
Abstract
Data owners are expected to disclose micro-data for research, analysis, and various other purposes. In disclosing micro-data with sensitive attributes, the goal is usually two fold. First, the data utility of disclosed data should be maximized for analysis purposes. Second, the private information contained in such data must be to an acceptable level. Typically, a disclosure algorithm evaluates potential generalization functions in a predetermined order, and then discloses the first generalization that satisfies the desired privacy property. Recent studies show that adversarial inferences using knowledge about such disclosure algorithms can usually render the algorithm unsafe. In this paper, we show that an existing unsafe algorithm can be transformed into a large family of safe algorithms, namely, k-jump algorithms. We then prove that the data utility of different k-jump algorithms is generally incomparable. The comparison of data utility is independent of utility measures and syntactic privacy models. Finally, we analyze the computational complexity of k-jump algorithms, and confirm the necessity of safe algorithms even when a secret choice is made among algorithms.
Introduction
The issue of preserving privacy in micro-data disclosure has attracted much attention lately [24]. Data owners, such as the Census Bureau, may need to disclose micro-data tables containing sensitive information to the public to facilitate useful analysis. There are two seemingly conflicting goals during such a disclosure. First, the utility of disclosed data should be maximized to facilitate useful analysis. Second, the sensitive information about individuals contained in the data must be to an acceptable level due to privacy concerns.
A micro-data table and three generalizations
A micro-data table and three generalizations
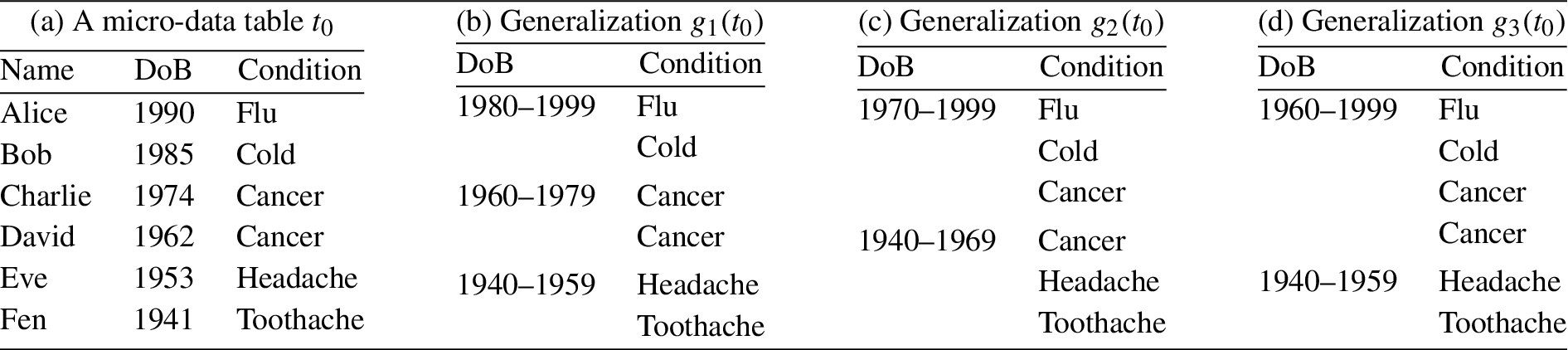
To prevent such a linking attack, the micro-data table can be partitioned into anonymized group and then generalized to satisfy k-anonymity [39,42]. Table 1(b) shows a generalization
Nonetheless, k-anonymity by itself is not sufficient since linking a person to the second group in
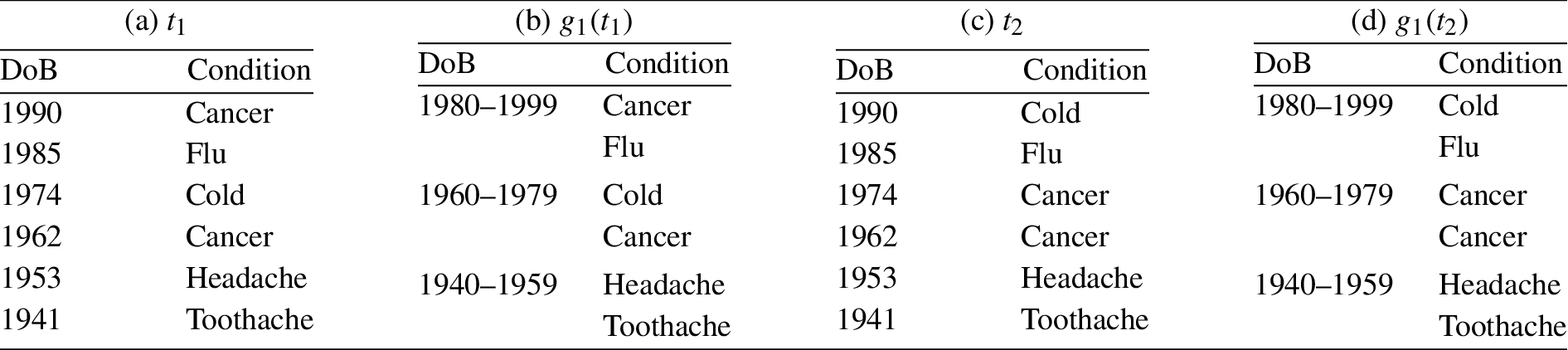
Two tables in the permutation set and their corresponding generalizations under
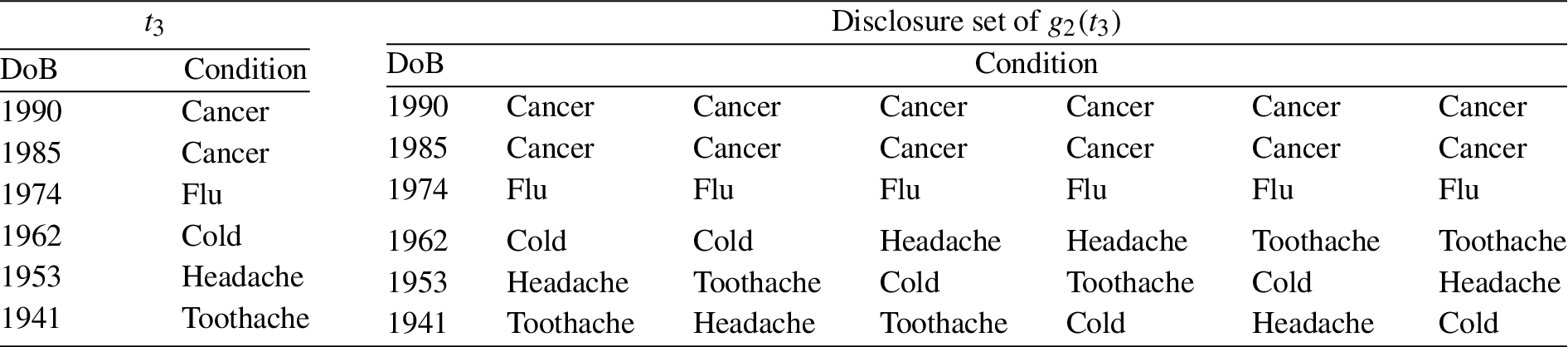
The disclosure set of
A table
The contribution of this paper is three fold. First, we show that a given generalization algorithm can be transformed into a large family of distinct algorithms under a novel strategy, called k-jump strategy. Intuitively, the k-jump strategy penalizes cases where recursion is required to compute the disclosure set. Therefore, algorithms may be more efficient under the k-jump strategy in contrast to the above safe strategy. Second, we discuss the computational complexity of such algorithms and prove that different algorithms under the k-jump strategy generally lead to incomparable data utility (which is also incomparable to that of algorithms under the above safe strategy). This result is somehow surprising since the k-jump strategy adopts a more drastic approach than the above safe strategy. Third, the result on data utility also has a practical impact. Specifically, while all the k-jump algorithms are still publicly known, the choice among these algorithms can be randomly chosen and kept secret, analogous to choosing a cryptographic key. We also confirm that the choice of algorithms must be made among safe algorithms. Furthermore, the family of our algorithms is general and independent of the syntactic privacy property and the data utility measurement. Note that in this paper we focus on the syntactic privacy properties which has been evidenced as complementary and indispensable to the semantic notion of privacy, such as differential privacy [9,33].
The preliminary version of this paper has previously appeared in [35]. In this paper, we have substantially improved and extended the previous version. The most significant extensions include the computational complexity analysis of k-jump algorithms by mathematical induction (Section 6), the confirmation on the necessity of safe algorithms by demonstrating that secret choice among unsafe algorithms cannot ensure the privacy (Section 7). In addition, we also further elaborate the preliminary results in [35], such as the proofs in Section 5.
