
Abstract
Water Turbine Unit is the core equipment of water power generation. It is the most important research object in hydroelectric power. The analysis of daily monitoring data of Water Turbines can evaluate its running state and avoid the loss caused by failure. In this paper, A hybrid neural network architecture which CNN combines Transformer is proposed to evaluate the health state of water turbines based on multivariate long time series data. It has two core components: (i) dilated convolution applies to capture low-level and local semantic information, then the output of convolutional layers is divided into subseries-level patches by time, these patches are regarded as input tokens of Transformer layers; (ii) utilizing self-attention of Transformer to extract high-level and global semantic information. Patching design naturally has benefit as follow: (i) local semantic information is retained in Transformer input tokens and high-level semantic confirm to common sense of human understanding through low-level construction; (ii) the length of Transformer input sequence is greatly shorted and attention can be more concentrated compared with point-wise form. Meanwhile, the computation and memory usage reduces at the same time. The experimental result indicates that the hybrid architecture can achieves excellent performance in time series understanding.
Keywords
Introduction
Electricity is an indispensable power resource for modern industrial and life. Hydropower generation is an important branch of electricity production. Compared with other power generation methods, it has many advantages, such as renewable, environmental protection, etc. Hydro turbine is a kind of fluid machinery widely used in the field of hydropower generation, and is the core power generation equipment in hydropower stations. Its main function is to covert the kinetic energy of the water flow into mechanical energy, and the drive the power generation equipment to convert the mechanical energy into electrical energy. Its failure will be cause huge economic losses and safety hazards. Traditionally, maintenance personnel analyze the operating status of the unit through daily monitoring data, while, due to differences in manufacturing technology, various operating environment, inexperience of the maintenance personnel, it becomes a difficult problem to detect and find abnormalities in the early stage, especially the slight fluctuations in monitoring data. Therefore, it is a general trend to solve the above problems through AI technology.
The monitoring data often tends to span a long period of time, long-term time series analysis requires to sufficient long-term context information, Besides, the local information is also important because of the devil is in the details. Convolutional operator is good at extracting local features via the kernel design. Recently, Transformer have shown great power in sequence modeling and global features extracting with the self-attention module. Based on the above motivations, a new architecture that combines CNN and Transformer for time series classification task is proposed. It has three main components: (i) dilated convolution is used for focus the local details; (ii) Transformer is used for modeling the long-term context; (iii) a module is designed to aggregate the different range information. The task of assessing the health condition of water turbine unit is adopt to verify the validity of our method. It accepts multivariate long time series monitoring data and outputs the faulty component. Experiments show that our method is effectiveness and efficiency in time series analysis application, and we strongly believe this network will be effective on any time series analysis task.
Review of the literature
In the early days, time series classification task mainly relied on machine learning methods. Among the various of approaches, the most impressive one is nearest neighbor applied a distance function [1]. Particularly, the combination of dynamic time warping distance and nearest neighbor was a breakthrough at that time [2]. Later, researchers discovered that ensembling different distance functions and various discriminant models could archive better results. While, the disadvantages of these methods is obvious, machine learning approaches are for structured data, often applied hand-designed features based on statistical theory, unfortunately, time series data is usually unstructured, the transformation between structured and unstructured is accompanied by information loss, and even more fatal is unable to capture the devil of data. Thus, it is necessary to develop a simple method that directly predicts the category of input.
