
Abstract
The current massive data storage and sharing algorithm based on file system and NIOT have not considered the heterogeneous and real-time characteristics of data in distributed and heterogeneous environment, which has the problems of high storage capacity, high time delay of data sharing, and poor security of data. To address this problem, massive data storage and sharing algorithm in distributed heterogeneous environment is proposed in this paper. Hierarchical analysis of distributed heterogeneous environment is carried out. By using the file system, database technology, and hybrid technology, with the heterogeneous and real-time characteristics of massive data in distributed heterogeneous architecture, a three-level storage framework is obtained. Distributed storage algorithm is applied to save massive data. Through HBase-based massive data sharing algorithm in distributed heterogeneous environment, based on data integration mode of data warehouse, massive data sharing is achieved based on blackboard system to reduce data sharing delay. The node encryption unit is used to improve data security. Experimental results show that the proposed algorithm can reduce the occupancy rate of storage capacity, with stable storage speed and low sharing time delay. It can play a good role for data security.
Introduction
With the development of computer technology and network technology, the whole social information level is continuously improved. With the increase of user volume and user activity and the accumulation of time, data is growing faster and faster. Data accumulation is bigger and bigger. Data dimension is increasing. Data types are more and more, and data islands are also increasing. A lot of burdens are brought to users, and the cost is increasing [1, 2]. The explosive growth of information resources is becoming more and more demanding for data storage and sharing system, and it is becoming more and more difficult to store and share massive data.
The difficulties in storage of massive data are: high data amount leads to high occupancy of system resources, unstable storage speed, and high level requirement for processing methods and techniques. The difficulties of sharing the massive data: the relative independence of the system causes the data inconsistency; the high sharing time delay causes the information update not to be updated in time. Massive data storage and sharing technology is being extended to commercial application field, and the amount of data to be processed is large, which has higher requirements for the enterprise. The traditional storage method based on file system and database technology and NIOT-based sharing algorithm is hard to meet the requirements of growing massive data in capacity, storage efficiency, update speed, and security. Therefore, the research of massive data storage and sharing algorithms has become a hot topic. In this paper, massive data storage and sharing algorithm in distributed heterogeneous environment is proposed, which improves the storage capacity, efficiency, and update efficiency of massive data, and enhances data security [3].
Massive data storage and sharing in distributed heterogeneous environment
Hierarchical analysis of distributed heterogeneous environment
Distributed heterogeneous environment is a kind of Internet of things system. With the development of distributed heterogeneous environment to various industries, as one of the important public services of distributed heterogeneous environment in various industries, information service has been widely concerned [3]. The massive data in the distributed heterogeneous environment are characterized by heterogeneity, large scale, space-time association, high redundancy, and high multidimensional scalar. Figure 1 shows the architecture of distributed heterogeneous environment.

Distributed heterogeneous environment architecture.
Data storage is the core of distributed and heterogeneous environment information service system, including internal storage and external storage. Figure 2 shows the massive data storage classification and technical structure in a distributed heterogeneous environment.
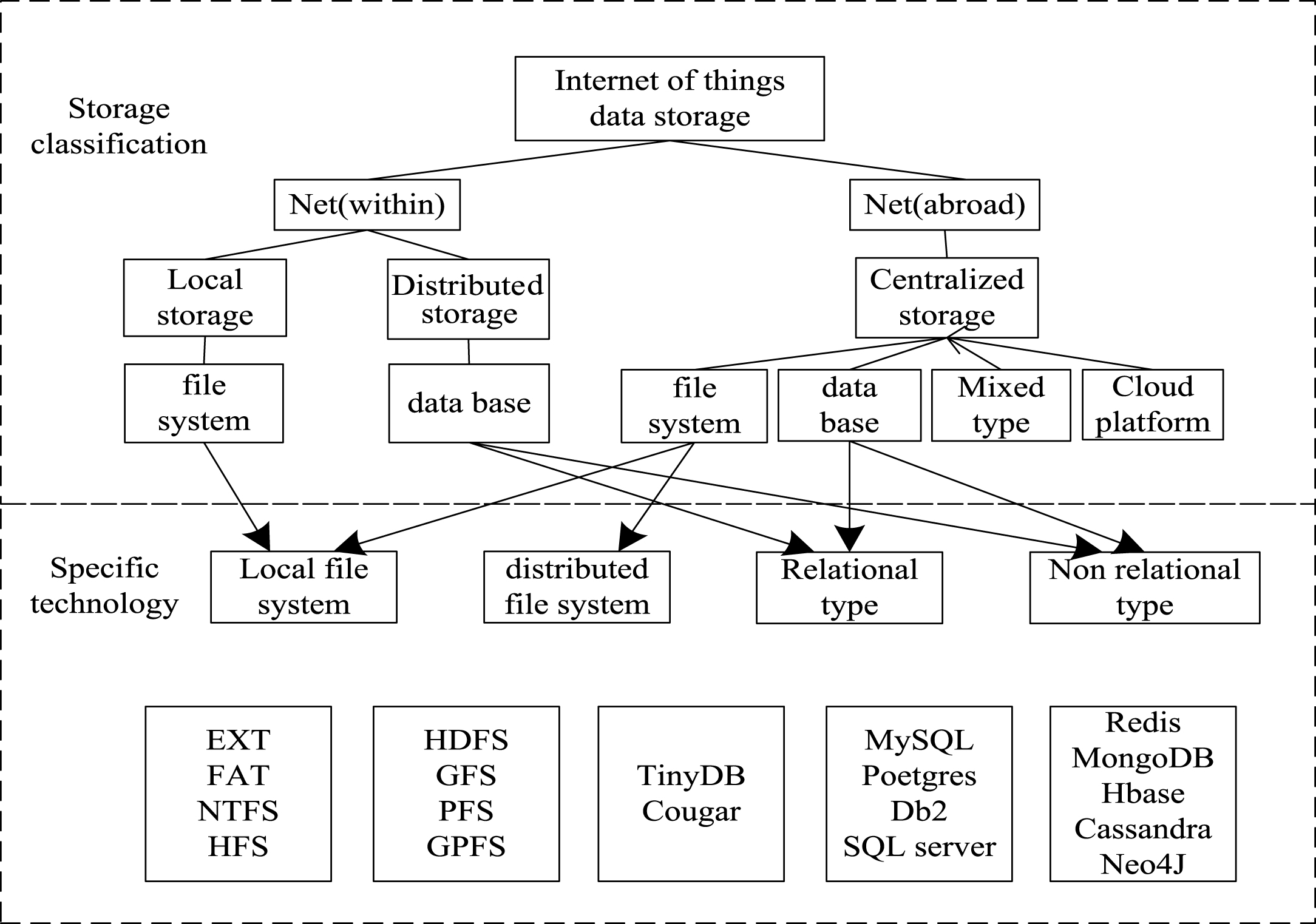
The storage classification and technology of the Internet of things.