The rest of the paper is organized as follows. Section 2 reviews related work. Section 3 gives our model of two existing algorithms. Section 4 then introduces the k-jump strategy and discusses its properties. Section 5 presents our results on the data utility of k-jump algorithms. We analyze the computational complexity of k-jump algorithms in Section 6, and confirm that the secret choice must be made among safe algorithms such as the family of k-jump algorithms in Section 7. Section 8 concludes the paper.
Privacy-preserving micro-data disclosure
The micro-data disclosure problem has received significant attention lately [10,11,18,23,24,41,43]. Various generalization techniques and models have been proposed to transform a micro-data table into a safe version that satisfies given privacy properties and retains enough data utility. In particular, data swapping [13,16,20] and cell suppression [12] both aim to protect micro-data released in census tables, but those earlier approaches cannot effectively quantify the degree of privacy. A measurement of information disclosed through tables based on the perfect secrecy notion by Shannon is given in [38]. The authors in [15] address the problem ascribed to the independence assumption made in [38]. The important notion of k-anonymity has been proposed as a model of privacy requirement [39]. The main goal of k-anonymity is to anonymize the data such that each record owner in the resultant data is guaranteed to be indistinguishable from at least
Since the introduction of k-anonymity, privacy-preserving data publishing has received tremendous interest in recent years. A model based on the intuition of blending individuals in a crowd is proposed in [7]. A personalized requirement for anonymity is studied in [46]. In [6], the authors approach the issue from a different perspective, that is, the privacy property is based on generalization of the protected data and could be customized by users. Much efforts have been made around developing efficient k-anonymity algorithms [2 –5,19,30,39], whereas the safety of the algorithms is generally assumed. Many more advanced models are proposed to address limitations of k-anonymity. Many of these focus on the deficiency of allowing insecure groups with a small number of sensitive values. For instance, l-diversity [36] requires that each equivalence class on the disclosed table should contain at least l well-represented sensitive values; t-closeness [31] requires that the distribution of a sensitive attribute in any equivalence class is close (roughly equal) to the distribution of the attribute in the whole table;
The case when disclosure algorithms is publicly known
While most existing work assume the disclosed generalization to be the only source of information available to an adversary, recent work [44,50] shows the limitation of such an assumption. In addition to such information, the adversary may also know about the disclosure algorithm. With such extra knowledge, the adversary may deduce more information and finally compromise the privacy property. In the work of [44,50], the authors discover the above problem and correspondingly introduce models and algorithms to address the issue. However, the method in [44] is still vulnerable to algorithm-based disclosure [25,26], whereas the one in [50] is more general, but it also incurs a high complexity.
In [50], Zhang et al. presented a theoretical study on how an algorithm should be designed to prevent the adversary from inferring private information when the adversaries know the algorithm itself. The authors proved that it is NP-hard to compute a generalization which ensure privacy while maximizing data utility under such assumptions of adversaries’ knowledge. The authors then investigate three special cases of the problem by imposing constraints on the functions and the privacy properties, and propose a polynomial-time algorithm that ensures entropy l-diversity.
