
Abstract
In most real life investment situations future security returns are represented mainly based on expert’s judgments due to the occurrence of unexpected incidents in economic and social changes or lack of historical data. In order to tackle such uncertainties, the returns of the securities are evaluated by the experts instead of historical data. In this study, a multi-objective uncertain portfolio selection model has been proposed by defining average return as expected value, risk as variance and divergence among security returns as cross-entropy where the security returns are considered as uncertain variables. The transformed deterministic form of the proposed model is presented by considering security returns as linear uncertain variables. The deterministic model is then solved by using two multi-objective genetic algorithms (MOGAs), namely, Nondominated Sorting Genetic Algorithm II (NSGA-II) and Archive-Based hYbrid Scatter Search (AbYSS). We use a dataset from the Shenzhen Stock Exchange to illustrate the performance of the algorithms. Finally, a comparative study is performed in terms of certain performance matrices among NSGA-II and AbYSS.
Keywords
Introduction
Markowitz [18] first presented the idea of an optimal portfolio selection by taking into account the trade-off between return and risk. The author introduced mean–variance model which plays an important and critical role in modern portfolio theory. Markowitz’s model is a bi-criteria optimization problem where an investor attempts to maximize portfolio expected return for a given amount of portfolio risk or minimize portfolio risk for a given level of expected return. However, most of the existing approaches for portfolio optimization problems are developed based on a single objective semi-optimal solution, rather than a set of Pareto optimal solutions that exhibits the trade-offs between the two objectives, risk and return objective.
Markowitz’s pioneering work has been widely extended by various researchers considering several conflicting objectives such as the mean semi-variance model [34], mean absolute deviation model [9, 52], mean-risk below-target model [12], mean VaR model [29], mean CVaR model [36], mean-entropy model [40], mean-variance-skewness model [16, 37], mean-entropy-skewness model [33], etc.
The conventional portfolio selection models are generally obtained by probability theory based on precise historical data. However, in real situation there are many inputs in the security markets, such as company performance, market forces of supply and demand, political factors, etc. These types of inputs are associated with non-statistical uncertainty and cannot be assessed using probability theory. They involve some linguistic knowledge in the security return which can be tackled by possibility theory, i.e., fuzzy set theory. Using risk management several fuzzy portfolio selection models [31, 48] have been proposed.
The belief degree of human beings has much greater variance than the real frequencies due to their conservatism or optimism. In order to handle belief degrees, counter-intuitive results may occur if we use probability theory. To model belief degrees, Liu [4] established the concept of uncertainty measure and further developed it in [5]. Liu and Chen [7] also proposed evaluations rather than historical data. Huang [43, 45] also proposed risk curve and risk index uncertain programming for solving optimization problems involving uncertain variables. Uncertainty theory has been used by the researchers in different portfolio selection problems. Huang [42] introduced uncertainty theory in portfolio selection in which the security returns are given by the experts’ which contributed in risk control of portfolio selection. Qin et al. [54] developed a mean-variance portfolio selection model in uncertain environment. Huang [41] presented a fuzzy mean-semivariance portfolio model and solved the model using genetic algorithm. Furthermore, the mean-variance and mean-semivariance portfolio selection models were also proposed by Huang [44] for uncertain environment. In 2013, Huang [46] also proposed multi-period uncertain portfolio selection. Recently, Huang [47] also developed an uncertain portfolio selection problem by considering background risk.
In this study, we have proposed a multi-objective mean, variance, cross-entropy model of uncertain portfolio optimization problem. The mean, variance and cross-entropy of the uncertain securities represent the average return, risk and divergence among the securities respectively. The model is then solved by two classical multi-objective optimization techniques as well as by two multi-objective genetic algorithms (MOGAs). We have also proposed two related theorems to examine the Pareto optimality condition of the compromise solutions generated by the proposed model using classical multi-objective methodologies. For solving the model with different methodologies, we have considered a dataset of 20 security returns from Shenzhen Stock Exchange. The performance of MOGAs are also studied for our proposed model.
The rest of the paper is organized as follows. Section 2 provides some definitions and properties of uncertain variables. In Section 3, we discuss about uncertain programming. Section 4 discusses two multi-objective evolutionary algorithms: NSGA-II [23] and AbYSS [1]. Section 5 explains about the proposed multi-objective portfolio selection model in uncertain environment. In Section 6, we have provided a real life case study to illustrate the performance of the proposed model when solved by different techniques. Finally, Section 7 concludes the paper.
Preliminaries
Liu [4] proposed the concept of uncertain measure and founded uncertainty theory. In this section, we recall some basic definitions and properties about uncertain measures and uncertain variables, which are associated with this article.
