
Abstract
With the rapid development of Internet of Things (IoT) technology, a large amount of sensor data, images, voice, and other data are being widely used, bringing new opportunities for intelligent and cross-domain information fusion. Effective feature extraction and accurate recognition remain urgent issues to be addressed. This article explores the application of deep learning (DL) in multimodal data recognition methods of the IoT and proposes path optimization for multimodal data recognition methods of the IoT under DL. This article also provides in-depth analysis and discussion on the optimization of multimodal data recognition models based on DL, as well as specific measures for optimizing the path of multimodal data recognition based on DL. In this paper, the long short-term memory (LSTM) technology is introduced, and the LSTM technology is used to optimize the multi-modal data recognition method. It can be seen from the comparison that the processing efficiency of data analysis, information fusion, speech recognition, and emotion analysis of the multimodal data recognition method optimized by LSTM technology is 0.29, 0.35, 0.31, and 0.24 higher, respectively, than that of data analysis, information fusion, speech recognition, and emotion analysis before optimization. Introducing DL methods in multimodal data recognition of the IoT can effectively improve the effectiveness of data recognition and fusion and achieve higher levels of recognition for speech recognition and sentiment analysis.
Keywords
Introduction
With the advent of the digital age, various forms of data, such as images, text, sound, etc., have experienced explosive growth. Multimodal data contains abundant information, but it also faces problems such as how to fuse multiple information sources, extract effective features, and accurately identify them. The most important part of multimodal data processing is to perform emotional analysis on the data and extract the required data. With the development of the IoT, a large amount of sensor data, image data, voice data, and other data are collected in large quantities. How to effectively identify and fuse these data is the key to improving the intelligence level of the IoT.
With the development of the Internet, data has shown explosive growth. Multimodal data recognition methods can improve data recognition and optimization, and have great application prospects in fields such as the IoT. Jing Gao proposed some groundbreaking DL models to fuse these multimodal big data, and summarized the in-depth learning overview of multimodal data fusion [1]. Valentin Radu used a DL algorithm to explain the benefits of user activities captured by multimodal systems, focusing on four variants of deep neural networks, which are based on fully connected deep neural networks or convolutional neural network. Two of these architectures followed the traditional deep model, and analyzed information data from the serial execution characteristics of sensor types [2]. Sharmeen M Saleem Abdullah used DL for emotion recognition of multimodal signals and compared their current research based on DL applications [3]. Yi Yu proposed a new DL model in which data from different patterns are projected onto the same space through a deep network, optimizing the relevant data for precise site search [4]. Although multimodal data recognition methods have many potential and application space in fields such as data recognition and image analysis, there are still certain recognition limitations in the face of complex data.
DL can leverage its powerful nonlinear fitting ability to accurately identify abnormal data, thereby achieving anomaly detection in the IoT and promoting the development of the Internet of Animals. Xuyu Wang proposed a universal DL framework for radio frequency sensing in the IoT. He first proposed the proposed framework, and then reviewed various sensing technologies, DL technologies, and standardized sensing applications [5]. Wei Wang believed that the rapid development of big data of the IoT provides valuable opportunities for the development of people in all fields of society, and the current machine learning model works in Vector space. He proposed a DL computing model called tensor DL, which further improved big data feature learning and advanced feature fusion [6]. Tausifa Jan Saleem found that DL would undoubtedly play a role in generating valuable inferences from a large amount of data, thus helping to create a more intelligent IoT. After that, a detailed review was conducted on the use cases of DL driven IoT [7]. Although DL can promote the development of the IoT, there is a huge data system in the IoT that requires data recognition and classification.
This article aimed to explore DL methods for multimodal data recognition in the IoT. Through the analysis of existing technologies and algorithms, combined with LSTM technology and other technologies, it was used for multi-modal data recognition. Firstly, a multi input single output model and a multi output model optimization were proposed, and techniques such as fusion of multimodal features and production adversarial networks were applied to generate realistic multimodal data. In this paper, the specific measures of multimodal data identification optimization path based on DL were proposed, and LSTM technology was introduced to optimize the multimodal data identification method. Through experimental analysis, it was found that the optimized multimodal data recognition efficiency greatly improved model accuracy, multimodal data fusion effect, and computational efficiency, which was higher than the multimodal data recognition efficiency before optimization.