Most researches paid attention on massive data storage with file system. This kind of file system connects several storage nodes through the network, and logically aggregate the independent storage nodes into a whole file system [4]. Unified management of node physical resources is carried out and concurrent control is provided to achieve multiuser file access. It can solve the problems of I/O bottleneck and spatial dynamic extension.
However, this kind of file system has the following problems: file structure and application tight coupling cause data sharing difficult, and special processing methods are needed [5]; the multi-dimensional and multi-granularity characteristics of mass data in the distributed heterogeneous environment are difficult to retrieve data, and the capability of real-time online data flow processing is poor. Therefore, the method based on file system is not applicable for massive data storage in distributed heterogeneous environment.
Database technology
According to data model, database technology is divided into relational database and non-relational database.
The relational database technology is mature, and most of the massive data storage methods are based on this technology in most distributed and heterogeneous environment. However, it is difficult to meet the requirement by simply extending the database to the distributed heterogeneous environment. Therefore, the corresponding solutions to the characteristics of massive data in the distributed heterogeneous environment are proposed. For the space-time association characteristics [6] of massive data in distributed heterogeneous environment, a database model BDR-KV with compatible key value (Key-Value) is proposed based on improved RDBMS. For the high degree of duplication of data, this method reduces the amount of data under the premise of data accuracy, and improves data quality. However, the core technology of the scheme is BDBMS, which has the problem that is difficult to store data, does not support fuzzy query, and does not meet the requirement of real-time query of data flow.
Hybrid technology
The hybrid method can take advantages of both database and file system. But because of the two types of storage systems, additional cost is added to the data than a single system, and the performance of the system will be affected.
In conclusion, the problem of the current research on distributed heterogeneous environment storage system is that, for the massive data in distributed heterogeneous environment, storage performance is low and sharing is hard.
Massive data storage algorithm in distributed heterogeneous environment
With the heterogeneous and real-time characteristics of massive data under distributed heterogeneous environment, under the guidance of cloud storage idea, based on distributed computing idea, a distributed file system with unified management function is established for massive data. According to the characteristics of massive data with large scale information and frequent concurrent access, a flexible cluster-based three-layer storage framework is proposed. Figure 3 shows the architecture three-layer storage.

Three-layer storage architecture diagram.
The three-layer storage framework includes data storage layer that coordinates the unified work of various devices at the low level, data service layer that plays a link between the upper and the lower layers, and data management layer for end-users in distributed heterogeneous environment. Distributed storage of mass data is realized in multiple data centers [7].
In the proposed algorithm, system storage level index is used to design a hierarchical storage mechanism for massive data in data center for solving the problem of data consistency distribution between data centers. Communication messages are transmitted to each other at fixed interval for solving the communication problem between data centers to obtain storage state [8]. The concept of storage of complete storage is used for solving the problem of storage and allocation of original data stream.
As the proposed algorithm is with the distributed architecture, data fragmentation must be carried out when the amount of increased data cannot be fully stored for a single machine. For data fragmentation, execution time of a query T
P
is given by
There is no need to fragment the smaller data to avoid the time cost of the storage space expansion. In the case of the increased amount of data, the additional performance cost of the fragmentation is less than the small amount of data [9]. The steps of the proposed algorithm are as follows.
The unified setting at system storage level is carried out for all data centers and the initial setting is 1. The distributed heterogeneous environment terminal A first sends out access request to the local data center B. If the storage capacity of the local data center B does not reach the system storage level allocated by the current system, it receives the access request and stores the data. If the storage capacity of the local data center B does not reach the system storage level allocated by the current system, it rejects the storage request. But it traverses the communication node table, looks for a data center C near the terminal A, and sends a storage request to the data center C. If the data center C meets the storage requirements of the data, the access request is accepted, and the data is stored. Otherwise, the communication node table is traversed and the appropriate distance is found for a data center, and so on. The transmission of communication messages in each data center are transmitted with fixed time for the exchange of storage capacity [10]. Local communication node table is updated in real-time. When the values in the available column of the communication node table are all 0, that is, the storage capacity of all data centers has reached the current system storage level. The current system storage level plus 1 and the corresponding communication message is sent at the same time. The data center of the whole network updates the communication node table, and waits for the next storage request.
