
Abstract
In previous studies, due to the sparsity and chaos of distributed data, such a result would lead to a local convergence phenomenon by using PSO algorithm, resulting in low accuracy of data mining. So this time we proposed a data mining algorithm based on neural network and particle swarm optimization. At the beginning, we calculated the global kernel function of differentiated distributed data mining and mixed to build the mining decision model. The training error was used as the constraint condition of mining optimization to realized data optimization mining. The results showed that the differential distributed data mining with this algorithm has higher accuracy and stronger convergence.
Introduction
Today’s society is a rapidly developing era. Along with the continuous development of technology and information technology, a large amount of information and data has been generated. It is very necessary to analyze the information of big data [1]. Anyone needs to analyze the information he accepts. And then transform it into useful information, the application of the current social big data is becoming more and more important [2]. From such a trend, we are still at the primary stage, but as technology becomes more and more mature, we need to work hard to analyze and research big data online, extract useful information, and use them [3].
The essential source of particle swarm optimization algorithm is from the way of group movement of natural birds and fish groups. This algorithm is simply to simulate the group predation behavior of birds. Through the observation of bird groups, we can know that when a group of birds preys, when a bird finds food, it can transmit information to the group of birds, and let them find the nearest way [4]. It is an optimal search algorithm, which can be obtained from the large amount of information of the large data of the network to the information that is favorable to the target. When we get a group of initial random particles, then we find the optimal solution by iteration, and we choose the best way in every iteration. In this way, we can play a role in the era of network big data [5].
State of the art
In the traditional particle swarm optimization algorithm in data mining, due to the sparsity and chaos of differentiated distributed data, resulting in data mining using particle swarm algorithm is easy to fall into local convergence, data mining accuracy is not good [6]. Aiming at the above problems, the training error as constraints mining using particle swarm optimization, the generalization ability of learning clustering data mining center calculation, overcome the initial clustering center is sensitive and easy to fall into the local optima, combined with neural network classifier attribute clustering data mining after the implementation of mining algorithm [7].
Neural network is initially established by simulating the human brain’s nervous system, so it is destined to be made up of simple information processing units, also known as neuron structure. [8]. The interconnection of these neurons is combined into a model of the information processing algorithm we need. Because the basic processing unit is the structure of neurons, we must pay attention to improving the performance of neurons before you, so that we can help our research [9]. The construction of neurons is very important, so we have improved the algorithm on the basis of the original. This algorithm is simply by simulating the group predation behavior of a bird group [10]. During group predation, when a bird finds food, it can transmit information to the group of birds, so that they can find the nearest way to the target.
Methodology
Model construction of particle swarm optimization algorithm
In this study, we use the particle swarm optimization algorithm, we need to build on this model, so this process is the main operation of the network data based on particle swarm optimization algorithm to find an optimal results. Because particle swarm optimization (PSO) is built on the biological habits of nature, which is an evolutionary computation technology invented by Dr. Eberhart as a new way of learning in the field of evolutionary computing. As an individual’s way of collaboration, we come to search among individuals to find the most favorable information. Because all members of a biological group are searching for food, because the distribution of food is unpredictable, so a good way to choose information is needed. This is also the biggest feature of particle swarm optimization. We need to build a mathematical model of the algorithm. We can describe it in the following mathematical ways.
We assume that in a search space for a food with a dimension of D, we use M to represent the population of particles that are potential problems.
We need to choose the set we face algorithm pattern to be selected to represent information sets by s, we need to pick out from the inside with your goal then we will use x value into a calculation of a problem associated with the objective function of the adaptive value. These records are numeric, so we do the best selection of the data under the constraints of these formulas. Mark them up, and then search for a selection of the optimal value. Then we use the PSO algorithm to use the following companies to perform the following operations on the selected particles. The way to select the process is as follows:
In the upper form, the i = 1,2,3 … M is used as the particle labeling. K is a generation number of iteration. C1 and C2 are two constant values. We generally value it as 2. R1 and R2 are the random numbers distributed between 0 and 1. So in order to control the value of
The styles defined in the PublisherDoubleColumnJournal.dot file
Through the acquisition of external information for internal analysis and research, the final conclusion is reached. We improved the algorithm based on the previous algorithm, and improved the particle’s previous formula. We can find information that matches the target more quickly by improving our algorithm. The particle will be kept on the original basis for the selection of the data. This greatly speeds up the agility and speed of our algorithms. It is the most convenient way to use the search algorithm in all kinds of problems, especially the processing of our optimization problem.
