
Abstract
The multi-stage uncertain risk decision-making problems are very common in production and life, such as emergency decision-making problems, batch product sampling inspection, etc. It’s very complex and interesting in applications. The multi-stage uncertain risk decision-making process often involves multiple reference points owing to decision-making environment and decision-makers’ mentalities. This paper aims to solve the multi-stage uncertain risk decision-making problems without probability information. Decision makers’ psychological behaviors are considered by setting the thresholds of possibility degree in different states. The attribute weight optimization model is established based on the extended LINMAP method through a two-stage model, considering the principle of maximizing the ranking consistency of alternatives in all states. The stage weight optimization model is established in the viewpoint of minimizing the opportunity loss. The optimal alternative is selected according to the compromise ranking values, which consider the satisfaction of decision makers. A case is presented to illustrate the feasibility and validity of the proposed method.
Keywords
Introduction
Multi-stage uncertain risk decision-making (MSURDM) problems exist widely in daily life. For example, emergency assessment, quality inspection, disaster prediction and so on. There are several special issues that have to be concerned.
There may be several states without probability information in the future due to the uncontrollable natural factors and human factors. That may lead to certain risks and uncertainties to decision-making (DM)problems [8]. When facing DM risks, decision-makers (DMs) often have some risk appetite [5–7]. Due to the limited rationality of humanity’s thinking, there is psychological perceptual deviation. DM environment is always in a dynamic change [21, 33]. The development levels at different stages are required to be considered.
Multiple states often exist in DM problems owing to the uncertain environment. DMs often rely on the expected value to solve this kind of problem, if the probability is known [1–3]. Probability information is a prediction of future which needs a long-term observation. It’s hard to obtain the probability information. In this context, scholars have made a lot of research taking into account the multiple impacts on DM environment, DM information and DMs’ preferences. An evidence reasoning approach is proposed to solve the multi-criteria ranking problem in uncertain environment [10]. Immediate probabilities are modified based on the objective probability with the DMs’ attitudinal characters [1]. Interval probabilities are proposed to solve the multi-attribute DM problems with uncertain linguistic information [4].
It’s hard to get accurate information under complex and uncertain environment. Fuzzy set [11, 12], linguistic set [20], interval grey number [13] and so on are often used to express the DMs’ opinions. Interval grey number is an effective form to represent uncertain information. Julong Deng first proposed interval grey number to measure complex issues [14]. Later, many scholars represented by Sifeng Liu conducted an in-depth study and discussion on interval grey number [13]. A novel dominance relation between interval grey numbers is proposed for multiple attribute DM problems [9]. The degree of greyness and choquet integral is presented to solve the multiple attribute DM problems based on interval grey number [17].
The perceived deviation from DMs is ubiquitous in DM process [6]. People often make decisions by comparing the values of alternatives to the value of the reference point in order to reduce the perceived bias. Reference points are considered in the dynamic stochastic multi-criteria DM problems [18]. The target space closest to the reference point is presented to select the optimal alternative [19]. Multiple reference points are set in multi-attribute RDM problems [3]. The difference between the comprehensive evaluation point and the reference point is minimized to solve project evaluation problems [20].
DM problems are always in dynamic development. Multi-stage evaluation problems become a hot research topic. A multi-stage investment DM method is proposed based on expert evaluation [21]. A multi-objective DEA method is suggested to solve the multi-stage efficiency evaluation problem [22]. A multi-stage stochastic programming method is proposed to solve the water resource planning problem [23]. A new consensus reach model is proposed and used in a dynamic DM problem [24]. An interval dynamic reference point method based on prospect theory is suggested to solve the emergency DM problem [25].
Multiple attribute DM method is an effective way to settle the MSURDM problems. Linear programming technique for multidimensional analysis of preference (LINMAP) is a famous multiple attribute DM method to analyze the individual differences depending on a set of stimuli predefined. LINMAP method is first proposed by Srinivasan and Shocker [27]. Extensions of LINMAP can be divided into two classes. The first class is applied the decision data to uncertain forms, such as fuzzy sets [34], intuitionistic fuzzy sets [35], linguistic variables [36] and so on. The second class is the comprehensive application of LINMAP and other methods to solve different kinds of problems. LINMAP method is utilized to solve multiple criteria group DM problems [37]. LINMAP and TOPSIS are integrated to solve the hesitant fuzzy DM problems [38]. The extended LINMAP method is designed to solve the interval type-2 fuzzy DM problems [39].