Path optimization of multimodal data recognition methods for the IoT under DL
Optimization of multimodal data recognition model based on DL
Multi input single output model and multi output model optimization
Characteristics of multimodal data.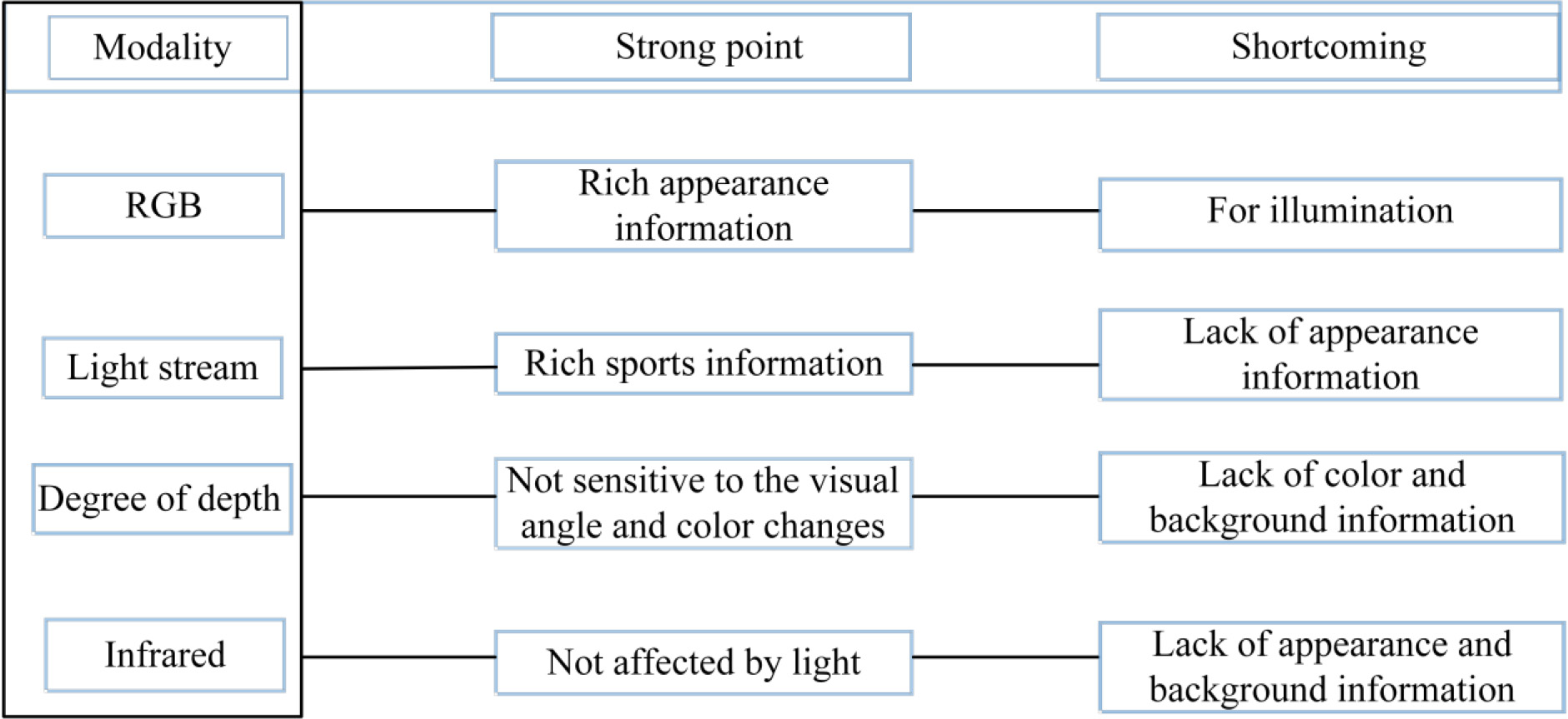
This article used a multi input single output model to input data from multiple input patterns into a deep neural network, and utilized mechanisms such as network connectivity and weight allocation to achieve information exchange and fusion between multiple patterns. The multi input multi output model is a more flexible and mature multimodal data identification method, which can process multiple input modes at the same time and obtain multiple results. For example, for both image and text inputs, this model can not only answer a question but also generate a description of the image, providing more information in multi task and multi output situations. The characteristics of multimodal data are shown in Fig. 1.