Since we need to establish an algorithm evaluation model, we have to classify these sub-indices by membership functions, and we need to transform them through the following functions.
First, we need to calculate the average value of the sub index: the calculation function is shown as follows
Then we calculate the variables of different types of indicators respectively: first, the economic indicators of the benefit of the limit.
Then we need to return the results of index revised:
On the Z
j
is in the function index J through the data will be unified data processing we need to design a genetic algorithm, learning algorithm, so we need a genetic algorithm out of the results of the test error, our error calculation formula is as follows:
In the upper form, represents the expected output value of the network, and represents the actual output value of the network, where e is the error value through the expected output and the actual output. The distribution of the three in the model is shown in Fig. 1.
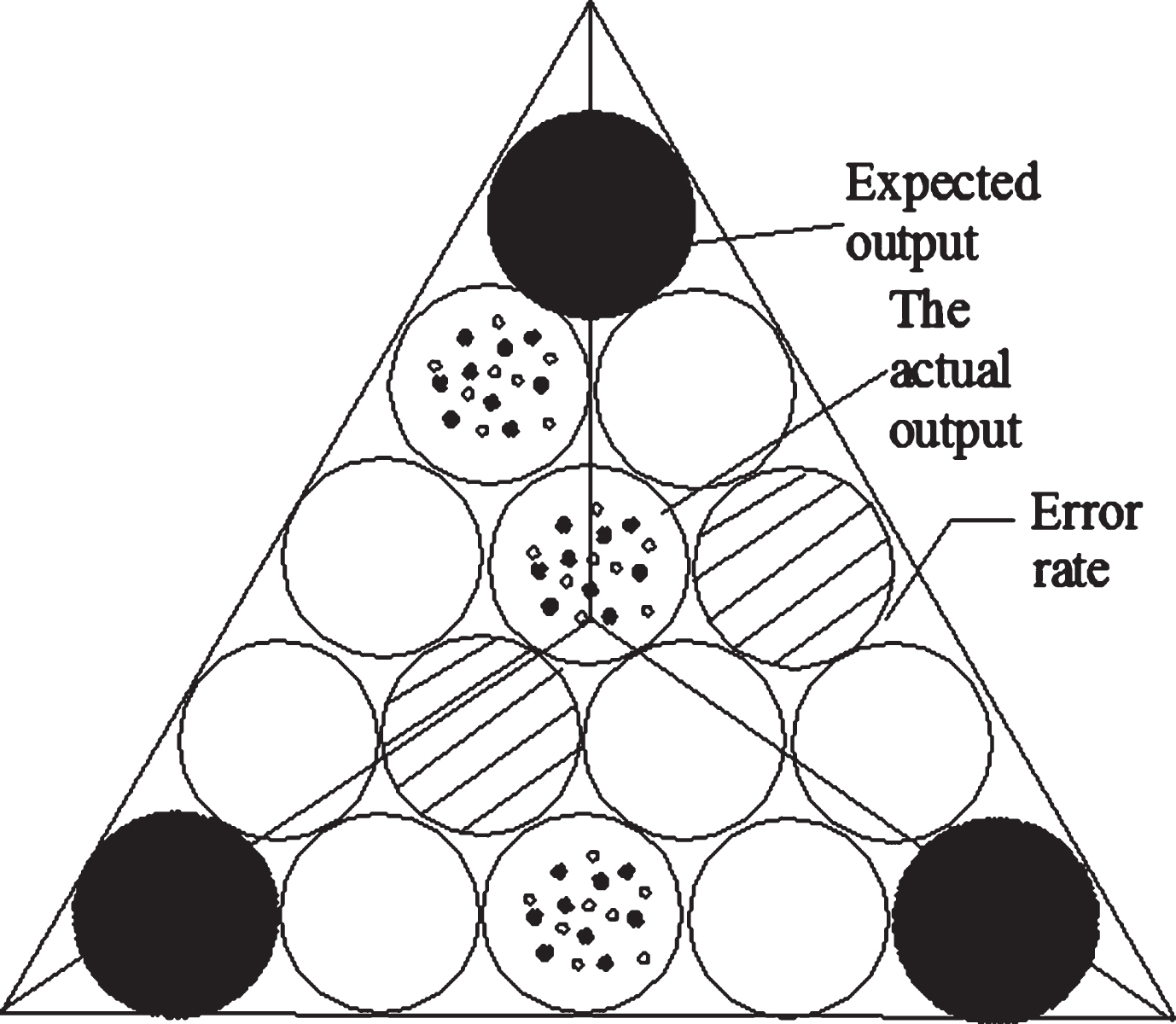
The actual output value of the expected output value network of the network is expected to be output and the error value of the actual output.
