
Abstract
In order to improve the security and performance of the oral English instant translation model, this paper optimizes the instant translation model through the Internet of Things (IoT) security technology and deep learning technology. In this paper, the real-time translation model based on deep learning and IoT technology is analyzed in detail to show the application of these two technologies in the real-time translation model, and the related information security issues are discussed. Meanwhile, this paper proposes a method combining deep learning network and IoT technology to further improve the security of instant translation model. The experimental results show that under the optimized model, the parameter upload time is 60 seconds, the aggregation calculation time is 6.5 seconds, and the authentication time is 7.5 seconds. Moreover, the average recognition accuracy of the optimized model reaches 93.1%, and it is superior to the traditional machine translation method in accuracy and real-time, which has wide practical value and application prospects. Therefore, the research has certain reference significance for improving the security of the English corpus oral instant translation model.
Keywords
Introduction
Research background and motivations
In recent years, the rapid development of Internet of Things (IoT) technology and the wide application of deep learning in the field of artificial intelligence (AI) have brought great changes and convenience to people’s daily life. Meanwhile, with the trend of globalization, the communication among people has become more frequent and diversified. The development of IoT technology makes the connection and communication among devices more intelligent and automatic. This provides a new possibility for the collection and processing of real-time data [17, 18]. Deep learning, especially in the field of natural language processing, has shown its powerful ability in understanding and generating human language [19]. Combining the IoT with deep learning can realize a more intelligent and adaptive real-time translation system. With the acceleration of globalization, the demand for cross-language communication is increasing, especially for instant oral communication in multilingual environment [23, 26]. Although the existing translation technology meets these needs to some extent, there is still room for improvement in real-time, accuracy and naturalness. The research motivation of this paper is to explore how to build a more efficient and accurate real-time oral translation model by combining the IoT and deep learning technology, and improve the natural communication ability of the translation system to make it more suitable for the needs of daily life and professional fields.
In a word, it is of great significance and broad application prospect to build an instant translation model of English corpus based on the IoT and deep learning. This paper explores how to use the latest deep learning technology, large-scale English corpus and IoT technology to build an efficient, accurate and safe oral translation model, which provides convenience for people’s daily life and work. This paper first explains the research background, research motivation and research objectives, and then summarizes and analyzes the previous studies. Thirdly, it expounds the concept and application of instant translation model under deep learning and IoT information security, and optimizes the security of translation model. Finally, this paper verifies the effectiveness and feasibility of this research through experiments, summarizes and analyzes the research, and puts forward the shortcomings of this paper and the direction of future optimization.
Research objectives
This paper’s main objective is to use deep learning and IoT improvements to enhance security measures for real-time translation models for English corpora in the context of information security. This entails the implementation of spoken data encryption and decryption in real-time, with a focus on protecting user privacy and data security. In order to improve the overall intelligence of the model, this paper explores the use of deep learning technology in the field of oral translation models. It also adds new ideas and approaches that are pertinent to how voice interactions in the IoT space will develop in the future.
Literature review
The application of deep learning technology in information security mainly focuses on pattern recognition and anomaly detection. And the deep learning model can effectively identify malware, phishing attacks and other network threats, which is very important for protecting IoT devices and networks. Instant language translation is an important application in the field of AI. Deep learning techniques, especially recurrent neural network (RNN) and long short-term memory (LSTM) network, have been used to develop efficient oral translation models. These models can understand and translate complex language patterns and provide support for cross-language communication. The establishment of English corpus is very important for training deep learning model. By collecting a large amount of spoken English data, the model can be trained to understand natural language better and translate it accurately. These corpora usually include samples of different accents, dialects and language styles. In an examination of the field of instant oral English translation models, Zheng et al. [38] conducted an analysis of Gaussian Mixture Model (GMM) and Dynamic Neural Network (DNN) structures and training techniques, with a particular focus on acoustic modeling. Their experimental findings demonstrated the superior performance of the DNN model, resulting in a reduction of phoneme error rates and word error rates by 5.66% and 3.48%, respectively [38]. Swar and Mohsen [30], on the other hand, focused on the modeling of oral fluency, the detection and removal of fluency characteristics, and the final product of written transcriptions of spoken text. The paper highlighted distinctions among various fluency detection types and the significant impact of fluency detection tasks on machine translation. Their experimental results underscored that oral fluency detection can substantively enhance machine translation quality [30]. Poulis [26] introduced the Convolutive Neural Network
All of the previous research has shown the several difficulties that come with creating spoken English translation models in real time for the IoT [13]. These challenges encompass the adaptability of traditional translation methods to the dynamically changing IoT landscape and deficiencies within conventional oral translation systems related to language expression diversity, environmental noise, and real-time constraints [3]. These limitations have constrained the applicability and advancement of oral translation systems within the IoT. Furthermore, prior studies have demonstrated a relatively limited focus on constructing oral translation models leveraging extensive English corpus data within the IoT environment. On the other hand, this paper presents a solution based on deep learning technology and highlights how crucial it is to develop instantaneous English corpus translation models within the IoT framework, with a foundational focus on information security. It examines the accompanying information security issues as it investigates real-time translation models based on deep learning and IoT technologies. Furthermore, the paper elaborates on how these two technologies – deep learning networks and IoT technology – are integrated to strengthen the security constraints of instant translation models.
