
Abstract
The volume and complexity of lighting system are increasing, and the traditional fault diagnosis method can not meet the requirements. It is proposed to use the strong knowledge association and analysis ability of knowledge graph on big data to assist fault analysts in the lighting system fault diagnosis. Firstly, the schema layer of the knowledge graph in the top-down style was designed, which defined the overall architecture of the lighting system fault diagnosis knowledge graph. Then, the BERT-BiLSTM-CRF model was constructed and trained for knowledge extraction by using self-built data set, and the data layer of the knowledge graph in the bottom-up style was built. And then, the fault diagnosis rule module was constructed and optimized by combining the knowledge graph with the deduction lattice algorithm. Finally, the knowledge graph was visualized by using the Neo4j graph database and its application process in fault diagnosis was analyzed. The experimental results show that the BERT-BiLSTM-CRF model has a 17.58% improvement in precision over the BiLSTM-CRF model for the lighting data knowledge extraction task, and has better accuracy and effectiveness. This method effectively improves the reliability and intelligent level of fault diagnosis of lighting system.
Keywords
Introduction
Lighting is an important part of the smart city, good maintenance and even fault prediction has become a necessary part of the normal use of the system [1]. At the same time, the lighting industry is the object of intelligent transformation and upgrading in the era of “Industry 4.0”, the volume and complexity of the lighting system are increasing, and the data of the lighting industry is growing rapidly. However, the traditional fault diagnosis method not only requires high professionalism of fault analysts, but also requires fault analysts to repeatedly review and memorise a large amount of unstructured text information, such as fault diagnosis work orders and maintenance manuals, which wastes a lot of manpower and time. Therefore, this method of relying on human labour to carry out fault diagnosis of the lighting system is no longer able to meet the demand [2]. Secondly, the intelligent level of lighting system troubleshooting is not high, and it does not have the ability of big data analysis, and there is no good data processing and analysis platform for the growing industrial big data, which results in low efficiency and difficulty of lighting system troubleshooting [3]. With the introduction of artificial intelligence technology to make the fault diagnosis of the efficiency of a substantial increase in the knowledge graph technology as an important means of big data analysis and mining, can provide technical support for intelligent upgrading and transformation of the lighting industry [4].
In this paper, for the problems in lighting system faults, deep learning method is used to construct a knowledge graph of lighting system fault diagnosis, and combined with the deduction grid algorithm to establish a fault diagnosis rule module. The use of knowledge graph on big data strong knowledge association and analysis ability, improve the intelligent level of lighting system fault diagnosis.
Current status of the study
Current status of lighting system fault diagnosis research
Failure of a lighting system refers to a reduction in the functional level of the system due to deviation of its performance parameters from normal values during actual operation, and when a serious failure occurs in a city’s lighting system, it may result in traffic jams and disruption of social order. Therefore, it is crucial to find possible faults in the lighting system in time and maintain it, and lighting system fault diagnosis can effectively prevent major failures and reduce economic losses. General lighting control systems are designed only to reduce energy consumption and prevent energy waste, but do not integrate the fault diagnosis function in the lighting control system, which lacks an important link to ensure the normal operation of the lighting system and verify its reliability.
Literature [5, 6, 7, 8, 9, 10] has proposed improvements to fault detection methods, but with the increasing complexity and scale of the lighting system, the equipment network is more complex and large, and it is difficult to determine the type of faults and the exact location of the faults at the first time when new faults are generated in the system and the historical data in the lighting system can not be effectively used to analyse and mine, and does not have the function of providing solutions for fault maintenance. As the lighting system fault diagnosis can not only timely find the current system faults and equipment abnormalities, but also to be able to extract effective information from the massive amount of data generated by the system, analyse the causes of the faults and put forward practical solutions for the maintenance of the system.
Knowledge graph can effectively extract the correlation relationship between data and continuously update it with newly generated data, thus maintaining the reliability of the system [11]. At present, there is no research content combining knowledge mapping and lighting system fault diagnosis in the lighting field, but this paper draws on the analysis of knowledge mapping research in other fields of fault diagnosis, and applies knowledge mapping technology to the field of lighting system fault diagnosis, which is able to efficiently process, deal with, and integrate the experience of experts, historical fault information, fault principles, and solutions, and effectively solve the problems of complex structure, huge scale, massive data, and multi-source faults of lighting system, so as to improve the reliability of the lighting system. The application of knowledge graph technology in the field of lighting system fault diagnosis can effectively process, process and integrate experts’ experience, historical fault information and solutions, and effectively solve the problems of complex structure of lighting system, large scale, massive data and multi-source faults, so as to improve the intelligent level of lighting system fault diagnosis.
