
Abstract
In the stages of development of probabilistic expert systems, knowledge merging is a major concern. To deal with knowledge merging problems, several approaches have been put forward. However, in the proposed models, each original probabilistic knowledge base (PKB) is represented by a set of probabilistic functions fulfilling such knowledge base. The drawbacks of the solutions are that the output of model is also a set of probabilistic functions satisfying the resulting PKB and there is no algorithm for implementing the merging process of PKBs in which each of them consists of probabilistic constraints. In this paper, distance-based approach is utilized to propose a new method of merging PKBs to ensure that both the input and output of methods are represented by sets of probabilistic constraints. To this aim, the relationship between the probability rules and the probabilistic constraints, and the several transformation methods for the representation of the original PKB are presented, a set of merging operators (MOs) is proposed, and several desirable logical properties are investigated and discussed. Several algorithms for merging PKBs are presented and the computational complexities of these algorithms are also analyzed and evaluated.
Introduction
Improving appropriate methods to build and maintain the action of knowledge-based systems is very necessary. In security systems, advanced methods of symbolic knowledge representation are used to integrate different, distributed source of information and in this way to make a system be flexible and more effective [1]. It is necessary to transform information stored in knowledge bases when two computer systems need to be integrated or when they exchange content of their knowledge bases [2]. In order to ensure that systems could interact with each other, the knowledge bases originating from these systems have to be consistent. Knowledge merging could be understood as a process of creating a consistent knowledge from a set of knowledge bases deriving from different systems [3]. Knowledge merging is an important problem and its applications are many and diverse. The process of merging could require that knowledge bases should change to ensure the consistency of the merged knowledge base. Therefore, it is a difficult problem and considering these changes is very essential. Knowledge merging could be observed in two respects: Merging knowledge bases which are not similar and merging a set of different representations for same knowledge base but different in representing degree [3]. Therefore, the first task in the knowledge merging process is to solve the inconsistency in knowledge bases. A data filling approach for incomplete set in which missing data is filled in terms of the probability of objects appearing in the mapping sets of parameters could find in [4]. A class of basic inconsistency measures for probabilistic framework has been introduced in [5, 6]. In a probabilistic environment, some strategies have been developed to deal with the inconsistency of a knowledge base. The method of modification of probabilities is one of the most common approaches. This method has been applied in [7–10].
A general model of knowledge merging problem referring to its inconsistency in distribution aspect was introduced in [3]. In this work, the author worked out and discussed the knowledge merging problem, postulates for knowledge merging and algorithms for this process. In a logic environment, some approaches were proposed to merge propositional knowledge [11–13]. The main idea of those strategies is often to build a family of MOs: Model-based operators and Formula-based MOs [11], DA2 MOs [12], MOs (Quota, Gmin) [13]. MOs in [11, 12] are built in the propositional logic framework and they require all the knowledge bases have the same importance, priority, or feasibility. Moreover, model-based operators cannot take into account inconsistent knowledge bases, but in some cases the information from these bases can be useful while the drawback of formula-based MOs is that the sources of information could be lost in the merging process.
It can be necessary to merge knowledge bases with more structure than the one of propositional logic. In this case weighted approaches are the best way. This is usually represented using possibilistic logic. For possibilistic knowledge merging issue, there are many different methods [14–16] proposed to solve. Merging process of these methods includes two stages: the separation and the combination. In the first step, each knowledge base is divided into two sub-bases and then the combination step employs different operators to combine different classes of sub-bases. However, there is no possibilistic merging operator satisfying all the postulates for merging possibilistic knowledge bases [16]. Another method proposed in [17] state that keeping weighted information after merging is not always necessary. The models of this work are models of the formula representing the integrity constraints that are maximal with respect to the lexicographic ordering. However, the drawback of the solutions is that the work does not present a representation theorem for the generalized postulates. Moreover, the merging results are usually consistent when using the propositional MOs, while the merging results may be inconsistent if using the possibilistic MOs.
Within the probabilistic framework, knowledge merging is understood as a process of building a joint probability distribution from an input set of low-dimensional distributions [18–20]. The main purpose of this work is to create a unifying framework for operations with probability distributions that would be used for description of iterative procedures for proposing solving methods. However, the convergence of those algorithms in [18–20] have not been carefully considered. Another approach is to build MOs based on convex Bregman divergences. A family of probabilistic MOs was first introduced in [21] and they were further studied in [22, 23]. These operators were discussed, evaluated, and compared to each other in detail in [23]. However, the main limitation of approaches proposed in [21–23] is that it only works with PKBs represented by probability functions.
