
Abstract
As an important part of automotive shock absorber, the columnar parts in automotive shock absorber will inevitably have machining defects during the process, which will not only degrade the performance of the parts, but also degrade or even fail the performance of the final shock absorber after assembly. Yolov5, as a target detection algorithm, has received much attention due to its high accuracy and fast operation speed. However, the algorithm faces some challenges when applied in a practical industrial environment. In this paper, improvement measures are proposed to address the limitations of sample collection and the high speed of pipeline recognition in industrial environments. The network model is optimized and designed. Firstly, the ASPP module is replaced by the SPP module thus improving the viewability throughout the process providing recognition accuracy. Secondly, the Conv and C3 layers of Yolov5s are replaced by Transformer to obtain higher recognition accuracy. By improving and optimizing the above methods, we can better cope with the improvement of detection accuracy under small sample conditions. Experiments show that the method can significantly improve the detection accuracy and operation speed of Yolov5s under the hardware condition of lower computing power, which is more suitable for industrial scenario application scenarios.
Introduction
The production process of columnar parts in automotive shock absorbers requires multiple machining processes. Due to the special structure of the cylindrical surface, the manual observation method was used in the previous quality inspection for the full-side quality inspection, which is slow and strongly influenced by subjective consciousness. Therefore, it is important to realize a high precision algorithm for detecting surface defects of columnar parts in automotive shock absorbers to improve the product surface quality. The research methods of computer vision technology for defect detection by domestic and foreign scholars are mainly divided into methods based on machine learning and methods based on deep learning.Machine learning-based methods are mainly based on artificial design to extract features [1]. Celik et al. proposed a simple detection system based on wavelet transform, grayscale co-generation matrix (GLCM) and feedforward neural network, but the method cannot locate the specific location of defects [2]; Querqing et al. proposed a Gabor filter optimization algorithm based on the evolution of composite difference for the problem of many parameters of traditional Gabor wavelet filter and poor real-time algorithm [4]. The detection speed of the optimized model is 11 fps, which is still lower than the requirement of real-time detection; Liu Yuan et al. proposed a surface defect image edge detection algorithm based on Sobel operator by combining bilateral filtering and Hilditch refinement algorithm. However, the algorithm is affected by the light environment and is sensitive to noise. The detection method based on machine learning is simple and easy to implement, but it is influenced by human extracted features and has poor adaptability and robustness [5]. Deep learning based methods are mainly divided into YOLO, SSD in the first stage and Faster-RCNN algorithm in the second stage. He et al. proposed a defect detection system based on Faster-RCNN, and the mAP value of the defect detection task on NEU/DET dataset was 82.3%, but the detection speed of this method is slow and not suitable for industrial scenario applications [6]. The mAP of the improved algorithm reaches 80% and the detection speed is maintained at 50 fps, but the model has a large number of parameters and is not easy to deploy [7]. The mAP is 78. 25% on the NEU-DET dataset, but the accuracy of this model is low [8]. There are many algorithms for surface defect detection, but the algorithms that meet the requirements of real-time detection still have problems of low accuracy and real-time performance [9]. The above studies are inadequate for small samples and high-speed detection. In this paper, we propose a network structure ATYolo based on YOLOv5, which firstly combines Transformer and YOLOv5 model to improve the recognition accuracy, and secondly introduces APPF module instead of SPP module to optimize the training and inference speed of the model [10]. This method has good performance in the task of detecting surface defects of parts and can further meet the industrial deployment requirements.
