
Abstract
Fuzzy decision trees are one of the most popular extensions of decision trees for symbolic knowledge acquisition by fuzzy representation. Among the majority of fuzzy decision trees learning methods, the number of fuzzy partitions is given in advance, that is, there are the same amount of fuzzy items utilized in each condition attribute. In this study, a dynamic programming-based partition criterion for fuzzy items is designed in the framework of fuzzy decision tree induction. The proposed criterion applies an improved dynamic programming algorithm used in scheduling problems to establish an optimal number of fuzzy items for each condition attribute. Then, based on these fuzzy partitions, a fuzzy decision tree is constructed in a top-down recursive way. A comparative analysis using several traditional decision trees verify the feasibility of the proposed dynamic programming based fuzzy partition criterion. Furthermore, under the same framework of fuzzy decision trees, the proposed fuzzy partition solution can obtain a higher classification accuracy than some cases with the same amount of fuzzy items.
Introduction
Decision trees are one of the well-known methods based on some past knowledge to describe the progress of decision making. A decision tree is made up by some decision rules in the shape of internal nodes and leaf nodes [1]. Each internal node can be split into one or more children nodes to make a decision, and each leaf node is associated with a class label or an outcome. Decision trees transform a complex decision process into a set of simpler decisions to classify a given object with an easily understandable representation [2]. Many extensions have been derived from the classical decision trees because of their higher accuracy [3], fewer parameters [4], and better comprehensibility (compared to some other classification models) [5, 6]. In these extensions, fuzzy decision trees are one of the most popular approaches. They combine symbolic decision trees with the approximate reasoning offered by fuzzy representation [7]. The intent is to exploit the complementary advantages of the comprehensibility of decision trees and the uncertain information of fuzzy representation [8–10].
Based on some splitting mechanisms, fuzzy decision trees recursively partition the training data into several subsets with the similar or the same outputs in a top-down way. Specifically, fuzzy information theory as one of the splitting mechanisms has exerted a widespread influence on the growth of fuzzy decision trees. In 1992, Weber et al. [11] presented a well-known fuzzy ID3 algorithm by modifying the information gain measure, which is used to split a node for fuzzy representation. Through eliciting fuzzy sets defined for all attributes by a user, Umanol et al. [12] designed a new algorithm based on the probability of membership values to generate a fuzzy decision tree from numerical data. Ichihashi et al. [13] extracted fuzzy reasoning rules viewed as fuzzy partitions, where an algebraic method to facilitate incremental learning was also employed. As knowledge inference must be newly defined in fuzzy decision trees, Janikow et al. [8] studied several alternatives for fuzzy decision trees based on a rule-based system and fuzzy control [14]. Then, a new splitting criterion developed with a fuzzy cumulative distribution function was designed by Qi [15]. The criteria adopted minimum classification information entropy to select expanded attributes in fuzzy decision trees model. In addition, some extended fuzzy decision trees [16, 17] were established in the framework of axiomatic fuzzy set logic by improving membership functions used in the computing of fuzzy entropy. There are also some recently proposed fuzzy decision trees [6, 18–21]. However, the number of fuzzy partitions in many fuzzy decision tree approaches is predefined, which means the same number of fuzzy items is forcedly utilized in all the tree nodes. It is obvious that, to some extent, these kinds of partitions limit the representation ability and the classification accuracy.
This study proposes a dynamic programming based fuzzy partition (DPFP) criterion for fuzzy decision trees. The most important characteristic of this paper is to generate an optimal number of fuzzy items (fuzzy numbers or fuzzy sets) for each condition attribute during the fuzzy decision trees induction. This solution can avoid to predefine the number of fuzzy partitions that exists in many fuzzy decision trees. In other words, the fuzzy partitions used in this paper are flexible and realistic. The proposed DPFP algorithm processes datasets from the viewpoint of dynamic programming problems. We improve a dynamic programming method in scheduling problems on its optimal objective function, in which the new objective function can make the samples that belong to the same partition more compact. For different condition attributes, the numbers of partitions are different and the mean value of the samples in each partition is applied to define fuzzy items. Finally, a fuzzy decision tree is constructed based on the predefined fuzzy items. The main contributions of this paper include: (1) establishing a dynamic programming based fuzzy partition criterion to make the partitions more suitable for the uncertain information of fuzzy representation; (2) constructing a dynamic programming based fuzzy decision tree with higher classification accuracy than some fixed partitions based fuzzy decision trees.
The remainder of this paper is organized as follows: Section 2 offers a simple introduction about the relevant basic knowledge. In Section 3, a dynamic programming based fuzzy partition criterion, called DPFP, to confirm the best splitting points for each condition attribute. Then, the dynamic programming based fuzzy decision tree learning algorithm (DP-FDT) is proposed in Section 4. Section 5 provides our experimental results. Finally, Section 6 concludes this paper and describes the direction of future work.