Let Γ be a nonempty set and
Then, the triplet
It is denoted by,
The Zigzag uncertain variable is denoted by Z (a, b, c), where a, b and c are real numbers with a < b < c.
The normal uncertain variable is denoted by N (μ, σ) where μ and σ are real numbers with σ > 0 .
For examples, the linear uncertain variable
In terms of distribution function cross-entropy is defined as,
where Φ ξ and Φ η are the respective distribution functions of uncertain variables ξ and η.
If E [ξ1] ≥ or (>) E [ξ2] then ξ1 ≽ Eor (≻ E) ξ2, where ξ1 ≽ Eξ2 means that the valuation of ξ1 is greater than or equal to that of ξ2 in terms of the corresponding expected values of ξ1 and ξ2. ξ1 ≻ Eξ2 means that the valuation of ξ1 is strictly greater than ξ2 in terms of the corresponding expected values of ξ1 and ξ2.
Uncertain programming is a type of mathematical programming which contains uncertain variables in both the objectives and constraints. We discuss uncertain single objective and uncertain multi-objective programming in subsequent sub-sections.
Uncertain single objective programming (USOP)
In uncertain programming, an uncertain objective function is represented as f (x, ζ) , where x = (x1, x2, …, x
n
) is a n-dimensional decision vector and ζ = (ζ1, ζ2, …, ζ
m
) is an uncertain coefficient vector. In uncertain programming model both the objective function as well as in constraints can be uncertain. The set of uncertain constraints is defined as, g
l
(x, ζ) ≤ 0, l = 1, 2, …, p. The set of uncertain constraints does not define the crisp feasible set, however, the constraint conditions hold with certain confidence levels α1, α2, …, α
p
. Then, we obtain a set of chance constraints,
In order to obtain an optimized expected objective value subject to a set of chance constraints, Liu [4] proposed the following uncertain single objective programming model.
Equation (11) can also be remodeled in terms of variance and cross-entropy of uncertain variables which are defined below in (12) and (13) respectively.
where η is an uncertain variable from which the cross-entropy of an uncertain vector ζ, is to be calculated.
Similarly we can also define an optimal solution x* of (12) and (13) if,
becomes,
Many real world optimization problems consider a vector of objectives which are conflicting in nature. These objectives are needed to be optimized contemporaneously. To optimize such vector of objectives multi-objective programming techniques are applied widely. Liu and Chen [7] first introduced the uncertain multi-objective programming,
where f i (x, ζ) are the uncertain objective functions for i = 1, 2, …, r, g l (x, ζ)’s are the uncertain constraint set and α l ’s are the confidence levels for l = 1, 2, …, p. Due to the existence of trade-off among the objectives there does not exists a single optimal solution that simultaneously minimizes all the objectives of (23). In this situation, we use the concept of Pareto front containing a set of nondominated optimal solutions.
We can also design uncertain multi-objective model by minimizing the variance and cross entropy of the uncertain objective functions. We reformulate Problem (23) by considering variance and cross-entropy for uncertain objective vectors which are represented by (24) and (25).
Combining models (23) through (25) together we formulate a multi-objective model in (26).
If the constraint set is deterministic then (26) can be remodel as,
Similarly, we can also define a Pareto optimal solution x* for uncertain multi-objective programming in (24) and (25) below.
The uncertain objective vectors can be converted to a USOP by aggregating all f i (x, ζ) of (26) with a real-valued preference function subject to a same set of chance constraints. This model is referred to as a compromise model and the corresponding solution of the model is known as compromise solution. In Subsections 3.3 and 3.4, we discuss about two compromise models, weighted sum method and global criterion method for UMOP. In this article, the global criterion method has been extended to solve UMOP. Two related theorems are also proposed in Subsection 3.3 and 3.4 to prove that the solutions of the equivalent compromised model of (26) is Pareto optimal.
We implement weighted sum method on model (26), to formulate its compromise model asbelow,
Model (31) can also be reformulated as (32) with uncertain objective functions and crisp constraint functions.
The Pareto optimality condition for the solution of (31) is proved by the following theorem.
Furthermore we can say,
Hence we can write,
∀p ={ 1, 2, …, u } , ∀ q = { u + 1, u + 2, …, v } and ∀t ={ v + 1, v + 2, …, r }.
Moreover, for at least one index value of p, q and t,
It says, x* is not the optimal solution of model of (31), which contradicts with our hypothesis that x* is an optimal solution of (31) at the beginning of the proof. Therefore, we can say that x* is the Pareto optimal solution of model (26). In the similar way this theorem can also be proved considering model (32) and (27).