Wong et al. in [44] showed that a minimality attack can compromise most existing generalization techniques with the aim of only a small amount of knowledge about the generalization algorithm. The authors assume that the adversaries only have one piece of knowledge that the algorithm discloses a generalization with best data utility. Under this assumption, minimality attacks can be prevented by simply disclosing sub-optimal generalizations. Unfortunately, the adversaries, equipped with knowledge of the algorithm, can still devise other types of attacks to compromise sub-optimal generalizations.
Since the problem is discovered, some work have been developed to tackle the problem in the case that l-diversity is the desired privacy property [26,34,48,52]. For example, [26] defines a new privacy model, namely, Algorithm-SAfe Publishing (ASAP), to capture and eliminate threats when the algorithm is publicly known. Global look-ahead and local look-ahead are then proposed to be integrated in the existing solutions to achieve ASAP. The authors also propose a post-process to enhance data utility.
To protect the individual privacy, the data owners may have different methods of anonymizing the original table. While there exist other techniques in the literature which are efficient for some privacy property, such as, anatomy [47] for l-diversity, in this paper, we focus on grouping-and-breaking, which partitions the records into anonymized groups and break the linkage between the quasi-identifier value and sensitive value inside each group by generalization. Our proposed family of algorithms is general to handle different syntactic privacy properties and different measures of data utility. Closest to this work, a special case of the k-jump strategy is discussed in [51] where all jumps end at disclosing nothing. Our result in this paper is more general than those in [51]. It is also worth noting that we substantially extend our previous version [35] by elaborating on the proofs, analyzing the computational complexity, and confirming the necessity of safe algorithms even when making the choice secret among the algorithms.
Privacy-preserving macro-data disclosure
In contrast to micro-data disclosure, aggregation queries are addressed in statistical databases [1,23,40]. The main challenge is to answer aggregation queries without allowing inferences of secret individual values. The auditing methods in [8,17] solve this problem by checking whether each new query can be safely answered based on a history of previously answered queries. The authors of [8,27,29] considered the same problem in more specific settings of offline auditing and online auditing, respectively.
Recently, a semantic privacy notation, differential privacy [21,22], has been accepted as one of the strongest privacy models for answering statistic queries. Differential privacy aims to achieve the goal that the probability distribution of any disclosed information should be similar enough regardless of whether that disclosed information is obtained using the real database, or using a database without any one of the existing records. However, while the qualitative significance of the privacy parameter is well understood in the literature, the exact quantitative link between this value and the degree of privacy guarantee has received less attention. Furthermore, although differential privacy is extended to privacy preserving data publishing (PPDP) [33,49], most existing approaches that ensure differential privacy are random noise-based and are suitable for specific types of statistical queries. It has also been evidenced that data analysis cannot replace PPDP in some situations, such as, large number of queries, diverse analysis tasks, and so on [9,32,33]. Moreover, Kifer and Machanavajjhala [28] disproved some popularized claims about differential privacy and showed that differential privacy cannot always guarantee the privacy in some cases. Due to these reasons, we focus on syntactic privacy properties in this paper and regard the differential privacy as future work.
The model
The notation table
The notation table
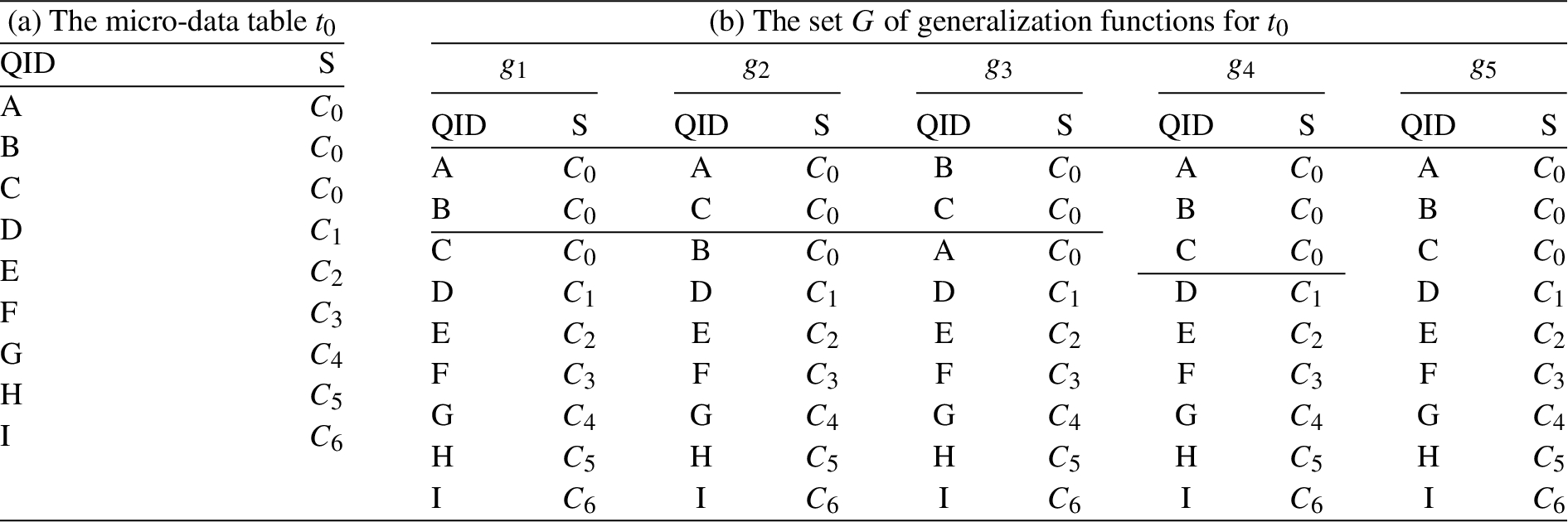
A secret micro-data table (or simply a table) is a relation
We are also given a generalization algorithm a that defines a privacy property
Note that in a real world generalization algorithm, a generalization function may take an implicit form, such as a cut of the taxonomy tree [44], illustrated as the dash-line in Fig. 1. Moreover, the sequence of generalization functions to be applied to a given table is typically decided on the fly. Our simplified model is reasonable as long as such a decision is based on the quasi-identifier (which is true in, for example, the Incognito [30], and the predetermined cuts of taxonomy trees as shown in Fig. 1), because an adversary who knows both the quasi-identifier and the generalization algorithm can simulate the latter’s execution to determine the sequence of generalization functions for the disclosed generalization.
