
Abstract
An algorithm based on EMD-LSTM (Empirical Mode Decision – Long Short Term Memory) is proposed for predicting short time series with uncertainty, rapid changes, and no following cycle. First, the algorithm eliminates the abnormal data; second, the processed time series are decomposed into basic modal components for different characteristic scales, which can be used for further prediction; finally, an LSTM neural network is used to predict each modal component, and the prediction results for each modal component are summed to determine a final prediction. Experiments are performed on the public datasets available at UCR and compared with a machine learning algorithm based on LSTMs and SVMs. Several experiments have shown that the proposed EMD-LSTM-based short-time series prediction algorithm performs better than LSTM and SVM prediction methods and provides a feasible method for predicting short-time series.
Keywords
Introduction
Currently, time series forecasting is performed using both qualitative and quantitative methods [1]. In qualitative forecasting, empirical factors are considered that are not suitable for use in big data forecasting. Having experts familiar with the forecasting field is likely to improve forecasting accuracy. One method of quantitative forecasting is the simple moving average method [2] and another method is the weighted moving average method [3]. The simple moving average and weighted moving average methods are only applicable to commodities whose demand is relatively stable and without seasonal fluctuations. In the weighted average method, the weight assignment remains subjective [4]. Uncertainty, rapid change, and no period of stability exist in the short time series. It is difficult to adapt the above prediction algorithm [5].
The empirical mode decomposition [6] is proposed by Huang Yu (N. E. Huang) as a method for analyzing and processing nonlinear non-stationary signals as a new type of adaptive signal time-frequency processing. It is particularly useful for processing non-stationary and non-linear data because the EMD method is theoretically capable of processing any type of signal decomposition. By decomposing the short time series using EMD, the complexity of the short time series can be eliminated, which will benefit future modelling. The RNN can suffer from gradient disappearance or explosion when transmitting data. Therefore, the network level needs to be improved to prevent it from being too deep.
The LSTM works in a similar way to the RNN. However, the LSTM uses a more detailed internal processing unit to efficiently store and update context information. A number of tasks related to sequence learning have been performed using LSTM due to its excellent properties, such as short-term fog prediction based on meteorological elements [7], remaining useful life regression [8] multi-disease prediction [9], and emergency event prediction [10]. As a result of its unique design structure [11, 12, 13], LSTM can be used for time series data analysis and forecasting, but in actual forecasting, LSTM is unstable for short-term time series forecasting with irregular and fast transformations [14, 15, 16].
Given the characteristics of nonlinear short time series, it is difficult to construct a prediction model and make an accurate prediction. In this paper, a nonlinear non-stationary signal is processed using empirical mode decomposition. The EMD decomposition of the short time series provides the IMF components and trend elements of the intrinsic mode function. The decomposition of the time series eliminates the volatility and complexity of the short time series. The LSTM is then used to forecast and sum the IMF components and trend items to produce forecasts for the time series. Through experimental verification, non-linear short time series can be predicted more accurately and with greater stability.
EMD decomposition principle
The function is symmetrical in its characteristics when the instantaneous frequency is of practical significance, the local mean of the function is zero, and the number of zero crosses and extreme points are identical. As a result, Huang et al. developed the concept of IMF.EMD decomposition to obtain the eigenmode function. The following steps are involved in the decomposition:
1. First, find all the extreme points of the original signal
The upper and lower envelopes of the IMF.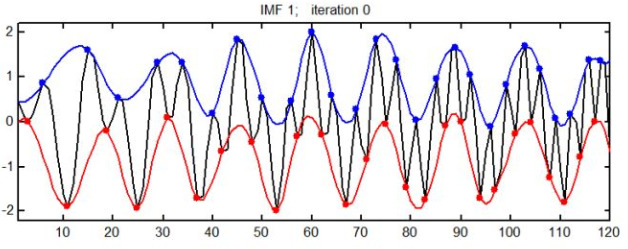
The mean value of the upper and lower envelopes of the IMF.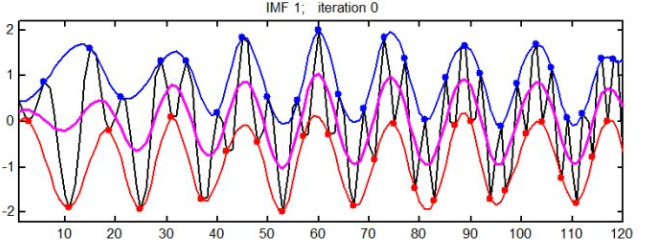
The difference between the original signal and the envelope average.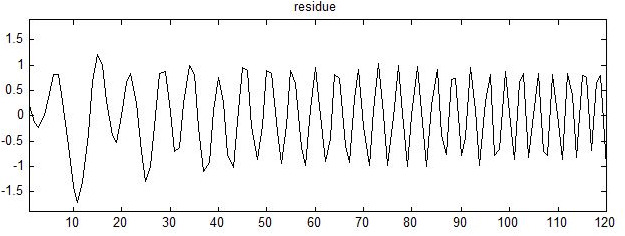
2. Determine whether
3. When
4. The EMD decomposition process ends when
Based on Eq. (4),
Results of EMD decomposition.
