
Abstract
In the mean-variance-skewness-kurtosis framework, this paper discusses an uncertain higher-order moment portfolio selection problem when security returns are given by experts’ evaluations. Based on uncertainty theory and the assumption that the security returns are zigzag uncertain variables, an uncertain multi-objective portfolio optimization model is proposed by considering the maximization of both the expected return and skewness of portfolio return while simultaneously minimizing the risk and kurtosis of portfolio return. Subsequently, the proposed model is transformed into a single-objective programming model by using fuzzy programming approach, in which investor preferences for high moments are incorporated. Furthermore, a modified flower pollination algorithm (MFPA) is developed for solution, in which PSO in local update strategy (PSOLUS) and dynamic switching probability strategy (DSPS) are employed to enhance the local searching and global searching abilities. Finally, a numerical example is presented to illustrate the application of the proposed model and solution comparisons are also given to demonstrate the effectiveness of the designed algorithm.
Keywords
Introduction
Portfolio optimization as an effective wealth allocation and risk management tool has attracted a lot of attention from both academics and practitioners. The mean-variance (MV) model formulated by Markowitz [38] lays the foundation of modern portfolio selection theory. As it is well known, the standard MV model relies strictly on the assumptions that the returns of assets are normally distributed or investor’s utility function is quadratic. However, empirical studies show that asset returns typically have heavy-tailed feature than implied by the normal assumption, and are often not symmetrically distributed [17, 39]. Additionally, Scott and Horvath [49] showed if the distribution of returns for a portfolio is asymmetric, or the investor’s utility is of higher-order than quadratic, then at the very least, the third and fourth moments of return must be considered. Especially, Samuelson [47] presented that higher moments are relevant for investors to make decisions in portfolio selection and almost all investors would prefer a portfolio with a larger third order moment if first and second moments are same. Therefore, several researchers have investigated portfolio selection problem by incorporating higher-order moments of return distributions into the analysis. In the presence of skewness, the portfolio selection problem has been widely investigated, see for example Adcok [2], Chunhachinda et al. [12], Harvey et al. [19], Kane [24], Lai [29], Liu et al. [35], Sun and Yan [52]. In addition to the first three moments, the return distribution’s fourth moment, namely, kurtosis, notwithstanding the disproportionate attention to the skewness in the literature, has recently received increased attention. Lai et al. [28] presented a polynomial goal programming (PGP) method to solve a mean-variance-skewness-kurtosis portfolio selection model. Yu et al. [57] proposed a portfolio rebalancing model including the transaction cost, skewness, and kurtosis, and then employed fuzzy multi-objective programming to transfer the proposed multi-objective model into a single-objective model. Beardsley et al. [4] extended classical MV model by including the higher return moments as well as the first four liquidity moments.
Besides the higher-order moments, the uncertainty associated with the returns of assets is also an important factor for constructing a reasonable portfolio. Traditionally, the returns of risky assets are regarded as random variables with probability distributions. As we know, a premise of applying probability theory is that the obtained probability distribution is close enough to the true frequency. In order to get it, we should have enough samples. However, in real financial markets, there are situations where people have none or no sufficient historical data. For example, newly listed securities have few historical data and in unexpected events such as a surprising announcement of interest rate cut by central bank, etc., there are no suitable historical data either. Thus, in such situations, the predictions of security returns have to rely on experts’ estimations rather than historical data. With the introduction of fuzzy set theory by Zadeh [59], more and more researchers have studied portfolio selection problem in fuzzy environments, e.g., Carlsson et al. [7], Chen [9], Chen et al. [10], Gupta et al. [18], Huang [21], Keskin et al. [27], Nguyen [41]. These researches broadened the way to handle portfolio selection problems with returns given by experts’ estimations. However, deeper researches find that paradoxes will appear when fuzzy variable is used to describe the security returns (Liu [30]). In order to better describe the subjective imprecise quantity, an uncertainty theory was founded by Liu [31] in 2007, and refined by Liu [32] in 2010. By using uncertainty theory no counterintuitive results occur. So far, uncertainty theory has been employed in many theoretical studies and applications. In the area of portfolio selection, Huang [22] introduced a risk curve and developed a mean-risk model for uncertain portfolio selection. After that, Huang [23] proposed a risk index model for uncertain portfolio selection. Later, Bhattacharyya et al. [6] proposed an uncertain multi-objective mean-entropy-skewness portfolio model. Recently, Chen et al. [8] proposed two diversified models for portfolio selection based on uncertain semivariance. Qin et al. [44] formulated an uncertain mean-semiabsolute deviation portfolio adjustment model with transaction costs. Ying et al. [56] presented three new portfolio selection models based on the cross-entropy of uncertain variables.