Research model
Real-time translation model under deep learning and IoT information security
The realm of IoT information security constitutes a critical assurance for the effective deployment of IoT technology. As IoT technology advances, an ever-expanding multitude of devices becomes interconnected within an extensive network infrastructure. These devices require accurate and efficient communication while maintaining data integrity [34]. Because there are more devices in the IoT environment, inter-device communication has become a more delicate and involved process, which raises the importance of information security issues [5]. The IoT is playing an increasingly important role in improving our way of life and work, but meanwhile, information security issues are becoming increasingly prominent. These problems mainly include data leakage, equipment being hacked and malware attacks. In terms of data leakage, IoT devices often collect personal information including geographical location and credit card number. Once these data are leaked, users may be seriously affected. The general solution is to strengthen data encryption and anonymous processing to ensure the security of data during transmission and storage. Meanwhile, the principle of minimum data collection is adopted, and only the information necessary to realize the function is collected. In terms of device intrusion, intruders may control the system through IoT devices and conduct illegal operations, such as stealing data or destroying the system. Normally, as long as the end-to-end security authentication is implemented, the access control of equipment is strengthened, and the firmware and software are updated regularly, the exploitation of known vulnerabilities can be prevented. In terms of malware attacks, malware may destroy IoT devices or steal user sensitive information [37]. This requires the deployment of advanced anti-virus software and intrusion detection system to monitor and respond to potential malware threats in real time.
Among the most prominent problems related to IoT information security include malware attacks, device invasions, and data breaches. Of these, data breaches are the most common worry, mostly because IoT devices have a tendency to collect users’ personal data, such as credit card numbers and location information. If this private information is compromised, users may suffer serious consequences [2]. Device infiltration is a serious problem as well since malicious hackers might use gadgets to carry out illegal actions like data theft and system sabotage. Malware attacks also appear as a persistent problem at the same time. Malware is used by attackers to breach devices and steal confidential data from consumers In order to fortify IoT information security, a series of comprehensive measures must be implemented [37].
Furthermore, the incorporation of deep learning into the domain of speech translation represents a pivotal sphere of research. With the growing ubiquity of IoT devices, an escalating demand for voice translation capabilities has arisen [29]. An essential tool for achieving this goal is real-time speech translation, which promotes improved accuracy and efficiency in inter-device communication. Prominent for its abilities in natural language processing, deep learning presents a strong path for the creation of speech translation models [7]. But because data processing involves sensitive information, it is still crucial to protect these systems from security risks. Machine translation based on statistics and neural machine translation are the two main applications of deep learning in speech translation [21]. However, deep learning technology integration necessitates careful consideration of security issues. IoT devices often gather a lot of private information, including credit card details and user locations, which could be accidentally revealed and result in serious privacy violations as well as financial losses [35].
In conclusion, a crucial area for the advancement of IoT devices is the incorporation of deep learning into the voice translation space. However, while utilizing deep learning technology, stakeholders must carefully manage the information security of IoT devices. The optimal achievement of efficient and exact voice translation and the general proliferation of IoT equipment can only be realized with the simultaneous fortification of device security [33]. Therefore, in order to guarantee the strong information security posture of IoT devices, future research endeavors need to place an even greater emphasis on the intersection of deep learning and information security technology.
Application of IoT technology and deep learning in the instant translation model
The data expansion method, in which every original data sample converts a row vector, is included in the data deformation approach. Subsequently, a deformation matrix is formulated for the purpose of data distortion. Initially, a stochastic reversible matrix is generated, followed by its diagonal expansion in accordance with the equation illustrated in Eq. (1):
Diagonal expansion operation diagram.
Lastly, the transformed data is derived through the multiplication of the data line vector by the deformation matrix. Differential privacy represents a compromise between data privacy and data accessibility, achieved by perturbing data. This approach is distinguished by its high computational efficiency and minimal impact on data availability [28].