Because each genetic algorithm needs to be repeated calculations, a more accurate algorithm evaluation model is finally obtained. One of the main functions of neural network is self-learning function, neural network, that is, the learning process of error back propagation error back propagation algorithm, which consists of two processes, namely, the positive propagation of information and the backward propagation of errors. The input layer neurons responsible for receiving the input information from the outside world, and transfer to the middle layer neurons; the middle layer is the layer responsible for internal information processing, information transform, according to the information demand, the middle layer can be designed as a single hidden layer or multi hidden layer structure; the last hidden layer to the output layer neurons transfer the information is further processed after the completion of a forward propagation process of learning, from the output layer to the external output information processing. When the actual output does not match the desired output, it enters the back propagation phase of the error. The error is corrected by the output layer and the weight value of each layer is corrected according to the gradient of the error gradient, and the hidden layer and the input layer are retransmitted layer by layer.
Through the information forward and back propagation process again and again, is a process of constantly adjust the weights, and the neural network training process, this process has been carried out to reduce the error of the network output to an acceptable level, or set membership function on the definition of the X of the three different other the classification of data values, incremental decision current w, for these benchmark functions and we are through a large number of data obtained a best fit value. We take into account the efficiency and search accuracy of the search. As the most effective search method, we will adaptively adjust a global search method. On the basis of this, we have evolved an evolutionary function of our current algorithm through the idea of genetic algorithms. We combine the selection mechanism with the PSO algorithm, and we can compile the iterative algorithm for the survival of the fittest. The selection mechanism of the hybrid PSO algorithm and the other evolutionary optimization algorithms are most suitable for each individual’s current location. The probability of the hybridization given by the particle in the particle swarm is determined by the user of our algorithm. We select the specified number of particles according to the probability of crossing into a natural hybridization environment. The preferred result is shown in Fig. 2.
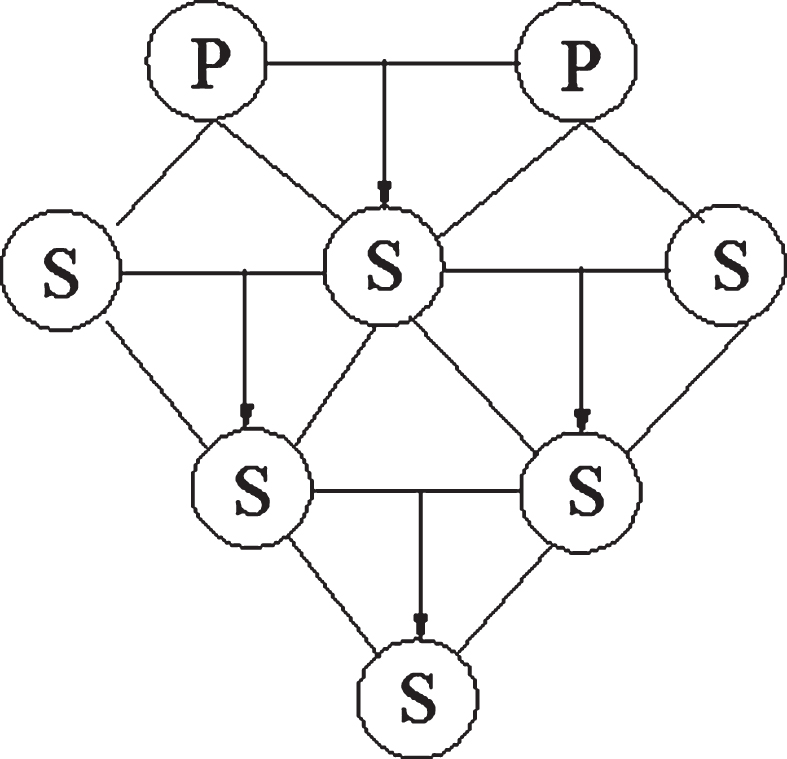
The hybridization probability given by particles in a particle swarm.