Nature-inspired metaheuristic algorithms have become very popular in the last two decades; this is due to their success in finding good solutions for complex problems in engineering and industry, especially the NP complete problems. Up to now, a number of meta-heuristic algorithms have been mentioned in literature, such as the genetic algorithm (GA) [20], particle swarm optimization (PSO) [26], artificial bee colony (ABC) [25], firefly algorithm (FA) [54], etc. Recently, a new metaheuristic algorithm called the flower pollination algorithm (FPA) was proposed by Yang [55] in 2012. It is inspired from flower pollination process of flowering plants. This algorithm is very simple in form. There are only two different operators in the algorithm, and only a few parameters need to be set. Therefore, this algorithm is easy to be implemented and does not need tedious parameter tuning. In addition, experiments carried out by Yang [55] demonstrate that the FPA is more efficient than the GA and PSO. A recent study by Chiroma et al. [11] showed that FPA algorithm for Neural Network (NN) training performs better than the GA, PSO and ABC, in terms of convergence speed, forecasting accuracy and robustness. As a result, the FPA has gained a growing interest and it has been used to solve a number of practical optimization problems such as sizing optimization [5], economic dispatch [1, 15], channel selection [45], feature selection [48], etc. To the best of authors’ knowledge, application of FPA for portfolio optimization problem has not yet been reported.
The purpose of this paper is to construct a novel uncertain portfolio selection model with higher-order moments based on uncertainty theory and to develop an efficient heuristic approach based on FPA algorithm for solution. The main contributions of this paper are as follows: (1) Regarding the security returns as zigzag uncertain variables, we formulate an uncertain multi-objective mean-variance-skewness-kurtosis portfolio optimization model, and then transform the proposed model into a single-objective model by using fuzzy programming method; (2) we develop a MFPA algorithm to solve the corresponding optimization problem, in which two improved strategies, namely as PSOLUS and DSPS, are employed to further enhance the local searching and global searching abilities of basic FPA.
The rest of the paper is organized as follows. In Section 2, we first review some concepts and theorems in uncertainty theory, and then introduce the concept of skewness and kurtosis for uncertain variable and present its mathematical properties. In Section 3, we present an uncertain multi-objective mean-variance-skewness-kurtosis portfolio selection model, and then employ fuzzy programming technique to transfer the proposed multi-objective model into a single-objective model. In Section 4, MFPA algorithm is developed to solve the proposed model. After that, an example is given to illustrate the effectiveness of the proposed model and algorithm in Section 5. Section 6 presents conclusions.
Preliminaries
Let Γ be a nonempty set, and ℒ a σ-algebra on Γ. A set function ℳ is called an uncertain measure if it satisfies the following axioms [31]:
Axiom 1: (Normality Axiom) ℳ {Γ} =1;
Axiom 2: (Duality Axiom) ℳ {Λ} +ℳ {Λ c } =1 for any Λ ∈ ℒ;
Axiom 3: (Subadditivity Axiom) For every sequence of {Λ
i
} ∈ ℒ, we have
In this case, the triplet (Γ, ℒ, ℳ) is called an uncertainty space. Further, Liu [33] defined a product uncertain measure by the fourth axiom:
Axiom 4: (Product Axiom) Let (Γ
k
, ℒ
k
, ℳ
k
) be uncertainty spaces for k = 1, 2, … Then the product uncertain measure ℳ is an uncertain measure satisfying
Similar to the random variable, the distribution of an uncertain variable ξ is defined by Φ (x) = M {ξ ≤ x} for any real number x. For example, the zigzag uncertain variable
If an uncertainty distribution has an inverse function, then the inverse function is called an inverse uncertainty distribution. In this case, the uncertainty distribution is called regular. Inverse uncertainty distributions play an important role in the operation of uncertain variables.
Now, we recall two important concepts: expected value and variance of an uncertain variable.
In the following, we will introduce concepts of skewness and kurtosis for uncertain variable and then prove some desirable properties.
Using the same way as above, it follows that
In this section, we first present an uncertain multi-objective mean-variance-skewness-kurtosis model for portfolio selection under the assumption that the security returns are zigzag uncertain variables. Then, different from Lai et al. [28], the proposed multi-objective optimization problem is transformed into a single-objective model by using fuzzy programming method.
