
Abstract
With the development of big data technology, medical data has become increasingly important. It not only contains personal privacy information, but also involves medical security issues. This paper proposes a secure data fitting scheme based on CKKS (Cheon-Kim-Kim-Song) homomorphic encryption algorithm for medical IoT. The scheme encrypts the KGGLE-HDP (Heart Disease Prediction) dataset through CKKS homomorphic encryption, calculates the data’s weight and deviation. By using the gradient descent method, it calculates the weight and bias of the data. The experimental results show that under the KAGGLE-HDP dataset,we select the threshold value is 0.7 and the parameter setting is (Poly_modulus_degree, Coeff_mod_bit_sizes, Scale) = (16384; 43, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 43; 23), the number of iteration is 3 and the recognition accuracy of this scheme can achieve 96.7%. The scheme shows that it has a high recognition accuracy and better privacy protection than other data fitting schemes.
Introduction
Medical data is extremely valuable. For patients, personal medical data is an important foundation for individuals’ physical and mental health development. For hospitals and other medical institutions, it is also a significant reference for the development of medical technology.
With the rapid advancement of the Internet, big data, and cloud computing technology [2,11,28]. The medical indurstry is increasingly informatizationlized, and digital medical treatment is becoming more generalization. For example, Yu et al. [32] proposed a telemedicine method using deep learning technology in 2021. From July and September in 2019, Green Bone Networks analyzed approximately 2,300 online medical image archiving and communication systems (PACS) worldwide, among which about 590 are publicly available on the Internet, which includes about 24 million patients records. What worse, the data leaked from the dark Web could be worth more than $1 billion, it may be used by attackers for a variety of purposes, including damaging individual’s privacy by exposing personal names and images.
Linear regression model [7] is one of the most widely used models in machine learning, which makes predictions using linear combinations of sample features. In linear regression, the model is built by the linear prediction function, of which the parameters are estimated using the samples. When the sample data has several sample characteristics, the prediction function cannot be described by one linear function alone; Insteadly, a complex curve is used to depict the trend of the samples. Unlike linear regression, curve fitting involves using a continuous curve to approximate samples by resolving the relationship between variables to infinitely approximate or fit the known data. Curve fitting allows people observe trends in complex data and predict data outcomes for greater benefit [13]. The most classical method of curve fitting is to determine the parameters of the fitted curve by building and solving a system of equations using the least-square error method, which results in a specifically fitted curve equation. A system of nonlinear equations, also known as least-squares fitting, is used to find the parameters of the fitted curve for nonlinear models. On the other hand, the polynomial fit is a more widely used curve fitting method in which a polynomial is extended to include all sample data points in the analysis area, and its coefficients are determined using a least-squares fit [15].
With the development of big data technology in recent years, more and more users are turning to cloud servers to process data [17,27]. The powerful computing power of the cloud server can help users do a huge number of computing operations that cannot be completed by a local server, which considerably reducing the computing burden of users. As a distributed technology, cloud computing can utilize computing resources across the country, process data in the cloud, and return the computing results to users. On the cloud server, the user can allow the cloud server to process data according to the users’ preferences by designing the computing mode in advance [5,8,16,26].
Fitting data allows people to discover the pattern underlying the data. However, in reality, users do not want others to gain access to sensitive data, such as patient health data, confidential business development data, and so on. With the booming of data, local computing servers are becoming increasingly unable to process them, and more and more users are outsourcing data to cloud servers. Whereas, this always has some restrictions due to inherent security issues. Therefore, many researches began to focus on how to securely process the outsourced data on cloud servers in recent years [14,29].
There are many kinds of network security technologies, such as artificial intelligence based secruity technology [24,33], blockchain technology [25,34] and threat detection based on deep learning [10]. At present, homomorphic encryption technology is more popular. Homomorphic encryption [19] is a type of encryption technology that can decrypt data safely. Homomorphism means that after decryption the result of ciphertext data is the same as the operation performed on the plaintext data. Even if a third party acquires ciphertext data, it will be unable to obtain the plaintext information. The well-known encryption schemes include fully homomorphic encryption scheme BGV (Brakerski-Gentry-Vaikuntanathan) [4], BFV (Brakerski/Fan-Vercauteren) [9], CKKS [6], semi-homomorphic encryption scheme Paillier [20,21], RSA [22,23] and so on. Holomorphic encryption can support addition and multiplication, while semi-homomorphic encryption can only support addition or multiplication. In a finite number of operations, holomorphic encryption can perform more sophisticated calculations. This paper uses CKKS homomorphic encryption algorithm to ensure data security.
To tackle the privacy security problem of cloud data and realize efficient fitting data on the cloud server, this paper designs a fitting data scheme based on ciphertext data. The contributions of this paper are as follows:
The article uses the CKKS homomorphic encryption scheme to encrypt the data, apply the gradient descent method on ciphertext data to train the model. In order to overcome the limitation of homomorphic operation of ciphertext data, the article replacea the inverse operation in the solution matrix with an iterative algorithm to find out the weights and deviations. The CKKS encryption algorithm is implemented by employing the TenSEAL library, and the optimum parameters and iterative parameters are selected through extensive testing to efficiently and securely perform the fitting scheme under ciphertext data.
The first and second sections of the article mainly introduce the background and significance of the research. The third section introduces the theoretical knowledge coverd in the article. The fourth section introduces the scheme model and the fifth section tests the scheme experimentally. The sixth section summarizes the whole article.
Related work
The curve fitting is an important study direction in the machine learning. A lot of progress has been achieved in the research of fitting data in recent years. With the advent of big data era, data collection become relatively easy.
There are many types of curves fitting, such as linear fitting, quadratic polynomial fitting, cubic polynomial fitting, exponential fitting, Gaussian fitting, Bayesian curve fitting, etc.