Current status of knowledge mapping research
Knowledge graph is a structured semantic knowledge base, which is essentially a structured network storing knowledge entities and the relationships between them, capable of describing and understanding entities and their interrelationships in the physical world in the form of symbols, and therefore the knowledge graph has a strong descriptive capability for data [12]. The construction of knowledge graph is an iterative updating process, including three stages of knowledge extraction, knowledge fusion and knowledge storage, which requires the application of various information processing technologies and tools such as machine learning algorithms, deep learning models and graph databases [13].
The main goal of knowledge extraction is to extract knowledge, and the resulting knowledge needs to be in a machine-readable and machine-interpretable format, which is the basis for constructing a knowledge graph [14]. Knowledge extraction methods mainly include rule- and template-based methods, machine learning-based methods and deep learning-based methods. Among them, rule- and template-based knowledge extraction methods mainly adopt manual writing of rules and templates for extraction, which is very mature in research and practical application, but relies heavily on domain experts to write specific rules and templates manually, which not only consumes a lot of manpower and time, but also has very low portability and generalisation, and cannot be adapted to different domains [15]. The machine learning based methods mainly use the labelled data for model training, but the machine learning based methods have feature extraction errors and produce the problem of error propagation, so the deep learning based methods are beginning to be applied to knowledge extraction, which not only improves the ability of automated acquisition of big data for constructing knowledge graphs, but also promotes the enhancement of the scale of knowledge [16]. In summary, the application of knowledge graph technology to the lighting field, the use of deep learning methods to build a knowledge graph of lighting system fault diagnosis, and the establishment of fault diagnosis rule module to achieve data-driven fault diagnosis applications, can help to improve the intelligent level of lighting system fault diagnosis [17].
Therefore, in this paper, we create a dataset for the national standard documents of the lighting industry, troubleshooting work orders, experts’ experience and system operation status, construct and train the BERT-BiLSTM-CRF model for knowledge extraction, build a module of troubleshooting rules by using the inferred lattice algorithm, and then store and visualize the knowledge graph of lighting system troubleshooting based on the Neo4j graph database. display, and finally realized the intelligent fault diagnosis application of lighting system driven by data.
Troubleshooting data sources and characteristics
Troubleshooting scenarios and data sources
Troubleshooting refers to the process of judging the type of fault, fault location and cause of fault in the abnormal situation of lighting system operation, and finally giving solutions to make the system return to normal. In this paper, from the perspective of whether the type of fault is clear and unambiguous, the lighting system in the actual operation of the need for fault diagnosis of the scene is divided into two cases:
The type of fault is clear. Failure analysts still need to analyse the causes of the failure and provide solutions by consulting relevant documents and combining experience. In this case, the data source of fault diagnosis mainly includes the basic information of each device in the system, national standard documents of the lighting industry, fault diagnosis work orders and different types of data such as the experience of experts. Fault type unknown. Lighting system can not work properly under unknown circumstances, may be caused by a variety of factors, fault analysts need to analyse the possible types of faults one by one according to the system operation data, and finally determine the exact location of the fault and give solutions. Therefore, the state information and operating parameters of each device during the operation of the lighting system will be the key data to be analysed, and according to what rules to determine whether the lighting system is malfunctioning or not is the key issue for fault diagnosis in this case.
Based on the above analysis, this paper divides the lighting system fault diagnosis data into two parts, as shown in Fig. 1. The first part is the data used to construct the lighting system fault diagnosis knowledge graph, through the knowledge graph can be a large number of multi-source heterogeneous data can be effectively organised together; the second part is used to determine whether the system failure of the system in real time system state information and operation data, the use of rules module to judge these data to get the system fault type.
Data related to lighting system fault diagnosis.