In the previous work [24], the representation of PKB by probability functions and divergence distance functions is taken into account. A deeply survey is first made on how to compute a set of probability functions satisfying PKB, then the way these functions could be employed to merge probabilistic knowledge bases by proposing two MOs based on divergence distance functions has also been shown. Satisfied probabilistic functions correspond to convex optimization problems or linear programs while all these operators correspond to convex optimization problems. However, the propositions and examples are given but there is no proofs nor algorithms to implement the merging process. Moreover, the output of the proposed model is only the probabilistic functions representing newly merged knowledge base being not represented in the same form as the original knowledge bases.
This paper is extended from our conference paper [24]. It introduces in more details how to calculate a set of probability functions satisfying a PKB, probability merging vector as well as the new probability of constraints in merged PKB. Comparing with the conference paper our contributions are based on the fact that propositions for calculating such values are proved by pointing that there always exists optimal solutions [25] and the output of merged PKB is similar to original PKBs in representation. Besides, main algorithms using to merge PKBs have been put forward by obeying probability rules and condition property of MOs. In addition to pointing out that proposed operators fulfill several desirable properties, two new operators is investigated more and unproven remaining statements have also been made. Finally, a simple but explanatory example to illustrate, analyze and evaluate computational complexity of proposed algorithms is presented.
The rest of this paper is organized as follows. The second section presents the related work on approaches for merging PKBs. Some basic notions about probability function, probabilistic constraint, probability rules, the representation of knowledge bases in a probabilistic framework, and a PKB profile for such bases are presented in the third section. The subsequent section gives distance-based probabilistic MOs. The way to determine probabilistic merging vector as well as the desirable logical properties for MOs are also drawn and discussed in this section. Algorithms for merging PKBs as well as the analysis and evaluation of these algorithms are presented in the next sections. The final section will conclude the main results that have been investigated and give some future works.
Related work
The problem of merging PKBs has been studied for a long time and gets a lot of attention in recent years. The idea of probabilistic merging has been introduced and discussed in detail by Vomlel [18]. This work proposed a design and characterization of methods applicable to the merging process of knowledge bases represented by a set of probability distributions. Vomlel used the means of the Iterative Proportional Fitting Procedure (IPFP) to build a joint probability distribution from an input set of low-dimensional distributions. In the case of inconsistent input set, five iterative methods were proposed, namely: CC LCC, AA, GA, and GEM. In the case of consistent input set, iterative proportional fitting procedure have the best convergence rate of five iterative methods for inconsistent input set. However, several properties of methods were not proven and not achieved in this general case due to problems with probability distributions containing zeroes. Vomlel continued proposing another method that extends IPFP to deal with inconsistent constraints, named GEMA [19]. It generalizes the concept of expectation maximization. The time performance of GEMA was extremely sensitive to both the initial knowledge bases and the constraints. As full joint distributions were directly manipulated by GEMA, the advantages of other probabilistic models such as the Bayesian networks (BNs) could be taken. In order to overcome these limitations, Zhang et al. [20] proposed another algorithm called Smooth which addressed both consistent and inconsistent constraints. However, the convergence of Smooth was only proven empirically through experiments. Therefore, the key drawback of the approaches [18–20] is that PKBs must be represented by probability distributions.
Adamcik [23] associated the geometrical notion of projections by means of a Bregman divergence with the framework of pooling operators to solving the problem of probabilistic knowledge merging. A class of MOs based on minimization of a sum of convex Bregman divergences was introduced and proposed. The most common model of merging operator was defined by
The new approach proposed in this paper is compared with existing ones given in the literature. Like the merging methods given in [18, 26], this new approach also employs distance functions to find a set of probability functions representing common PKB. However, the first difference is that some propositions introduced in [9, 10] are applied to find probabilistic functions satisfying original PKB that is represented by probabilistic constraints. The second difference is that probability rules proposed [27] are employed to find new value of probabilistic constraints in common PKB.
Basic notions
A sample space, denoted by
Let
(
(
(
(
(
Any countable sequence of disjoint sets (synonymous with mutually exclusive events) F1, F2, … F n satisfies
(
Intuitively, a constraint (F|G) [ρ] means that our knowledge in F given that G hold has probability value ρ. If F does not depend on G,G ≡ ⊤ , (F| ⊤) [ρ], is abbreviated by (F) [ρ].
Let
Distance-based probabilistic MOs
Desirable properties
In the rest later, several properties of our family of probabilistic MOs used to characterize MOs will be put forward. Let Γ be a function
The property CP1 assures that if the input PKB profile is consistent then the result of merging will be a subset of the intersection of the set of all probability function values satisfying
The property SCP assures that if the input PKB profile is consistent then the result of merging will be the intersection of the set of all probability function values satisfying
The property IP state that the result of merging process should not be affected when an empty PKB is added.
The property EP implies that result of merging process should not be contingent on the occurrence order of PKBs.