We will be the same number of particles between the populations unchanged, we can add the algorithm, the calculation formula is as follows:
X is used as the location vector of D, where child and parent are selected as the parent offspring in the natural data exchange location. The components of the crossover probability are all between 0 and 1. Big data brings us three subversive ideas: all data, not random sampling; general direction rather than precise guidance; correlation, rather than causality. Is not a random sample, but all the data in the era of big data, we can analyze more data, sometimes even can handle all of the data and a special phenomenon, rather than relying on random sampling (random sampling, we usually take it as granted, the times of learning so far.
Based on particle swarm optimization algorithm, we need to detect algorithm after analyzing the algorithm of network big data analysis, in order to verify the feasibility of the algorithm. We will use the model of particle swarm optimization algorithm, aiming at the network data environment for optimal selection, as the era of big data is mixed, because there are a lot of data is created in people’s daily life and production activities, including a lot of useless information. We need to find the information we need in these complicated information, so that we can achieve our value in the current era. We use the Rosenbrock function test method, Rosenbrock is a function of a single peak value, and the variables between us have a strong integrity. Its overall situation is distributed in a very small area, and it is distributed between 0 and 1. On this basis, the Griewark function is used as a function of multiple peaks that influence each other, and their locality is also at some minimal points. The calculation records are shown in Table 2.
Uses the research pattern of particle swarm optimization algorithm to select the optimal solution under the current network data environment
Uses the research pattern of particle swarm optimization algorithm to select the optimal solution under the current network data environment
From the above table, we can see that the crossover rate of our SGA is p = 0.2, and the optimal solution of group n = 30 is much better than the previous algorithm after many times of operation. So the algorithm of our study is of great superiority. The result is that the SPSO optimization result is better than the SGA.
The method of SPSO and CPSO is used to calculate the parameters. As the comparison of the SGA method, the selection of the control parameters and the test of the standard function are the same. So in order to avoid the contingency of the test, the method of cross validation is used for the estimation and the test of the result. Then we test 60 of the samples we have encountered. We have 30 run tests on each group of data as shown in Table 3.
The running record table of multiple data calculation of group data