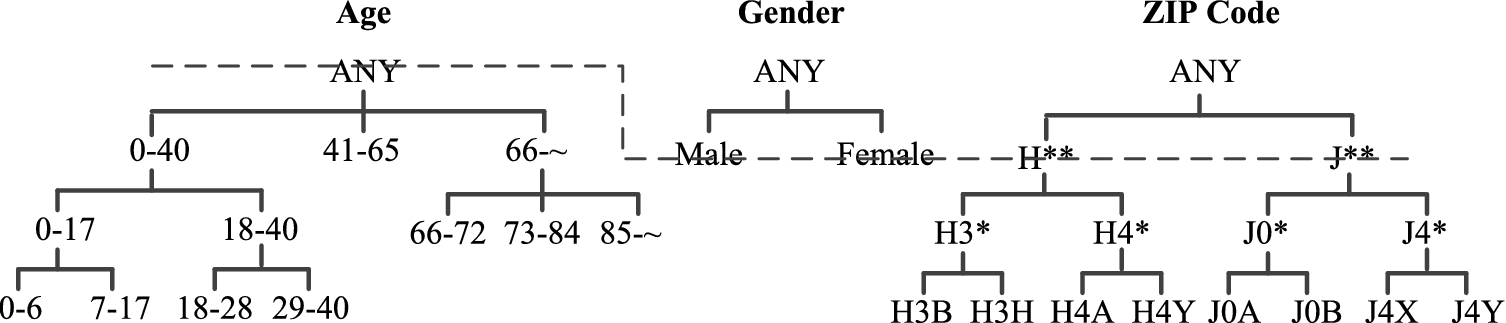
Taxonomy trees example: Age, Gender and ZIP Code.
When adversarial knowledge about a generalization algorithm is not taken into account, the algorithm can take the following naive strategy. Given a table
Before giving the detail of naive strategy, we first formalizes the set of all tables in T whose generalizations, under a given function, are identical with that of a given table in Definition 1.
(Permutation set).
Given a micro-data table
Note that
Next we introduce the evaluation path in Definition 2. Informally, evaluation path represents the sequence of evaluated generalization functions.
(Evaluation path).
Given a micro-data table
The algorithm
The algorithm

Unfortunately, the naive strategy leads to an unsafe algorithm as illustrated in Section 1 (that is, an algorithm that fails to satisfy the desired privacy property). Specifically, consider an adversary who knows the quasi-identifier
First, by only looking at the disclosed generalization
Clearly, any
Given a micro-data table
The algorithm
(outline)
The algorithm

Taking the adversary’s point of view again, when
It is worthy noting that, returning
Returning
First of all, we assume the given privacy property to be satisfied to an adversary who has no knowledge at all. For example, if the sensitive attribute has only two possible values in its domain (e.g., Gender), then 3-diversity can never be satisfied, even if the adversary has no knowledge at all about the original table.
We will focus on the worst case in which the adversary knows about following facts, and will discuss other cases later.
The data owner was planning to publish data. The data owner did not publish anything, because the algorithm The adversary has a working copy of the algorithm The adversary does not know
In such a case, we show that the adversary’s mental image about
More formally, we first define a new concept, the symmetric set of a micro-data table, as follows. Given a micro-data table
Then we have the following result: Given a generalization algorithm
The generalization algorithm
Given any table
For any
Therefore, if the domain of a sensitive attribute has totally m different values, then the adversaries with aforementioned knowledge can only infer that each record owner in the table has
Next, it is easy to see that other cases in which an adversary has less knowledge than in the above case will also be safe. For example, assume the adversary does not know that the data owner was planning to publish a table. In this case, when the data owner does not release anything, it may happen in two scenarios, which the adversary cannot distinguish:
The data owner did not plan to publish anything (the result of the algorithm may or may not be an empty set). The data owner plans to publish, but the algorithm returns empty set.
In case (A), it is obvious that the adversary would not gain any additional knowledge about the original table. For case (B), we have provided the proof above. Hence, when adversary cannot distinguish between the two cases, it is easy to show that his/her mental image will still satisfy the privacy property by following similar reasoning.
For another example, if the adversary does not know the number of records in
As discussed above, we need to evaluate the privacy property on the disclosure set (the adversaries’ mental image about the original table). Informally, we call an algorithm is safe if, when that algorithm disclose a generalization for any original table, the disclosure set of that disclosed generalization with regard to the original table satisfies the desired privacy property, as formally stated in Definition 4.
Given a generalization algorithm G composed of a sequence of generalization functions
The algorithm
(detail)
The algorithm

On the other hand, we can see that for computing
In this section, we first introduce the k-jump strategy in Section 4.1, and then discuss its properties in Section 4.2.
