
Abstract
Decision-making is very important activities in the various applications of science, engineering, and technology. A decision can be derived in three manners by these applications: (1) by developing a mathematical model, (2) taking domain experts advice, (3) developing an expert system. However, accurate mathematical model may not be developed for the domain that might not be completely interpreted. Moreover, the problem with the second method is that the human intervention is not possible all the time and the expenditure of hiring a domain expert may be high. Decision-making, using expert system or controller induces great interest among the researchers and professionals. Expert systems or controllers are capable enough to counter unpredictability, noise, and vagueness. Fuzzy set theory is commonly used in building the expert systems and controllers due to its ease and similarity to human reasoning. Therefore, the proposed approach is based on fuzzy logic for decision making. The proposed model is explained through a case study. The result of the proposed work is compared and judged by the results of earlier studies. The result depicts that the proposed method has a better performance and effectiveness than existing studies.
Introduction
Decision-making using expert system or controller induces great interest among the researchers and professionals since last three decades [6]. In the past, many theories have been developed to deal with uncertainty, noise and vagueness such as fuzzy set theory [22, 25–31], probability theory, D-S theory [19]. Fuzzy set theory is commonly used in building the expert systems and controllers. Therefore, fuzzy logic based decision making has become an interesting fact-finding field among scientists and researchers. However, there are two general limitations such as: 1) fuzzy systems are case-dependent; 2) contribution of domain experts is of significant importance in building of fuzzy logiccontrollers.
A fuzzy logic controller is a knowledge-based control arrangement. It includes scaling functions of physical variables, used to subsist with doubt in process dynamics or the control environment [8]. To depict data into linguistic variable terms and numeric data, membership functions are utilized. The linguistic variables are generally explained as fuzzy sets with the appropriate membership functions. The defining of fuzzy profile is one of the beginning steps in the formulation of a problem,which will be solved by fuzzy set theory. Creating an effective membership function is always a typical task. Reason being, there are no specific instructions or directions defined in the literature. Either a domain experts knowledge or the help of real data is sought to create membership functions. However, how an individual perceives the very meaning of the concept is dependent on the individual. Hence, a variety of membership functions could be created for the same concept [5]. Developing an effective membership function and fuzzy rule set has always been a challenging task among the researchers. This is due to the success ratio is directly proportional to the above said two factors. In the literature, lot of research has been reported either using help of a domain expert or without developing effective membership function. Therefore, a new fuzzy logic-based method has been proposed for decision-making.
The paper is comprised as: Section 2 comprises related work. Section 3 comprises method explanation. Section 4 comprised case studies. At the last, Section 5 is comprised of conclusion.
Related work
In controller building, the development of membership function and the fuzzy rule base are highly essential since the success of a controller is completely dependent on the membership functions and fuzzy rule base used. For that reason, the explanation that how these two are acquired is a requisite. The present-day literature is brimming with the methods of membership function generation based on Nature inspired algorithms (like GA, PSO, etc.), histograms, neural networks, clustering [4, 16]. The predefined shape of membership functions is used in heuristic method [10]. Histograms of attribute give data about the delivery of input attribute values. Using histogram depictions, it becomes easy and quite suitable for generating membership function [13]. Dombi et al. identified few ordinary characteristics among the following distinct approaches [4]: Every membership function is enless. All membership functions matches an interval [a, b] to [0, 1]. Membership functions are either continuously ascending or continuously descending or both ascending and descending.
The generation of if-then rule from the numeric data has been put forward by numerous research articles [1–3, 21]. The fact that the membership function still needs to be predefined is a major disadvantage of a majority of the model. A procedure is proposed for evolution of fuzzy profile with the help of fuzzy clustering technique and decision tables [7]. They have predefined the initial fuzzy profile of the input training data and updated by a series of merge operations. Nevertheless, the decision table will grow enormously and the decision tables start to get more complex as the number of variable increases. A novel approach is discussed for fuzzy profile creation using α cuts [14]. The algorithms become more complicated for larger number of input variable having an enormous amount of values. Mitra et al. developed a new approach for continuous attributes [14]. Fuzzy profiles are mapped as membership functions and can be presented graphically. In the literature, distinct type of numerous membership functions are present. Domain experts prefer the triangular and trapezoidal shapes to present the knowledge and computations of the process [22, 24–26]. Hence, these two shapes are considered in the presented approach in order to minimize the programming and mathematical complications. Over time, various authors have created various classification models in the decision making [11, 18]. However, if you compare the decision tree models with the traditional decision tree models, it seems that the latter is robust and involves lesser quantities of computational attempts. The causes for the inclusion of decision tree in the proposed approach are as follows: Decision trees are significantly vital, easily understandable and robust methods of decision-making. The method is simple and handy for a huge amount of data. Hence, it is likely appropriate to comprehend with humane perceptions. It takes fewer time to compute, providing quick outcomes.
Therefore, based on the various observations of literature survey, a new method is proposed for developing fuzzy profiles and fuzzy rules for decision making.
Proposed methodology
The model architecture shown in Fig. 1. Model comprises of four main phases. Evolution of Fuzzy Profile Construction of decision tree Extract rules Decision making
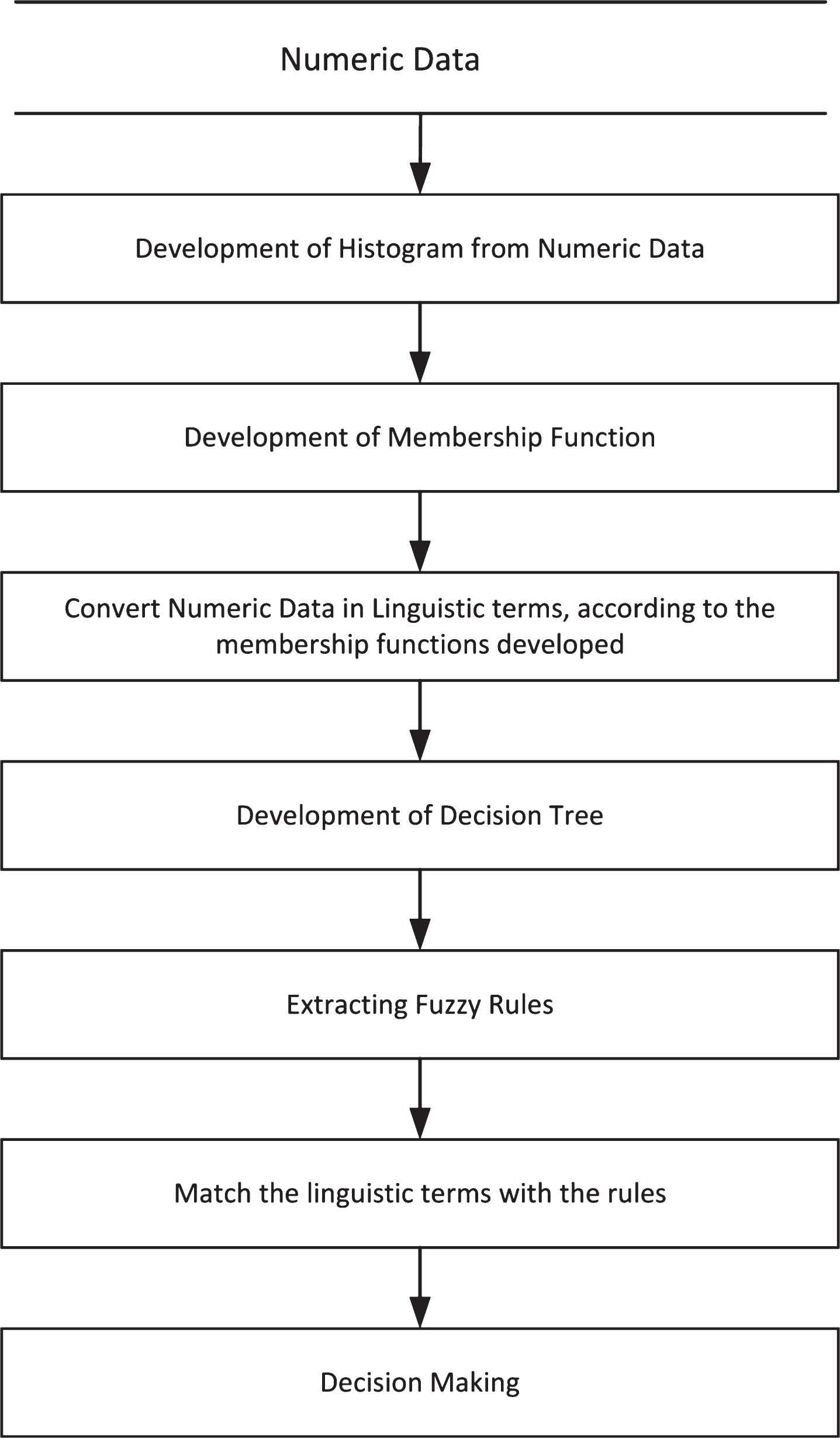
Steps of proposed model.
