
Abstract
Aiming at the problems of slow target detection speed and low accuracy caused by occlusion, illumination and complex background environment interference in wheat ear detection of natural environment, the paper proposes to improve the network model based on YOLOv5s algorithm model to achieve fast and efficient target detection. The first improvement point is to add the attention mechanism. In the backbone and head parts, the CBAM attention mechanism module is added to reduce the interference of non-critical information, extract the key feature information of the image, and improve the detection accuracy. The second improvement point is to combine the lightweight network MobileNetV3 for target detection, using channel separable convolution and SE channel attention mechanism to improve the accuracy of target detection. The Shangmai 5226 as the research object, the optimized wheat ear database was built, and the training images were labeled and converted into yolo format. Under the operating environment of Pytorch, the improved YOLOv5s model was used to extract the image features of Shangmai 5226 series wheat ears with iteration of 300 times. The result was shown that compared with the single structure YOLOv5s model, the accuracy of the improved comprehensive network model is improved by 0.7 %, mAP reaches 91.1 %, which is increased by 1.3 %, and Fps reaches 25.821, which is increased by 5.7 %. The improved network model can effectively improve the speed and accuracy of wheat ear detection, improve the effect of wheat ear detection, and provide technical support for the development of agricultural automation and intelligent agriculture.
Introduction
Wheat is one of the three major grains in the world, and it is also the most widely distributed crop. The global wheat planting area is about 250 million hectares,1,2 and China is about 24 million hectares, with a yield of about 130 million tons. China is also the world‘s highest total wheat production and the largest wheat consumption group. Due to the huge population, environmental damage, climate deterioration, arable land shortage and other reasons, wheat production cannot meet their own needs, and wheat yield prediction plays a vital role in product production and food security. Spike detection per unit area is the focus of wheat yield prediction. Because of the different growth environment of wheat, the grain size, color and sparse degree of wheat ear are different, which brings great difficulties to the prediction of wheat yield. 3 Early manual estimation of wheat yield wastes human resources and has low accuracy.
In the early stage of the development of target detection, the traditional methods of wheat ear detection mainly uses image processing to extract the shape, texture, color and other characteristics of wheat ear from RGB images, and then construct the model with the classifier to realize the automatic recognition and counting of wheat ears. With the application of artificial intelligence technology in target detection, the efficient feature extraction ability of convolutional neural network for wheat ears is used to realize the accurate detection and counting of wheat through a large number of training models, so as to the purpose of predicting the total yield of wheat. Bao et al. 3 designed a lightweight convolutional neural network (CNN) model called SimpleNet for the automatic identification of wheat ear diseases (2021). The proposed SimpleNet model achieved an identification accuracy of 94.1% on the test data set, which is higher than that of classic CNN models. Su et al. 4 proposed a new method for mask region convolutional neural network (Mask-RCNN) allowed for reliable identification of the symptom location and the disease severity of wheat spikes (2021). The feature pyramid network (FPN) based on ResNet-101 network was used as the backbone of Mask-RCNN for constructing the feature pyramid and extracting features.
Fernandez-Gallego et al. 5 proposed an automatic wheat ears counting method based on color digital images to estimate the density of wheat spikes in the field under natural light conditions (2018). The algorithm uses Laplace frequency filter, median filter and maximum segmentation method to process the wheat ears of the image of the data set, and the accuracy rate reaches 90 %. Hao et al. 6 proposed a detection method based on YOLOv3 model (2021). This model excavates the complementary information between multi-scale features and effectively detects wheat ears of different sizes. According to the experiment, YOLOv3 was tested on common wheat varieties, and the average accuracy mAP was 67.81 %, and the accuracy of wheat ear counting was 93 %. To alleviate the bottleneck of data collection in wheat breeding, Khaki et al. 7 highlighted a new deep learning method for accurately calculating the number of wheat spikes in order to facilitate the collection of real-time data required for detection (2021). This model is WheatNet, which uses the truncated MobileNetV2 as the main function extractor, which combines the graphs of different proportions of functions to cope with the change of image proportion. Then, the extracted multi-scale features are sent to two parallel sub-networks, which can perform density-based counting and localization tasks simultaneously. Gong et al. 8 proposed a wheat ear detection method based on YOLOv4-based deep neural network (2021). By adding a two-space pyramid pool (SPP) network to enhance the backbone of the basic network, it is used to improve the accuracy and speed of wheat ear detection.
In summary, some achievements have been made in the research on wheat ear detection in recent years. The traditional feature extraction + classification training is used to improve the accuracy of wheat ear detection, but the detection speed is slow.9–12 The single target detection algorithm improves the detection speed and the detection accuracy is low.13–16 There are few studies on efficient wheat ear detection in wheat ear occlusion and complex environment background. Based on the target detection algorithm of YOLOv5, this paper proposes to add attention mechanism, add CBAM module in the backbone and head parts, and combine the lightweight network MobileNetV3 to construct a new network model to improve the speed and accuracy of wheat ear detection in complex environment background.
Materials and methods
Materials
Dataset
The series of Shangmai 5226 as the research object, the wheat ears were all from the experimental field of Shangluo University in Shangluo City, Shaanxi Province (109.93E, 33.87N). The device for collecting images is a drone. The model of the drone is DJI macvic nimi. The camera parameters are resolution of 4000 × 2250, focal length of 5 mm, and exposure time of 1/400 s. In the process of image acquisition, the different growth periods, light conditions and acquisition conditions of wheat were considered. The occlusion between wheat ears, the images of no occlusion, and complex background were collected to ensure the comprehensiveness and robustness of image acquisition. A total of 3190 images were collected of the wheat ears dataset. Some of the sample images are shown in Figure 1. Wheat image dataset.
Dataset partitioning
The dataset was trained byYOLOv5s .The minimum circumscribed rectangle is used to label the wheat ear with manually frame 3000 images. The dataset is divided into a training set (2552), a verification set (319), and a test set (319) according to the ratio of 8:1:1 to train the model and test. It includes three different growth cycles of wheat heading stage, filling stage and maturity stage. The image data set Voc format is converted into YOLO format for YOLO training model. The visualization results of data set analysis are shown in Figure 2. According to the number of labels and the size distribution of objects, it can be seen that there are more small targets and medium targets, and less large targets. The distribution of sample characteristics conforms to the improvement idea of wheat detection model. In the training process, the Mosaic data enhancement method is introduced for image enhancement to enrich the dataset. The method can randomly read four images of training sets in each epoch, randomly arrange, randomly scale, randomly cut and then splice together. The random arrangement increases the number of wheat ears, which not only improves the number and quality of samples, but also speeds up the convergence of the model and enhances the detection effect of the grid on wheat ears. Figure 3 is the image enhancement effect of Mosaic data. Label width and height distribution. Mosaic data enhancement.

Methods
YOLOv5 network
Comparison of parameters of each version of YOLOv5 algorithm.