This study aims to solve the MSURDM problems with reference points in which the probability information of states is unknown. Firstly, the threshold of possibility degree is presented to construct a new value function. The operator uses interval grey number, the possibility degree and the prospect theory. This makes it possible to consider DMs’ risk preferences. Secondly, the attribute weight optimization model is established based on the extended LINMAP method. The model helps to improve the ranking consistency of alternatives in different states. Thirdly, the stage weight optimization model is set up based on the relative entropy. The model helps to minimize the opportunity loss. Finally the best alternative is chosen according to the compromise ranking values, which consider DMs’ satisfaction.
This paper is structured as follows. Section 2 introduces the basic concepts. Section 3 presents the new MSURDM method. Section 4 makes a case study. Section 5 concludes the paper.
Preliminaries
DMs do not often know the distribution of DM information. They can only give the possible range of DM information. Interval grey number is an effective method to represent the uncertain information [13].
Operation rules of interval grey number are omitted [13]. There are both similarities and differences between interval grey number and interval number [13–16]. The main difference between the two kinds of numbers is the range of number. An interval grey number is the only one number which belongs to the range. However, an interval number is the whole range [13].
The formula is derived from interval number [40]. It’s found that the possibility degree of interval number has also been used in the calculation of interval grey number [2, 42], if two interval grey numbers are not identical.
In prospect theory, the value function defines the deviation of a value relative to its reference point.
Where x denotes the gain or loss of a value relative to its reference point. x ⩾ 0 represents a gain, and x < 0 represents a loss. α is the risk-seeking coefficient, and β is the risk-averse coefficient. θ indicates the loss-averse coefficient. Tversky and Kahneman [7] used a nonlinear regression procedure to estimate that when α = β = 0.88 and θ = 2.25, the experimental results are more consistent with the empirical results. The set of values have already been used in much research [3, 32]. So, we take α = β = 0.88, θ = 2.25.
Where D (p||q) ⩾ 0, if and only if p = q, D (p||q) = 0. D (p||q) ≠ D (q||p).
Problem description
This paper aims to rank alternatives or select the desirable alternative(s) from a set of feasible alternatives. The MSURDM problem is illustrated in Fig. 1. There are two kinds of information in the MSURDM problem: the values of alternatives and the values of reference points. There are several states in the future without the probability information. Decisions are made by comparing the gain or loss between the values of attributes and the reference points.

The MSURDM problem with reference points.
Let A ={ a1, a2, ⋯, a
I
} be the set of I alternatives. Let C ={ c1, c2, ⋯, c
J
} be the set of J attributes. Let
Interval grey number is commonly used to express fuzzy and uncertain information [13]. But the distribution in a given interval range is unknown. The possibility degree is introduced to measure the relationship between two interval grey numbers.
In the existing methods [16], when
Because the distributions of interval grey numbers are unknown, comparison of two interval grey numbers cannot only depend on the possibility degree. DM’s risk preferences in different states affect the relationships between interval grey numbers. It is necessary to make a comprehensive judgment on DMs’ psychological factors [6, 7].
In practice, ɛ can be obtained by interviews with experts. In a low-risk environment, DMs may set a threshold of possibility degree closer to 0, which means a smaller threshold of possibility degree can make
Where
DMs’ risk preferences have an important impact on DM values. The introduction of the threshold of possibility degree makes it possible to consider DMs’ risk preferences. Using different thresholds of possibility degree to measure DM values is more suitable for risk and uncertain information.
DM goals change over time, so attribute weights are very different from different stages. Traditional approaches (AHP method [24], the maximum entropy method [27], LINMAP method [28]) can solve DM problems with no risk. They cannot adapt to the DM environment under multiple states without probability information [2, 4].
DMs can make scientific decisions easier if the ranking results in different states are more consistent. TOPSIS [38], LINMAP [28] are value-based methods that rank alternatives according to the closeness to the ideal alternative. The traditional idea of LINMAP [28] is to construct the consistency and non-consistency of the alternative to the ideal alternative. LINMAP can realize the comparisons without a given rank. Therefore, the traditional LINMAP method is extended to the uncertain RDM environment to reduce the ranking conflict in different states.