Related work
In this section, we offer a simple review about a dynamic programming algorithm for semi-continuous batch scheduling problems.
Semi-continuous batch scheduling problems
In [22], Tang et al. presented a new kind of batch scheduling problem. In this problem, the jobs are processed on a machine in batch mode, where the jobs enter and leave the machine one by one and semi-continuously. The machine can handle more than one job simultaneously. The maximum number of jobs that can be held at a time in the machine is defined as the capacity of the machine. A new batch can be processed only when the processing of the previous batch is completed. For jobs in the same batch, there is a basic processing time that is defined by the longest processing time among the jobs in the batch. This problem arises in the heating operation of tube-billets in the steel industry [22].
To be able to refer to the problem being studied in a concise manner, some notation of [23] are used to present the batching machine scheduling. This notation consists of three fields, α|β|γ, where α specifies the machine environment (single machine (α = 1)); β specifies the job characteristics such as preemption, precedence relations, batching problems, and so on; and γ denotes the optimality criterion. Suppose there are n independent jobs J1, J2, . . . , J n to be processed in a machine with C capacity. The processing time of job J j is denoted by p j . All data are assumed to be deterministic [22] since the processing time is known a priori from the product specification. Adding the symbol c - batch and the symbol C to the β-field represents the fact that the machine being scheduled is a semi-continuous batching machine and the capacity of the machine is C, respectively. The notation can be summarized as follows:
1|c - batch, C|C max :] Minimize makespan on a single semi-continuous batching machine, of which the capacity is C.
For resolving of the problem 1|c - batch, C|C
max
, there is an O (n2) time dynamic programming algorithm [22] as shown in Algorithm 1. In the algorithm, f (k) denotes the minimum makespan value of a partial schedule containing jobs J1 through J
k
. B
k
represents a batch containing the k-th job. In
An example with 10 independent jobs and 5 capacity
An example with 10 independent jobs and 5 capacity
According to the initial condition, we can get f (0) =0, r0 = 0, B0 =∅.
At k = 1, i ∈ [rk-1, k - 1] = [0, 0] = {0}, when i = 0, B0 is divided from the 0-th position, which means J1 forms a single batch, that is, B1 = {J1}. As the processing time of batch B1 is p1,1 = p1 = 10, the total processing time is f (0) + p1,1 = 10. Therefore, f (1) = f (0) + p1,1 = 10, r1 = 0, B1 = {J1}.
At k = 2, i ∈ [rk-1, k - 1] = [0, 1] = {0, 1}, when i = 0, the batch B1 is divided from the 0-th position, which means J2 and B1 form one batch, that is, B2 = {J1, J2}. As the processing time of batch B2 is
At k = 3, i ∈ [rk-1, k - 1] = [0, 2] = {0, 1, 2}, when i = 0, the batch B2 is divided from the 0-th position, which means J3 and B2 form one batch, that is, B3 = {J1, J2, J3}. As the processing time of batch is
Similarly, the following results can be computed:
f (4) =15.6, r4 = 2, B4 = {J3, J4}.
f (5) =14, r5 = 3, B5 = {J4, J5}.
f (7) =16.88, r7 = 3, B7 = {J4, J5, J6, J7}.
f (8) =17.2, r8 = 4, B8 = {J5, J6, J7, J8}.
f (9) =17.4, r9 = 4, B9 = {J5, J6, J7, J8, J9}.
f (10) =17.6, r10 = 4, B10 = {J5, J6, J7, J8, J9, J10}.
Finally, the optimal value is 17.6 and the last optimal batch is B10. By backtracking, we can get the corresponding optimal schedule: {J1, J2}, {J3, J4}, {J5, J6, J7, J8, J9, J10}.
In this section, an improved dynamic programming algorithm based on a new optimal objective function is introduced. Then, the fuzzy partition criterion DPFP based on this improved dynamic programming algorithm is proposed. Let X be a set of samples with M condition attributes
An improved dynamic programming algorithm
First, an introduction is given below about how to deal with data set X from the viewpoint of adapting dynamic programming algorithm (Algorithm 1). For each condition attribute A i in data set X, there are |X| attribute values, that is, v (x1, A i ), v (x2, A i ), . . ., v (x|X|, A i ). We make three assumptions: (1) the samples are treated as |X| independent jobs J1, J2, . . . , J|X|; (2) the X attribute values are regarded as the corresponding processing time p1, p2, . . . , p|X|; (3) in Algorithm 1, there is a parameter C representing the capacity of the machine, where we consider it as a given parameter. Based on these assumptions, the dynamic programming Algorithm 1 can be applied to each condition attribute of data set X. The detailed process flow can be illustrated by Fig. 1.