Introduction of Yolov5 algorithm
Yolov5 uses a single-stage detection-based approach that divides target detection into three stages: feature extraction, prediction, and post-processing. In the feature extraction stage, a lightweight convolutional neural network is used, which can quickly extract feature information from images. In the prediction stage, an Anchor-based method is used to predict the position and size of the target. In the post-processing stage, non-maximal suppression (NMS) is used to reject overlapping bounding boxes and retain the bounding box with the highest confidence. However, despite its high accuracy and fast running speed, Yolov5 still faces some challenges in practical applications. For example, when dealing with some complex scenes, the detection accuracy is low and the running speed is slow [11]. The different number of feature extraction modules and convolutional kernels for specific network locations are the main differences of the YOLOv5 model. The model size and the number of model parameters increased sequentially for the five versions. Later more complex models YOLOv7 were developed, YOLOv8 is not suitable for industrial scenario applications [12]. Since defect detection requires high performance in real time and lightweight, this study improves the design of the strip surface defect detection network based on YOLOv5s model by considering the accuracy, efficiency and size of the recognition model. The network structure is shown in Fig. 1.
Yolov5 model structure.
Optimization of the SPP module
SPP (Spatial Pyramid Pooling) is a feature processing method commonly used in the field of neural network computer vision, whose main function is to extract features from input images of different sizes and scales in a hierarchical manner, so that neural networks can classify and recognize features from different parts of the input image more effectively. The core idea of SPP is to divide the original image into multiple layers and generate a grid of corresponding sizes. Then, the feature vectors in each grid are subjected to a maximum pooling operation to obtain the output feature vectors with fixed dimensions. Finally, the vectors of each layer are stitched together to form a fixed-length feature vector as the input of the neural network. This method can not only handle input images of different sizes and scales, but also reduce the size of the input images without losing important information. the advantages of SPP are that it can effectively handle different sizes, scales, and input image position transformations, and it can reduce the computational effort while keeping the size of the input images constant before and after pooling [13]. However, the disadvantages are that there may be information loss and overfitting problems, and more computational resources are required when processing high-resolution input images. the SPP module can lead to a huge amount of computation when performing pooling operations because of the need to process subregions of different sizes. Especially when the number of sub-regions is large, the computation will be very large, which limits the speed of SPP module in industrial scenarios. the SPP structure is shown in Fig. 2.
SPP module structure diagram.
ASPP (Atrous Spatial Pyramid Pooling) is an improved SPP method that mainly solves the problem that SPP is computationally intensive when processing high resolution input images. It can increase the perceptual field without affecting the input image size by using a dilated convolution model instead of the traditional convolution operation [14]. The advantage of ASPP is that it can improve the classification accuracy of the model while using the same computational resources, and it can effectively handle the feature extraction task for high-resolution images. Compared with SPP, the advantages of ASPP are: ASPP can obtain richer perceptual field information. while SPP can only perform multi-scale pooling at some level of the input feature mapping, ASPP can provide information at various scales and has better adaptability for targets of different sizes. ASPP reduces the impact of scale variation on feature learning [15]. In SPP, features at different scales are processed by different pooling layers, while ASPP can compress features at different scales when feature extraction is performed by null convolution, reducing the error between features with different scales. This module adds a BN layer to incorporate depth-separable convolution, but the basic idea remains consistent relative to SPP. Convolutional kernels with different receptive fields are constructed by different null rates and used to obtain multi-scale object information.ASPP can effectively solve the over-fitting problem.
In summary, compared with SPP, ASPP can better cope with multi-scale image feature extraction tasks and can effectively reduce the occurrence of overfitting problems, which is of high practical value for neural networks in classification and recognition tasks. The structure of ASPP is shown in Fig. 3.
