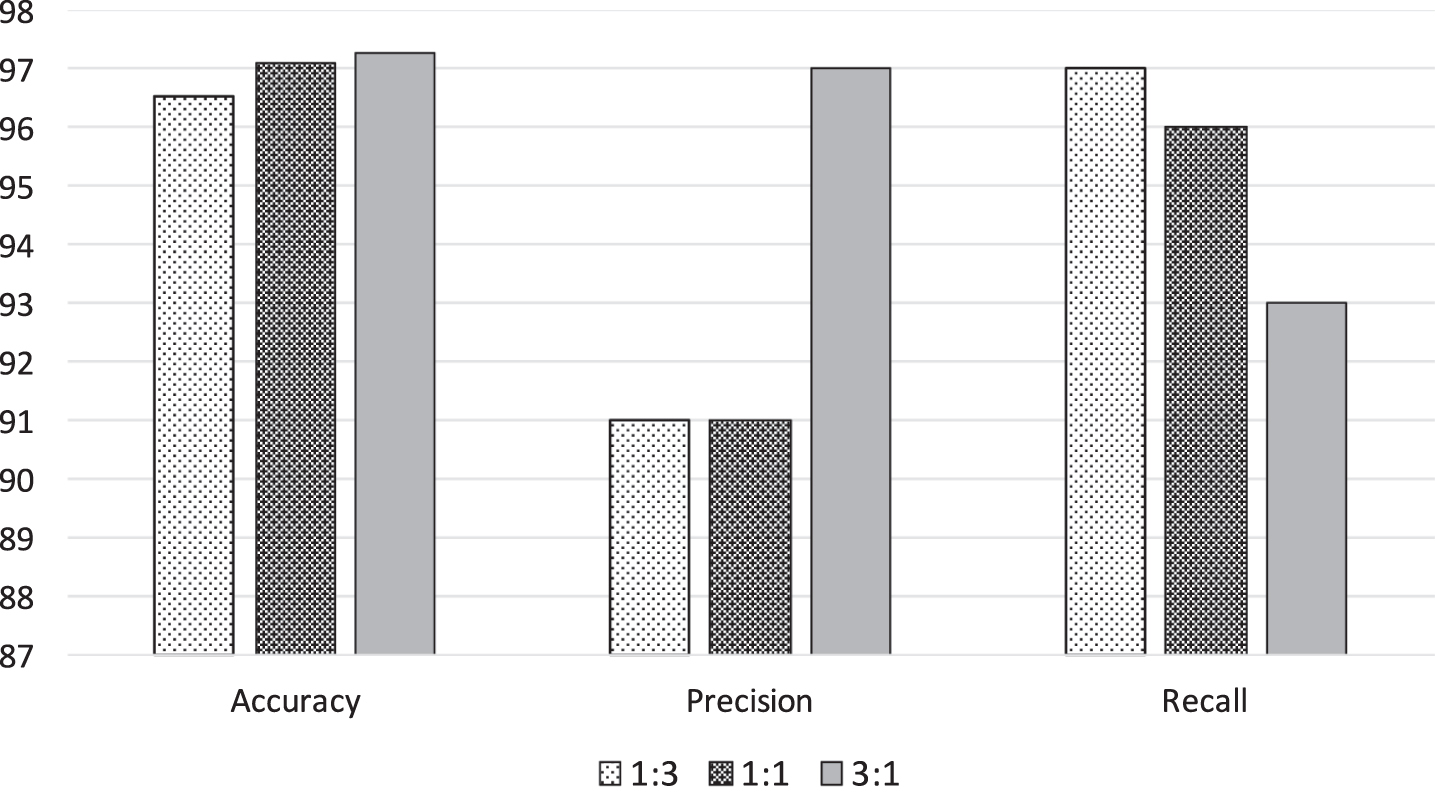
Classification result by tuning ratio
Figure 9 shows that the ratio 3:1 has the best performance in terms of accuracy and robustness, specifically 97.1% accuracy rate, 0.97 precision and 0.93 recall score. Note that our approach is primarily based on word2vec which is built by benign tokens. In the setting like ratio 3:1, since more benign tokens are used in the training phase, our classifier consequentially has more confidence in distinguishing between benign and malicious URLs.