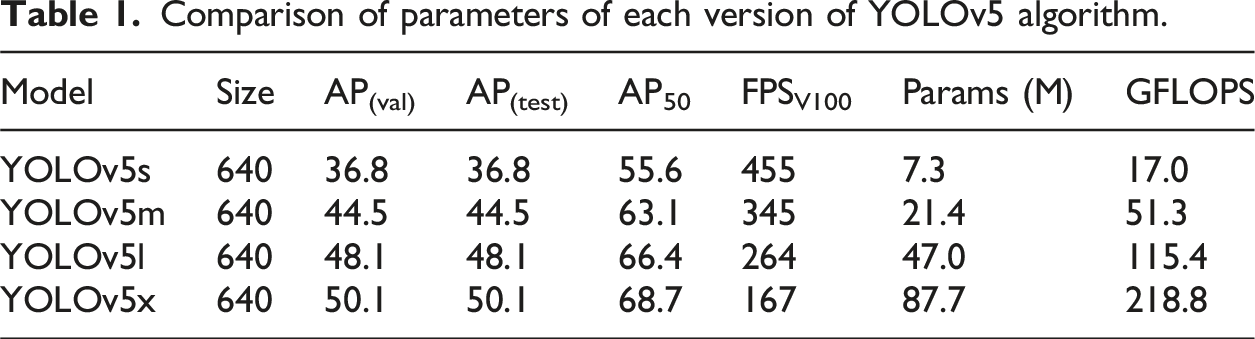
It is mainly composed of four structures with YOLOv5s: input terminal, backbone network, neck network and prediction layer. Figure 4 is the neural network structure diagram of YOLOv5s. (1) Input: The method of Mosaic data enhancement is used for online data enhancement. In each epoch, four images in the training set are randomly read for splicing, scaling, translation, rotation, random clipping and splicing together, and color transformation is performed to increase the role of information expression. The random arrangement increases the number of wheat ears and enriches the sample set information. (2) Backbone network: YOLOv5 uses CSPDarknet53 or ResNet backbone network, which is mainly composed of Focus, C3 and SPP (Spatial Pyramid Pooling) networks. It is mainly responsible for the feature extraction of the input image. The Focus module reduces the height and width of the input image to half of the original by slicing the input feature map, C3 is a residual structure, which allows the model to learn more features. The SPP module can extract features from many aspects and improve the accuracy of the model. (3) Neck: The neck network is used to fuse the feature information of each level of the network, and the feature information of the image can be obtained to avoid disappearance. The neck network uses feature pyramid networks (FPN) structure and path aggregation network (PAN) structure to enhance features. FPN can fuse the sampled deep feature map with the shallow feature map, and predict each layer feature map. PAN can fuse the shallow feature map and the deep feature map after sampling. (4) Prediction: The prediction layer applies the features extracted by the network to infer the probability and location information of the predicted target category, obtain the output information of the network. It was performed the final regression prediction in the prediction layer. The neural network structure diagram of YOLOv5s.
Experimental platform
Computer parameters and environment configuration.

Model evaluation indexes
After the model trained, the effect of the model must be evaluated, and the parameters of the model should be optimized according to the evaluation results to achieve the expected results. In this paper, multiple indexes are used to evaluate the model of wheat ear detection. Such as: precision rate P (precision, recall rate R (recall), mean average precision (mAP), confusion matrix, model size and detection speed (FPS). The intersection over union (IOU), IOU-LOSS box_loss, obj_oss and cls_loss were used to evaluate the accuracy.
19
The calculation formulas of accuracy, precision and recall rate are expressed as (1), (2), (3), and (4). Precision represents the proportion of correct judgment in the samples judged by the algorithm as wheat ears; Recall indicates that in all wheat ear samples, the algorithm is judged to be the proportion of wheat ears, corresponding to the missed detection rate. F1-Score is the harmonic average evaluation index of Precision and Recall. When one of the values of Precision and Recall of the network is greatly improved, the probability of another value will decrease. A high-performance network hopes that the false detection rate is low and the missed detection rate is also low. F1-Score can well measure the balance between them. AP is the accuracy of a single category in target detection. The value is equal to the area enclosed by the P (R) curve on the coordinate axis. Precision is the ordinate and Recall is the abscissa. The mAP is the average AP value of all categories in the target detection. The wheat spike data set in this paper has only one category, and the value of mAP is equal to AP.



Construction of wheat ear model based on improved YOLOv5s
Improvements are made in two aspects: (1) Adding CBAM attention mechanism (2) Combined with lightweight network MobileNetV3
Adding CBAM attention mechanism
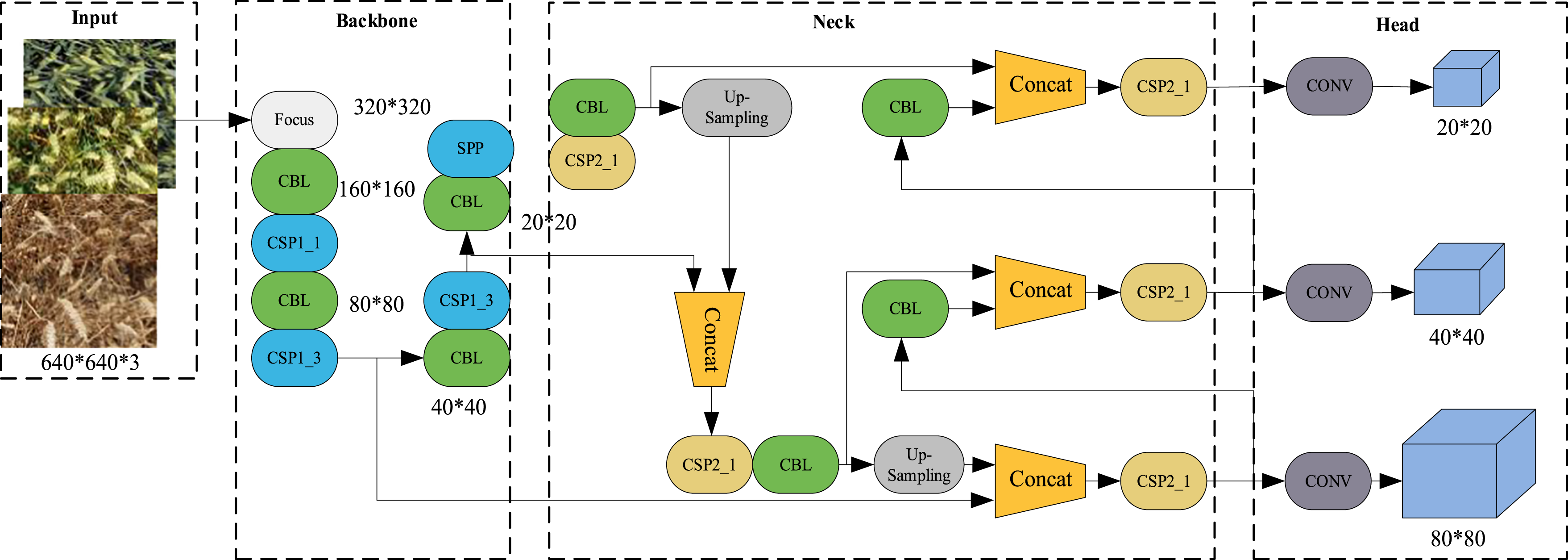
In deep learning, the attention mechanism can make the model pay more attention to the core part and reduce the attention to the non-core part, so as to improve the detection ability of wheat ear and improve the accuracy. As shown in Figure 5, the added attention mechanism is the CBAM module. It is added to the backbone and head parts of the YOLOv5 s neural network respectively. Adding the CBAM attention mechanism can reduce the interference of non-critical information and extract the key feature information of the feature map, which improves the detection accuracy. The CBAM attention strengthens both spatial dimension features and channel dimension features. The neural network structure diagram after adding the attention mechanism.