In 2019, Xie [31] used data fitting to model and analyze data from Liberia. The extended epidemiological model (SEIHFR) used data combination and scenario analysis to better understand virus transmission to develop strategies that may lead to disease-free status.
In 2020, Windarto et al. [30] proposed a parameter estimation method for the dengue heat transfer model based on particle swarm optimization. This approach estimated the parameters of host vector and the Sir dengue transmission model using the data from dengue patients. By streamlining the parameters, this method received better data fitting results than that of the SIR model.
In 2020, M. Kowsher et al. [12] proposed two new linear and nonlinear regression techniques. In 2021, Woldegerima et al. [3] extended the SeIRS-SEI type model using data fitting. They did a lot of clinical advances in the development of antimalarial medications and have a preventive effect on treating disease.
At the same time, the curve fitting has a wide range of applications and it can also be used for face recognition to characterise facial organs with good adaptability. In contrast to the above-mentioned articles, this article proposes a secure data fitting scheme based on the CKKS homomorphic encryption algorithm. The scheme achieves data fitting in the ciphertext state by encrypting the data and calculates the coefficients of the fitting polynomial using a recursive descent method, which is also able to ensure data privacy. In the scheme proposed in this paper, the threshold method is used to supervise the data fitting process. In this paper, the maximum benefit of the scheme is systematically predicted by fixing the critical value, and the threshold method can also be used in other scenarios. For example, in data analysis, the data is classified by determining the threshold, and in image segmentation, the image pixels are classified by using the threshold. In this scheme, the threshold is used to make maximum accuracy measurements of ciphertext data. While ensuring data privacy, it can also measure the data efficiently. In the future work, threshold can be used not only for plaintext data, but also for ciphertext data. With the maturity of homomorphic encryption technology, threshold can also be applied in more fields.
Preliminaries
Least square method
Given n data points
CKKS homomorphic encryption algorithm
In 2017, Cheon et al. [12] proposed a method to construct a homomorphic encryption scheme supporting approximate addition and multiplication for encrypted messages. The specific algorithm flow is shown in Fig. 1.
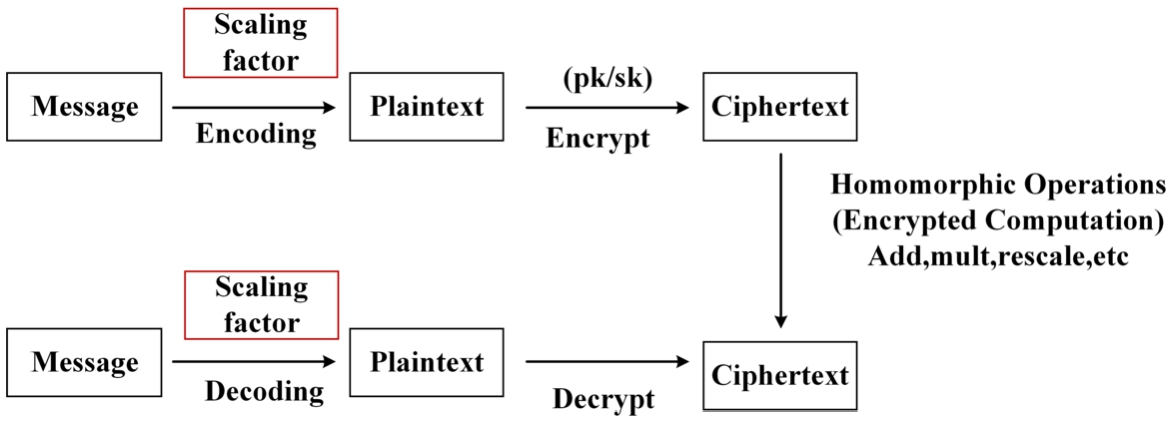
CKKS algorithm model.
Chosen a base
The CKKS homomorphic encryption algorithm is based on the RLWE problem. All its operations are implemented in the polynomial ring
Due to its own characteristics, homomorphic algorithm can ensure that after decryption of ciphertext data in cloud server, the rusult is same as the operation performed on the plaintext data. This effectively protects the privacy of user’s data.
This paper uses the KAGGLE-HDP dataset adjust by predict the patient’s heart disease data. In order to make sure the data security, the dataset is encrypted by the CKKS algorithm. Then, the gradient descent method is used to solve the weight and deviation bias. The efficiency and accuracy of the scheme are tested by extensive experimental tests with different iteration times and encryption parameters. The specific scheme is shown in Fig. 2.
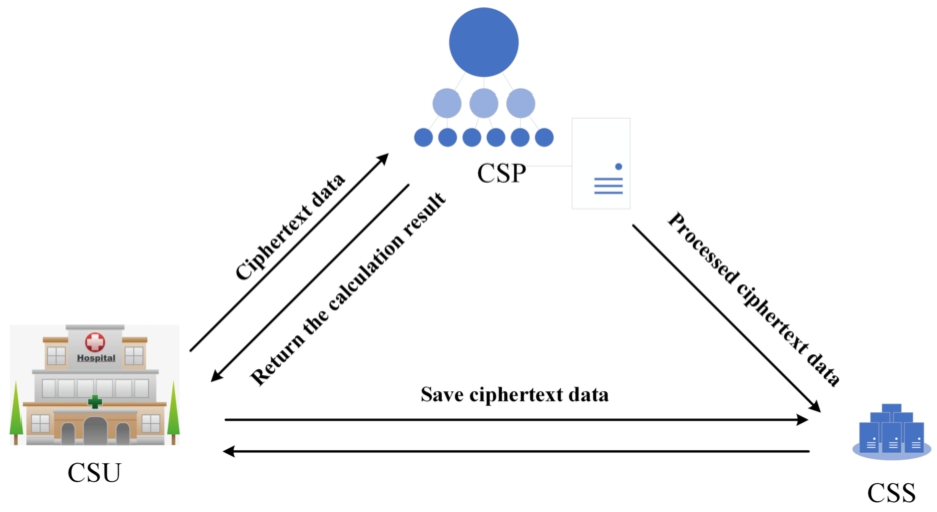
Safety data fitting scheme model.