In the tth stage,
The pair of alternatives (k, l) is ordered, which means alternative a k is better than a l .
The bigger the value of ΔV t (k, l), the higher the ranking consistency of (k, l). The smaller the value of ΔV t (k, l), the higher the ranking consistency of (l, k). The bigger the value of (ΔV t (k, l)) 2, the higher the ranking consistency of (k, l) or (l, k).
Attribute weight shows the relative importance of the attributes with respect to the DM goal. It is difficult to determine the exact attribute weight, due to the fuzziness of human thinking and the increasing complexity of the DM environment.
The following settings are considered when establishing the attribute weight optimization model. (1) In the viewpoint of ranking alternatives more easily, it is feasible to set the objective function with
Following consideration of the above principles, model M1 is established.
In model M1,
It’s hard to determine the exact values of γ1, γ2. γ1lnJ indicates the minimal entropy of attribute weights. γ2lnJ indicates the maximal entropy of attribute weights. By establishing model M2, the minimum value of γ1 and the maximum value of γ2 can be calculated under the prior conditions.
The objective function represents the maximum entropy or the minimum entropy. The constraint conditions are the same with those in model M1. Then calculate
Then the value of alternative a
i
of state s
n
in stage t
From the viewpoint of maximizing the ranking consistency in different states, the attribute weight optimization model is established based on the idea of LINMAP. In the constraint conditions, the full utilization of information and the differences between attribute weight are also considered. In MSURDM environment, stage weights have a great influence on the comprehensive ranking values. The method to optimize stage weight is researched in the next part.
If probability information is unknown, multiple DM principles according to DMs’ risk preferences are usually used, such as the Optimistic Principle (OP), the Pessimistic Principle (PP), the Mean Value Principle (MVP), the Minimum Regret Principle (MRP).
An example of RDM problems
An example of RDM problems
It is unable to find the best alternative or an effective rank according to OP and MRP. The best alternative can be obtained according to PP and MVP. But the three alternatives cannot be ranked effectively. There are no effective comparisons between states and alternatives when using the above DM principles. The relative entropy method [26] cannot only compare the differences between two distributions, but also compare the differences between each alternative. Here, the relative entropy method is extended to the MSURDM problem without probability information.
The relative entropy D (p||q) represents the information loss when using the possible distribution q (i) to fit the real distribution p (i) [26]. DMs always want the information loss as small as possible, which means D (p||q) as small as possible.
The thresholds of possibility degree in real state s
nr
and error state s
ne
is ɛ
nr
and ɛ
ne
. If ɛ
nr
> ɛ
ne
,
For any two states sn1 ∈ S and sn2 ∈ S, if n2 > n1 then ɛn1 < ɛn2.
In MSURDM process, the following factors are taken into consideration. (1) Due to the uncertain and fuzzy DM information, the opportunity loss caused by DM mistakes often exists objectively. The lower the value of D, the smaller the opportunity loss is. So, the objective function is set to minimize the total opportunity loss. (2) Stage weight meets the prior conditions H2, which can be expressed in 5 forms [29]. (3) Orness measure can reflect DM’s preference for recent and long-term data [31]. (4) Things always develop from tiny, non-significant quantitative changes to significant and fundamental changes in nature. In the time of observation, those changes tend to be quantitative changes which are relatively stable within a certain range. So, the changes of adjacent stages are relatively stable, which should be set in a certain range. There is this setting
Following consideration of the above principles, model M3 is established.
The objective function D (λ t ) represents the total opportunity loss in all states. Constraints are the following conditions. The sum of stage weight is equal to 1. Stage weight meets the prior conditions H2. Stage weights satisfy the orness measure. δ indicates the DMs’ preference for recent and long-term data (0 ⩽ δ ⩽ 1). The smaller the value of δ, the more attention DMs pay to the recent data. Otherwise DMs pay more attention to the long-term data. The last condition indicates that the change rate of adjacent stages is in the interval range of [- η, η]. Generally, η is usually given by DMs depending upon practical experience.
There are different absolute change rates with data in different stages. It is difficult to determine the absolute change rates. DMs can only give the probably range, such as
By solving model M3, the stage weights λ = (λ1, λ2, ⋯, λ T ) can be obtained. The comprehensive values V i (n) can be calculated according to Equation (12).