This study adopts the method of fusing multimodal features to establish a common expression space. Multimodal fusion networks can fuse multiple modal information through methods such as connection, weighted fusion, and cascading [8, 9]. Through the attention mechanism, the characteristics of each channel can be weighted, so as to improve the model’s ability to process key information. This method uses the production countermeasure network to realize the generation and transformation of multimodal data, and conducts confrontation training between the generator and the discriminator, so as to produce realistic multimodal data. First, a certain mode is pre trained, and then Transfer learning is carried out.
Specific measures for optimizing paths for multimodal data recognition based on DL
By preprocessing multimodal data, noise and outliers can be eliminated, thereby improving the quality of the data. Rotation, translation, scaling and other methods are used to expand the sample and training set of data and improve the generalization ability of the model [10, 11]. The article designed a deep network architecture and applied the established model to multimodal data recognition using the deep network architecture and existing large sample data, thereby improving the initialization of the model. This method achieves the learning of other modalities by learning one modality, thereby reducing the learning requirements for each modality and improving the generalization performance of the model. The data recognition process of the multi input multi output model is shown in Fig. 2.
Data recognition process for multi input multi output model.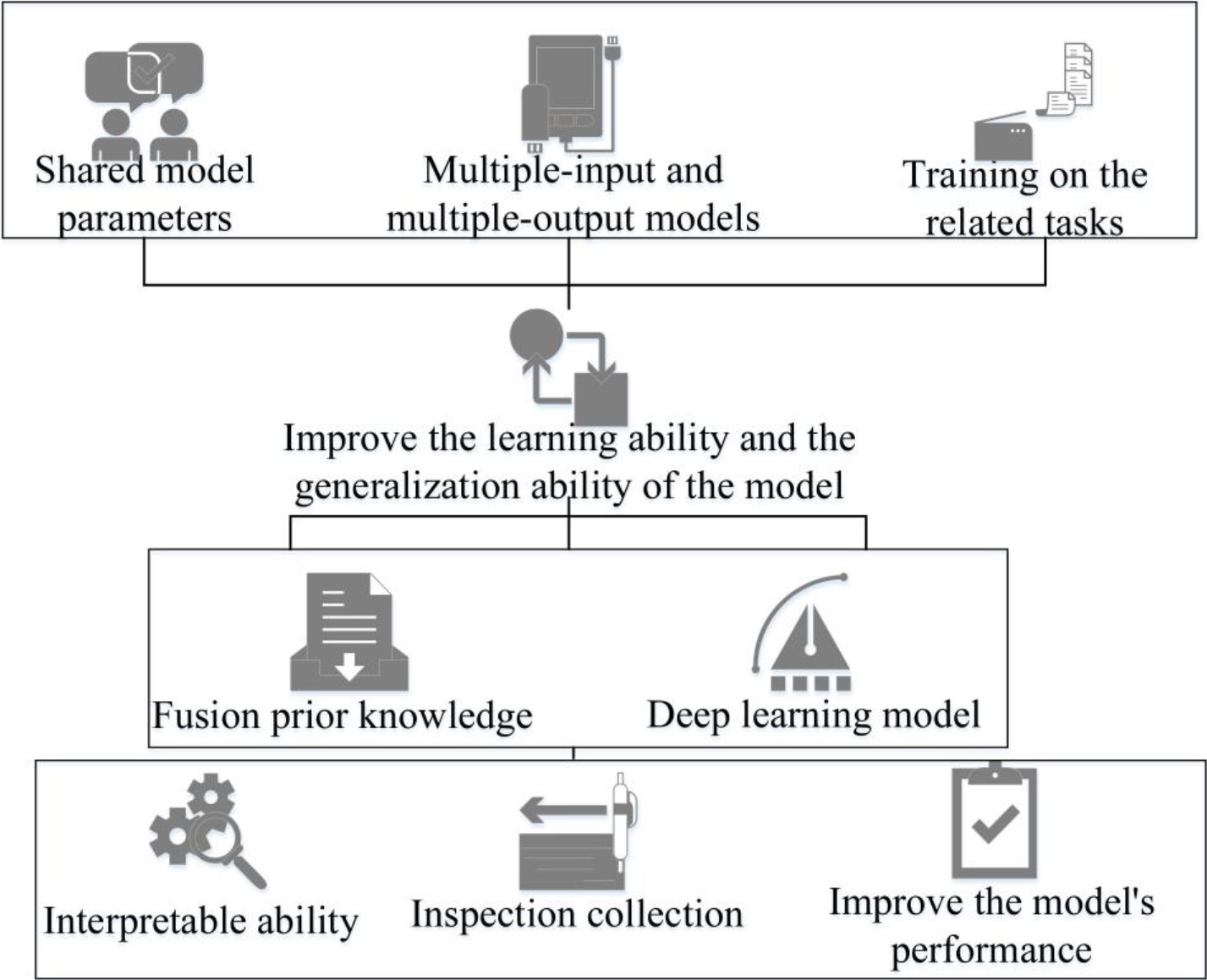
By designing a multi input and multi output model, multiple related tasks are trained and model parameters are shared, thereby improving the learning and generalization abilities of the model. Information exchange between tasks: By designing appropriate mechanisms, information sharing and interaction can be achieved between different tasks, which enhances the fusion and joint learning capabilities of multimodal data. Based on professional knowledge in specific application fields, specific rules and constraints can be designed to guide models in learning more accurate multimodal data recognition [12, 13].
By integrating prior knowledge and DL models, the interpretability of the model in specific tasks and domains can be improved [14]. By means of cross validation and other means, the test set is reasonably selected and the model’s generalization ability is evaluated to prevent overfitting and underfitting of the model.