CSU: Cloud server user, generates the encrypted public key and encrypts the data, uploads the ciphertext data to CSP for calculation, decrypts the ciphertext result returned by CSP and performs the corresponding comparison.
CSP: Cloud computing server with powerful computing and storage capacity, which is assumed to be “honest and curious” in the system, is mainly responsible for computing and processing ciphertext data in the whole system, and returning the result to CSU.
CSS: Cloud storage server, which mainly stores ciphertext data, when CSU uploads ciphertext data, it stores the data in CSS, and after iteration, it stores the ciphertext data in CSP.
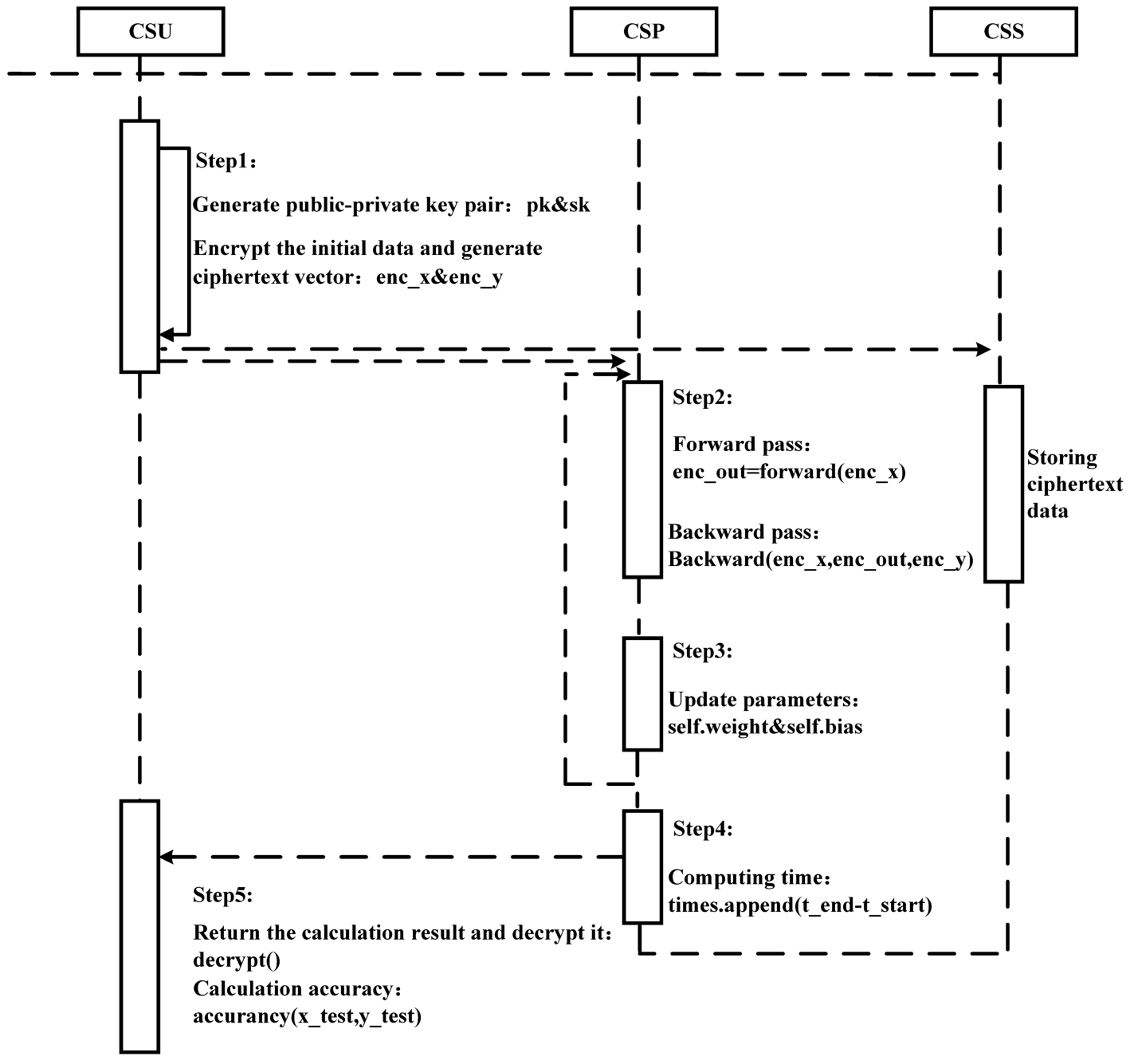
Framework of the proposed model.
As shown in Fig. 3, the specific process of the framework of the security data fitting scheme is as follows.
According to the framework of the scheme, the algorithm is as follows:
The CSU users generate public and private key pairs locally. Encrypt the uploaded original data, initialize the ciphertext data to get
After receiving the ciphertext data, CSP uses the gradient descent method to obtain the weight and bias of the model in ciphertext form. First of all, the forward propagation of
CSP backpropagates the ciphertext data, and the substitution value is
CSP updata the parameters. According to the Eq. (8):
In the process of uploading, calculating and storing ciphertext data by CSU, two points must be guaranteed for the data security: First, it is necessary to ensure that CSP and CSS cannot recover relevant information related to the original data from the ciphertext data; The second is to ensure that even if the third party obtains the ciphertext data, the original data cannot be obtained by decrypted ciphertext data.