For massive data sharing in the distribution isomerism, the data exchange standard defines the massive data exchange protocol and interaction mode under the distributed heterogeneous condition. Because of the limitation of each standard, it is difficult to achieve seamless connection and interconnection between different distributed and heterogeneous environments [11]. This is also one of the important reasons for the closed loop of the distributed heterogeneous environment.
On the basis of the blackboard system, an HBase-based massive data sharing algorithm in distributed heterogeneous environment is proposed. The algorithm is based on data warehouse-based data integration model for data sharing control. HBase database is an intermediary warehouse for data sharing. On the one hand, it provides virtual global view for all source databases. On the other hand, data with fixed subscription and high sharing frequency for all source databases are shared by data reconstruction and data replication [12]. The framework of HBase-based massive data sharing algorithm in distributed heterogeneous environment is shown in Fig. 4.

Architecture of HBase-based massive data sharing algorithm in distributed heterogeneous environment.
The specific contents of the HBase database are as follows.
Metadata management
Metadata is the data describing data. Technical metadata and business metadata are the two categories of metadata. The metadata management is mainly for technical metadata and business metadata, and management goal is to improve the sharing level and understanding of the information asset.
Blackboard system
In the proposed algorithm, HBase-based data sharing is mainly based on the idea of blackboard system. The blackboard system consists blackboard, knowledge source (KS), and monitoring organization. The structure of blackboard system is shown in Fig. 5.
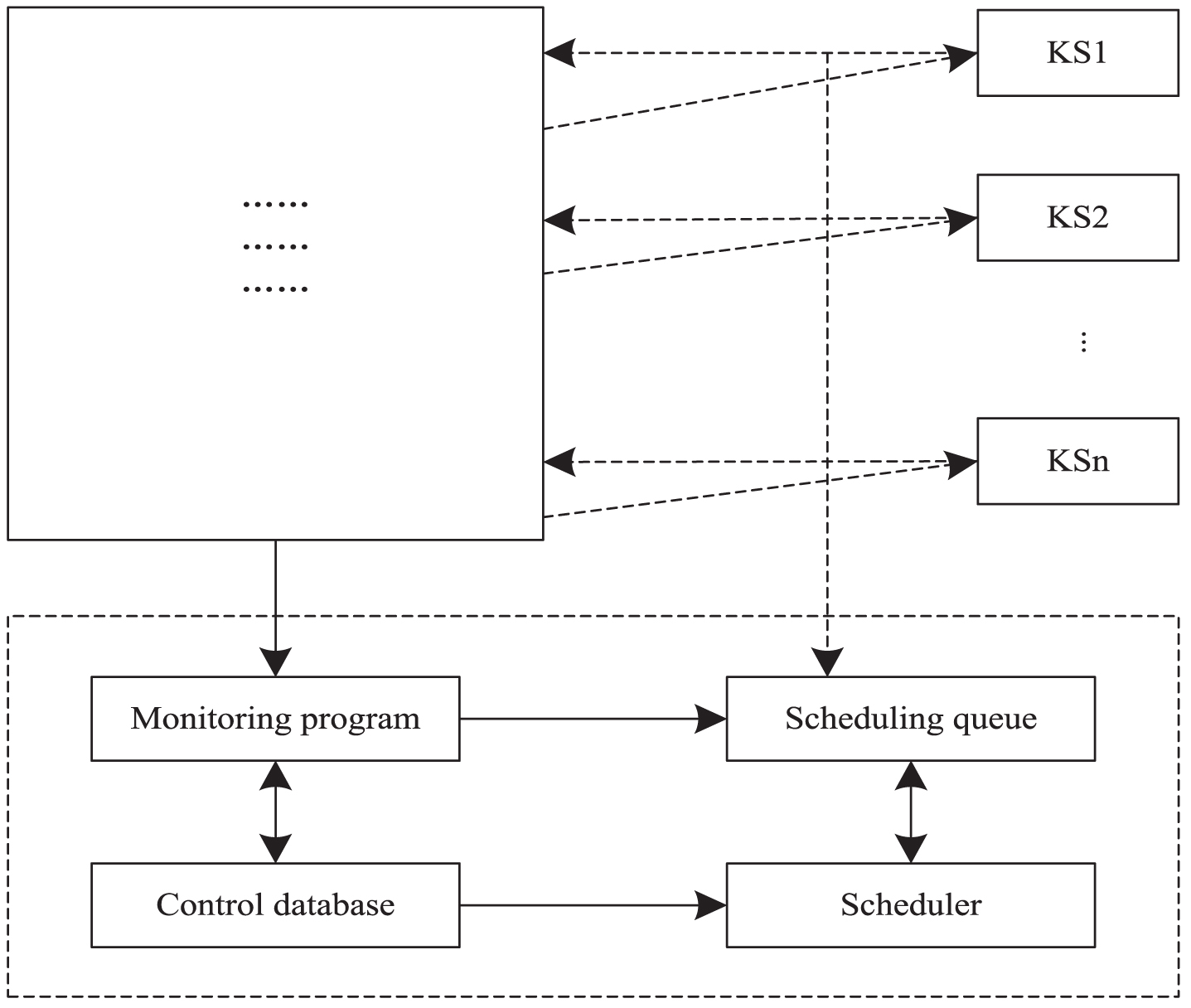
Blackboard system structure.
