
Abstract
The present paper is an attempt to integrate inverse Data Envelopment Analysis (DEA) and Artificial Neural Network (ANN) for a large dataset with multiple Decision Making Units (DMUs). The purpose of this study is to determine the best possible values of inputs for a large number of DMUs when their output levels are changed and their efficiency values remain unchanged. When the ANN is used to develop inverse DEA, it is not necessary to solve the inverse DEA model for every single DMU. Therefore, this approach can save the computer’s memory and the CPU time especially for very large scale datasets. To illustrate the ability of the proposed methodology, a set of 600 Iranian bank branches is used.
Keywords
Introduction
There are diverse methods to evaluate efficiency measure in the literature. Methodologically, they are assorted in accordance with two criteria. The first classification distinguishes between parametric and non-parametric approaches. In the parametric approach, specific analytic function with constant parameters is used to describe the boundary of production possibility set. On the contrary, the non-parametric approach makes no stringent assumptions about production possibility set. The second category differentiates between stochastic and deterministic methods. Deterministic approaches do not allow uncertainty in data whereas the stochastic approach regards the stochastic nature of data. The following stochastic approaches can be cited as the commonly used parametric ones:
Stochastic frontier approach (SFA) which was engendered by Aigner et al. [9], thick frontier approach (TFA) of Berger and Humphrey [1] and distribution free approach (DFA) which was developed by [7]. The non-preferable over parametric ones; on account of the fact that they are intuitive and easy to carry out. The common non-parametric methods are Data Envelopment Analysis (DEA) of Charnes et al. [2] and free disposal hull (FDH) which was first formulated by Deprins et al. [11]. Both the deterministic and stochastic DEA models are extended in the literature. FDH as a deterministic method is the DEA relaxed of the convexity assumption. DEA is a leading approach in distinction from other approaches since DEA needs no explicitly assumptions on the specification of the production function and is capable of evaluating efficiency change over time.
DEA is a method for assessing the productive efficiency of a set of homogeneous Decision Making Units (DMUs) enjoying multiple inputs and outputs. The preliminary objective of DEA is to partition the DMUs into two classes: efficient and inefficient ones. It is based on establishing the efficient frontier via a piecewise form that rests on top of the empirical observations. DEA provides a measure of the efficiency score for an inefficient DMU as its distance from the efficient frontier.
Efficiency evaluation of DMUs (involved complex and often unknown relations between inputs and outputs) are measured easily without requiring superfluous assumptions. The first model in DEA was presented in the CCR paper [2] (after Charnes, Cooper and Rhodes). In the CCR model, the efficiency of each DMU is obtained as the maximum of a ratio of weighted outputs to weighted inputs subject to the constraint that the similar ratio for all DMUs is less than or equal to one. Subsequently, Banker et al. [29] proposed a variable returns to scale version of the CCR model which was named the BCC model (after Banker, Charnes and Cooper). To acquaint with other DEA models, the reader is referred to [24, 25].
There has been a widespread tendency in both theoretical developments and applications in DEA literature. In regards to the development of DEA applications, Liu et al. [22] provided a systematic survey of DEA applications. They reported that, on the whole, two-third of DEA studies incorporated applications while the remaining one-third focused on purely-methodological. Their results indicated the five major DEA applications as banking, health care, agriculture and farm, transportation, and education.
Extensive surveys are introduced in regards to the DEA methodologies and its theoretical developments, as the following examples show. Seiford [24] traced the evolution map of DEA from inception to the year 1995 and provided an extensive bibliography of DEA during a 17-year period. Cooper et al. [34] described some of DEA models and noted their properties. So they demonstrated relations between the models and the associated measures of efficiency. Liu et al. [21] studied the DEA literature by applying a citation-based approach. They addressed the most influential DEA paper and the five most active DEA subareas. A sketch of the major methodological developments of DEA covering its 30 years of history is available in [33].