From the previous table, we can see that the algorithm model has great stability and convenience when it is inputting large data. This time, we based on particle swarm optimization algorithm of network data analysis than before the algorithm model of computing power has great improvement, this is not only show a more efficient way in our data operation, but also in the practical application, the design scheme of a new type of algorithm through the calculated it is more accurate and practical, has carried on the simulation experiment, the experimental results are shown in Fig 3.
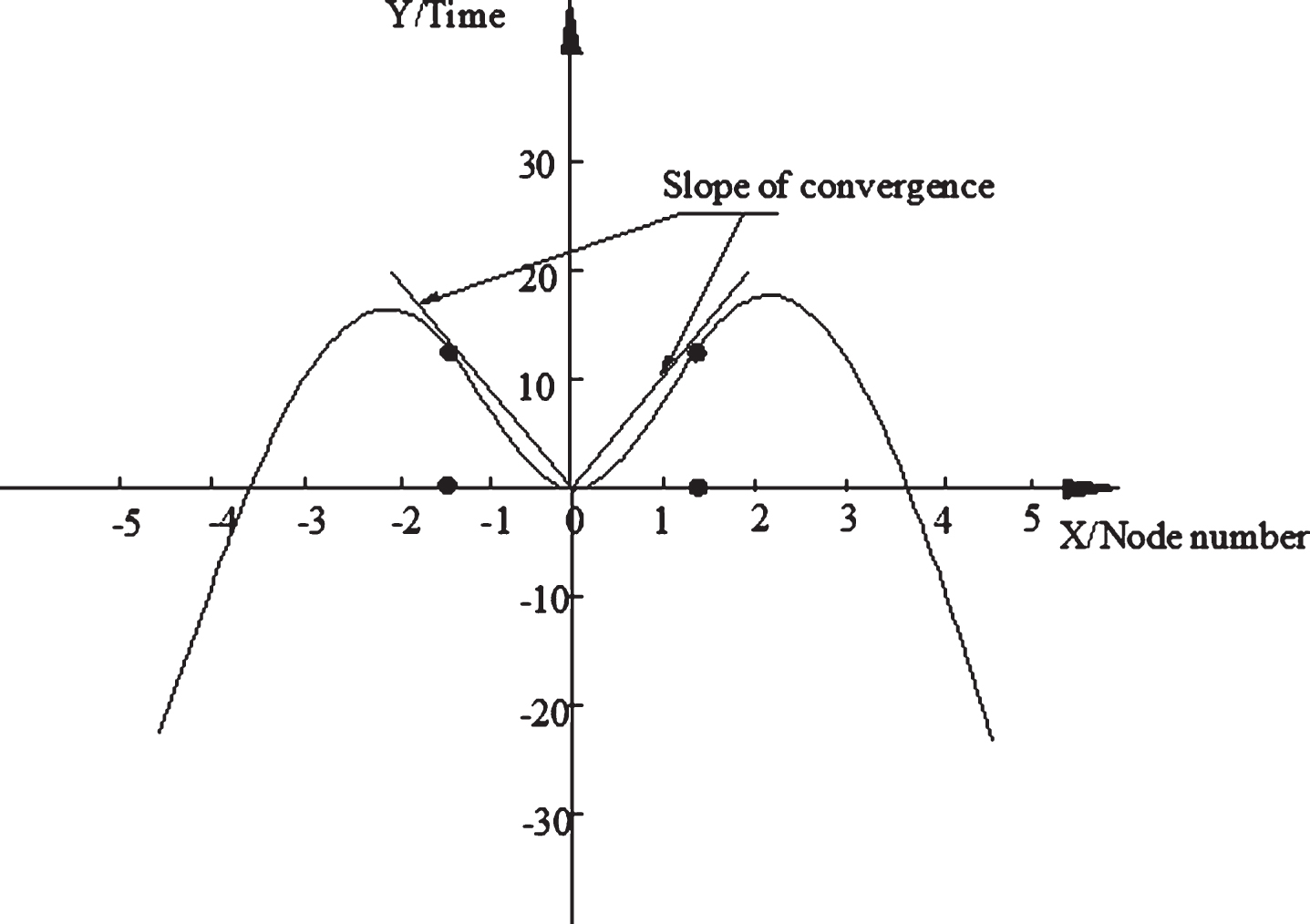
Network large data analysis based on particle swarm optimization algorithm.
From the above results, this paper adopts the algorithm of data mining; the minimum number of iterations to converge to the optimal value, and then converge to the global optimal clustering center makes data mining through multiple iterations in the energy value of 4. 4456656670e+05, after the search, the convergence of the clustering center of data mining of the global optimum value to achieve better a value of 4. 2434556777e+05 before using neural network and particle swarm optimization based method can effectively overcome the initial cluster center is sensitive and easy to fall into the local optimum problem, the data mining search has been in a stable stage, showing the convergence ability of the. It can perfect the optimization of data mining algorithm and turn our algorithm into a general algorithm.
In previous studies, because of the sparsity and chaos of distributed data, such a result would lead to a local convergence phenomenon by using PSO algorithm, resulting in low accuracy of data mining. So this time we proposed a data mining algorithm based on neural network and particle swarm optimization. At the beginning, we calculated the global kernel function of differentiated distributed data mining and mixed to build the mining decision model. The training error is used as the constraint condition of mining optimization to realize data optimization mining. In this study, we use the particle swarm optimization algorithm, we need to build on this model, so this process is the main operation of the network data based on particle swarm optimization algorithm to find an optimal results. It’s the algorithm flow that simulates the predation of group animals, because now we find information resources that match our goals from the vast network information data. Through the acquisition of external information for internal analysis and research, the final conclusion is reached. We have improved the previous algorithm base to improve the velocity of the previous formula of the particle.
Footnotes
Acknowledgment
The study was supported by National Natural Science Foundation of China. Concurrent scheduling and cost optimization for multiple workflows in hybrid cloud computing environment (61363004).