Blackboard: it is a global workspace. In the proposed algorithm, it is a global database for data storage at all stages. Knowledge source: it is a knowledge module. All knowledge sources are independent of each other, and their connections and calls are done through the blackboard [13]. Monitoring organization: it is an inference mechanism consisting of monitoring and scheduling program that aims to successfully solve the problem. In the proposed algorithm, blackboard is the HBase database, each source database is the knowledge sources in the blackboard system, and the metadata management module is the monitoring organization.
Data distribution strategy
The publish-subscribe model is used to distribute data in the current distributed database. The model consists mainly of three parts of message publisher, message subscriber, and publish-subscribe server. The architecture of the model is shown in Fig. 6.
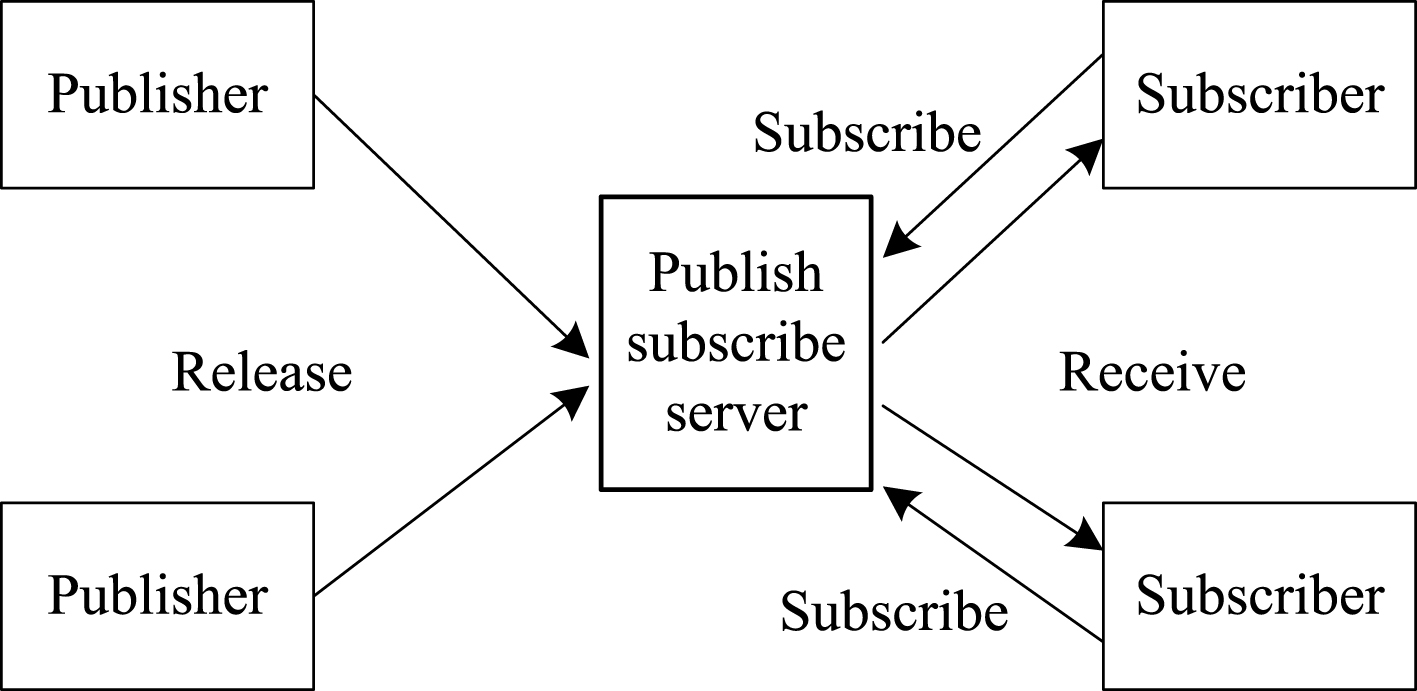
Publish - Subscribe Model.
Message publisher: a server responsible for publishing data from a data source. Message subscriber: the server responsible for receiving the data released by a message publisher. Publish-subscribe server: bridge the message publisher and subscriber and sending the publisher’s data to the subscriber. Theoretically, these three roles can be combined on the same server, but in practice, the system performance should be considered, and usually limited to some extent [14].
In the proposed algorithm, the data sharing model composed of HBase database and source database includes 5 parts: shared interface, data replication, subscription data, shared data manager, data source, and metadata management module, as shown in Fig. 7.

HBase-based data sharing algorithm model.
The operating mechanism of the proposed massive data sharing algorithm is as follows. Each knowledge source realizes data reconstruction and data replication through the connection of the HBase sharing interface and the node shared interface. The data reconstruction is the method of sharing data in HBase database. The data to be shared is stored separately from other data to form centralized management.
The performance of the proposed algorithm is as follows. (1) Efficient data manipulation ability. (2) Support for the changed requirements for public data application with system integration. Under the premise of ensuring that the functions of other modules of the system are not disturbed, the number of columns of other database tables can be dynamically increased, deleted, modified, and checked [15]. (3) Efficient system reliability and availability. When a sudden situation occurs, such as a failure of one of the nodes or the paralysis of a link, there is no impact on the normal operation of the HBase database. Multi-replica storage is beneficial to the recovery of the damaged data [16]. (4) High expansibility. It is possible to make full use of existing cheap servers. (5) Automatic recovery ability. It can automatically recover four faults of system fault, transaction fault, disk fault, and computer virus.
Aiming at the problem of poor data protection and lack of protection in network environment for the current security policy, a node encryption unit is set up in the proposed algorithm for encryption protection of data storage and sharing and encryption operation for the dynamic node in data exchange [17].