The methods for the development of the fuzzy profile of numeric data are as follows: Find out the distinct values of each attribute. Obtain the frequency of every distinct value of each attribute. Draw histogram of each attribute. Select the major possibility for each attribute and draw the histogram. Smoothing the histogram. Based on frequency, categories the major possibility of attribute into k cluster. Decide the shape of membership functions.
Construction of decision tree
The root node of the decision tree is known to be the primary classification factor for the assessment of a particular class label. Subsequent deciding attributes will become the branches of the tree. A fuzzy decision tree algorithm that handles fuzzy input sets is taken from [23] to generate decision tree.
Decision making using extracted fuzzy rules
Fuzzy categorization rules are extracted from the decision tree for decision making.
Case study
To validate the suitability and applicability of the model, it is applied to KC2 data set [18]. This project written in C++ platform and contains the ground emissions data for processing. Further, this dataset contains 522 modules [18]. KC2 dataset consists of 21 software metrics. From literature, it can be noticed that only thirteen matrices used for measuring the defects out of twenty-one matrices [18]. Seliya et al., provided a brief explanation of the metrices that are presented in Table 1 [18].
Software metrics
Software metrics
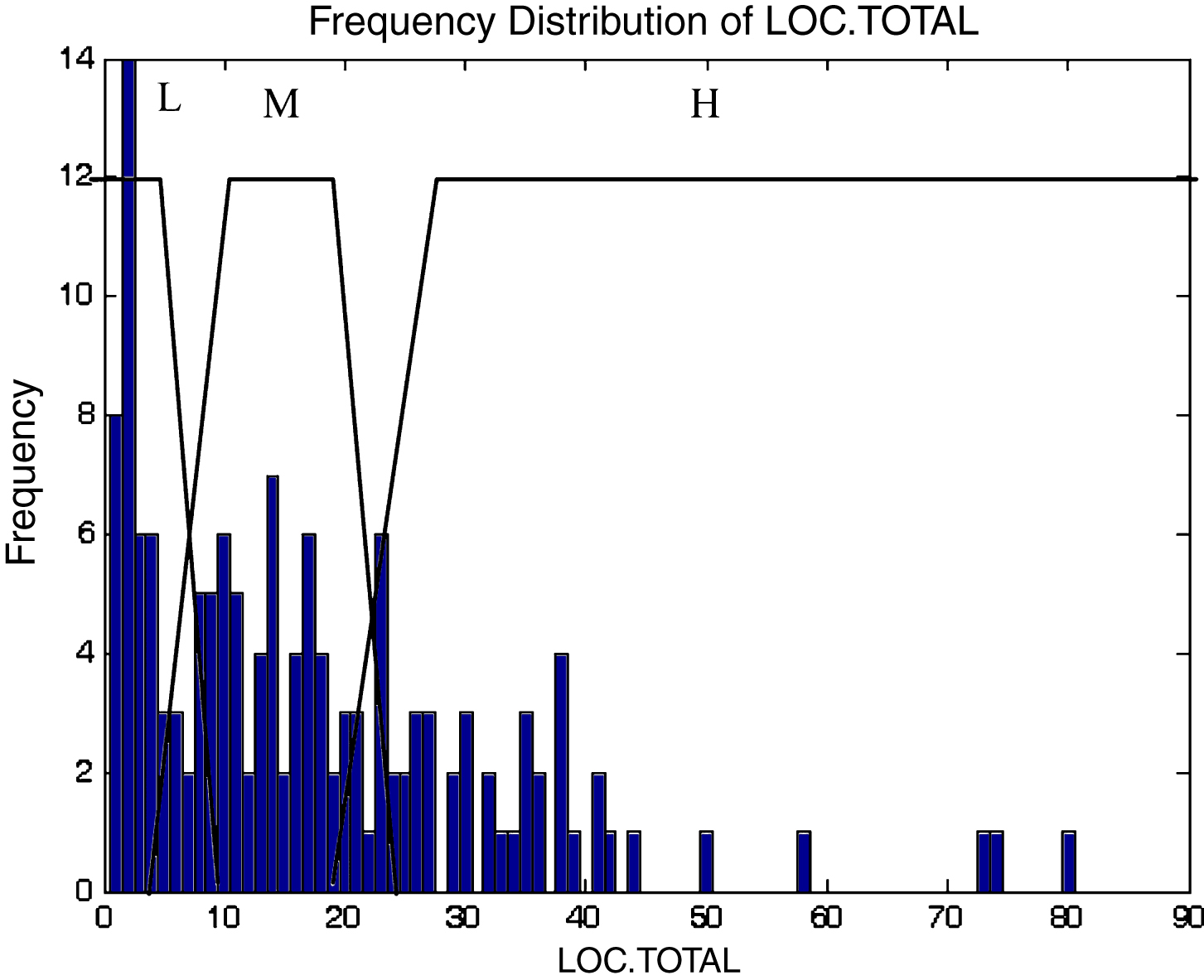
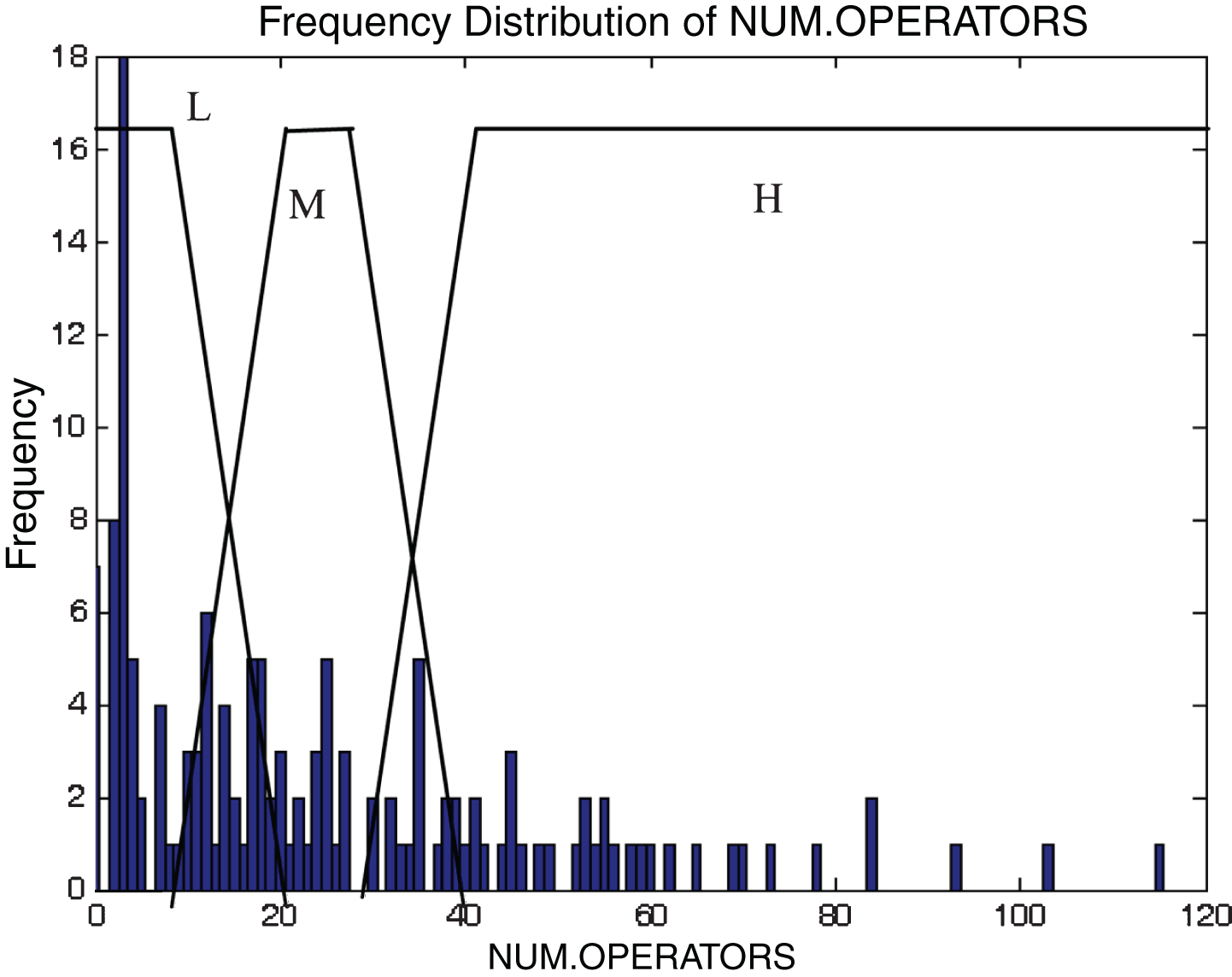
This subsection describes the different membership functions developed for the proposed model. In this work, thirteen membership functions are generated for thirteen attributes of the KC2 dataset [17]. The analyses of these membership functions are done using histograms. Figures 2–14 illustrate the membership functions analysis using histogram method.