The data used to construct the lighting system fault diagnosis knowledge graph in the first part are structurally divided into three categories, including (semi-)structured data and unstructured data. Structured and semi-structured data mainly refer to the basic information of devices and device binding relationships in the lighting system, which are mainly in the form of tables and data in JSON format; unstructured data mainly refer to text-type data such as national standard documents of the lighting industry, troubleshooting work orders, and experts’ experiences. The unstructured data mainly refers to text-type data such as lighting industry national standard documents, troubleshooting work orders and expert experience. The lighting industry national standard documents are the current lighting safety standard documents related to lighting system troubleshooting that have been screened; the troubleshooting work orders record the daily maintenance of the lighting system, formulate the solutions to the various faults and form the text-format data; and the expert experience mainly consists of experience and knowledge of the lighting experts and the lighting system troubleshooting analysts in the daily maintenance of the lighting system. The second part is used to determine whether the system is faulty in real time. The second part is (semi-)structured data for real-time judgement of whether the system is faulty or not, mainly in JSON format, which mainly includes the equipment status information and operation-related parameters obtained during the operation of the lighting system.
Based on the analysis of the lighting system troubleshooting scenarios and data sources in Section 3.1, the data were found to have the following characteristics:
The data come from a variety of sources and have different main uses and scenarios. Part of it is used to construct a knowledge graph for lighting system fault diagnosis, while the other part is used to determine whether the system is malfunctioning in real time through the fault diagnosis rule module. The composition of data is complex and includes three categories: structured data, semi-structured data and unstructured data. There are no datasets related to fault diagnosis in the field of lighting that can be used directly in academia or industry, so there is a need to produce targeted datasets applicable to fault diagnosis in lighting systems.
In this paper, after fully considering the characteristics of lighting system troubleshooting data, the YEDDA tool is used to filter and annotate the collected data to produce a lighting system troubleshooting related dataset. The entity categories defined in this paper are shown in Table 1, which contains a total of four named entity categories: equipment (Equipment), fault name (Fault), fault reason (Reason) and solution (Solve). The BIO annotation system is used for the definition, and each word vector is labeled as “B-X”, “I-X” or “O”. Where “X” denotes different categories, “B” denotes the start position of an entity, “I” denotes the middle or end position of an entity, and “O” denotes a non-entity, making a total of nine types of labels. Finally the lighting system troubleshooting knowledge extraction dataset was produced.
Entity categories and labels
Overall architecture of fault diagnosis knowledge graph
Knowledge graph can be divided into two levels according to its logical structure: schema layer and data layer [18] Among them, the data layer is expressed in the form of (head entity, relationship, tail entity), i.e.
In order to construct a high-quality knowledge graph for lighting system troubleshooting, this paper adopts a hybrid knowledge graph construction method, and the construction process is shown in Fig. 2. Firstly, the top-down approach is adopted, combining the professional vocabulary and expert knowledge in the field of lighting, and the pattern layer is constructed for the overall architecture of the lighting system and the needs of troubleshooting, so as to guide the extraction of knowledge and construct the data layer; then the bottom-up approach is adopted, and the knowledge extraction is carried out by using the method of deep learning, and the ternary obtained by the extraction is mapped to the relevant concept nodes, which can supplement and update the pattern layer of the knowledge graph; finally, the construction and improvement of the knowledge graph of lighting system troubleshooting is realised. pattern layer; and finally realise the construction and improvement of the knowledge graph of lighting system fault diagnosis.