NIE-cas node bidirectional encryption algorithm is used in node encryption unit. The underlying architecture of the algorithm applies the logic of RAS encryption technology and adds node communication protocol rule. The characteristics of the data kernel are determined by generating a data induction pulse during the interactive process of accessing data nodes in the storage data. By binding the encrypted ciphertext to the outer space kernel of the normal data node, the data is in the closed specific data domain with the real-time protection [18]. The decrypted data is released by the algorithm based on the logical compensation unit feedback signal for the authentication type binding release. The NIE-cas node bidirectional encryption algorithm is divided into three sections, which are uploading node encryption, downloading data encryption and external chain access encryption [19]. The expression is given by
The experimental conditions are as follows. The size of each server storage capacity is the size of 3/20 frame data and the initial state is null. The size of the server’s store amount is set to 1 frame. The communication message is sent once every 0.3 seconds. The transmission speed of the user terminal is 2 frames per second. The simulation time is set to 5 seconds. Case 1 is that the transmission speed is 10 frames per second for the user terminal and case 2 is 30 frames per second.
According to the given experimental conditions, the comparison of the storage capacity occupancy rate of each server is obtained and the performance of the occupancy rate is compared and analyzed.
Figure 8 shows the LAN data center distribution. Three servers are set up in the LAN. A terminal user C and its local server is S1.
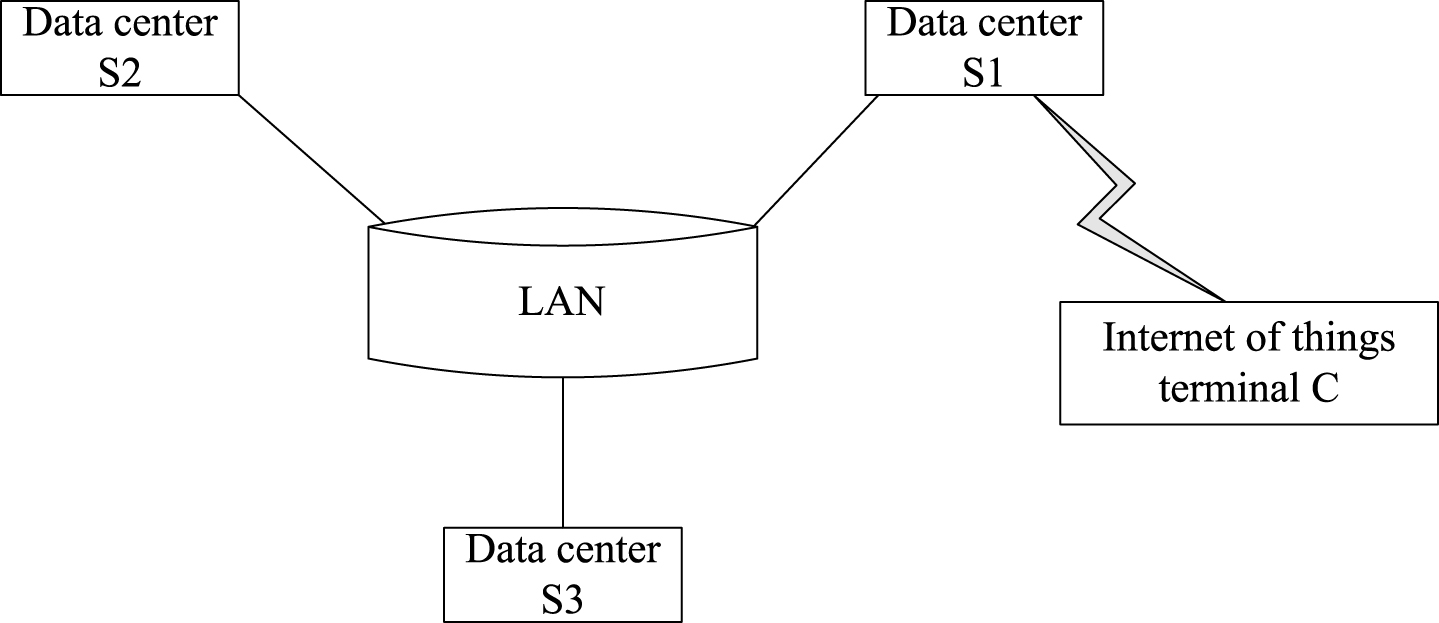
LAN server distribution diagram.
Figure 9 shows the comparison of storage capacity change of three data centers. From Fig. 9, it can be seen that, the changing curves of the storage capacity of the three data centers are roughly the same. Because the three data centers understand each other’s data storage capacity information through the interaction of timed communication messages, and set up a system storage level to achieve distributed data storage.