LOC blank.
LOC code and comment.
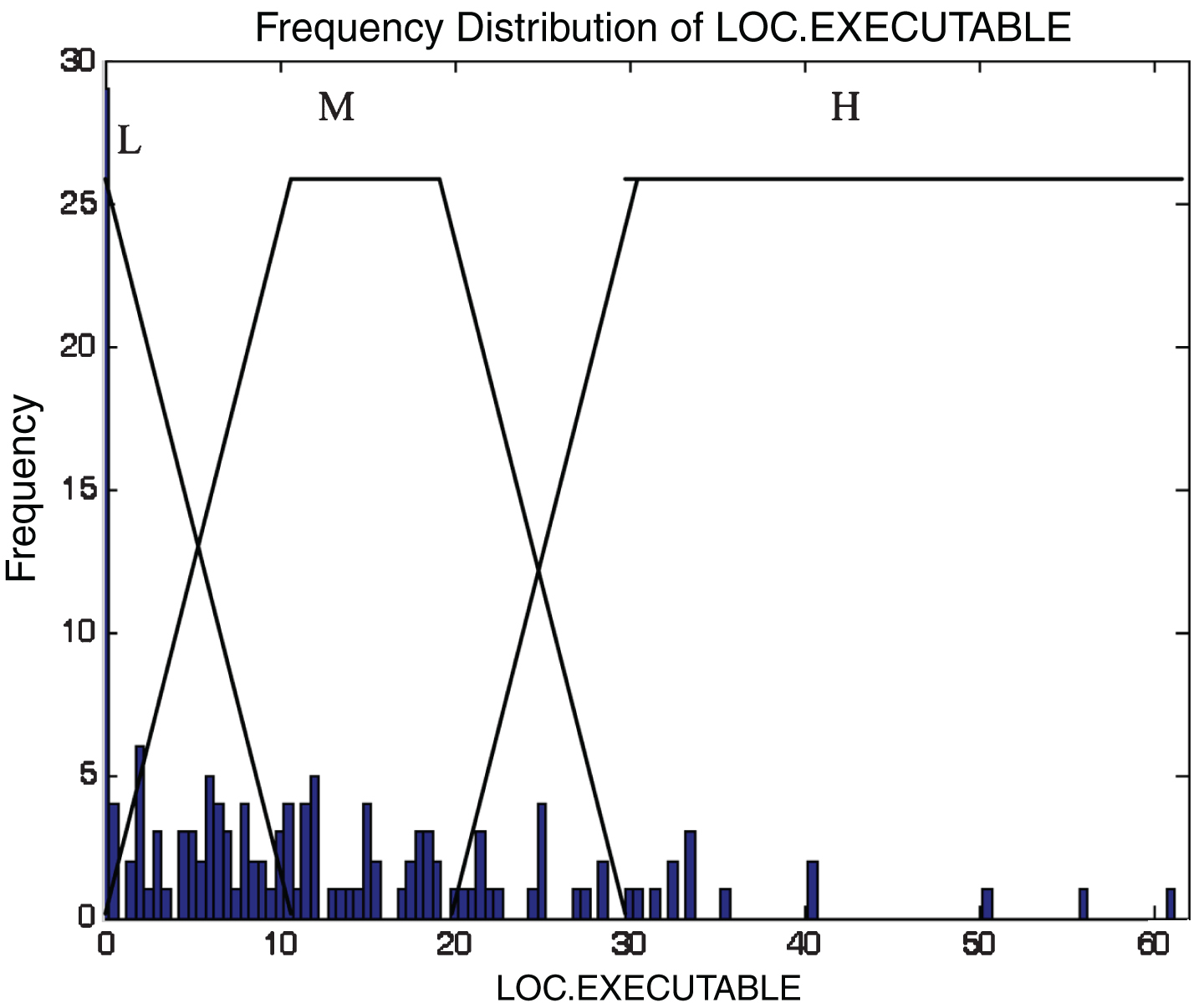
LOC executable.
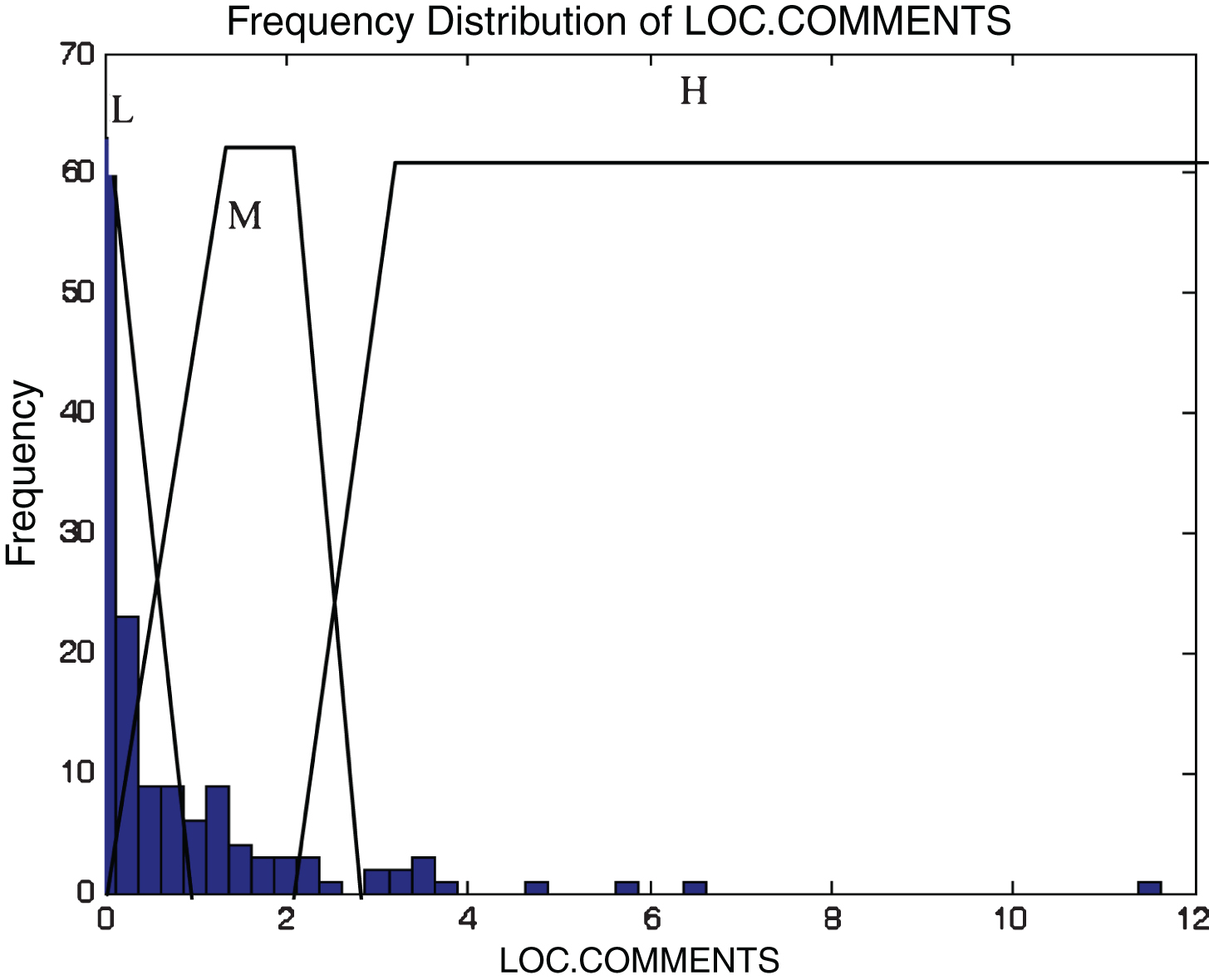
LOC comments.