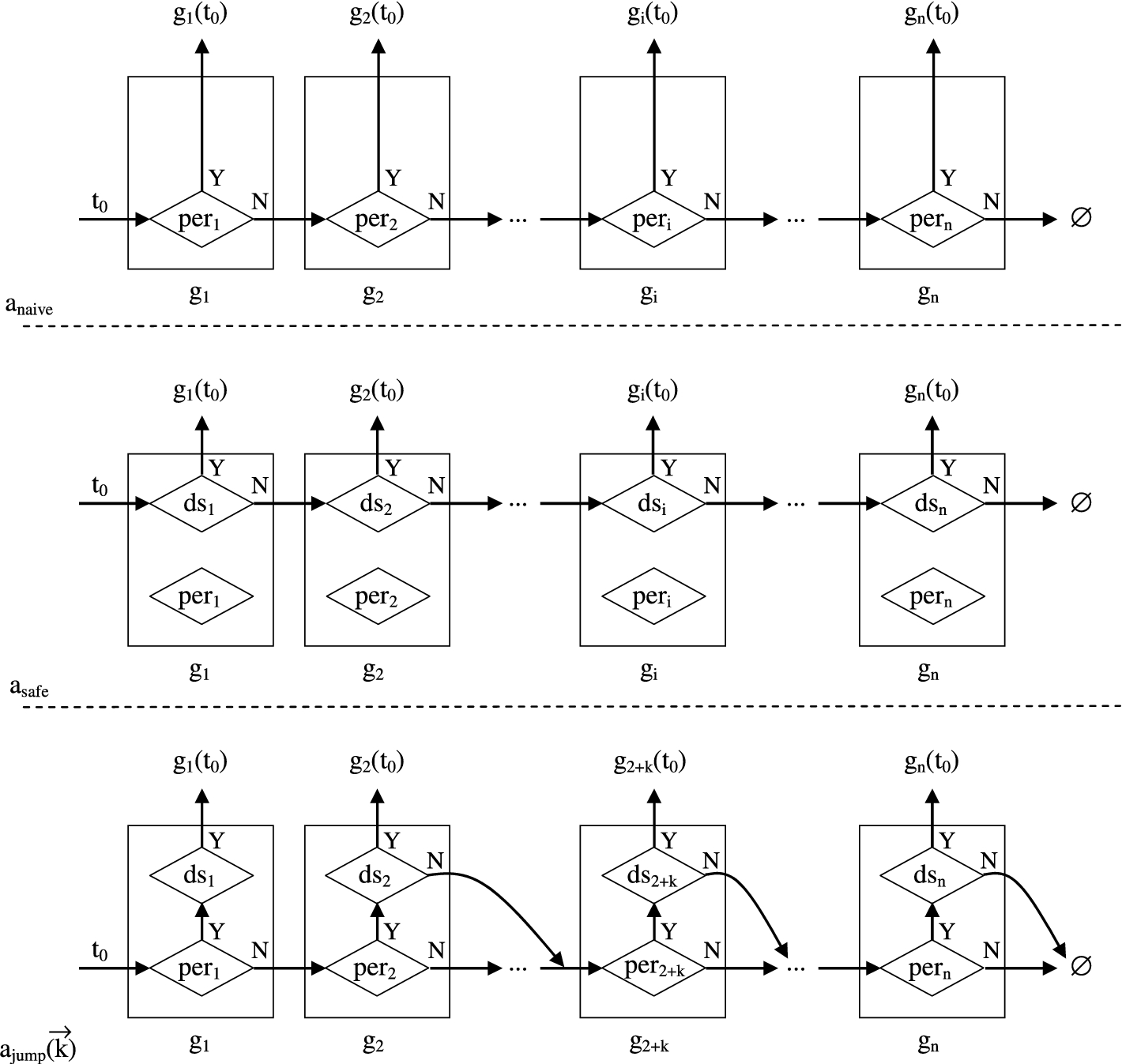
The decision process of different strategies.
In the previous section, we have shown that the naive strategy is unsafe, and the safe strategy is safe but may incur a high cost due to the inherently recursive process. First, we more closely examine the limitation of these algorithms in order to build intuitions toward our new solution. In Fig. 2, the upper and middle chart shows the decision process of the previous two algorithms,
Comparing the two charts, we can have four different cases in each iteration of the algorithm (some iterations actually have less possibilities, as we shall show later):
If
If
The case of
We can see the last case,
The algorithm family
The algorithm family

There are two main differences between
Second, the algorithm family
Despite the difference between
We discuss several properties of the algorithms
Computation of the disclosure set
Again, the disclosure set is well defined under
Although computing disclosure sets under
Referring to the lower chart in Fig. 2, to compute
As an extreme case, when the jump distance vector is
and
The first two disclosure sets have some special properties. First of all,
Second, we show that
Size of the family
First, with n generalization functions, we can have roughly
Note here the jump distance refers to possible ways an algorithm may jump at each iteration, which is not to be confused with the evaluation path of a specific table. For example, the vector
Data utility comparison
In this section, we compare the data utility of different algorithms. Section 5.1 considers the family of k-jump algorithms. Section 5.2 studies the case when some generalization functions are reused in an algorithm. Section 5.3 addresses
Data utility of k-jump algorithms
Our main result is that the data utility of two k-jump algorithms
We do not rely on specific utility measures. Instead, the generalization functions are assumed to be sorted in a non-increasing order of their data utility. Consequently, an algorithm
Such a construction is possible with two methods. First, we let
From now on, we shall add superscripts to existing notations to denote the distance vector of different algorithms. For example,
vs.
(
)
First, we need the following result.
For any
By definition,
From Lemma 1, we can have the following straightforward result for the case that privacy property is set-monotonic. This result is needed for proving Theorem 2.