In Eq. (2),
PK is the key generation function.
Model parallel schematic diagram.
During the training process of deep learning models, users are faced with the intricate task of not only supplying effective data samples for training but also taking into consideration model architecture, initial model weights, and parameter configurations [22]. This can be especially difficult for non-expert users because some people want to use deep learning models only for their predictive power, without any need for customized involvement that involves model training and prediction [1]. Unlike the complex process of building a deep learning model, deep learning model prediction only requires users to provide the data they want to predict [8].
The system for data collection comprises three fundamental components: data owners, IoT devices, and data consumers [36]. The structural framework of this system is elucidated in Fig. 3.
System structure of data collection scheme.
The entity referred to as the “data owner,” or alternately the “data provider,” is an individual equipped with data collection apparatus. Ownership of the collected data belongs to the data owner, who acts as the seller in the context of the data transaction [18]. Through an incentivized mechanism, the data owner can also access deep learning model prediction services by furnishing points acquired through data exchanges, thus obviating the need for the full model download and merely retrieving the corresponding prediction results [14]. IoT devices, which are also referred to as data collectors, primarily consist of IoT devices that are used for data collection by data collectors, such as wearables, sensors, and smartphones [32]. Once the data owner has given permission, the information gathered by IoT devices is sent to the cloud server of the data consumer, which is the organization that purchased the information. Moreover, data collectors are accountable for establishing and maintaining blockchain infrastructure [11]. Data consumers, who serve as purchasers in data transactions, are similarly tasked with provisioning deep learning model prediction services to data owners. Subsequent to receiving the data uploaded by IoT devices, data consumers may elect to either store the data in the cloud server for subsequent offline analysis and utilization or engage in immediate online analysis and utilization [4]. The optimized data transaction framework delineated in this paper is illustrated in Fig. 4.
Blockchainbased data trading solution.
The data transaction scheme based on blockchain in this paper can meet the following requirements, as shown in Table 1.