ASPP module structure diagram.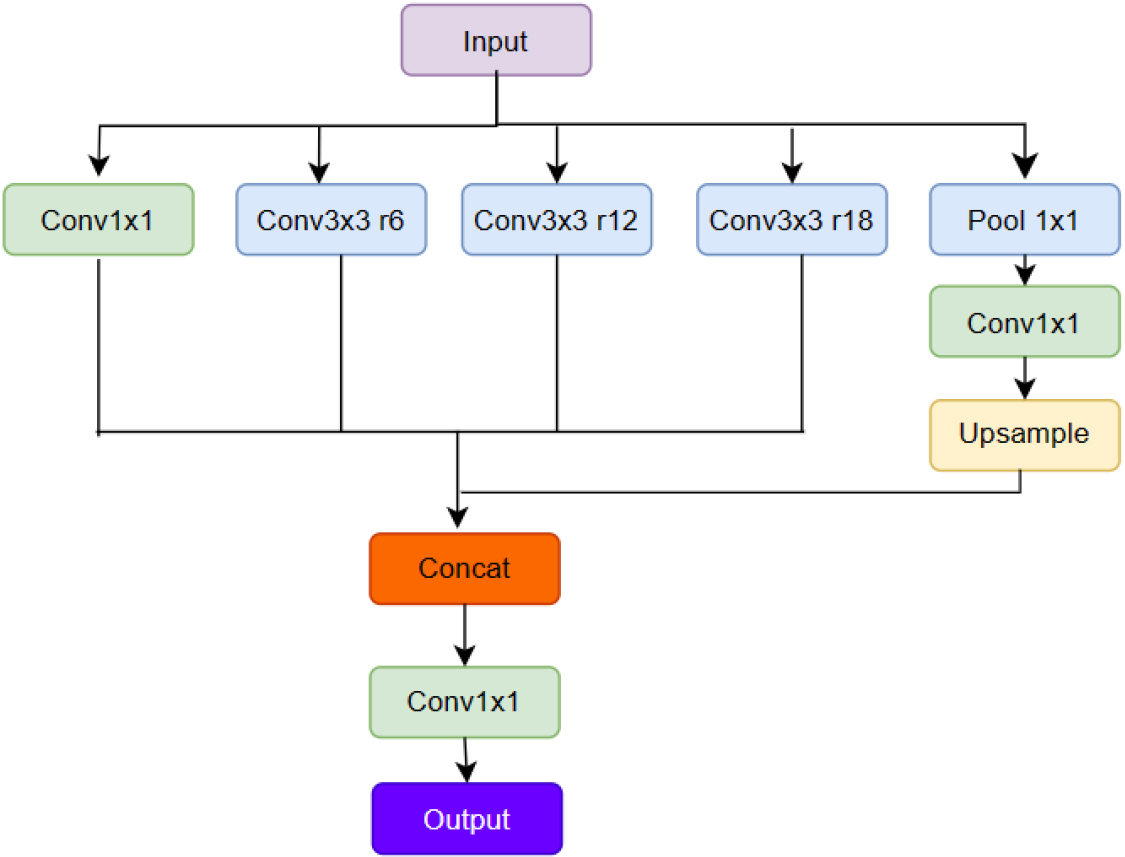
In YOLOv5, the convolutional layer is mainly used to build the skeleton network and extract features from the input image. C3 layer is implemented by combining the convolutional layer and the channel rearrangement module and is mainly used in the downsampling process of the YOLOv5 network. C3 layer can reduce the size of the feature map while retaining more feature information. In the C3 layer, the number of channels in the feature map is first reduced by 1
YOLOv5 backbone feature extraction network adopts C3 structure, which brings larger number of parameters, slower detection speed and limited application, and it is difficult to be applied in some real application scenarios such as mobile or embedded devices with such a large and complex model. Firstly, the model is too large and faces the problem of memory shortage, and secondly, these scenarios require low latency. Therefore, it is crucial to study small and efficient CNN models in these scenarios.YOLOv5 lacks the ability to model globally for convolutional neural networks, Transformer has the ability to obtain global information, which has been improved by introducing the multi-head attention mechanism earlier.
The Transformer model was firstly applied in Natural Language Processing (NLP), which mainly consists of Encoder and Decoder. ViT model firstly applied Transformer encoder module to computer vision. By combining Transformer with YOLOv5s, we introduce Transformer in the backbone network and replace some Convolutional blocks and C3 modules in the original YOLOv5s model with Transformer encoder modules. The Transformer encoder module is composed of a multi-head attention mechanism and a feedforward neural network (MLP). The specific structure is shown in Fig. 4. To begin with, the process starts by dividing the image into patches of a predetermined size. Each patch is then transformed into a one-dimensional vector by incorporating position encoding. This vector serves as the input to the Encoder module. A significant component of the Encoder module is the multi-head attention mechanism, which enables the simultaneous processing of multiple sets of input data. The self-attention mechanism plays a crucial role in computing the self-attentive feature output through dot product attention, as depicted in Eq. (1).