Uncertain multi-objective portfolio model with higher moments
As mentioned before, we know that the asset returns tend to be symmetrically distributed. Thus higher-order moments should be considered in the portfolio selection problems. In general, investors prefer to maximize the odd portfolio moments and to minimize the even ones [43]. All the even moments measure dispersion (thus, volatility) which is undesirable due to increase in the uncertainty of returns. On the other hand, the odd moments express measures of asymmetry and it can be seen as a way to decrease the extreme values on the loss side and increase them on the gains. Assume that a rational investor would maximize expected return and skewness, while minimize investment and kurtosis, simultaneously. Thus, the multi-objective mean-variance-skewness-kurtosis model for portfolio selection can be formulated as follows:
In reality, it is found that sometimes the prediction of security returns has to rely on experts’ evaluations rather than historical data. Thus, it is better to use uncertain variables to describe the security returns. With the same consideration as Qin et al. [44], we also assume that the security returns are zigzag uncertain variables. In the following, an equivalent deterministic form of the above model (12) are given.
Then, by Equations (4), (5), (8) and (9), we have
Since r i are zigzag uncertain variables and x i are nonnegative real numbers for all i = 1, 2, …, n, by the operational law of uncertain variables, the total uncertain return is still a zigzag uncertain variable with the following form
Thus, by Equations (10) and (11), the uncertain expected return, variance, skewness and kurtosis of the portfolio can be, respectively, expressed by
where
By substituting Equations (19)–(22) into the model (12), the corresponding crisp form can be obtained. □
Multi-objective optimization generally involves balancing all conflicting objectives and searches for a set of compromise solutions between the objectives while satisfying the various constraints. In such context, this set of solutions is known as Pareto-optimal solutions. In recent years, many researchers have focused on multi-objective portfolio selection problems in different ways, see for example Beardsleyet al. [4], Gupta et al. [18], Lai et al. [28], Liu et al. [35], Yue and Wang [58].
In the above researches, fuzzy programming approach proposed by Zimmermann [60] is one of the widely used method. Additionally, to express investor’s aspiration levels, various types of membership functions have been proposed such as a linear membership function [36, 60], S-shape membership function [18] and so on. Among them, linear membership function is the most commonly used because it is simple and produces a computationally tractable function that closely reflects the real-world structure of the decision problem. Thus, in this paper, we use the fuzzy programming approach to transform the proposed multi-objective model (13) into a single-objective optimization problem, in which linear membership functions are employed to express investor’s aspiration levels for each objective.
Here, we summarized the steps of fuzzy programming approach for solving the proposed model (13) as follows.
• Membership function of the goal for expected return is given by
• Membership function of the goal for portfolio risk is given by
• Membership function of the goal for the skewness is given by
• Membership function of the goal for the kurtosis is given by
Notice that the transformed model (28) is a complex fractional programming problem. If using traditional optimization algorithms, it may fail for solution. In this case, it is necessary to employ an efficient heuristic algorithm to find the solution. In this paper, we propose a modified FPA algorithm to solve the model (28). In the following, the basic FPA algorithm is firstly reviewed, and then, the modified FPA algorithm is presented.
The basic FPA algorithm
Inspired by the pollination process of flowers, Yang [55] proposed the flower pollination algorithm (FPA) in 2012. The objective of this algorithm is the survival of the best and the optimal reproduction of plants, which is, in fact, an optimization process of plant species. The FPA is governed by the four basic rules bellow: Biotic and cross-pollination is considered as global pollination process with pollen-carrying pollinators performing Abiotic and self-pollination are considered as local pollination. Flower constancy can be considered as the reproduction probability which is proportional to the similarity of two flowers involved. The interaction or switching of local pollination and global pollination can be controlled by a switch probability p ∈ [0, 1], slightly biased towards local pollination.
Meanwhile, for simplicity, Yang assumes that each plant only has one flower, and each flower only produces one pollen gamete. Under this assumption, a pollen gamete, a flower, or a plant can be equated with a solution of a problem without any additional distinction.
In the global pollination step, flower pollen gametes are carried by pollinators such as insects, and pollen can travel over a long distance because insects can often fly and move over a much longer range. Therefore, Rules 1 and 3 can be represented mathematically as follows:
This distribution is valid for large steps s > 0.
For the local pollination, both Step 2 and Step 3 can be represented as
As stated in Rule 4 above, switching between local and global pollination is controlled by a probability p. To start with, one can use a naive value of p = 0.5. A preliminary parametric showed that p = 0.8 might work better for most applications.
Finally, the pseudo code of FPA algorithm is described in Algorithm 1.
1: Define objective function f (x), x = (x1, …, x d )
2: Set switch probability p ∈ [0, 1], the maximum number of iteration MaxGeneration
3: Initialize a population of SN flowers in random positions
4: Find the best solution g* in the initial population
5:
6:
7:
8: Draw a (d-dimensional) step vector L which obeys a Lévy distribution;
9: Do global pollination via Eq. (29);
10:
11: Draw ɛ from a uniform distribution in [0, 1];
12: Randomly choose x j and x k among all the solutions;
13: Do local pollination via Eq. (31);
14:
15: Evaluate the new solutions;
16: If new solutions are better, update them in the population;
17:
18: Update the current best solution g*;
19:
20: Output the best solution found
This section describe the key steps of the modified FPA algorithm for the optimization model (28). Especially, two new optimization strategies are employed, namely as PSO in local search (PSOLS), and dynamic switching probability strategy (DSPS), respectively.