Construction method of lighting system fault diagnosis knowledge graph.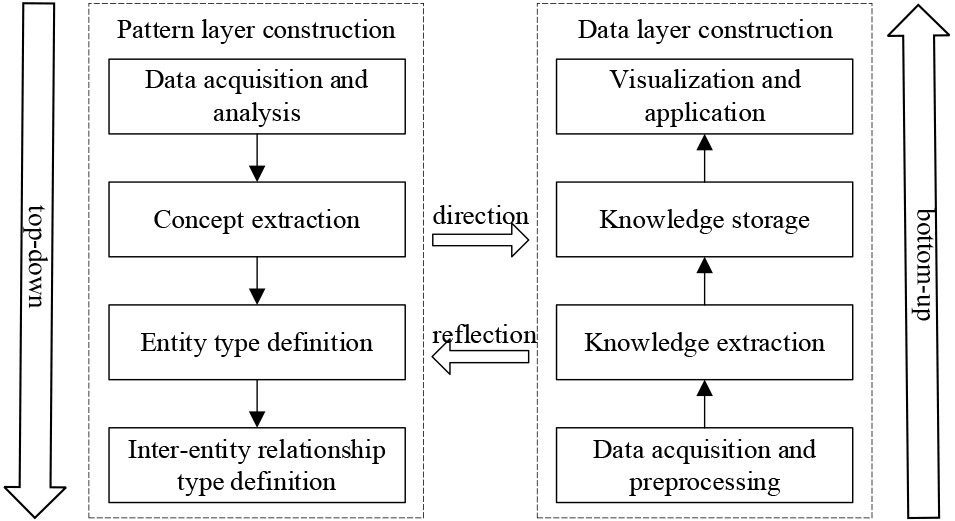
First, the overall architecture of the lighting system is analyzed to determine the networking mode between devices, and the schema layer of the knowledge graph is designed in a top-down manner for the information of troubleshooting work orders, national standard documents on lighting safety and equipment operation data to determine the devices included in the lighting system, the binding relationship between devices, and the possible failures of the devices, the causes of the failures and the solutions. Then, under the guidance of the schema layer, the bottom-up approach is used to construct the data layer, construct the BERT-BiLSTM-CRF model and use the fault diagnosis dataset to train the model, use the trained model to extract knowledge from the lighting system fault diagnosis data, and form the entity and relationship triples to be finally stored in the Neo4j graph database. While the schema layer guides and specifies the data layer, the data layer simultaneously complements and updates the schema layer.
The schema layer is the knowledge organisation structure of the lighting system troubleshooting knowledge graph, which mainly describes the relationship information between entities and entities within the lighting system through the form of concepts. The schema layer of the knowledge graph is generally stored in the ontology library, where ontology refers to the conceptual template of the knowledge, which has the advantages of a strong hierarchical structure and a small degree of redundancy. In this paper, under the guidance of experts in the field of lighting, combined with the actual situation of lighting system troubleshooting, we analyse the national standard documents of the lighting industry, the basic information of each device in the system, the troubleshooting work orders and other data, and refine the types of concepts, the relationships between concepts and the relevant attributes that are meaningful in lighting system troubleshooting, so as to form the schema layer of the lighting system troubleshooting knowledge mapping.
Schema layer of lighting system fault diagnosis knowledge graph.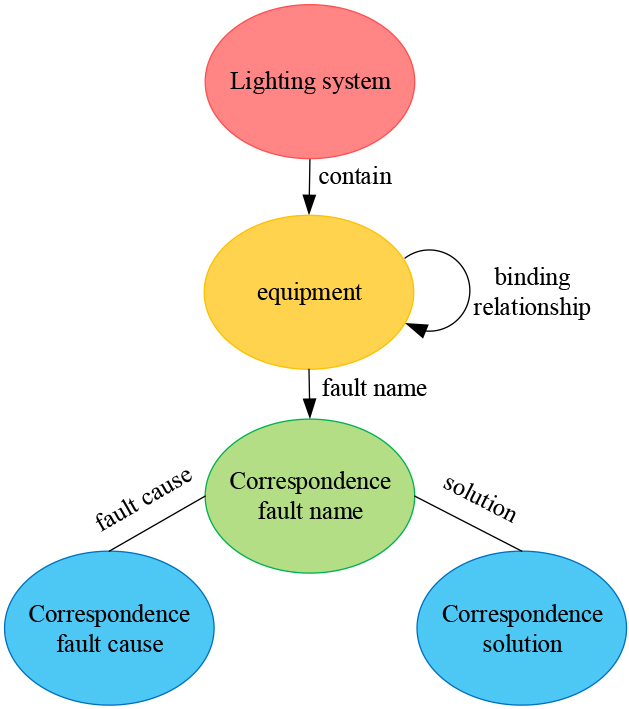
The lighting system fault diagnosis knowledge mapping schema layer is shown in Fig. 3, which mainly consists of each device included in the lighting system, the corresponding fault name, the corresponding fault cause, the corresponding solution, and the interrelationship between them.