Applying dynamic programming algorithm to attribute values.
In this work, our target is partitioning the |X| condition attribute values to produce fuzzy representations. In order to make the samples in a same fuzzy representation more compact, we employ a new optimal objective function to improve Algorithm 1. Suppose the |X| attribute values are ordered as p1 ≥ , . . . , ≥ p|X| and denoted as J1, J2, . . . , J|X|. For each alternative batch B
k
containing the k-th job (suppose the first job in B
k
is Jr
k
+1), we define ∥diff (B
k
)∥ as follows:
The improved dynamic programming algorithm based on the new objective function is established in the following Algorithm 2, where α ∈ [0, 1] is a parameter and α * |X| can be regarded as the capacity C of the used machine. From

The final partitions of two dynamic programming algorithms on iris dataset.
In terms of the improved dynamic programming algorithm, a partition algorithm named DPFP is designed. The purpose of DPFP algorithm is searching the optimal splitting points to generate a different number of fuzzy items for each condition attribute during the induction of the fuzzy decision tree. For a condition attribute A
i
, suppose there are M
i
the optimal partitions, that is,

The dynamic programming based fuzzy decision trees
In this section, the forms of fuzzy items related to fuzzy decision trees induction are first introduced. Then, a simple review is made about fuzzy entropy and fuzzy information gain. Finally, the dynamic programming based fuzzy decision tree, called DP-FDT, is established. Let X be a set of samples with M condition attributes
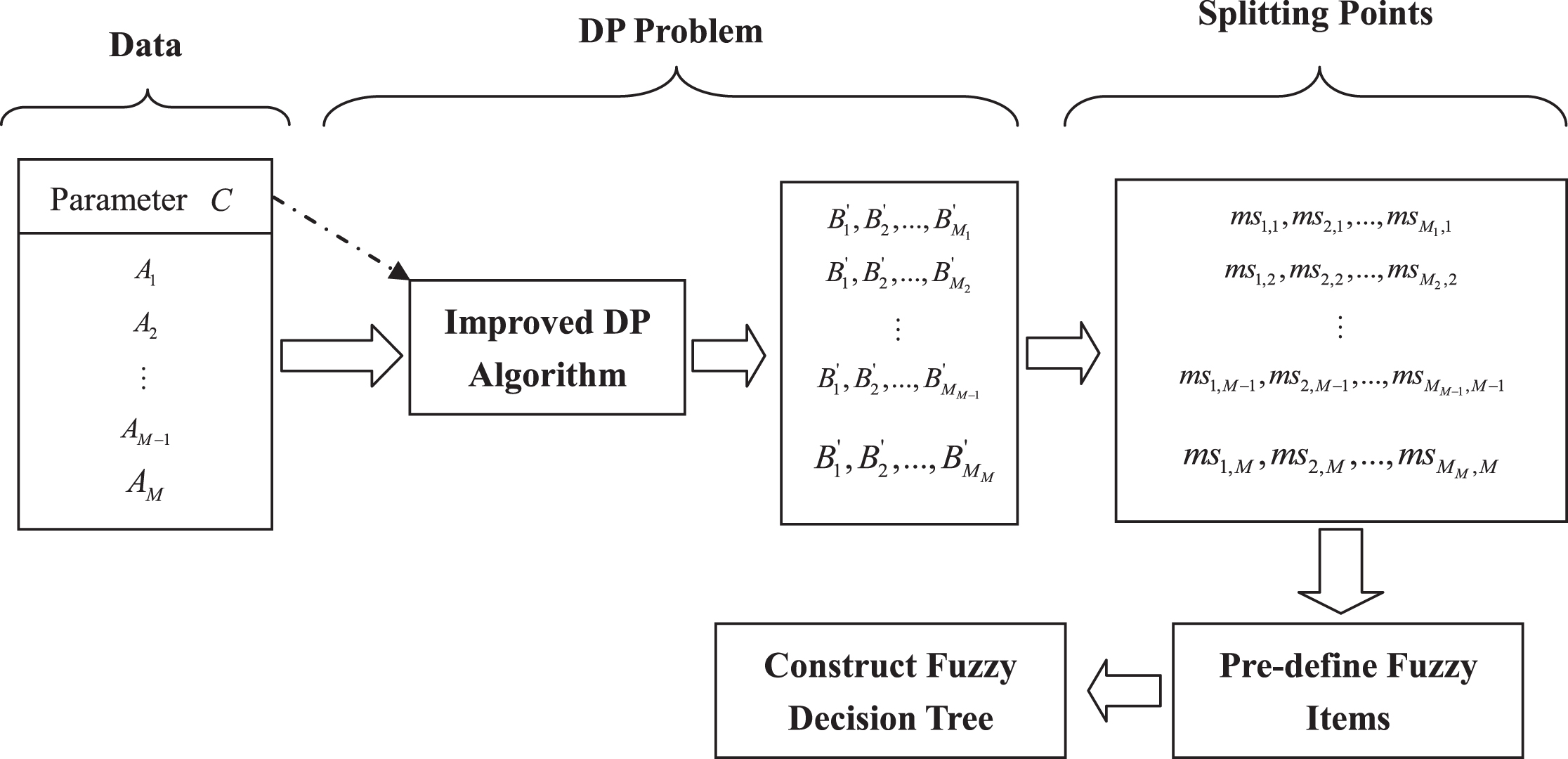
Constructing dynamic programming based fuzzy decision trees.