Initialization
Population initialization is the first step of population based meta-heuristic algorithms not excepting the FPA. Meanwhile, it is a crucial task because it can affect the convergence speed and the quality of the final solution. In the basic FPA, the initial population is randomly generated. This method is widely used in almost all population based meta-heuristic algorithms due to its simplicity. For simplification, random initialization is also used in this paper.
Two new search strategies
In the basic FPA, Particle swarm optimization (PSO) was first introduced by Kennedy and Eberhart [26] in 1995. The basic idea behind PSO is to simulate a swarm of bees, fishes, or birds looking for food. In PSO, the potential solutions, named as particles, ‘fly’ through the multidimensional search space with a velocity, which is constantly updated by the particle’s own experience and the experience of the particle’s neighbors or the experience of the whole swarm. Accordingly, the velocity updating rule of each particle contains three terms: the previous velocity, the cognitive component, and the social component. The first term is considered to be the memory of the previous search direction; the second term, that is cognitive component, tries to tune the search direction toward the best position ever found by the particle itself; and the third term, that is social component, is used to change the search direction toward the global best position ever found by all the particles. However, in FPA, the local pollination operation is defined by Equation (31), which just includes the random search based on neighborhood without considering the best solution ever found by the pollinators itself. Therefore, inspired by the PSO exploitation mechanism, one modification introduced to the basic FPA is the PSOLUS, which takes advantage of the information of the personal best solution. This operation can be defined as follows:
Like many metaheuristic optimization methods, choosing appropriate parameters are an important task to achieve the best solution. In the FPA, local pollination corresponds to the exploitation phase whereas global pollination is for exploration phase. Switching between local and global pollination is controlled by a probability p, and it is a constant value. In the study by Yang [55], it is said that one can use p = 0.5 as an initial value and then does a parametric study to find the most appropriate parameter range. He stated that the best value has been found to be equal to 0.8 for most applications. However, for any generalized algorithm, we know that more global search should be done at the beginning as it will tend to explore the search space better and when enough exploration has been done, the process should move on to local search that is exploitation. Also, Draa [14] confirmed that fixing the switching parameter at the value 0.8 is not always a good choice. Thus, in this paper, dynamic switching probability strategy (DSPS) is used to makes the algorithm more reliable in exploring and exploiting the search space. More specifically, the sigmoid function is employed to dynamically adjust p, due to its wide applicability as an activation function in artificial neural networks. This function is a strictly monotone increasing function, that is, as the iterations increases, the switching probability p also increases. This shows that the global search is gradually replaced by the local search with the iterations increasing. The general equation for dynamic switch probability p used here is given by:
Finally, the pseudo code of MFPA algorithm is described as follows:
The main task of a constraint handling approach is to deal with infeasible solutions to drive the search efforts to feasible solution region while maintain the diversity of the overall population. According to the characteristics of different constraint handling methods, Mezura-Montes and Coello Coello [40] grouped them into five categories: (1) penalty functions; (2) special representations and operators; (3) repair algorithms; (4) separate objective and constraints; and (5) hybrid methods. Among those methods, the penalty function is the most popular approach due to its simplicity and ease of implementation. This method punishes the solution violating constraints by adding a penalty value to its fitness value, to direct infeasible individuals to move to feasible area. Despite the popularity of penalty functions, they have several drawbacks out of which the main one is that of having too many parameters to be adjusted and finding the right combination of the same may not be easy. This approach are highly problems-dependent [46].
1: Initialization
2:
3:
4:
5: Draw a (d-dimensional) step vector L which obeys a Lévy distribution;
6: Do global pollination via Eq. (29);
7:
8: Draw ɛ from a uniform distribution in [0, 1];
9: Randomly choose x j and x k among all the solutions;
10: Do local pollination by PSOLUS;
11:
12: Adjust switching probability p by DSPS;
13: Constraints handling;
14: If new solutions are better, update them in the population;
15:
16: Update the current best solution g*;
17:
18: Output the best solution found
In this study, Deb’s heuristic constrained-handling method [13] based on the penalty function approach, which does not require any penalty parameter, is incorporated into the proposed algorithm to deal with the constraints. This method works according to following rules. (1) When comparing two feasible solutions, the one with the best objective function is chosen. (2) When comparing a feasible and an infeasible solution, the feasible one is chosen. (3) When comparing two infeasible solutions, the one with the lowest sum of constraint violation is chosen. Furthermore, Deb [13] proposed the following fitness function, where infeasible solutions are compared based on only their constraint violation:
To illustrate our proposed effective means and approaches to the efficient portfolios discussed in this paper, we chose a portfolio selection example found in [44]. The algorithm was coded in Python and ran on a PC with 2.9 GHz processor and 4 GB RAM.