The efficiency of each DMU in DEA is clearly designated by its input and output levels. Therefore, changes in input or output values can induce changes in the relative efficiency values of DMUs. Inverse DEA is discussed to maintain current efficiency value of a given DMU if its internal structure changes. Inverse DEA models are classified into two bundles relying on which parameters are changed and which parameters must be adjusted with the understanding that the efficiency remains unchanged. These two types are the investment analysis problem and the resource allocation problem. The investment analysis problem of DEA is an inverse DEA problem in estimating output levels for the given inputs, under the condition of preserving the efficiency index. In contrast, the resource allocation problem deals with determining possible inputs for the demanded outputs while the efficiency score stays unchanged. For the first time, Wei et al. [28] intimated inverse DEA model to answer the following question: among a group of DMUs, if we increase certain inputs to a particular unit and assume that the DMU maintains its current efficiency level with respect to other units, how much more outputs could the unit produce? Or, if the outputs need to be increased to a certain level and the efficiency of the unit remains unchanged, how much more inputs should be provided to the unit? They assumed that the increase in input and output values to be nonnegative values and proposed a multi-objective linear programming (MOLP) for inefficient DMUs and a linear programming (LP) for weakly efficient DMUs. Subsequently, Yan et al. [19] discussed the inverse DEA problem with preference cone constraint to provide the properties of the inverse DEA problem through a discussion of its related multi-objective and weighted sum single-objective programming problems. Jahanshahloo et al. [16] expanded the method presented by Yan et al. [19] and proposed a method to estimate output levels of a DMU when some or all of its input entities were increased and its current efficiency level was improved. Jahanshahloo et al. [17] showed that the inverse DEA models could be used to estimate inputs for a DMU when some or all outputs and the efficiency level of the DMU were increased or preserved. They also introduced an approach to identify extra inputs when the outputs were estimated using the proposed models by Yan et al. [19] and Jahanshahloo et al. [17]. Hadi-Vencheh and Foroughi [6] amplified the work of Wei et al. [28] by allowing a simultaneous increase of some inputs (outputs) and a decrease of some other inputs (outputs). Moreover, they proposed a MOLP model for both inefficient and weakly efficient DMUs. In addition, they showed that the solution proposed by Wei et al. [28] did not guarantee the efficiency result for input estimation and introduced some solutions to overcome this failure. Lertworasirikul et al. [30] considered the inverse BCC model for a resource allocation problem. Their developed model keeps the relative efficiency values of all DMUs in a new production possibility set composing of all current DMUs and a perturbed DMU with new input and output values. The inverse BCC problem was in the form of a multi-objective nonlinear programming model (MONLP) which was not easy to solve. They proposed a LP model which gives a Pareto-efficient solution to the inverse BCC problem. Jahanshahloo et al. [18] analysed inverse DEA under inter-temporal dependence assumption. They used solutions of a new optimality notion for MOLP, the periodic weak Pareto optimality in inverse DEA. They illustrated that these solutions can be characterized by a simple modification in weighted sum scalarization tool.
Artificial Neural Networks (ANNs) are information processing algorithms that emulate the behavior of neurons in the brain. They can be applied to approximate complex relationships between sets of variables. Therefore, ANNs have extensive applications in many areas such as weather forecast, air traffic control, medical research, economics, and finance. Various approaches have been proposed aiming at contributing to the use of ANN in DEA. The first combination of ANN and DEA to assess performance measurement was introduced by Athanassopoulos and Curram [4]. They demonstrated that both methods offer a useful range of information regarding the assessment of performance. Emrouznejad and Shale [5] combined ANN with DEA to introduce an approach to estimate the efficiency of DMUs in large data sets. The results indicated that the ANN-DEA prediction of the efficiency score appears to be a good estimate for the majority of DMUs. According to Santin et al. [13], ANNs constitute a promising alternative to traditional approaches, econometric models, and non-parametric methods such as DEA in order to fit production functions and measure the efficiency under non-linear contexts. Costa and Markellos [3] proposed an ANN approach to measure performance of public transport services. They analyzed the London underground efficiency with time series data and explained that the ANN approach is superior to traditionally applied techniques since it is both nonparametric and stochastic and offers greater flexibility. Additional related approaches can also be found in references such as [14, 35]. The related literature vastly shows the applicability of ANN in predicting the DEA results. Moreover, it indicates that DEA and ANN can successfully assist each other. In this study, a combination of resource allocation problem and ANN is employed which serves to estimate the necessary input levels for the production of demanded output levels while the efficiency values of all DMUs remain unchanged. In contrast with inverse DEA models, the proposed method does not need to be reprogrammed. Also, it is simple to be implemented in parallel architectures. This reduces the processing time compared to inverse DEA models with similar results. The rest of the paper unfolds as follows. In Section 2, inverse DEA model and the method of calculation in inverse DEA are described. Section 3 explains the ANN approach which is followed by a back-propagation algorithm. An ANN algorithm for inverse DEA, namely ANN-inverse DEA is introduced in Section 4. Section 5 reports results from the application of ANN-inverse DEA to a really large set of Iranian bank branches. Finally, Section6 deals with the concluding remarks.