Another approach to tune a classifier is to use multiple algorithms in the classifier. In that case, we have a voting mechanism to produce the final decision. We take the advantage of this by using scikit-learn library [18]. The chosen algorithms include SVM, LR, KNN and Random Forest.
In this experimentation, we use the hard rule and soft rule decisions. Hard rule means that it first computes all the result labels, and then counts the number of labels. The label which occurs more is chosen as the final prediction result. In the case of soft rule, the prediction result from the algorithm is not the label but probabilistic result. The final decision in soft rule is made by taking the mean of these prediction results. Figure 10 shows that the performance of the hard rule is a little lower than the soft rule. It is because the hard rule relies on the number of label occurrences as prediction result. Therefore, even though some algorithms such as SVM have better prediction, the final result possibility is shared across all classifiers. That makes accuracy as well as F1 slightly decresing compared to the soft rule which is probabilistic. We also tried the soft rule and adjusted the weights of the classifier as follows: SVM:2, Random Forest:2, KNN:1, LR:1. As we increase the weights of the first two algorithms which belong to the best algorithms in performance, the probability of prediction result is two times higher than the other algorithms. We can see that the performance does not change much because the overall result is impacted by the ones which have higher weights, in this case, SVM and Random Forest. This makes all the results similar to soft rule only.
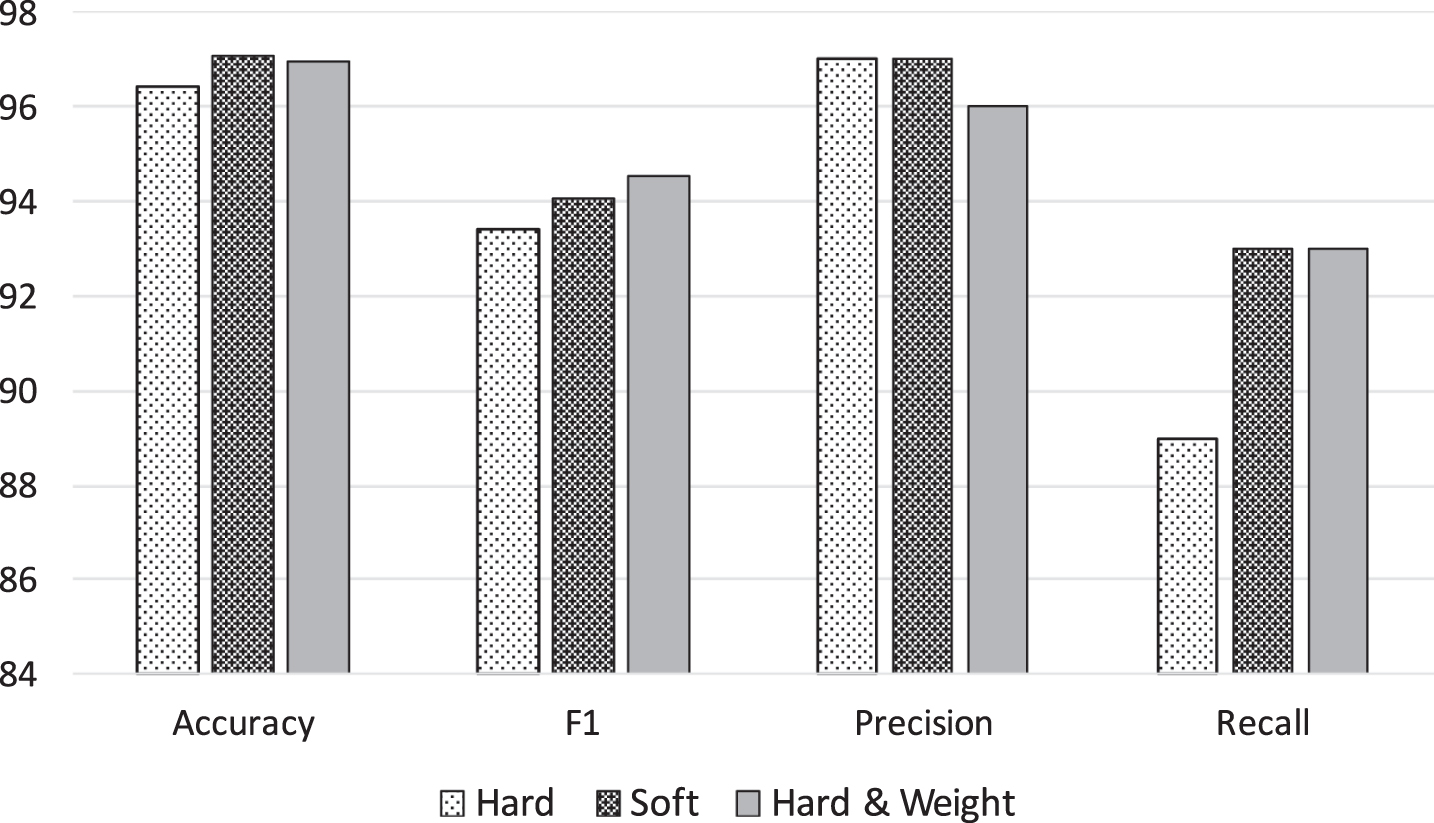
Combined classifier.