We formulate the compromise model of problem (26) by adhering the concept of global criterion method [35] as given below,
Model (33) can also be designed as (34) with uncertain objective functions and crisp constraint functions.
The Pareto optimality condition of the compromise solution generated from (33) is proved in the following theorem.
Moreover,
Therefore,
Also, for at least one index value of each p, q and t,
This implies,
Also for at least, one index value of p, q and t
Thus, x ≼ Ex*, x ≼ Vx* and x ≼ Dx*, which suggests that x* is not the optimal solution of model (33). But this result contradicts with our previous hypothesis that x* is an optimal solution. Hence x* is the Pareto optimal solution of model (26). In the similar way this theorem can also be proved for model (34) with respect to (27).
Since the initiation of multi-objective genetic algorithm (MOGA) by Fonseca and Flaming [10], it has drawn immense research interest among researchers and has become a well known methodology for solving complex multi-objective optimization problems. MOGA considers population comprises of nondominated and diverse set of solutions. In the literature there exist different variant of MOGAs such as [1, 30], etc. Unlike a single objective genetic algorithm, a MOGA generates a set of solutions which creates a set of nondominated fronts in the objective space.
In this article, we discuss about NSGA-II and AbYSS developed by Deb et al. [23] and Nebro et al. [1] respectively.
Nondominated sorting genetic algorithm II (NSGA-II)
A nondominated sorting genetic algorithm II (NSGA-II) has been developed by [23]. It is an elitist model, which ensures retaining the fittest candidates in the next population to enhance the convergence. In a generation, the parent of size N produces same number of offspring using selection, crossover and mutation operators. These offspring are then combined with the parent population to form a total of 2N solutions. Among these, best N solutions are selected for next generation using crowded-comparison operator [23]. The crowded-comparison operator uses two metrics: nondomination rank (i
rank
) crowding distance (i
distance
).
Solutions having lower i rank are preferred than those with higher i rank . If the solutions have same i rank then the solutions with greater i distance , i.e., from less crowded regions are selected. This way NSGA-II promotes elitism and diversity in every generation. This process continues until the elimination criteria (maximum number of function evaluations) is reached.
The important features of NSGA-II are nondominated sorting procedure for ranking solutions and introduction of elitism. Nondominated sorting genetic algorithm (NSGA) [27], i.e., the earlier version of NSGA-II uses a sharing function to maintain the diversity in the population with appropriate setting of the σ share parameter. NSGA-II eliminates sharing parameter and introduces crowded-comparison operator, discussed earlier.
Archive-Based hYbrid Scatter Search (AbYSS)
Archive-Based hYbrid Scatter Search (AbYSS) proposed by [1] implements the technique of scattered search [13] along with crossover and mutation operators to enhance its search capability while exploring the search space of the MOPs. AbYSS [1] incorporates the concepts of Pareto archived evolution strategy (PAES) [22], NSGA-II and Strength Pareto Evolutionary Algorithm 2 (SPEA 2) [14]. The selection process of AbYSS subsumes the density estimation of SPEA 2 [14] while selecting the solutions from the initial set of population which are eventually used to build the reference set. It maintains an external archive to store the nondominated solutions of the objective functions found so far from the search process of the algorithm by adapting the technique of PAES and at the same time uses the crowding distance of NSGA-II as the nichingmeasure.
AbYSS initially generates a diverse set of solutions using diversification generation method [1] which sub-divides the ranges of all the decision variables into equal intervals. The value of each variable of a solution is determined in two steps: Firstly, it randomly selects an interval of a variable. The probability of selecting such an interval is inversely proportional to the number of times the same interval was selected previously for that variable. Secondly, once the interval for the variable is selected a value from that interval is selected randomly and is assigned to the variable. This process is applied to all the decision variables of every solution. These solutions are then improved by using improvement method [1] which implements the local search algorithm along with the (1+1) evolutionary algorithm (EA) [1]. The (1+1) EA uses the mutation operator and Pareto dominance test and does not use non-stochastic parameters in scatter search technique, used as local search, in order to get the benefits of well-known popular operators of EAs. The improvement method ensures that all the nondominated solutions are inserted in the external archive and at the same time this method adjusts the improvement effort of each solution. In this way an initial set of population P is created with diverse and better set of solutions. The reference set update method [1] is applied on the initial population P to select a reference set of population P r . This selection process follows the selection strategy used in SPEA 2 [14]. Once the reference set is filled up with P r solutions, new solutions are generated by crossover operation which is then improved by improvement method. Then these solutions are tested again for their inclusion in the reference set. The balance between elitism and diversity in the population of AbYSS is maintained by the reference set. This set consists of two subsets. One subset (RefSet1) is responsible for storing all the solutions having best fitness values in terms of all the objectives and the other subset (RefSet2) contains all those individuals that promote diversity. The individuals of the subsets of referenceset are combined to generate new solutions which are again improved. This method is basically responsible for the progressive improvement of both the population and the reference set. The subset generation for the reference set and their combination after possible improvement of solutions to form a reference set of better solutions are done respectively by subset generation [1] and solution combination method [1] respectively. The new solutions explored from subset generation and solution combination methods are compared pairwise with the solutions of the external archive (repository). If the newly generated solution is dominated by at least one solution of the archive then the new solution is discarded, otherwise it is added in the archive. If a set of solution(s) in the archive are dominated by the newly generated solution then the entire set of such solution(s) are replaced by the new solution in the archive. In this process if the archive attains its maximum limit then a solution from the archive having smallest crowding distance is replaced by the new solution.