The CBAM (Convolutional Block Attention Module) module is an efficient attention module that acts on feedforward convolutional neural networks. It can be divided into two parts, spatial attention and channel attention. The output result of the original network convolution layer is first passed through a channel attention module, and then the weighted result is input into the spatial attention module to obtain the final weighted result. The input feature map is input into a multi-layer perceptron (MLP) after maximum pooling and average pooling, and then the output feature is weighted and summed and input into the sigmoid activation function to obtain the normalized channel attention weight. Finally, this weight channel is added to the feature map one by one, and finally the re-calibration of the input feature map by channel attention is completed. As shown in Figure 6, it is the internal structure of the channel attention module. The internal structure of the channel attention module.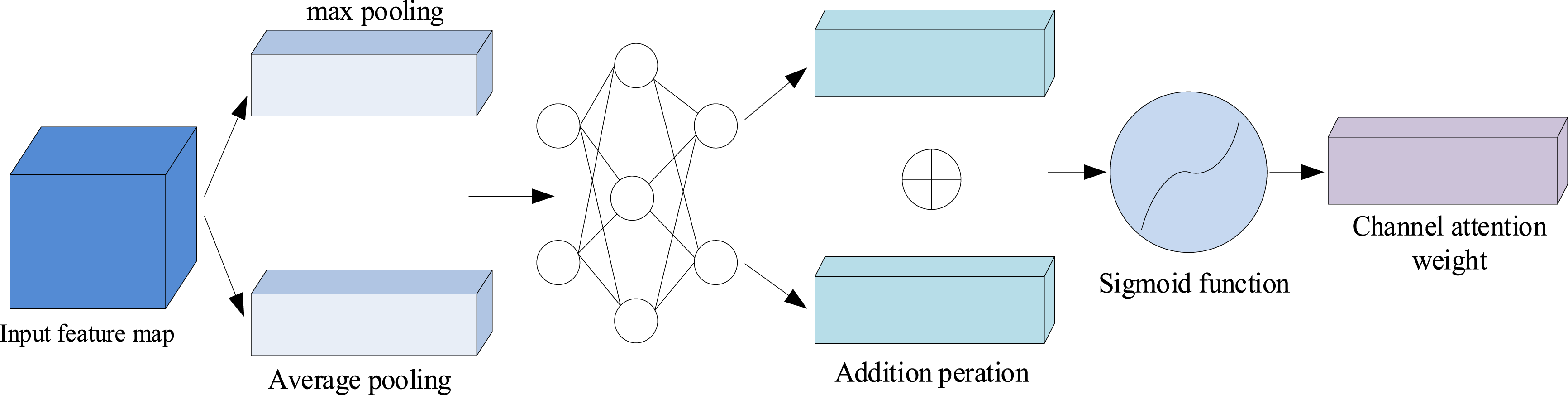
The channel attention is expressed as: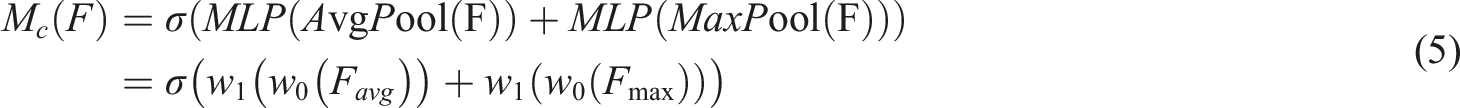
Combined with the lightweight network MobileNetV3
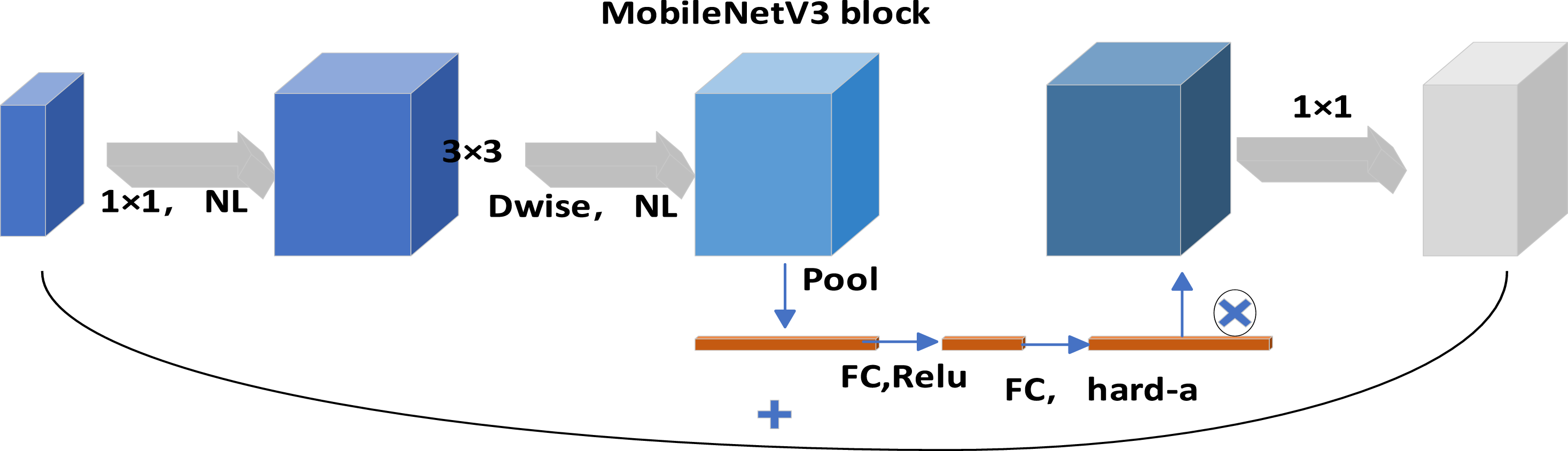
MobileNetV3 is a leader in lightweight networks. Compared with heavyweight networks, lightweight networks have the characteristics of small computation, few parameters, and short inference time. MobileNet is currently composed of three generations. MobileNetV3 is the accumulation of the first two generations of V1 and V2, and the effect of speed and performance is more significant. It uses the NetAdapt algorithm to obtain the optimal number of convolution kernels and channels. At the same time, MobileNetV3 not only has the deep separable convolution of MobileNetV1, but also inherits the residual structure of the linear bottleneck of MobileNetV2. On this basis, the SE channel attention mechanism is introduced. MobileNetV3 uses a new activation function called h-swish (x) to replace the original Relu6, and uses Relu6 (x + 3)/6 to approximately replace the sigmoid of the SE module. Finally, the output head part of the V2 backend is modified. As shown in Figure 7, it is the overall structure of the MobileNet network. FC represents full connection operation. Bneck is the basic structure of the network and the core module of MobileNetV3 network. It has channel separable convolution, SE channel attention mechanism and residual connection. Figure 8 shows the structure of bneck in MobileNetV3 module. The diagram of MobileNetV3 network structural. The diagram of bneck structural.