Requirements met by blockchainbased data trading solutions
In the prospective context of an intelligent “battlefield” environment, the comprehension of the “battlefield” scenario hinges upon the comprehensive analysis and processing of voluminous data. Simultaneously, the actualization of combat functionalities is contingent upon the meticulous analysis, processing, and strategic utilization of data resources. The trajectory of the collaborative combat paradigm’s evolution is substantially intertwined with the proficiency exhibited in data analysis and processing capabilities [27]. Figure 5 shows the results obtained from the federated learning system model that is suggested in this paper to protect the confidentiality of the data of the participants.
A federated learning system model for protecting participant data security.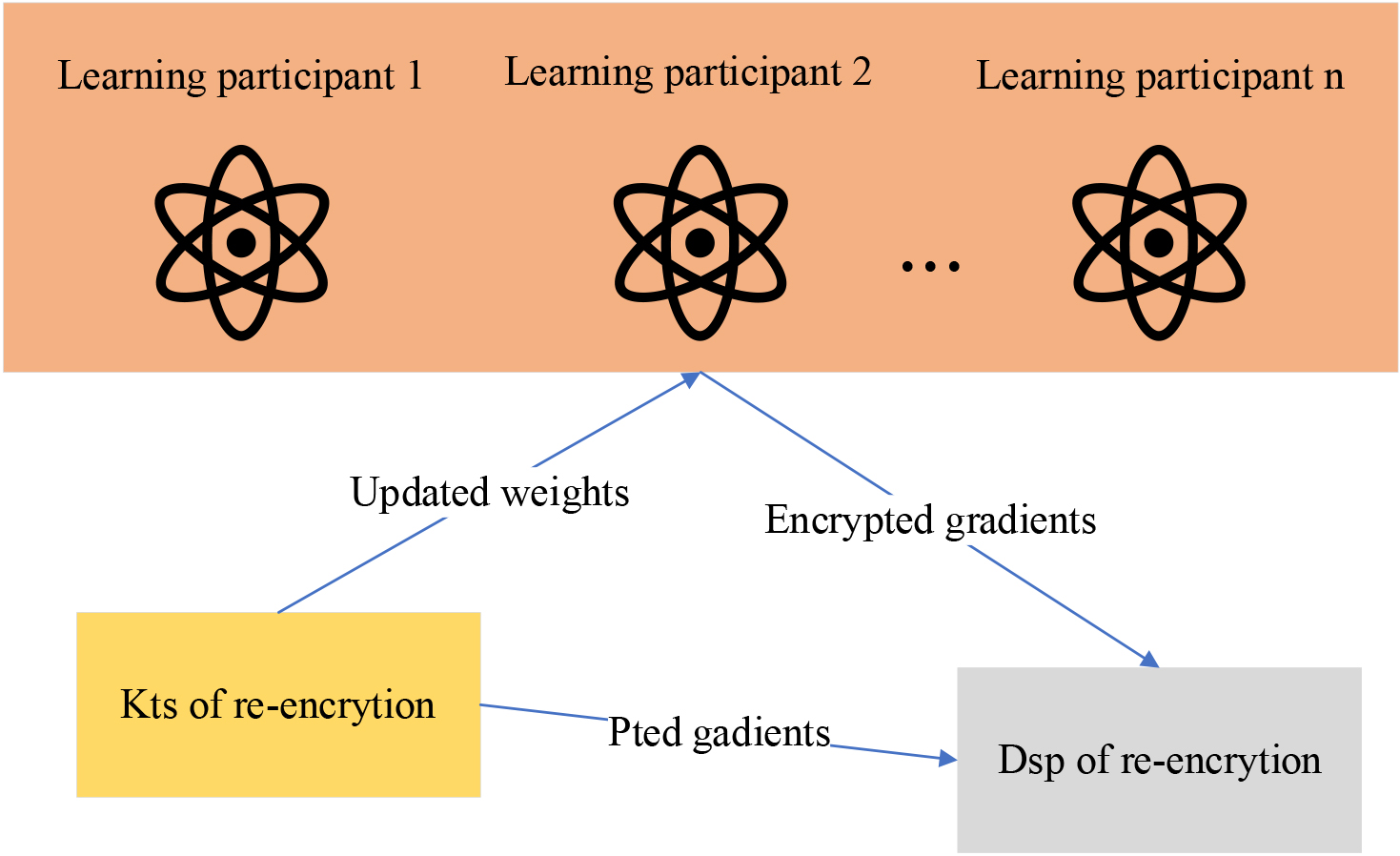
The refined system model delineated in this paper underscores the dual role undertaken by learning participants within the system. Concisely, these participants function as both data providers and data requesters. Learners essentially provide the cloud server with newly calculated gradients, which makes it easier for the cloud server to update the weight vector. Meanwhile, they request the most recent weight vector from the cloud server in order to coordinate the gradient generation that follows. In consideration of the dispersed nature of learning participants in this context, the training dataset is also distributed. The operational sequence of the model is meticulously illustrated in Fig. 6.
Steps for running the model.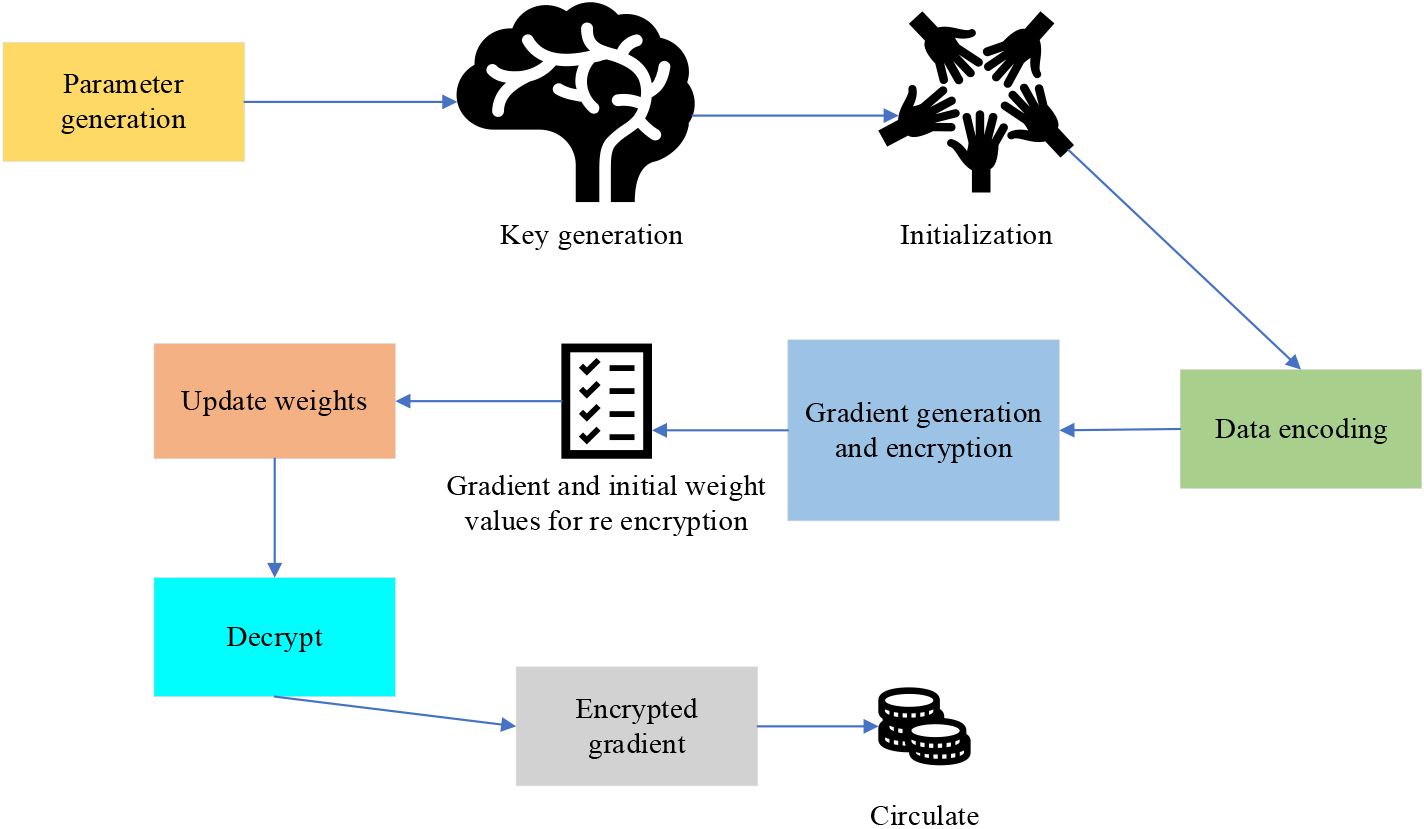
Combined with the model of the federated learning system and the data transaction mechanism that is intended to protect the participants’ data security, it is clear that the model involves three different roles interacting dynamically. These roles include one user who provides input data and consumes services, three workers who act as the computation’s execution agents, and one server responsible for delivering the model [16]. Users confidentially share their personal input data exclusively with the trio of workers, while the server likewise shares its pre-training model parameters confidentially with the same trio of workers. Subsequently, the workers collaboratively engage in secure tripartite computations to derive the predictive outcomes of the model. Ultimately, each worker transmits the prediction results to the user, thereby reinstating the output outcome. Figure 7 illustrates this security model’s conclusion graphically.