In the scheme, we assume that the cloud server is “honest and curious”. Honesty means that participants do not falsify data and the server does not maliciously attack, decipher or reverse engineer the data uploaded by participants. Curiosity is that the server side has some degree of curiosity about the user’s raw data and may bypass some security measures to access the user’s raw data directly. The keys are only generated and stored by individuals, while CSP and CSS are only responsible for computing and storing ciphertext data. The CSP and CSU cannot obtain the keys and original data.
It is assumed that the ciphertext data is secretly obtained by the third party. During the whole communication process, the data is transmitted in the form of ciphertext, and its security can be attributed to the security of the CKKS encryption scheme. The security of CKKS encryption scheme relies on the RLWE(Ring Learning with Error) problem. The data calculated and stored by CSP and CSS are all ciphertext data, and the key information cannot be obtained. Therefore, the key and original data cannot be recovered by calculation.
We define the safe model as shown in the Fig. 4.
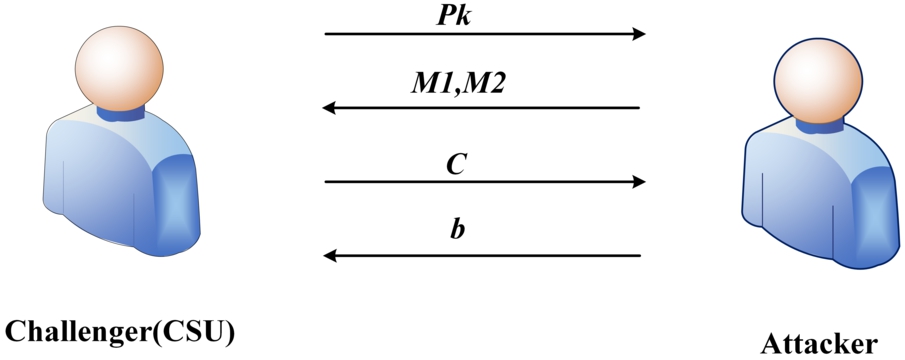
IND-CPA safe model.
We define the CSU as the challenger, possess the
The attacker selects two equal-length plaintexts
The challenger obtains the plaintext, it randomly selects the value of b, where
If the attacker can give the value of b, it can determine whether the ciphertext is encrypt with
The advantage of the attacker to obtain b is
To further analyze the efficiency of the scheme, this section conducts experimental evaluations. The whole experiment was conducted at Intel® Core™ under the environment of i7-9750hq CPU @ 2.60ghz/8 GB ram, pycharm2020.3.3 x64 is used to test plaintext and ciphertext data under windows10 operating system. CKKS encryption scheme is realized by calling TenSEAL0.1.4, KAGGLE-HDP dataset [1,18] is called to evaluate the data. Due to technical reasons, the article only uses a laptop to carry out the experimental simulation, and the results are limited by the computer configuration, but it can be used as an important reference for cloud computing. In the future work, we will carry out the experiments in a cloud server to get better data results. Also, we will conduct in-depth research and analysis.
Encryption efficiency test
This section mainly tests the encryption efficiency of CKKS encryption scheme under different encryption parameters. By calling the TenSEAL library, we use CKKS encryption scheme, and record the runtime of KAGGLE-HDP dataset under different encryption parameters. Poly_modulus_degree represents the size of the messages that can be encrypted and must be a power of 2. The larger the parameter, the greater the computational efficiency. Coeff_mod_bit_sizes represents the number of times that the ciphertext can be rescaling. The specific parameters are shown in Table 1.
Encryption parameter setting
Encryption parameter setting
Efficiency impact of different scale values. With fixed parameters (poly_modulus_degree, coeff_mod_bit_sizes), the dataset is encrypted under different scale values, and the average value of 10 runtime is recorded as the final result of the experiment. In the test, let poly_modulus_degree = 8192, coeff_mod_bit_sizes = (30,21*7,30), select different scale values. As shown in Fig. 5.
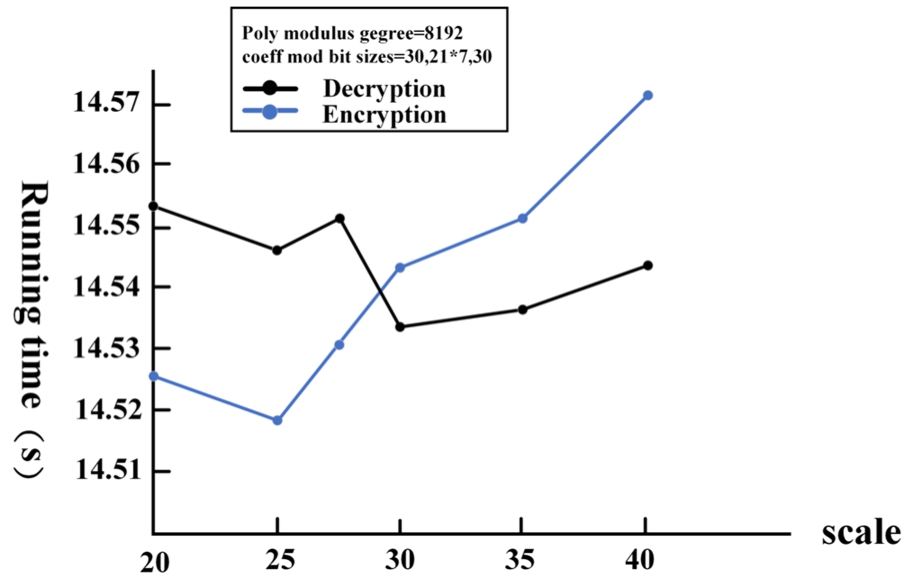
Different scale values running time.
Second, we set the parameter poly_modulus_degree = 16384 to perform tests on the dataset under different coeff_mod_bit_sizes values. Record the average of 10 runtime as the final result of the experiment. As shown in Fig. 6.