The implementation of YOLOv5s-CBAM wheat ear detection algorithm
Detection results of wheat ears
The model detection uses 112 unlabeled images with the trained model. It can view the wheat spike map with labels and accuracy as Figure 9(a)–(d) in different situations. Figure 9(a) and (c) are the graphs with labels detected by the YOLOv5s model, and Figure 9(b) and (d) are the wheat ear head detection graphs of the improved YOLOv5s model. It can be seen that the YOLOv5s algorithm can achieve accurate detection of wheat ears, no matter what type of wheat ears. Comparing the detection results of the original YOLOv5s and the improved YOLOv5s model, it can be seen that the improved YOLOv5 detection has higher accuracy. Detection results of wheat ears. (a) YOLOv5s test results, (b) YOLOv5s-CBAM test results, (c) YOLOv5s test results, (d) YOLOv5s-CBAM test results.
Detection results of YOLOv5s + MobileNetV3 module
It selected two different object detection models for comparison: YOLOv5s and YOLOv5s + mobileVit3. At the same time, we also selected four different neck layer outputs, namely 160 × 160 features for XSmall objects 80x80 features for Small objects, 40 × 40 features for middle objects, and 160 × 160 features for large objects. The detection results of YOLOv5s + MobileNetV3 module are shown in Figure 10. It can be seen that compared to the comparison model, the detection results of YOLOv5s + MobileNetV3 modulewere more accurate than YOLOv5s. Detection results of YOLOv5s + MobileNetV3 module.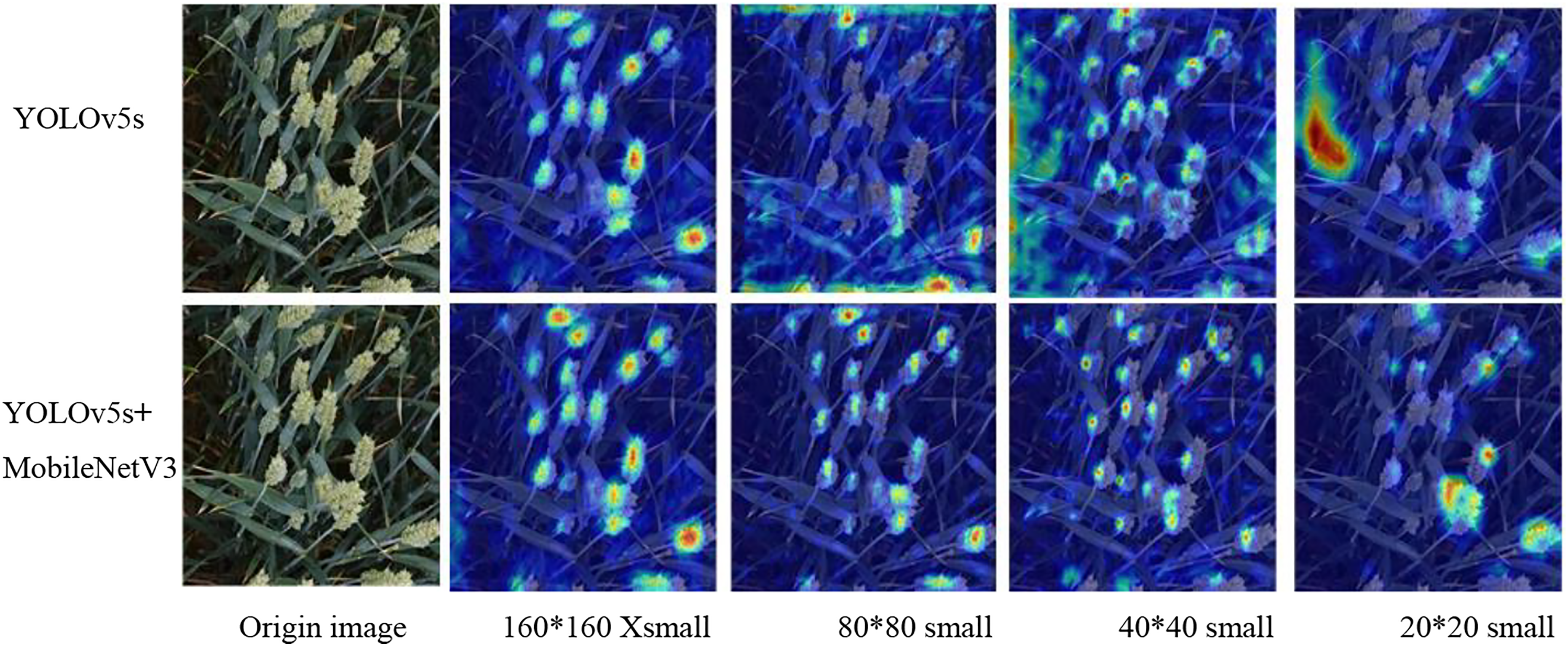
Analysis of model training results
The training results of the wheat ear head of the YOLOv5s algorithm are shown in Figure 11. The training results of wheat ear head by YOLOv5s algorithm.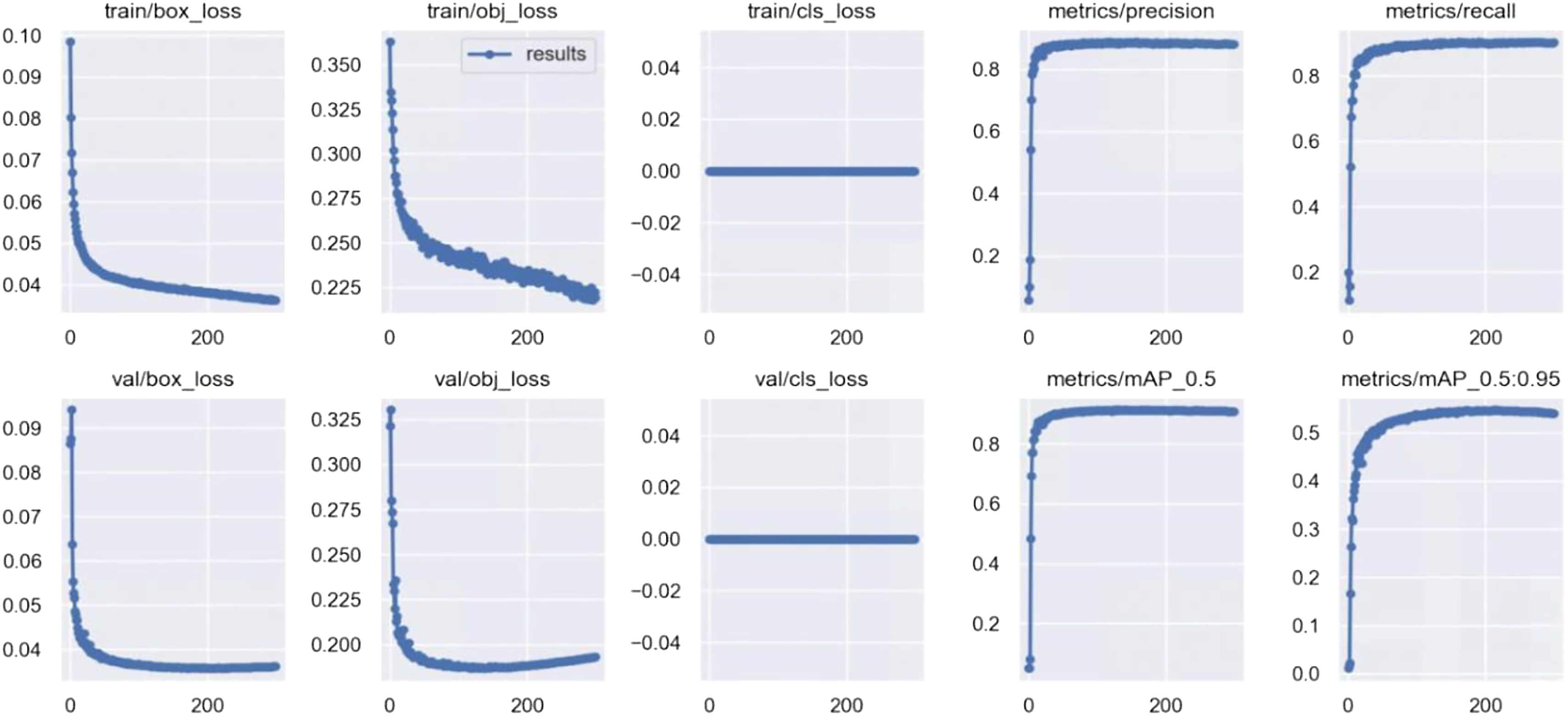
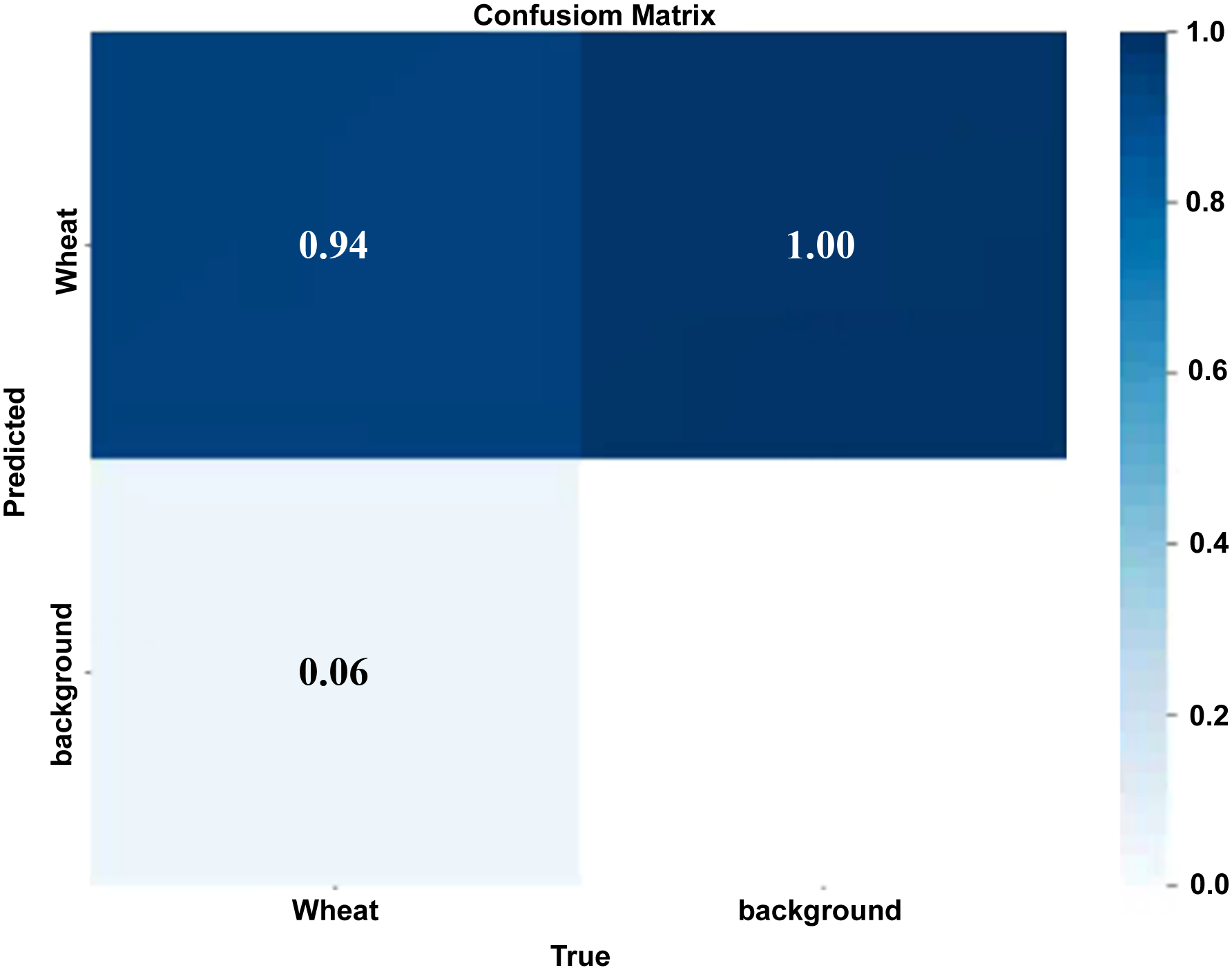
Box_loss tends to be 0.04, obj_loss tends to be around 0.2. Cls-loss is always 0 because of only one type of research object. Recall and precision are both about 0.9, and the two synthesis index mAP exceeds 0.9. The smaller the loss function value, the higher the coincidence rate between the prediction frame and the real frame, and the higher the accuracy. (1) Confusion matrix: As a specific two-dimensional matrix, the row represents the actual category, and the column represents the predicted category. The diagonal value of the matrix represents the probability of correct prediction, and the higher the diagonal value of the confusion matrix, the better. As shown in Figure 11, it is training for wheat ear detection.