The fusion of voice data and sensor data in the IoT can be used for applications such as speech recognition and sentiment analysis [15]. This article can achieve applications in speech recognition and emotion analysis by integrating speech and sensor information. On this basis, this article proposed a multimodal information fusion method based on DL. Through the research of this project, efficient fusion of multimodal data can be achieved, thereby achieving a higher level of semantic understanding and recognition.
Application of LSTM technology based on DL in multi-modal data recognition
In this paper, LSTM technology was used to optimize the application of multimodal data identification. LSTM is a specially designed memory neural unit. It is required to identify the data of the input sequence and manage the gates of different data states in the LSTM, so as to achieve data control [16]. The data status gates are: forgetting gate, input gate, and output gate. When processing the input data, each gate would control whether it is triggered through the activation function
The output value of the function is between 0 and 1, which describes how much each component should pass. A value of 0 indicates that no component passes, while a value of 1 indicates that all components can pass.
LSTMs need to decide which information to pass through the core.
A decision needs to be made on how much new data to let into the information kernel, and a vector
The formula for updating the old memory state
The output is performed on the data, and the output is based on the existing memory element states, but filtering is required to compress the values taken from the memory element states, and the point-by-point product of the compressed data is performed with Eq. (6):
Current efficiency of multimodal data recognition
Current efficiency of multimodal data recognition
To analyze the efficiency of current multimodal data recognition, this article extracted 10 data samples and conducted recognition analysis on sensor data, image data, and text data in the data samples. The peak recognition efficiency of sensor data, image data, and text data in the data sample is 1, with a value of 0.6 or above being qualified and 0.8 or above being excellent. The specific investigation is shown in Table 1.
After conducting experimental analysis on the efficiency of current multimodal data recognition, it was found that the average efficiency of sensor data recognition in 10 data samples was 0.49. Only 2 out of 10 samples had a qualified recognition efficiency, and the average efficiency of image data recognition among 10 data samples was 0.58; 5 out of 10 data samples had qualified recognition efficiency, and the average efficiency of text data recognition among 10 data samples was 0.59; out of the 10 data samples, 5 had qualified recognition efficiency. It can be seen that there are still some problems in current multimodal data recognition, and the recognition efficiency of sensor data, image data, and text data in the data samples is not high. Therefore, multimodal data recognition technology should be optimized.