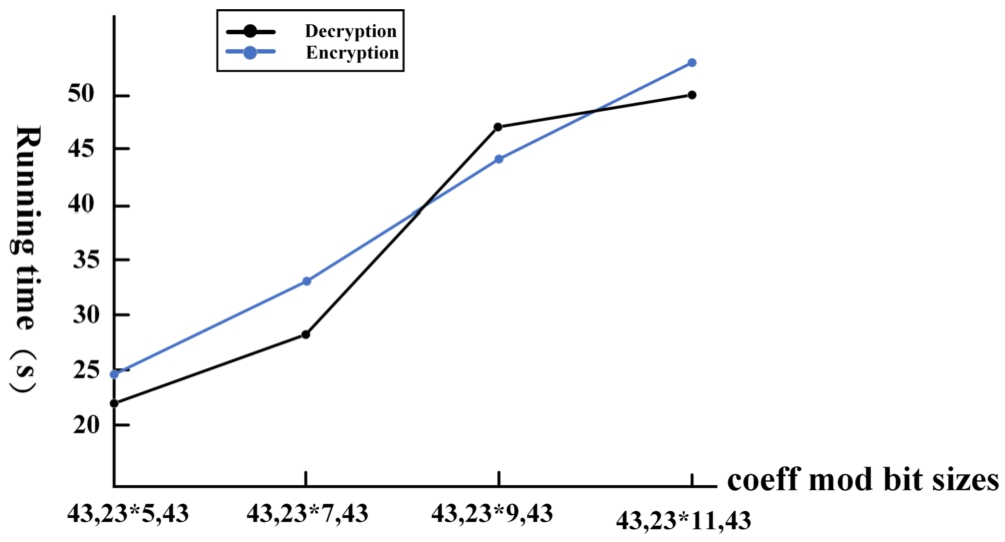
Different coefficient modulus running time.
Then, we test the effect of poly_modulus_degree on the experiment. Select the coeff_mod_bit_sizes parameter as 7. Record the average value of 10 runtime as the final result of the experiment. As shown in Fig. 7.
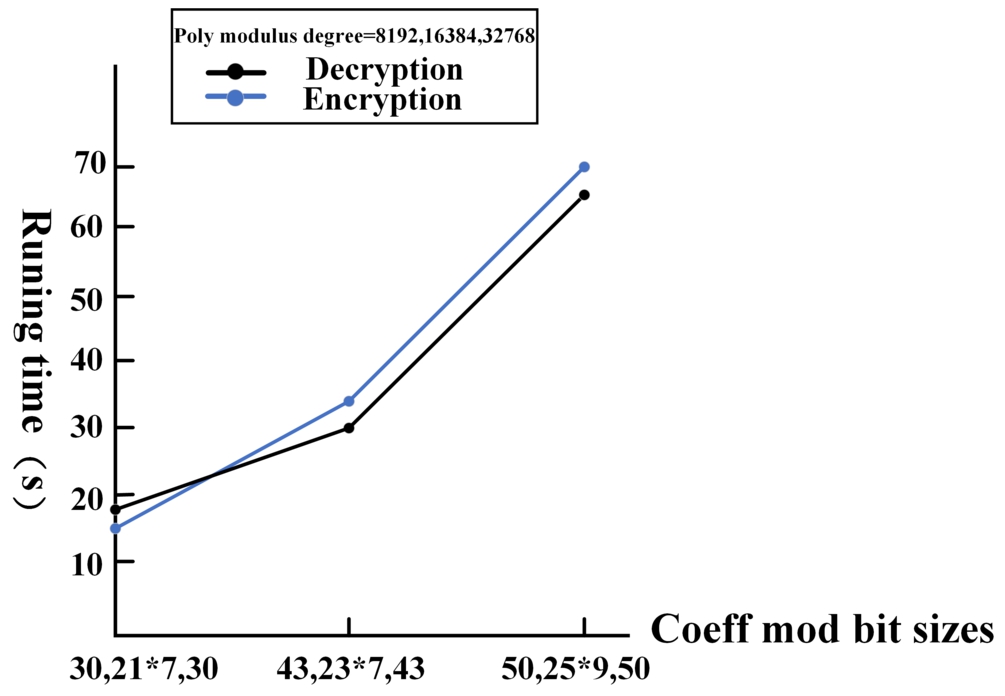
Different polynomial modulus running time.
The encryption time of the dataset with different encryption parameters is tested first. Record the average encryption time of 10 experiments as the final result. Table 1 where the horizontal coordinates in the figure indicate the parameter settings in the table. The encryption time of the dataset is shown in Fig. 8.
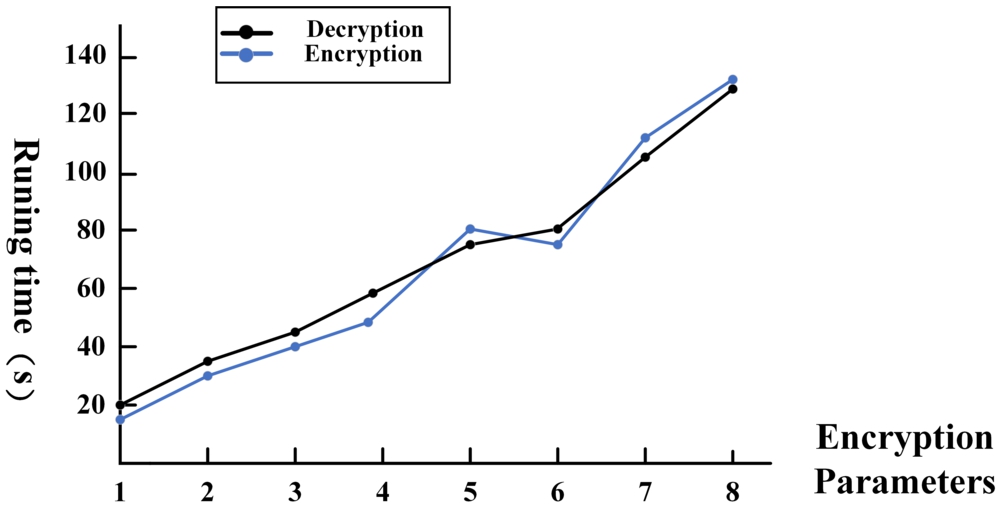
Data set running time.