The concept of “lighting system”, as the centre of the schema layer, is the core of the knowledge graph for lighting system fault diagnosis. In practice, a lighting system usually contains many various types of lighting equipment and management control equipment, which are defined as “equipment” in the schema layer. Therefore, the concept of “lighting system” and the concept of “device” naturally belong to the inclusion relationship. Each management and control device may carry multiple lighting fixtures, e.g., a DALI gateway may carry up to 64 fixtures, which are bound to the DALI gateway. Therefore, there should be a binding relationship between “devices” in the schema layer, and this binding relationship between devices can also better respond to the occurrence of faults when the fault location to accurately locate the fault, thereby reducing the difficulty of troubleshooting.
Each device has its corresponding faults, and these faults are unified and abstracted into the concept of “corresponding fault name”, so the relationship between the concept of “device” and the concept of “corresponding fault name” is called fault name. Therefore, when the concept of “equipment” points to the concept of “corresponding fault name”, the relationship is called fault name. The significance of the lighting system fault diagnosis knowledge graph is not only to indicate that a fault has occurred in a device, but also to point out the cause of the fault and the corresponding solution. Therefore, the schema layer also contains the concepts of “corresponding fault cause” and “corresponding solution”. The concept of “corresponding fault name” points to the concept of “corresponding fault cause” as the relationship of fault cause, and the concept of “corresponding fault name” points to the concept of “corresponding solution” as the relationship of solution. The concept of “corresponding solution” points to the concept of “corresponding cause” as the relationship of the cause of the fault, and the concept of “corresponding fault name” points to the concept of “corresponding solution” as the relationship of the solution.
The concepts in the schema layer are extracted and abstracted from the entities in the data layer, and the relationships between the schema layer concepts also provide guidance for the relationships between the entities in the data layer [20]. Therefore, in this section, under the guidance of the schema layer of the knowledge graph, a deep learning approach is used to extract knowledge from the data related to lighting system troubleshooting so as to construct the data layer of the knowledge graph from the bottom up. Knowledge extraction generally includes two parts, entity extraction and relationship extraction [21], because lighting system fault diagnosis belongs to a specific domain, in which the types of relationships between entities are characterised by a limited number, and this paper constructs the schema layer of the knowledge graph in Section 4.2, which can provide a basis and a normative role for the types of inter-entity relationships in the data layer. Therefore, this paper optimises the knowledge extraction work when the types of inter-entity relationships are determined, and builds the BERT-BiLSTM-CRF model to focus on the extraction of entities in the troubleshooting-related data using deep learning, which is also called the named entity recognition task in the field of Natural Language Processing, so as to improve the accuracy of the entity recognition in the data layer, and to make the constructed Lighting System Troubleshooting knowledge graph more clear and explicit.
One of the more mainstream models in named entity recognition tasks is the BiLSTM-CRF model, which was first proposed by Lample et al. 2016.The BiLSTM-CRF model mainly consists of three layers, namely Word Embedding, BiLSTM and CRF [22]. Although the experimental results of Lample et al. show that the predictive effect of the BiLSTM-CRF model in the named entity recognition task has exceeded that of the CRF model, the direct use of the model in the named entity recognition task of lighting system fault diagnosis does not work well. The main reason is that the Chinese corpus is in a different form from the English corpus, the Chinese sentences do not have clear word boundaries, so it is necessary to transform the vectors for each word in the Word Embedding layer, and the lighting domain has a large number of jargons, and there is a lack of a unified Chinese annotation dataset, which all these problems greatly increase the difficulty of feature vector extraction [23].
Introducing the pre-trained language model into the neural network can improve the sequence labelling performance of the model [24], so in this paper, for the characteristics of the lighting system fault diagnosis data, we improve on the BiLSTM-CRF model by introducing the BERT pre-trained language model as the feature representation layer in the Word Embedding layer, and propose a BERT-BiLSTM-CRF model-based The BERT model is different from the traditional unidirectional language model in that it is based on the mechanism of bi-directional attention so that the context in the text is well captured in both directions, thus providing a strong guarantee for the subsequent tasks. The structure of previous pre-trained models is limited by the unidirectional language model, which can only capture the text information in one direction, resulting in a poor representation ability of the model. The BERT model adopts a deep bi-directional transformer structure to build the whole model and uses a new masked language model for pre-training, so it can integrate the deep feature information of the text context and has the ability of bi-directional linguistic representation, and can be quickly tuned with a small number of labelled samples of the model parameters under the new training task.