Preliminaries
Suppose there are n DMUs, {DMUj : j = 1, …, n} each using m inputs to produce s outputs and also assume
where λj is the intensity variable for DMUj and is the efficiency index of DMUo. If , then DMUo is called (at least) weakly efficient.
Following the studies conducted and the trends taken in inverse DEA [6, 28], Lertworasirikul et al. [30] supposed that DMUo, among a group of current DMUs with their relative efficiency values of , changes its output levels to
They specified the minimum Δ
Moreover, they proved there exists at least an optimal solution to model (2) if and only if
In light of this discussion, they determined a set of non-dominated DMUs based on the output comparisons. As a result, they explained if all the elements of
Via the theory of multi-objective optimization, Δ
ANNs can learn from training samples like human brains, and they have the capability to decide based on the data from past training. The structure of generic ANNs consists of layers and neurons (node) as connection weights. Neurons are processing elements which are fully in connection with each other between consecutive layers. Multi-layer Perceptrons (MLP) is one of the most popular and widely used ANN types. MLP includes three different layers:
The input layer simultaneously receives inputs of the ANN; each input needs one node. This layer shifts the data to the linkage layer, so it is not used to perform any calculations. The output layer refers to the estimation of the network and has neurons as outputs of the ANN.
One or more hidden layers with an arbitrary number of computational nodes lie between the input and the output layers. While each data set is given to the ANN, hidden layers manage the internal mapping and let the ANN to learn and generalize the new data by the formerly learned data sets. Therefore, choosing the number of hidden layers and the number of nodes in each hidden layer is important. It is noteworthy that a network with few hidden layers and hidden nodes inhibits identifying the structure of training patterns. On the other hand, owing to extra calculations, the large number of hidden layers and nodes in each hidden layer is associated with longer training time. In most cases, the best structure of hidden layers is determined through a trial and error process. MLP is feed-forward due to the connections between neurons which are in one direction from the input layer to the output layer without any feedback. An example of an MLP is shown in Fig. 1. The illustrated MLP has three input neurons, two outputs and two hidden layers with four neurons in each.
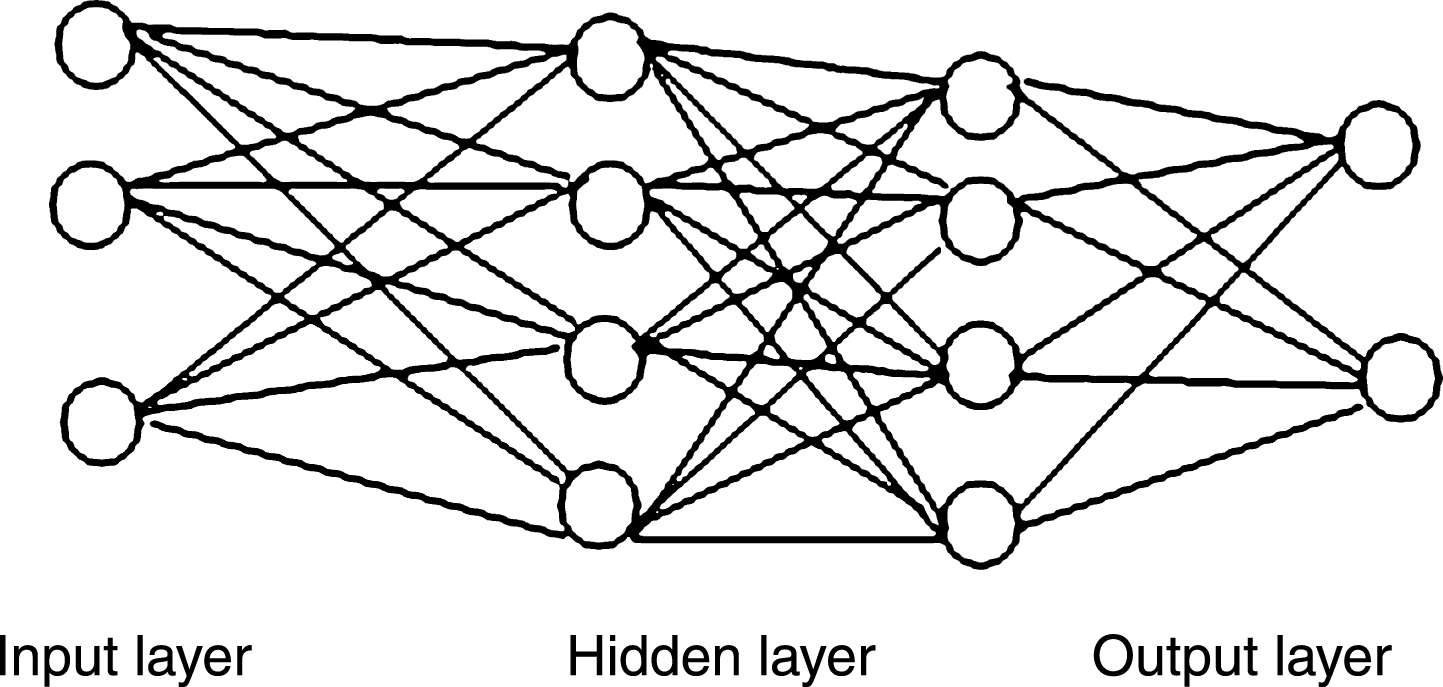
The structure of MLP.