As a result of gradient disappearance or gradient explosion during transmission, the network level of RNNs needs to be improved in order to prevent the network level from becoming too deep. According to Fig. 5, the system is composed of three doors: input doors, forgetting doors, and output doors. As a result of the information contained in both the input layer and the hidden layer from the previous time, the on/off state of the door is influenced. Using the input door, the unit value
LSTM memory unit.
The Forget Gate produces the following output when it forgets C
The output of the output gate is shown below:
In order to select a suitable forecasting model, evaluation indicators are indispensable. However, there is no general standard index evaluation system in place at the present time. There are two formulas commonly used to evaluate errors: Average Absolute Error (MAE) and Root Mean Square Error (RMSE). Here are some related formulas:
LSTM is divided into two steps for predicting short time series. In order to obtain the basic modal components imf with varying scale characteristics, an EMD decomposition is performed on the original time series. In order to predict and analyze each component of the imf, the LSTM neural network is used. The final forecast result is obtained by summarizing the forecast results of each component of the imf. A model combination of EMD-LSTM can be seen in Fig. 6.
Modeling process
Input and output data of modeling
Input and output data of modeling
EMD-LSTM prediction model.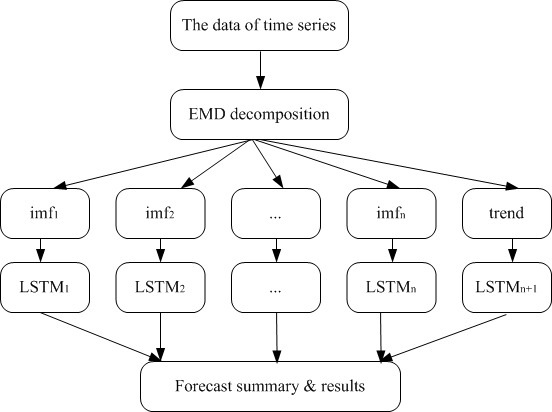
A time series is presented as
After the input and output data have been divided, they are further divided into training sets, test sets, and validation sets. To train the forecasting model of LSTMLSTM, training sets and test sets are used, while validation sets are used to verify the model’s forecasting capabilities. In general, training sets, test sets, and validation sets are divided into 80% and 20%, respectively.
Time series prediction with LSTM is also one of the keys to the training of LSTM networks, as well as processing of input data, including modal decomposition with EMD and data normalization, while training is primarily targeted at the hidden layer of the network. From the IMF, time series are entered as
In this case, the output is as follows:
In the equation,
Set optimization targets for loss functions, as well as the initial network random seed (seed), learning rate (
Based on the LSTM forecasting algorithm, the EMD-LSTM algorithm was derived. As a result, it modifies the instability of the original LSTM when forecasting data. Consequently, the forecasting process becomes more accurate and adaptable since the data development trend is maintained.
Eliminate abnormal data
Alternatively, anomaly data may be referred to as isolated data or out-clustered data. There is a significant difference between this data and the normal data in the graph. Due to its presence in the forecast, the establishment of the model is affected, which results in an increase in forecast errors. Multiple methods can be used to eliminate abnormal data. In this article, abnormal data is determined using the following methods:
If
In this case,
Among them
The setting of model parameters
When entering data for the LSTM network for training, the nodes and hidden nodes should be designed carefully in order to achieve better prediction of time series data. Repeated experiments, empirical formulas, growth methods, deletion methods, and other methods can be used to determine the number of neural units in the hidden layer of an LSTM network. To determine the roughness of the hidden layer, this chapter combines the growth method, the reduction method, and the empirical formula method. After comparing the accuracy of the results with anti-growth and deletion methods, The number of hidden level nodes are calculated based on the number of nodes with the highest accuracy. In this thesis, the following empirical formula has been adopted:
EMD-LSTM forecasting algorithm
The LSTM training forecast algorithm consists of the steps listed in Algorithm 1.
Experimental results and analysis
To evaluate the effectiveness and superiority of the EMD-LSTM model, this experiment was verified with a real dataset, which addresses the following two questions: (1) Validity. Time series data are predicted using the EMD-LSTM algorithm and compared with the original time series data. In the case of a small error, the validity can be reflected. (2) Advantage. EMD-LSTM data forecasts are compared with forecasts obtained from other models. In this way, forecasting accuracy will be improved, which will result in a competitive advantage.
Experimental data
In this thesis, Eamonn Keogh provides the data through his classic time series data website, which is available at
Experimental setting
Using SVM and LSTM forecasting algorithms and the EMD-LSTM algorithm model proposed in this chapter, a comparative experiment was conducted to verify the effectiveness and feasibility of the EMD-LSTM algorithm model. Synthetic Control series data were utilized as experimental objects to test the proposed method’s forecasting capability.