To model malicious URLs, our approach relies on the lexical features with the machine learning models which are based on statistics. Therefore, attackers can try evading detection by making malicious URLs look like benign URLs by accessing those public resources we make access to, and generating malicious patterns which can bypass our system. In this case, our model can partially handle this attack by continuously updating the word2vec model by benign URLs which can be retrieved from some public benign sources such as DMOZ [3], and by continously training the word2vec model with the legitimate tokens from trusted sources such as Alexa [24]. The more we train the model with those URL tokens, the more the classifier can dissimilar malicious URLs. We take this as a solution to make our system work in the real world.
Moreover, attackers can use the shortener services to evade detection. In this case, our model can handle as well because we try to lengthen the URL before feature extraction. Although it can slow down the classification speed, we can mitigate the attacker’s evasion attempts proactively.
Although the lexical approach is fast and lightweight, it may not be enough to ensure the full security in the case that attackers try to hide malicious content under normal URLs using benign token. Therefore, it would be better to have another system to complement the lexical approach. This motivate us to implement another non-lexical approach and combine them together to complement the current system.
Related Work
In this section, we survey related work on URL classification using machine learning and data mining techniques.
Justin Ma et al. [6, 7] used lexical features based on the bag-of-words approach and host-based features to classify URLs. Also, they tried to apply this approach to online learning to achieve a large-scale system. Although we use lexical features in our proposed method, we do not rely on the bag-of-words approach. Instead, we use other properties to patternize malicious URLs.
In CATANA+, Guang Xiang et al. [25] used multiple categories of features: 7 features in URL-based, 4 features in HTML-based and 5 features in Web-based called Rich Features. They also relied on machine learning algorithms for phishing Websites. They claimed to achieve a 1% false positive score with 100 benign Website URLs and 100 phishing Web site URLs. Our feature set is similar to this one. However, we incorporate just a few important features into those categories such as key sensitive words.
Anh Le et al. [26] conducted a study on machine learning to classify phishing URLs. This approach is an adopted version proposed by Ma et al with some hand-selected features such as URL obfuscation. Various machine learning techniques were compared and they proved that the Confident-Weight approach has the highest accuracy rate of up to 97%. Our approach is similar, though we also use other features such as sensitive words and unsafe file extensions which help to patternize URLs more efficiently and effectively.
Islam et al. [27] proposed a system which combines multiple classifiers to increase reliability in spam email filtering. This approach uses the features related to header, content-type and message body characteristics to filter spam email. The evaluation of this system was very high, with up to 97% accuracy and under 2% false positive rates.
Conclusion
Although many signature-based IDS systems have been proposed, online users are still at risk from malicious attacks. Hence, the challenge is to design a more effective and reliable protection system. In response to this, our paper presents a new approach to apply the natural language processing techniques such as the ngram and word representation vector models to machine learning to classifiy benign and malicious URLs. Taking advantage of these models, our classifier can differentiate between malicious and benign URLs with a high degree of accuracy because it can understand the relationship of the tokens inside the URL. This is firmly supported by our various experiments and analysis. We conclude that our approach can be effectively deployed in protecting users from malicious URLs when combined with existing signature-based IDS, even on a large scale environment.
Footnotes
Acknowledgment
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. 2017R1A2B4001801).