The architecture of transformer encoder.
ATYolo model structure.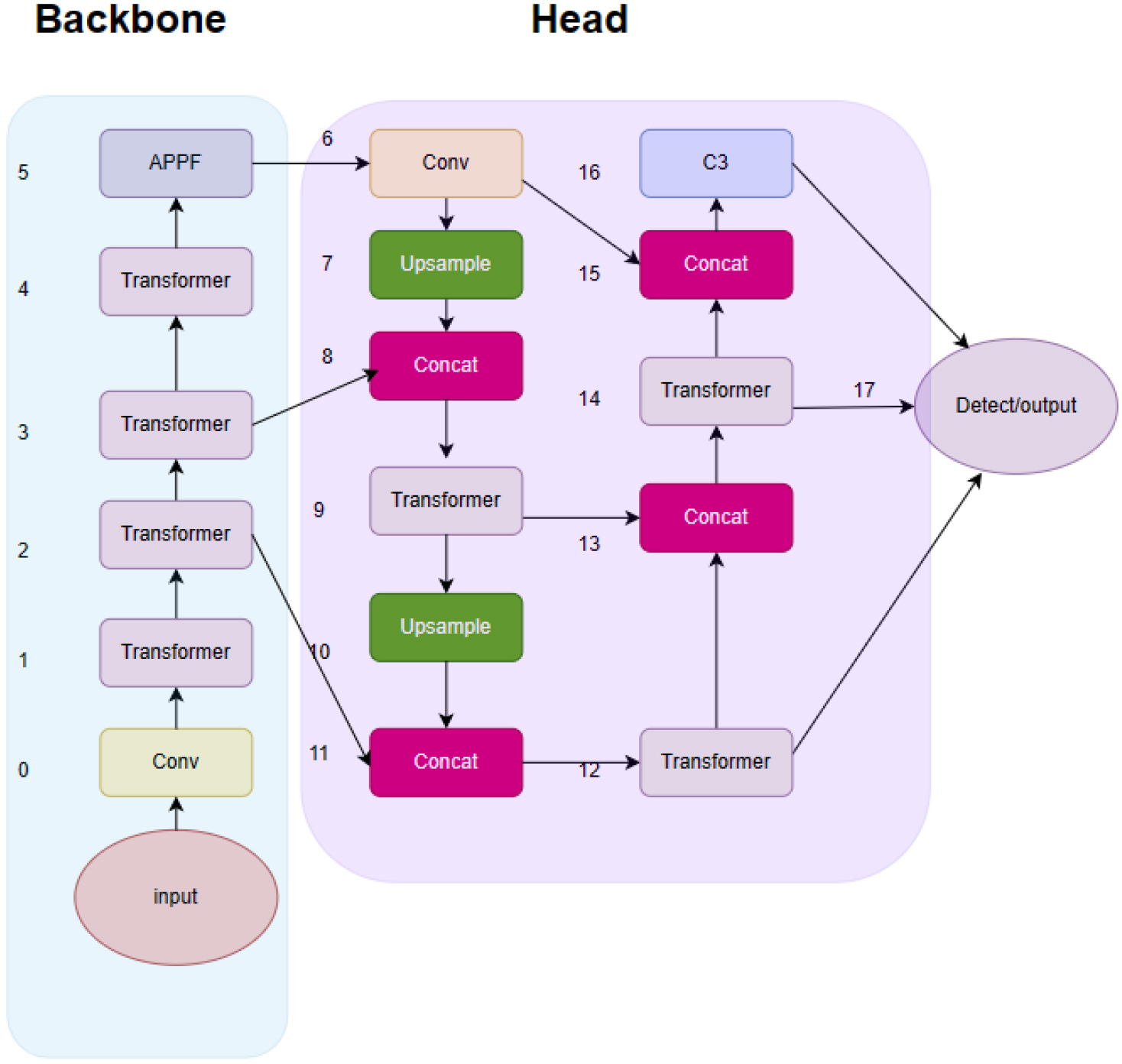
The correlation matrix of the vectors is generated by multiplying the transposed points of the query (
Live sampling chart.