In 2018, Devlin et al. of Google AI proposed a pre-trained language model BERT (Bidirectional Encoder Representations from Transformers, BERT) model by combining Transformer’s encoder and bi-directional language model [25], whose structure is shown in Fig. 4 is shown. In terms of language model training, the BERT model performs the two tasks of Masked token prediction and Next sentence prediction as the training objectives, so that the BERT model can learn the deep semantic information in the text, so as to express the text at a high level of abstraction.
Structure of BERT model (trm for transformer).
In this paper, the BERT model is introduced as the feature representation layer on the basis of BiLSTM-CRF model, thus the BERT-BiLSTM-CRF model is constructed for knowledge extraction in the lighting domain, with the following two main advantages:
The BERT model maps the text into a low-dimensional dense real-valued vector space so that each dimension can represent a potential syntactic or semantic feature, and thus can represent each word in the text related to lighting system troubleshooting as a vector for a higher-level and more abstract expression, effectively solving the problem of the BiLSTM-CRF model in extracting knowledge in the lighting domain. effectively solves the problem of the BiLSTM-CRF model in extracting lighting domain knowledge, which is difficult to capture the deeper semantic information within the Chinese corpus; The BERT model has a powerful migration capability, and a variety of downstream tasks can be done by combining the pre-trained BERT model with other models. In this paper, adding BiLSTM-CRF model to the pre-trained BERT model for fine-tuning not only reduces the amount of annotated samples required for tuning the model parameters, but also fully understands the semantic information of the professional terms in the lighting domain, which makes the knowledge extraction results of the text of the lighting system fault diagnosis more accurate and effective.
The BERT-BiLSTM-CRF model consists of three models, BERT, BiLSTM and CRF, and the overall model structure is shown in Fig. 5.
Firstly, the text related to lighting system troubleshooting is inputted into the feature representation layer of the BERT model, and the important features of the text are extracted by combining the contextual information, and each word in the sentence is mapped into a word vector
Structure of BERT-BiLSTM-CRF model.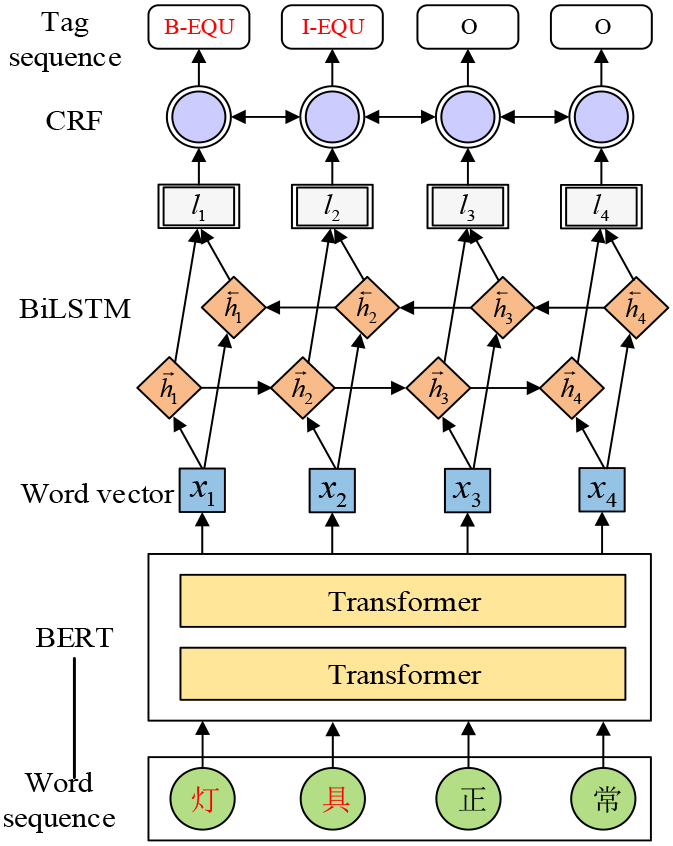
Finally, the tag sequence output from the BiLSTM model is processed using the CRF model. The CRF model takes into account the influence of the front and back tags can take into account the logic and order of the entities, for example, the tag B-EQU tags will not be followed by the tag I-REA tags, so as to obtain a globally optimal sequence of the entity category tags, which can further improve the accuracy of the named entities.