Deep learning have been seen so many successful applications in different domains, it is desired to bring deep learning methods to time series classification tasks. Recurrent Neural Network (RNN) are specifically designed for modeling temporal sequences, it takes input from the previous step and current state. When a standard RNN is exposed to long sequences or phrase it tends to lose the previous information because it lacks the ability of storing the long-term context, this problem is commonly defined as vanishing gradients. Many specialized versions of models are created to overcome this disadvantage, such as LSTM, GRU and so on. Deep Convolutional Neural Network (CNN) can be said the most successful architecture, especially, in the computer vision field. It relies on the kernels to slide and extract features in space. There are so many approaches are proposed to model the long-range time series analysis, Beijie Hong built a memory pool to storage distant information [3], which is to used refer the history when it is necessary, they thought it can avoid the information loss in this way. Cui used multi-scale convolutional layers to capture features at different scales [4], which can explore the knowledge of different receptive field. Falze proposed a hybrid architecture of LSTM and convloutional network to enable spatiotemporal feature learning [5]. Although RNN have been designed and optimized, they still cannot fully solve the problems of gradient vanishing and long-range dependencies. Convolutional layer are inspired the theories of digital image processing, the convolutional operator is designed to capture local information by sliding step by step, While, the shallow CNNs are insufficient to model dependencies that extend beyond the receptive field. Just extending the receptive field by stacking the convolutional layers is not the perfect way to solve this problem. More layers means more parameters and deeper network, meanwhile, deeper networks mean more computation and harder to train.
Over the last few years, Transformer is the most successful and fascinating design in AI field, its excellent capabilities at modeling long-range dependencies based on self-attention architectures. Motivated by these observations, we propose a hybrid network of CNN and Transformer. Our approach is influenced by Vision Transformer (VIT), great work that use transformer block for image classification [6]. First, utilizing CNN strong inductive biases (e.g., local connectivity and translation equivariance) to capture local and low-level features, such as shape, amplitude, etc. Second, segment time series sequence into patches by time, capture the global and high-level semantic information based on Transformer blocks. Since timing information generally has redundancy, applied dilated convolutional operator to obtain more diverse content. To adapt to the multivariate case, 1x1 convolution is used for aggregation before inputting Transformer block. In order to collect monitoring data required for experiment in multiple dimensions and solve the problem of few samples of difference degrees of fault data, an equivalent test environment platform has been established. Our approach have outstanding performance over the previous methods, we hope this method will be a indispensable part of hydropower in the further.