In RDM environment, DMs may consider both the possible benefit and the possible regret value. Take into account this, the compromise ranking value V
i
is designed as follows.
Where max
n
V
i
(n) - min
n
V
i
(n) represents the opportunity cost by selecting alternative a
i
.
Steps to solve the MSURDM problems are as follows.
To simplify the expression, the normalized data expression is unchanged. For benefit data
The possibility degrees
The range of entropy for attribute weights
The change rate [- η, η] and the orness measure δ are given according to the knowledge, experience and preference of DMs. By solving model M3, the stage weights λ = (λ1, λ2, ⋯, λ T ) can be obtained. The comprehensive value V i (n) in all stages can be calculated by Equation (12).
V i can be calculated by Equation (13) with the given preference coefficient μ. The best alternative can be selected by max i V i .
These steps can be implemented by Excel, Visual Basic 6.0, Lingo, MATLAB programming and so on. Users can package the algorithm programmatically. In practical applications, these programs can be used to solve problems easily and quickly.
From the viewpoint of minimizing the opportunity loss in all states, the stage weight optimization model is set up based on the relative entropy. In the constraint conditions, the DMs’ preference for recent and long-term data and the stability of changes between adjacent stages are considered. Finally, the best alternative can be selected by the compromise ranking values.
Background of case
To purchase a certain electronic component, Commercial Aircraft Corporation of China carries out the supplier evaluation. Products from 4 suppliers comprise the set of alternatives A = { a1, a2, ⋯, a
I
} (I = 4). Evaluation attributes comprise the set of attributes C = { c1, c2, ⋯, c
J
} (J = 5). DM information from T (T = 4) stages comprises the DM matrix
Decision data in different stages