Using the BERT-BiLSTM-CRF model for knowledge extraction of data related to lighting system troubleshooting is a method that combines deep learning models with machine learning models, which not only solves the problem that the CRF model needs to manually extract textual features and cannot extract long textual features, but also solves the problem that the BiLSTM model performs poorly in the professional vocabulary of the lighting domain as well as in the entity extraction of Chinese datasets. extraction.
Experimental design and evaluation indicators
In order to verify the effectiveness of the knowledge extraction model constructed in this paper, the daily maintenance work orders of a lighting company, national standard documents of the lighting industry and expert experience documents are used as experimental objects, firstly, the YEDDA tool is used to produce the lighting system fault diagnosis dataset, and then the dataset file in .anns format is saved as a .txt file, and finally, the data for training the BERT-BiLSTM- CRF model for lighting system fault diagnosis named entity recognition task with a total of 7890 data. The dataset was randomly divided into training set, validation set and test set in the ratio of 7:2:1 for model training and testing.
The hardware environment for the experiment was 64-bit Windows 10 operating system, AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz processor, 16 GB RAM, and NVIDIA GeForce RTX 3060 graphics card. The software environment is TensorFlow 2.5.0 framework with Python 3.7.4 programming language for algorithm design. In the BERT-BiLSTM-CRF model, the number of Transformer layers of the Chinese language model pre-trained with BERT is 12, the dimension of hidden layer is 768, the number of multi-attention is 12, and the size of the total number of parameters is 110 M. Specific model training parameters are configured as shown in Table 2.
Parameters configuration
Parameters configuration
In order to verify the effect of the improved algorithm, the evaluation indexes used in this paper include Precision (P), Recall (R) and the comprehensive evaluation index
Among them,
Explanations related to evaluation indicators
The BERT-BiLSTM-CRF model proposed in this paper is trained and applied to the task of knowledge extraction of lighting system fault diagnosis data with BiLSTM-CRF model and BiLSTM model, and compared and analysed according to the experimental results. The performance comparison of each model is shown in Fig. 6, where Fig. 6(a) shows the loss curve of each model and Fig. 6(b) shows the accuracy curve of each model. Analysing Fig. 6, it can be seen that the BERT-BiLSTM-CRF model constructed in this paper has a loss value close to 0 when the epoch is 30, and the accuracy is close to 1 when the epoch is 20, so the model constructed in this paper can achieve a lower loss value with fewer epoch iterations, and it can obtain a higher accuracy rate quickly.
Experimental results of each model (%)
Experimental results of each model (%)
The specific experimental results are shown in Table 4, the model knowledge extraction method constructed in this paper improves the precision rate by 17.58%, the recall rate by 11.65%, and the
Comparison of each model performance.
Troubleshooting rules module
By adopting the deep learning method to extract knowledge from the basic information of each device in the lighting system, national standard documents of the lighting industry, troubleshooting work orders and expert experience, the knowledge graph of lighting system troubleshooting is constructed, which can assist the fault analysts to carry out lighting system troubleshooting, analyse the causes of faults according to the fault names, provide solutions to the faults and realise the faulty devices. Rapid positioning of faulty equipment. In this paper, in order to further improve the intelligent level of lighting system fault diagnosis and reduce the involvement of personnel in the process, the algorithm for determining the cause of the fault is integrated into the lighting system fault diagnosis knowledge graph and combined with the deduction grid algorithm, a fault diagnosis rule module is established, which is used for real-time judgement of whether a fault occurs in the lighting system and generates a fault descriptive language, realizing the data-driven intelligent fault diagnosis application.
The fault causes that account for a relatively high percentage of faults in the lighting system are selected to set the judgement rules in this paper as shown in Table 5, including nine fault causes such as loss of voltage, phase breakage, three-phase load imbalance, and so on. According to the definition and judgement methods of these faults in the lighting field, combined with the knowledge graph and the deduction grid algorithm to improve, forming the rule module of lighting system fault diagnosis in this paper.
When judging the possible faults of the lighting system, there is a sequence between the steps of the judgement algorithm for each fault cause. In this paper, the sequential relationship between the steps of these judgement algorithms is organised into the form of ternary groups and integrated into the lighting system fault diagnosis knowledge graph, and then the rule reasoning process is improved by combining the deduction grid algorithm with the lighting system fault diagnosis knowledge graph, and the steps of the fault cause judgement algorithms are fused and optimised, and a complete fault diagnosis rule module is formed in the end.