There are two different modes of learning ANNs: supervised and unsupervised. For a supervised learning algorithm, the outputs are known for the given inputs. For an unsupervised learning algorithm, no outputs are specified for a set of inputs. The MLP network is utilized in a supervised manner. Back-Propagation (BP) of Rumelhart et al. [12] is the most popular learning algorithm for a training MLP. Celebi and Bayraktar [10] reminded that the popularity of BP is because of its high level of accuracy and low level of complexity. BP algorithm takes training datum of input patterns and the related set of desired output patterns along with small arbitrary weights.
Following the propagation of inputs in the input layer and directly passing them through the first hidden layer, the weighted inputs are summed up in each node and the result is transferred to an activation function in order to transmit an output from the node. The consequence can be an input to the second hidden layer (if there is any), and so on. Finally, the outcome of the last hidden layer is used as the input for the output layer and the network’s prediction is provided by transforming the sum of weighted inputs into an activation function. In case there is a difference between the desired output and the output produced by the network, the connection weights should be altered and adjusted so as to minimize the Mean Squared Error (MSE) as follows:
Where n1 is the number of nodes in the output layer and P is the number of learning samples (input-output pairs). This error will be distributed in the backward direction from the output layer through each hidden layer down to the first hidden layer. This leads to the so-called Back-Propagation algorithm.
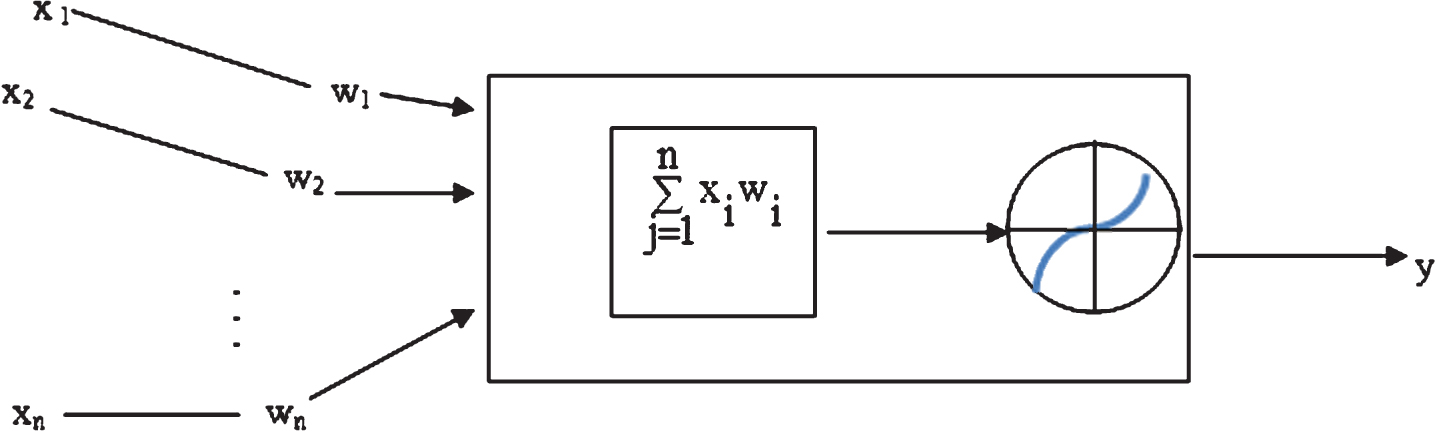
Operation of neuron in BP algorithm.