By utilizing secure tripartite computation, a collaborative endeavor is undertaken by three workers who collectively utilize confidentially shared input data and models to conduct calculations, ultimately generating prediction outcomes from the deep learning model. Subsequently, each worker individually conveys the results they have computed to the user. Through this process, users can readily recover the corresponding model prediction outputs. Compared with the previous model, this model emphasizes information security in its design, and integrates the IoT technology compared with the existing model, especially in the process of data collection and transmission. Moreover, this model uses more advanced deep learning algorithm, which makes the model more accurate and natural in dealing with oral translation.
Experimental materials
In order to substantiate the security robustness of this model, the present study employs the Technology Entertainment Design (TED) Talks dataset. This dataset encompasses an extensive collection of both voice and text data, encompassing thousands of TED speeches. These speeches span a diverse array of topics, including but not limited to science and technology, design, society, and culture. This dataset finds utility in a spectrum of tasks, such as speech recognition, speaker recognition, and emotion analysis. Access to this dataset can be procured via the TED official website (https://www.ted.com/participant/organize-a-local-tedx-event/tedx-licensing/tedx-talks-subtitles-and-transcripts), which hosts video, audio, and textual resources for each speech. A detailed breakdown of the TED Talk dataset is presented in Table 2.
Specific content of TED Talk data
Specific content of TED Talk data
Instant translation security model.
For the accuracy of the experiment, this paper also prepares the People’s Speech dataset, which contains more than 30,000 hours of diverse spoken English data, aiming at promoting the innovation of machine learning. It is the largest diversified English speech recognition corpus for academic and commercial purposes. This dataset is suitable for training a comprehensive end-to-end model and improving applications such as automatic speech recognition, transcription, sound separation and noise reduction. The dataset is constructed from the audio data licensed by the public domain in Archive.org, with the existing transcribed text. The dataset can be downloaded from the official website (
The experimental environment of this experiment is shown in Table 3.