From the above figure, it can be seen that the encryption and decryption time of the dataset is independent of the scale value. With the same polynomial modulus, they increase with the number of coefficient modulus. With the same coefficient modulus, they increase with the polynomial modulus. These data results also lay the foundation for the next experimental operation.
In this subsection, the efficiency of the CKKS encryption scheme is evaluated, because the CKKS encryption algorithm cannot implement the division operation, so here the gradient descent method is used to approximate the inverse matrix by iteration.
In this subsection, the number of iterations of the encryption scheme is set to 3, 5, and 7. Due to the computer configuration, if more iterations are chosen, the computational efficiency will be very expensive and extremely detrimental to the whole experiment. For the parameter configurations in the table, we compute 3, 5, and 7 iterations for each set of parameters. In the calculation accuracy, the experiment is carried out by setting the size of the threshold. We set the threshold to 0.5, 0.6 and 0.7 to observe the best parameter selection of the experiment.
Firstly, with the threshold is 0.5, we perform 3, 5, and 7 iterations of calculation on the eight sets of parameters to obtain the computational efficiency and accuracy. The encryption efficiency and iterationtime is shown in Fig. 9 and Fig. 10.

Encryption efficiency when the difference is 0.5.
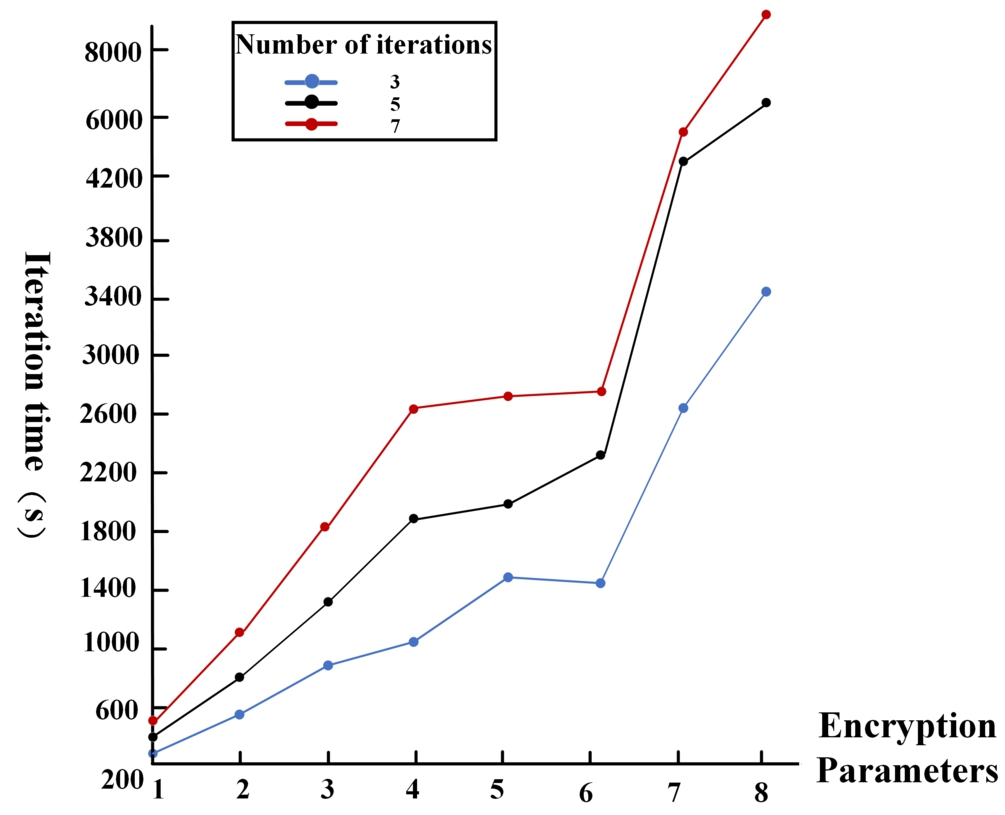
Iteration time when the difference is 0.5.
From the above figures, we can see that the highest accuracy is 67% for the threshold 0.5, and the parameters are set as (16384; 43, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 43; 23). The iteration time increases with the increase of the ciphertext size and ciphertext extension space and the number of iterations.
In the presence of the threshold is 0.6, we perform 3, 5, and 7 iterations on each of the eight sets of parameters for obtain the computational efficiency and accuracy. The encryption efficiency and iterationtime is shown in Fig. 11 and Fig. 12.