The subset generation and solution combination are continued for the reference set until no new solutions are found. Then there is a restart phase which consists of three steps: firstly, the solutions from RefSet1 are inserted in the population P. Secondly, the best n solutions from the archive having n best crowding distance [20] are inserted in P, where n is the minimum archive size, which is half of the size of P. The remaining solutions of P are generated by diversification generation [1] and improvement method, as mentioned earlier. Once the population P is created, the population of reference set P r is selected out of it again and is improved along with the update in the external archive until no new solution is found. This process continues until the stopping criteria of the algorithm is reached.
Proposed multi-objective portfolio selection model
In this section, we have formulated a three objective uncertain portfolio selection model. Let us consider a financial market with n risky assets. Let x i and ξ i (i = 1, 2, …, n) are the investment proportion and the uncertain return of the ith security respectively and η is a prior investment return. The purpose of our model is to keep the divergence of the investment return from η as small as possible. In this article, the cross-entropy is used to measure the divergence, variance to measure the risk and expected value to measure the return.
Then the mathematical formulation of the mean-variance-cross-entropy multi-objective portfolio selection problem is modeled below in (35).
Multi-objective decision-making problems are generally solved by combining the multiple objectives into one scalar objective, whose solution is a Pareto optimal solution for the original multi-objective decision-making problem. A multi-objective model with uncertain variables can be considered as an evolution of the multi-objective decision-making model with uncertain variables. The security returns represented by uncertain variables with linear distributions may not be independent on each other. Therefore it is difficult to obtain the optimal solution of the multi-objective portfolio selection problem through above results.
In this article, we have solved the proposed model by two multi-objective classical approaches, which are weighted sum and global criterion method. Moreover two MOGAs: i.e., NSGA-II and AbYSS are used to solve the model.
To illustrate our proposed portfolio selection model presented in (35) we have considered a dataset of 20 investment returns from the Shenzhen Stock Exchange. For the portfolio model its average return is determined by expected value, risk is defined by variance and divergence among security returns by cross-entropy.
We solve and compare the results of equivalent compromise models, (32) and (34) for (35). This section also discusses about the nondominated front obtained by solving model (35) using NSGA-II and AbYSS.
20 security returns for (35), used here for experimentation are expressed as linear uncertain variables. These security returns are listed in Table 1 with their corresponding security codes. Table 2 displays expected value (E), variance (V) and cross entropy (D) of 20 uncertain security returns. We have considered a linear uncertain variable η, which is denoted as
Uncertain returns of 20 securities (units per stock)
Uncertain returns of 20 securities (units per stock)
Expected value (E), variance (V) and cross-entropy (D) of 20 uncertain investment returns
Table 3 displays the compromised results of (32) and (34) with the corresponding values of E, V [f (x, ζ)] and D [f (x, ζ, η)]. It is observed from Table 3 that the solutions which are generated by solving the models, (32) and (34) independently using weighted sum and global criterion methods respectively are nondominated with respect to the model (35).
Compromised solutions obtained from weighted sum and global criterion methods
Table 3 displays the compromised results of (32) and (34) with the corresponding values of E [f (x, ζ)], V [f (x, ζ)] and D [f (x, ζ, η)]. It is observed from Table 3 that the solutions which are generated by solving the models, (32) and (34) independently using weighted sum and global criterion methods respectively are nondominated with respect to the model (35).