Many forms of fuzzy items have been commonly studied, such as the asymmetric trapezoidal form and the triangular form [25, 26]. In this paper, the forms of membership function of fuzzy items used are mixed types, such as Figure 4 in Example 3, where the first fuzzy item uses the right trapezoidal form, the last fuzzy item uses the left trapezoidal form, and the mid fuzzy items take the triangular form.
For an attribute A
i
, we treat the splitting points

Triangular and trapezoidal forms of fuzzy items.
There are many attribute selection criteria in fuzzy decision trees. The most common criterion is information gain used in the Fuzzy ID3 algorithm [11, 12]. The Fuzzy ID3 algorithm is a well-known decision tree extending from Interactive Dichotomizer 3 (ID3) algorithm [1]. Basically, both of them use an information theoretic measure of entropy to select an attribute for splitting such that the information difference is maximized between that contained in a given node and in its children nodes [10].
Let β
N
denote the set of fuzzy items appearing on the path leading to a tree node N, μ
β
N
(x) represents the membership degree of a sample x ∈ X at the node N. If
Then, the fuzzy entropy [8] can be calculated as follows:
Finally, fuzzy information gain [8] for each attribute is computed as:
Following the traditional construction process, advance consideration are taken to induct DP-FDT from four aspects: (1) predefining fuzzy items: defining or appointing the forms of fuzzy items; (2) splitting rule: selecting an attribute to generate tree’s branches; (3) stopping criterion: determining when the tree’s growth should be stopped; and (4) labeling rules: assigning the class label for leaf nodes. The following Algorithm 4 summarizes the overall flow in detail.

As shown in Algorithm 4, to predefine the used fuzzy items, the proposed Algorithm 3 is first applied to confirm the splitting points for each attribute. Then, the fuzzy items are defined according to the previous introduction about the forms.
About the splitting rule, to evaluate the feature quality, fuzzy information gain is employed, which is widely used in node splitting criteria for fuzzy decision trees. During the decision making, the attribute adding the greatest information about the decision is selected first [27]. A larger mount of information gain means there is a decrease in entropy. The growth process of tree is guided by the maximum information gain. During each repetition of the fuzzy decision trees, if an attribute has the greatest gain of information, then it is selected as the best splitting attribute for the next splitting of tree nodes.
Regarding stopping criteria, there are usually three cases for stopping in the proposed DP-FDT algorithm, as described in Algorithm 4. Obviously, one is that if all the samples covered in a tree node belong to the same class, then the entropy is zero. In this case, there is no need to split the node on the corresponding decision level. The second case is that when all the attributes are used in the path from the root to a tree node, the growth of the tree should be stopped in this node. The final stopping criterion is the information gain. If the maximum information gain at a tree node is zero or negative, then the growth of the tree is stopped.
For the labeling rules, if all the samples in a leaf node belong to the same class, then the class label is assigned to this leaf node. Otherwise, the leaf node of tree is assigned with the class label containing most of the samples covered by the current node, which is widely discussed and used in many decision tree classifiers.
Experimental studies
In this section, several experimental studies are described. First, Section 5.1 introduces the computing environment and the datasets. In Section 5.2, we investigate the impact of parameter α on the number of fuzzy items. Furthermore, Section 5.3 provides a detailed comparative analysis of the classification accuracy with several traditional decision tree classifiers. Finally, in Section 5.4, the proposed DPFP criterion is compared with two fuzzy items partitioning criteria in terms of classification accuracy, the number of leaves and the depth of tree in a same constructing framework of fuzzy decision trees.
Computing environment and datasets
In the experimental studies, the proposed DPFP and DP-FDT algorithms are implemented in Java programming language. The data structures of WEKA [28] and the related software package are utilised (Version 3.6.9). All the experiments are conducted on a machine with a Pentium 5 3.30 GHz processor, 8 GB of RAM, and Ubuntu 14.04.1 LTS (64 Bit) operating system.