Analysis of multimodal data recognition efficiency before and after optimization. A. Analysis of accuracy and recognition efficiency of multimodal data models before and after optimization. B. Analysis of the recognition efficiency of multimodal data fusion effects before and after optimization. C. Analysis of computational efficiency for multimodal data recognition before and after optimization.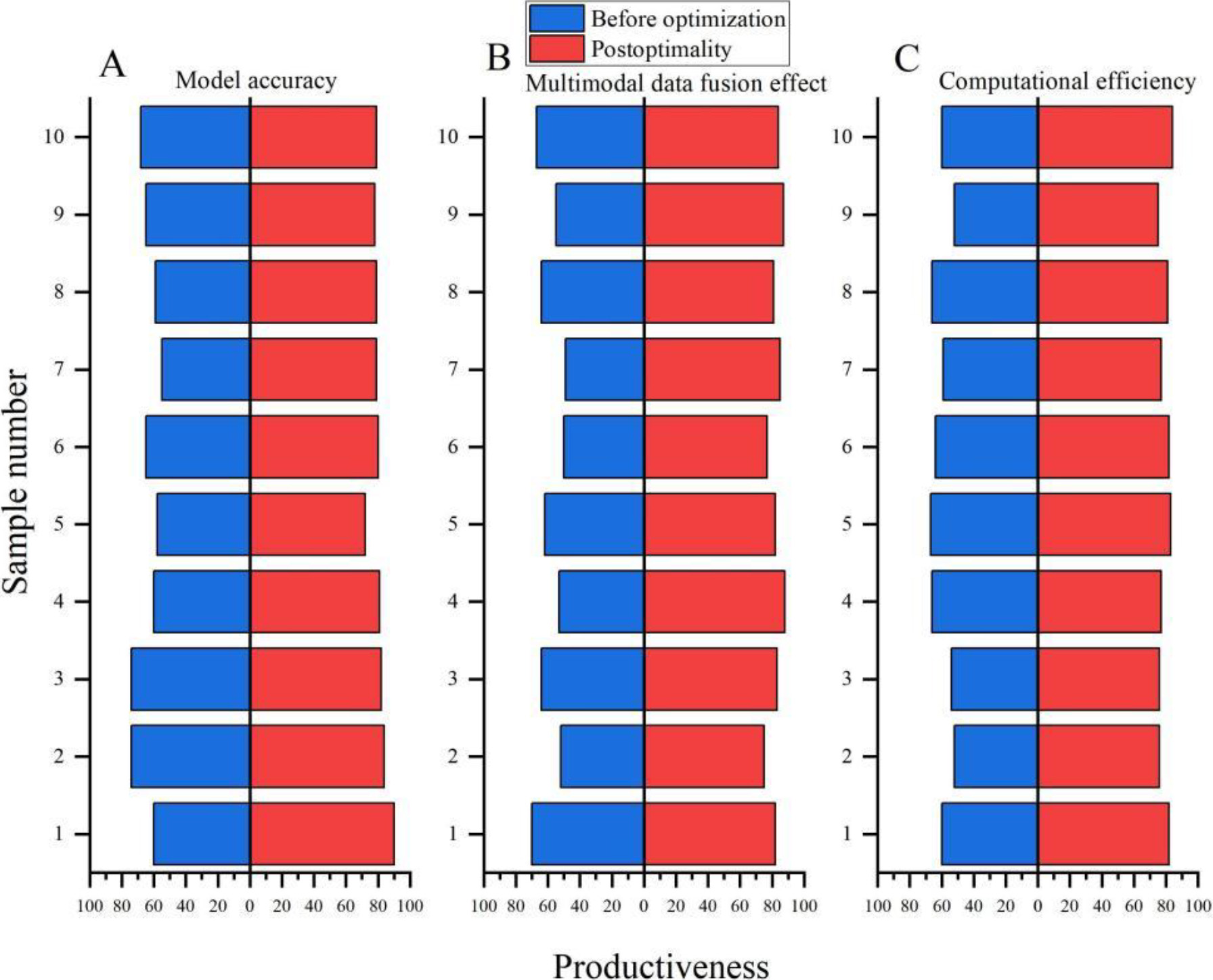
In order to optimize the multimodal data identification technology, this paper used the LSTM technology in DL to analyze the model accuracy, multimodal data fusion effect and calculation efficiency of the optimized multimodal data identification technology. This article selected 10 data samples for experiments and compared their efficiency with the multimodal data recognition before optimization. The efficiency was set at 1–100, with scores below 60 being considered unqualified, 60–80 being qualified, and 81–100 being excellent. The specific analysis is shown in Fig. 3.