To find a set of nondiominated solutions, we also optimize the model (35) using two MOGAs, which are, NSGA-II and AbYSS. In order to make a comparison between two MOGAs: NSGA-II and AbYSS, the nondominated optimized solutions, generated by them, are analyzed in details in terms of the performance metrics which are, hypervolume (HV) [13], spread (S) [2], generational distance (GD) [11] and inverted generational distance (IGD) [11]. For most of the real life problems, the set of optimal solutions in the Pareto front (PF) are usually not available. For our proposed model (35), there also exists no PF in the literature. So, we approximate the PF by generating a reference front by collecting all the best quality solutions from every independent execution of both NSGA-II and AbYSS.
The parameter settings for both the algorithms, NSGA-II and AbYSS, are listed below while optimizing the proposed portfolio model (35). Population size = 100, Crossover probability = 0.9, Mutation probability = 0.03 Number of function evaluations = 25,000.
Mean and s.d. of HV, S, GD and IGD after 100 runs of NSGA-II and AbYSS
Median and I.Q.R. of HV, S, GD and IGD after 100 runs of NSGA-II and AbYSS
The parameters settings specifically required for AbYSS are:
RefSet1 size = 50, RefSet2 size = 50 and Improvement round = 4.
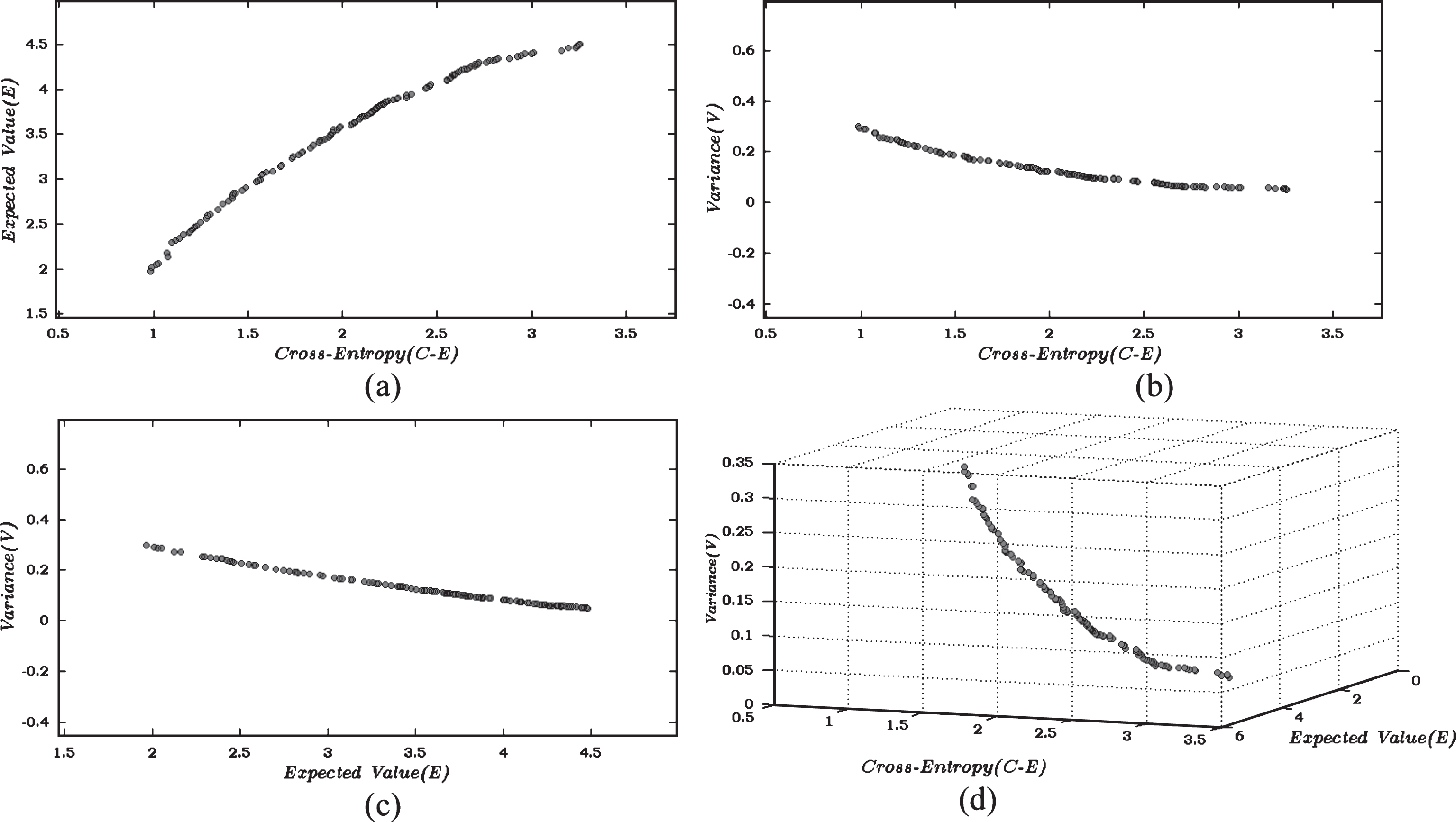
Different nondominated solutions of the proposed Portfolio model after 25000 function evaluations of NSGA-II.