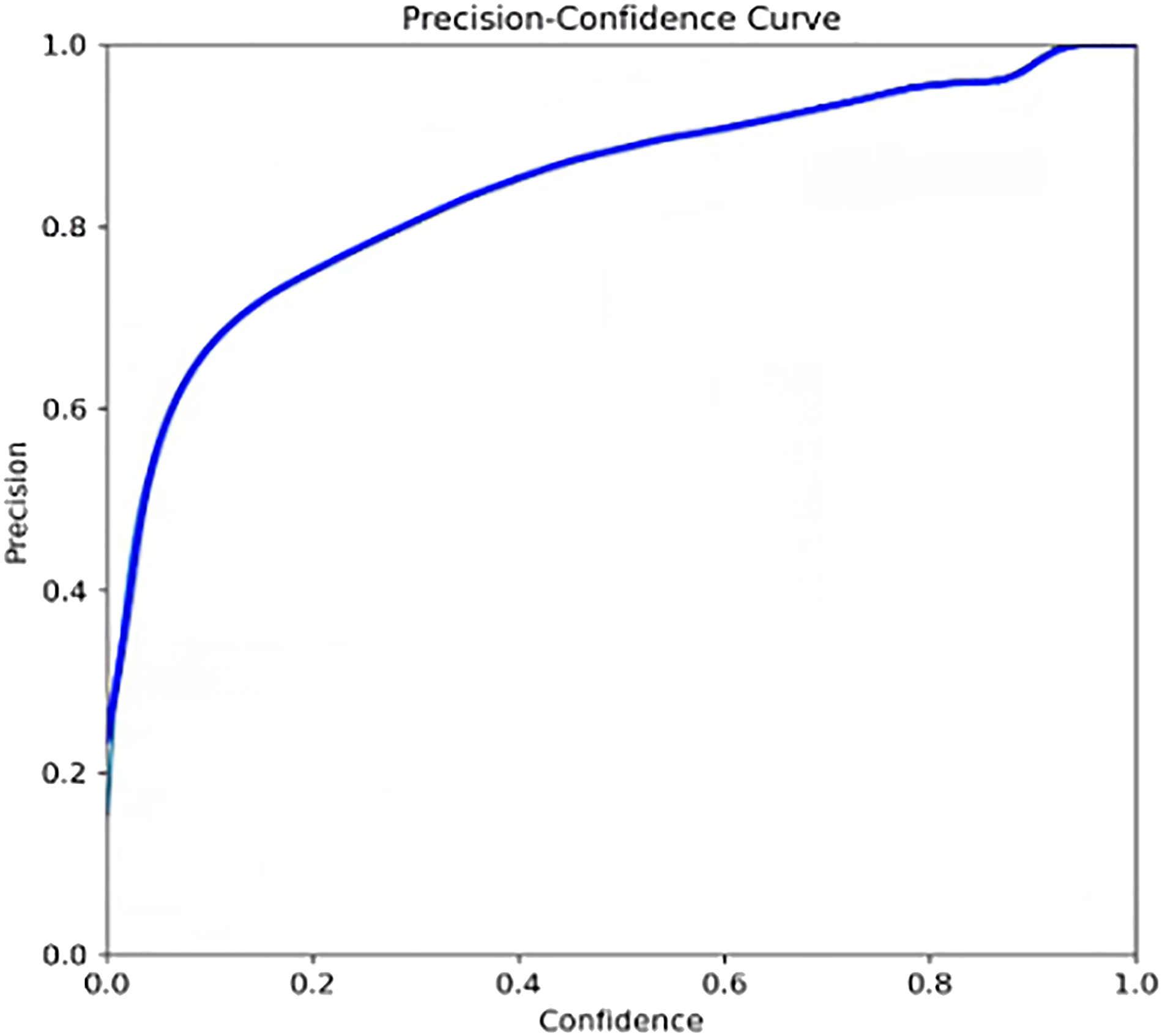
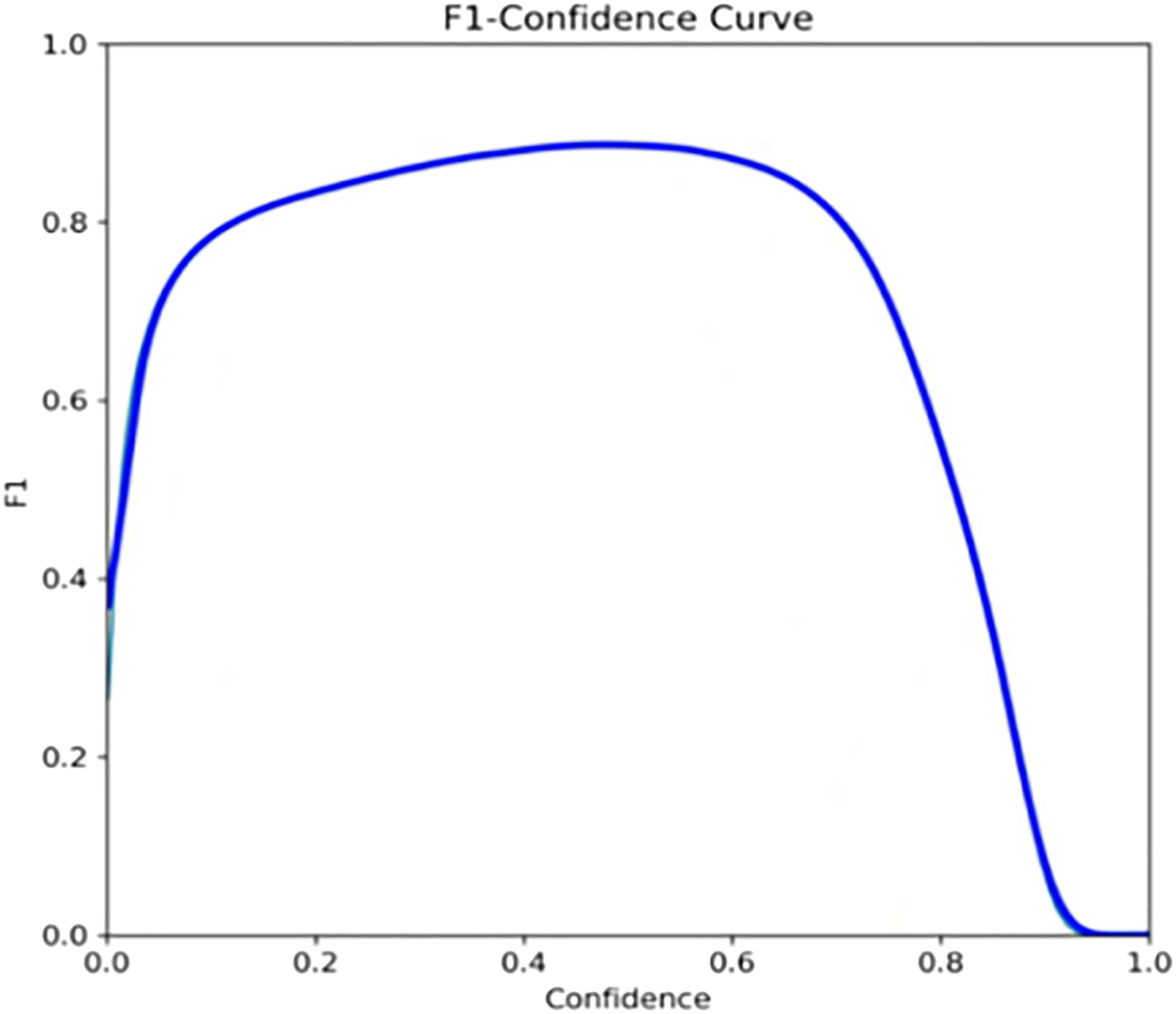
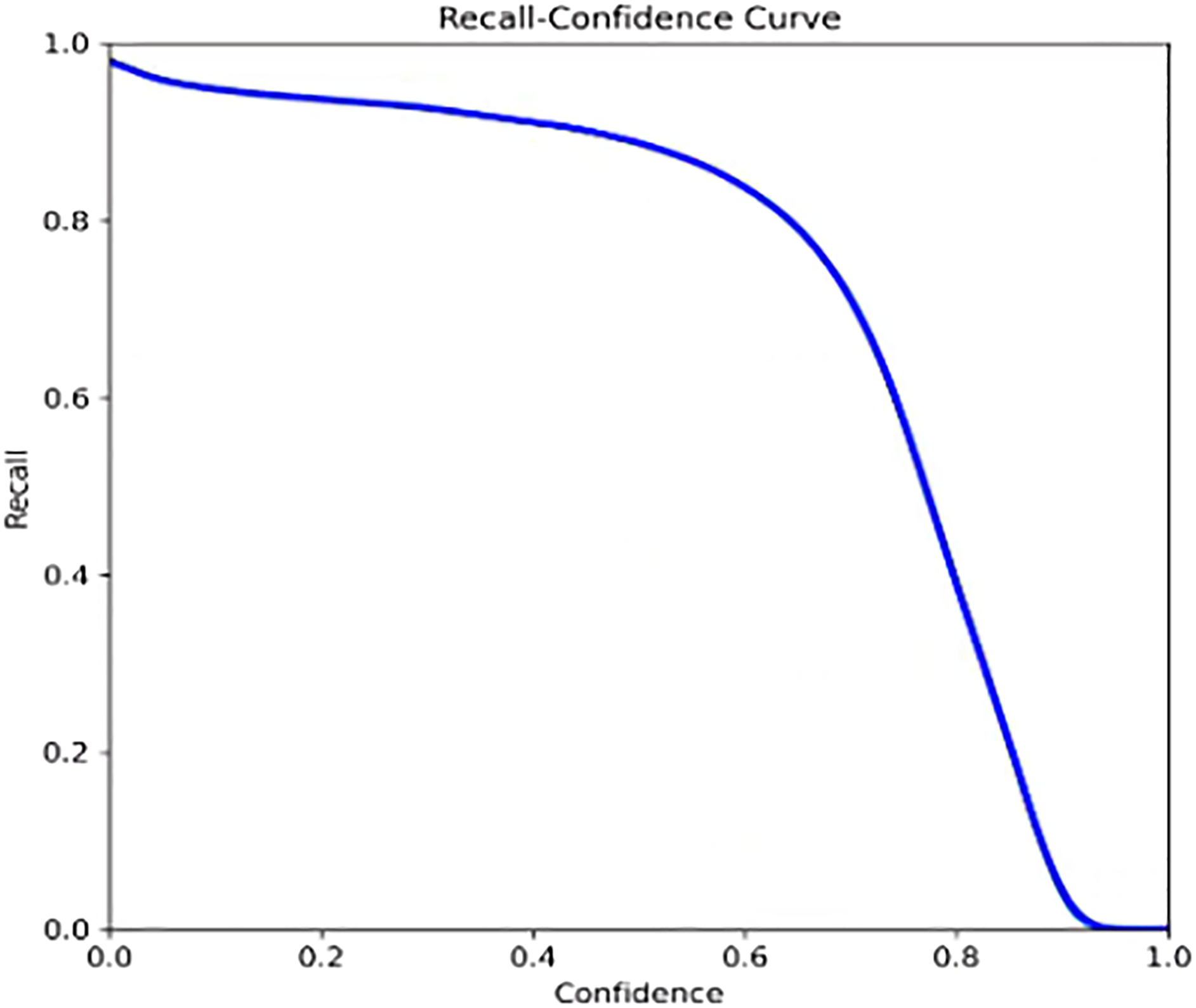
From the diagram, there are only two parts in this diagram, of wheat spike and background. Normalization is performed in each column. It can be seen from the graph that the probability of correct prediction of wheat ear detection is 0.94, and the probability is higher (Figure 12). (2) F1_curve: The relationship between F1 score and Confidence. As shown in Figure 13, F1 score is a measure of classification. It is a harmonic average function of precision and recall rate. The expression of F1 and precision and recall rate is between 0 and 1. The greater the value, the better the effect. (3) P_curve: represents the relationship between confidence and accuracy. The abscissa represents the confidence, and the ordinate represents