To clearly test the behaviors of our approach in real-world applications, we choose 24 datasets from the UCI Machine Learning Repository [24] as shown in Table 2. The collected datasets are related to life sciences, social sciences, and medical sciences. As a benchmark, these datasets have been widely discussed in many of the proposed approaches. In the experiments, all the results are the average values based on ten times 10-folds cross-validation technique.
The detailed information of the used data sets
The detailed information of the used data sets
In this experiment, our goal is to research the impact of parameter α on the number of fuzzy items for the data sets. From the form of fuzzy items discussed in this paper, it is obvious that the number of splitting points generated by the proposed DPFP algorithm (Algorithm 3) is equal to the number of fuzzy items used in the proposed DP-FDT algorithm. Therefore, to study the changes of fuzzy items on each condition attribute when the parameter α is shifted, the proposed Algorithm 3 is employed. The detailed changes can be found in Fig. 5, where the Y-axis is the parameter α varying from 0.1 to 1.0 under a step length 0.1, and the X-axis is the indices of the condition attributes and different colors represent the different number of fuzzy items.

The impacts of parameter α on the number of fuzzy items.
From Fig. 5, three observations can be made: (1) for a fixed α, the number of fuzzy items on different condition attributes are different; (2) with an increase of α in a certain range, the number of fuzzy items on one condition attribute has a slight decrease; and (3) when parameter α is large enough, the number of fuzzy items has no obvious changes for some condition attributes.
The underlying reasons for the above-stated results can be understood through a review of the proposed DPFP algorithm. In the proposed DPFP algorithm, there is an improved dynamic programming algorithm, where the parameter α ∗ N (where N is the number of attribute values or the number of jobs) can be regarded as the capacity C of a machine used in the steel industry. For a certain machine, the capacity is confirmed. By applying dynamic programming algorithm, different jobs may form different optimal batch schedules, which means different attribute values may have different splitting points in Algorithm 3. For multiple machines with different capacities, when the capacity of one machine is small, the optimal batch schedules of the same jobs may be different because of the capacity, however, when the capacity increases to a certain degree, the same jobs may have same optimal batch schedules. Therefore, it can be concluded that the proposed DPFP algorithm can divide different condition attributes to different numbers of fuzzy partitions on a given parameter α.
In order to evaluate the classification accuracy of the proposed DP-FDT approach, DP-FDT is compared with several traditional decision tree classifiers, including C4.5 decision tree (C4.5) [29], Multi-class alternating decision tree (LAD) [30], Simple cart (SC) [31], Random decision tree (RT) [32] and Random forest (RF) [32] (More detailed comparisons with some fuzzy decision trees are described in the next section, and thus we only discuss some classic non-fuzzy decision trees at here). All these existing decision tree classifiers are implemented by the Weka machine learning toolkit [33] (The version is Weka 3.6.9). Meanwhile, all the parameters used in these methods are set as their defaults. In the proposed DP-FDT algorithm, the parameters α and δ are respectively preset to 0.1 and 0.5. The employed datasets are 24 benchmark data sets which can be found in Table 2.
This study mainly focus on the comparative analysis on classification accuracy. The experimental results are shown in Table 3, where all the results are the average values of ten times 10-folds cross-validation technique. Meanwhile, the results marked with a bold face represent that the current traditional method can obtain a higher accuracy than the proposed DP-FDT algorithm.
The comparative results on classification accuracy with non-fuzzy decision trees
The comparative results on classification accuracy with non-fuzzy decision trees
From Table 3, we can find that, in the comparisons with the proposed DP-FDT algorithm, the traditional C4.5, LAD, SC, RT and RF classifiers can obtain better performance on 11, 2, 11, 14,4 and 4 datasets in 24 datasets, respectively. According to the average of the testing accuracies on all the testing datasets, only the C4.5 algorithm is slightly higher than the proposed DP-FDT algorithm.
In order to give a statistical analysis of the results, the Friedman test [34] is employed to verify if there is any significant difference among these results, where the null hypothesis of the Friedman test is that the tested indices are equivalent. Since the tests are related to 24 datasets and 6 classifiers, the Friedman statistic F F is distributed according to the F-distribution with 5 and 115 degrees of freedom, and the critical value for the significance level 0.05 is 2.2932. As the F F statistics for the results in Table 7 is 12.3307 greater than 2.2932, the null hypothesis cannot be rejected, which means that there is a significant difference among these classifiers.