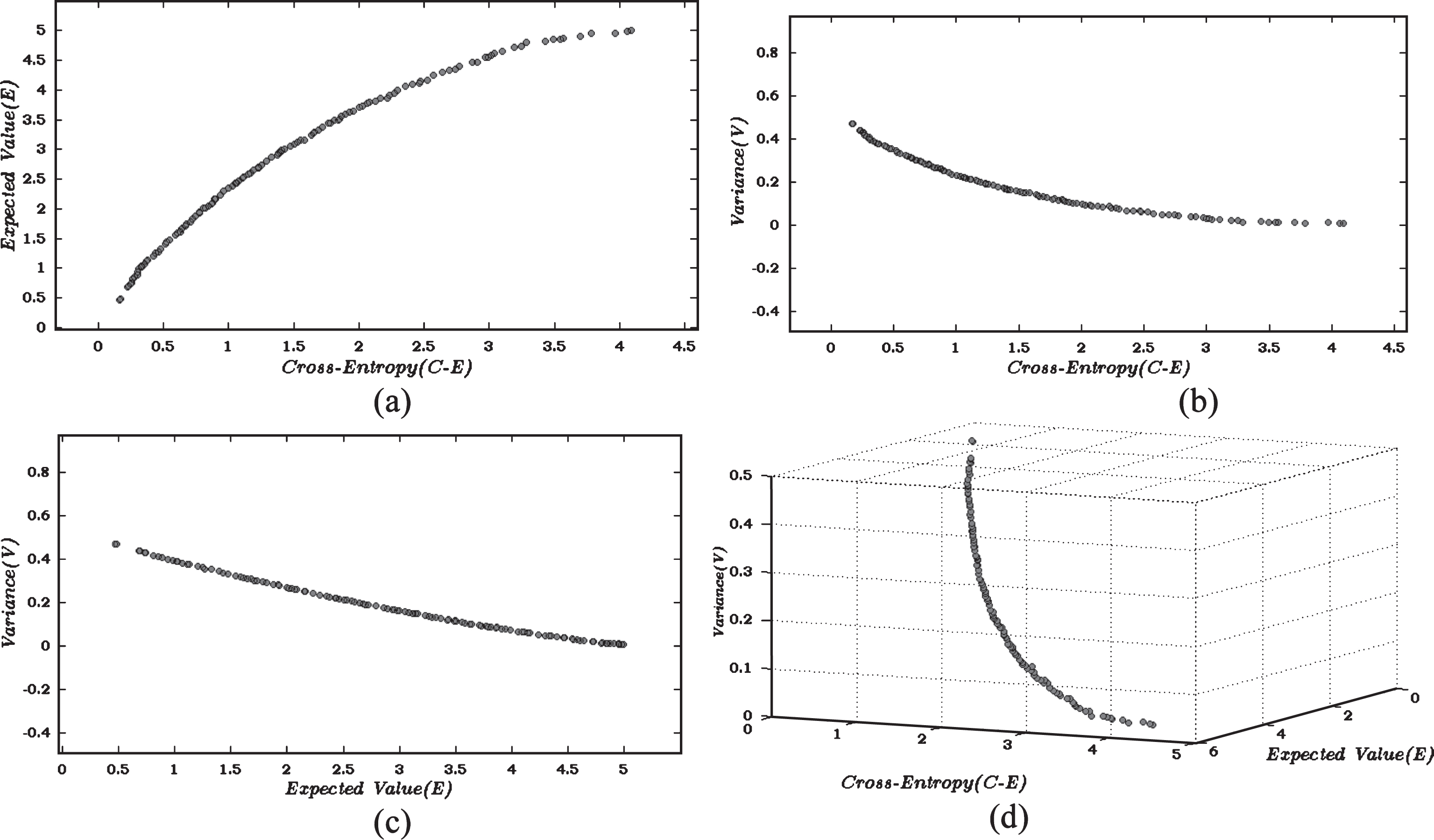
Different nondominated solutions of the proposed Portfolio model after 25000 function evaluations of AbYSS.