Experimental setup
In this example, the returns of ten securities were given by the expert’s evaluation and regarded as zigzag uncertain variables. The uncertainty distributions of ten security returns r i for i = 1, 2, …, 10 are given as shown in Table 1, as well as the other parameters of the model (28).
Portfolio parameters
Portfolio parameters
In addition, to evaluate the performance of the designed MFPA algorithm, we compare it with the basic FPA, PSO, GA and FA. In the following experiments, values of control parameters employed for MPFA, FPA, GA, and FA are shown in Table 2.
The main parameters’ setting of algorithms
We assume that the investors’ preferences on the mean, variance, skewness and kurtosis of the portfolio return are ω1, ω2, ω3 and ω4. That is, the preferences set is (ω1, ω2, ω3, ω4). In this paper, investors’ preferences of (1/2, 1/2, 0, 0), (1/3, 1/3, 1/3,0), (1/3, 1/3, 0, 1/3), (1/4, 1/4, 1/4, 1/4), (1/5, 1/5, 3/5, 0), (1/5, 1/5, 0, 3/5) and (3/8, 1/8, 3/8, 1/8) are considered. It is worth noting that preference set (1/2, 1/2, 0, 0) is a benchmark case, representing the Markowitz mean-variance portfolio, and preference set (1/4, 1/4, 1/4, 1/4) is a compromise case where the weights for mean, variance, skewness and kurtosis are equivalent.
For the proposed model (28), we use modified FPA algorithm to solve it. After running the designed algorithm with 100 generations, the investment strategies with different preferences are given in Table 3. We can see that, under different investment preferences, the obtained portfolio also satisfy the basic return-risk relationship, i.e., the higher the associated risk is, the higher the associated return. Moreover, the histograms for the optimal