Experimental environment
Experimental environment
Model efficiency comparison results.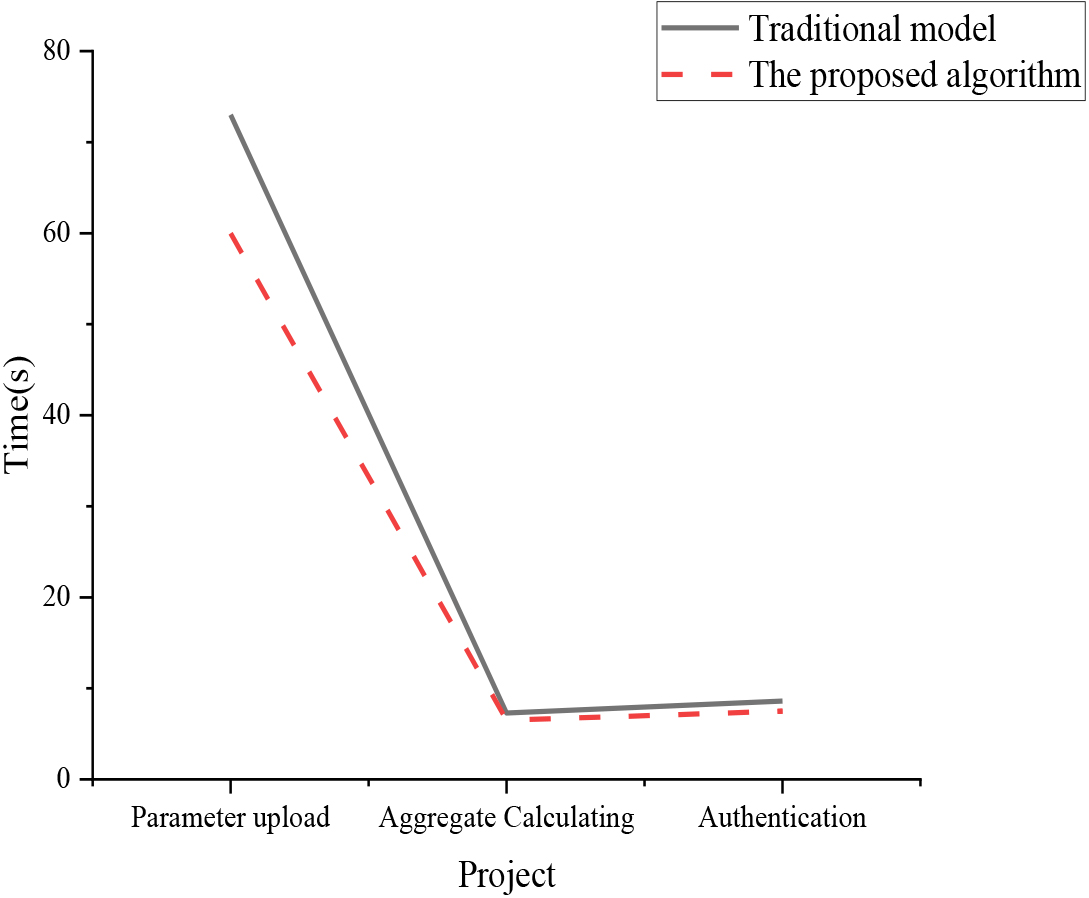
In order to maximize the utility of the data, standardization of the model parameters is undertaken. The model configuration entails two convolution layers, each comprising 64 filters with a filter size of 3*3. The node size is established at 128, while both the encoder and decoder are endowed with a hidden state size of 512. Within the Transformer layer, there are eight attention heads, and the data dimension is set to 1,000. A learning rate of 0.0001 is employed throughout the training phase, which spans a duration of 40 iterations. A weight decay factor of 0.001 is also incorporated into the model. The traditional model chosen in the experiment is Sequence-to-Sequence (Seq2Seq), which is a deep learning model framework and has been widely used in the field of machine translation. The core of Seq2Seq model consists of two parts: encoder and decoder. The function of the encoder is to understand and process the input source language sequence and convert it into a fixed-length context vector. This context vector contains the main information of the input sequence and is passed to the decoder. The decoder is responsible for converting this context vector into the target language sequence. In this process, the decoder generates the output of the target language step by step, one word at a time.
In the experiment, the computational efficiency of the traditional model and the optimized model in this paper is studied and compared. The time cost of three key processes in the running process of the model, parameter uploading, aggregation calculation and authentication, is analyzed. In order to accurately evaluate the performance of each stage, the experiment made detailed statistics on the results of 50 iterative trainings and calculated the average time consumption of each process. This statistical method can observe and compare the performance of each algorithm more accurately. The comparison result between the optimized model and the traditional model Seq2Seq is shown in Fig. 8.