The data utility of
As shown in Section 4.2.2,
For
For any
The case where
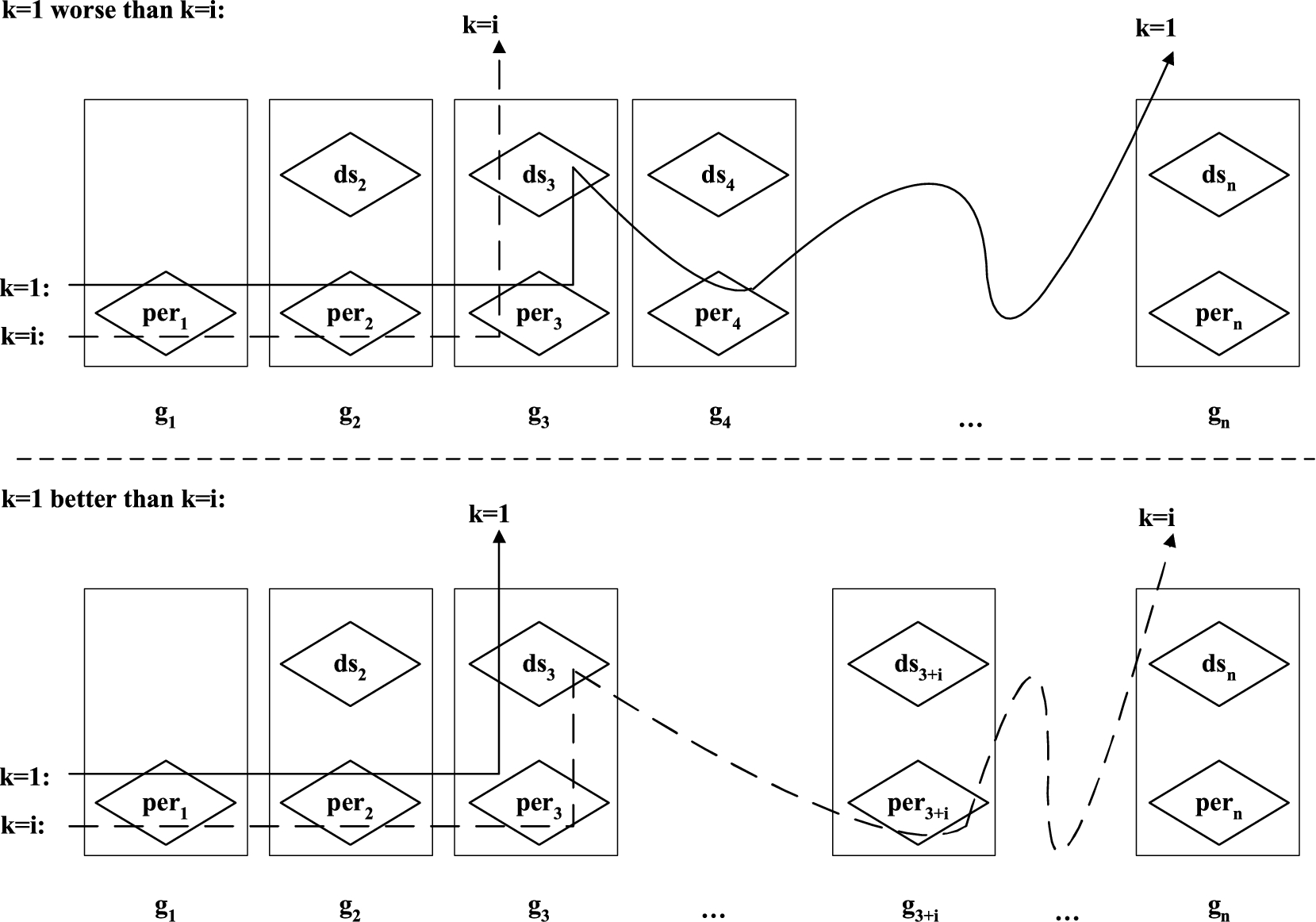
The construction for
By Lemma 2, the case where the data utility of
Table 10 shows our construction for the proof. The privacy property For this special case, In the first case, I has sensitive value Now consider generalizing these tables using For As to the case of Either N or O has H has H does not have sensitive value The other two cases are that N and O have
Consequently, all the tables in
In summary, the disclosure set of every table in this subset under function
Next, we prove the data utility of

The construction for
For any
Since both
Firstly, the case where
The above conditions imply that
Secondly, we show the construction for the other case where
The above conditions imply that
The data utility comparison between
Firstly, we discuss the left side of Table 11. The given table, denoted by
Now we show that Two of A, B and C have S. This subset has Both D and E have S. This subset has Both F and G have S. This subset also has
Next,
Secondly, we discuss the right side of Table 11. Similarly,
Next, we extend the above results to the more general case in which the two algorithms
For any

The construction for
Suppose the first element with different jump distance of
First,
Second, In this sub-case, we can construct the following two evaluation paths.
In this sub-case,
Since
Clearly, the data utility of
With the naive strategy, whether a generalization function satisfies the privacy property is independent of other functions. Therefore, it is meaningless to evaluate the same function more than once. However, we now show that with the k-jump strategy, it is meaningful to reuse a generalization function along the evaluation path. This will either increase the data utility of the original algorithm, or lead to new algorithms with incomparable data utility to enrich the existing family of algorithms. That is, reusing generalization functions may benefit the optimization of data utility.
Given the set of generalization functions
Consider two algorithms
Clearly, the data utility of
It is worth noting that although the same generalization function is repetitively evaluated, its disclosure set will depend on the functions that appear before it in the evaluation path. Take the identical functions
With a set-monotonic privacy property
Suppose
On the other hand, when generalization functions are reused at the end of the original sequence of functions, some tables which will lead to disclosing nothing under the original sequence of functions may have a chance to be disclosed under the reused functions, which will improve the data utility.