Method
An overview of the hybrid architecture is depicted in Fig. 1. The model receives as input a 1D multi-channel time series data
Convolution operator is a form of non-linear transformation of input tensor. It is a powerful tool of extracting local information because of its property. The success of the CNN in the various tasks, researchers have adopt it for time series analysis [7].
In our opinion, the shape of time series represented by the value of data values is the most basic and important feature. Meanwhile, a lot of redundant and useless information is hidden in time series, for example, values with small intervals of show high consistency. Inspired by above, channel-wise dilated convolutional layers are applied to learn the local representation. Given the multi-channel tensor
The standard Transformer layer takes 1D sequence of token embedding as input, therefore, 1x1 convolution is used to reduce the channels of previous layer output and aggregate the information from different channels. In this paper, we stacked three dilated convolutional layers, the dilation rates are 1, 2, 4, respectively, and batch normalization is applied in each layer, the activation function we used is ReLU.
Our global features extraction model, consisting of 6 Transformer blocks, aims to output the global representation based on local representation. We segment the long time series
Overview of our proposed architecture, it consists of two models: convolution models extract local and low-level semantic information. Transformer models capture global and high-level semantic information, both are aggregated by cross-attention.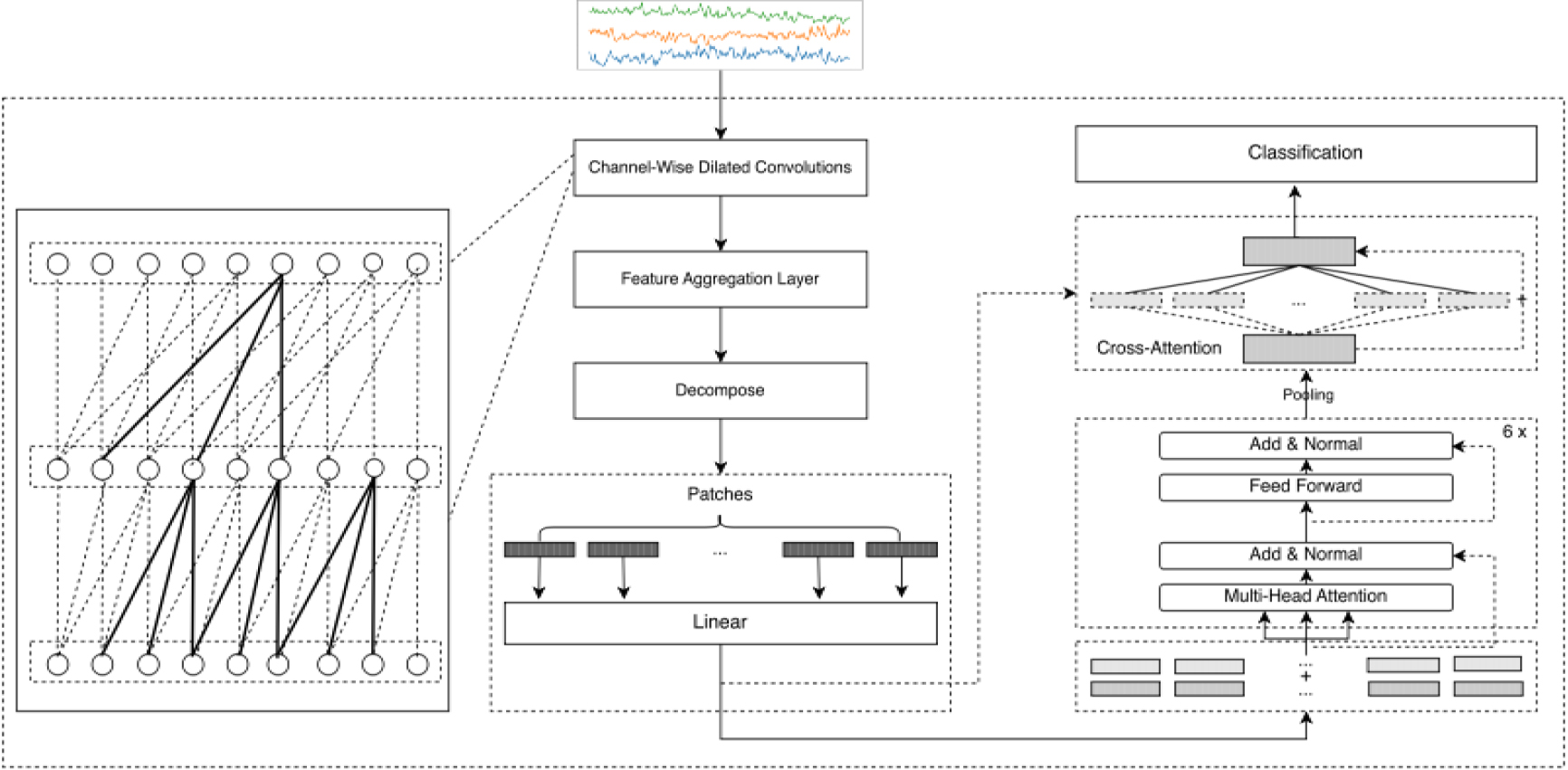
Position embedding
Temporal information is necessary for time series analysis. As mentioned in [8], time location information of patches is added to
Where
Self-attention
Like information exploration, human beings firstly focus on the more important parts of object in daily life. Mimicking the way of understanding of human beings, researchers introduced attention mechanism for deep learning to filter out redundant, irrelevant, insignificant information. Various of attention mechanism designs exist. Among them, self-attention [8] was the most influential. Queries, keys and values are generated from the input tokens by linear transformation. The output is a weighted sum of values, where the normalization weight of all elements is scaled dot product between queries and keys follow softmax activation function.