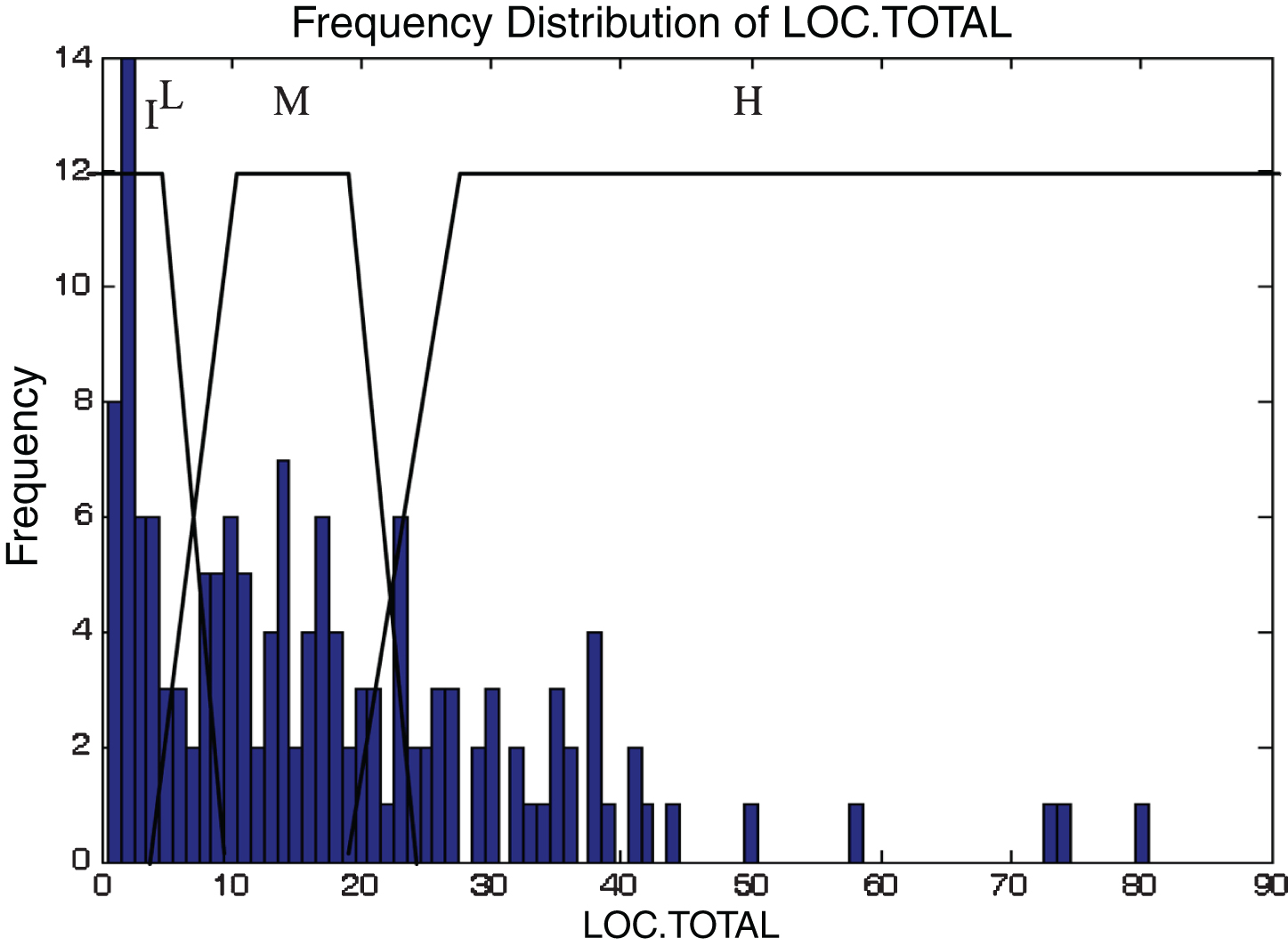
LOC total.
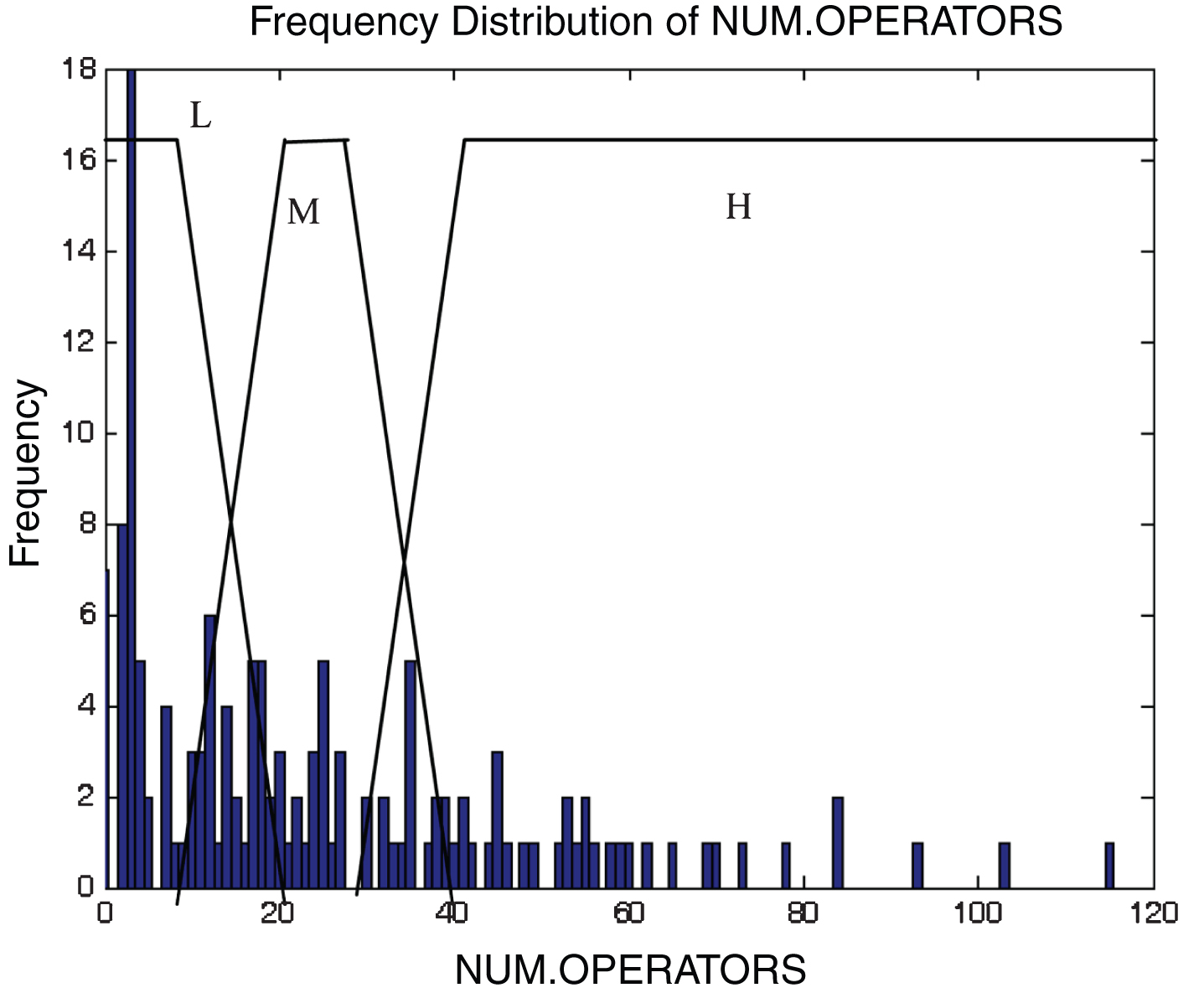
Total operators.