Therefore, we use the Nemenyi post hoc test [34] to evaluate the pairwise differences, where the critical difference (CD) is 1.5392 for α = 0.05. In Table 4, the pairwise differences (in absolute value) of the average performance ranks for the classification accuracies are described. The underlined values are the pairwise differences greater than CD, which implies that there is a statistically significant difference in performance. From the highlights in Table 4, the following conclusions can be summarized about the proposed DP-FDT algorithm: (1) the proposed DP-FDT algorithm performs significantly better than the traditional LAD, RT and RF classifiers; and (2) the C4.5 classifier and SC classifier are not significantly different from the proposed DP-FDT algorithm.
Pairwise differences of average performance ranks for classification accuracy
Based on the above analysis, the proposed DP-FDT approach can obtain a similar classification accuracy to the existing traditional tree models, and even better than some approaches such as the LAD classifier, RT classifier and RF classifier.
The goal of this experiment is to compare the proposed DPFP criterion with two fuzzy items partitioning criteria in the same induction framework of fuzzy decision trees. The two partitioning criteria need to predefine a fixed number of fuzzy items for each condition attribute. One criterion is that the number of splitting points used in fuzzy items is equal to 3 [7, 17], where the first splitting point is the minimal attribute value, the second splitting point is the mean value, and the third splitting point is the maximal attribute value. The other criterion is that the number of splitting points is equal to the number of classes [6, 35], where the cut points are calculated as follows:
In this experiment, the above three different fuzzy items partitioning criteria are simply marked as Fuzzy items=DP, Fuzzy items=3, and Fuzzy items=Class. It should be note that the same framework is employed to construct tree except for the partitioning of fuzzy items. The parameter δ varies from 0.1 to 1.0 under a step length 0.1 during the induction. The parameter α used in DP-FDT is 0.1. More in detail, we are interested in evaluating the impacts of these criteria in final decision trees on the classification accuracy, the number of leaves, and the depth of the constructed trees. The detailed results on 12 CUI datasets can be found in Figs. 6, 7, and 8.

The impact of different partitioning criteria on the classification accuracy with varying of δ.
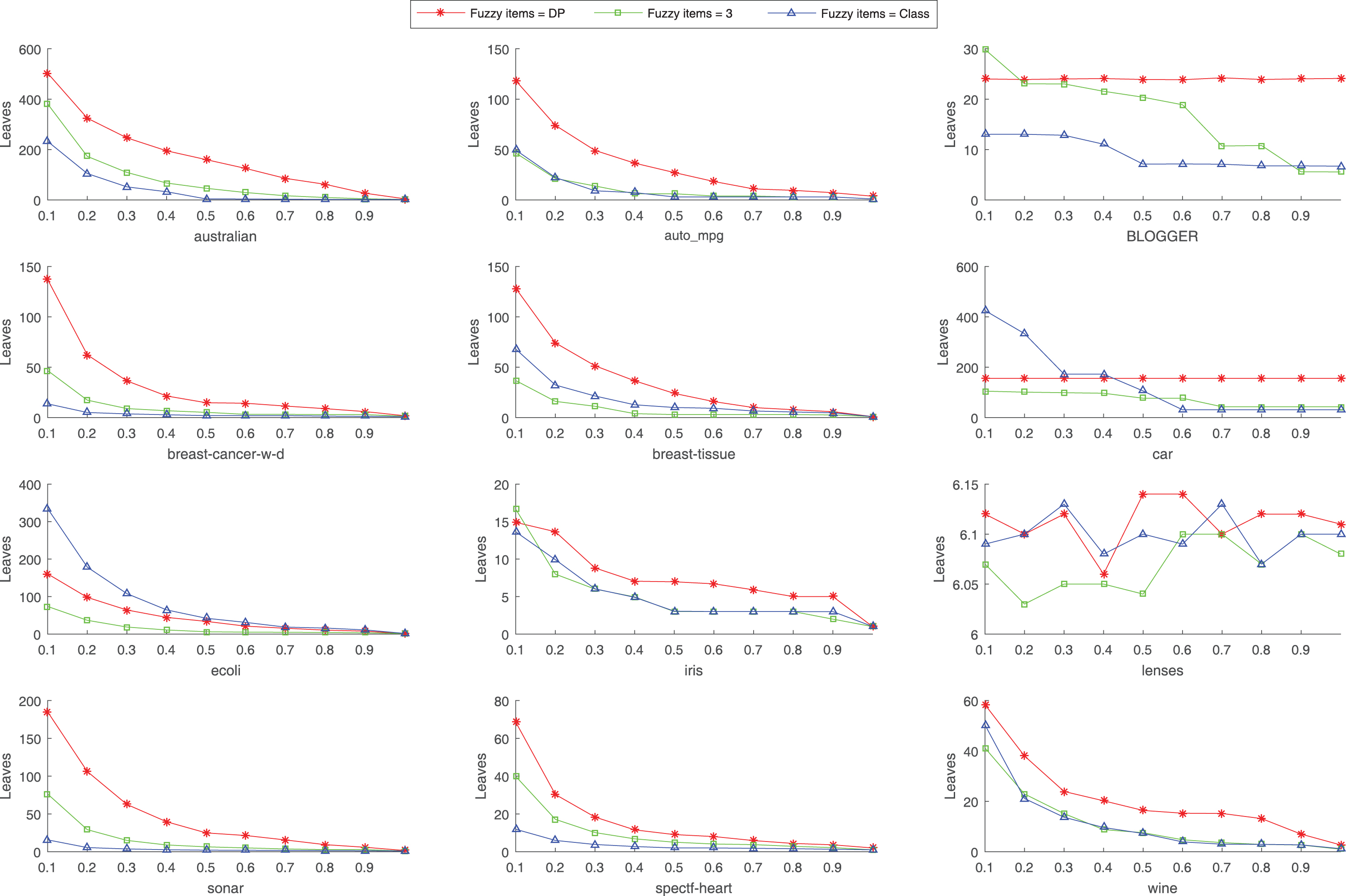
The impact of different partitioning criteria on the number of leaves with varying of δ.