This article analyzed the efficiency of multimodal data recognition before and after optimization. Figure 3 shows the efficiency analysis of multimodal data recognition before and after optimization. Figure 3A shows the accuracy identification efficiency analysis of the multimodal data model before and after optimization; Figure 3B shows the efficiency analysis of multimodal data fusion effect recognition before and after optimization; Figure 3C shows the efficiency analysis of multimodal data recognition calculation before and after optimization.
The X-axis in Fig. 3 represents efficiency, while the Y-axis data represents the number of samples. After experimental analysis, it was found that the average accuracy and efficiency of the 10 data sample models for multimodal data recognition before optimization was 64; the average efficiency of multimodal data fusion was 59; the average calculation efficiency was 60. The average accuracy and computational efficiency of the model before optimization were above 60 points, which met the qualified standard but did not reach the excellent level, and the multimodal data fusion effect did not reach the passing level. The average accuracy and efficiency of the 10 data sample models for optimized multimodal data recognition was 80; the average efficiency of multimodal data fusion was 82; the average calculation efficiency was 79. The average accuracy, multimodal data fusion effect, and computational efficiency of the optimized model were all above 60 points, which met the qualified standard. The average efficiency of multimodal data fusion effect was above 81, which was considered excellent. It can be seen that the optimized multimodal data recognition efficiency greatly improved model accuracy, multimodal data fusion effect, and computational efficiency, which was higher than the multimodal data recognition efficiency before optimization.
Analysis of processing efficiency of multimodal data recognition technology before and after optimization. A. Processing efficiency of optimized multimodal data recognition technology. B. Processing efficiency of multimodal data recognition technology before optimization.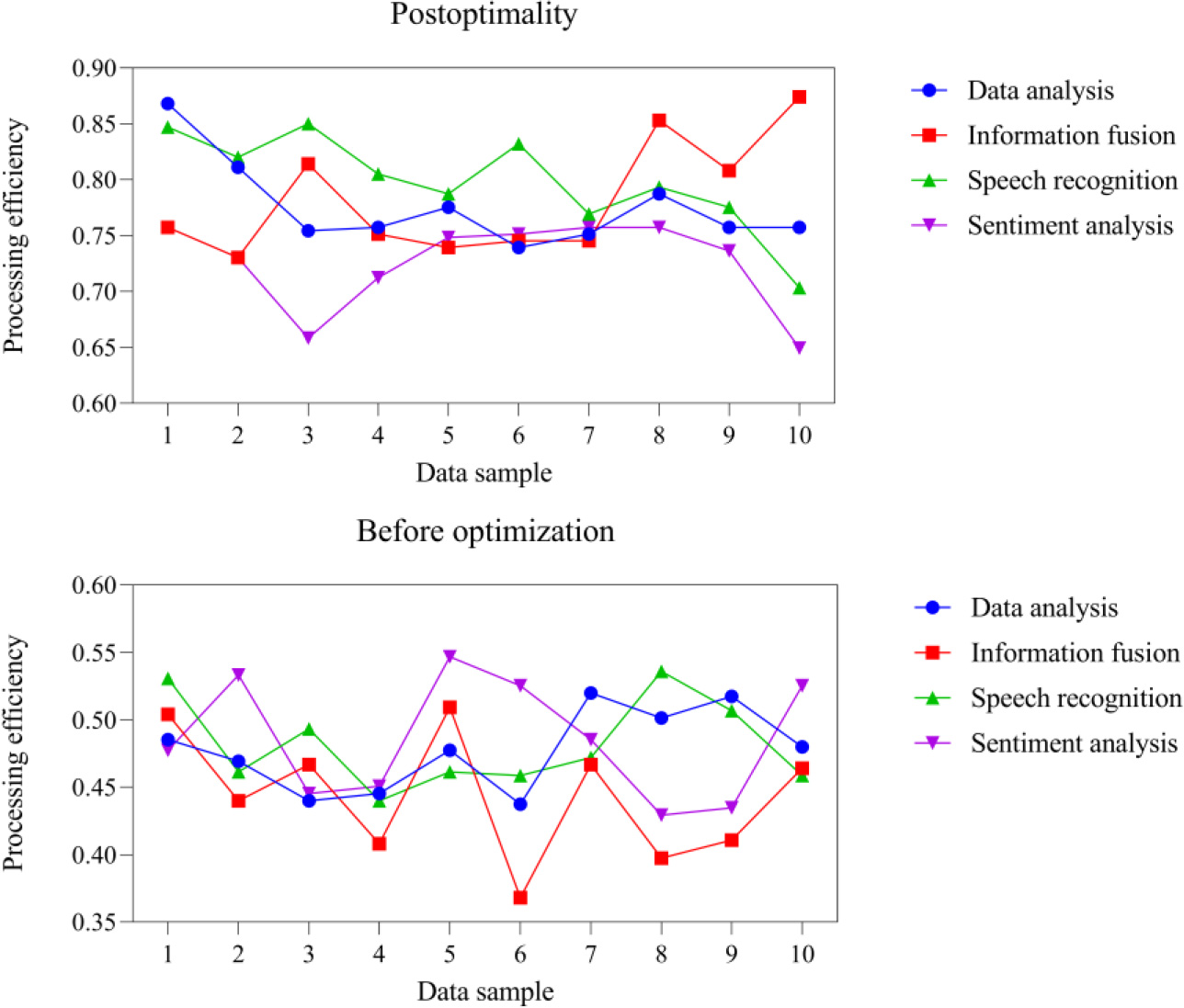
Integrating image data with sensor data can combine image processing technologies such as object detection, image segmentation, and feature extraction with sensor data in the IoT environment, providing richer information for object detection, image segmentation, and feature extraction in the IoT environment. In order to investigate the processing efficiency of data analysis, information fusion, voice recognition and emotion analysis in the IoT environment using multimodal data recognition technology optimized by LSTM technology, this paper selected 10 pieces of information data in the IoT environment, and used the optimized multimodal data recognition technology to conduct experiments. At the same time, experiments were conducted using the multimodal data recognition technology before and after optimization, and the processing time of the multimodal data recognition technology before and after optimization was compared. The specific experiment is shown in Fig. 4.