Decision data in different stages
The following attributes are considered. c1 represents the battery capacity. c2 represents the ultimate strength before external damage. c3 represents the time that can be used continuously. c4 represents the ability to resist corrosion damage to the surrounding medium. c5 represents the ability to perform functions without error. The using environment of the electronic component is displayed as follows. s1 represents low interference. s2 represents moderate interference. s3 represents high interference.
There are two kinds of interval grey numbers. One is the values of alternatives with respect to each attribute. It is mainly acquired by quantitative methods. The other one is the values of reference points with respect to each attribute. It is mainly acquired by} technical analysis and expert discussion. The information about the thresholds of possibility degree, the attribute weights and the stage weights are acquired by interviews with experts.
The possible values of alternatives. The comprehensive values of different states.
Individual preferences and judgments of value and other subjective factors affect the final DM results. The preference coefficient μ is different from DMs. Let μ change according to step (μ) = 0.1, the change of the compromise ranking values is showed in Fig. 4. The ordinate represents the change of μ from zero to one. The horizontal ordinate represents the compromise ranking values V
i
.
The change of the compromise ranking values as μ changes.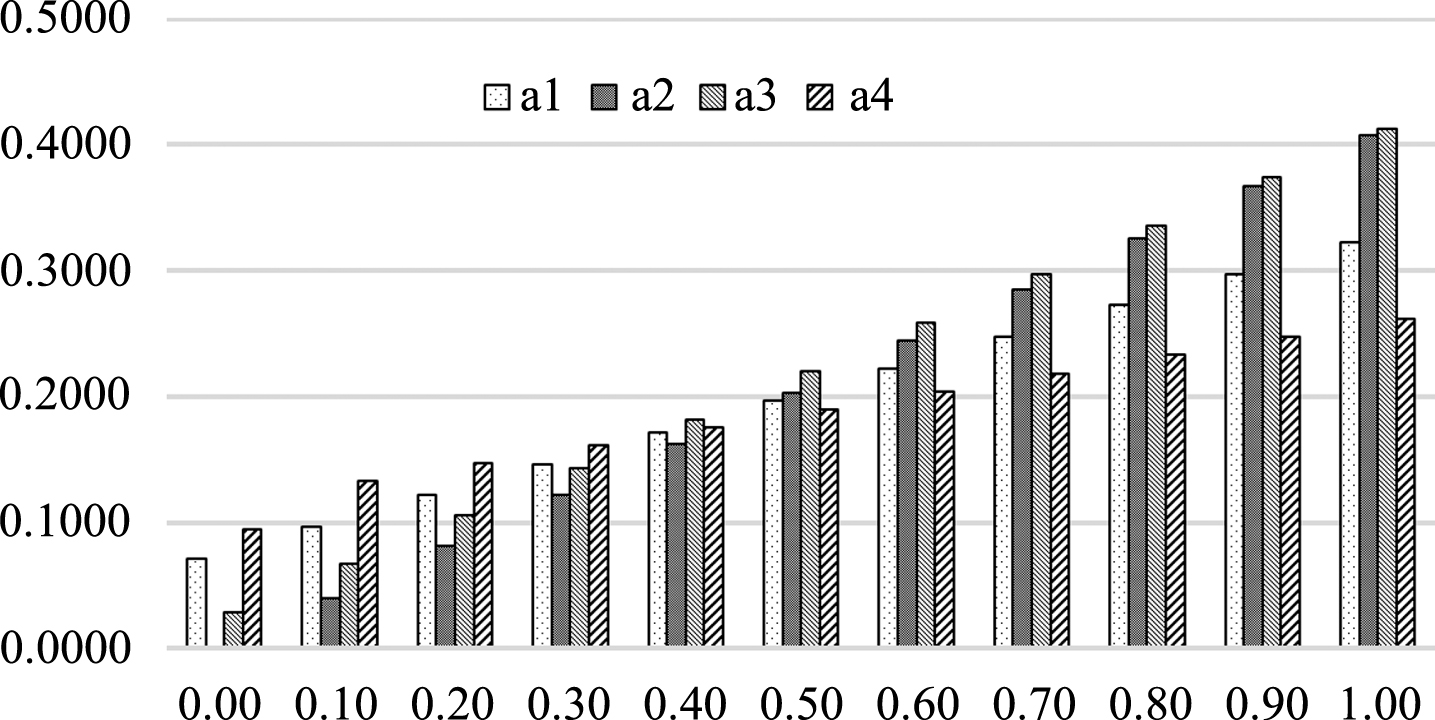
Method comparisons for the value function
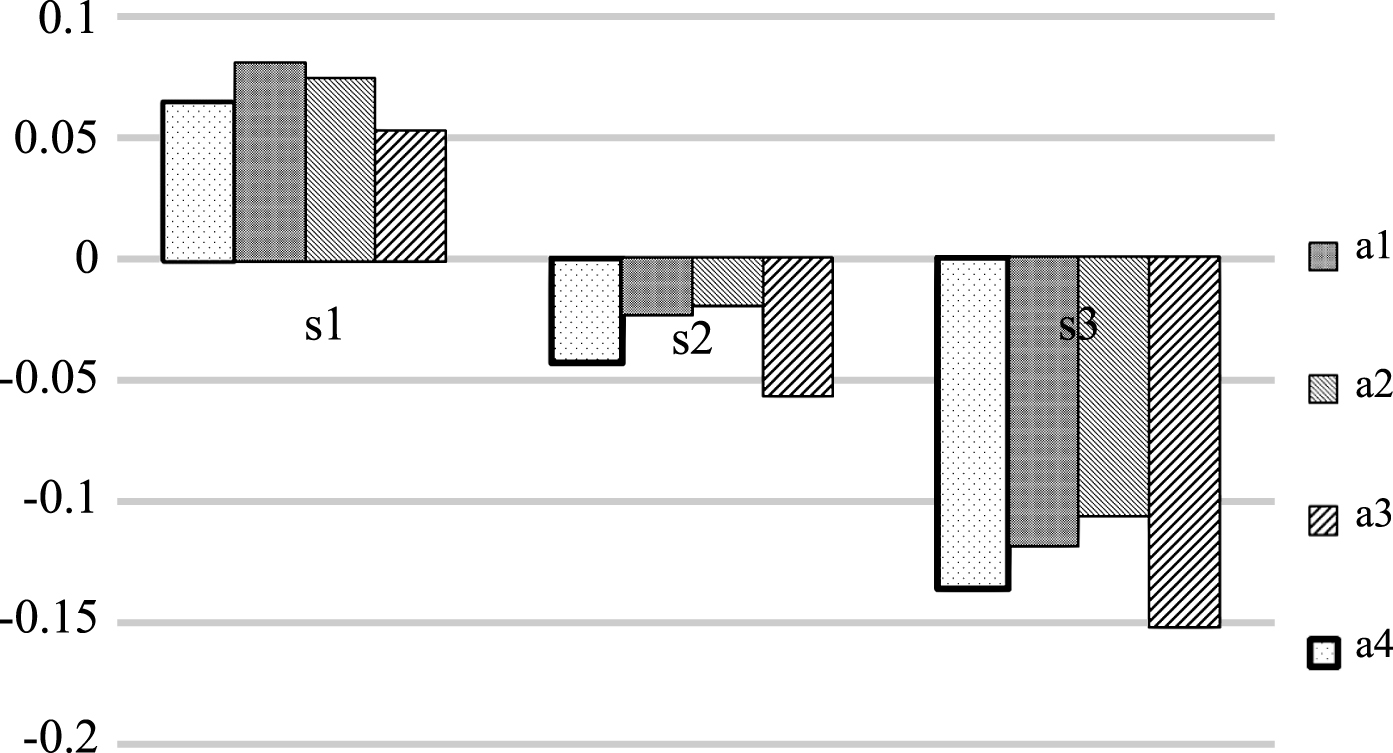