Reusing a generalization function after the last iteration of an existing k-jump algorithm may improve the data utility when
We construct a case in which reusing a function will improve the data utility. Consider two algorithms
The case where reusing generalization functions improves data utility
More specifically, the given table, denoted by C has the sensitive value C does not have C does not have
We then have
Now, consider the case that One and only one of D and E has Both D and E have Both F and G have
All the tables in Both A and B have Two of C, D and E have
We must exclude from
Therefore, the disclosure set under the reused function
We show that the algorithm
Given a group
If the privacy property is either set-monotonic or based on the highest ratio of sensitive values
The result is obvious if the privacy property is set-monotonic. Now consider a privacy property based on the highest ratio of sensitive values, which is supposed to be no greater than a given δ. Suppose that
Therefore, we have
Since the disclosure set is computed by excluding tables from the corresponding permutation set, we immediately have the following.
When the privacy property is either set-monotonic or based on the highest ratio of sensitive values
For other kinds of privacy properties, we prove that the data utility is again incomparable between
The
By definition, we have the following (where the superscript 0 denotes Therefore, we have
The data utility of
Based on Lemma 4, we can construct the following two evaluation paths.
Clearly, the data utility of
In this section, we analyze the computational complexity of k-jump algorithms. Given a micro-data table
Due to the definition of permutation set, we directly have the following result: Given a micro-data table
Algorithms:
and
with any given privacy property
Algorithms:

Basically, an
To compute the disclosure set
Based on the above detailed analysis of the algorithm, it can be shown that the running time of evaluating whether a given disclosure set satisfies privacy property is different from the time of deriving that disclosure set. On one hand, we consider
With the aforementioned discussions, we can analyze the time complexity of k-jump algorithms as follows.
Given a micro-data table
Given a jump-vector, we prove the result by mathematical induction on n. Note that, the number of generalization functions is related to the domain size (the larger the domain size is, the more possible of generalization functions based on the methods in the literature). For simplicity, we assume the jump-vector to be jump-distance k, where k is a constant.
The Inductive Hypothesis: To compute the disclosure set of micro-data table
The Base Case: When
For
The Inductive Assumption: Suppose the inductive hypothesis hold for any
The Inductive Step: Now we show the hypothesis also holds for
Summarily, it is shown that the computational complexity of the family of algorithms is exponential in
Although the worse case complexity is still exponential, this is, to the best of our knowledge, one of the first algorithms that allow users to ensure the privacy property and optimize the data utility given that the adversaries know the algorithms. Furthermore, unlike the safe algorithms discussed in [26,48] which only work with l-diversity, the family of our algorithms
The analogy between secret choice among k-jump algorithms and cryptography
The analogy between secret choice among k-jump algorithms and cryptography
From previous discussions, we know that the family of algorithms
On the other hand, as discussed in previous sections, a safe algorithm (e.g.,
The secret-choice strategy
The secret-choice strategy

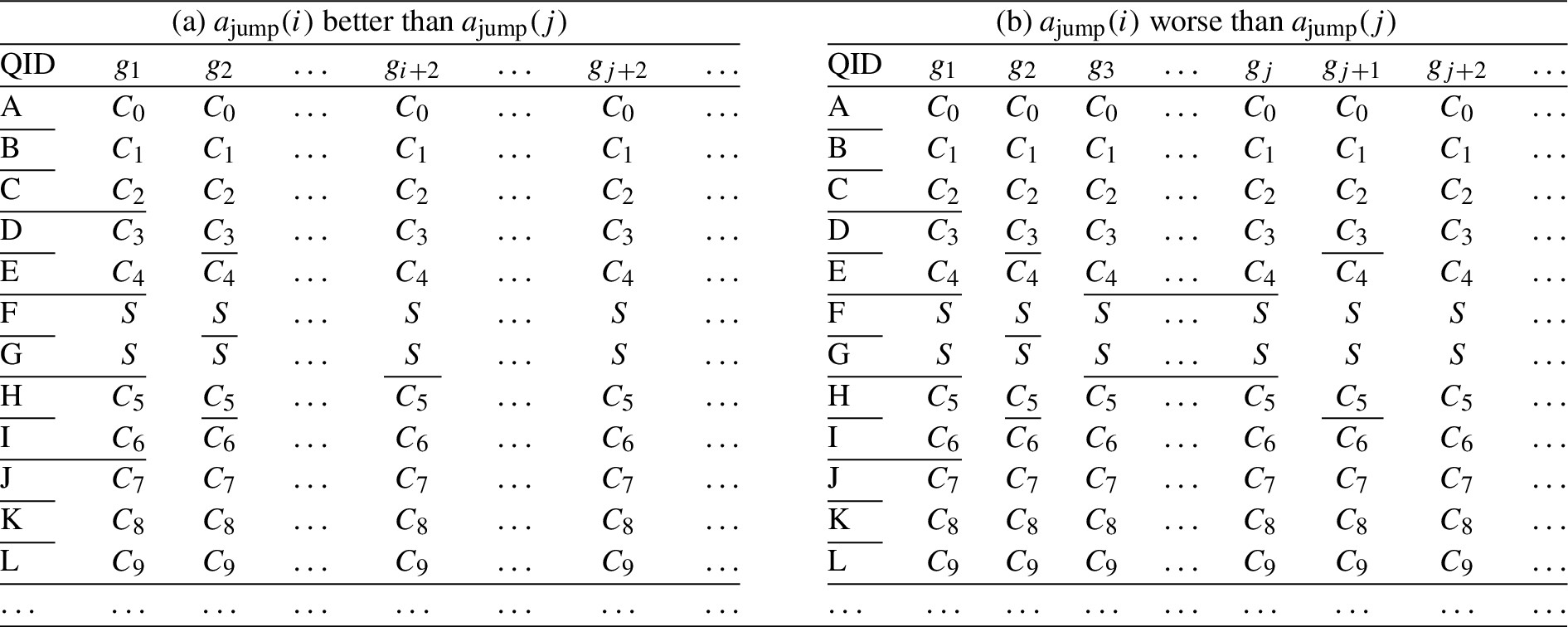
There certainly exist many approaches to defining the sets of algorithms (the first stage of
First, each generalization function is slightly revised to be a generalization algorithm. That is, instead of only evaluating whether the permutation set of a micro-data table under the function satisfies the desired privacy property, such generalization algorithm further discloses the generalization or nothing. To complete the random selection, the
The k-jump strategy is another possible approach to defining the set of algorithms based on a given set of generalization functions. In k-jump, k is the secret choice, while all the functions appear in each algorithm and are sorted based on data utility. Given the set of functions, the one and only difference among k-jump algorithms is the jump-distance (k). As discussed above, k-jump algorithms are safe and the adversaries can at most refine their mental image to the disclosure set no matter whether they know the k. In other words, it is not necessary to hide the k among the family of k-jump algorithms. Similarly, we do not need to make a secret choice among other categories of safe algorithms. Therefore, in the remainder of this section, we will restrict the discussions on the case of secret choice among the unsafe algorithms based on predetermined order of the generalization functions. We show that secret choice among such unsafe algorithms cannot guarantee the privacy through a family of unsafe algorithms.