Figure 4A shows the processing efficiency of the optimized multimodal data recognition technology, while Fig. 4B shows the processing efficiency of the pre optimized multimodal data recognition technology. In Fig. 4, the X-axis represents the number of data samples, while the Y-axis represents the efficiency of data processing; the legend represents different information in the IoT environment. The average processing efficiency of the optimized multimodal data recognition technology for data analysis, information fusion, speech recognition, and sentiment analysis in the IoT environment was 0.78, 0.79, 0.80, and 0.73. The average processing efficiency of the optimized multimodal data recognition technology for data analysis, information fusion, speech recognition, and sentiment analysis in the IoT environment was 0.49, 0.44, 0.49, and 0.49. The processing efficiency of optimized data analysis, information fusion, speech recognition, and sentiment analysis was 0.29, 0.35, 0.31, and 0.24 higher than that of the pre optimized data analysis, information fusion, speech recognition, and sentiment analysis. It can be seen that the optimized multimodal data recognition technology has improved the processing efficiency of data analysis, information fusion, speech recognition, and sentiment analysis in the IoT environment compared to the previous optimization.
In summary, after research and analysis, it has been found that the multimodal data recognition method based on DL has made significant breakthroughs in achieving information recognition and fusion. The use of multiple input single output models, multiple input multiple output models, deep fusion models, and other methods can extract useful features from multiple information sources and perform accurate recognition. Multimodal data recognition in the IoT is a key technology for achieving intelligent information fusion in multiple fields. Technical means such as sensor data processing, data fusion, and speech are important ways to solve the problem of multimodal data recognition. On this basis, this paper optimized the multimodal data identification technology by using LSTM technology, so as to enhance the model accuracy, multimodal data fusion effect and calculation efficiency of multimodal data identification technology. For the high quality and heterogeneity of multimodal data, exploring smarter multimodal data processing and fusion methods can promote the development and application of multimodal data.
Footnotes
Funding
This work was supported by the National Natural Science Foundation of China: Research on Internet of Things Network Architecture and Key Technologies for Heterogeneous Wireless Protocol interoperability (62072396); The Teaching Reform Project of Jiangxi Province Educational Department of China: Research on the Construction of Digital High Quality Teaching Resources and Intelligent Education Innovation Based on IoT Remote Platform (JXJG-22-13-26, 22YB195).