Value function is used to measure the gain and loss when comparing with reference points. The existing methods [18, 32] mainly study the expansion of value functions dealing with different data forms. The changing of DMs’ risk preferences is not considered. Considering this, the possible value function is proposed to measure the gain and loss of an attribute to its reference point in different states. The proposed method is compared with the method in literature [25]. Take the data in the first stage as anexample. The possible values The possible values obtained by the proposed method.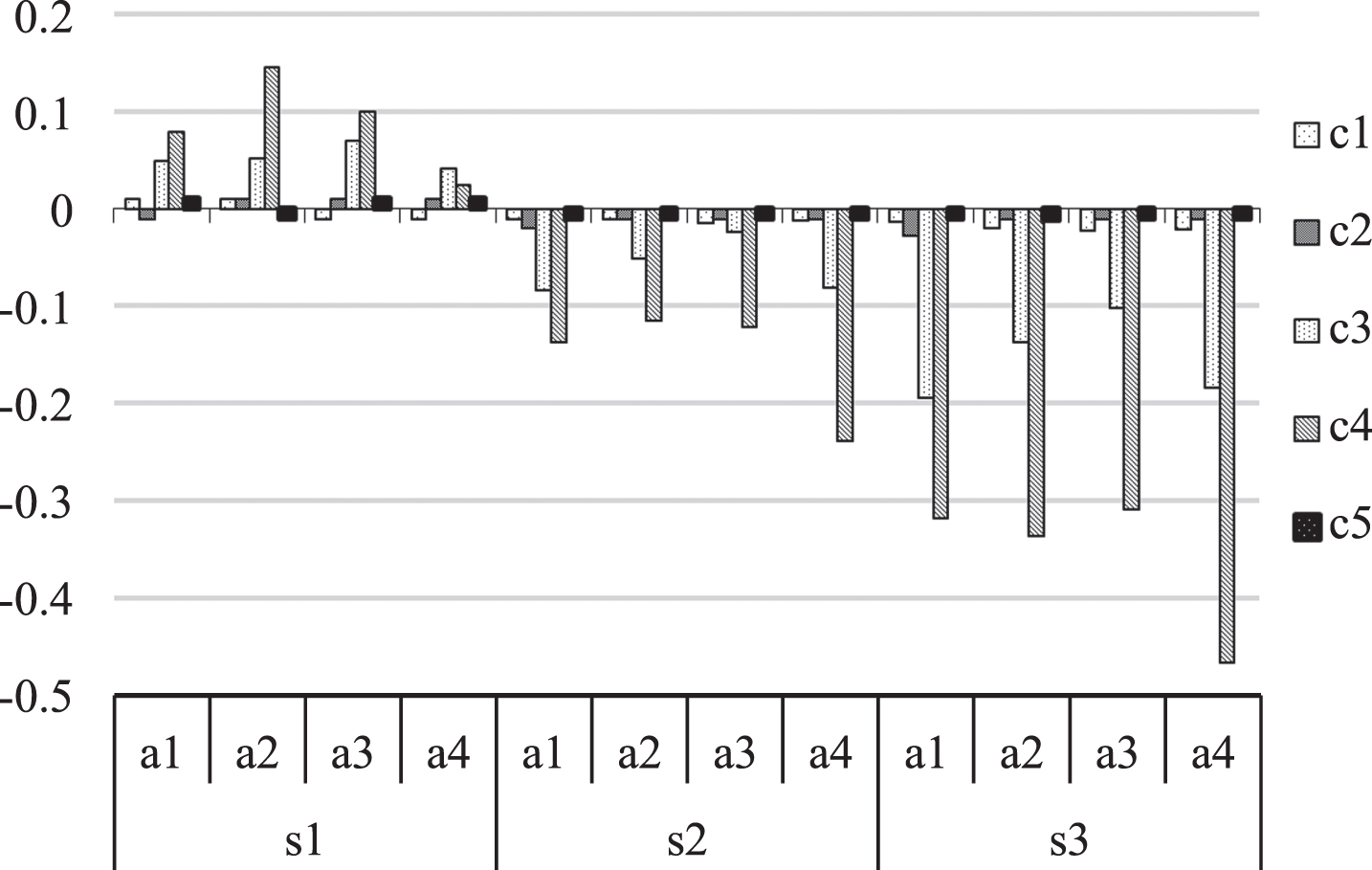
The values obtained by the method in literature [25]
The results show that. (1) The proposed method has a higher utilization rate of information. In a comparison between an attribute and a reference point, there are four endpoints in total. The four endpoints are fully used in the paper. Only two or three endpoints are used in literature [25]. (2) The consideration of DMs’ risk preferences in this paper makes the result more diversified under different states. The result of the method in literature [25] is relatively unitary. (3) The results of the proposed method are more obvious. Attribute data obtained by the proposed method are more distinct as can be observed from Fig. 5. The expression of values in literature [25] is too rough seen from Table 3. Multiple attribute values are zero. It is difficult to describe the differences between attributes.
From the viewpoint of maximizing the ranking consistency of alternatives, the attribute weight optimization model is built based on the extended LINMAP method. To illustrate the superiority of the proposed method in Section 3.3, the proposed method is compared with the method in literature [2]. Take the data in the first stage as an example. The result is displayed in Fig. 6. The ordinate represents the comprehensive values and the compromise ranking values. M1S1, M1S2 and M1S3 represent the comprehensive values of each state by the proposed method. M1R represents the compromise ranking values by the proposed method. M2S1, M2S2 and M2S3 represent the comprehensive values of each state calculated by the method in literature [2]. M2R represents the compromise ranking values by the method in literature [2].