Rules for determining faults
Rules for determining faults
Algorithm flow chart of fault diagnosis rule module.
The deduction lattice algorithm is an intelligent and efficient partial order inference model [27], and the inference rules include the following three points.
If
If
Before the use of deduction grid algorithm optimisation, usually each kind of fault needs to establish a judgement algorithm to carry out the diagnosis of the fault, however, due to the fact that the judgement algorithms of these fault causes are independent of each other, it is necessary to judge each algorithm one by one in the actual use of the algorithms, so it will produce a large amount of repetitive work, resulting in the judgement of the speed of the slow speed, which affects the speed of the fault diagnosis of the lighting system.
Flow chart of lighting system fault diagnosis.
After optimising the fault judgement algorithm by combining the deduction lattice algorithm with the fault diagnosis knowledge graph, the algorithm flow of the established fault diagnosis rule module is shown in Fig. 7, and the optimised algorithm reduces the redundant judgement steps and improves the speed of the lighting system fault diagnosis. Combining the deduction grid algorithm with the knowledge graph, making full use of the powerful relational expression capability of the knowledge graph, the established fault diagnosis rule module can judge whether the lighting system is faulty or not in real time by obtaining data such as the equipment state information generated during the operation of the lighting system, realizing the conversion from data to the descriptive language of faults, thus reducing the involvement of personnel in the fault diagnosis process, and realizing the data-driven lighting system fault diagnosis application. The application of data-driven lighting system fault diagnosis.
The constructed lighting system fault diagnosis knowledge graph is stored and visualised in the graph database Neo4j. The process of applying the lighting system fault diagnosis knowledge graph for fault diagnosis is shown in Fig. 8. Firstly, obtain the state information and operation-related parameter data of the equipment in the running lighting system, which are mainly semi-structured data in JSON format, recording the parameters such as voltage, current and power of the equipment; then input these data into the constructed fault diagnostic rule module to determine whether the system is faulty and output the name of the fault; finally, use Neo4j’s Finally, using Neo4j’s Cypher query statement to search the fault name in the knowledge graph, when there is a corresponding fault in the lighting system fault diagnosis knowledge graph, not only can we query the exact location of the fault information, but also can directly get the cause of the fault and the solution. In addition, if the corresponding fault does not exist in the lighting system fault diagnosis knowledge graph, it is necessary to deposit the fault as new knowledge into the knowledge graph to update it, so that the knowledge graph provides a more accurate, comprehensive, real-time fault diagnosis basis. Finally, the updated knowledge graph is combined with the deduction lattice algorithm to achieve the updating and improvement of the fault diagnosis rule module.
Conclusion
In this paper, with the goal of realising intelligent fault diagnosis of lighting system, deep learning method is used to construct the knowledge graph of lighting system fault diagnosis, which improves the data analysis ability of lighting system. Then, a fault diagnosis rule module converted from system operation data to fault description language is established by combining the deduction lattice algorithm to realise a data-driven intelligent fault diagnosis application. Using the knowledge association and data analysis ability of knowledge graph, the key knowledge of lighting system fault handling is comprehensively grasped, which can help fault analysts to quickly locate faults and analyse the fault causes and solutions based on expert experience and historical maintenance information, and effectively improve the intelligent level of lighting system fault diagnosis.
The BERT-BiLSTM-CRF model constructed in this paper improves the accuracy rate by 17.58% over the BiLSTM-CRF model on the task of knowledge extraction from lighting data, which has better accuracy and effectiveness, and guarantees the reliability of lighting system fault diagnosis in practical applications. However, the shortcoming of this paper is that the fault cause diagnosis algorithm used does not cover all the faults involved in current lighting systems. In the subsequent research, with the actual operation of the lighting system, the lighting system fault diagnosis knowledge map and rule module will be continuously updated and improved, so as to improve its completeness and practicality.
Footnotes
Acknowledgments
The authors acknowledge the Shaanxi Province Key R&D Programme Project (No. 2023-YBGY-208), the Shenzhen Science and Technology Programme (No. JSGG20210802154545031), Shaanxi Provincial Education Department Service local special Plan project (No. 23JC016).