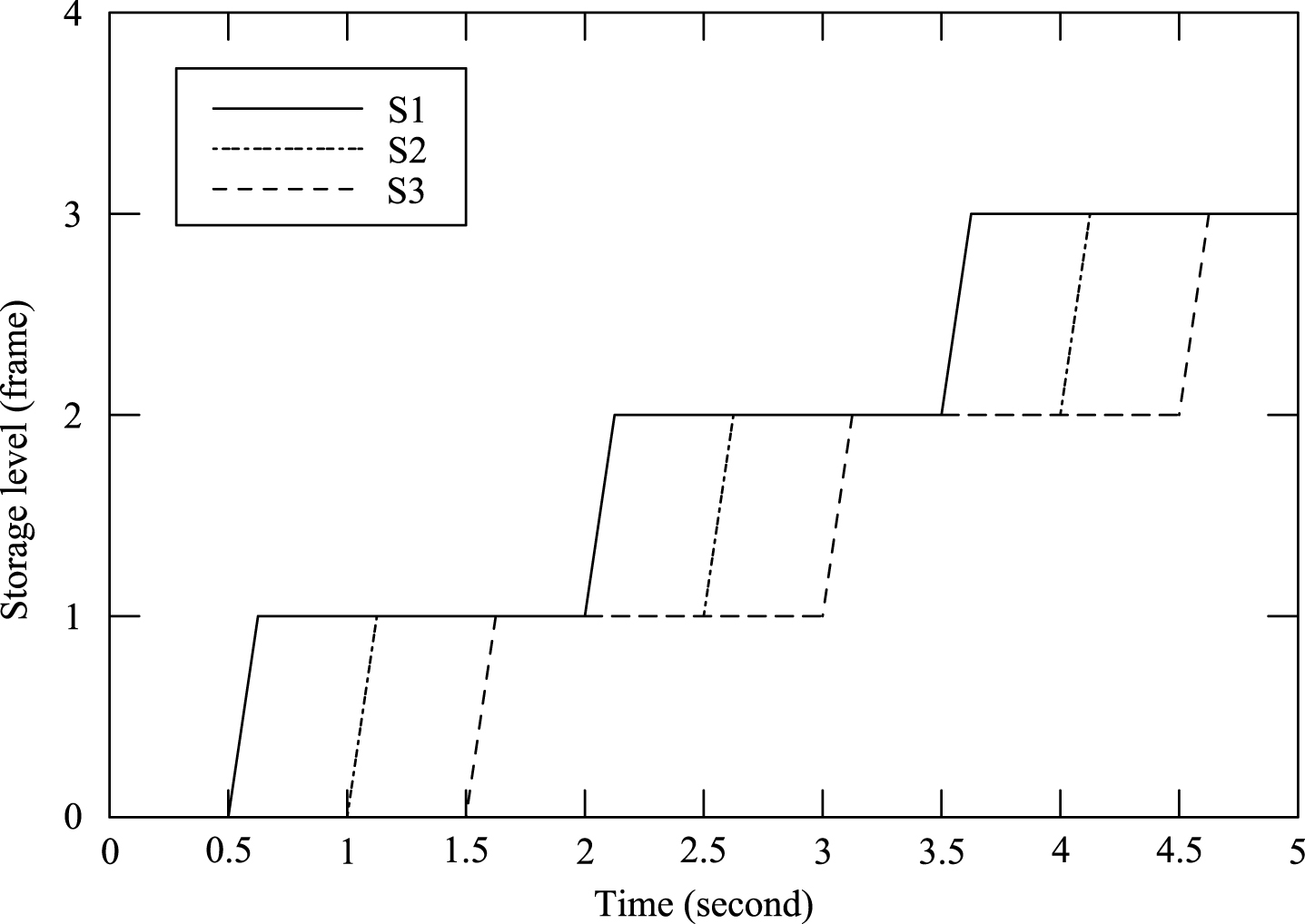
Comparison diagram of storage capacity change.
In Fig. 8, the solid line represents S1 data center. The dotted line represents S2 data center. The dashed line represents S3 data center. The comparison of the change of the storage capacity change of each data center is obtained, as shown in Table 1.
Storage capacity occupancy rate (%) contrast diagram
From Table 1, it can be seen that, the storage capacity occupancy rate R of each server can be maintained within a relatively stable range under the control of this algorithm. In the distributed heterogeneous environment, the time consuming of communication between the local data center and the response data center for the exchange of the storage state information is in the level of millisecond. The access time required by the data center to store massive data is at least in the level of minute. Compared to the storage time of massive data, the communication overhead time is even negligible.
Therefore, in the control of this algorithm, each data center can maintain local storage capacity to a relatively balanced range, so as to achieve the distributed storage of massive data in distributed heterogeneous environment.
For the storage capacity of the server with the storage space of 20 frames, the storage space of the server is in a stable state when the transmission speed of the user terminal is 10 frames per second for the first time. For the second time, when the transmission speed of the user terminal is 30 frames per second, the storage space of the server is in a state of overload [20]. Comparison of storage speed between MR algorithm and the proposed algorithm is obtained. Then the performance of the storage speed in the cases of transmission speed of the user terminal with 10 frames per second and 30 frames per second is compared and analyzed. The comparison results are shown in Figs. 10 and 11.