The subset approach for designing the set of unsafe algorithms
The subset approach for designing the set of unsafe algorithms

From the adversaries’ point of view, when they know the disclosed data, the subset-choice strategy (that is, the secret-choice strategy with the subset approach as its first stage), the privacy property, and the set of functions G, they may be able to validate their guesses and refine their mental image about the original data. With the knowledge about G, the adversary can know there are
Based on such a mental image, the adversary may refine his knowledge about an individual’s sensitive information. For example, for entropy l-diversity, the adversary can calculate the ratio of an individual being associated with a sensitive value in each disclosure set, and then average the ratio among all disclosure sets. Whenever the average ratio among the disclosure sets of an individual being associated with a sensitive value is larger than
In the following, we show that subset-choice strategy cannot ensure the privacy property by constructing a counter-example.
Given a subset-choice strategy
The counter example for secret choice among unsafe algorithms
Suppose that the algorithm select subset
Unfortunately, the knowledge of G and disclosed table will enable the adversary to refine his mental image about the original micro-data, and finally violate the privacy property since the adversary can infer that the ratio of A, B and C being associated with
The possible subsets of functions and the corresponding probability of A, B and C being associated with
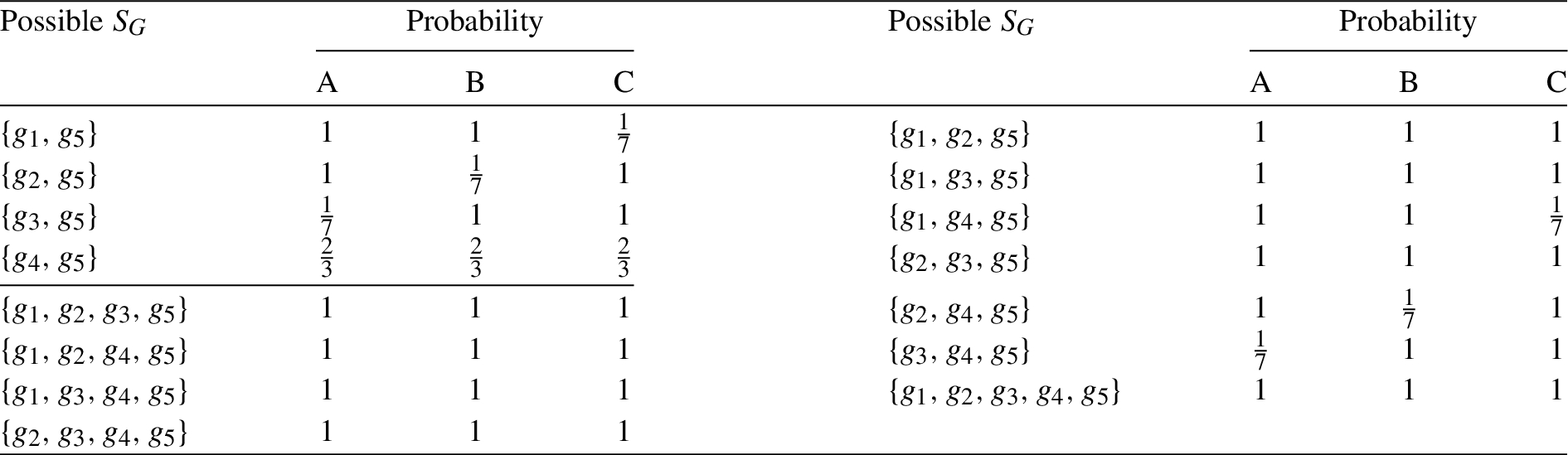
By the data utility measurement DM,
Based on the disclosed data
The counter example in the above proof is sufficient to demonstrate that secret choices made among unsafe algorithms does not always guarantee the privacy property. Therefore, safe algorithms are still necessary for preserving the privacy property.
In this paper, we have proposed a novel k-jump strategy for preserving privacy in micro-data disclosure using public algorithms. We have shown how a given unsafe generalization algorithm can be transformed into a large number of safe algorithms. By constructing counter-examples, we have shown that the data utility of such algorithms is generally incomparable. It has been shown that the computational complexity of a k-jump algorithm with n generalization functions is exponential in
Further studies will be conducted in the following directions. First, we will study other, more efficient algorithms using the same strategy of making a secret choice of public algorithms. Second, we will employ statistical methods to investigate the average-case data utility provided by different k-jump algorithms. Third, we will further investigate the issue of reusing generalization functions in an existing algorithm, which has only received limited study in the current work.
Footnotes
Acknowledgments
The authors thank the anonymous reviewers for their valuable comments. Authors with Concordia University are partially supported by Natural Sciences and Engineering Research Council of Canada under Discovery Grant N01035, and Canada Graduate Scholarship. Zhu’s research is supported in part by the National Natural Science Foundation of China under Grants No. 61373147.