The impact of different partitioning criteria on the depth of tree with varying of δ.
As shown in the curves in Fig. 6, in most cases, the proposed DPFP criterion-based decision trees possess higher classification accuracies than the other two partitioning criteria. Moreover, regarding the curves in Fig. 7 and Fig. 8, there are not obvious differences among the three partitioning criteria. Meanwhile, with an increase of the parameter δ, all the curves have a decreasing tendency, which is in accordance with the intent of parameter δ. In conclusion, the proposed dynamic programming based fuzzy partition criterion for fuzzy items has more advantages over the two partition criteria for classification accuracy.
In this section, we further investigate the proposed DPFP criterion in terms of the classification accuracies, the number of leaves and the depth of tree on artificial data sets in fuzzy decision trees. During the experiments, the parameters α and δ are preset to 0.1 and 0.5, respectively. The generated artificial data sets mainly contain three categories (each category contains 200 instances), where each category obeys the normal distribution, and the means are μ = 2, μ = 6 and μ = 10, respectively. Based on these artificial data sets, this experiment mainly focuses on three aspects: the dimensionality, the noise intensity and the extreme outliers. Besides, the results are the average values of ten times 10-folds cross-validation technique.
For the dimensionality of data, we generate 6 artificial data sets, where the standard deviation σ is 1 in the normal distribution for all categories, and the dimensionality varies from 2, 4, 6, 8, 10 and 12, respectively. The experimental results can be found in Fig. 9. From the results, it is obvious that the performances on the classification accuracies, the number of leaves and the depth of tree tend to be stable with the increase of dimensionality.
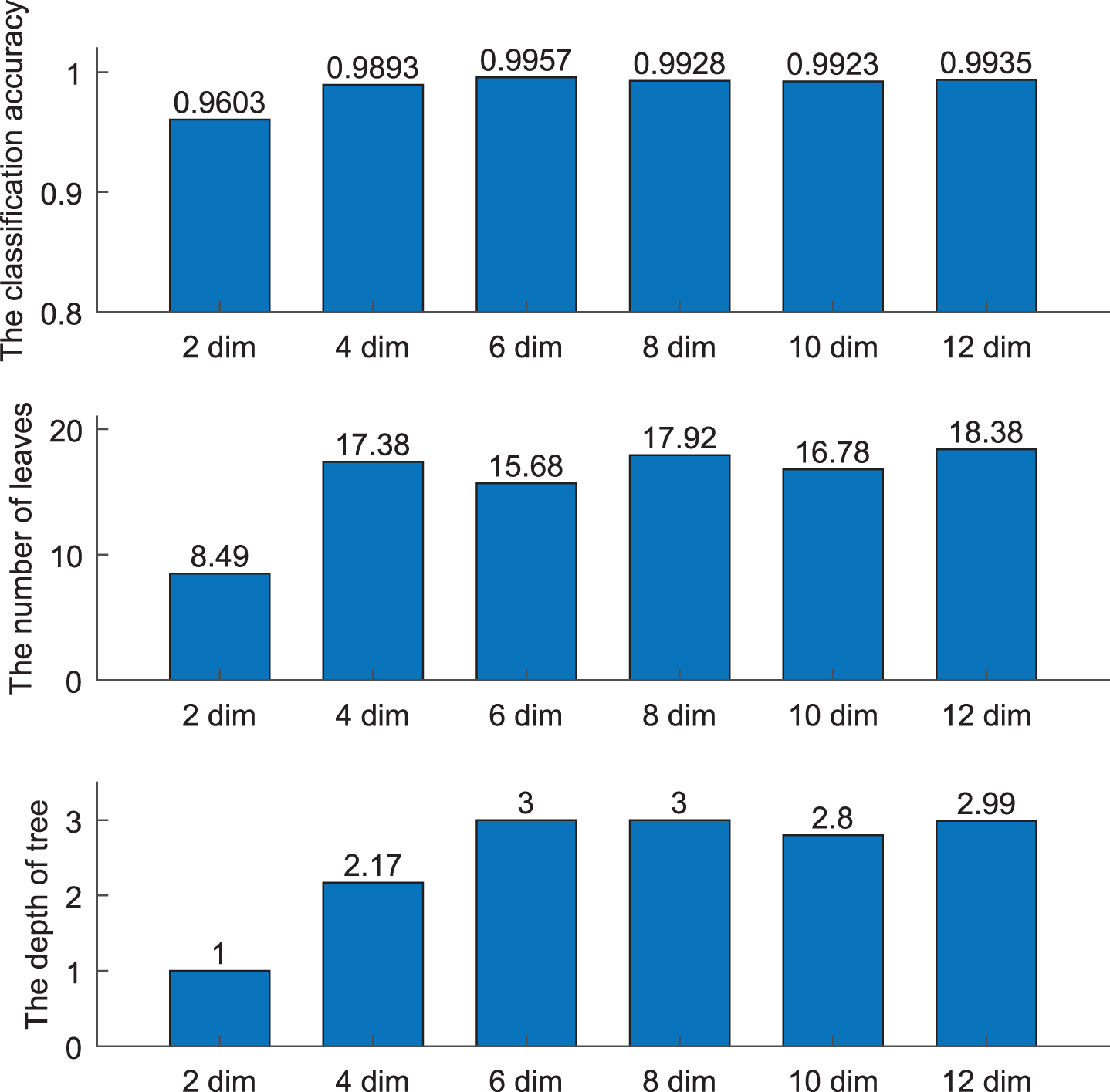
The comparative results on different dimensionality.
For the noise intensity, there are also 6 artificial data sets, where the dimensionality is fixed to 4, and the standard deviations for all categories in these data sets are σ = 1.0, σ = 1.1, σ = 1.2, σ = 1.3, σ = 1.4 and σ = 1.5, respectively. The artificial data set with the standard deviation σ = 1.0 is treated as the benchmark data set. With the increase of standard deviation, the noise intensity is increasing gradually. In order to overcome the influence of noise on the benchmark data set, the number of leaves and the depth of trees appear an upward trend, but the classification accuracy is slightly reduced (about 2.4%). Thus, the proposed method has some capability of noise immunity. The detailed experimental results are presented in Fig. 10.