Comparison of experiments
We designed two scenarios for the prediction and comparison to test the sophistication of the EMD-LSTM algorithm proposed in this thesis: Program I: EMD-LSTM forecasting for two types of raw data; Program II: LSTM and SVM are employed to predict and compare for both types of data.
EMD decomposition of Normal data.
EMD decomposition of Cyclic data.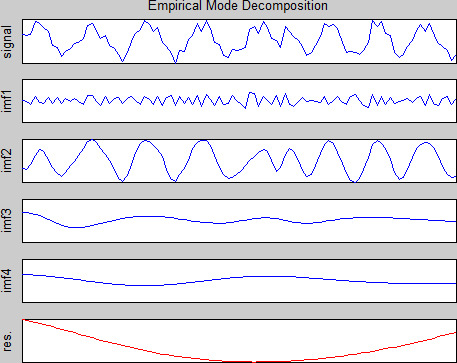
The algorithm is running in the following environment: Intel i7-8565U@1.8GHz Quad-core CPU; 16 G internal storage; 1 TB hard drive for storage capacity of the hard drive; Microsoft Windows Operating System; MATLAB 7.1; python 3.5; tensorflow 1.2 and Keras.
As a result of the abnormal processing, the two types of data are decomposed by EMD. EMD decomposes the first data set (Normal) into 10 components. The original time series signals are each shown in Fig. 7. An analysis of the inherent mode function (imf1, imf2, …, imf8) shows that the volatility of the function is gradually decreasing, while the stationarity is gradually increasing, and the res represents the trend line. EMD generates six components from the second (cyclical) data. The original time series signals are shown in Fig. 8. The inherent mode function (imf1, imf2, …, imf8) decomposed by EMD shows that its volatility is gradually decreasing and its stationarity is gradually increasing, with res representing the trend line. According to the analysis, the data characterized by Normal have more imf than the inherent modal functions decomposed by Cyclic.
Predicted Normal type data using EMD-LSTM.
Cyclic type data predicted by EMD-LSTM
During the experiments, the model sets the initial input to 500, the density to 12, the output to 1, the weight and bias to [
In the experiment, the model sets the initial inputs to 100, Dense to 6, output to 1, the initial weight and bias to [
An EMD decomposition of the short time series yields the IMF components and trend items of the intrinsic mode function. As a result of the decomposed time series, the volatility and complexity of the short series are eliminated. Next, we use the LSTM to predict and sum up the components of the IMF and trend items in order to obtain the prediction results for the time series. According to Figs 10 and 11, the EMD-LST model algorithms show adaptability and reliability for prediction, regardless of whether the data are normal-type data (representing irregular data) or cyclic-type data (representing periodic data).
Prediction error of Normal data
Prediction error of Normal data
Prediction error of Cyclic data
Comparison of three models for predicting data of the Normal type.
Comparison of three models for predicting data of the cyclic type.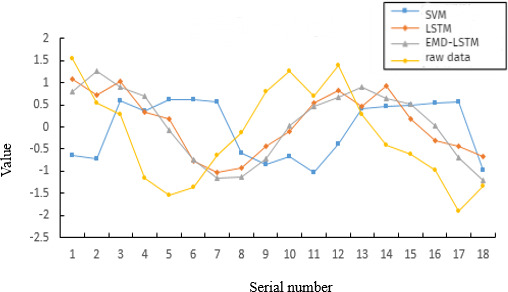
In order to further validate the superiority of the EMD-LSTM model presented in this section, a comparative study is conducted to compare the forecasts of the LTEM, LSTM, and EDM-LSTM models in this theme. The same data is selected as in Program I. In this case, the kernel function of SVM is RBF as the core, and the regularization parameter C and the kernel function parameter gamma are set to 10 and 2, respectively. Program I provides instructions for setting the LSTM and EMD-LSTM parameters.
Figures 11 and 12 illustrate a comparison between forecast data and actual data for each model, along with the corresponding evaluation indicators in Tables 2 and 3. The EMD-LSTM forecasts perform well for both normal and cyclical forecasts. In the case of Cyclic data forecasting, SVM and LSTM are acceptable, but in the case of Normal data forecasting, they are not satisfactory. It can be concluded that the prediction accuracy has improved when compared with other models using the EMD-LSTM algorithm, which is a testament to its superiority.
This paper proposes a time series forecasting algorithm based on the EMD-LSTM model. First, anomalous data is eliminated, and then EMD is used to perform modal decomposition. By decomposing the data, the influence of random nature is eliminated, thus improving the forecasting accuracy of LSTM on short time series. Based on experimental validation and comparison, it has been determined that an EMD-LSTM algorithm demonstrated good adaptability and prediction accuracy for a variety of range series, and the use of this approach in scenarios is more widespread.
Footnotes
Acknowledgments
It is supported by the State Key Laboratory of Tibetan Intelligent Information Processing and Application/Tibetan Information Processing and Machine Translation Key Laboratory of Qinghai Province (2020Z003), Fuzhou Polytechnic (FZYRCQD201901), and Fuzhou Polytechnic’s Certification Training Program (LX-2019-HX-005).