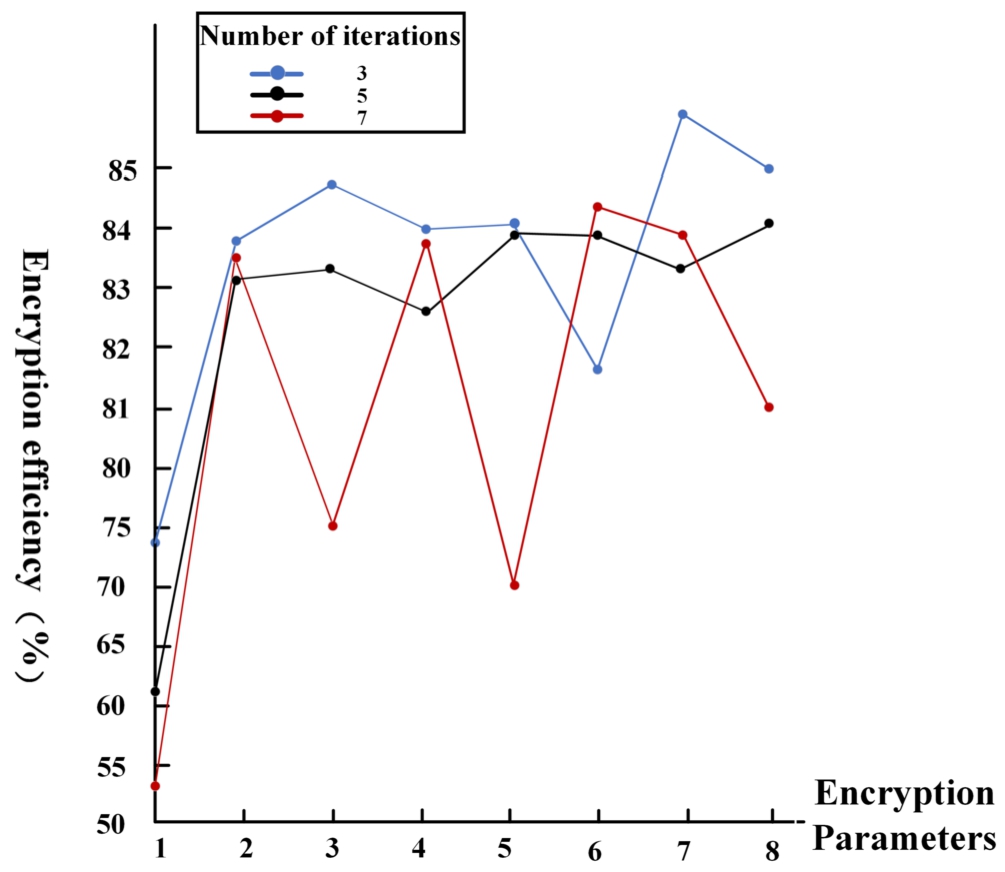
Encryption efficiency when the difference is 0.6.

Iteration time when the difference is 0.6.
From the above figure, it can be seen that the highest accuracy of 85.6% is achieved at when the threshold is 0.6 and parameters (32768; 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25, 25; 25) with 7 iterations, but the computational efficiency corresponding to this also consumes a lot of time. The highest accuracy of the comparison was achieved at the parameter of (16384; 43, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 43, 43; 23) with 3 iterations and 84.7% accuracy, so under the same conditions, we selected the latter set of parameters as the optimal parameters for this group of tests, which can take into account the efficiency while satisfying the accuracy.
Finally, in the case of the threshold is 0.7, we test eight groups of parameters to obtain the computational efficiency and accuracy. The encryption efficiency and iterationtime is shown in Fig. 13 and Fig. 14.
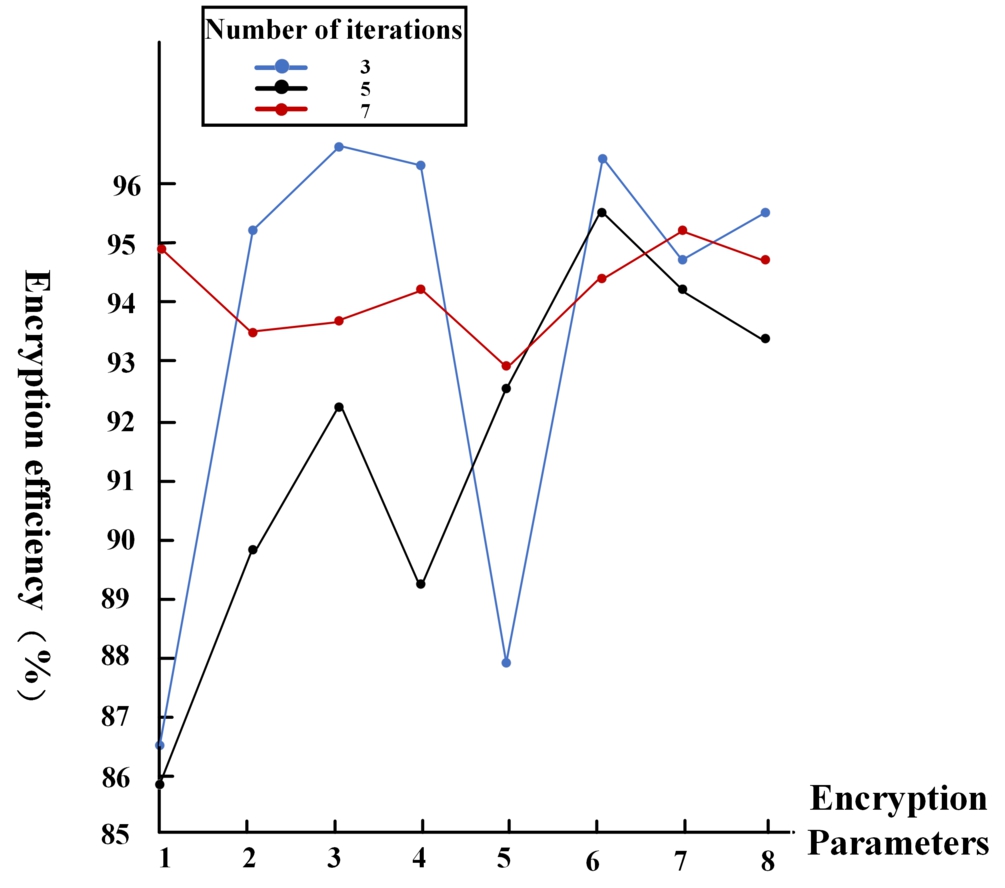
Encryption efficiency when the difference is 0.7.

Iteration time when the difference is 0.7.