Figure 2 illustrates a computational neuron of BP algorithm in which x1, x2, x3, …, xn are inputs of the neuron and w1, w2, w3, …, wn respectively show their weights. Output of the neuron is then computed as:
In this section, ANN-inverse DEA approach will be proposed to develop the inverse BCC model to preserve relative efficiency values of all DMUs. At first, the researchers design a network to estimate the efficiency scores of DMUs. To do so, inputs and outputs in the corresponding DEA model are defined as variables in the input layer and the DEA efficiency score is used as the only variable in the output layer.
Then changes in the output levels of several DMUs, e.g. DMUjk : k = 1, 2, …, K, are taken into consideration. The purpose is to propose ANN to estimate the input levels of these DMUs so that the relative efficiency values of all DMUs remain unchanged with no need to solve the resource allocation problem for every single DMU.
The analysis of the proposed network is managed in the following steps:
Step 1: configuring the architecture of the ANN-inverse DEA
In the ANN modeling, the researcher should decide on selecting the architecture components such as the inputs and outputs of the network, the number of hidden layers and that of neurons in each hidden layer, the initial values of weights, and the activation function. In the integrated approach, the architecture components include the following:
Inputs of the network: the original input and output values, the new outputs, and the efficiency value of each DMU are utilized as inputs of the network.
Outputs of the network: the new input values that should be predicted by the resource allocation problem, namely Δ
Number of hidden layers and the number of neurons in each hidden layer: It is noteworthy that the number of hidden layers and the number of neurons in each hidden layer are decided by trial and error.
Weights: Before training begins, the weights are set to small random values, close to zero.
Activation function in output layer: in the present study, linear activation function is used in the output layer.
Activation function in the hidden layer: sigmoid function is used in the hidden layer as follows:
where x refers to
Step 2: partition data into two data sets
The data set is partitioned into two subsets: Training set: The training pattern is used to fit the ANN-inverse DEA parameters and to find the optimal weights Testing set: The testing data is used in order to validate the learned ANN-inverse DEA system.
Step 3: normalizing the data
Since sigmoid function will generate output values in [0,1] and due to the different ranges of inputs, normalization of all data in an acceptable range will help speed up the learning phase and will lead to smooth imperfection of the network. Via the following function, all data are normalized in [0,1].
pn= the normalized value of pi
pmin= minimum value among all the ith component values
pmax= maximum value among all the ith component values
Step 4: training ANN-inverse DEA by training set.
The aim of the training phase is to alter the values of the weighted connections to calculate more precise outputs. Thus the sequence of iterations, each called an epoch, is followed in the training process. Each of these epochs is completed when data set of inputs and desired outputs are presented to the network and the weights are adjusted to reduce the MSE. The errors between the network output values and the desired outputs are propagated back through the network so that they are imputed to the weight connections. BP minimizes the MSE via the gradient (steepest) descent method by updating the network weights according to:
Where
and η is the learning rate.
The learning rate represents the rate of improvement in the training phase and is user-designated (between 0 and 1). If the learning rate is too large, it results in oscillatory learning or converges to a local minimum. On the contrary, if the learning rate is too small, it leads to a long training time but can more closely represent relationships between input and output variables.
The training process is considered complete if any of the following conditions known as stopping criteria is satisfied. A fixed number of epochs are repeated. The MSE falls below a threshold value.
Step 5: Testing ANN-inverse DEA approach by testing set.
The generalization capability of the ANN-inverse DEA is confirmed by evaluating its performance on an independent set of data (testing set).
Step 6: Estimating the predicted outputs using the generated ANN-inverse DEA process.
At this stage, the necessary inputs in regard with the resource allocation problem are estimated, which keep the efficiency scores of all.
In this section, the results from the application of the integrated approach are reported. A large set of 600 bank branches in Iran were gathered. The problem of identification of the banking inputs and outputs is a controversy in the literature [15, 23, 26, 27]. There is not consistency concerning the role of input and output selections due to different research objectives in banking. For instance, Isik and Hassan [20] involved labor, capital and loanable funds as input measures and short-term loans, long-term loans, off-balance-sheet items and other earning assets as output measures. Chang et al. [32] used two inputs, physical capital and labor and two outputs, total loans and other earning assets. Halkos and Salamouris [15] used five financial ratios as outputs with no input measures. They argued that all banks manage in the same market; consequently, the inputs are identical for all banks. Weill [26] selected Personnel expenses, other noninterest expenses and interest paid as inputs and loans and investment assets as outputs. Wang et al. [23] defined fixed assets and labors as inputs and Interest income, non-interest income and bad loans as outputs. In addition, deposits are considered as Intermediate measures. Lastly, in order to consider the most relevant and acceptable items of banking system, which are commonly used for measuring efficiency in the literature, this study regards the following categories of inputs:
Input1 (personnel) includes personnel expenses. Input2 (Payable interest) refers to interest expense and revenue. Input3 (Deferred receivables) concerns to Instalments of deferred receivables and deferred payment credits.