For easily understanding the computational logic of self-attention, We first describe the element-wise form. Given the input token
The normalization weight is the scaled dot product of query and key, then get the weighted sum of value
where
In practice, all the tokens should compute the weight sum as above, we can extend to matrices from the element-wise form. Let
We have mentioned that the core idea of computing
where the
Transformer block
Self-attention is the soul of Transformer, furthermore, layer normalization layer, residual connection and multi-layer perceptron are its components. Figure 3 is an brief overview of Transformer block. Layer normalization and residual connection make the training of model more stable and converge faster. Stacked Transformer blocks are capacity to capture global information, while, the intuition is that a fixed-size representation is insufficient to express all critical features in both local and global. Local information will be lost after global information extraction process. Hence, we propose a hybrid representation aggregation layer to integrate local and global information via cross-attention. Cross-attention is similar to self-attention, the distinction is that Q and K, V are generated from different input. In our aggregation model, Q is generated by global representation and K, V are generated by local representation, the output of Transformer blocks.
A brief illustration of multi-head self-attention.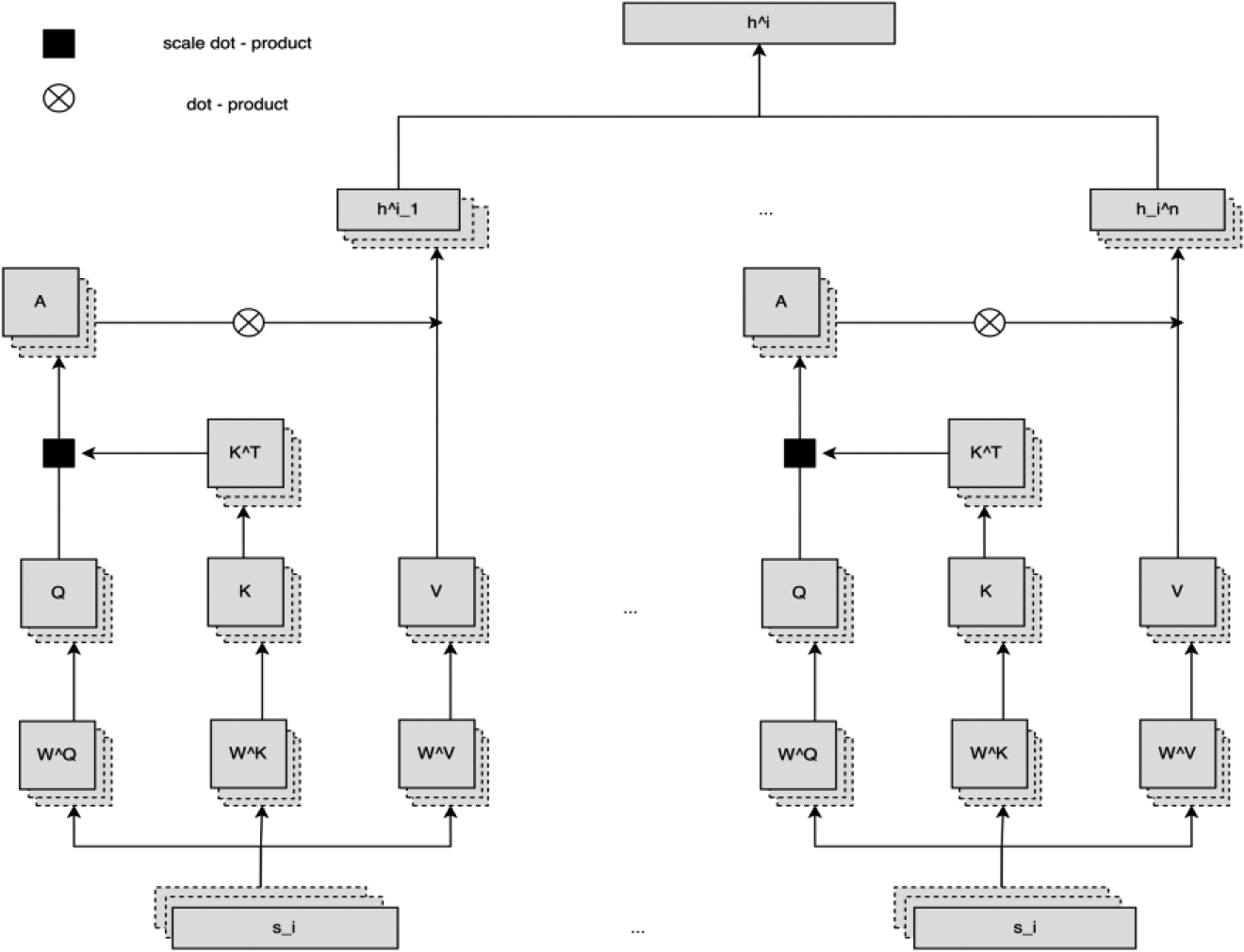
Transformer block structure.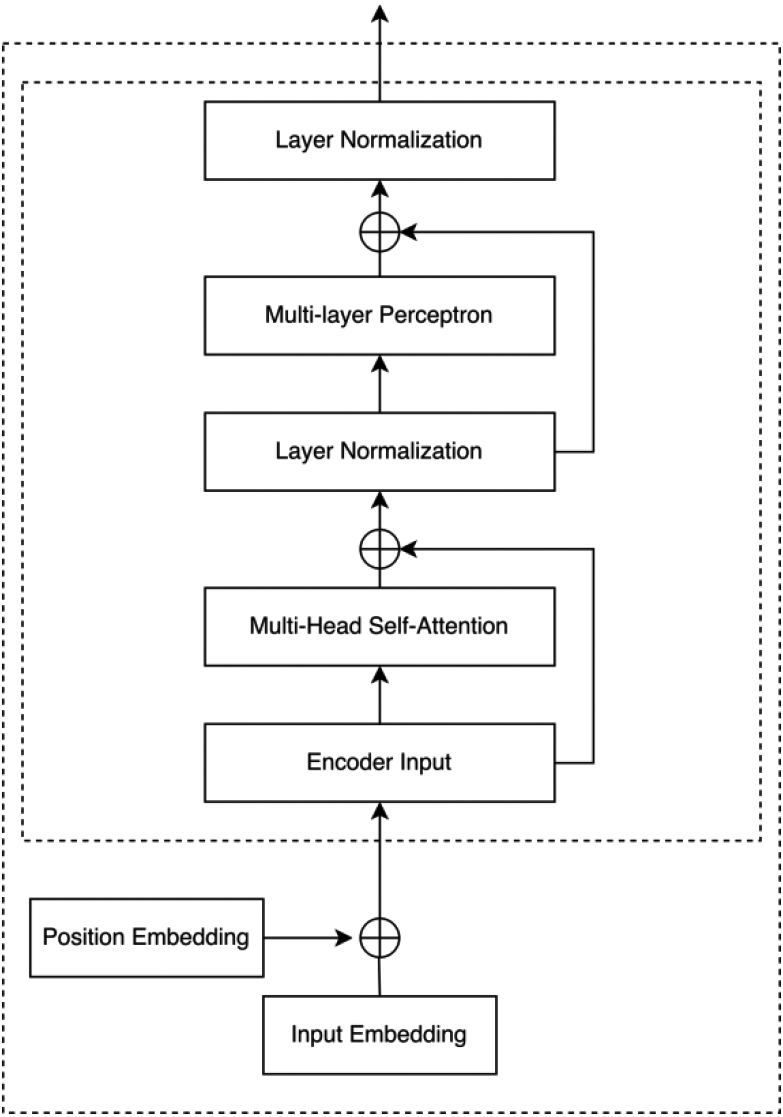
Datasets
It is almost impossible to collect sufficient and various of faults data from production environment. For the purpose of verifying the performance of our proposed method, a micro hydroelectric turbine units and some sensors were bought from the internet and equivalent test environment was established. The hardware parameters of test environment can be seen in Table 1 and the live situation of test environment is shown in Fig. 4. We simulated faults via the control units, five types of faults are our research objects, Genset Temperature Faults (GTF), Bearing Temperature Fault (BTF), Bearing Horizontal Vibration Amplitude Fault (BHVAF), Bearing Vertical Vibration Amplitude Fault (BVVAF) and Oil Pressure Fault (OPF). These states are closely related to the health state of the turbine. For example, the amplitude is a measure of whether the mechanical operation of the water wheel is normal. If the temperature is too high, it means whether the heat energy generated by the mechanical operation exceeds the normal value. Overheating will cause mechanical damage. In an experimental setting, we measured the state of turbine units every second and stored on the storage devices. A total of 5200 pieces of record were collected, all the results were generated through 5-fold cross validation in our experiments. These records are continuous floating-point type value data, the sampling rate is 8k, and the range of different data is different. The categorical distribution of collected data is shown in Fig. 4.