The comparative outcomes of the experiments, as depicted in Fig. 8, demonstrate that the optimized model presented in this paper exhibits superior performance across various metrics, encompassing parameter upload time, aggregation computation time, and authentication time. Specifically, the parameter upload time for the optimized model in this paper stands at 60 seconds, while the traditional model consumes 73 seconds for the same task. In the case of aggregation computation, the optimized model achieves a time of 6.5 seconds compared to the traditional model’s 7.3 seconds. Similarly, the authentication process takes 7.5 seconds in the optimized model, in contrast to the 8.6 seconds required by the traditional model. All of these data together highlight the observable improvements that the optimization approach described in this paper achieves on all assessed aspects. In order to further validate the efficiency of the optimized model, experiments are conducted with different iteration numbers, and the experimental results are shown in Fig. 9.
Comparison of model runtime under different iterations.
In Fig. 9, as the number of iterations increases, the model’s runtime gradually increases. However, it is evident that the runtime of the optimized model increases at a significantly slower pace compared to that of the traditional model. Moreover, as the number of iterations increases, the gap in runtime becomes more pronounced. In order to verify the security of the model, the experiment assumes that there are 30% malicious node attacks, and the model classifies the nodes. The classification structure of the optimized secure model compared to the traditional Seq2Seq model, is illustrated in Fig. 10.
Classification accuracy comparison results.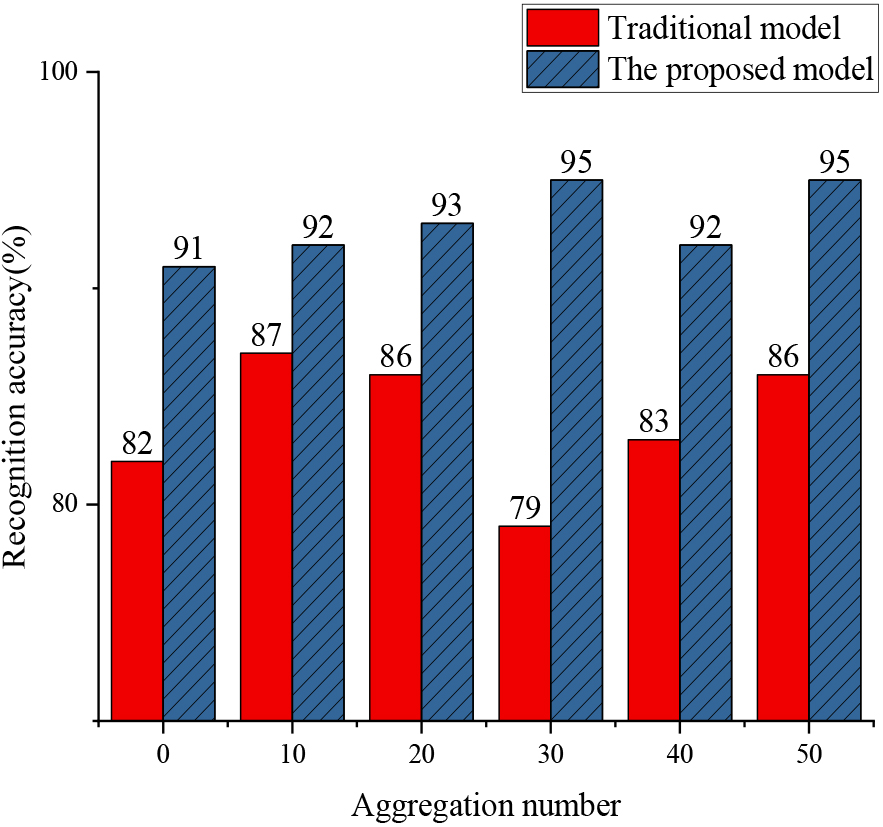
In Fig. 10, this paper achieves an average recognition accuracy of 93.1% with the optimized model. Compared to traditional Seq2Seq models, the optimized English spoken language corpus real-time translation secure model demonstrates significantly higher recognition accuracy under various aggregation scenarios. This noteworthy improvement signifies that the optimized model can more accurately identify speech signals and convert them into corresponding textual outputs.
In complex environments with malicious nodes and different aggregation frequencies, the optimized model maintains a consistently high recognition accuracy level, whereas traditional models’ performance tends to decline. This result further validates the superiority of the optimized model in terms of recognition accuracy and security. These experimental results confirm the significant achievements of the optimized model in handling real-time translation tasks for English spoken language corpus. The attainment of high recognition accuracy implies that the model can provide users with more precise and reliable translation services. Additionally, the stability of the optimized model in the presence of malicious nodes and varying aggregation frequencies highlights its robustness and security in handling complex environments.