And the following categories of outputs are considered:
Output1 (Facilities) consists of term loans, cash credit, overdraft, letters of credit, and bank guarantees. Output2 (The total sum of four main deposits) refers to demand deposits, short-term investment deposits, long-term investment deposits, and foreign currency deposits. Output3 (Received interest) represents earning assets into investment and interest income. outpu4 (Fee received) includes fee income and fee- based services. output5 (Other deposits) refers to other earning asset, Commercial deposits and Retail deposits. It is worth stressing that all inputs and outputs are measured in terms of Iranian million Rials.
Tables 1 and 2 relate a summary of the statistical properties for inputs and outputs.
Summery statistic of input values
Summery statistic of input values
Summery statistic of output values
The first and the second rows in Tables 1 and 2 are the parameter values associated with the normalization equation Equation (7). After normalizing the data, we designed an ANN to measure the efficiency scores of 600 bank branches. For more details of this ANN, readers are referred to [4, 35]. The efficiency results for the randomly-selected sample of 200 bank branches are listed in Table 3.
Bank branch’s efficiency scores
Now suppose the outputs of 237 branches are changed so that positive and negative changes are taken into account at the same time. The stochastic properties of new outputs are summarized in Table 4. It has been straightforwardly confirmed that new outputs are in Pout. Hence model (2) can estimate the necessary inputs while the efficiency values of all branches remain unchanged.
Summery statistic of new output values
In this research, the aim has been to employ the ANN-inverse DEA to estimate inputs for 237 banks such that the efficiency scores of 600 banks remain unchanged. To this end, the illustrated neural network from the previous section will be used. At first, the original input and output values of 237 banks, their efficiency scores, and their new outputs as inputs of the ANN-inverse DEA are normalized. Afterward, these branches are partitioned into two parts, the training set and the validation set. 75% of the branches are used as the training set which determine the optimal network parameters, and the remaining 25% are used as the validation set which serve to evaluate the network generalization capability. The reason for selecting a high percentage of data for training is that the network could recognize the patterns governing the inputs and outputs and accommodate to different conditions in a better way. Let
Estimated neural network parameters
Summery statistic of estimated input values
To verify the credibility of the obtained results, the efficiency values of 600 bank branches (by applying new inputs and outputs) are gauged as before by the ANN. Ultimately, comparison of efficiencies by the original inputs and outputs and the new ones are analyzed through the following policies:
From Tables 3 and 7, it can be seen that efficiency scores for certain bank branches are more than 1. This is not voidable in the DEA context. It is not, however, a surprising result for DEA-ANN, since ANN with statistical properties generate a stochastic frontier according to efficient DMUs (Desheng et al., [35]). In what follows, Fig. 3 depicts a comparison of the efficiency scores for the remaining branches before and after changes in 237 branches (note that 200 random branches in Tables 3 and 7 are not considered). Figure 3a regards bank branches No. 1-299, and Fig. 3b regards bank branches No. 300-600.
Figure 4 shows histogram of efficiency to the 600 evaluated bank branches according to the original inputs and outputs and new ones.