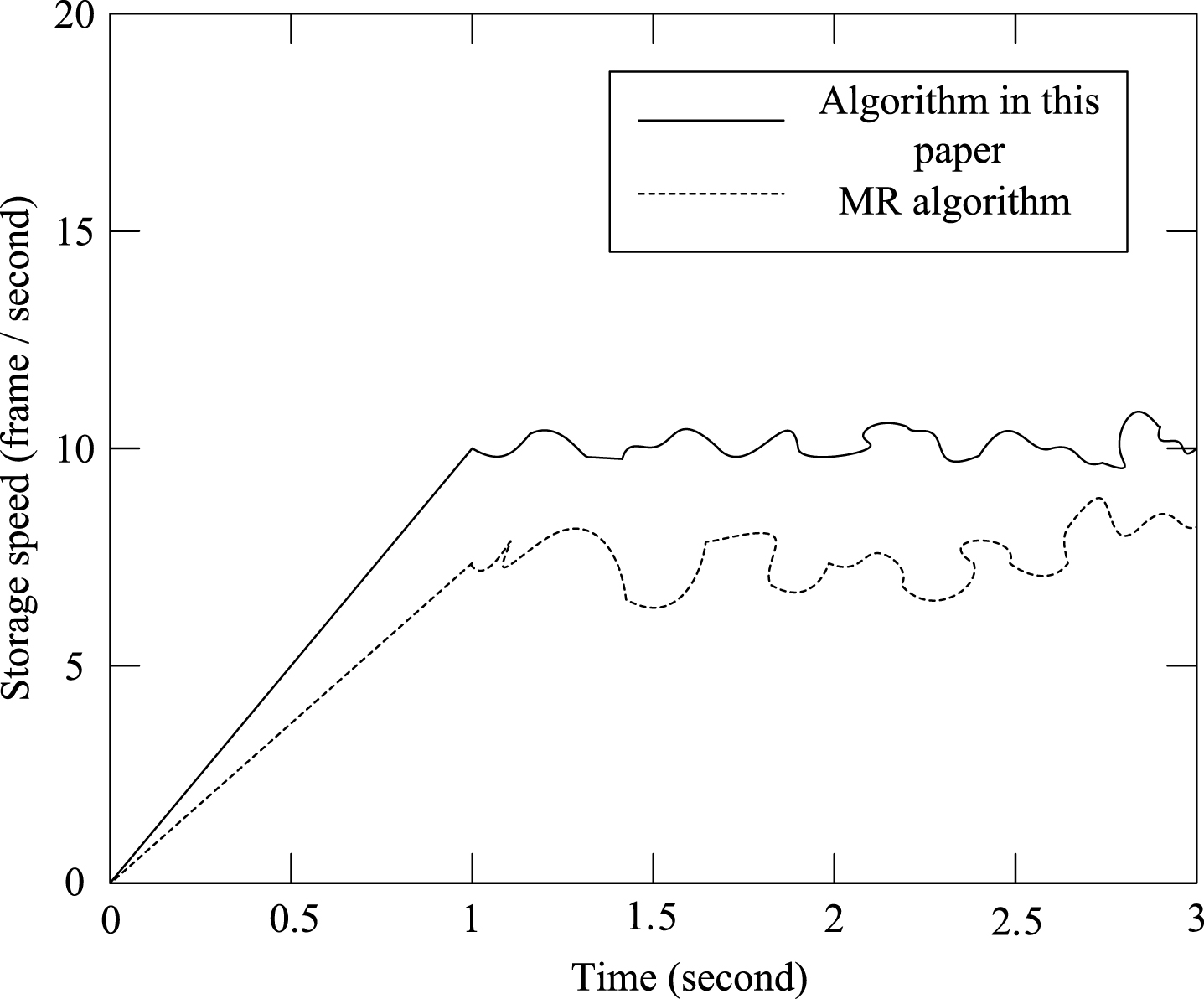
Comparison diagram of the change of storage speed (10 frames/seconds).

Comparison diagram of the change of storage speed (30 frames/seconds).
From Fig. 10, it can be seen that, the change curve of the storage speed of the proposed algorithm is more stable than the MR algorithm. It shows that the proposed algorithm can achieve the goal of stable storage speed change when storing a small amount of data, which is superior to the MR algorithm.
From Fig. 10, it can be seen that, when there is still a surplus in the buffer zone of the cluster server, the two algorithms can maintain a more uniform speed change. But when the data is full in the buffer zone, the storage speed of the MR algorithm fluctuates greatly, while the proposed algorithm has relatively small change of storage speed. The real-time massive data storage is achieved.
For testing the sharing performance of the proposed algorithm, concurrent reading and concurrent writing are evaluated.
In the test of concurrent reading, data is inserted into the database by using 1, 2, 4, 8, and 16 threads, respectively. Each thread inserts 100 thousand pieces of data and writes one piece at one time. In the test of concurrent reading test, 1, 2, 4, 8, and 16 threads is used to execute query to each database. The data scale is about 50 million, and the result set is 50 thousand. Test environment parameters include: Intel Xeon X5670 2.93 GHz (6CPU) CPU, 8GB memory, 160GB hard disk, Red hat Linux4.1.2–48 OS, Mysql-5.5.17/mongodb-2.0.4 database, the test language is Python/JAVA, and average network delay is 1.1 ms.
In the test, real data is selected in a heterogeneous environment of logistics distribution, including 2.3 million WSN data of Intel Berkeley Laboratory and 3.3 million RFID data of the lahar project of the school of computer science, University of Washington. The comparisons of performance and time delay of the algorithm are shown in Figs. 12 and 13.