The property CP2 implies that the result of merging process should not be affected when a PKB profile which the intersection of the set of all probability function values satisfying
This property states that the intersection of the merging results of two distinct sets of knowledge bases is not empty, it should be similar to the merging of all PKBs in those two sets.
This property states that if the merged PKBs in
This property states that the intersection of the merging results should be empty.
Satisfied probabilistic functions
Intuitively, a ij is either 1-ρ, -ρ or 0 dependent on whether F i ∩ G i satisfies Θ j , F i ∩ G i satisfies Θ j , or not computable.
Proposition 2 is the result of Proposition 4 which was proposed and proved in [10].
Proposition 3 is the result of Proposition 5 which was proposed and proved in [10].
Proposition 4 is the result of Proposition 6 which was proposed and proved in [10].
Let
Proposition 5 is the result of Proposition 9 which was proposed and proved in [10].
Proposition 6 is the result of Proposition 5 which was proposed and proved in [24].
For any
d (x, y) =0 iff x = y
d (x, y) ≥0 d (x, y) + d (y, z) ≥0, d (x, z) =0
where x, y, and z are probability functions.
The probabilistic merging operator Γ SQ
CP1. This property is easily result from SCP.
IP and EP. Follows from Definition 15
AP. Firstly,
Secondly,
Then
Therefore,
SDP. The proof for this property is similar to the proof for 4.1.5 in [23].
DP. This property is easily result from SDP.
CP2. By property SCP, since
Let
Let
Therefore,
Secondly,
Then
The proof for remaining properties of Γ LE is similar to that of Γ SQ by using distance function d SQ (x, y) instead of d KL (x, y).
Let
Let
From Definition 6, it follows that
Let
IP and EP. Follows from Definition 19. CP2: If
In this section, algorithms for merging PKBs are proposed.
Finding probability merging vector
Algorithms
The problem (3) with constraints (4)–(5) is implemented by using LPSolve (http://lpsolve.sourceforge.net) and ojAlgo (http://ojalgo.org/).
The solution of the problem (9) is similar to the method of solving (1). By Proposition 6, algorithms lead to a same result.
The computational complexity
The interior-point methods [29] were employed to solve convex optimization problems:
One of these methods is the barrier method. Now assume that the problem is solvable. Let m be the number inequality constraints,
Let function
The constant γ depends on the backtracking parameters α and β,and is given by
The computational complexity of algorithm is
The following propositions provide some assessments of the complexity of the algorithms.
By (26),
Therefore, the cost is
Algorithms
The problem (14) with constraints (15) is also implemented by using interior-point algorithm [29].
The computational complexity
By (28) and (14),
Therefore, the cost of the SQMA is
Algorithm for computing new probability value of constraints
By using algorithm for finding probability merging vector, distance-based merging algorithms, and algorithm for computing new probability value of constraints, a common consistent PKB can be obtained from a PKB profile. The process of merging PKB is presented in Fig. 1.