Bank branch’s efficiency scores with new inputs and outputs
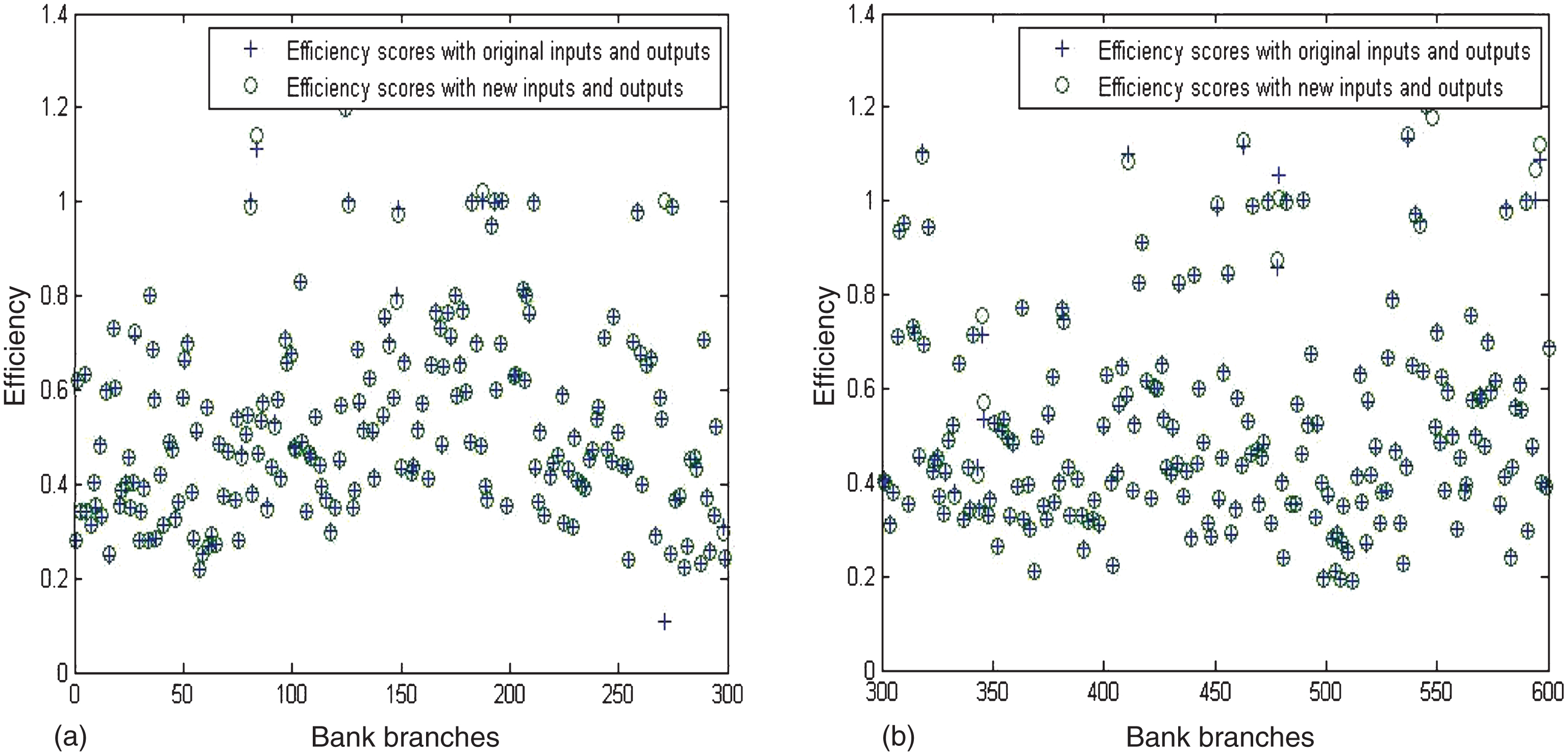
Efficiency scores of bank branches (a) bank branches No. 1-299, (b) bank branches No. 300-600.
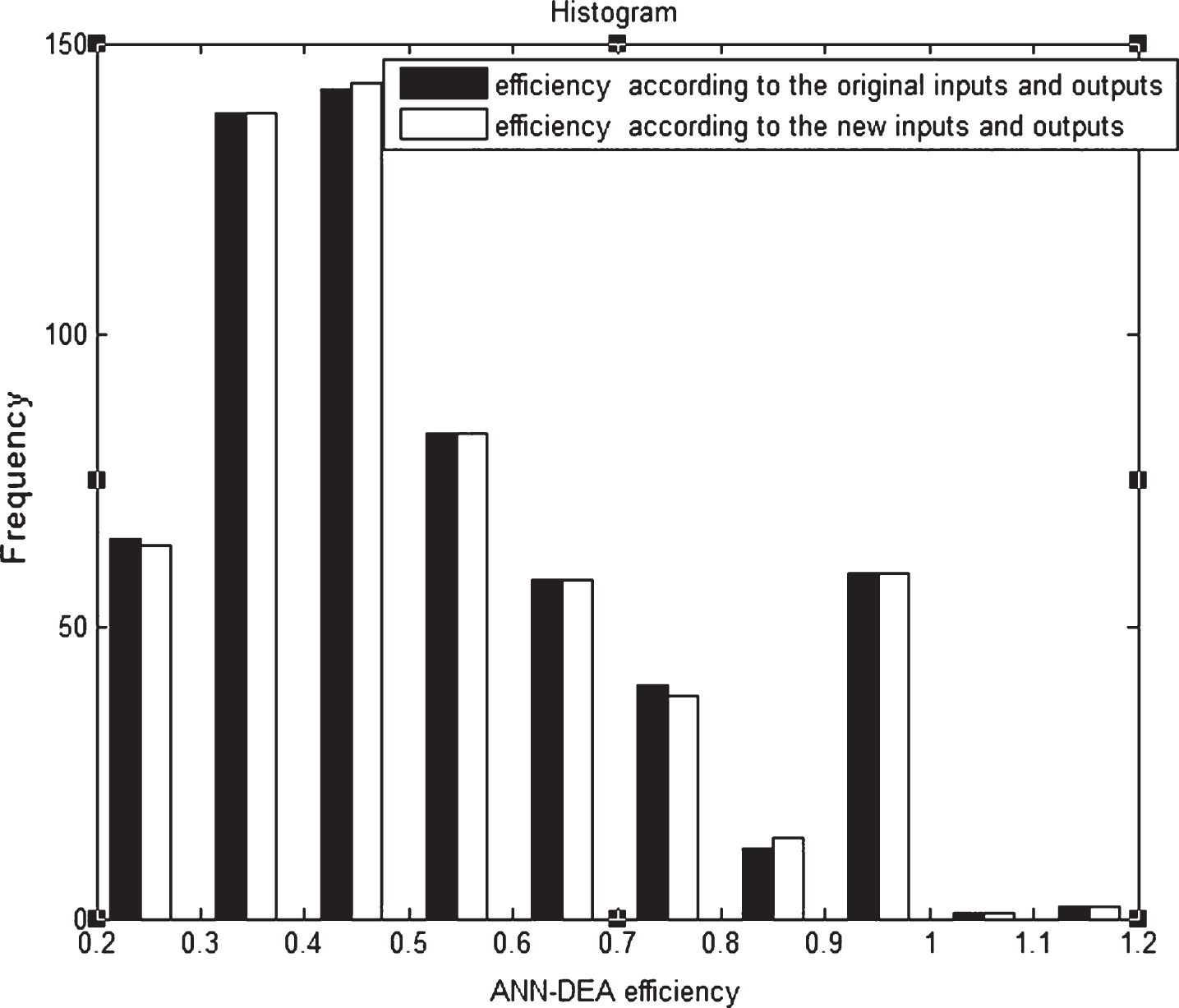
Histogram of efficiency to the 600 evaluated bank branches according to the original inputs and outputs and newones.
As is evident by Fig. 4, the histogram of efficiency measures following original inputs and outputs is drastically similar to the histogram of efficiency results according to the new inputs and outputs. The average distance between efficiencies of the original inputs and outputs is obtained 0.1703 and the average distance between efficiencies by the new inputs and outputs is procured0.1729.
It signifies that there is similar variability in the efficiencies of original inputs and outputs and the new ones. The correlation between efficiency and the original inputs/outputs and the new ones are declared in the following table:
According to Table 8, the correlation between efficiency and inputs/outputs does not change after the mutation of inputs and outputs.
The correlation between efficiency and the inputs/outputs
1correlation between efficiency and the original inputs/outputs.
2correlation between efficiency and the new inputs/outputs.
MSE values for the train, test, and all data sets of the ANN models (which estimate bank’ efficiency)
1MSE values related to the ANN with original inputs and outputs. 2MSE values related to the ANN with new inputs and outputs.
The above analyses imply reliable input forecasts while keeping the efficiency of bank branches unchanged.