Nondominated solutions generated after 25,000 function evaluations, are depicted in Figs. 1(a-d) for NSGA-II and Figs. 2(a-d) for AbYSS. Figures 1(a) and 2(a) display the nondominated solutions considering two objectives, cross-entropy (D) and expected value (E). Figures 1(b) and 2(b) display the nondominated solutions for the objectives cross-entropy (D) and variance (V). Figures 1(c) and 2(c) display the nondominated solutions for expected value (E) and variance (V). Finally, Figs. 1(d) and 2(d) display the nondominated solutions considering all the 3 objectives: cross-entropy (D), expected value (E) and variance (V).
We have used jMetal 4.5 [20] framework for simulation of the MOGAs. Considering stochastic fluctuations of the MOGAs, every simulation of the results with the mentioned parameter settings as mentioned above were executed 100 times. For each execution, different performance metrics, e.g., HV [13], S [2], GD [11] and IGD [11] are evaluated for the optimized solutions obtained after 25000 function evaluations with respect to the corresponding reference front.
Different statistical measures of the performance metrics, HV, S, GD and IGD are displayed in Tables 4 and 5. Table 4 gives the mean and standard deviation (s.d.) while median and interquartile range (I.Q.R.) are shown in Table 5. The statistical parameter values in both the Tables 4 and 5 not only determine the quality of the optimized solutions obtained using two MOGAs separately but also the relative performance between them while optimizing the proposed model defined in (35).
In Table 4 we observed that AbYSS outperforms NSGA-II in terms of the performance measures, HV, S, GD and IGD for both mean and s.d. It suggests that AbYSS proves to be relatively better than NSGA-II for the proposed portfolio selection model. Table 5 shows that AbYSS is superior to NSGA-II while considering the medians for all the performance metrics. The statistical dispersion for all the performance metrics, i.e., HV, S, GD and IGD are also measured as the difference between lower and upper quartile. This measure is displayed as I.Q.R. in Table 5. By observing the I.Q.R. values of HV, GD and IGD we notice that the deviation around the median is less for AbYSS than NSGA-II. While for S, the deviation around the median is less for NSGA-II compared to AbYSS. This suggests that the probabilistic fluctuations of AbYSS after executing model (35) are less while calculating HV, GD and IGD compare to NSGA-II. In the similar way the occurrence of probabilistic fluctuation is less for S when NSGA-II is considered for execution of (35) as compared to AbYSS.
Figure 3(a-d) depict the normal probability plots of all the performance metrics. The plot includes a reference line useful for determining whether the dataset follow a normal distribution. The reference line is shown as dashed line. The performance metrics which are calculated after execution of AbYSS 100 times on model (35) are represented by ′ × ′ symbol, where for NSGA-II the representation symbol is ′o′ in the normal probability plots. If the dataset follows normal distribution then the elements of the dataset will concentrate around the reference line. More the elements of dataset is dispersed from the reference line there will be less chance that the dataset will follow normal distribution. From Fig. 3(a) and (b), we can affirm that, HV and S values obtained after 100 executions of AbYSS are relatively more normally distributed than those obtained by NSGA-II for same number of executions. Figure 3(c) and (d) suggest that, the values of GD and IGD obtained from 100 runs of NSGA-II are relatively more normally distributed than those which are obtained after executing AbYSS equal number of times. The affirmation related to Fig. 3(a-d) can also be verified from the p-values which are listed in Table 6. The p-values of 100 observations of HV, S, GD and IGD obtained by equal number of executions of NSGA-II and AbYSS are evaluated by conducting t-test.