portfolio strategies under different levels of preferences are depicted in Fig. 1. The results presented in Table 3 and Fig. 1 clearly highlight that different investment preferences lead to different investment strategies. That’s to say, the investor can obtain his own investment strategies through setting appropriate preference weights. If he is not satisfied with any of these investment strategies, he could reallocate preference weights to the four objectives by solving model (28).
The optimal portfolios under different investment preferences
The optimal portfolios under different investment preferences
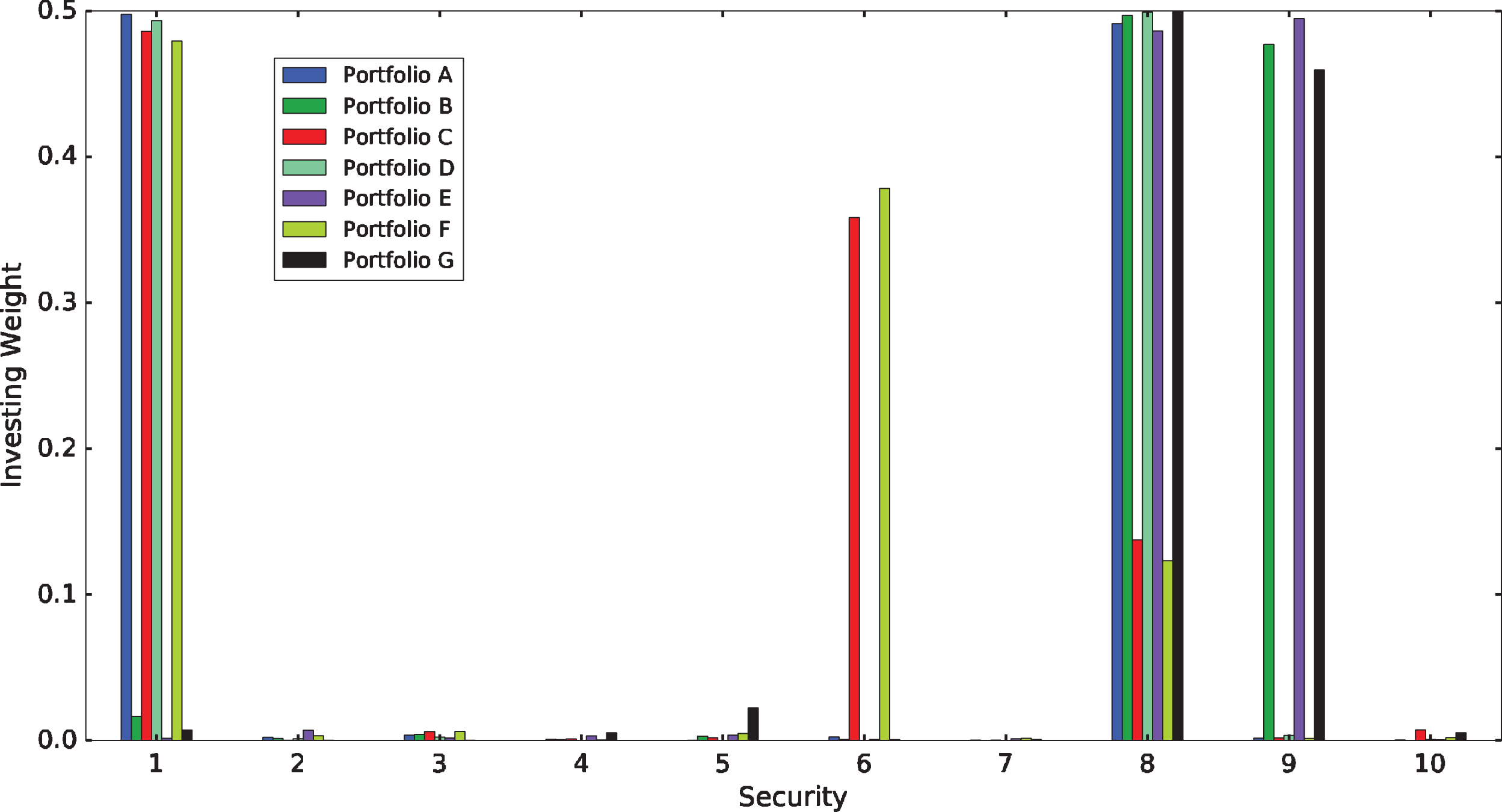
Comparative results about the investment strategies obtained by different preferences.
In addition, the four moment statistics of portfolio return are depicted in Fig. 2. It is found that the more importance investors’ preferences attach to a certain moment, i.e., the greater the preference parameter for this moment, the more favorable value of this moment statistic would be in the optimal portfolio. For example, for Portfolios A, B and C, the skewness in Portfolio B based on the (1/3, 1/3, 1/3, 0) preference structure is greater than that in Portfolios A and C based on the (1/2, 1/2, 0, 0) and (1/3, 1/3, 0, 1/3) preference structure respectively, while the kurtosis in Portfolio C is less than that in Portfolios A and B. It should be noted that, the expected return, variance, skewness and kurtosis are conflicting objectives in portfolio selection problem. That is, as a result of the trade-off between the four moments, at least one of the other three moment statistics deteriorates. Consequently, the improvement of portfolio skewness is not restricted by the simultaneous