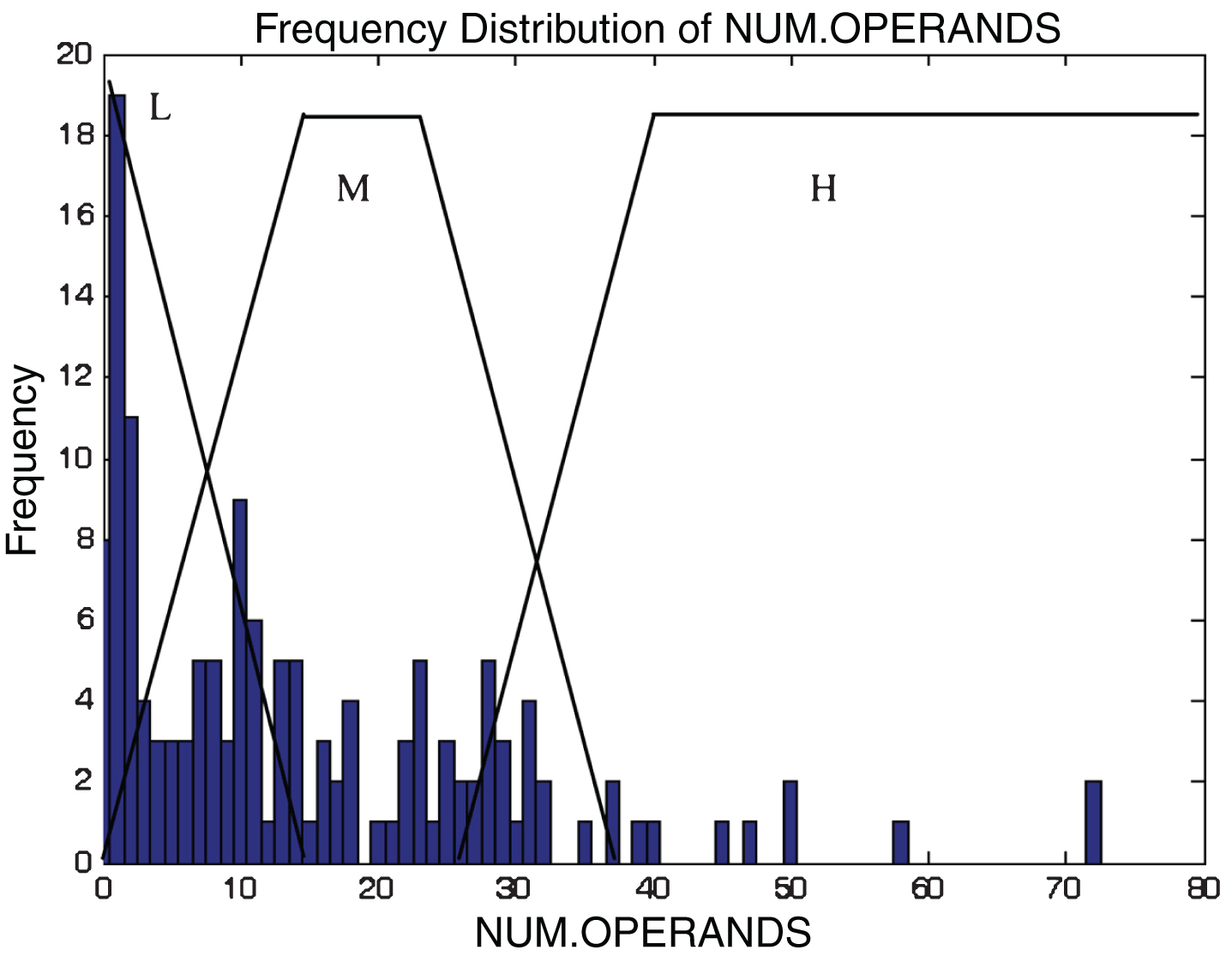
Total operands.
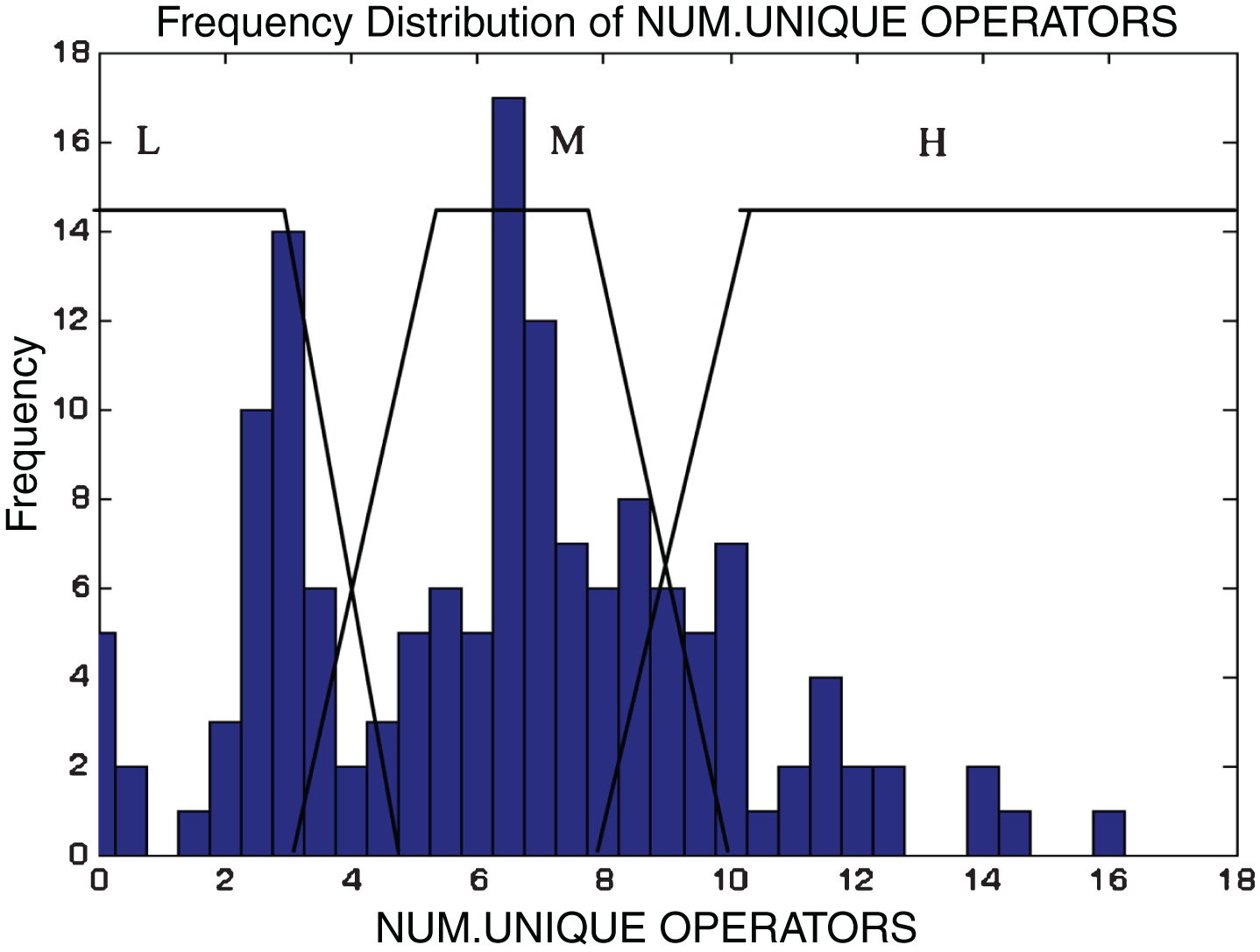
Unique operators.