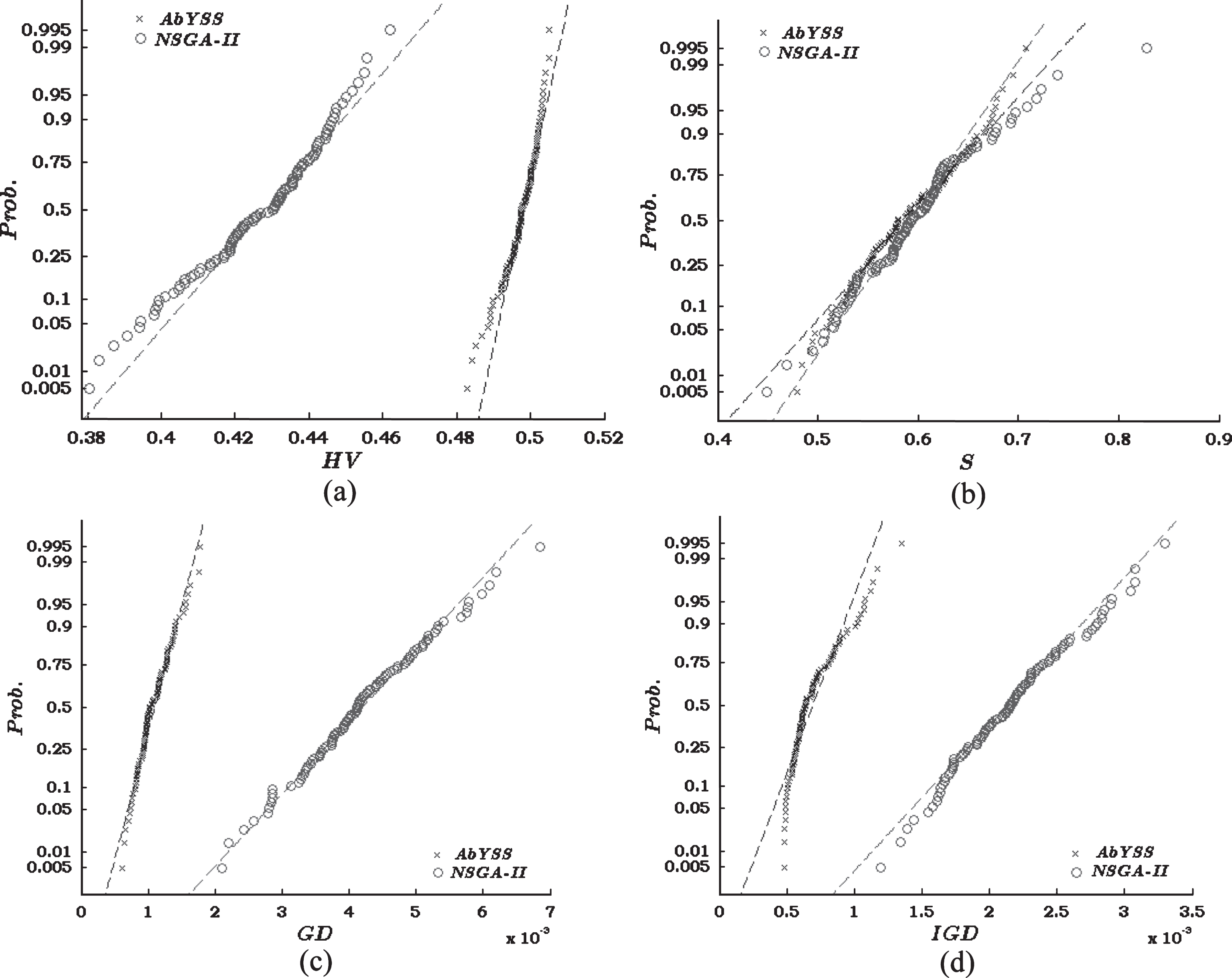
Probability plot of normal distribution for (a) HV, (b) s (c) GD and (d) IGD obtained after 100 runs of NSGA-II and AbYSS.
p-value of different performance metrics obtained by conducting t-test
We have considered a confidence level of 95% to perform the test. For this test, we have set the null hypothesis (H0) as the data corresponding to each dataset comes from a normal distribution. Considering AbYSS and NSGA-II, the corresponding p-values of HV and S validate our affirmation about Fig. 3(a) through Fig. 3(d), i.e., for Fig. 3(a) and (b), HV and S values obtained after execution of AbYSS [1] are more normally distributed than those obtained after executing NSGA-II [23]. Whereas, Fig. 3(c) and (d), shows that GD and IGD, obtained after execution of NSGA-II are more normally distributed than those obtained after executing AbYSS.
A multi-objective model of uncertain portfolio selection model has been proposed in this article. The model considers three objectives: maximization of expected value and minimization of both variance and cross-entropy. We have considered 20 investment returns of Shenzhen Stock Exchange for our proposed portfolio selection model. The investment returns are considered as linear uncertain variables. The proposed model is solved by two compromise multi-objective programming approaches: weighted sum approach and global criterion method. The model is also solved with two different MOGAs, namely, NSGA-II and AbYSS. The quality of solutions obtained from these MOGAs are analyzed in terms of the performance metrics HV, S, GD and IGD. We then provide some statistical interpretation on the values of those performance metrics. The overall analysis shows that AbYSS outperforms NSGA-II while solving the proposed portfolio selection model.
In future, large number of securities can be considered to study the performance of the proposed model. The proposed model can also be extended in fuzzy-random, uncertain-random and other hybrid imprecise environments.
Footnotes
Acknowledgments
The authors are very much grateful to the Editor and anonymous referees for their constructive and valuable suggestion to enhance the quality of the manuscript.
Saibal Majumder, an INSPIRE fellow (IF150410) would like to thank DST, Govt. of India, for providing him financial support for the work.