Implementation Details.
We evaluated the health state of water turbine units via multi-class classification task. We implement the submodels using Pytorch 1.8.0 and the models are jointly trained on our workstation (Ubuntu 18.04 LTS with four Intel Core i9 @3.60 GHz CPUs, four NVIDIA GeForce 3090 graphics cards, and 128-GB RAM, the version of CUDA is 11.0. Python version is 3.8). The parameters of the network are initialized by xavier initialization method, It employs an AdamW optimizer, which
Important parameters of our experimental equipment
Important parameters of our experimental equipment
The categorical distribution of collected data.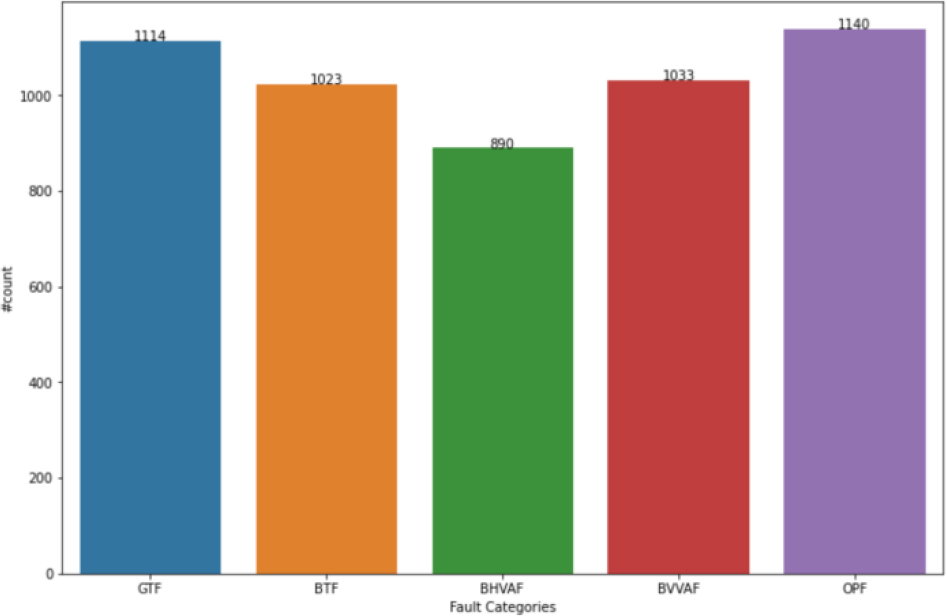
Experimental results
In order to further research the difference in performance between the proposed method and the traditional methods, a comparison experiment on 1D ResNet50, 1D ResNet50
Comparison results of algorithm
Experiment platform diagram.