In summary, this paper has made significant advancements in English spoken language corpus real-time translation tasks through model optimization, particularly in terms of recognition accuracy and security. These findings hold crucial significance for enhancing spoken language translation systems’ performance and user experience, offering valuable insights for researchers and practitioners in related fields.
An analysis of the execution time across various task stages reveals that the training component remains the most time-intensive segment during algorithm execution. Asynchronous aggregation is used to mitigate any delays associated with model training, although it is important to note that the training step usually takes place offline. Furthermore, the delay observed in the model aggregation process and authentication phase is minimal, indicating that the overall and partial processing time costs remain within reasonable bounds. Nevertheless, it is essential to acknowledge that there exists ample room for improvement, particularly when considering scenarios involving large-scale nodes. In such cases, the time incurred for parameter uploading, aggregation computation, and authentication within the model is expected to be higher, necessitating further optimization of the algorithm. It is imperative to recognize that the experimental results are contingent on specific datasets and tasks. Consequently, in practical applications, the model’s recognition accuracy may vary depending on the specific dataset and task at hand. Nonetheless, comparative analysis of the experimental outcomes affirmatively underscores the superior security and accuracy exhibited by the optimized model presented in this paper within the domain of instant translation tasks for spoken English corpora. This achievement holds profound practical significance. The advantage of this optimized model is that it improves the accuracy and real-time performance of oral translation by integrating IoT technology and deep learning. Especially in the aspect of information security, the model ensures the translation efficiency and effectively protects the security and privacy of user data through advanced data protection mechanism. The disadvantage is that although the model has improved information security and translation accuracy, it may still have limitations in dealing with complex and changeable actual environment and accent diversity. This may affect the general applicability and stability of the model in practical application. The limitation of the optimization model in this paper is that the research and experiments in this paper are based on specific datasets and task environments, so the performance and applicability of the model may change due to the differences between datasets and actual application scenarios.
Compared with previous studies and Lumei [20] work, this model integrates two key technical fields, namely the IoT and deep learning, and deeply explores the construction of oral instant translation model in the IoT environment under the framework of information security. This comprehensive research has important academic and practical significance for solving language communication barriers in the IoT [20]. In addition, compared with the research of Joshi et al. [15], the optimization model proposed in this paper can provide more accurate and natural translation results by using large-scale data sets and enhanced model learning ability [15]. This comparison not only highlights the innovation of this paper, but also shows its advanced nature in the application of language processing technology.
Conclusion
Research contribution
The main achievement of this paper is to build a real-time oral English translation model that integrates IoT technology and deep learning, and pays attention to information security. The model adopts advanced deep learning algorithm and IoT technology, which effectively realizes real-time safe translation of spoken English. This paper first analyzes the real-time translation model under deep learning and IoT information security, and then discusses the application of IoT technology and deep learning in translation model in detail, and improves the security of the model through these technologies. The experimental results show that the optimized model takes 60 seconds, 6.5 seconds and 7.5 seconds respectively in parameter uploading, aggregation calculation and identity verification. The average recognition accuracy reaches 93.1%, which surpasses the traditional machine translation method in accuracy and real-time. Therefore, this paper not only brings innovative ideas and methods to the field of oral English translation, but also provides new possibilities for the application of IoT and deep learning technology in other fields. These achievements are of academic significance and important value in practice, which provides reference for research and application in related fields and lay a foundation for further research and development in the future.
Future works and research limitations
Based on the results of this paper, future research can focus on further improving the accuracy of oral translation, especially by optimizing the algorithm and expanding the corpus to reduce the misidentification rate and translation error rate. Meanwhile, it can focus on context awareness and situational adaptability, and develop translation models that can be intelligently adjusted according to different contexts and cultural backgrounds. In addition, oral translation technology will be extended to more professional fields, such as medical care and law, to improve the efficiency of cross-disciplinary communication. In this process, it is very important to strengthen data security and privacy protection to ensure the safety of user information when technology is applied. Meanwhile, the ethics and responsibility of artificial intelligence should be considered to ensure the fairness, reliability and social responsibility of technology.
There are some restrictions on this paper. First, the need for a somewhat quiet location limits the range of voice input, which reduces the efficacy of oral translation when background noise is present. Second, there is a need to improve the model’s performance. Future research projects ought to consider implementing distributed computing technologies, such MapReduce or Spark to accelerate model training and maximize the effectiveness of inter-node communication. Moreover, the study can broaden its scope to investigate the application of more effective algorithms and computational frameworks, including Federated Learning and TensorFlow to enhance the algorithm’s scalability and performance.