requirement of improvement of portfolio kurtosis. For instance, compared the results of Portfolio C based on the (1/3, 1/3, 0, 1/3) preference structure, we find that the skewness in Portfolio D based on the (1/4, 1/4, 1/4, 1/4) preference structure is more larger than that in Portfolio C, while the kurtosis in Portfolio D is not less than that in Portfolio C.
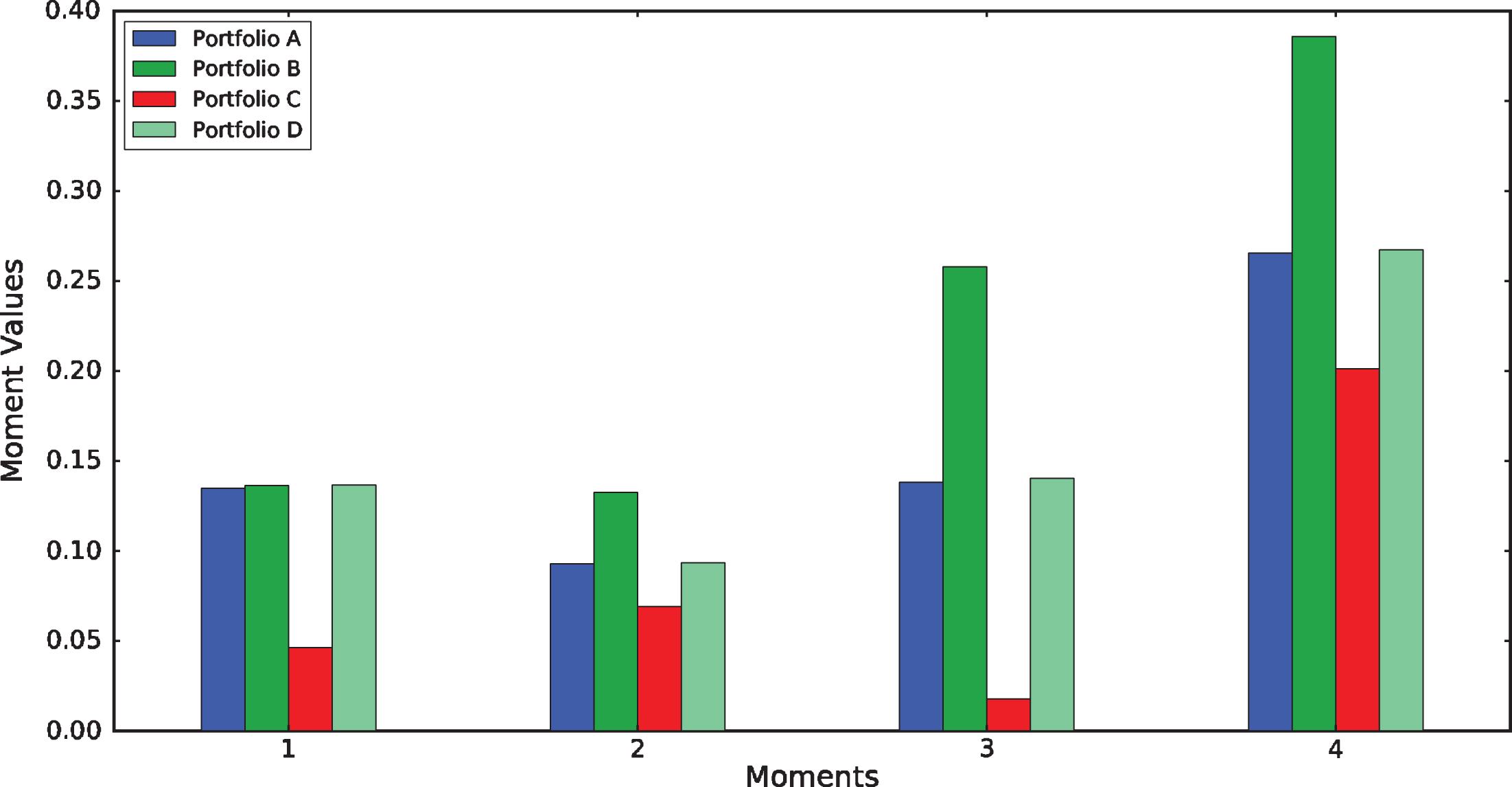
The comment values for different investor preferences.
Finally, to demonstrate the effectiveness of the MFPA, we compare it with basic FPA, PSO, GA and FA. The results are shown in Table 4 in terms of the maximum, minimum, mean, standard deviation (S.D.) and range values of the solutions obtained in the 100 independent runs by each algorithm. The best results are marked in bold. As is shown in Table 4, we can see that, the mean values obtained by the MFPA under three cases is larger than the ones obtained by other four algorithms. At the same time, we find that the standard deviation by the MFPA are better than those by other algorithms except the first case, i.e., ω1 = (1/4, 1/4, 1/4, 1/4). The lower values of standard deviations in MFPA indicate the fact that MFPA not only leads to more quality solutions but also it is more stable and reliable in finding quality solutions. Figure 3 shows the convergence characteristics of the MFPA, FPA, PSO and GA. It is obvious that the MFPA can converge fast and achieve a high accuracy than other algorithms. All these results show that the MFPA algorithm possesses superior performance in accuracy, convergence speed, stability and robustness, as compared to the other algorithms. Hence, the MFPA algorithm may be a good alternative to deal with portfolio optimization problems.