From the above figure, it can be seen that the accuracy of calculation at 0.7 is highest at 96.7% with parameters (163843 43, 23, 23, 23, 23, 23, 23, 23, 23, 23, 43, 43; 23), and its iteration number is 3. Combining the graphs, it can be seen that the time of the experimental test does not change much when the difference is different, while the iteration time increases with the number of iterations and the change of parameters.
In the above experiments, we choose the experimental data with the threshold is 0.7, parameters set to (16384; 43, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 43; 23) and iterations of 3 as the final result, from which we get the weight and bias bias of the data set, and derive the mixture matrix of plaintext and ciphertext.
The accuracy of the direct least-squares solution on the plaintext data is 70.36%, the time spent is 0.013 s, and the resulting polynomial coefficients are as follows:

Plaintext data mixing matrix.
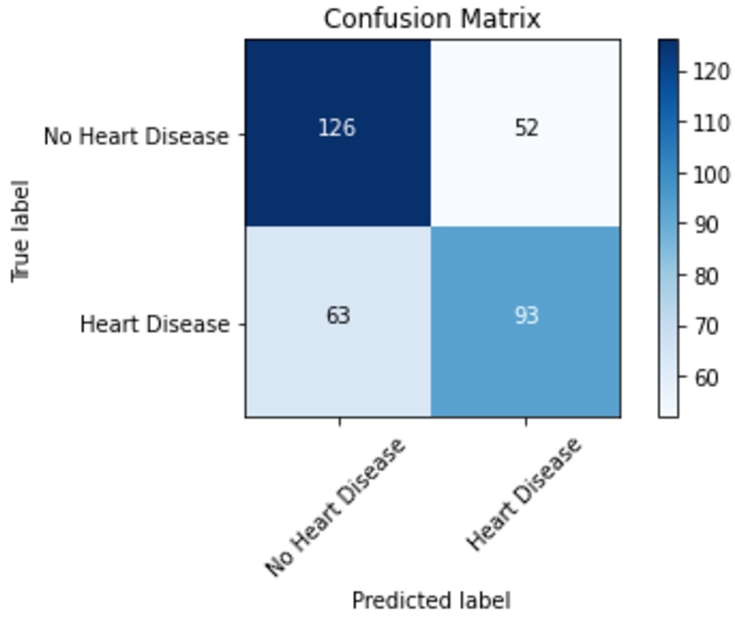
Ciphertext data mixing matrix.
Figure 15 and Fig. 16 represent confusion matrices generated after classification of plaintext data and ciphertext data. Specifically, the confusion matrix model is shown in Fig. 17. TP stands for true positive, FP stands for false positive, FN stands for false negative, TN stands for true negative. The evaluation index is that the more the proportion of TP and TN, the better classification result. Comparing Fig. 15 and Fig. 16, we can get the confusion matrix generated by plaintext data, its precision
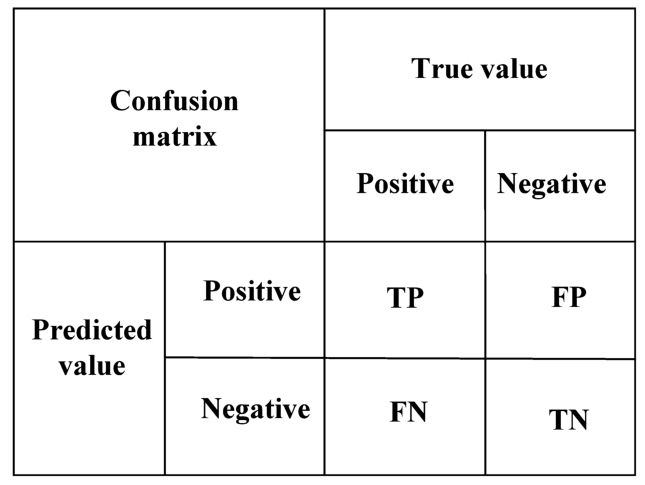
Confusion matrix.
The scheme proposed in this paper can be applied in more fields. The data fitting method based on homomorphic encryption can be applied to the medical field, such as the scheme proposed in the paper to predict the probability of a patient’s disease. It can also be used in the economic field. For example, prices in the market will change continuously with the number of customers. We can fit the best polynomial function to express the specific relationship between prices and customer groups in different periods. Then we can adjust the price to ensure the increase in the number of customers, thereby creating economic benefits. We may use personal information of customers, such as age, work, etc., as data features for training. The homomorphic encryption scheme can also better protect the customer’s private information and prevent data loss or leakage.
We can also use it in driverless fields. We can find out the optimal driving route through multiple fitting training of the unmanned trajectory. We can complete the trajectory re-planning of the vehicle, and achieve the maximum accuracy in the prediction time domain by making a polynomial fitting curve for the vehicle position, acceleration, etc. The homomorphic encryption scheme is mainly responsible for encrypting and protecting various data of the vehicle, preventing it from being stolen by a third party, and completing the test of the data during the training process.
To sum up, there are more fields where the scheme proposed in this paper can be applied. In future work, we will also actively explore the feasibility of the scheme in other fields.
Conclusion
This paper proposes a data processing scheme based on the CKKS homomorphic encryption algorithm and the gradient descent method. We use the TenSEAL library to implement the CKKS homomorphic encryption algorithm, and test the encryption efficiency and computational efficiency under different parameters. Finally, we determine the optimal parameters through experiments and realize safe data fitting in the cloud server.
In the future work, we will study to reduce the computational overhead, improve the accuracy and securely implement the data fitting in the ciphertext domain. We also conduct in-depth research on the scalability of data to meet different demand changes and improve the overall performance of the program.
Footnotes
Acknowledgements
This work is supported by the National Key R&D Program of China (2021YFF1201100), Engineering University of PAP’s Funding for Scientific Research Innovation Team [No. KYTD201805] and Engineering University of PAP’s Funding for Key Researcher [No. KYGG202011]
Conflict of interest
There is no conflict of interest.