Visualization of comparison results.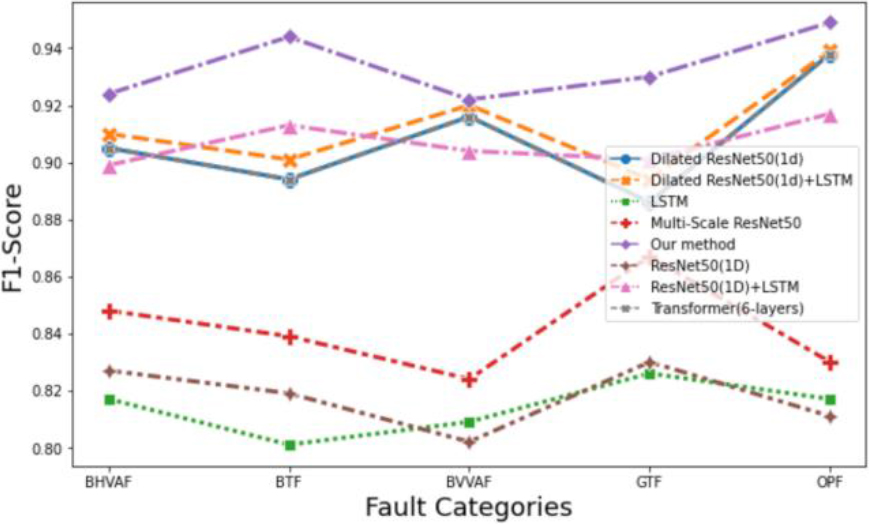
The training loss curve.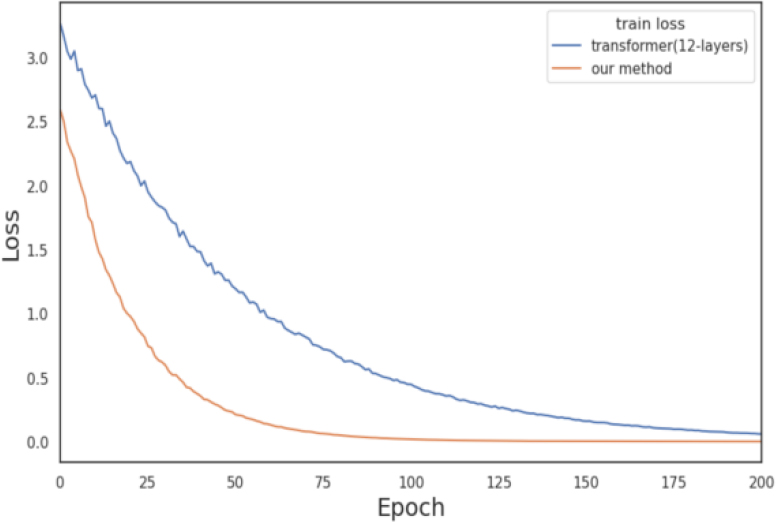
Ablation study
We first analyze the effect of number of dilated convolutional layers and the scale of dilated ratios, the results are reported in Table 3. It is observed that dilated convolutional operator is undoubtedly necessary to gain a notable boost relative to using traditional convolution, i.e., dilated ratio
Ablative testing for increasing number of layers (left) and different dilated ratio (right) of our method
Table 4 lists the results of different number of Transformer layers and different dimensions of Transformer input. From Table 4, we can see that Transformer can capture global information and be able to model the long-distance dependence based on the function of self-attention, what is the core components of Transformer. However, it usually requires stacking multiple Transformer layers to achieve it. At the same time, deeper networks require more data and more skills to update the parameters of network. That is why more Transformer layers is less effective. The reasons above can explain the effect of hidden size of Transformer input on the performance.
Comparison results of effect of the change of Transformer layers (left) and vector size of Transformer input (right)
The final ablative testing is the importance of our proposed information aggregation layer of local and global representation based on cross-attention. It can be observed from Table 5 that the information aggregation is necessary, it does improve the model performance and validates our inference of information loss, what is capturing the global information via self-attention, the details of local will be lost. For better performance, we can not ignore the local features. Utilizing the cross-attention to enhance the final representation by global representation adaptively looks for supportive information from local representation. We found that the performance is insignificant improvement with number of cross-attention layers increasing.
Results of with and without information aggregation layer
In the paper, A CNN and Transformer hybrid deep neural network is proposed to assess the state of health of water turbines based on multivariate long time series data. In order to verify the effectiveness of the method, an equivalent test environment was established. Through the analysis of fault experiments, it can be seen that the combine model of CNN and Transformer can effectively capture the local and global information. Meanwhile, local information will be lost after the global module working. Therefore, We proposed a representation aggregation layer to solve this problem. The results of experiments show that our propose method is advanced compared with the classical time series analysis method. While, the source of data used in this paper is narrow, we hope to verify the effectiveness in production environment. This will be the focus of our future work.