Performance comparisons with different preferences
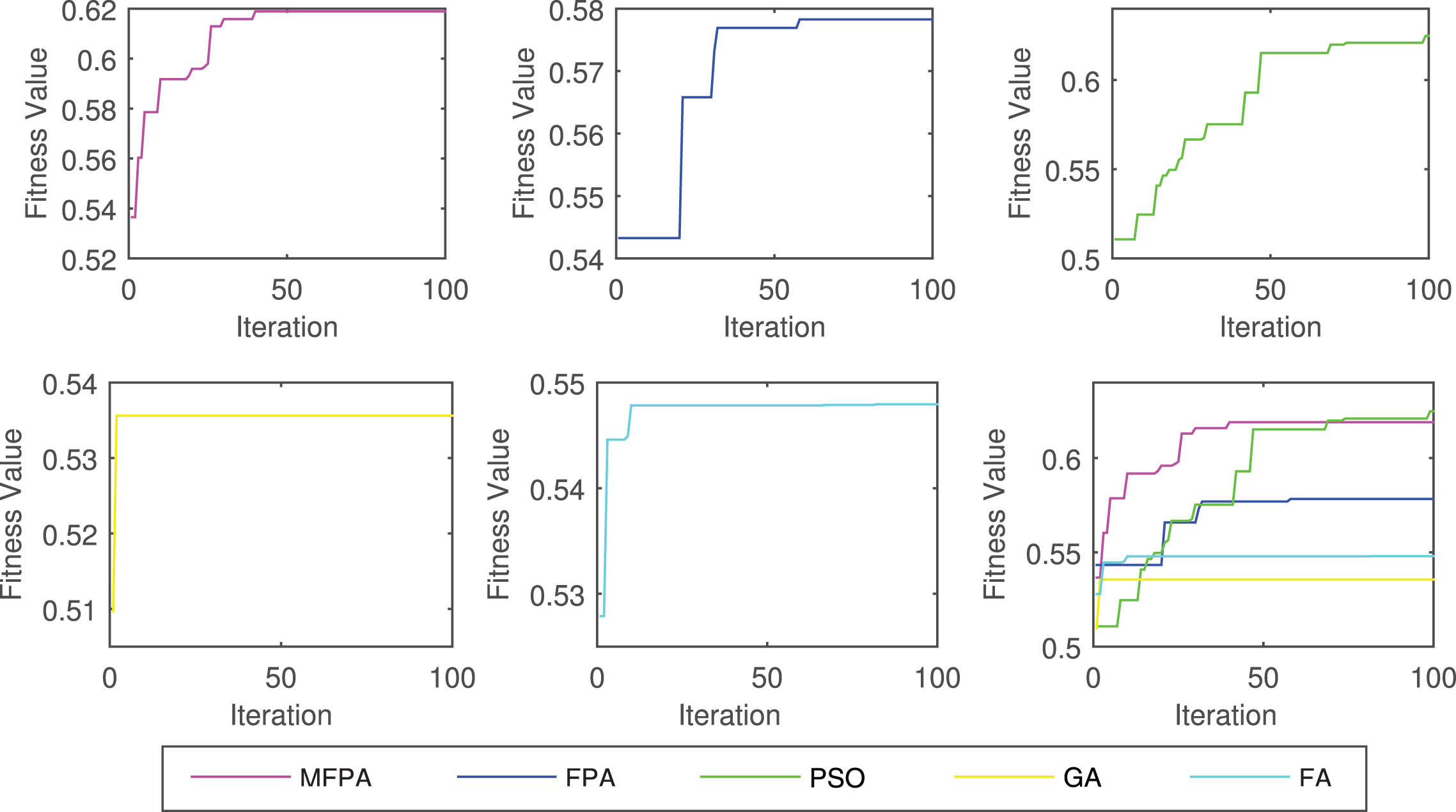
The convergence curves based on the (1/4, 1/4, 1/4, 1/4) preference structure.
In this paper, we have discussed an uncertain portfolio selection problem in which higher moments are considered and the returns of the securities by experts’ evaluations instead of historical data. Based on uncertainty theory and the assumption that the security returns are zigzag uncertain variables, we have proposed a new uncertain multi-objective mean-variance-skewness-kurtosis model for portfolio optimization problem and then transformed it into a single-objective model by using fuzzy programming approach, in which investor preferences over higher moments are incorporated. We have designed a MFPA algorithm for obtaining optimal solutions by employing two new strategies, named as PSOLUS and DSPS, respectively. Finally, we have presented a numerical example to illustrate the effectiveness of the proposed model and the corresponding algorithm. The experimental results demonstrate that the investors’ preferences not only affect the optimal investment strategy, but also affect the four moment statistics of return. In the mean time, the results also shows the proposed MFPA algorithm possesses superior performance in accuracy, convergence speed, stability and robustness, as compared to the other algorithms mentioned in this paper.
Finally, there are various issues that still deserve further study. First, one can extend the model by adding more constraints of real market such as transaction costs, cardinality constraint and minimum transaction lots. Second, granular computing is a novel computation theory to build an efficient computational model for complex applications with huge amounts of data, information and knowledge [3, 51]. Thus, another important extension is using granular computing techniques to solve uncertain portfolio optimization problems.
Footnotes
Acknowledgments
The author would like to thank the Editor and the anonymous reviewers for their valuable comments. The research of first author is supported by the Humanity and Social Science Youth foundation of Ministry of Education of China (No. 13YJC630012). The second author also acknowledges the support by Graduate Science and Technology Innovation Foundation from the Capital University of Economics and Business, Beijing, China. The third author acknowledges the support by the National Natural Science Foundation of China (No. 61540005).