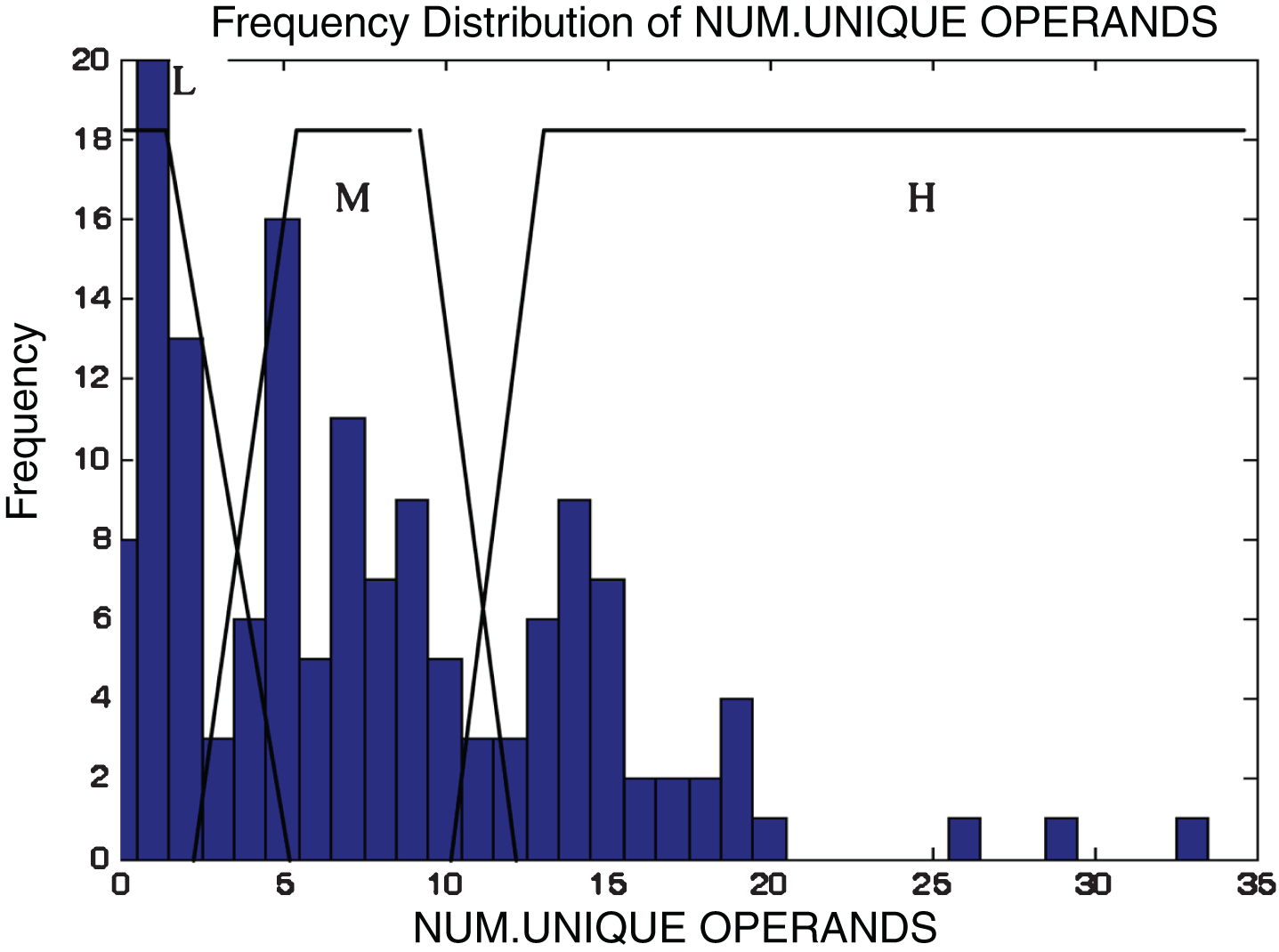
Unique operands.
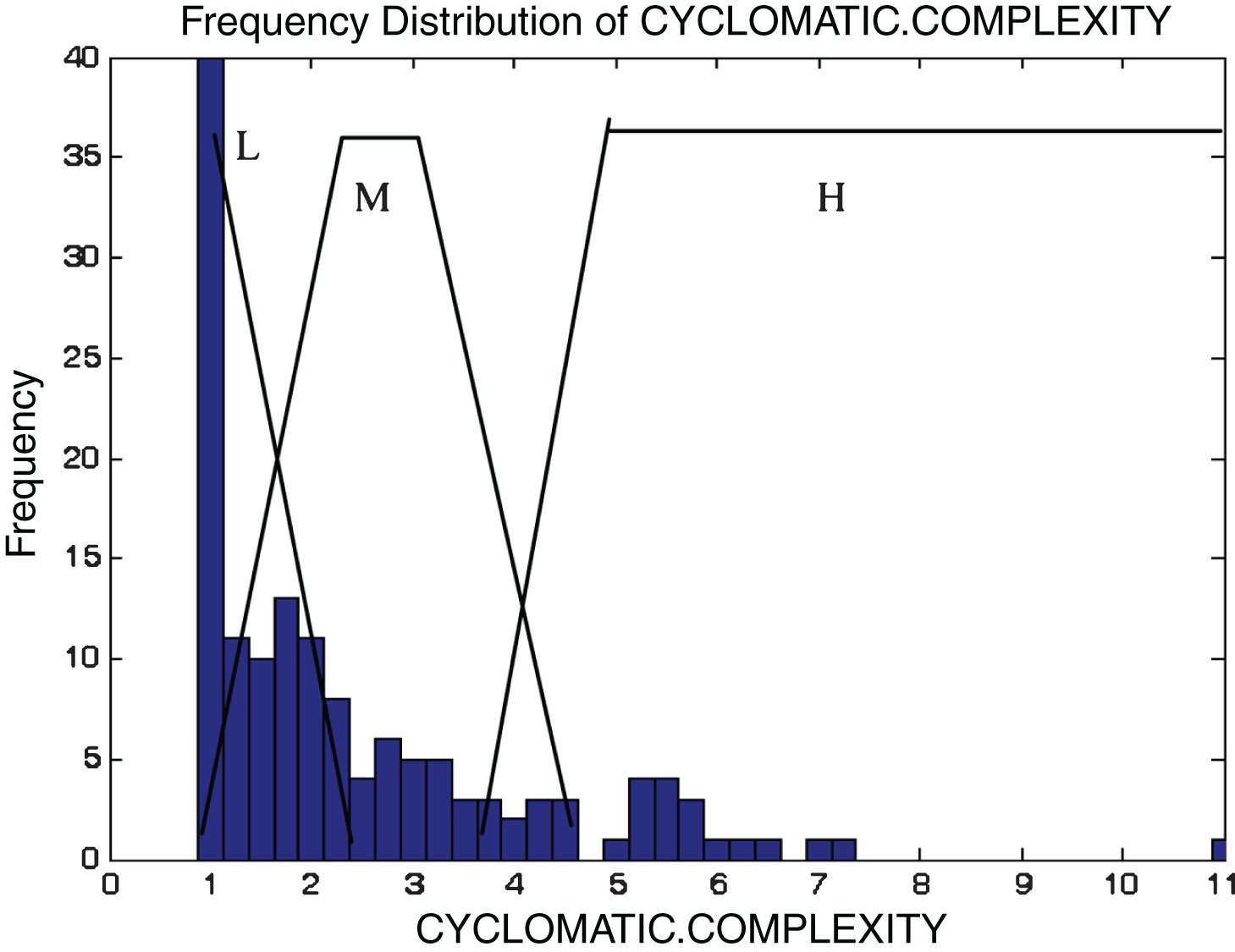
Cycloramic complexity.
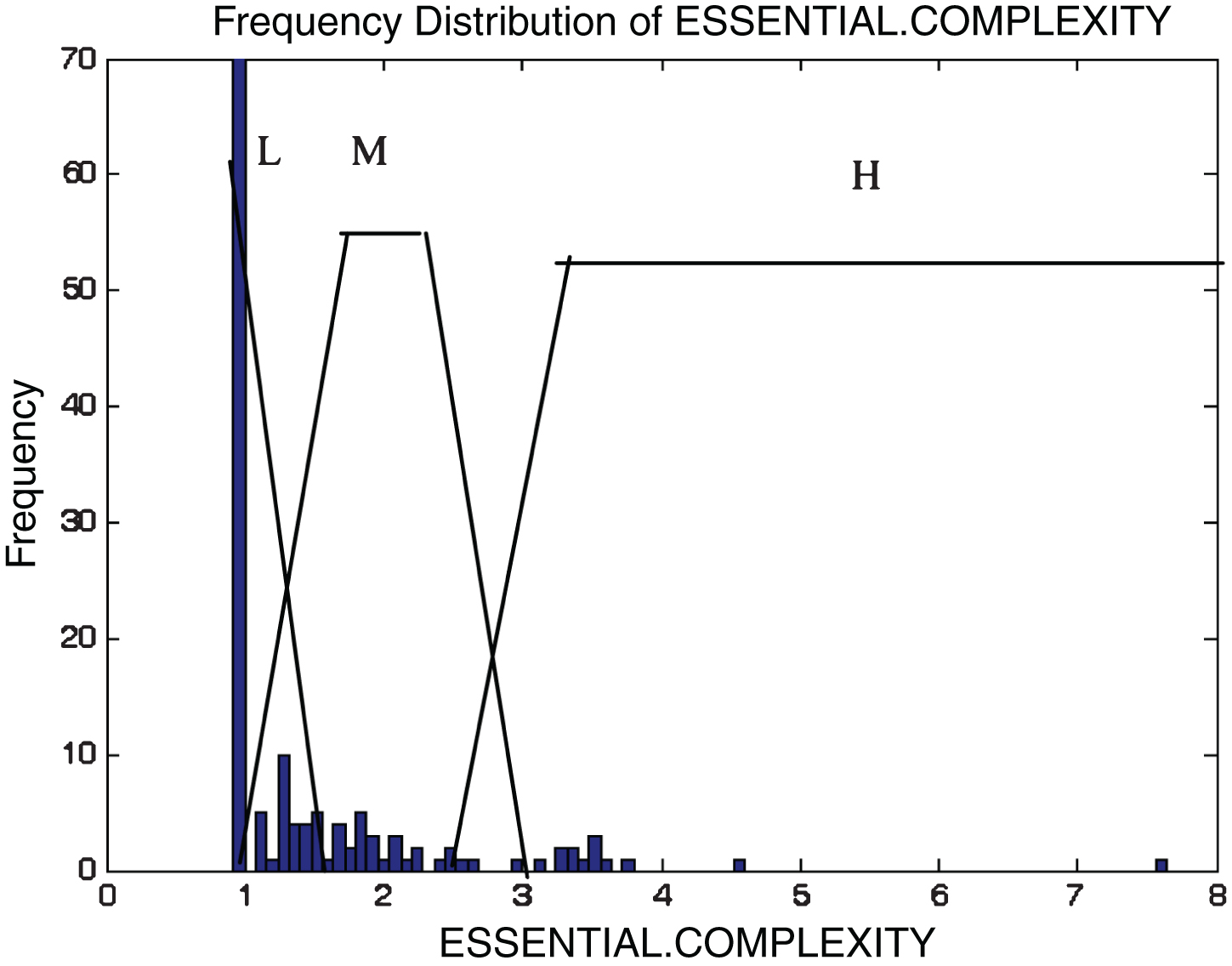
Essential Complexity.