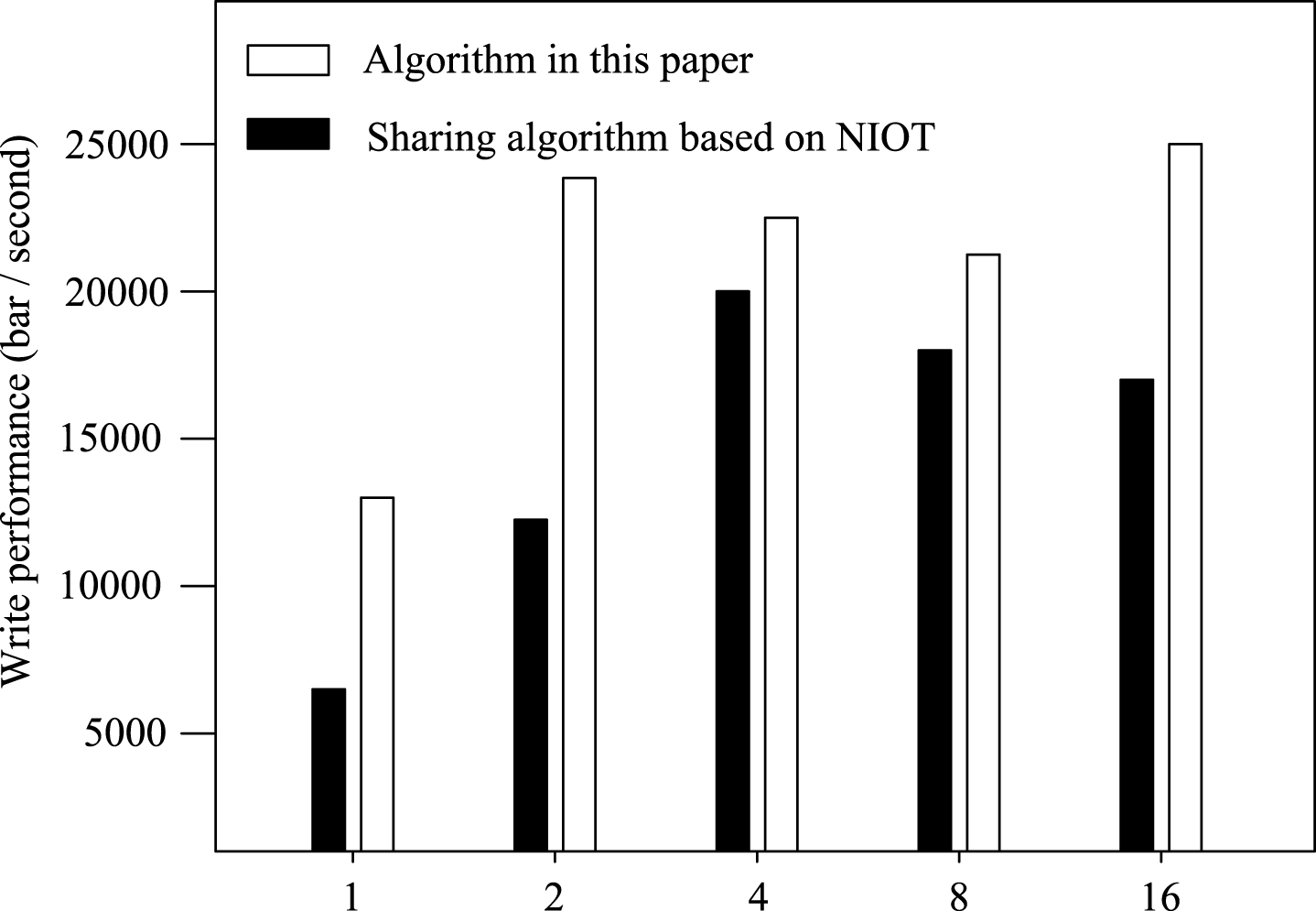
Performance comparison under concurrent writing.

Performance contrast diagram in concurrent query.
From Fig. 12, it can be obtained that, in the case of concurrent writing, the proposed algorithm can maintain at least 20%, with a maximum of about 200% performance advantages compared with the NIOT-based sharing algorithm. From Fig. 13, it can be obtained that, in the case of concurrent query, time delay of the proposed algorithm is far lower than the NIOT-based sharing algorithm, and it increases linearly with the concurrency number. Test results show that the performance of the proposed algorithm is better than the NIOT-based sharing algorithm.
In order to verify the stability of the node encryption unit and good data encryption of the proposed algorithm, the security performance simulation test of the node encryption unit is carried out. 10 different levels of attack and crack on the node encryption unit are test. Test time is 10 hr. The comparison results are shown in Table 2.
From Table 2, the node encryption unit in the proposed algorithm has a good data protection. It solves the problems of lack of safety protection and weak protection strategy of the traditional algorithm based on data storage file system and NIOT.
Performance simulation test of node encryption unit
The simulation test of the whole feasibility, performance and stability of the node encryption unit in the proposed algorithm is carried out, with the mode of continuous comparison test [21–28]. The test platform is Windows sever 2016 with 64G memory and 300TG hard disk. Test time is 72 hr. The test indexes are node processing response time, security logic overall response time, overall response time, Logical chain running continuity, maximum resource occupancy of logical chain, maximum level of security protection, security processing time under network operation, average cost of full resources, multilevel data attack protection, overall performance stability, and update and maintenance mode. The test results of the proposed algorithm are compared with the traditional algorithm. The comparison results are shown in Table 3.
From Table 3, it can be seen that, setting the node encryption unit in the proposed algorithm can solve the problems of traditional massive data storage and sharing algorithm in the network operation environment. For the storage security problems of the data leakage and storage server data overflow, the proposed algorithm has the advantages of fast data response, strong logic of reverse osmosis, high data security level and easy-to-use.
Simulation test of mass data security storage method under network computing environment
In this paper, massive data storage and sharing algorithm in distributed heterogeneous environment is proposed. The distributed storage algorithm is used to save massive data. Reduction of data sharing delay is achieved through HBase-based massive data sharing algorithm in distributed heterogeneous environment. Experimental results show that the algorithm can smoothly balance the storage capacity of the data center, stabilize the storage speed, and improve massive data storage performance. The node encryption unit in the proposed algorithm is stable and has good data encryption to improve the security of massive data in the distributed heterogeneous environment.