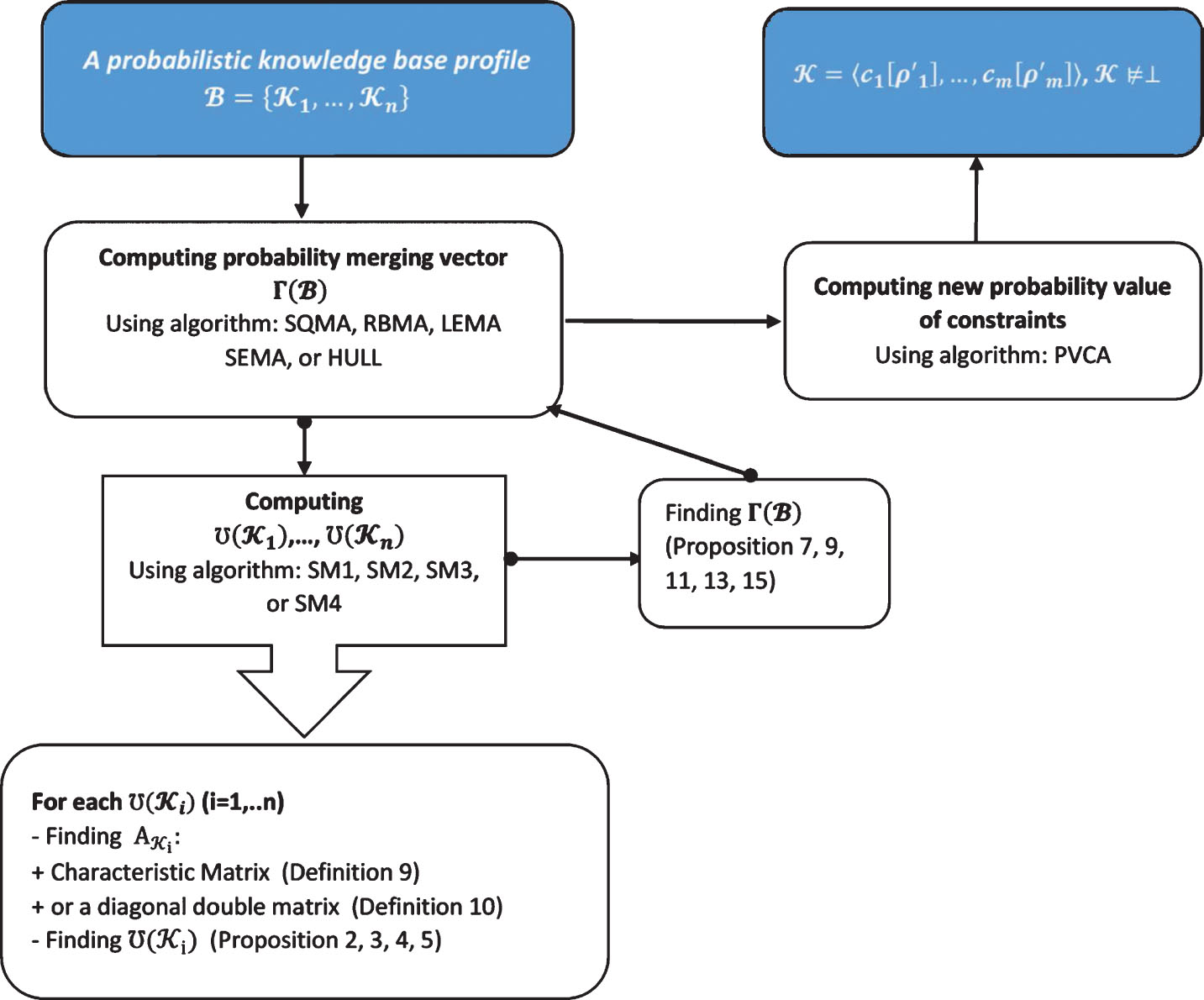
The process of merging PKBs.
To illustrate this merging process presented in Fig. 1, the following example will be considered:
A hospital makes a survey of depression disease. It assigns doctors who are neurologists to this survey.
These doctors provide the result in which the probability that people has depression disease (denoted by D) are, respectively, 0.7, 0.5, 0.5, 0.8, and 0.6; the probability that people always have sleep problems (denoted by S) are, respectively, 0.6, 0.5, 0.7, 0.7, and 0.8; the probability that people often feel life’s not worth living (denoted by L) are, respectively, 0.5, 0.5, 0.5, 0.6, and 0.6; the probability that a person has depression disease when that person who has always sleep problems are, respectively, 0.8, 1, 0.6, 0.75, and 0.7; and the probability that a person often feel life’s not worth living, given that he has depression disease are, respectively, 0.8, 1, 0.4, 0.75, and 0.5.
One of algorithms SM1, SM2, SM3, and SM4 is employed to find a set of probability function values satisfying
Table 1 shows these values when the SQMA, LEMA, SEMA are employed while Table 2 shows these values when the RBMA with different values of r and the HULL with different values of
Original PKBs and merged knowledge bases for algorithms SQMA, LEMA, and SEMA
Original PKBs and merged knowledge bases for algorithms SQMA, LEMA, and SEMA
Merged knowledge bases for algorithms RBMA and HULL
The detail for explaining the merging process and evaluating algorithms in this paper can be found in an online appendixrmbox1\footnote [1]https://vtn82.blogspot.com/2019/04/jifs.html.
In this paper, a new distance-based approach to implement the process of merging PKBs was proposed. The probabilistic MOs based on divergence concepts have been taken under deep consideration and adapted to new probabilistic merging framework by building distance functions between probabilities of constraints. Propositions to calculate the satisfied probabilistic functions of original knowledge bases, probability merging vector, and new probability of constraints in merged PKB were also proposed and proven. Then, postulates about logical relationships between the family of MOs and desirable properties were given. Finally, computational propositions were employed to build merging algorithms. The key differences between the proposed method and existing ones are that input knowledge bases and the merged knowledge base are represented by probabilistic constraints, and our method is considered in a sample space context. However, the input of merging algorithms was PKBs required to be in the same form. Therefore, in the future, new methods will be going on investigating to allow the original knowledge bases to vary in form.
Footnotes
Acknowledgment
This work has been supported by Vietnam National University, Hanoi (VNU), under Project No. QG.19.23. The authors would like to thank Professor Quang Thuy Ha and Knowledge Technology and Data Science Lab, Faculty of Information Technology, VNU - University of Engineering and Technology for expertise support.