The comparative results on different noise intensity.
For the extreme outliers, we first generate a data set with the standard deviation σ = 1 for all categories, and the dimensionality is fixed to 4. Then, the maximum value of each dimensionality (condition attribute) are enlarged to 2 times, 4 times, 6 times, 8 times and 10 times to conduct some extreme outliers, respectively. Through replacing the original values with these extreme outliers, the rest 5 data sets are produced. The following Fig. 11 describes the comparative results in detail. We can find that the different extreme outliers have relatively little effect on the performance results.

The comparative results on different extreme outliers.
In this paper, a dynamic programming based fuzzy partition criterion, namely DPFP, is established for fuzzy items that is mainly used in fuzzy decision tree induction. The proposed DPFP algorithm can produce different numbers of fuzzy items on different condition attributes, which resolves the fixed partitioning problem that occurs in some fuzzy decision trees. A new objective function is utilized in the established DPFP algorithm for a dynamic programming problem that makes the partitions more compact. In addition, the dynamic programming based fuzzy decision tree learning algorithm DP-FDT is proposed. The experimental studies investigate the number of fuzzy items for different condition attributes. Then, by comparing with several traditional decision tree models on classification accuracy, the proposed DP-FDT algorithm is comparable. Moreover, the DP-FDT algorithm presents a higher classification accuracy than some other fixed partitioning criteria.
It deserves to point out that there is a new parameter α in the proposed DP-FDT algorithm. How to optimize the parameter α is a meaningful direction in the future research. Besides, the proposed DPFP criterion may decrease the training time efficiency, since the dynamic programming algorithm needs more time to search the optimal partitions. However, it is necessary to highlight that the additional time can be tolerated in this study.
Footnotes
Acknowledgments
This work is supported by the Research Foundation for Advanced Talents of Henan University of Technology (No. 2019BS007), the Open Fund of Key Laboratory of Grain Information Processing and Control (Henan University of Technology), Ministry of Education (No. KFJJ-2020-112), and the National Natural Science Foundation of China under Grants (Nos. 62006071, 61773352).