Network model index mAP comparison.
After constructing the neural network model for surface detection of the finished part, the model training was started. Based on the training set of workpiece surface defects, the constructed neural network model and the yolov5s target detection model used for comparison experiments were trained separately, and then the trained models were tested using the test set. The hardware configuration used for this neural network model training is as follows: CPU: i7-10700/GPU: GTX3080/video memory: 10G/OS: Windows 10/ Python 3.8/ PyTorch. high-speed camera sampling is shown in Fig. 6. In this study, the Adam optimizer is used for training with an initial learning rate (Lr) of 0.001; the BatchSize is set to 16, i.e., 16 images are trained in one iteration with a training cycle of 300 rounds.
In this study, the effectiveness of the designed surface defect detection model was experimentally evaluated by comparing it with the yolov5s network model. The trained surface defect detection model was compared with the yolov5s network model that underwent similar training. The evaluation metrics, specifically the mean average precision (MAP) values, were statistically analyzed to assess the performance of the models. The results of this analysis are presented in Fig. 7, providing insights into the comparative performance of the two models.
The above figure shows that the neural network model designed for the detection of defects in ring workpieces has a certain improvement over the Yolov5s neural network model, with an increase of about 5.3% in MAP value.In this defect detection neural network, four image features are mainly detected in the collected images, which represent the painted workpiece (component), defective wound (SK), drive rod head (Top), and missed sprayed workpiece (blank), and the accuracy (precision) of these four image features are shown in Fig. 8.
Precision rate results display.
Figure 8 illustrates the changes in the accuracy rate with respect to the confidence level during the training process of both the designed network model and the yolov5 network model. The graph demonstrates that the accuracy rate of ATYolo, the designed network model, increases more smoothly with the progression of training iterations compared to Yolov5s. This indicates that ATYolo exhibits a more stable and consistent improvement in accuracy as the training proceeds, outperforming Yolov5s in terms of training efficiency and accuracy, and is slightly higher than Yolov5s. In the comparison, when the confidence level is greater than 0.5, the accuracy rate of ATYolo is two to three percentage points higher than that of Yolov5s. In the overall model, when the confidence level is greater than 0.5, the accuracy of the ATYolo model finally stays above 0.899 compared to 0.875 of Yolov5s, which is an increase. Also, our observation of Fig. 8 reveals that our SK convergence curves throughout in yolov5s show a lot of jumps etc. due to the smaller number of samples, however in the new network structure we find that a better smooth curve is obtained in ATYolo though with the same number of samples. It means that the network has a better generalization ability.
Among the target detection algorithms, Yolo has attracted much attention for its high accuracy and fast operation speed. However, when applied in industrial scenes, the algorithm faces the problem of low defect recognition rate due to the limited number of industrial scene samples. To solve these problems, two improvements are proposed to improve the network structure by replacing the SPP module with an ASPPF module to increase the size of the field of view. The high recognition rate of Transformer layer is also used to replace the original convolutional layer and C3 layer to improve the overall recognition capability. Experimental results show that the improvements proposed in this paper can significantly improve the detection accuracy of Yolov5 algorithm and make it more suitable for practical application scenarios. In subsequent experiments, we can try different Transformer layer depths to further optimize the impact on network recognition accuracy and computing speed. Meanwhile, readers can try to sample traditional image processing methods in a practical industrial environment to improve the quality of training images way to improve the recognition effect.
Footnotes
Acknowledgments
Supported by the Open Research Fund of Key Laboratory of Manufacturing and Automation, Xihua University (SZJJ2012-024).