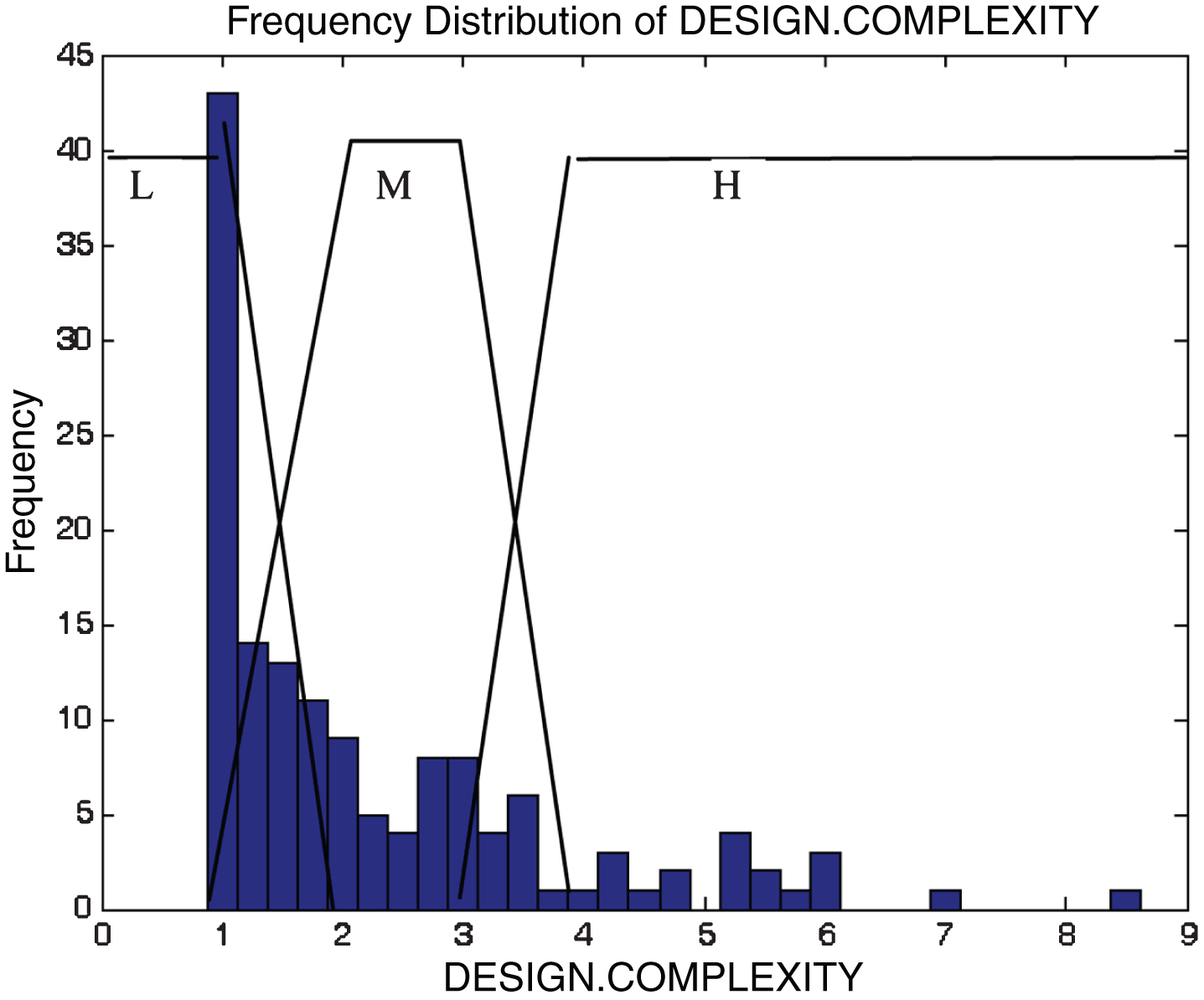
Design complexity.
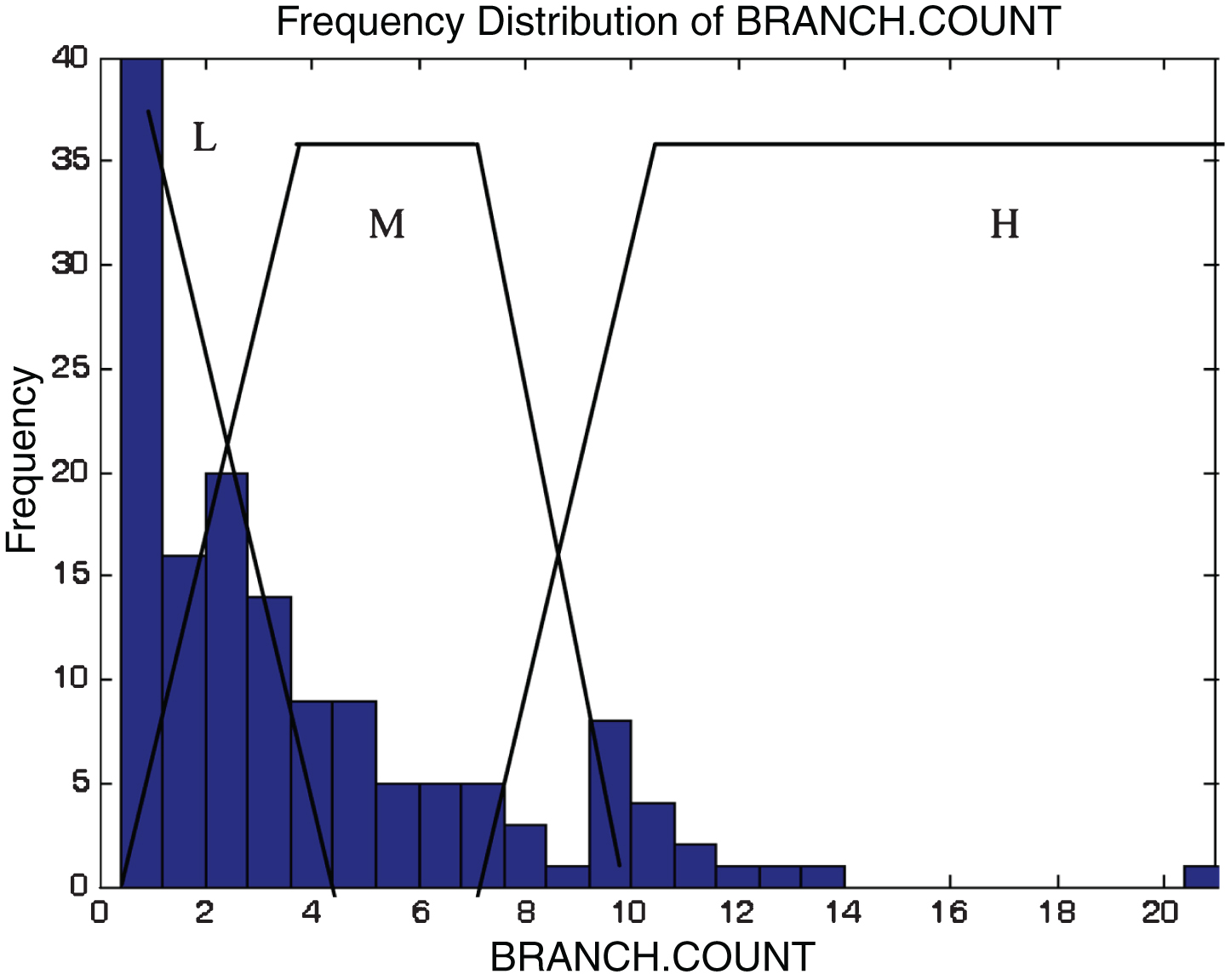
Branch count.