the accuracy. As shown in Figure 14, the higher the confidence, the higher the accuracy. (4) R_curve: represents the relationship between confidence and recall rate. As shown in Figure 15, the abscissa represents the confidence and the ordinate represents the recall rate. Confusion matrix. F1_curve. P_curve. R_curve.

Comparison of different target detection models
Model performance comparison.
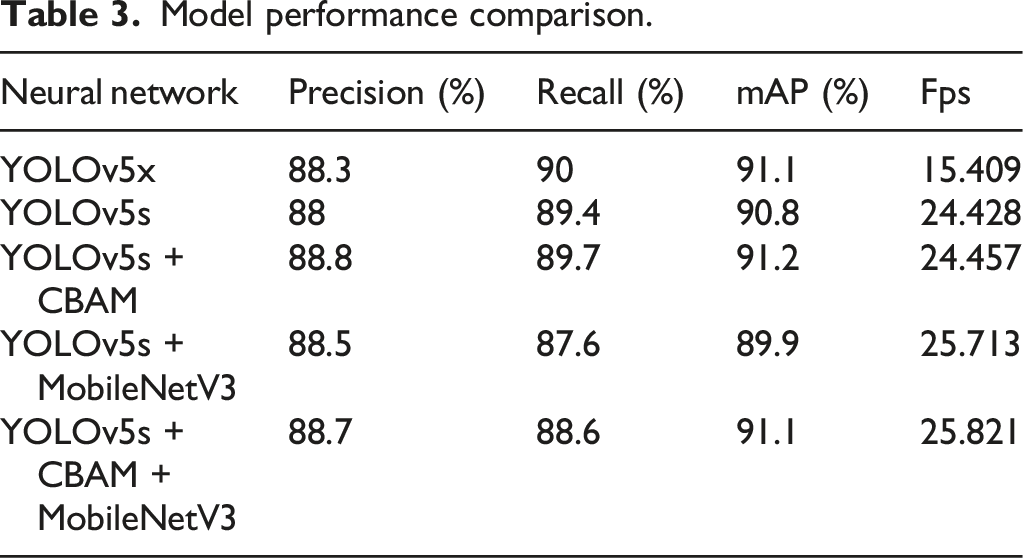
After adding the CBAM attention mechanism, the mAP of the YOLOv5s + CBAM model is 0.4% higher than the YOLOv5s, and the Fps is increased by 0.1%. The overall effect is better than the original. After combining the lightweight network MobileNetV3, although mAP is reduced by 0.9%, Fps has been significantly improved, which is 5.2% higher than the original, and the overall effect is better than the original YOLOv5s.