Resource allocation problem is a kind of inverse DEA that is concerned with the estimation of input levels when some or all output levels are changed while the efficiency score is fixed. This study combined a neural network with resource allocation problem to present a new approach to control the changes in input levels for large datasets having many DMUs so that the efficiency scores of all DMUs are preserved. The back-propagation algorithm has been used to determine the necessary input values for the given output values of a big set of Iranian banks so that the relative efficiency values of all bank branches could remain unchanged.
The efficiency scores of bank branches were evaluated through ANN approaches before and after making changes in inputs and outputs. Tables 3 and 7 demonstrated the efficiency scores of 200 randomly selected branches. The efficiency results of the remaining bank branches were contrasted in Fig. 3. Other quantities were used to validate the preciseness of the input prediction by ANN-inverse DEA approach. The results demonstrate that the integrated ANN-inverse DEA predicts reliable input levels for bank branches.
The needs of inverse DEA models for information, time, and computer memory are far more than those required by ANN-inverse DEA. It is noteworthy that the topology used in the ANN-inverse DEA, and particularly the number of hidden layers as well as the number of neurons in each hidden layers, have a significant impact on minimizing the error. However, the analysis of errors in previous related research shows that large datasets are associated with the smaller errors. Hence, the proposed approach is a useful method to get inverse DEA results, especially when there are large numbers of DMUs.