This subsection demonstrates the decision tree based approach on the KC2 dataset. The result of the decision tree approach is illustrated in Fig. 15. To generate the decision tree for KC2 dataset [17], fifty percent qualitative data is considered as training data whereas, rest of data can be considered for testing data.
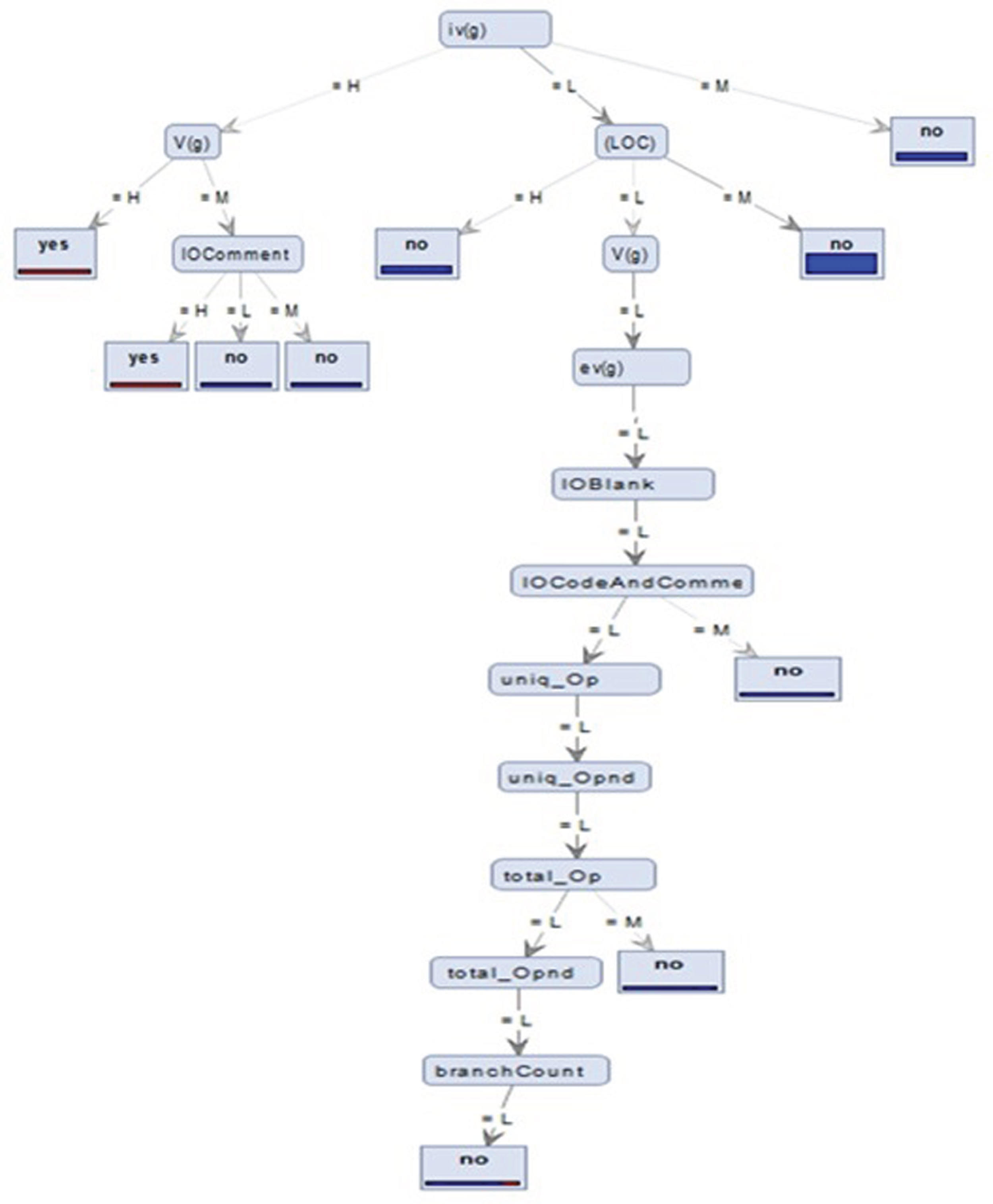
Decision tree of KC2 data set.
This subsection contains the different fuzzy rules, which are used to develop the fuzzy decision tree. These fuzzy rules are given as below.
Decision making and model validation
For the purpose of validation, out of 520 modules Khoshgoftaar et al. [12], considered randomly selected set of 260 modules as training data. While rest of dataset can be used for testing the performance of the approach. In the proposed model from module 1 to module no 260 is taken as the training data set and from module 261 to module no 520 is taken as the testing data set. For the validation of proposed methodology,we categorize the test data set into two categories. The first is fault-prone class that consist the faulty dataset, the other is in not fault-prone class. Further, the decision tree based approach is employed to extract the fuzzy rules from the training dataset. We applied the fuzzy rule 1-10 on the 10 % of the testing data set (module no. 410 to module no. 435). In this data set out of 26 modules, 12 modules are not fault-prone and 14 modules are fault prone.
In module no. 410, the value of design complexity i.e. iv(g) is Medium (M), therefore, rule no 5 will be fired, and module no. 410 is not fault-prone. Similarly, in module no. 421, rule no 5 will be fired. Therefore, module 410, and 421, are not fault-prone.
In module no. 411, the value of design complexity i.e. iv(g), is L and LOC is L and v(g) is L and ev(g) is L and IO Code is L and IO Comment is L and IO Blank is L and IO Code and Comment is L and Uniq op is L and Uniqopnd is L and Total op is L and Total opnd is L and Branch count is L, therefore, rule no10 will be fired, module 411, is the predicted result and the actual result of testing data is shown in Table 2. The result of 26 modules is presented in summarizing form in Table 3 not fault-prone. Similarly, in module 412, 413, 415, 416, and 420, rule no 10 will be fired. Therefore, module 411, 412, 413, 415, 416, and 420, are not fault-prone.
Actual and predicted result
Actual and predicted result
Decision of 26 modules
In module no. 417, the value of design complexity i.e. iv(g) is High (H), and vg(g) is M and IO Comment is L, therefore, rule no 3 will be fired, module 417, is not fault-prone.
In module no. 418, the value of design complexity i.e. iv(g) is High (H), and vg(g) is M and IO Comment is M, therefore, rule no 4 will be fired, module 418, is not fault-prone.
In module no. 419, the value of design complexity i.e. iv(g) is Low (L) and value of line of code i.e. (LOC) is Medium (M), therefore, rule no 7 will be fired, and module 419 is not fault-prone.
In module no. 414, the value of design complexity i.e. iv(g) is High (H), and vg(g) is H, therefore, rule no 1 will be fired, module 414, is fault-prone. Similarly, in module 414, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, and 435, rule no 1will be fired. Therefore, module 414, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, and 435 are fault-prone.is L and Total opnd is L and Branch count is L, therefore, rule no 10 will be fired, module 411, is not fault-prone. Similarly, in module 412, 413, 415, 416, and 420, rule no 10 will be fired. Therefore, module 411, 412, 413, 415, 416, and 420, are not fault-prone. Similarly, we applied the fuzzy rule 1–10, on 20%, 40%, 60%, 80%, 100% of the testing data set (module 261 to module 520). Table 4 depicts the simulation results of the proposed model. For showing the efficacy of the proposed model, we have distributed the test data set into six categories i.e. 10%, 20%, 40%, 60%, 80% and 100%. It is seen that our model achieves higher than 95% accuracy using all categories. The overall accuracy of our model is 96.58%. Further, to validate the proposed model, the simulation results are also compared existing work presented in The result of the proposed model is compared with earlier work of Pandey et al. [15]. From Table 5 we can infer that better exactness is attained by proposed model compared to Pandey et al. model [15].
Decision result of all modules of testing data set
Model validation
This paper presents a fuzzy profile and fuzzy rule base development process for decision making in various applications of science, engineering, and technology using numeric data. In the proposed model, fuzzy rule base is identified using decision tree based approach. Further, a fuzzy decision tree based approach is also presented to extract the fuzzy rules and fuzzy profile. In this work, thirteen-membership function is defined by using thirteen attributes of the KC2 dataset. These membership functions are analyzed using histogram method. This paper also presents a case study using KC2 dataset and overall process is described using this case study. The proposed approach is applied to small and big data set and compared to earlier work. The decision results from both data sets are satisfactory and have higher accuracy than existing. These results validate that the proposed model is an efficient model to predict the defects and can be applied effectively in decision-making process.