As shown in Figure 16, in order to improve the training results of the YOLOv5 s algorithm for wheat spikes. When the number of training rounds is close to 250, P, R and mMAP tend to be stable. After 300 rounds of training, the precision rate P is 88.6%, the recall rate R is 89.8%, the mAP@0.5 is 91.2%, and the mAP@0.5: 0.95 is 54%. The higher the value of precision rate and recall rate, the better. The training results of improved YOLOv5 s algorithm for wheat spike head training.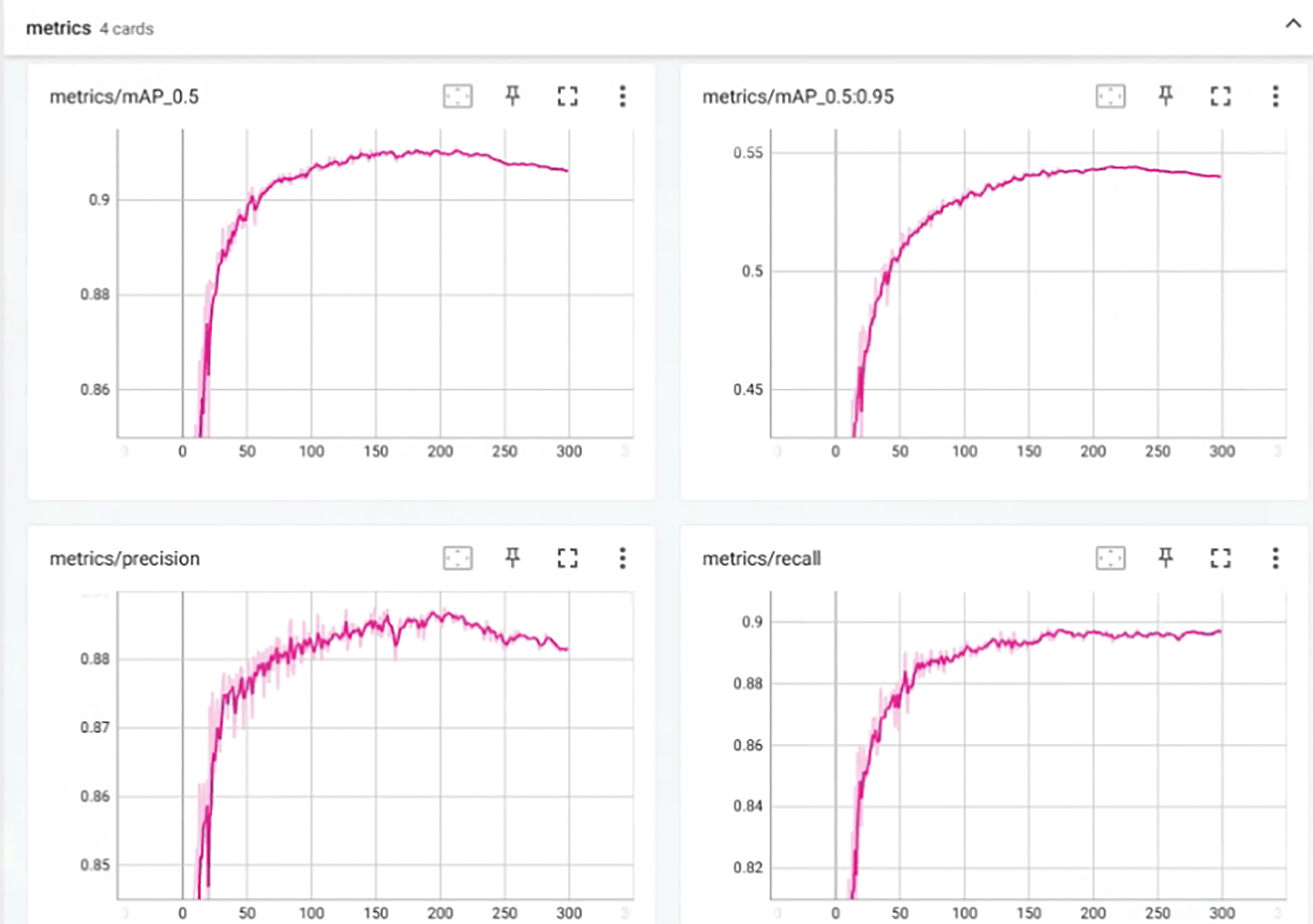
The YOLOv5x model is the best model when the number of training rounds reaches 104, and the positioning loss value is about 0.035. The confidence loss value is about 0.18; after 200 rounds of training, the accuracy rate P was 88.3%, the recall rate R was 90%, mAP@0.5 was 91.1%, and mAP @0.5:0.95 was 55.2%.
Conclusions
The Shangmai 5226 as the research object, building a wheat dataset, enriching the quantity and quality of the dataset through data enhancement, it proposes two improvements to the wheat ear detection model base on YOLOv5s. The CBAM module is added to the Backbone and head parts of the network structure of YOLOv5s, the mAP is increased by 0.4%, and the fps is basically unchanged. The attention mechanism can make the model pay more attention to the core part, thereby improving the detection ability of wheat spikes, thereby improving the accuracy. The lightweight network MobileNetV3 has the characteristics of small amount of calculation, few parameters and short reasoning time. The model improvement of the lightweight network is added. On the basis of basically unchanged mAP, fps is increased by 5.3%, and the performance of the model is better. Some lightweight network optimization models are added to improve the index parameters and achieve fast and efficient target detection.
Footnotes
Acknowledgements
Thanks for the project support of Shaanxi Provincial Science and Technology Department Science and Technology Plan Project (Grant No. 2023-JC-QN-0661), Shaanxi Provincial Department of Education Science and Technology Plan Project (Grant No. 22JK0360), and the scientific research and innovation team of Shangluo University (Grant No. 19SXC03).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Shaanxi Provincial Science and Technology Department Science and Technology Plan Project (Grant No. 2023-JC-QN-0661), Shaanxi Provincial Department of Education Science and Technology Plan Project (Grant No. 22JK0360), and the scientific research and innovation team of Shangluo University (Grant No. 19SXC03).