The comparison of the results by the two methods.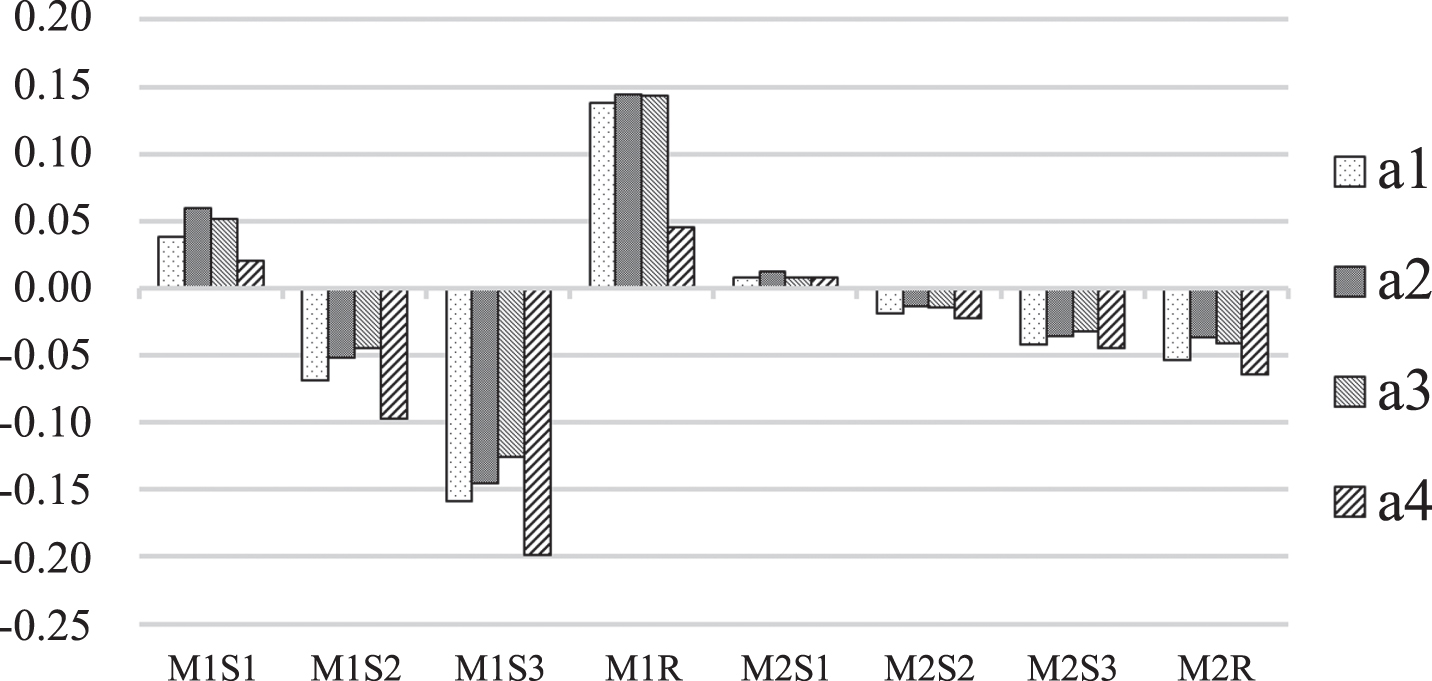
In order to compare the characteristics of model M3, DM data are calculated according to the proposed method and the method in literature [33]. The stage weights calculated by the proposed method is λ = (0.1835, 0.1433, 0.3628, 0.3104). The stage weights calculated by the method in literature [33] is λ′ = (0.1016, 0.1381, 0.2502, 0.5101). The method in literature [33] is based on the temporal characteristics of the data, and does not take into account the changes of data in different stages. The proposed method takes into account both the temporal characteristics and the stability of the data changes. These considerations are more in line with the actual DM environment. The comprehensive values and the compromise ranking values are showed in Table 4. According to the performances of the compromise ranking values, the values obtained by the method in literature [3] are bigger than the proposed method. From the final rank of alternatives, the two methods get the same rank a3 > a2 > a1 > a4, so the proposed method is desirable. According to the comparison results with different methods, the proposed method has advantages in the following aspects. (1) Considering the impact of DMs’ risk preferences is more in line with the actual DM process. (2) The proposed method makes full use of information, so the differences between attribute values are obvious. (3) The proposed method can improve the ranking consistency under different states. (4) Considering the minimization of the opportunity loss, the temporal characteristics and the stability of multistage data changes, the results can be both subjective and objective. The proposed method aims to solve the MSURDM problems without probability information. Based on the ideas of maximizing the ranking consistency and minimizing the opportunity loss, the proposed method can also be extended to solve the MSURDM problems with known probability information.
The ranking result by different methods
The ranking result by different methods
This study is capable in dealing with the MSURDM problems without probability information and allows DMs to express their risk preferences under different states. First, considering the impact of DMs’ risk preferences, the threshold of possibility degree is proposed to design a new value function. Our results are more distinct and have a higher utilization rate. Next, based on the LINMAP method and the entropy-weighing method, a two-stage model is developed to handle with attribute weight. The comparison results show that the ranking consistency by the proposed method is better and the diversity of attribute weights is bigger. Then, to aggregate the values in different states, the relative entropy method is used to measure the opportunity loss. Thus, the stage weight optimization model is designed in the viewpoint of minimizing the opportunity loss. The comparison results show that the proposed method is feasible and desirable.
In future work, a more appropriate method to deal with the MSURDM problems with uncertain probability information are an interesting topic. Besides, the MSURDM problems with multiple reference points are also considered.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China [grant numbers 71171112, 71502073, 71601002]; Scientific Innovation Research of College Graduates in Jiangsu Province the Fundamental Research Funds for the Central Universities [grant numbers KYZZ16_0147]; Humanities and Social Sciences Foundation of Ministry of Education of China [grant numbers 16YJC630077]; Anhui Provincial Natural Science Foundation [grant numbers 1708085MG168].